
Deep Learning and Entropy-Based Texture Features for Color Image Classification
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
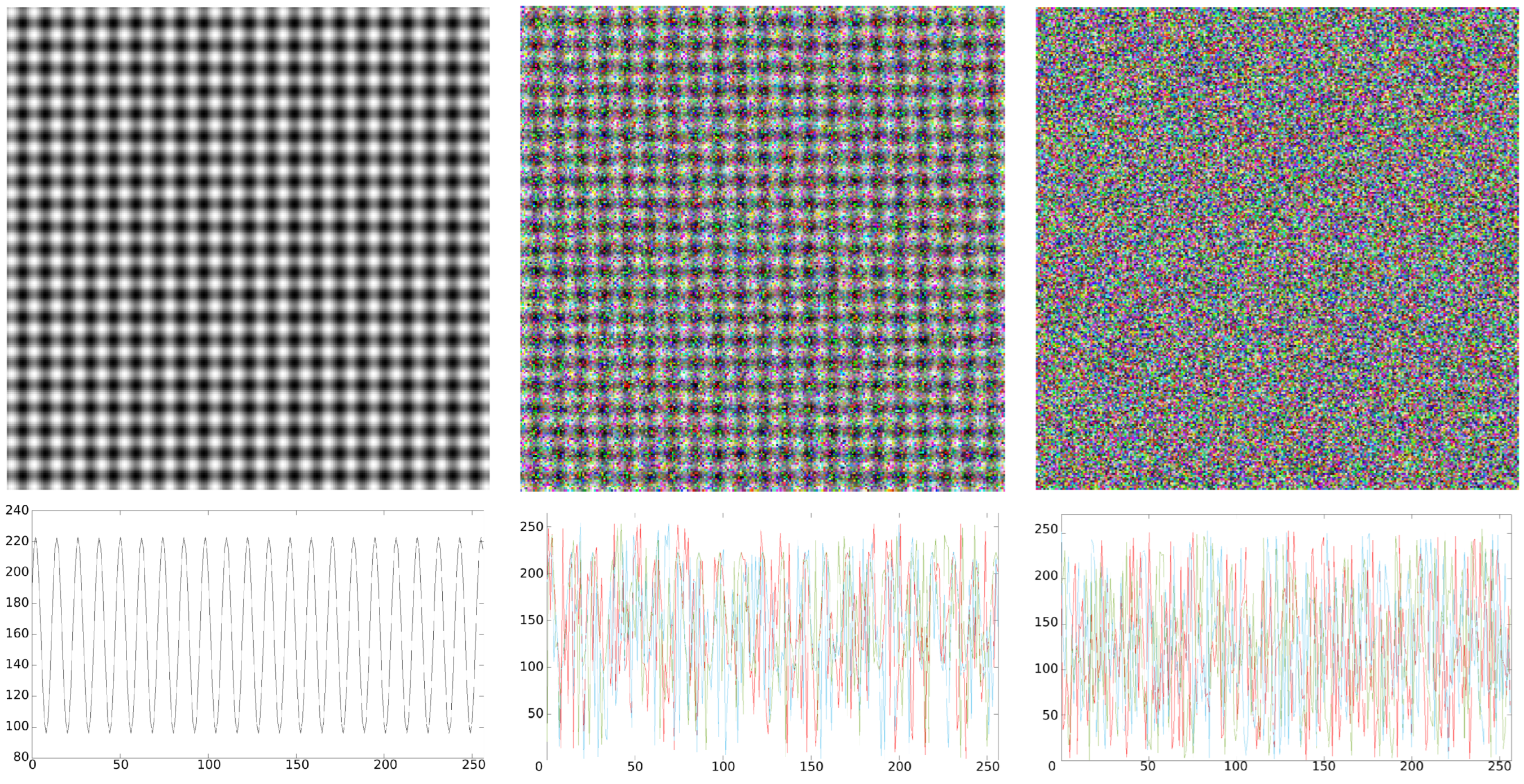
2.2. Synthetic Images
2.2.1. MIX Process for Multivariate One-Dimensional Signals
2.2.2. MIX Process for RGB Images
2.3. Pre-Processing of the Images
2.4. Entropy Methods
2.4.1. Sample Entropy
2.4.2. Fuzzy Entropy
2.4.3. Multiscale Entropy
2.4.4. Multivariate Entropy
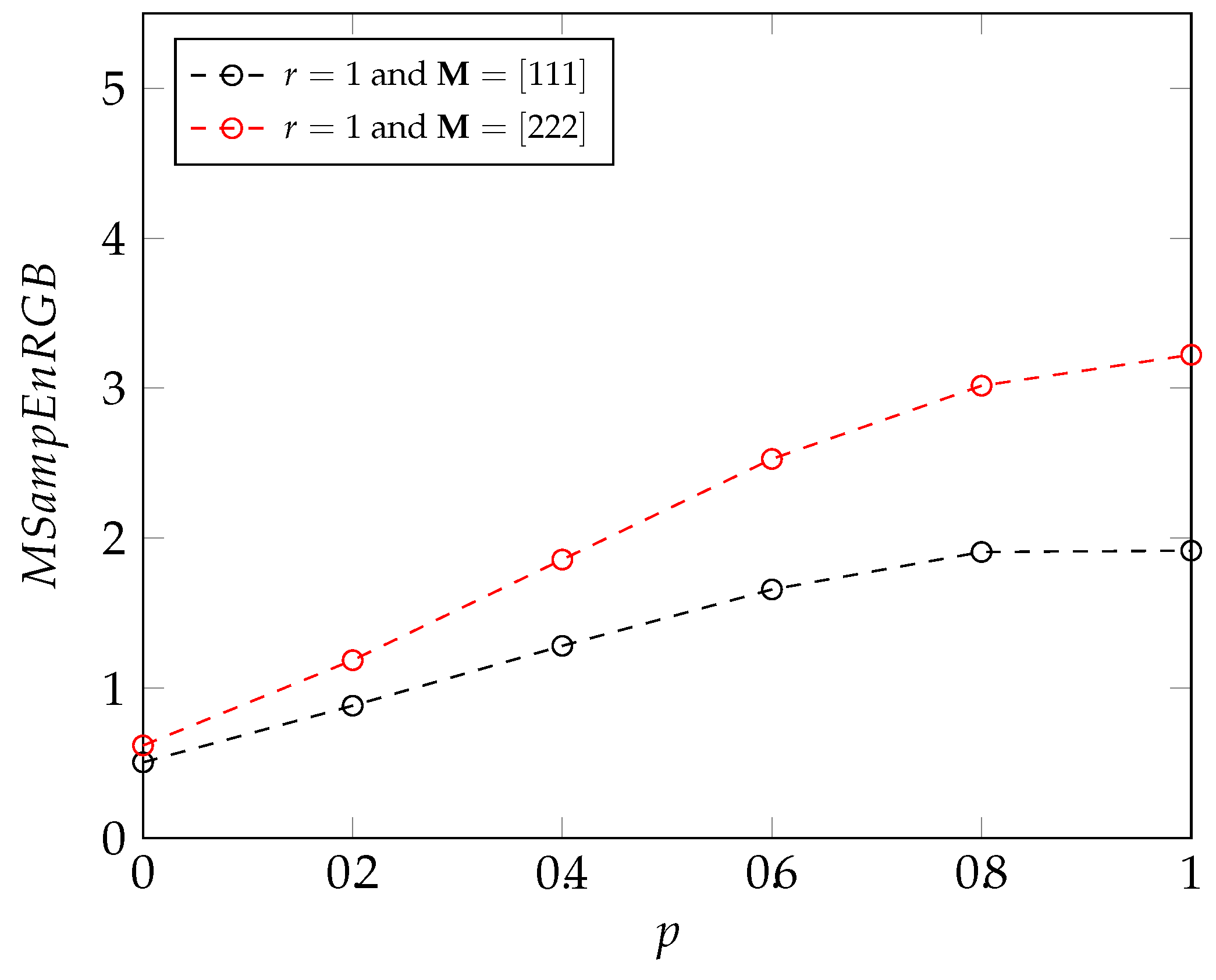
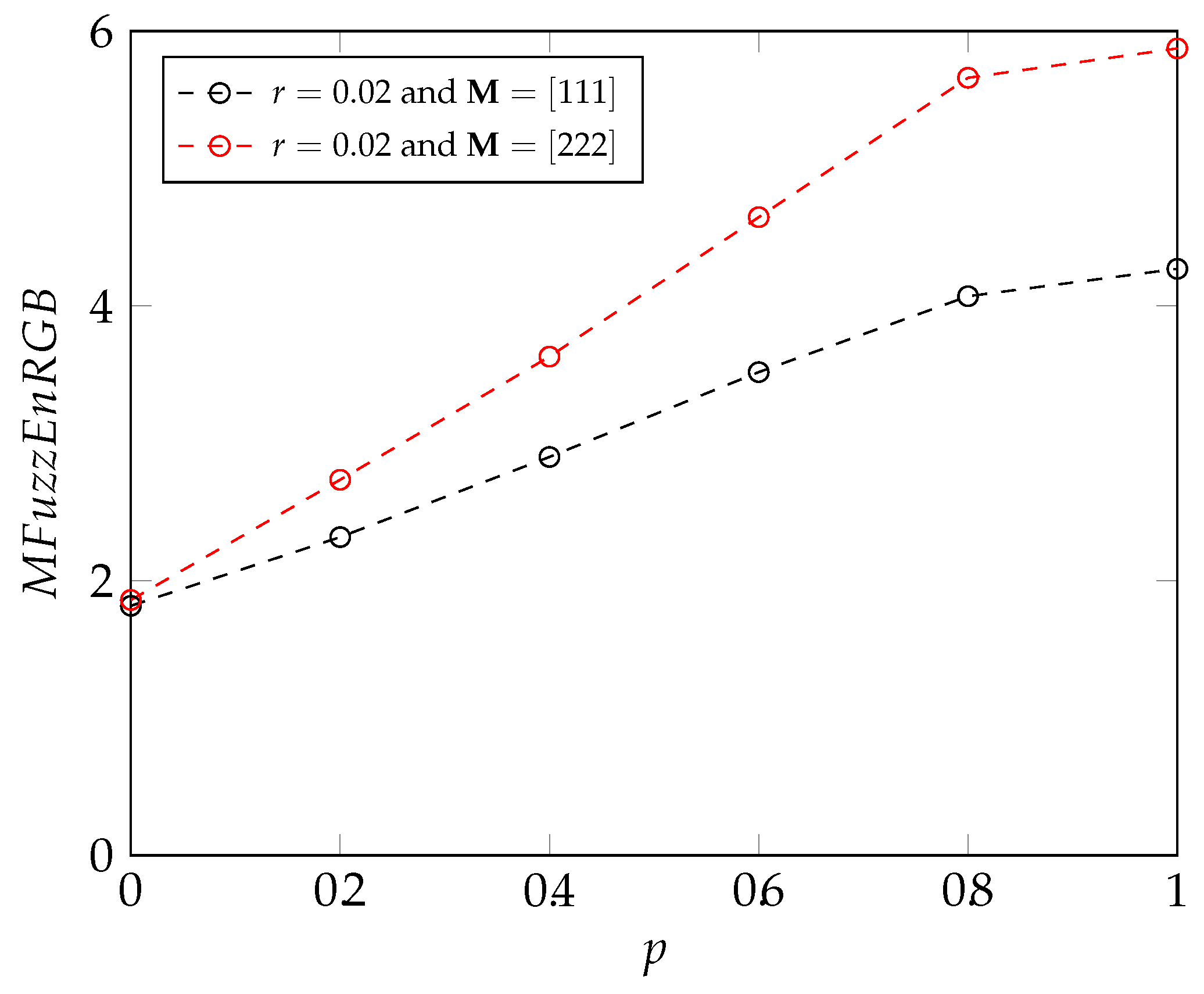
2.4.5. New Introduced Methods: Multivariate Sample and Fuzzy Entropy Measures for RGB Images
- Form composite delay vectors , where , , , is the embedding vector, and . The composite delay vector is determined as follows:
- Define the distance between any two vectors and , where , and , as the Chebychev or maximum norm distance between two vectors, that is,
- For a given composite delay vector and a threshold r, count the number of instances for which ; then, calculate the frequency of occurrence:and define
- Extend the dimension of the multivariate delay vector in Equation (3). This can be performed in p different ways, as from a space with the embedding vector the system can evolve to any space for which the embedding vector is . Thus, a total of vectors are obtained, where denotes any embedded vector upon increasing the embedding dimension from to for a specific variable k.
- For a given , calculate the number of vectors , such that ; then, calculate the frequency of occurrence:and define
- Finally, for a tolerance level r, estimate the multivariate sample entropy as
- 3.
- For a given composite delay vector , a threshold r and a fuzzy power s, compute the degree of similarity :Then, the function is defined as follows:where is the average of all the similarity degrees of a given composite delay vector .
- 5.
- For a given composite delay vector , a threshold r and a fuzzy power s, compute the degree of similarity :Then, the function is defined as follows:where is the average of all the similarity degrees of a given composite delay vector .
- 6.
