1. Introduction
Numerical weather prediction (NWP) predicts future atmospheric states using numerical methods on high-performance computers to solve equations describing atmospheric dynamics and thermal processes under certain initial conditions. Hence, it can be seen as an initial value problem [
1,
2,
3]. Information in the atmosphere is often expressed in the form of data. In order to obtain an accurate initial field, we need to increase the credibility of the data and artificially remove redundant information. This also means reducing entropy. Data assimilation (DA) merges observations with numerical model forecasts to estimate the current optimal atmospheric state. The analysis, which results from data assimilation, is employed as the initial field for NWP [
4]. Four-dimensional variational assimilation (4D-Var) is the most popular data assimilation method, which is widely used in many operational NWP centers [
5,
6,
7,
8,
9,
10].
The calculation of the 4D-Var assimilation system depends on the forecast model and the functional minimization calculation process to a large extent [
11]. The higher the accuracy of the forecast model, the better the effect of the assimilation system. However, the improvement of the model precision will not only increase the prediction time but also increase the computational cost of the tangent linear and adjoint models in the process of functional minimization [
12]. Meanwhile, the real-time performance of operational forecast determines the importance of computational efficiency. Therefore, the realization of the 4D-Var system must take into account the improved accuracy of the forecast model in the case of ensuring calculation efficiency. Currently, the approach that is achieved by reducing the resolution of the model is often adopted in the operational 4D-Var assimilation systems.
