
An Empirical Mode Decomposition Fuzzy Forecast Model for Air Quality

Abstract
:1. Introduction
- 1.
- We propose an empirical-mode-decomposition-based fuzzy prediction model for air quality, which can effectively explore the internal rules of air quality data and provide more accurate support for prediction;
- 2.
- The model uses the adaptive network-based fuzzy inference system to fuse the prediction results obtained by the extreme learning machine to obtain the prediction results with high precision and good generalization performance;
- 3.
- We collect and preprocessed a new dataset that contains much information about local pollution control factors.
2. Materials and Methods
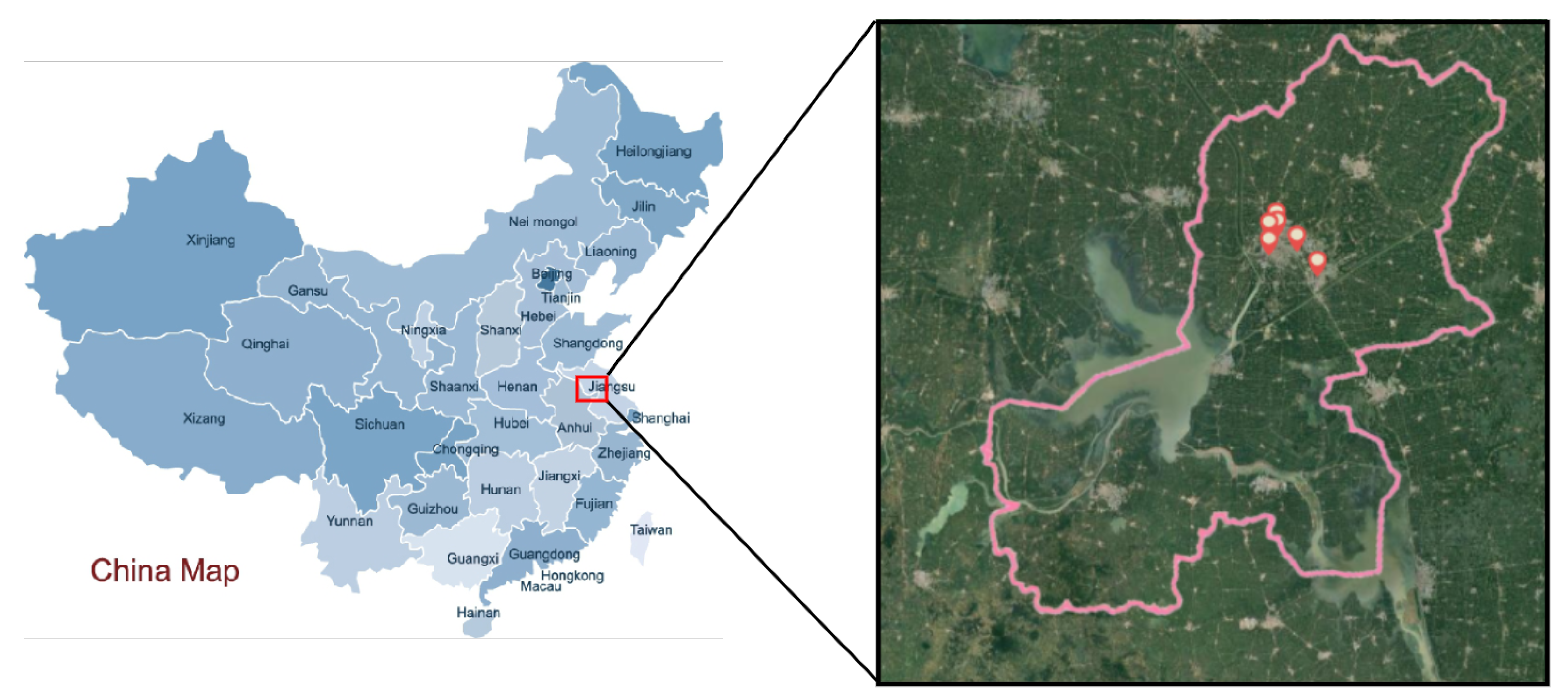
2.1. Data Set
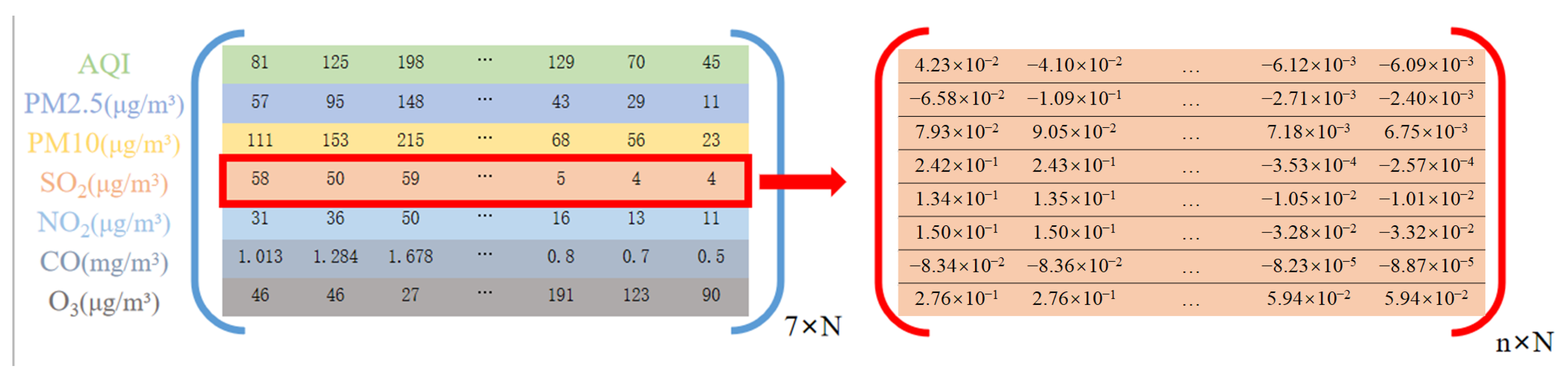
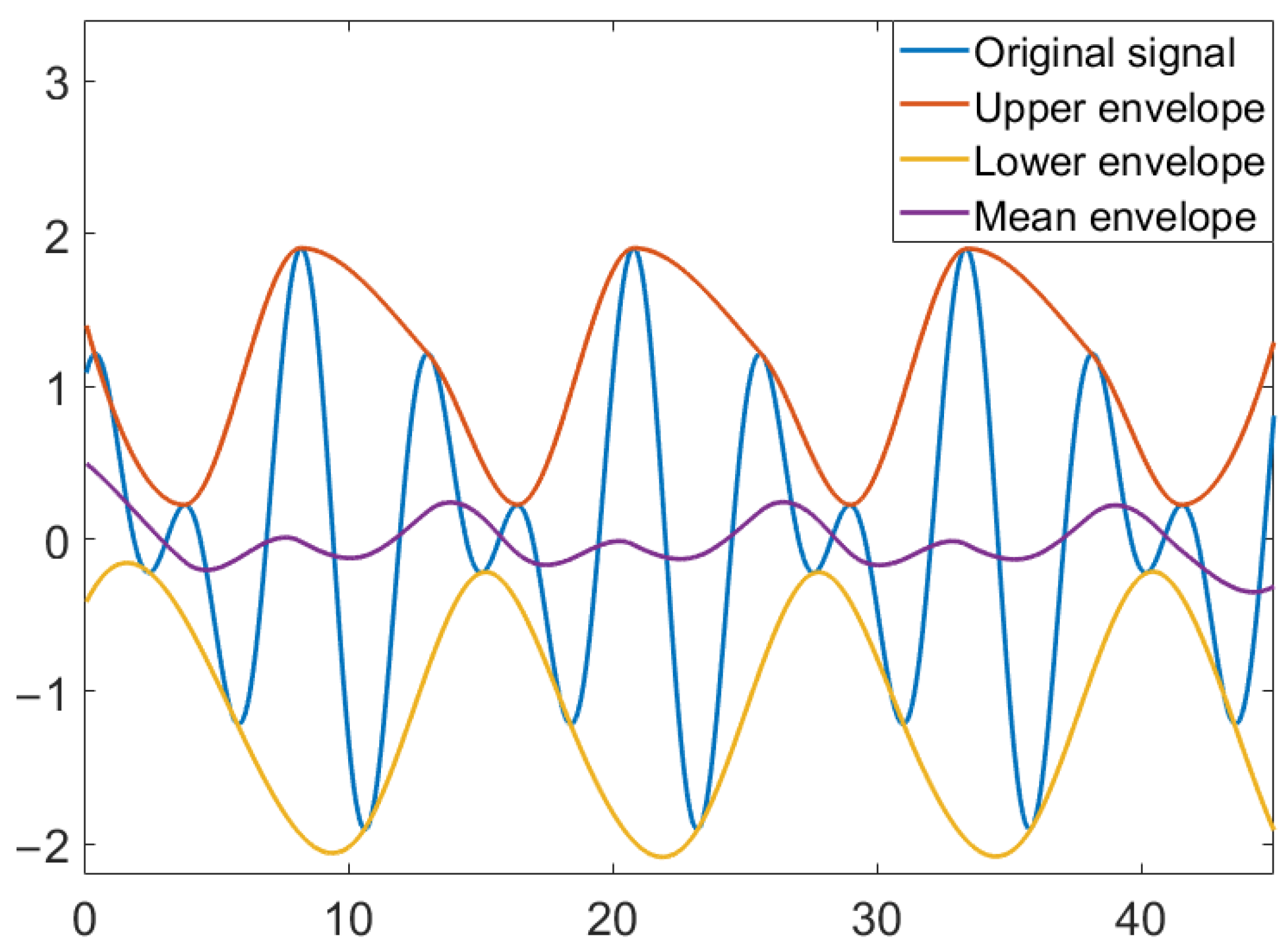
2.2. Empirical Mode Decomposition
2.3. Extreme Learning Machine
2.4. Adaptive Network-Based Fuzzy Inference System
- (1)
- If is and is , then ;
- (2)
- If is and is , then .
2.5. Empirical-Mode-Decomposition-Based Fuzzy Prediction Model
| Algorithm 1: Empirical mode decomposition fuzzy forecast model |
|
2.6. Evaluation Standard
3. Results and Discussions
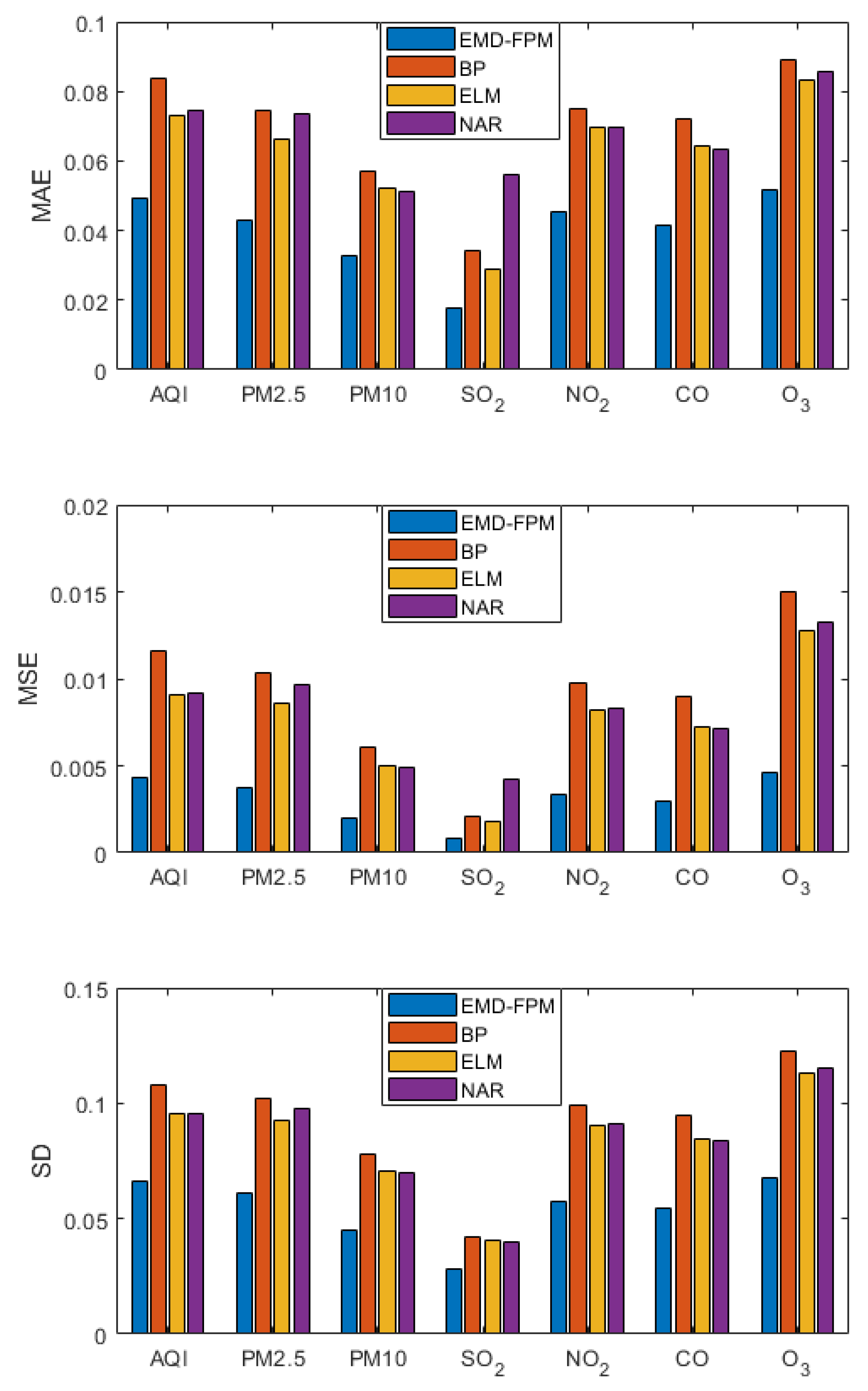
3.1. Contrast Experiment
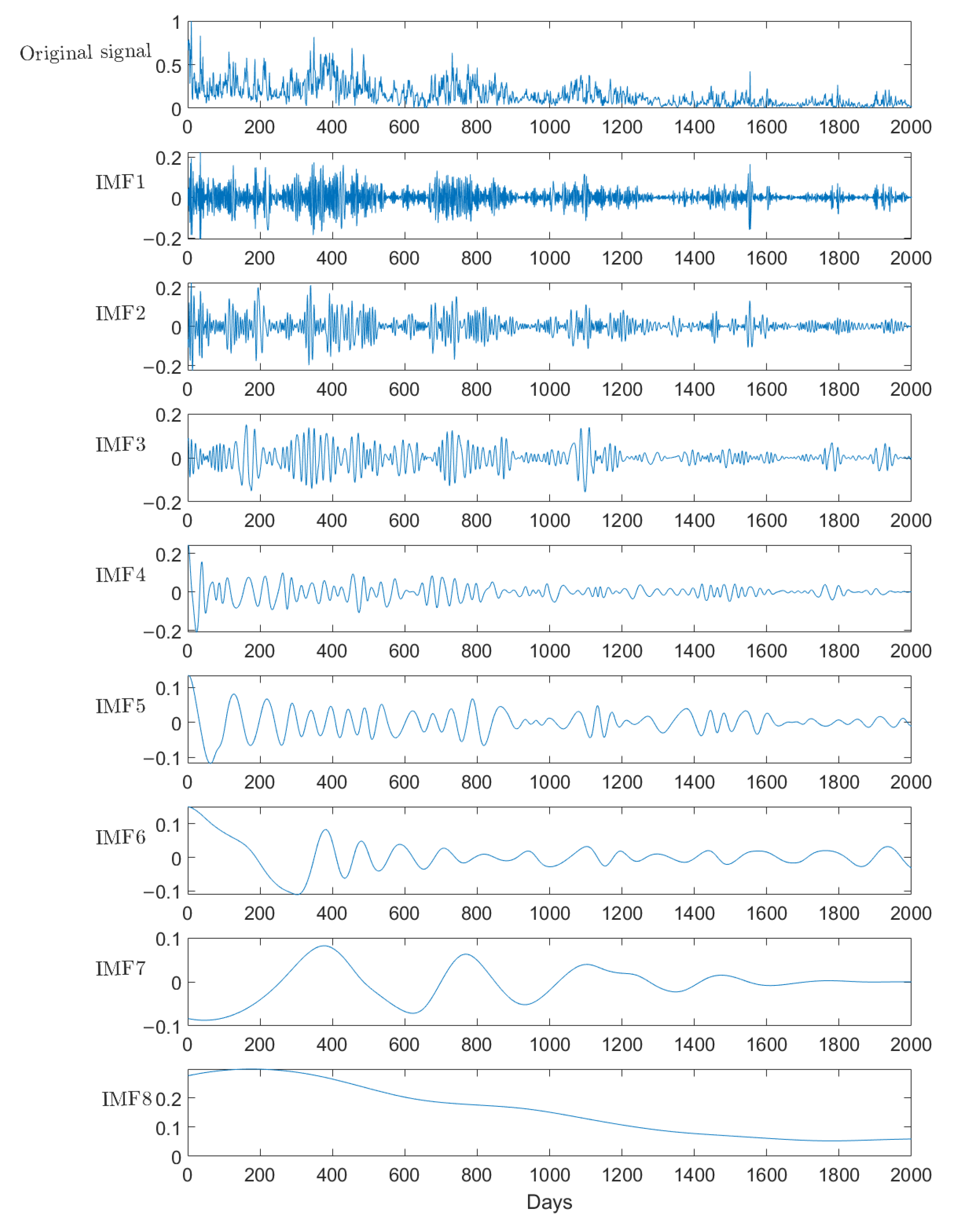
3.2. Decomposition Result
3.3. Short-Term Prediction
3.4. Long-Term Prediction
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AQI | Air Quality Index |
| GM | Grey model |
| ML | Machine learning |
| CV | Cross-validation |
