

Transformer-Based Model with Dynamic Attention Pyramid Head for Semantic Segmentation of VHR Remote Sensing Imagery


Abstract
:1. Introduction
- 1.
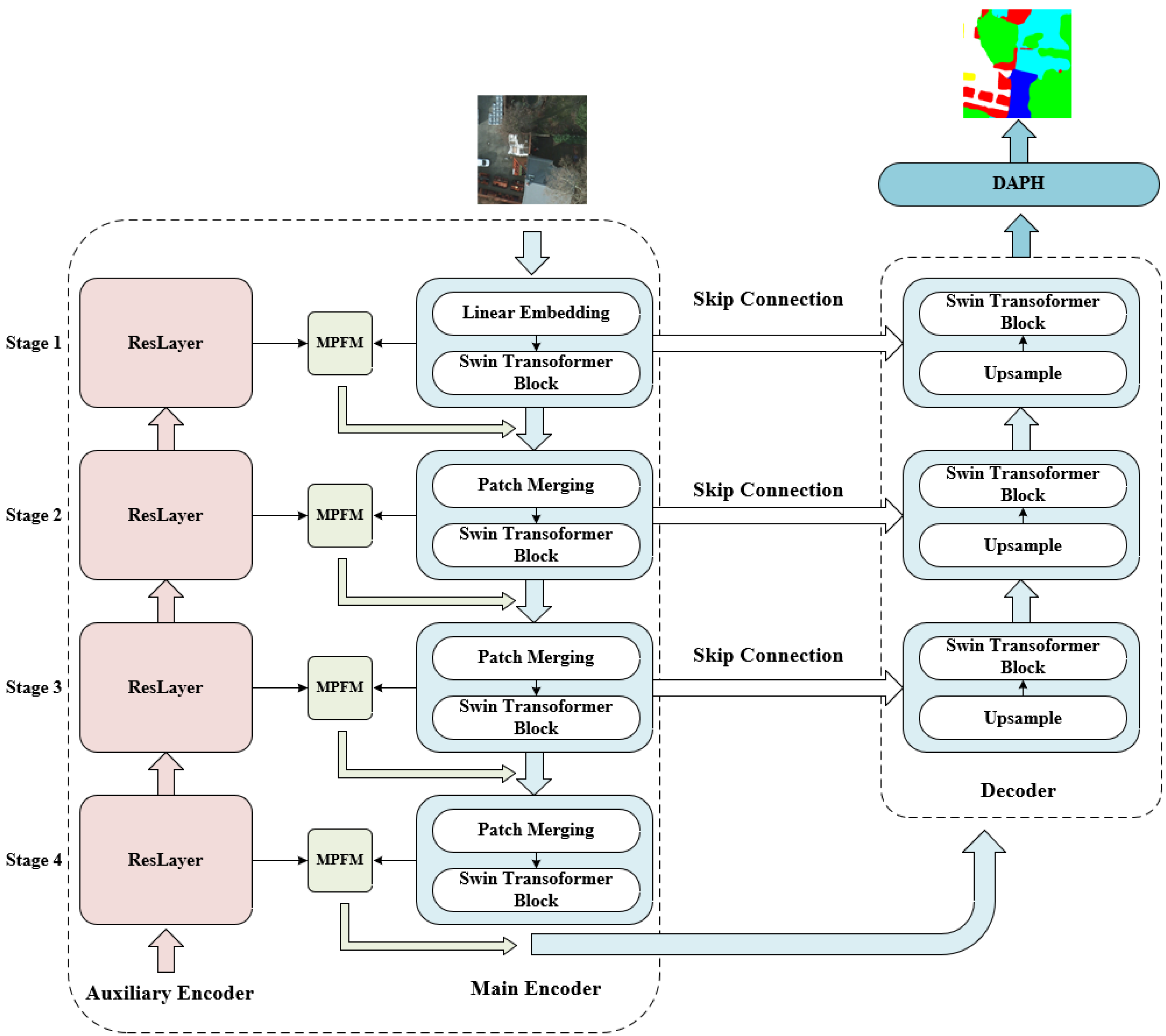
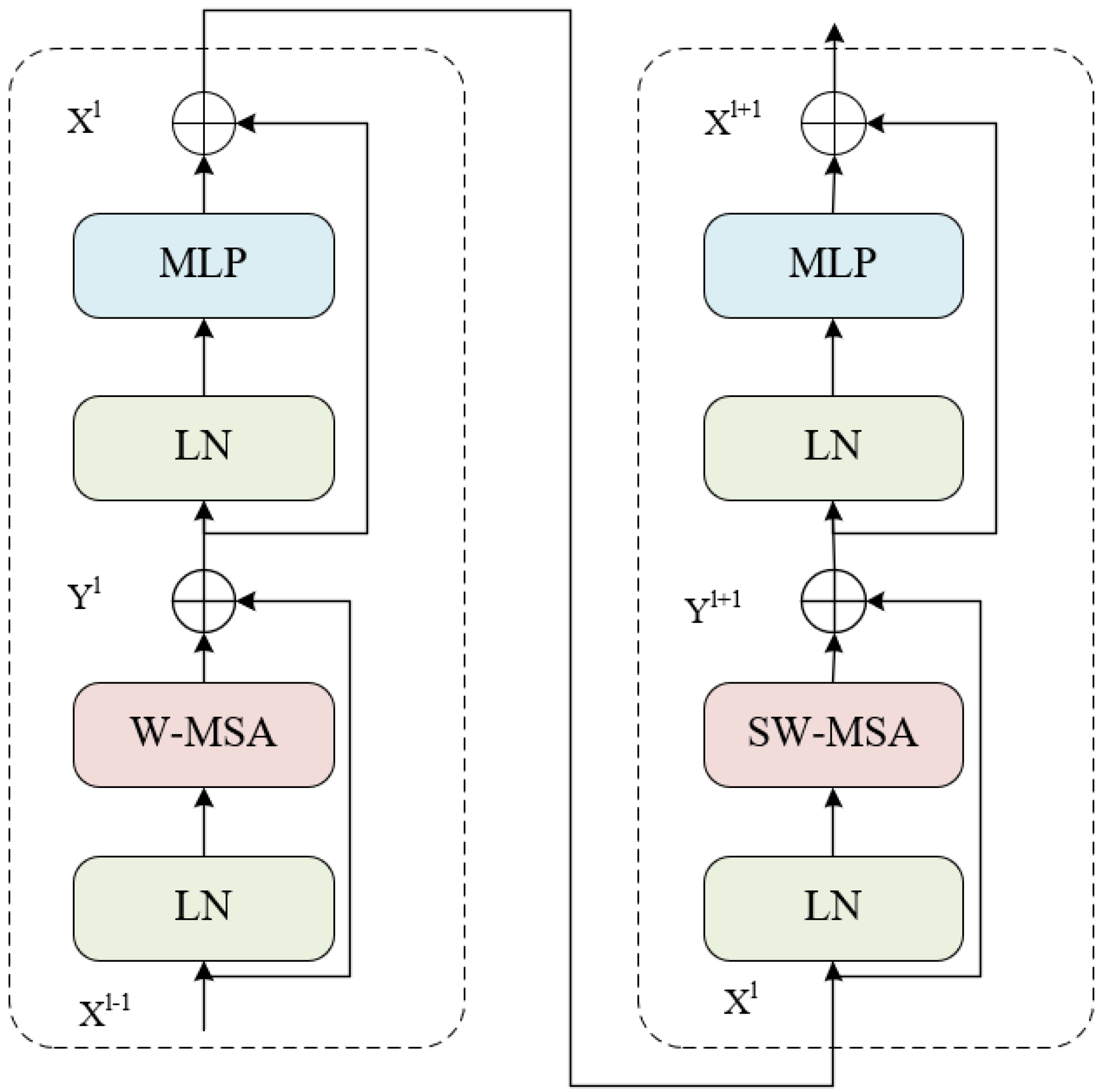
- A new dual framework based on Swin Transformer Block and reslayers was constructed in reverse order. By obtaining coarse-grained resolution and fine-grained resolution simultaneously, SUD-Net is capable of gathering global context and detailed information effectively. Additionally, by adding a decoder composed of Swin Transformer blocks to upsample feature maps extracted by the encoder, SUD-Net can restore sharper edge maps and achieve satisfying segmentation results.
- 2.