The ensemble assimilation method is an alternative to 4D-Var [
13]. Nevertheless, the ensemble method has a primary problem, which is that the number of ensemble members is much smaller than the dimensions of the system, resulting in sample errors, false correlations, and low-rank problems [
14]. The difficulty of 4D-Var stems from the complex forecast model. The difficulty of 4D-Var can be cut down by reducing the complexity of the forecast model.
With the development of machine learning (ML), the application of ML has penetrated various fields. As a data-driven method, it does not care about the calculation of the traditional physical model but obtains the underlying features and law through training data and then gains the simulation results [
15]. A great deal of forecast product data and satellite observations provide a good opportunity for the application of ML in earth science [
16]. The ML method has achieved rich research results in the physical process simulation [
17,
18], parameter estimation, and DA [
19].
Dueben and Bauer trained the deep neural network (DNN) using the reanalysis data on a coarse-resolution grid with a spatial resolution of 6 degrees. They employed the DNN to forecast 500 hPa geopotential height for global regions and demonstrated the feasibility of ML in the weather forecast [
16]. Weyn et al. utilized the reanalysis data to train the convolutional neural network (CNN) and built a deep learning weather prediction (DLWP) to forecast the geopotential height of 500 hPa in the northern hemisphere and meteorological elements of 300–700 hPa [