- Finally, for a tolerance level r and a fuzzy power s, estimate the multivariate fuzzy entropy as
2.5. Deep-Learning Methods
2.5.1. Full Learning (or End-to-End Learning)
2.5.2. Transfer Learning
2.5.3. Fine Tuning
3. Results and Discussion
3.1. MIX Process
3.2. Texture Image Classification Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Humeau-Heurtier, A. Texture feature extraction methods: A survey. IEEE Access 2019, 7, 8975–9000. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [Green Version]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J.-Physiol.-Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of surface EMG signal based on fuzzy entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.U.; Mandic, D.P. Multivariate multiscale entropy: A tool for complexity analysis of multichannel data. Phys. Rev. E 2011, 84, 061918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Wang, R.; Yang, J.; Duan, L. An improved refined composite multivariate multiscale fuzzy entropy method for MI-EEG feature extraction. Comput. Intell. Neurosci. 2019, 2019, 7529572. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.U.; Chanwimalueang, T.; Thayyil, S.; Mandic, D.P. A multivariate multiscale fuzzy entropy algorithm with application to uterine EMG complexity analysis. Entropy 2016, 19, 2. [Google Scholar] [CrossRef] [Green Version]
- Silva, L.E.; Duque, J.J.; Felipe, J.C.; Murta, L.O., Jr.; Humeau-Heurtier, A. Two-dimensional multiscale entropy analysis: Applications to image texture evaluation. Signal Process. 2018, 147, 224–232. [Google Scholar] [CrossRef]
- Silva, L.E.V.; Senra Filho, A.; Fazan, V.P.S.; Felipe, J.C.; Junior, L.M. Two-dimensional sample entropy: Assessing image texture through irregularity. Biomed. Phys. Eng. Express 2016, 2, 045002. [Google Scholar] [CrossRef]
- Hilal, M.; Berthin, C.; Martin, L.; Azami, H.; Humeau-Heurtier, A. Bidimensional multiscale fuzzy entropy and its application to pseudoxanthoma elasticum. IEEE Trans. Biomed. Eng. 2019, 67, 2015–2022. [Google Scholar] [CrossRef]
- Morel, C.; Humeau-Heurtier, A. Multiscale permutation entropy for two-dimensional patterns. Pattern Recognit. Lett. 2021, 150, 139–146. [Google Scholar] [CrossRef]
- Azami, H.; da Silva, L.E.V.; Omoto, A.C.M.; Humeau-Heurtier, A. Two-dimensional dispersion entropy: An information-theoretic method for irregularity analysis of images. Signal Process. Image Commun. 2019, 75, 178–187. [Google Scholar] [CrossRef]
- Furlong, R.; Hilal, M.; O’brien, V.; Humeau-Heurtier, A. Parameter analysis of multiscale two-dimensional fuzzy and dispersion entropy measures using machine learning Classification. Entropy 2021, 23, 1303. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 4700–4708. [Google Scholar]
- Humeau-Heurtier, A. Color texture analysis: A survey. IEEE Access 2022, 10, 107993–108003. [Google Scholar] [CrossRef]
- Bianconi, F.; Fernández, A.; Smeraldi, F.; Pascoletti, G. Colour and Texture Descriptors for Visual Recognition: A Historical Overview. J. Imaging 2021, 7, 245. [Google Scholar] [CrossRef]
- Napoletano, P. Hand-crafted vs learned descriptors for color texture classification. In Proceedings of the International Workshop on Computational Color Imaging, Milan, Italy, 29–31 March 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 259–271. [Google Scholar]
- Hilal, M.; Gaudêncio, A.S.; Vaz, P.G.; Cardoso, J.; Humeau-Heurtier, A. Colored texture analysis fuzzy entropy methods with a dermoscopic application. Entropy 2022, 24, 831. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep learning vs. traditional computer vision. In Proceedings of the Science and Information Conference, Las Vegas, NV, USA, 25–26 April 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 128–144. [Google Scholar]
- Bello-Cerezo, R.; Bianconi, F.; Di Maria, F.; Napoletano, P.; Smeraldi, F. Comparative evaluation of hand-crafted image descriptors vs. off-the-shelf CNN-based features for colour texture classification under ideal and realistic conditions. Appl. Sci. 2019, 9, 738. [Google Scholar] [CrossRef] [Green Version]
- Epistroma Dataset. 2012. Available online: http://fimm.webmicroscope.net/Research/Supplements/epistroma (accessed on 19 September 2022).
- Linder, N.; Konsti, J.; Turkki, R.; Rahtu, E.; Lundin, M.; Nordling, S.; Haglund, C.; Ahonen, T.; Pietikäinen, M.; Lundin, J. Identification of tumor epithelium and stroma in tissue microarrays using texture analysis. Diagn. Pathol. 2012, 7, 22. [Google Scholar] [CrossRef] [PubMed]
- KTH-TIPS Dataset. 2006. Available online: https://www.csc.kth.se/cvap/databases/kth-tips/documentation.html (accessed on 19 September 2022).