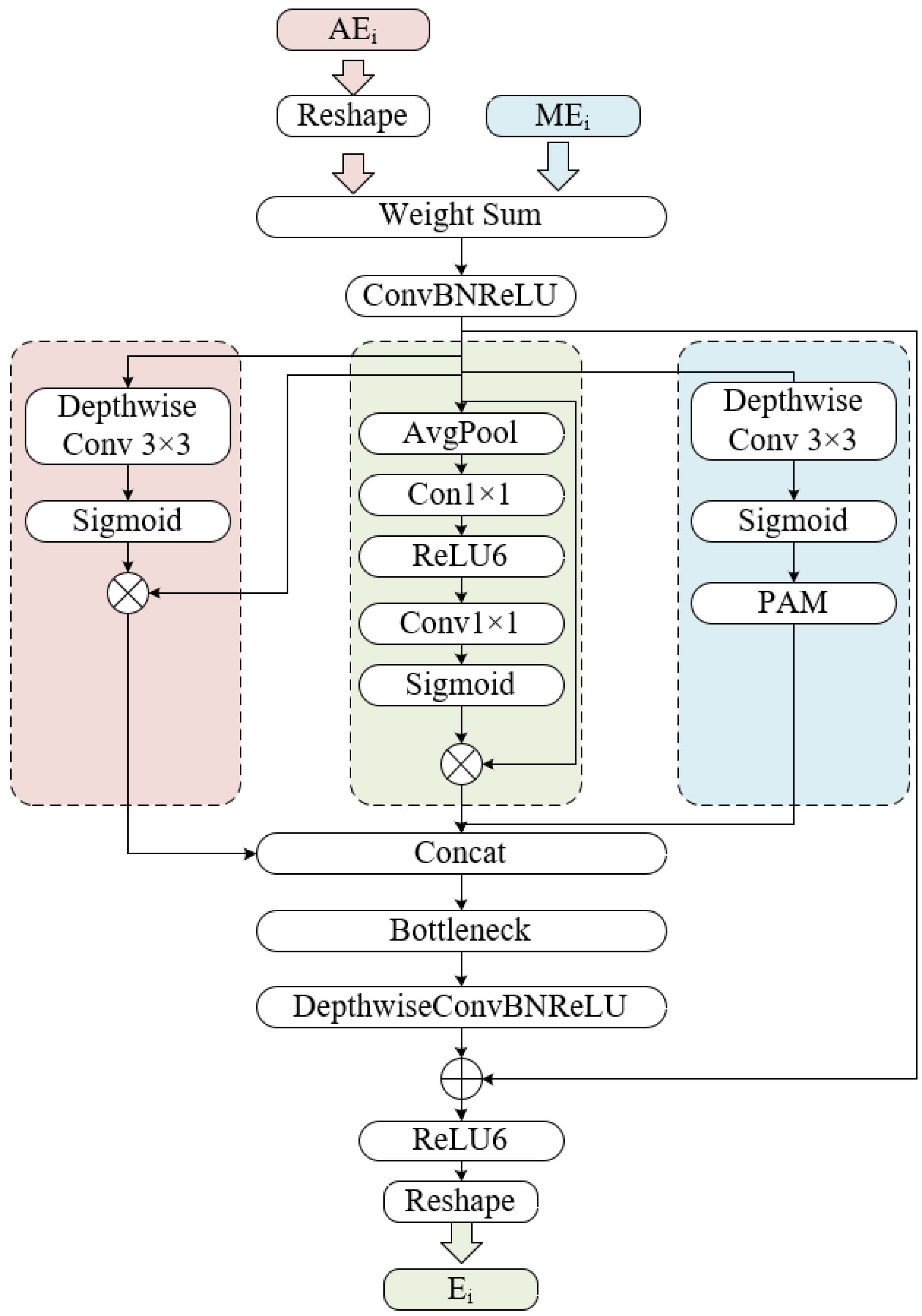
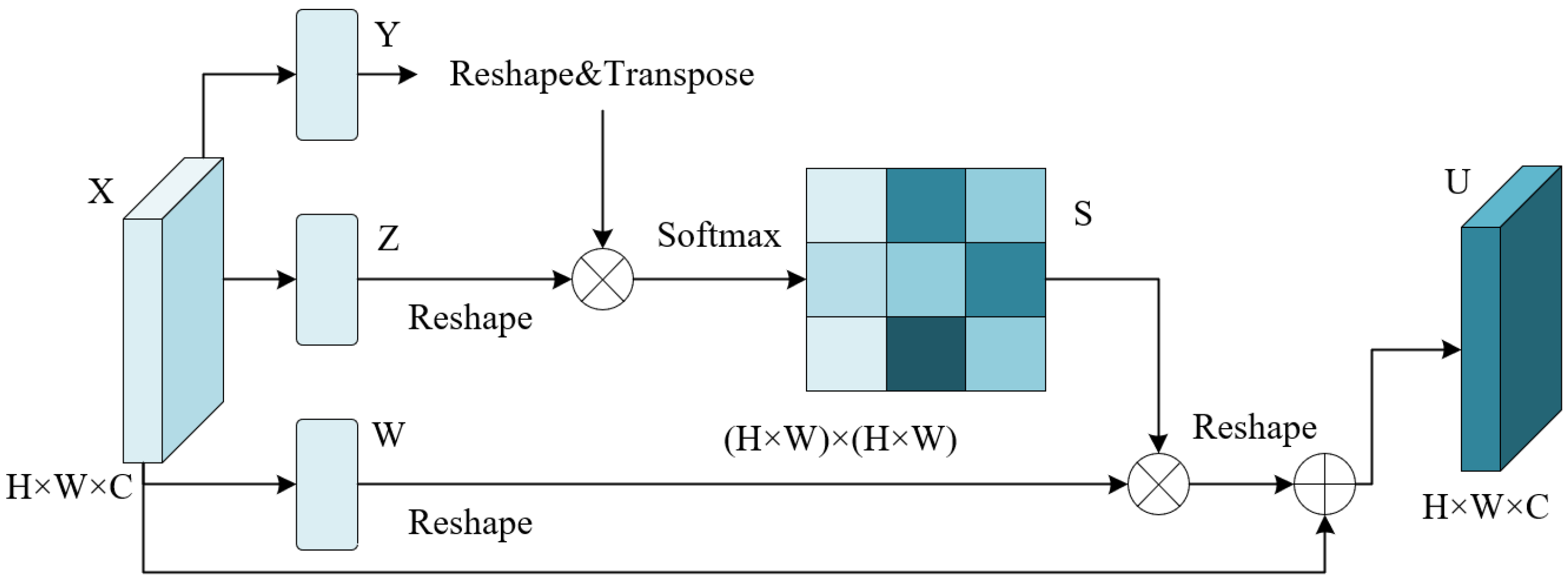
- A Multi-Path Fusion Module is proposed between the reversed reslayers and transformer layers to adaptively fusion features containing different semantics. Patch attention was incoporated into MPFM to retrieve spatial information loss inside each patch and further fuse position information.