20]. The experiments show that the prediction accuracy of the DLWP for the geopotential height of 500 hPa is better than that of the T42IFS model and lower than that of the T63IFS model. In terms of computational efficiency, the running time of the DLWP is much lower than that of classical forecasting models, which proves that ML is an essential means to solve the problem of computational cost effectively. At present, the simulation accuracy of NWP for subgrid-scale physical processes needs to be improved. Furthermore, these small-scale processes will affect the accuracy of forecast results [
21]. Therefore, it is crucial to improve the accuracy of the parameterization schemes of the physical process. Replacing traditional parameterization with ML is a way to improve accuracy. Rasp et al. used multilayer perceptron (MLP) to simulate a cloud parsing model. The experimental results show that the MLP parameterization scheme can run stably for a long time. Under the condition of ensuring the accuracy of the prediction results, the MLP parameterization scheme can reduce the computational cost [
22]. Yuval et al. demonstrate that it is possible to add physical constraints to the neural network parameterization to improve the physical interpretability of the neural network parameterization scheme [
23]. Song et al. used MLP to model the radiation parameterization scheme. The authors used the MLP parameterization scheme in the atmospheric model, which significantly reduced the root mean square error (RMSE) and increased the computational speed [
24]. Krasnopolsky gave a detailed introduction to the prospects, methods, evaluation criteria, and limitations of neural networks in subgrid-scale physical processes [
25]. Chantry et al. successfully emulated the nonorographic gravity wave drag scheme from the operational forecast model with the MLP [
26]. The experimental results demonstrate that the emulator can be coupled to an operational system for seasonal timescales and is more accurate than the parameterized scheme used in operational predictions. Bonavita applied the artificial neural network (ANN) to simulate weak-constraint four-dimensional variational data assimilation (WC-4DVar) [