| SVR | Support vector regression |
| LSTM | Long short-term memory |
| BP | Back-propagation |
| CT | Chi-squared test |
| ELM | Extreme learning machine |
| EMD | Empirical mode decomposition |
| IMF | Intrinsic mode function |
| ANFIS | Adaptive network-based fuzzy inference system |
| FPM | Fuzzy prediction model |
| EMD-FPM | Empirical-mode-decomposition-based fuzzy prediction model |
| MSE | Mean-squared error |
| MAE | Mean absolute error |
| SD | Standard deviation |
| NAR | Nonlinear auto-regression |
References
- Chen, Y.; Wang, L.; Li, F.; Du, B.; Choo, K.K.R.; Hassan, H.; Qin, W. Air quality data clustering using EPLS method. Inf. Fusion 2017, 36, 225–232. [Google Scholar] [CrossRef]
- Lee, H.J.; Coull, B.A.; Bell, M.L.; Koutrakis, P. Use of satellite-based aerosol optical depth and spatial clustering to predict ambient PM2.5 concentrations. Environ. Res. 2012, 118, 8–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahajan, S.; Liu, H.M.; Tsai, T.C.; Chen, L.J. Improving the accuracy and efficiency of PM2.5 forecast service using cluster-based hybrid neural network model. IEEE Access 2018, 6, 19193–19204. [Google Scholar] [CrossRef]
- Xiao, Q.; Chang, H.H.; Geng, G.; Liu, Y. An ensemble machine-learning model to predict historical PM2.5 concentrations in China from satellite data. Environ. Sci. Technol. 2018, 52, 13260–13269. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Gao, X.; Xiao, Y.; Liu, S.; Yang, Y. Using grey Holt–Winters model to predict the Air Quality Index for cities in China. Nat. Hazards 2017, 88, 1003–1012. [Google Scholar] [CrossRef]
