
DIR-Net: Deep Residual Polar Decoding Network Based on Information Refinement

Abstract
:1. Introduction
- (1)
- We design a novel information optimization module for polar decoding based on the attention mechanism. This module can avoid the interference of invalid information during the decoding.
- (2)
- With the designed information optimization module as the core, we construct an advanced deep learning decoding network. To our knowledge, this is the first time that the attention modules are used completely to construct a decoding network for polar codes. The network refines information step-by-step by cascading multiple attention modules and exhibits excellent decoding performance.
- (3)
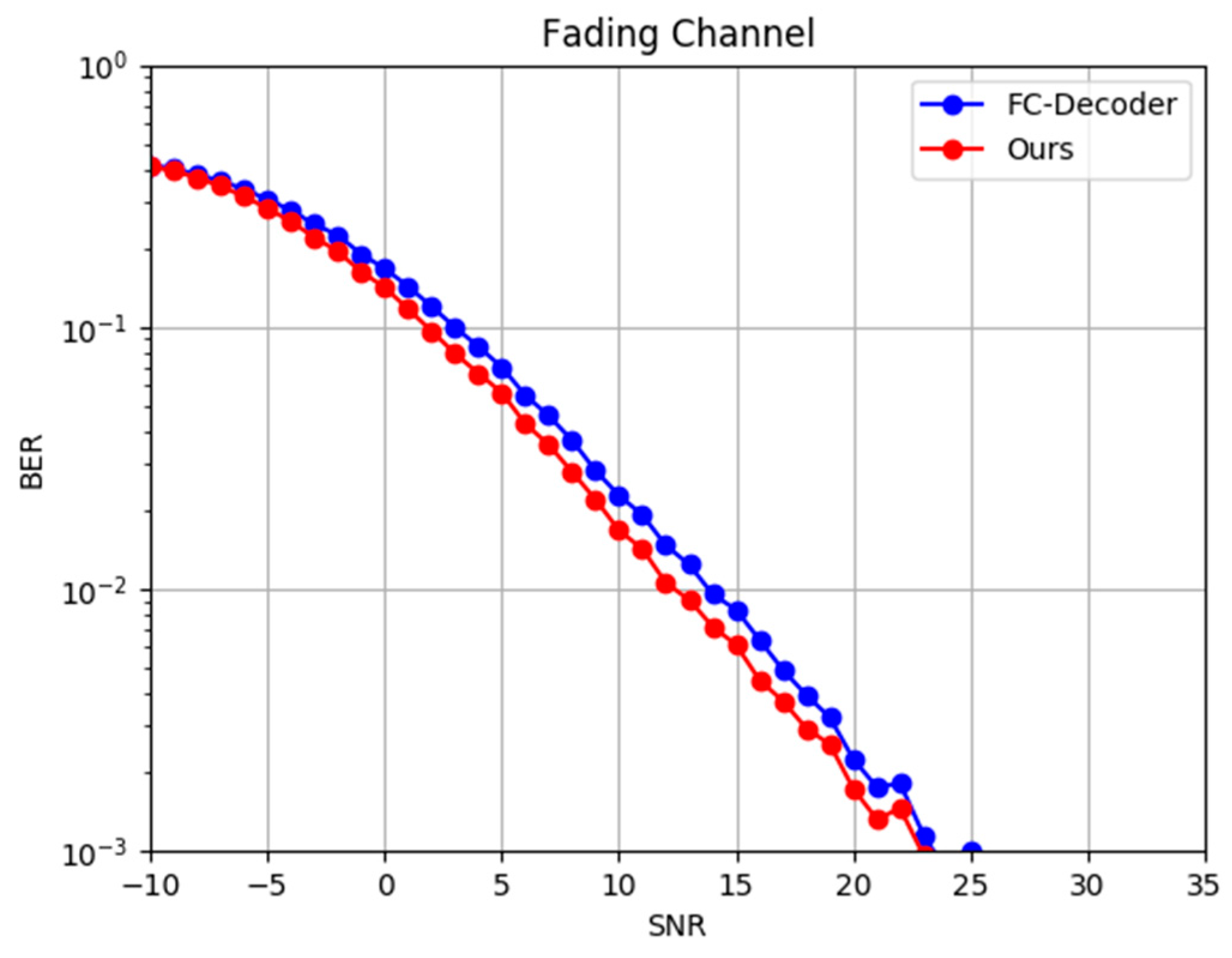
- We evaluated the effectiveness of the proposed decoding network in the Gaussian channel and the Rayleigh fading channel, respectively. The experimental results demonstrate that our proposed decoding network can effectively suppress the interfering information and achieve high BER performance in both channels.