27]. The results indicate that the assimilation products obtained by the ANN are similar to WC-4DVar. Furthermore, model errors can be corrected when the ANN is embedded in WC-4DVar. Hatfield et al. employed the MLP to simulate the parameterization of nonorographic gravity wave drag and applied the tangent linear and adjoint models of the MLP to 4D-Var [
28]. The research demonstrates that the tangent linear and adjoint models of the MLP can be used for data assimilation and weather forecast. There is no significant difference between the assimilation forecast result of this method and the operational NWP center. Nonnenmacher takes advantage of the DNN to simulate the Lorenz-96 model and investigates whether the DNN derivatives are available [
29]. The experimental results prove that the DNN can simulate kinetic models, and the accuracy of its derivatives is reliable and can be directly used for data assimilation and parametrization tuning.
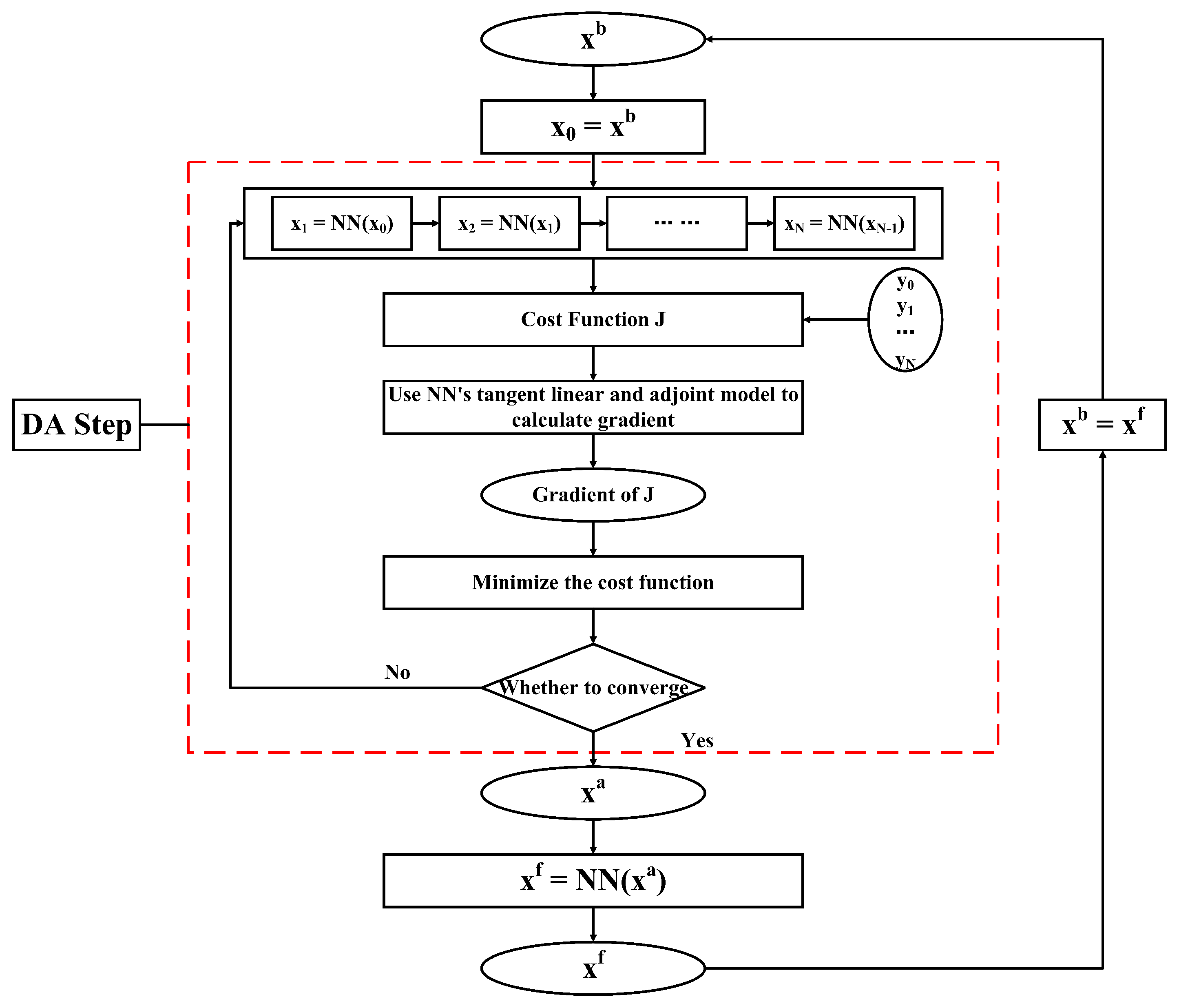
Although ML has rich research results in the numerical forecast, most of these results are only for a single problem in the assimilation system, and it does not propose a pure data-driven data assimilation solution from a system-wide perspective. Based on the idea of ML simulator, this paper structures a 4D-Var assimilation system based on machine learing (ML-4DVAR). It replaces the two most time-consuming processes in the traditional 4D-Var system with machine learning: one is the forecast model, and the other is the tangent linear and adjoint models. In order to show the feasibility of the system, we conduct 4D-Var assimilation experiments with the Lorenz-96 model. The experiments demonstrate that the ML-4DVAR can get more accurate analysis results and improve computational efficiency compared to traditional implementations.