- 3.
- A Dynamic Attention Pyramid Head was designed to aggregate contextual and local information effectively and refine feature maps obtained by the backbone, which can further decode necessary high-level representations for segmentation.
- 4.
- SUD-Net achieves state-of-the-art results on the Potsdam dataset and comparatively satisfying results on the Vaihingen dataset of 92.51%mF1, 86.4%mIoU, 92.98%OA, 89.49%mF1, 81.26%mIoU, and 90.95%OA, respectively.
2. Methods
2.1. Architecture
2.2. Multi-Path Fusion Module
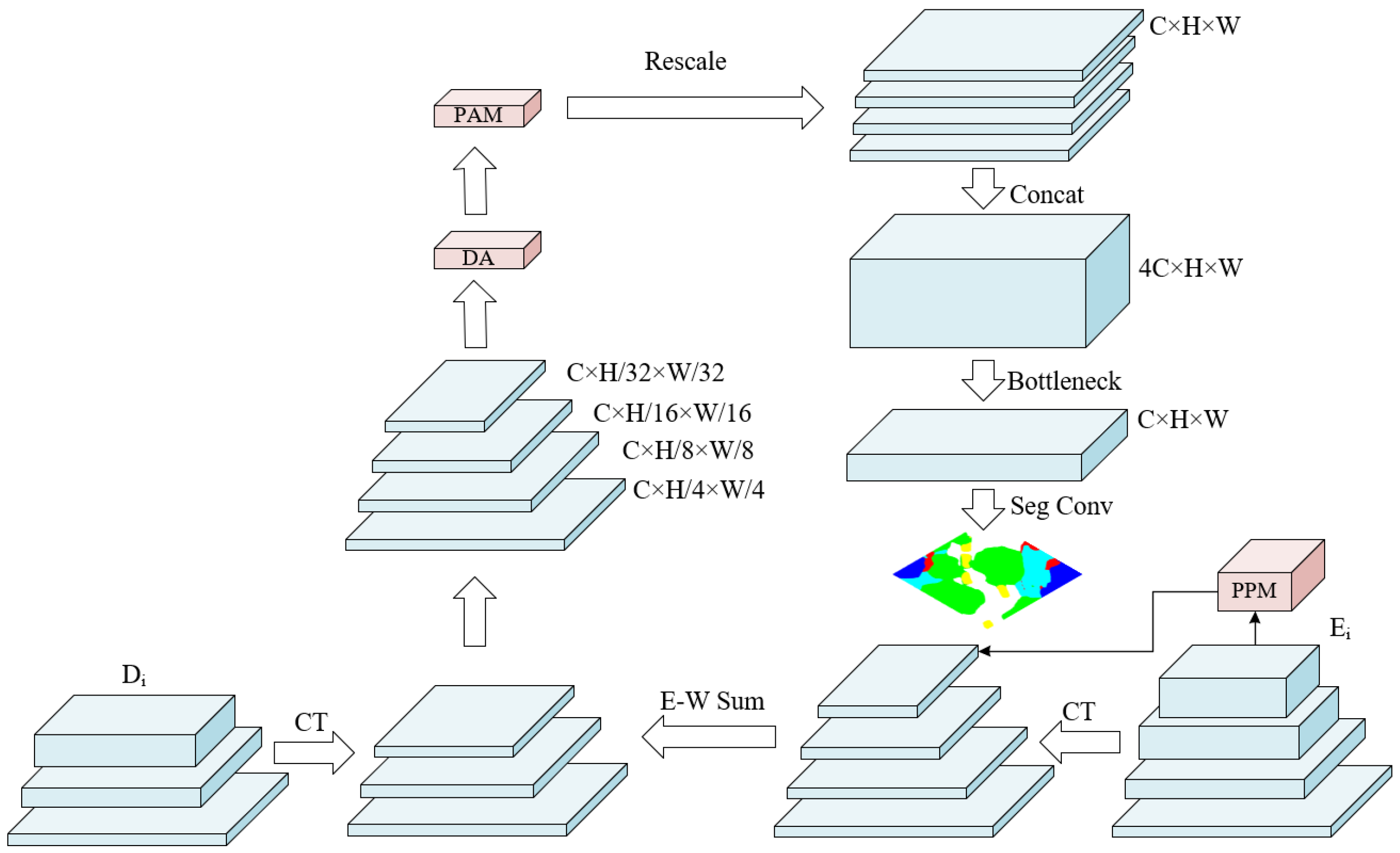
2.3. Dynamic Attention Pyramid Head
3. Experiments and Results
3.1. Experimental Settings
3.1.1. Datasets Description and Preparation
- 1.