2. Background
2.1. Polar Code
2.2. Neural Network Decoder
3. DIR-Net Method
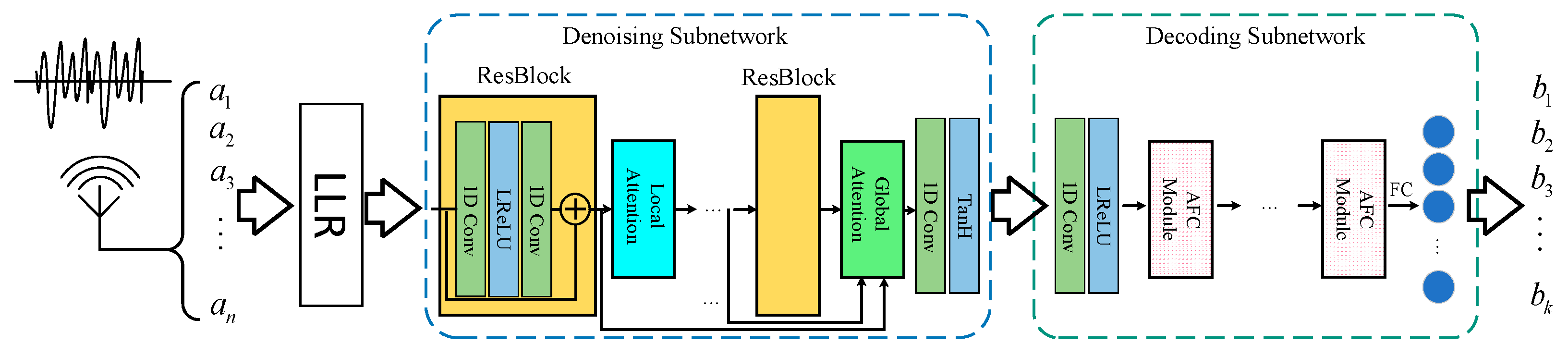
3.1. Overview of the Framework
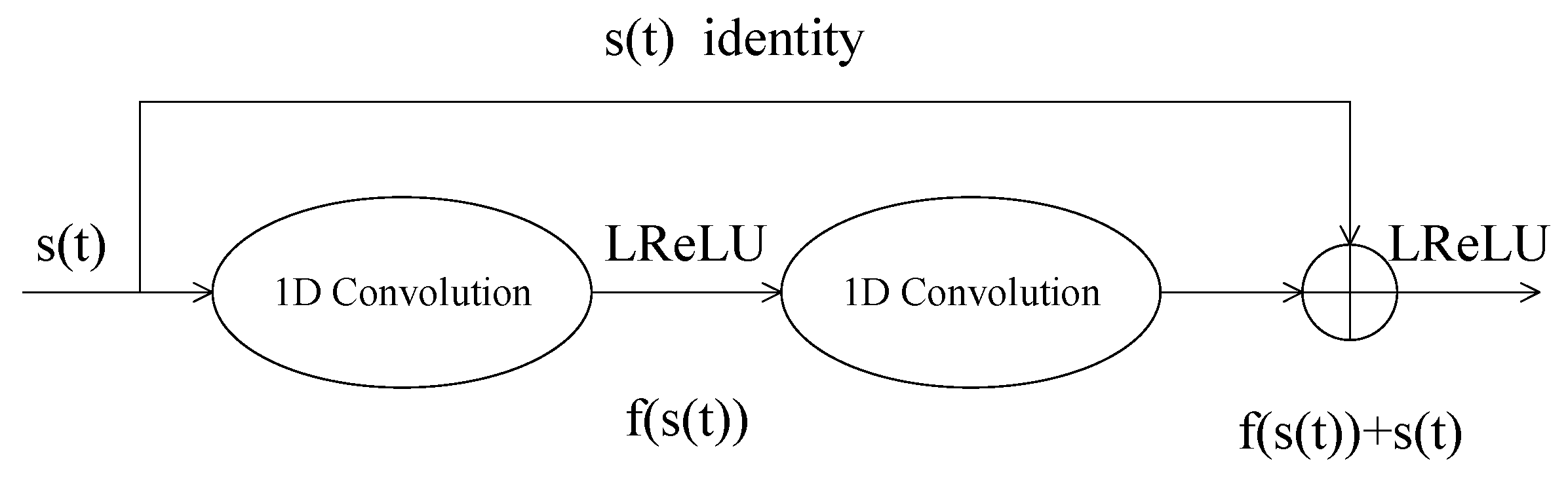
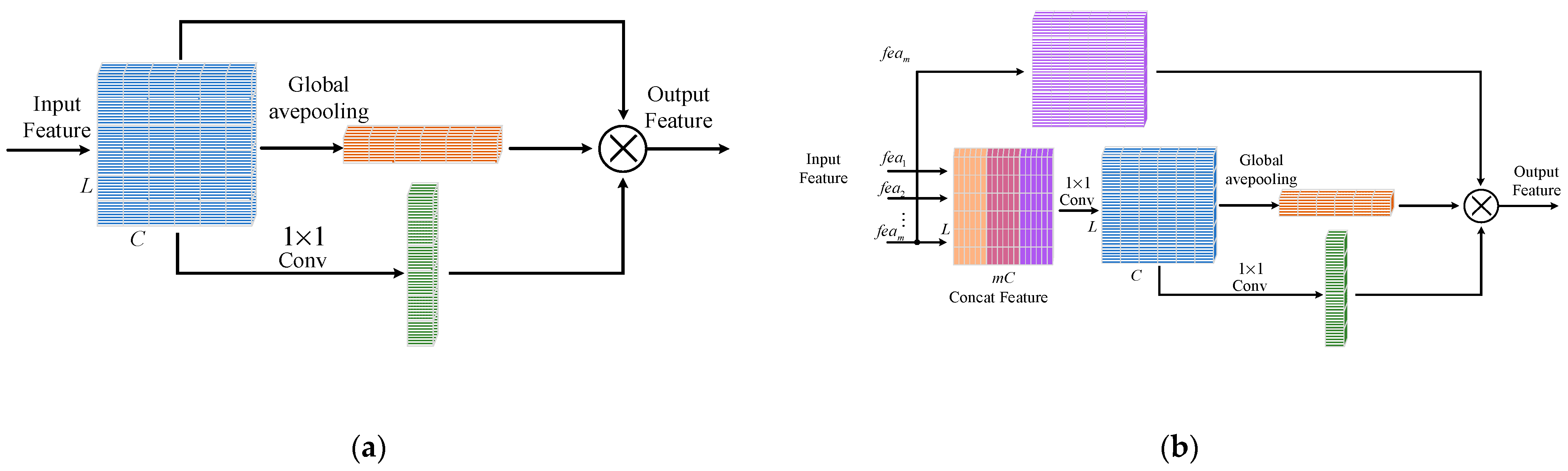
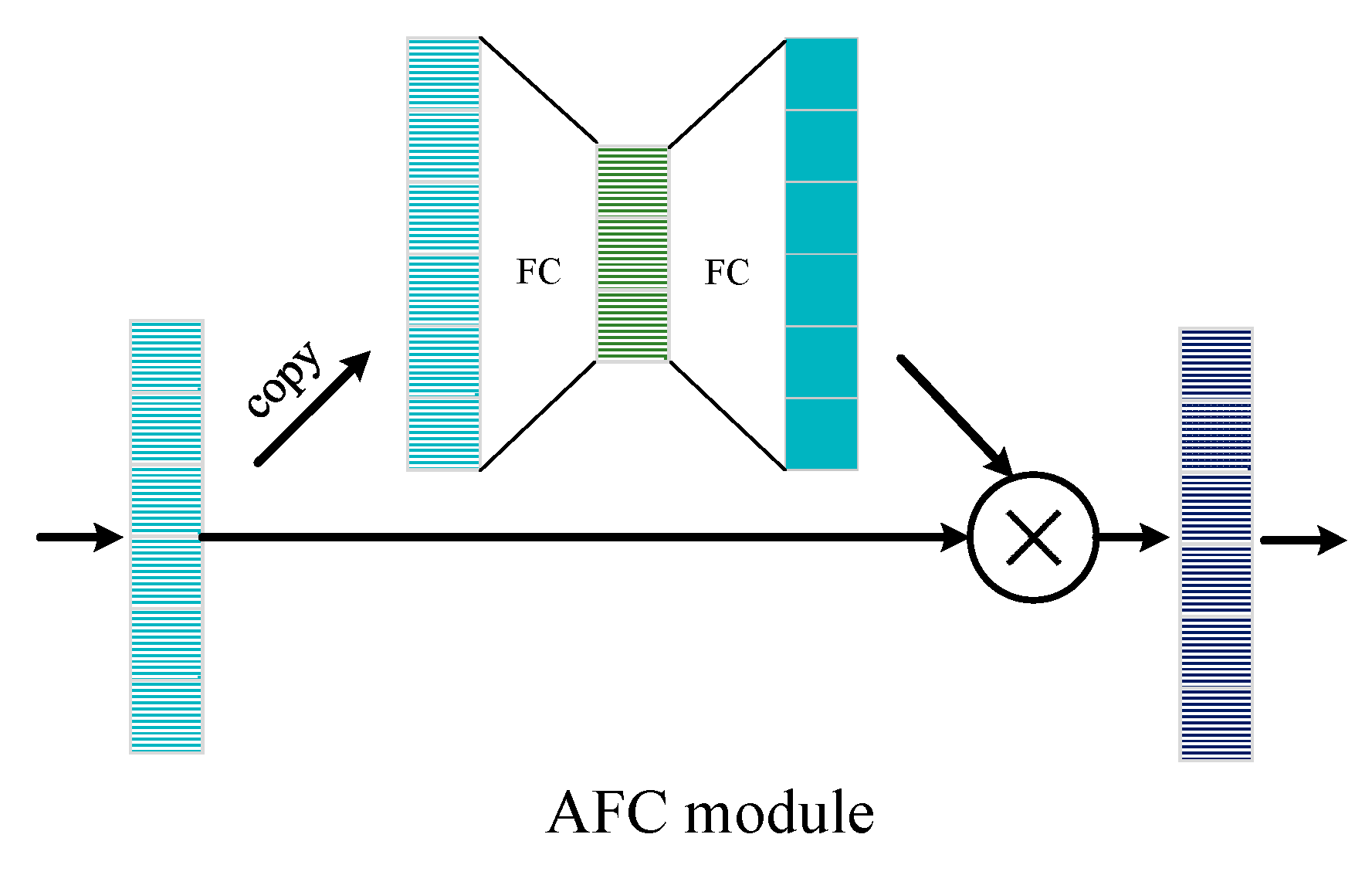
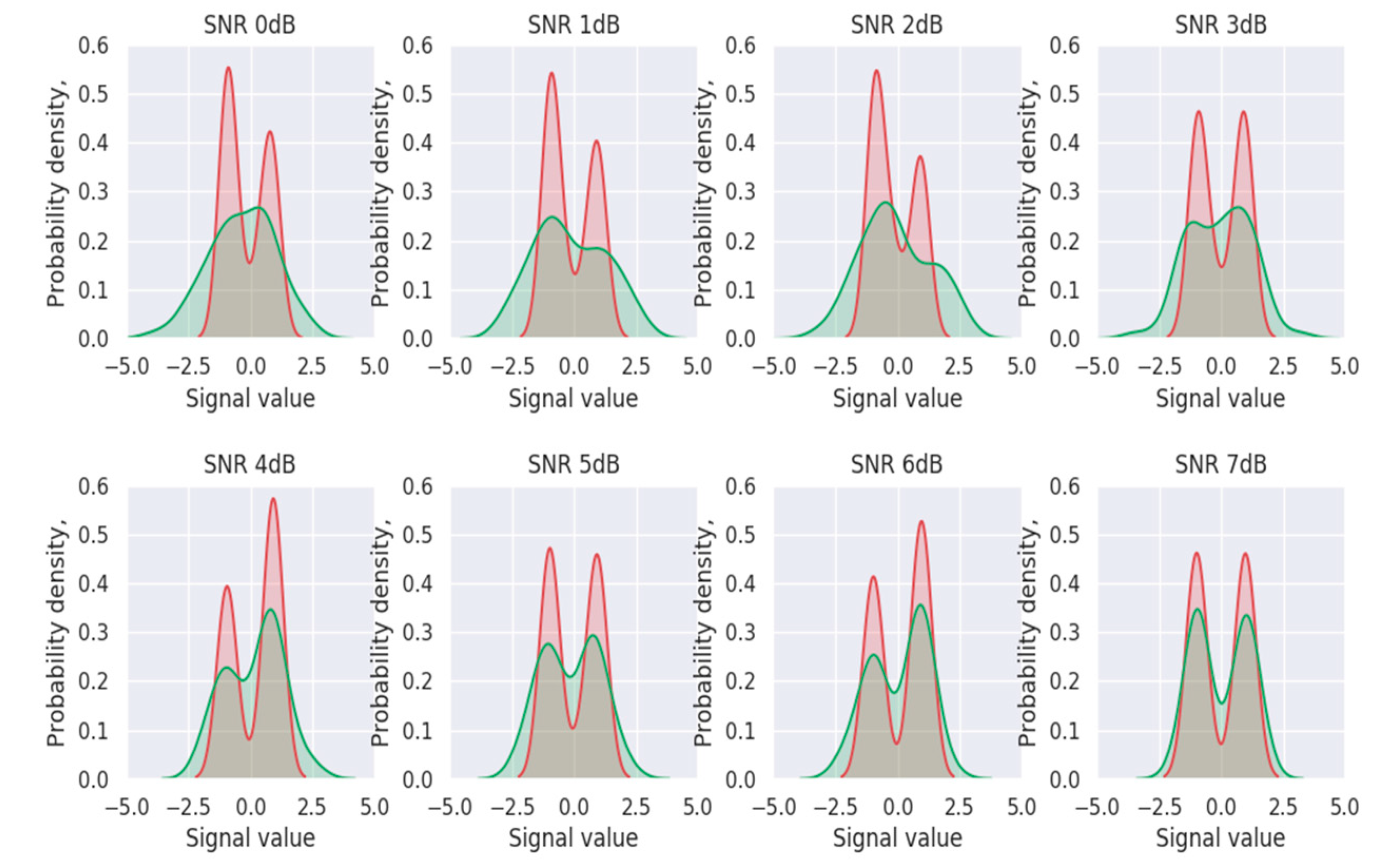
3.2. Attention-Based Denoising Subnetwork
3.3. Attention-Based Decoding Subnetwork
4. Experiments and Results
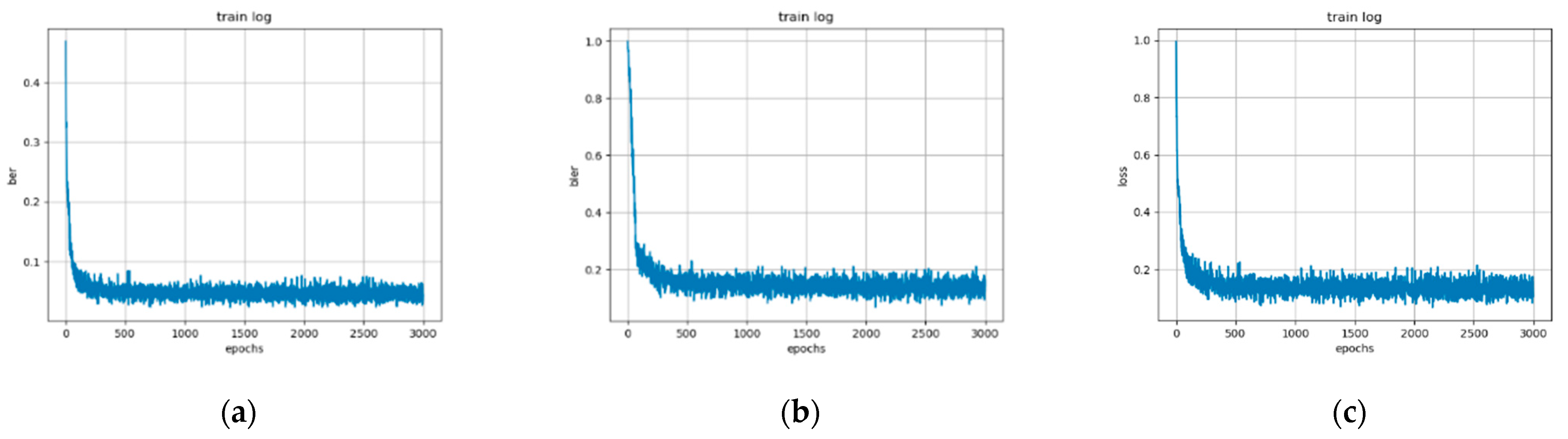
4.1. Experiment Setting and Training Details
4.2. Ablation Experiments
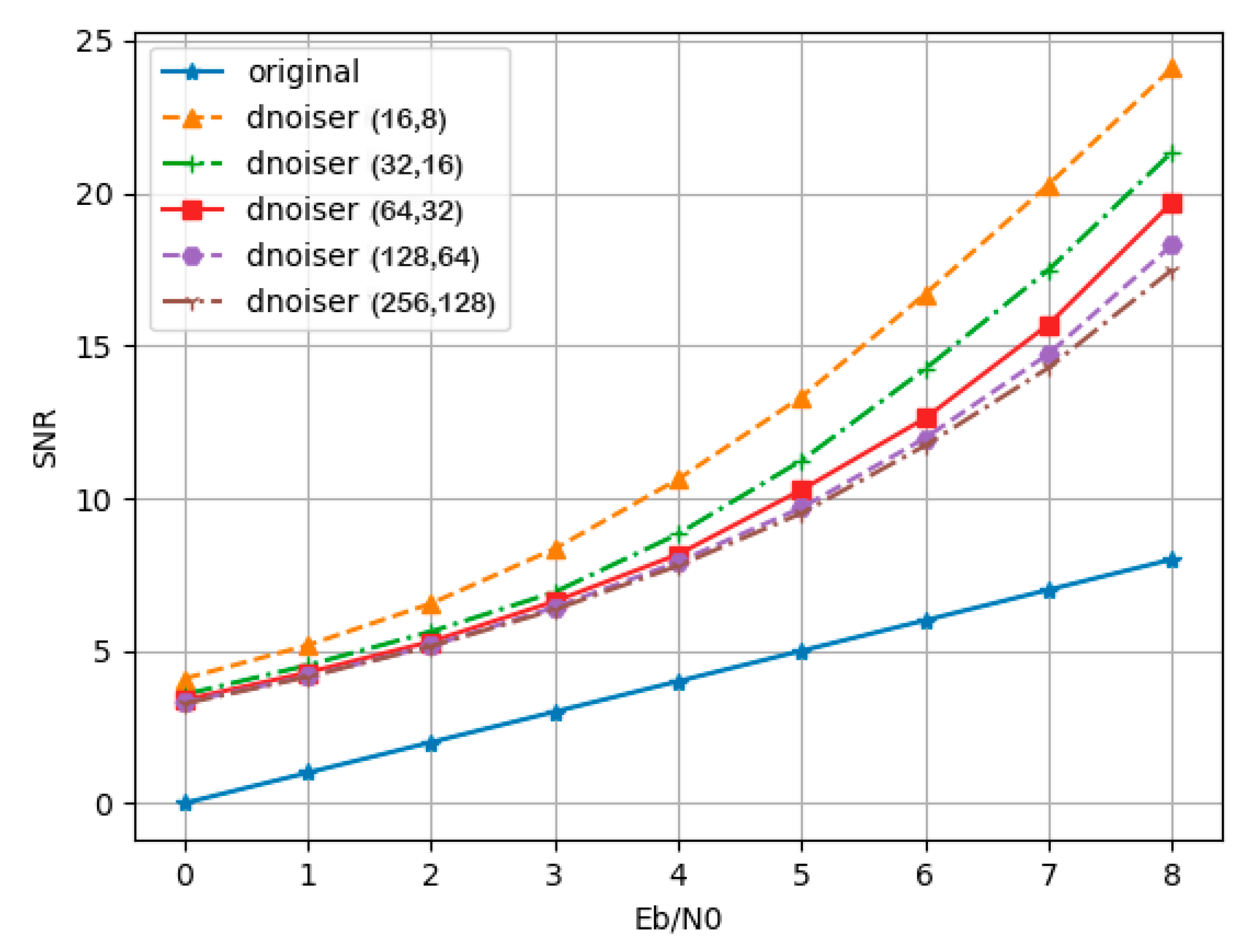
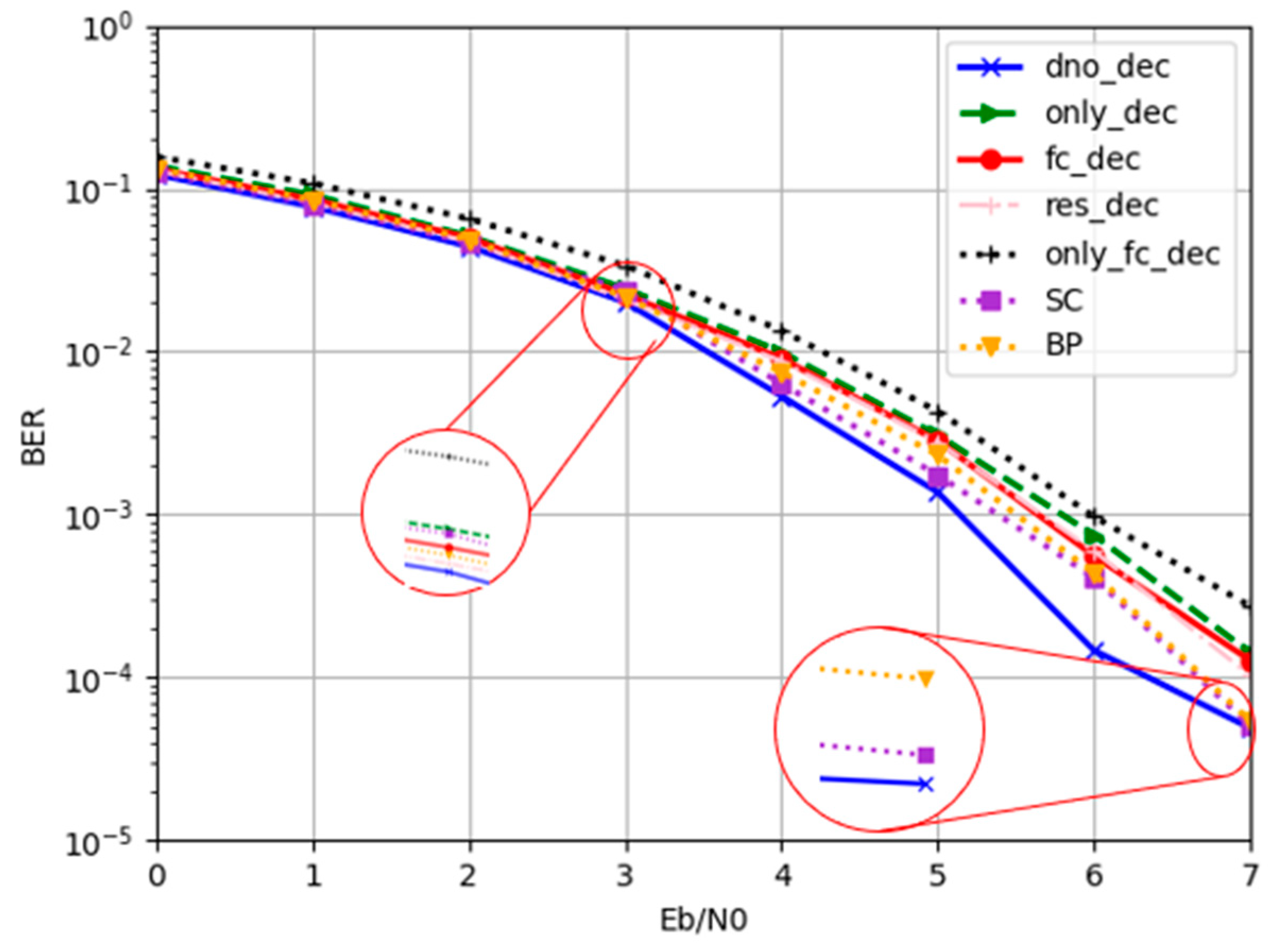
4.2.1. Denoiser Performance
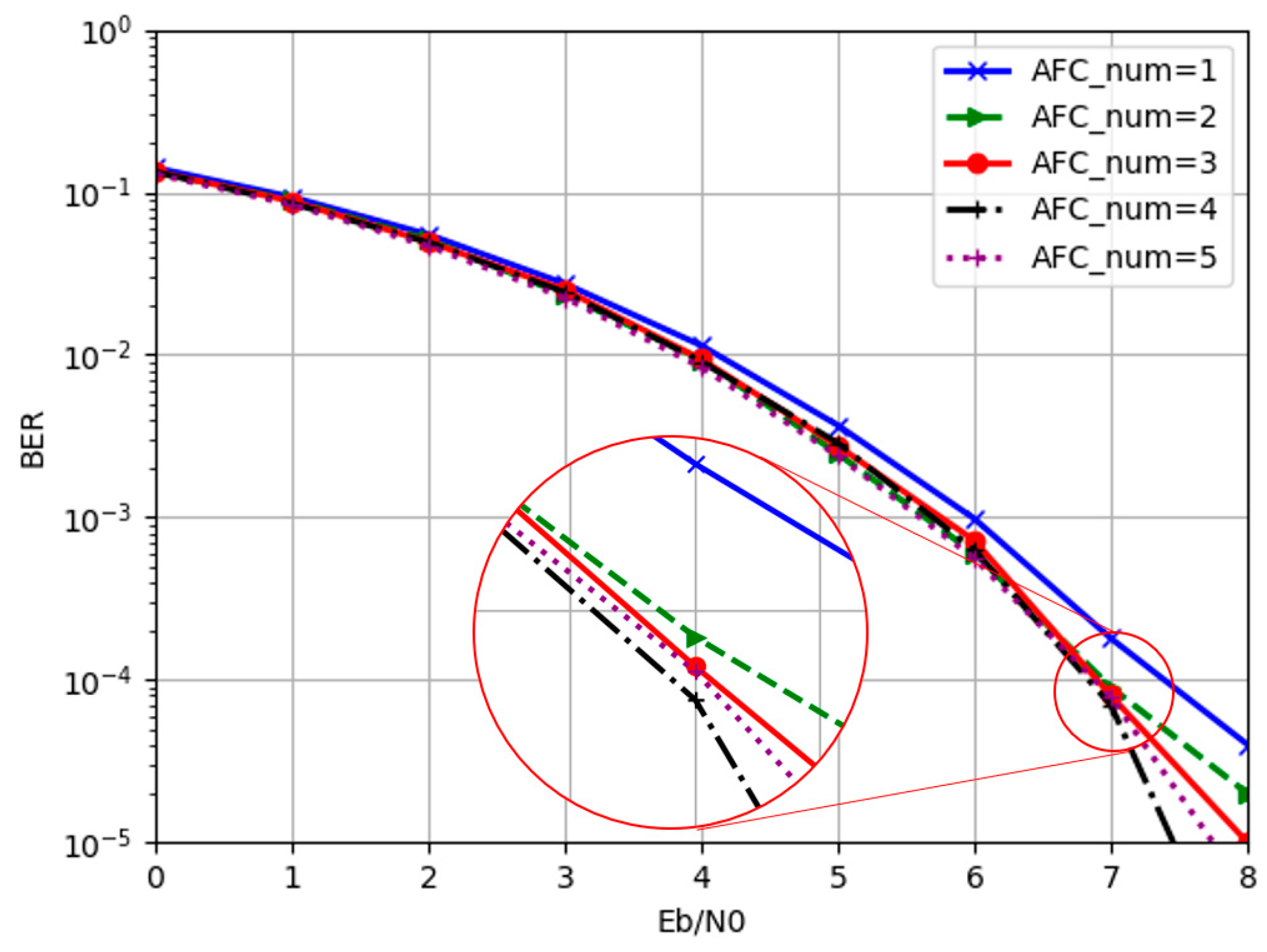
4.2.2. AFC Module Number
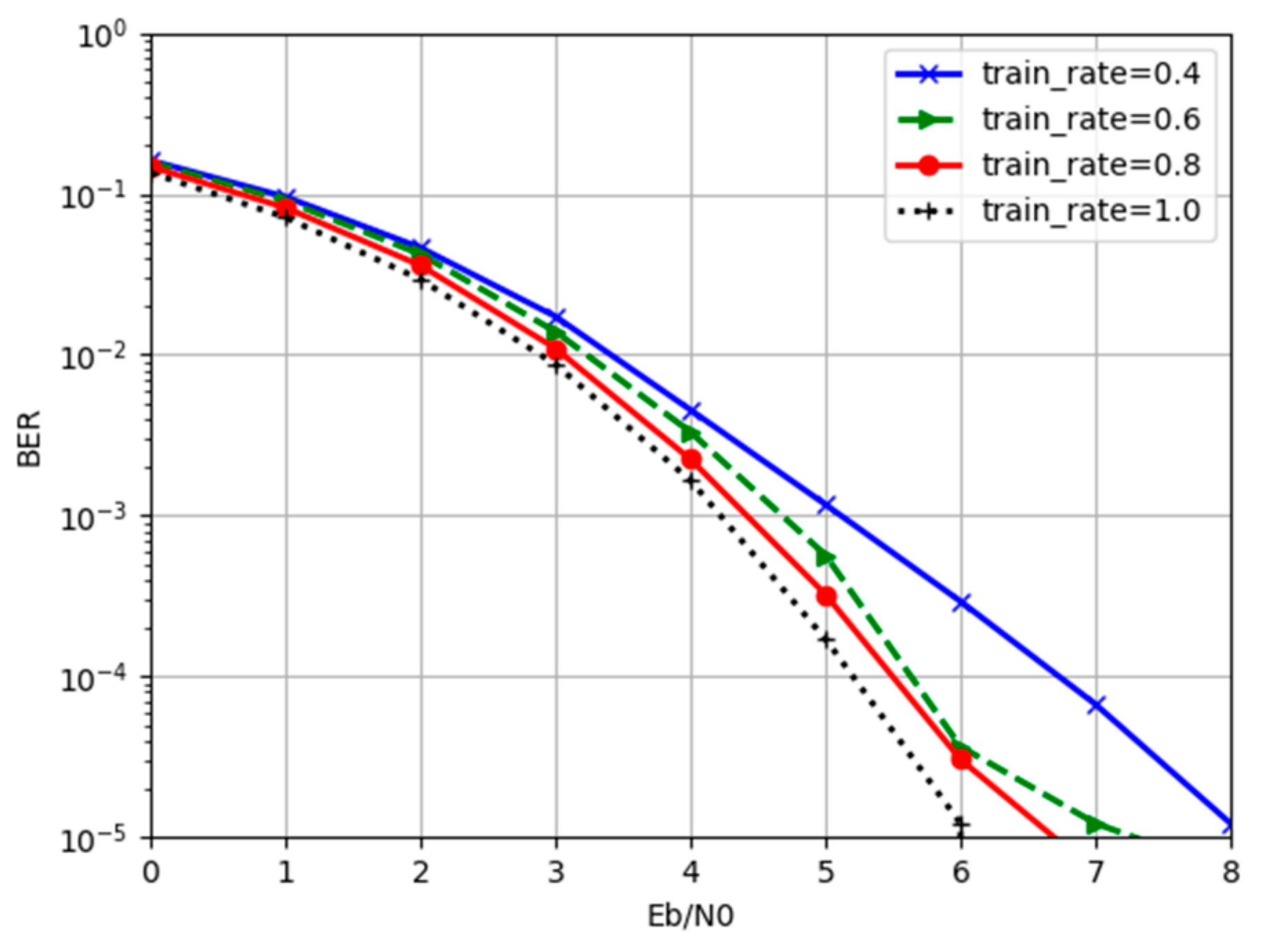
4.2.3. Training Rate
4.3. Comparison with Other Methods
4.3.1. Comparison Based on BER
4.3.2. Comparison Based on Decoding Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arikan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Bioglio, V.; Condo, C.; Land, I. Design of polar codes in 5G new radio. IEEE Commun. Surv. Tutor. 2020, 23, 29–40. [Google Scholar] [CrossRef] [Green Version]
- Jalali, A.; Ding, Z. Joint detection and decoding of polar coded 5G control channels. IEEE Trans. Wirel. Commun. 2020, 19, 2066–2078. [Google Scholar] [CrossRef]