The remainder of the paper is organized as follows.
Section 2 presents the structure of the ML-4DVAR.
Section 3 investigates the performance of ML-4DVAR with the Lorenz-96 model. Finally, we conclude the results of this research and discuss future work in
Section 4 and
Section 5.
4. Discussion
In the study, we make use of the tangent linear adjoint models of the ML model in 4D-Var. The prerequisite for applying the tangent linear and adjoint models of the ML model in 4D-Var is that the ML model accurately simulates the physical model. First, the BNN was built according to the characteristics of the physical model. Then, Joint-4DVAR is established, in which the tangent linear and adjoint models are derived from the BNN, and the prediction model is derived from the physical model. After that, this article tests the performance and computational efficiency of ML-4DVAR. ML-4DVAR is an assimilation system based on the ML model. Its prediction model and tangent linear and adjoint models are all provided by the ML model. Finally, we train the ML model on the observation data and build the 4D-Var assimilation system on this basis. The above results are discussed as follows:
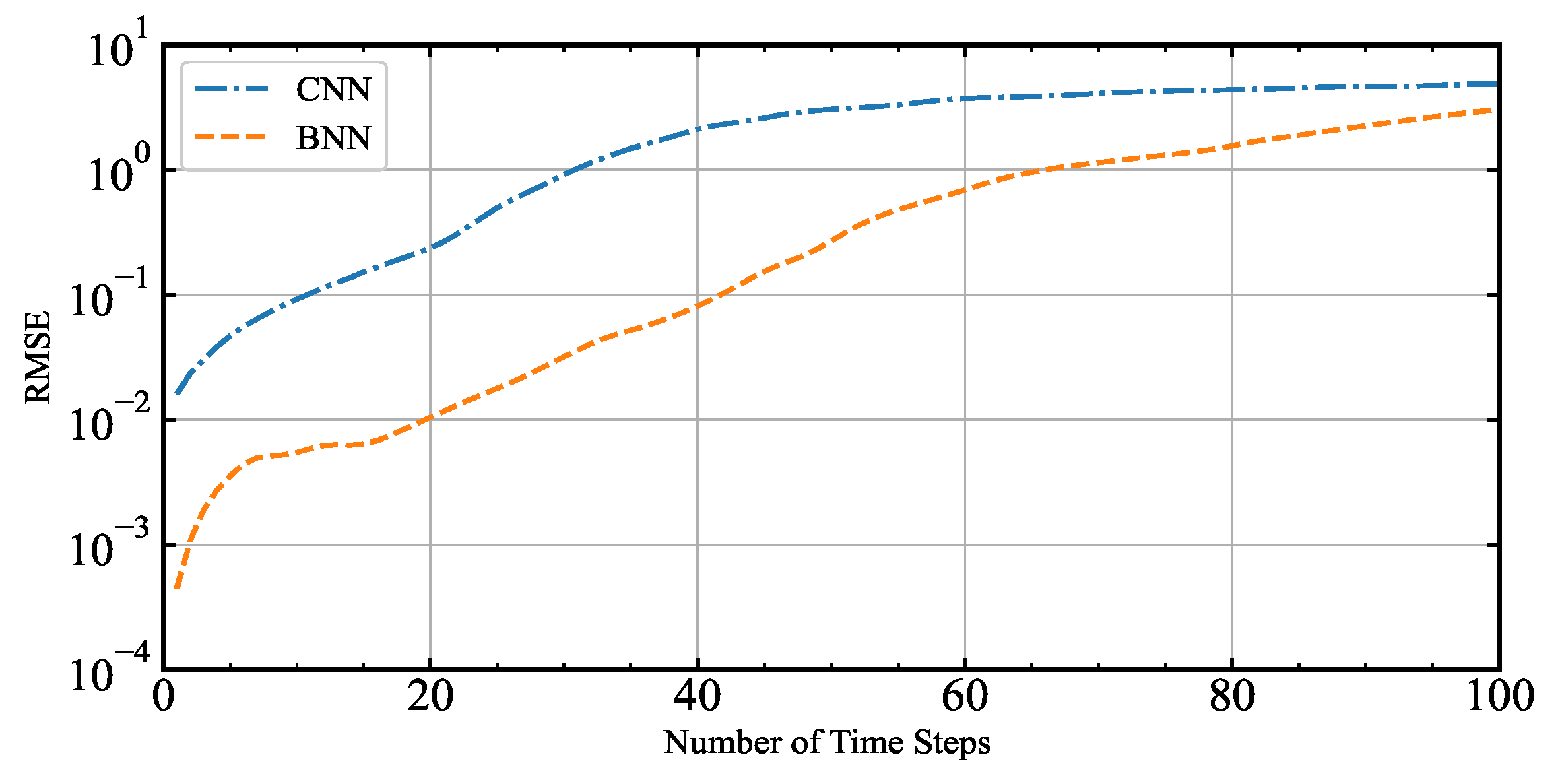
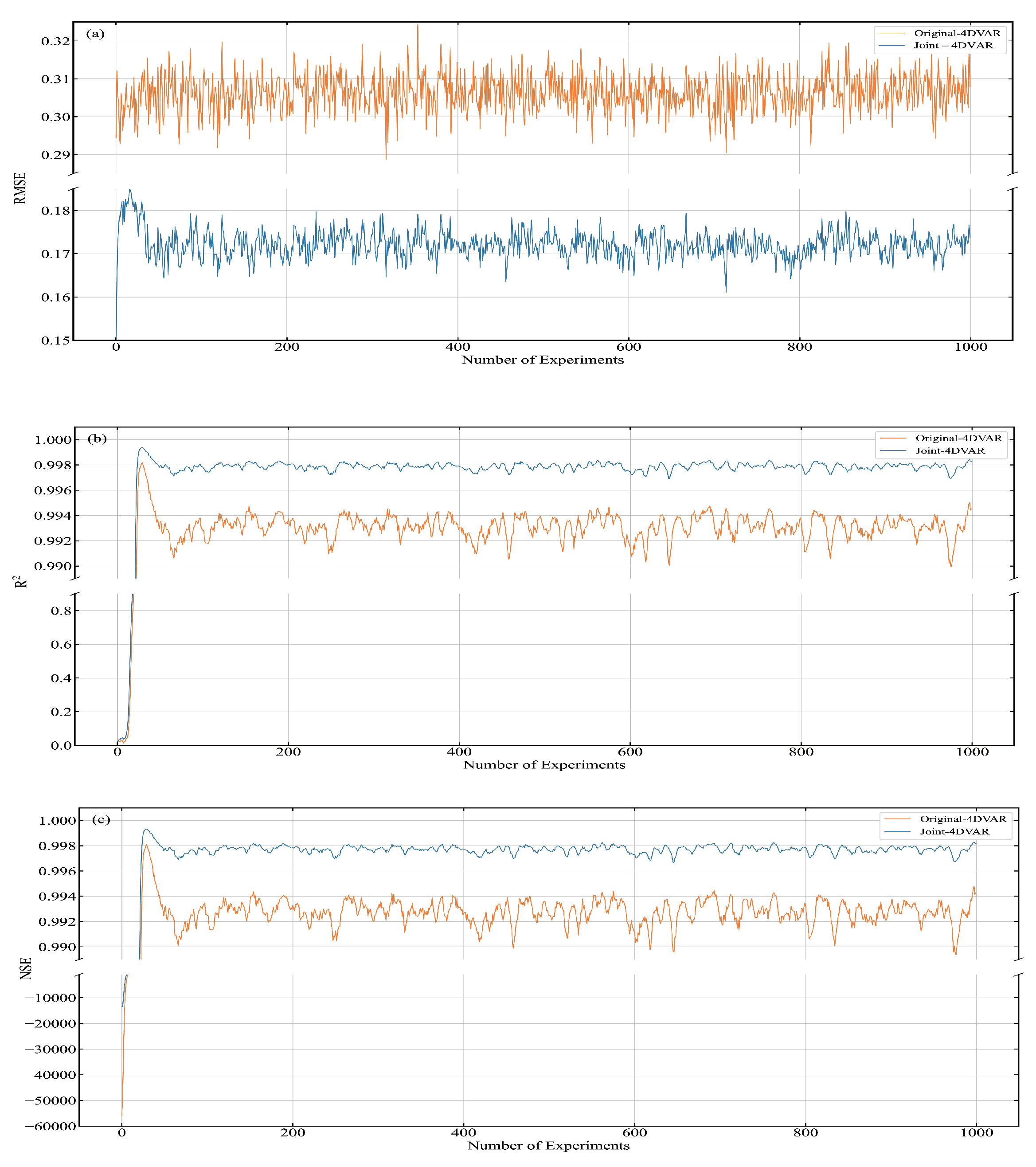
The BNN trained on Lorenz-96 model data can simulate the Lorenz-96 model. The RMSE of the one-step predicted value and the actual value of the BNN is 4.46 ×
, it can be seen that the RMSE is very small. The consequences indicate that BNN can simulate and predict dynamic systems well. The reason is that the bilinear operation embedded in the neural network is an essential feature of the dynamic system [
33].