- Potsdam DatasetWe employed the Potsdam dataset for the 2D Semantic Labeling Contest, which contains 38 patches of pixels. The true Othophoto (TOP) generated from a TOP mosiac in channel composition of RBG was used for training and testing. The ids of training patches are: 2_10, 2_11, 2_12, 3_10, 3_11, 3_12, 4_10, 4_11, 4_12, 5_10, 5_11, 5_12, 6_7, 6_8, 6_9, 6_10, 6_11, 6_12, 7_7, 7_8, 7_9, 7_10, 7_11, 7_12, and the rest patches are used for testing: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_13, 6_14, 6_15, 7_13. The Potsdam dataset involves six classes of Impervious Surface, Building, Low Vegetation, Tree, Car, and Clutter. Since each patch is too big to be fed into the network considering limited GPU memory, we followed the common principle of dividing patches into smaller images. In our paper, each patch was split into a resolution of with a stride of 256 in our default setting. As a result, we had 3456 images for training and 2016 images for testing, whose sizes were all .
- 2.
- Vaihingen Dataset.We employed the Vaihingen dataset for the 2D Semantic Labeling Contest, which contains 33 high-resolution TOP image tiles of different sizes. Following the same division principle, we split each image into with a stride of 256. There are also six categories, the same as Potsdam. In our experiments, the utilized ids for training were 1, 3, 5, 7, 11, 13, 15, 17, 21, 23, 26, 28, 30, 32, 34, 37, and the rest was for testing.
3.1.2. Implementation Details
3.1.3. Evaluation Metrics
3.2. Results
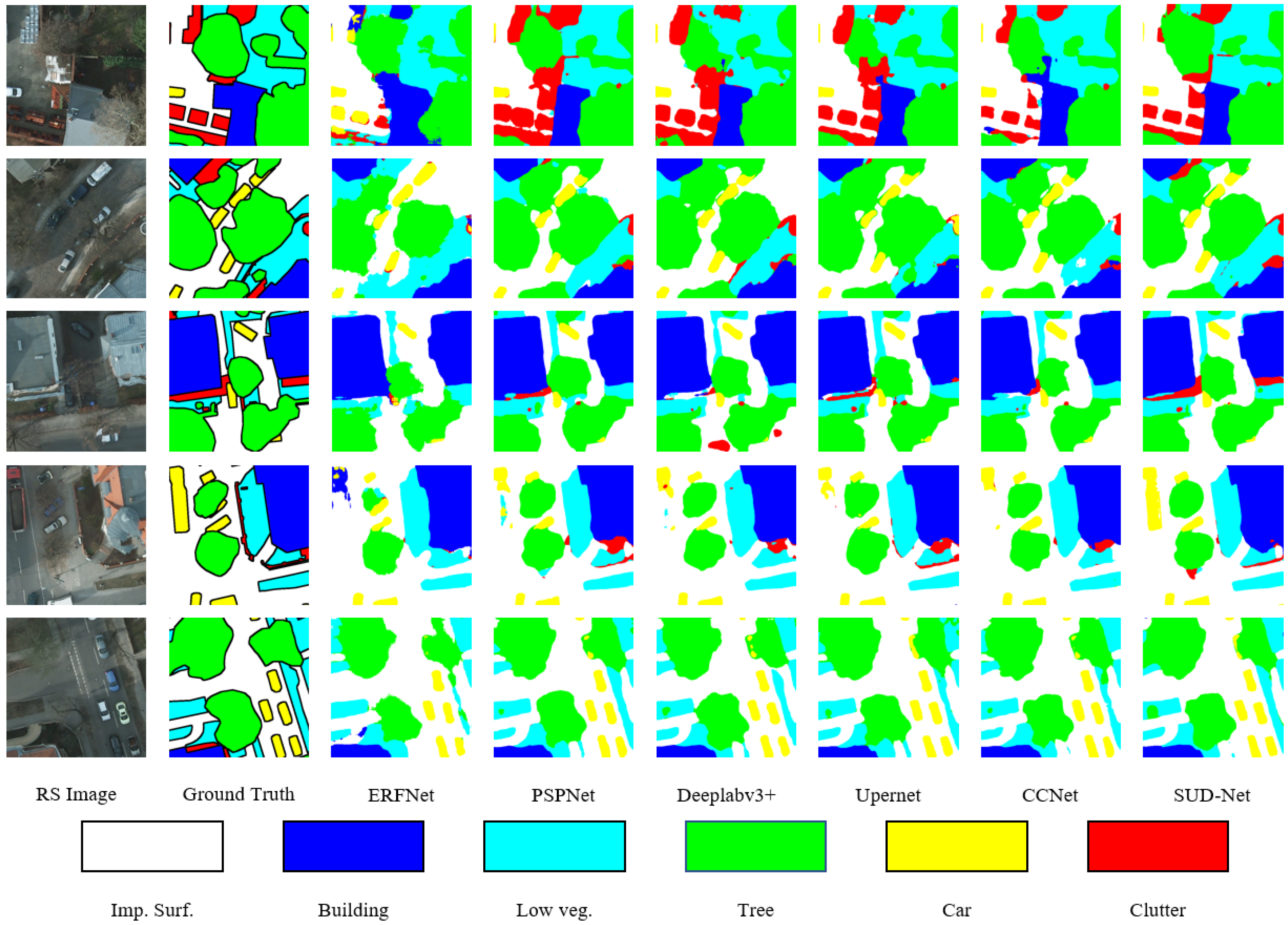
3.2.1. Comparison of SUD-Net and Other Networks
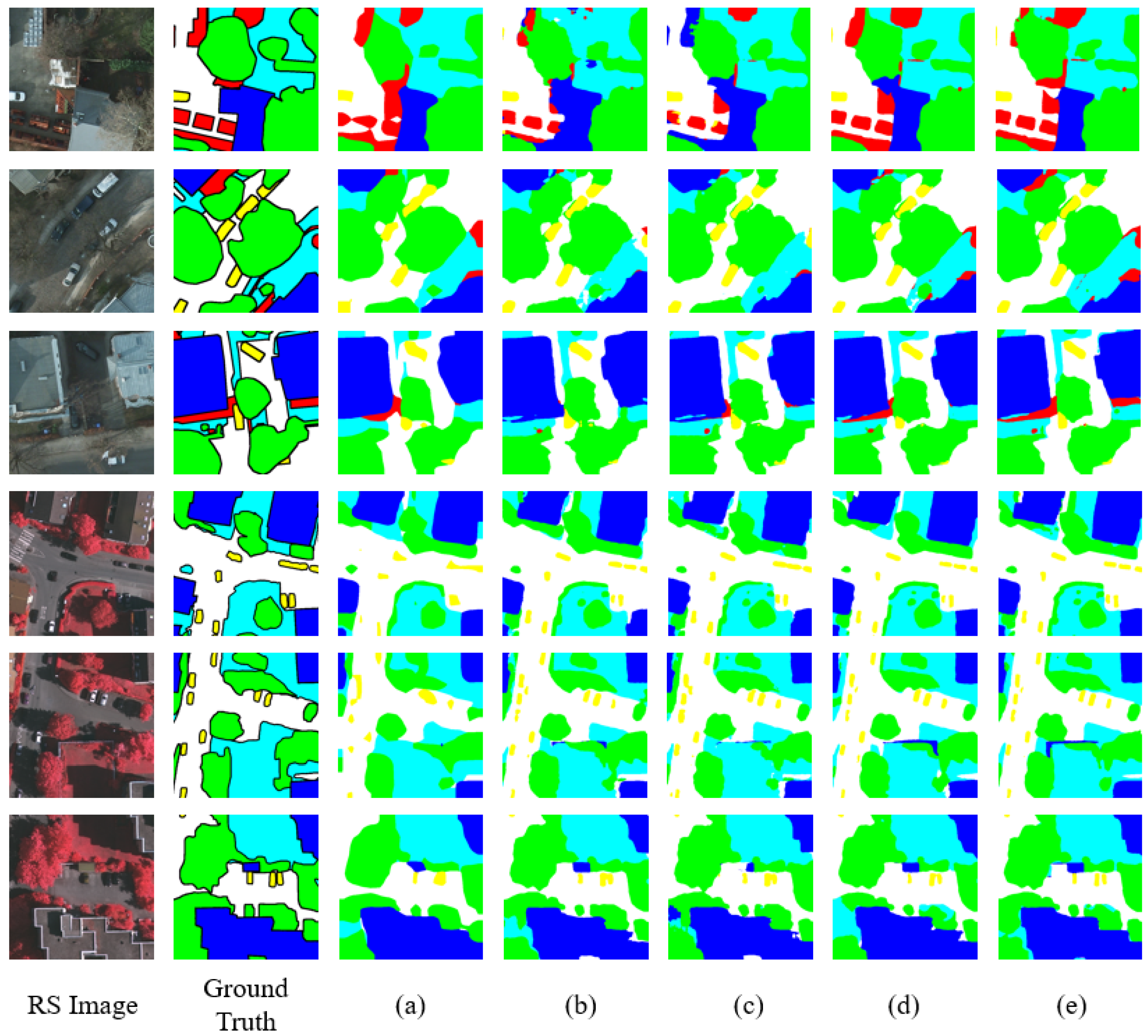
3.2.2. Ablation Studies
- Swin-Unet-T: = 768, 384, 192, 96, = 2, 2, 2, 2, 2, 2, 2, = 3, 6, 12, 24, 24, 12, 6
- Swin-Unet-S: = 768, 384, 192, 96, = 2, 2, 18, 2, 2, 4, 2, = 3, 6, 12, 24, 24, 12, 6
- Swin-Unet-B: = 1024, 512, 256, 128, = 2, 2, 18, 2, 2, 4, 2, = 4, 8, 16, 32, 32, 16, 8
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, H.; Chen, C.; Fang, L.; Khoshelham, K.; Shen, G. MS-RRFSegNet: Multiscale regional relation feature segmentation network for semantic segmentation of urban scene point clouds. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8301–8315. [Google Scholar] [CrossRef]