- Xing, C.; Huang, Z.; Zhao, S. Improvement of Fast Simplified Successive-Cancellation Decoder for Polar Codes. Information 2018, 9, 254. [Google Scholar] [CrossRef] [Green Version]
- Mondelli, M.; Hashemi, S.A.; Cioffi, J.M.; Goldsmith, A. Sublinear latency for simplified successive cancellation decoding of polar codes. IEEE Trans. Wirel. Commun. 2020, 20, 18–27. [Google Scholar] [CrossRef]
- Ercan, F.; Tonnellier, T.; Doan, N.; Gross, W.J. Practical dynamic SC-flip polar decoders: Algorithm and implementation. IEEE Trans. Signal Process. 2020, 68, 5441–5456. [Google Scholar] [CrossRef]
- Wang, X.; Ma, Q.; Li, J.; Zhang, H.; Xu, W. An Improved SC Flip Decoding Algorithm of Polar Codes Based on Genetic Algorithm. IEEE Access 2020, 8, 222572–222583. [Google Scholar] [CrossRef]
- Yang, D.; Yang, K. Error-aware SCFlip decoding of polar codes. IEEE Access 2020, 8, 163758–163768. [Google Scholar] [CrossRef]
- Tao, Y.; Cho, S.-G.; Zhang, Z. A configurable successive-cancellation list Polar decoder using split-tree architecture. IEEE J. Solid-State Circuits 2020, 56, 612–623. [Google Scholar] [CrossRef]
- Miloslavskaya, V.; Vucetic, B. Design of short polar codes for SCL decoding. IEEE Trans. Commun. 2020, 68, 6657–6668. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, C.; Song, W.; Xu, S.; You, X. Segmented CRC-aided SC list polar decoding. In Proceedings of the 2016 IEEE 83rd Vehicular Technology Conference (VTC Spring), Nanjing, China, 15–18 May 2016; pp. 1–5. [Google Scholar]