- Xiong, P.; Yin, Y.; Shi, J.; Gao, H. Nonlinear Multivariable GM (1, N) Model Based on Interval Grey Number Sequence. J. Grey Syst. 2018, 30, 33–47. [Google Scholar]
- Zalakeviciute, R.; Bastidas, M.; Buenaño, A.; Rybarczyk, Y. A Traffic-Based method to predict and map Urban Air Quality. Appl. Sci. 2020, 10, 2035. [Google Scholar] [CrossRef] [Green Version]
- Gu, K.; Qiao, J.; Lin, W. Recurrent air quality predictor based on meteorology-and pollution-related factors. IEEE Trans. Ind. Inform. 2018, 14, 3946–3955. [Google Scholar] [CrossRef]
- Castelli, M.; Clemente, F.M.; Popovič, A.; Silva, S.; Vanneschi, L. A machine learning approach to predict air quality in California. Complexity 2020, 2020, 8049504. [Google Scholar] [CrossRef]
- Lyu, B.; Zhang, Y.; Hu, Y. Improving PM2.5 air quality model forecasts in China using a bias-correction framework. Atmosphere 2017, 8, 147. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yan, S.; Li, J.; Qu, G.; Li, Y.; Lang, J.; Gu, R. A sequence-to-sequence air quality predictor based on the n-step recurrent prediction. IEEE Access 2019, 7, 43331–43345. [Google Scholar] [CrossRef]
- Ma, J.; Xia, D.; Guo, H.; Wang, Y.; Niu, X.; Liu, Z.; Jiang, S. Metaheuristic-based support vector regression for landslide displacement prediction: A comparative study. Landslides 2022, 19, 2489–2511. [Google Scholar] [CrossRef]