- Sheikh, R.; Milioto, A.; Lottes, P.; Stachniss, C.; Bennewitz, M.; Schultz, T. Gradient and log-based active learning for semantic segmentation of crop and weed for agricultural robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1350–1356. [Google Scholar]
- Samie, A.; Abbas, A.; Azeem, M.M.; Hamid, S.; Iqbal, M.A.; Hasan, S.S.; Deng, X. Examining the impacts of future land use/land cover changes on climate in Punjab province, Pakistan: Implications for environmental sustainability and economic growth. Environ. Sci. Pollut. Res. 2020, 27, 25415–25433. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, T.; Rahnemoonfar, M. Attention based semantic segmentation on uav dataset for natural disaster damage assessment. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium(IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 2325–2328. [Google Scholar]
- Mu, F.; Li, J.; Shen, N.; Huang, S.; Pan, Y.; Xu, T. Pixel-Adaptive Field-of-View for Remote Sensing Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Gao, H.; Cao, L.; Yu, D.; Xiong, X.; Cao, M. Semantic segmentation of marine remote sensing based on a cross direction attention mechanism. IEEE Access 2020, 8, 142483–142494. [Google Scholar] [CrossRef]
- Moghalles, K.; Li, H.C.; Alazeb, A. Weakly Supervised Building Semantic Segmentation Based on Spot-Seeds and Refinement Process. Entropy 2022, 24, 741. [Google Scholar] [CrossRef] [PubMed]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Yan, L.; Fan, B.; Liu, H.; Huo, C.; Xiang, S.; Pan, C. Triplet adversarial domain adaptation for pixel-level classification of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3558–3573. [Google Scholar] [CrossRef]
- Cai, Y.; Yang, Y.; Shang, Y.; Chen, Z.; Shen, Z.; Yin, J. IterDANet: Iterative Intra-Domain Adaptation for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Müller, A.C.; Behnke, S. Learning depth-sensitive conditional random fields for semantic segmentation of RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6232–6237. [Google Scholar]