- Xiang, L.; Liu, Y.; Maunder, R.G.; Yang, L.-L.; Hanzo, L. Soft-Output Successive Cancellation Stack Polar Decoder. IEEE Trans. Veh. Technol. 2021, 70, 6238–6243. [Google Scholar] [CrossRef]
- Gao, J.; Niu, K.; Dong, C. Learning to decode polar codes with one-bit quantizer. IEEE Access 2020, 8, 27210–27217. [Google Scholar] [CrossRef]
- Arlı, A.Ç.; Gazi, O. Noise-aided belief propagation list decoding of polar codes. IEEE Commun. Lett. 2019, 23, 1285–1288. [Google Scholar] [CrossRef]
- Doan, N.; Hashemi, S.A.; Gross, W.J. Neural successive cancellation decoding of polar codes. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Fang, J. Improved Polar Decoder Utilizing Neural Network in Fast Simplified Successive-Cancellation Decoding. J. Comput. Commun. 2020, 8, 90. [Google Scholar] [CrossRef]
- Chen, C.-H.; Teng, C.-F.; Wu, A.-Y. Low-complexity LSTM-assisted bit-flipping algorithm for successive cancellation list polar decoder. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1708–1712. [Google Scholar]
- Teng, C.-F.; Wu, A.-Y.A. Convolutional neural network-aided tree-based bit-flipping framework for polar decoder using imitation learning. IEEE Trans. Signal Process. 2020, 69, 300–313. [Google Scholar] [CrossRef]
- Wodiany, I.; Pop, A. Low-precision neural network decoding of polar codes. In Proceedings of the 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, 2–5 July 2019; pp. 1–5. [Google Scholar]
- Qin, Y.; Liu, F. Convolutional neural network-based polar decoding. In Proceedings of the 2019 2nd World Symposium on Communication Engineering (WSCE), Nagoya, Japan, 20–23 December 2019; pp. 189–194. [Google Scholar]
- Xu, W.; Tan, X.; Be’ery, Y.; Ueng, Y.-L.; Huang, Y.; You, X.; Zhang, C. Deep learning-aided belief propagation decoder for polar codes. IEEE J. Emerging Sel. Top. Circuits Syst. 2020, 10, 189–203. [Google Scholar] [CrossRef]
- Gao, J.; Liu, R. Neural network aided SC decoder for polar codes. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018; pp. 2153–2157. [Google Scholar]
- Wang, X.; Zhang, H.; Li, R.; Huang, L.; Dai, S.; Huangfu, Y.; Wang, J. Learning to flip successive cancellation decoding of polar codes with LSTM networks. In Proceedings of the 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 1–8 September 2019; pp. 1–5. [Google Scholar]
- Teng, C.-F.; Wu, C.-H.D.; Ho, A.K.-S.; Wu, A.-Y.A. Low-complexity recurrent neural network-based polar decoder with weight quantization mechanism. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1413–1417. [Google Scholar]