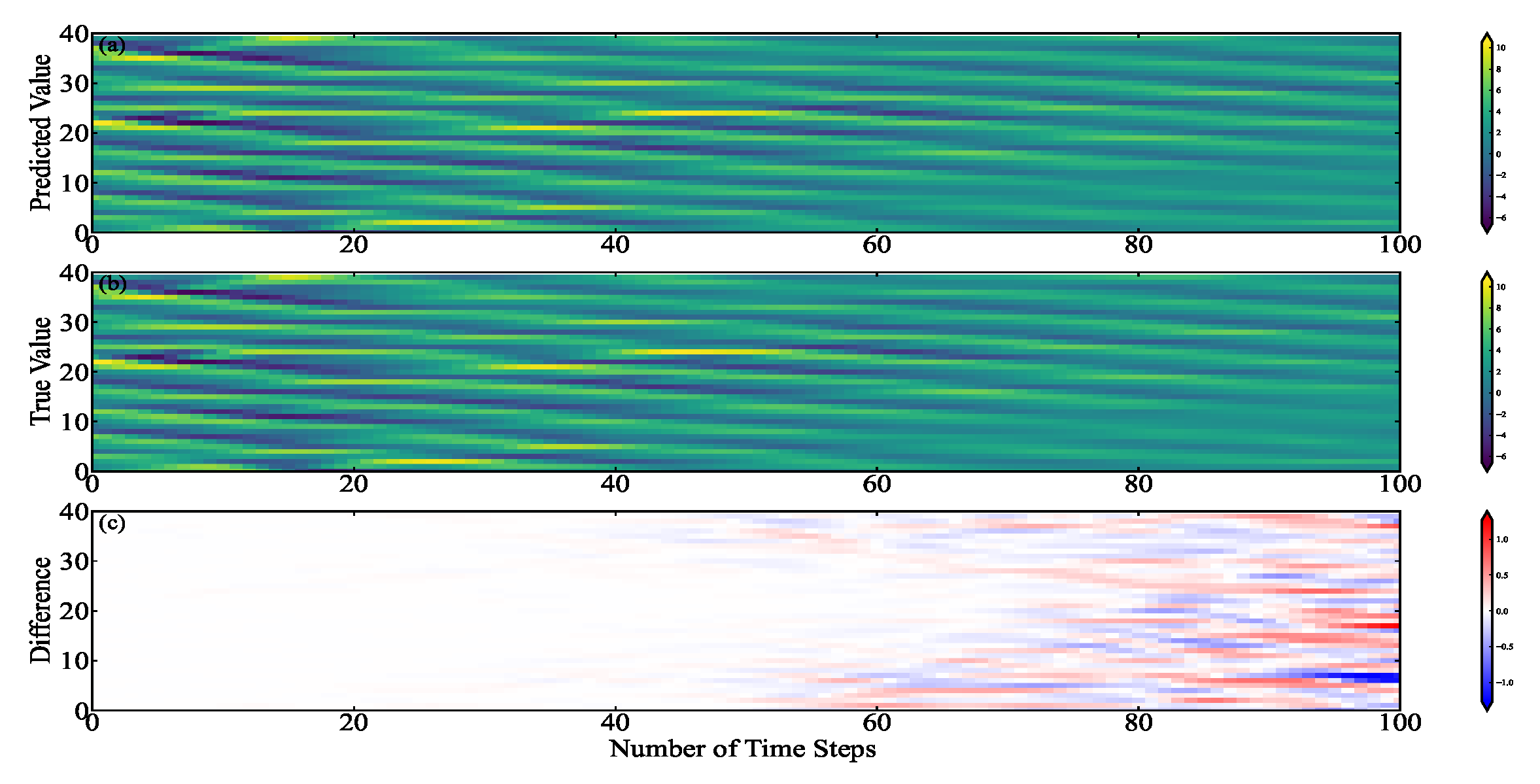
The Joint-4DVAR is reliable, and its computational efficiency is satisfactory. Through the analysis of the experimental results, we can see that the overall error between the Joint-4DVAR analysis and the forecast and the true is more minor. The forecast models of Joint-4DVAR and Original-4DVAR are derived from physical models. The assimilation module of Joint-4DVAR is different from that of Original-4DVAR. The 4D-Var used in the assimilation module of Joint-4DVAR is built based on the tangent linear and adjoint models of the neural network. The 4D-Var employed by the assimilation module Original-4DVAR is established based on the tangent linear and adjoint models of the physical model. The performance of Joint-4DVAR is better than that of Original-4DVAR, and the calculation efficiency is higher, indicating that the performance and calculation efficiency of the assimilation module of Joint-4DVAR is higher than that of Original-4DVAR. The results show that the tangent linear and adjoint models of the neural network can be used in 4D-Var, and its calculation results are more accurate, and the running time is shorter.