- Ravì, D.; Bober, M.; Farinella, G.M.; Guarnera, M.; Battiato, S. Semantic segmentation of images exploiting DCT based features and random forest. Pattern Recognit. 2016, 52, 260–273. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhang, X.; Yang, Y.; Li, Z.; Ning, X.; Qin, Y.; Cai, W. An Improved Encoder-Decoder Network Based on Strip Pool Method Applied to Segmentation of Farmland Vacancy Field. Entropy 2021, 23, 435. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2021, 11, 9. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 10012–10022. [Google Scholar]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-Resolution Transformer Network for Building and Road Segmentation of Remote Sensing Image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Yao, J.; Jin, S. Multi-Category Segmentation of Sentinel-2 Images Based on the Swin UNet Method. Remote Sens. 2022, 14, 3382. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Object detectors emerge in deep scene cnns. arXiv 2014, arXiv:1412.6856. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 7373–7382. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing semantics through points for aerial image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 4217–4226. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–27 November 2019; pp. 603–612. [Google Scholar]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Imp. surf. | Building | Low veg. | Tree | Car | mF1(%) | mIOU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|
| ERFNet [47] | 88.38 | 92.38 | 80.02 | 78.34 | 87.62 | 85.35 | 74.82 | 87.08 |
| PSPNet [15] | 91.99 | 95.49 | 84.26 | 87.79 | 95.24 | 90.95 | 83.69 | 91.34 |
| Deeplabv3+ [16] | 91.21 | 95.43 | 85.46 | 87.47 | 94.47 | 90.81 | 83.39 | 90.86 |
| Upernet [20] | 92.27 | 95.89 | 86.17 | 87.48 | 94.88 | 91.34 | 84.29 | 91.63 |
| CCNet [48] | 92.15 | 96.02 | 85.39 | 88.4 | 95.64 | 91.52 | 84.63 | 91.97 |
| STransFuse [49] | 89.75 | 93.92 | 82.91 | 83.61 | 88.51 | 82.08 | 71.46 | 86.71 |
| STUNet [30] | 79.19 | 86.63 | 67.89 | 66.37 | 79.77 | 86.13 | 75.97 | - |
| SUD-Net(Ours) | 93.61 | 96.98 | 87.63 | 88.7 | 95.95 | 92.57 | 86.4 | 92.98 |
| Model | FCN-Head | Swin-Res34-Unet | MPFM | DAPH | Imp. surf. | Building | Low veg. | Tree | Car | mF1(%) | mIOU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | √ | 92.31 | 96.42 | 86.68 | 88.23 | 87.43 | 90.21 | 82.38 | 92.07 | |||