- Ma, J.; Xia, D.; Wang, Y.; Niu, X.; Jiang, S.; Liu, Z.; Guo, H. A comprehensive comparison among metaheuristics (MHs) for geohazard modeling using machine learning: Insights from a case study of landslide displacement prediction. Eng. Appl. Artif. Intell. 2022, 114, 105150. [Google Scholar] [CrossRef]
- Ray, R.; Haldar, S.; Biswas, S.; Mukherjee, R.; Banerjee, S.; Chatterjee, S. Prediction of Benzene Concentration of Air in Urban Area Using Deep Neural Network. In Advances in Intelligent Systems and Computing: Proceedings of the International Ethical Hacking Conference, Kolkata, India, 17–25 August 2018; Springer: Singapore, 2019; pp. 465–475. [Google Scholar]
- Qi, Z.; Wang, T.; Song, G.; Hu, W.; Li, X.; Zhang, Z. Deep air learning: Interpolation, prediction, and feature analysis of fine-grained air quality. IEEE Trans. Knowl. Data Eng. 2018, 30, 2285–2297. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Wang, J. A new air quality monitoring and early warning system: Air quality assessment and air pollutant concentration prediction. Environ. Res. 2017, 158, 105–117. [Google Scholar] [CrossRef]
- Cheng, W.; Shen, Y.; Zhu, Y.; Huang, L. A neural attention model for urban air quality inference: Learning the weights of monitoring stations. In Proceedings of the AAAI Conference on Artificial Intelligence, Edmonton, AB, Canada, 13–17 November 2018; Volume 32. [Google Scholar]
- Yi, X.; Zhang, J.; Wang, Z.; Li, T.; Zheng, Y. Deep distributed fusion network for air quality prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 965–973. [Google Scholar]