This article builds ML-4DVAR on the Lorenz-96 model. It can be seen from the experimental results that the performance of ML-4DVAR is better than that of Original-4DVAR, and the computational efficiency of ML-4DVAR is higher. This article also compares the assimilation performance and computational efficiency of ML-4DVAR and Joint-4DVAR. We can see that compared with Joint-4DVAR, the assimilation performance of ML-4DVAR is improved very little, while the computational efficiency of ML-4DVAR is greatly improved. The assimilation modules of ML-4DVAR and Joint-4DVAR are the same, and their prediction modules are different. ML-4DVAR uses the neural network models for prediction, and Joint-4DVAR utilizes the physical models. The calculation efficiency of ML-4DVAR is higher than that of Joint-4DVAR. The result shows that neural networks can accelerate the forecasting process.
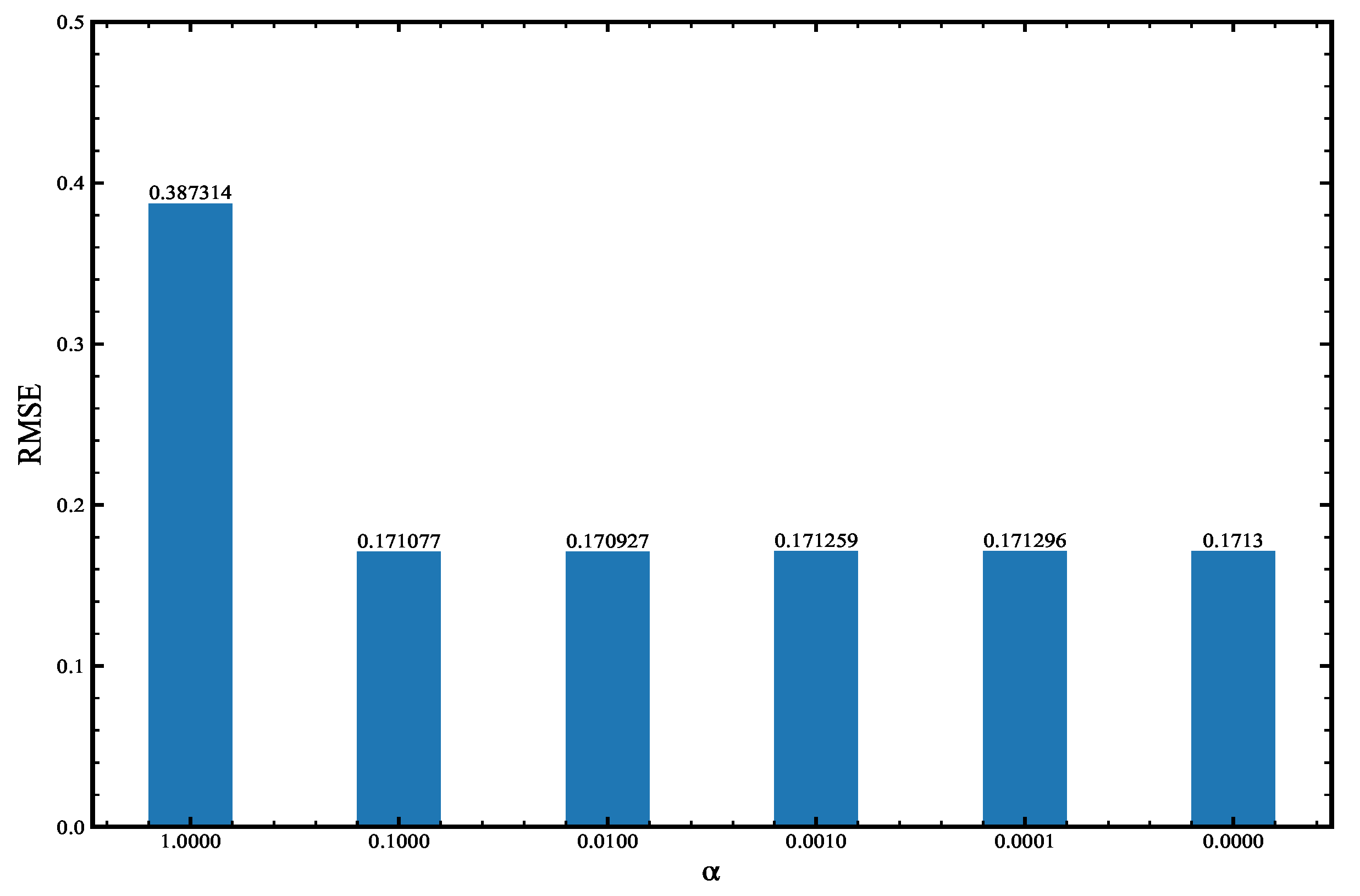
Neural networks trained using observation data are available. Although -4DVAR was not very stable during the first period, after the 50th time step, -4DVAR can be employed for assimilation and forecasting. We compared Joint-4DVAR, ML-4DVAR, and -4DVAR. The assimilation performance and computational efficiency of ML-4DVAR are the best. This results indicate that the pure data-driven numerical prediction system is feasible in the Lorenz-96 model.
In summary, the BNN can simulate dynamic models well. The performance of Joint-4DVAR is excellent, which shows that the physical model and the 4D-Var based on the tangent linear and adjoint models of the ML model can work together. Among the three assimilation systems, Original-4DVAR, Joint-4DVAR, and ML-4DVAR, the system with the best assimilation performance and calculation efficiency is ML-4DVAR. The results prove that the assimilation system composed of the ML model and its tangent linear and adjoint models are satisfactory. This paper establishes the 4D-Var assimilation system based on ML. This study provides a method to obtain the tangent linear and adjoint models in 4D-Var.