| (b) | √ | √ | 92.65 | 95.72 | 86.73 | 87.78 | 93.81 | 91.34 | 84.25 | 92.25 | ||
| (c) | √ | √ | √ | 92.99 | 96.04 | 86.74 | 88.13 | 94.63 | 91.7 | 84.88 | 92.39 | |
| (d) | √ | √ | 93.38 | 96.67 | 87.52 | 88.75 | 95.37 | 92.87 | 85.97 | 92.87 | ||
| (e) | √ | √ | √ | 93.61 | 96.98 | 87.63 | 88.7 | 95.95 | 92.57 | 86.4 | 92.98 |
| Model | FCN-Head | Swin-Res34-Unet | MPFM | DAPH | Imp. surf. | Building | Low veg. | Tree | Car | mF1(%) | mIOU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | √ | 90.7 | 94.99 | 82.28 | 88.41 | 67.18 | 84.71 | 74.63 | 89.56 | |||
| (b) | √ | √ | 91.99 | 95.27 | 81.63 | 88.32 | 84.77 | 88.4 | 79.55 | 90.06 | ||
| (c) | √ | √ | √ | 92.14 | 95.25 | 82.98 | 88.78 | 84.18 | 88.67 | 79.95 | 90.42 | |
| (d) | √ | √ | 92.29 | 95.55 | 83.21 | 89.09 | 86.35 | 89.3 | 80.94 | 90.73 | ||
| (e) | √ | √ | √ | 92.89 | 95.73 | 83.51 | 88.96 | 86.36 | 89.49 | 81.26 | 90.95 |
| Skip Connections | mF1(%) | mIOU(%) | OA(%) |
|---|---|---|---|
| PA | 91.11 | 84.07 | 92.09 |
| MC | 91.34 | 84.25 | 92.25 |
| Image Size | mF1(%) | mIOU(%) | OA(%) | GFLOPs |
|---|---|---|---|---|
| 87.94 | 78.65 | 88.9 | 9.55 | |
| 90.33 | 82.55 | 91.22 | 37.08 | |
| 91.34 | 84.25 | 92.25 | 143.68 |
| Swin Variants | mF1(%) | mIOU(%) | OA(%) | Params(M) |
|---|---|---|---|---|
| Swin-Unet-T | 91.34 | 84.25 | 92.25 | 74.68 |
| Swin-Unet-S | 92.55 | 86.35 | 93.16 | 106.66 |
| Swin-Unet-B | 92.57 | 86.38 | 93.09 | 165.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Zhou, S.; Huang, Y. Transformer-Based Model with Dynamic Attention Pyramid Head for Semantic Segmentation of VHR Remote Sensing Imagery. Entropy 2022, 24, 1619. https://doi.org/10.3390/e24111619
Xu Y, Zhou S, Huang Y. Transformer-Based Model with Dynamic Attention Pyramid Head for Semantic Segmentation of VHR Remote Sensing Imagery. Entropy. 2022; 24(11):1619. https://doi.org/10.3390/e24111619
Chicago/Turabian StyleXu, Yufen, Shangbo Zhou, and Yuhui Huang. 2022. "Transformer-Based Model with Dynamic Attention Pyramid Head for Semantic Segmentation of VHR Remote Sensing Imagery" Entropy 24, no. 11: 1619. https://doi.org/10.3390/e24111619