- Wen, C.; Xiong, J.; Gui, L.; Shi, Z.; Wang, Y. A novel decoding scheme for polar code using convolutional neural network. In Proceedings of the 2019 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Jeju, Republic of Korea, 5–7 June 2019; pp. 1–5. [Google Scholar]
- Seo, J.; Lee, J.; Kim, K. Decoding of polar code by using deep feed-forward neural networks. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 238–242. [Google Scholar]
- Irawan, A.; Witjaksono, G.; Wibowo, W.K. Deep learning for polar codes over flat fading channels. In Proceedings of the 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 488–491. [Google Scholar]
- Lyu, W.; Zhang, Z.; Jiao, C.; Qin, K.; Zhang, H. Performance evaluation of channel decoding with deep neural networks. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Zhu, H.; Cao, Z.; Zhao, Y.; Li, D. Learning to denoise and decode: A novel residual neural network decoder for polar codes. IEEE Trans. Veh. Technol. 2020, 69, 8725–8738. [Google Scholar] [CrossRef]
- Cui, J.; Kong, W.; Zhang, X.; Chen, D.; Zeng, Q. DLSTM-Based Successive Cancellation Flipping Decoder for Short Polar Codes. Entropy 2021, 23, 863. [Google Scholar] [CrossRef]
- Gross, W.J.; Doan, N.; Ngomseu Mambou, E.; Ali Hashemi, S. Deep learning techniques for decoding polar codes. Mach. Learn. Future Wirel. Commun. 2020, 2020, 287–301. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layer | Number | |
|---|---|---|---|
| Input | N × 1 | × 1 | |
| ResBlock | Conv + LReLU k3s1 N × 16 Conv k3s1 N × 16 Add + LReLU —— N × 16 | × 4 | |
| Local Attention | GAP + Sigmoid—1 × 16 | Conv + Sigmoid k1s1 N × 1 | |
| Multiply —— N × 16 | |||
| ResBlock | Conv + LReLU k3s1 N × 16 Conv k3s1 N × 16 Add + LReLU —— N × 16 | × 1 | |
| Global Attention | Concat —— N × 64 Conv + LReLU k1s1 N × 16 LReLU —— N × 16 | ||
| GAP + Sigmoid—1 × 16 | Conv + Sigmoid k1s1 N × 1 | ||
| Multiply —— N × 16 | |||
| Output | Conv + Tanh k3s1 N × 1 | × 1 | |
| Block | Layer | Number |
|---|---|---|
| Input | N × 1 | × 1 |
| ConvBlock | Conv + LReLU k3s1 N × 16 | × 1 |
| AFC Module | FC + LReLU 512 × 1 FC + LReLU 256 × 1 FC + Sigmoid 512 × 1 Multiply 512 × 1 | × 1 |
| AFC Module | FC + LReLU 256 × 1 FC + LReLU 128 × 1 FC + Sigmoid 256 × 1 Multiply 256 × 1 | × 1 |
| AFC Module | FC + LReLU 128 × 1 FC + LReLU 64 × 1 FC + LSigmoid 128 × 1 Multiply 128 × 1 | × 1 |
| AFC Module | FC + LReLU 64 × 1 FC + LReLU 32 × 1 FC + Sigmoid 64 × 1 Multiply 64 × 1 | × 1 |
| Output | FC K × 1 | × 1 |
| 16-8 | 32-16 | 64-32 | 128-64 | 256-16 | |