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef]
- Peng, H.; Lima, A.R.; Teakles, A.; Jin, J.; Cannon, A.J.; Hsieh, W.W. Evaluating hourly air quality forecasting in Canada with nonlinear updatable machine learning methods. Air Qual. Atmos. Health 2017, 10, 195–211. [Google Scholar] [CrossRef]
- Kabir, S.; Islam, R.U.; Hossain, M.S.; Andersson, K. An integrated approach of belief rule base and deep learning to predict air pollution. Sensors 2020, 20, 1956. [Google Scholar] [CrossRef] [Green Version]
- Bai, Y.; Li, Y.; Zeng, B.; Li, C.; Zhang, J. Hourly PM2.5 concentration forecast using stacked autoencoder model with emphasis on seasonality. J. Clean. Prod. 2019, 224, 739–750. [Google Scholar] [CrossRef]
- Pardo, E.; Malpica, N. Air quality forecasting in Madrid using long short-term memory networks. In Lecture Notes in Computer Science: Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation, Corunna, Spain, 19–23 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 232–239. [Google Scholar]
- Athira, V.; Geetha, P.; Vinayakumar, R.; Soman, K. Deepairnet: Applying recurrent networks for air quality prediction. Procedia Comput. Sci. 2018, 132, 1394–1403. [Google Scholar]
- Soh, P.W.; Chang, J.W.; Huang, J.W. Adaptive deep learning-based air quality prediction model using the most relevant spatial-temporal relations. IEEE Access 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Chang, L.C.; Kao, I.F.; Wang, Y.S. Explore a deep learning multi-output neural network for regional multi-step-ahead air quality forecasts. J. Clean. Prod. 2019, 209, 134–145. [Google Scholar] [CrossRef]