5. Conclusions
In order to reduce the development difficulty of the tangent linear adjoint model and improve the computational efficiency of 4D-Var, we establish ML-4DVAR. ML-4DVAR’s forecast model and tangent linear and adjoint models are derived from the ML model. The experiments show that the assimilation performance and computational efficiency of ML-4DVAR are better than those of Original-4DVAR. The results prove that building the 4D-Var assimilation system based on ML is feasible. This study shows that the forecast model based on the ML model and the Jacobians of the ML model can work stably for a long time in 4D-Var. This study expands the application scope of neural networks in NWP and provides a reference for the future combination of ML and DA.
However, there is still a problem in this study. From the experimental results, it can be seen that the results of ML-4DVAR are not available in the first 50 steps of the system just running. In the future, we need to improve and perfect the assimilation performance of the assimilation system in the early stage.
Nowadays, with the generation of large amounts of data and the emergence of various open-source software, we can build ML models more simply. Building a ML model is cheaper and faster than a physical model. There are two main applications of ML in NWP: one is to improve the accuracy of weather forecast [
26], and the other is to improve calculation efficiency. We need to build appropriate the ML models for different problems in this process. This method can reduce the difficulty of developing tangent linear and adjoint models, thereby expanding the application range of 4D-Var. The ultimate goal is to improve the accuracy of weather forecast in order to better understand and predict atmospheric systems. In the future, we need to build a suitable ML model for the actual atmospheric model in the future to support the application of ML in numerical weather prediction.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}