|---|---|---|---|---|---|
| Denoiser | 8.310 × 10−4 | 8.386 × 10−4 | 8.397 × 10−4 | 8.414 × 10−4 | 8.456 × 10−4 |
| Decoder | 3.371 × 10−4 | 3.386 × 10−4 | 3.409 × 10−4 | 3.423 × 10−4 | 3.431 × 10−4 |
| DIR-Net | 1.168 × 10−3 | 1.180 × 10−3 | 1.181 × 10−3 | 1.183 × 10−3 | 1.187 × 10−3 |
| res_dec | 7.089 × 10−4 | 7.115 × 10−4 | 7.120 × 10−4 | 7.145 × 10−4 | 7.469 × 10−4 |
| only_fc_dec | 1.844 × 10−4 | 1.856 × 10−4 | 1.857 × 10−4 | 1.864 × 10−4 | 1.868 × 10−4 |
| FC_Decoder | 1.818 × 10−4 | 1.819 × 10−4 | 1.836 × 10−4 | 1.840 × 10−4 | 1.848 × 10−4 |
| SC | 3.039 × 10−3 | 9.498 × 10−3 | 3.122 × 10−2 | 1.106 × 10−1 | 1.408 × 10−1 |
| BP | 3.727 × 10−2 | 9.214 × 10−2 | 2.189 × 10−1 | 5.047 × 10−1 | 1.1512 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, B.; Feng, Y.; Wang, Y. DIR-Net: Deep Residual Polar Decoding Network Based on Information Refinement. Entropy 2022, 24, 1809. https://doi.org/10.3390/e24121809
Song B, Feng Y, Wang Y. DIR-Net: Deep Residual Polar Decoding Network Based on Information Refinement. Entropy. 2022; 24(12):1809. https://doi.org/10.3390/e24121809
Chicago/Turabian StyleSong, Bixue, Yongxin Feng, and Yang Wang. 2022. "DIR-Net: Deep Residual Polar Decoding Network Based on Information Refinement" Entropy 24, no. 12: 1809. https://doi.org/10.3390/e24121809