- Lin, Y.C.; Lee, S.J.; Ouyang, C.S.; Wu, C.H. Air quality prediction by neuro-fuzzy modeling approach. Appl. Soft Comput. 2020, 86, 105898. [Google Scholar] [CrossRef]
- Yan, R.; Liao, J.; Yang, J.; Sun, W.; Nong, M.; Li, F. Multi-hour and multi-site Air Quality Index forecasting in Beijing using CNN, LSTM, CNN-LSTM, and spatiotemporal clustering. Expert Syst. Appl. 2021, 169, 114513. [Google Scholar] [CrossRef]
- Wang, J.; Song, G. A deep spatial-temporal ensemble model for air quality prediction. Neurocomputing 2018, 314, 198–206. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wang, X.; Wang, J.; Huang, M. Air quality prediction using CT-LSTM. Neural Comput. Appl. 2021, 33, 4779–4792. [Google Scholar] [CrossRef]
- Janarthanan, R.; Partheeban, P.; Somasundaram, K.; Elamparithi, P.N. A deep learning approach for prediction of Air Quality Index in a metropolitan city. Sustain. Cities Soc. 2021, 67, 102720. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Madan, T.; Sagar, S.; Virmani, D. Air quality prediction using machine learning algorithms—A review. In Proceedings of the 2020 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 18–19 December 2020; pp. 140–145. [Google Scholar]
- Zhu, Q.Y.; Siew, C.K. Extreme Learning Machine: A New Learning Scheme of Feed forward Neural Networks. Neurocomputing 2006, 70, 489–501. [Google Scholar]
- Baran, B. Prediction of Air Quality Index by extreme learning machines. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–8. [Google Scholar]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Jin, W.; Li, Z.J.; Wei, L.S.; Zhen, H. The improvements of BP neural network learning algorithm. In Proceedings of the International Conference on Signal Processing, Beijing, China, 26–30 August 2002. [Google Scholar]
- Chow, T.W.S.; Leung, C.T. Neural network based short-term load forecasting using weather compensation. IEEE Trans. Power Syst. 1996, 11, 1736–1742. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AQI | PM | PM | SO | NO | CO | O | |
|---|---|---|---|---|---|---|---|
| MAX | 203 | 153 | 336 | 33 | 67 | 1.8 | 255 |
| MIN | 15 | 5 | 6 | 3 | 6 | 0.3 | 17 |
| AVERAGE | 84.5 | 44.1 | 78.3 | 7.4 | 28.8 | 0.7 | 102.8 |
| MEDIAN | 78.5 | 36 | 69 | 6 | 26 | 0.7 | 98 |
| STANDARD DEVIATION | 36.1 | 29.4 | 44.5 | 3.4 | 13.4 | 0.3 | 46.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Zhu, G.; Shen, Y.; Xie, Q.; Ji, M.; Yu, Y. An Empirical Mode Decomposition Fuzzy Forecast Model for Air Quality. Entropy 2022, 24, 1803. https://doi.org/10.3390/e24121803
Jiang W, Zhu G, Shen Y, Xie Q, Ji M, Yu Y. An Empirical Mode Decomposition Fuzzy Forecast Model for Air Quality. Entropy. 2022; 24(12):1803. https://doi.org/10.3390/e24121803
Chicago/Turabian StyleJiang, Wenxin, Guochang Zhu, Yiyun Shen, Qian Xie, Min Ji, and Yongtao Yu. 2022. "An Empirical Mode Decomposition Fuzzy Forecast Model for Air Quality" Entropy 24, no. 12: 1803. https://doi.org/10.3390/e24121803