- Fritz, M.; Hayman, E.; Caputo, B.; Eklundh, J.O. The KTH-TIPS Database. Available online: https://www.csc.kth.se/cvap/databases/kth-tips/kth-tips2.pdf (accessed on 19 September 2022).
- Alot Dataset. 2009. Available online: https://aloi.science.uva.nl/public_alot/ (accessed on 19 September 2022).
- Burghouts, G.J.; Geusebroek, J.M. Material-specific adaptation of color invariant features. Pattern Recognit. Lett. 2009, 30, 306–313. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. In Fuzzy Sets, Fuzzy Logic, and Fuzzy Systems: Selected Papers by Lotfi A Zadeh; World Scientific: Singapore, 1996; pp. 394–432. [Google Scholar]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2002, 89, 068102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Nanni, L.; Brahnam, S.; Brattin, R.; Ghidoni, S.; Jain, L.C. Deep Learners and Deep Learner Descriptors for Medical Applications; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- ImageNet Dataset. 2021. Available online: https://image-net.org/ (accessed on 19 September 2022).
- Nanni, L.; Ghidoni, S.; Brahnam, S. Deep features for training support vector machines. J. Imaging 2021, 7, 177. [Google Scholar] [CrossRef]
- Simon, P.; Uma, V. Deep learning based feature extraction for texture classification. Procedia Comput. Sci. 2020, 171, 1680–1687. [Google Scholar] [CrossRef]
- Vogado, L.; Veras, R.; Aires, K.; Araújo, F.; Silva, R.; Ponti, M.; Tavares, J.M.R. Diagnosis of leukaemia in blood slides based on a fine-tuned and highly generalisable deep learning model. Sensors 2021, 21, 2989. [Google Scholar] [CrossRef]
- Sidiropoulos, G.K.; Ouzounis, A.G.; Papakostas, G.A.; Lampoglou, A.; Sarafis, I.T.; Stamkos, A.; Solakis, G. Hand-crafted and learned feature aggregation for visual marble tiles screening. J. Imaging 2022, 8, 191. [Google Scholar] [CrossRef]
- Yelchuri, R.; Dash, J.K.; Singh, P.; Mahapatro, A.; Panigrahi, S. Exploiting deep and hand-crafted features for texture image retrieval using class membership. Pattern Recognit. Lett. 2022, 160, 163–171. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Subject | Classes | Images per Classes (Mean) | Total Images | Images Size (px) | Year | Reference |
|---|---|---|---|---|---|---|---|
| Epistroma | Histological images of colorectal cancer | 2 | 688 | 1376 | 172 × 172 to 2372 × 2372 | from 1989 to 1998 | [25] |
| KTH-TIPS2-a | Mixed | 11 | 432 | 4608 | 200 × 200 | 2006 | [27] |
| ALOT | Mixed | 250 | 100 | 25,000 | 1536 × 1024 | 2009 | [29] |
| 10-Layers CNN | |||
|---|---|---|---|
| Layer | Input | Output | Parameters |
| Rescaling | image size | (224, 224, 3) | 0 |
| Conv2D | (224, 224, 3) | (222, 222, 32) | 896 |
| MaxPooling2D | (222, 222, 32) | (111, 111, 32) | 0 |
| Conv2D | (111, 111, 32) | (109, 109, 64) | 18,496 |
| MaxPooling2D | (109, 109, 64) | (54, 54, 64) | 0 |
| Conv2D | (54, 54, 64) | (52, 52, 64) | 36,928 |
| MaxPooling2D | (52, 52, 64) | (26, 26, 64) | 0 |
| Flatten | (26, 26, 64) | (1, 43,264) | 0 |
| Dense | (1, 43,264) | (1, 128) | 5,537,920 |
| Dense | (1, 128) | (1, number of classes) | 258 |
| Univariate sample entropy (for grayscale images): | 67.02% |
| Univariate multiscale sample entropy (for grayscale images): | 69.06% |
| Univariate fuzzy entropy (for grayscale images): | 62.85% |
| Univariate multiscale fuzzy entropy (for grayscale images): | 66.95% |
| Univariate fuzzy entropy (for RGB images): | 67.75% |
| Univariate multiscale fuzzy entropy (for RGB images): | 69.10% |
| Size of the images | 50 × 50 | 100 × 100 |
| Multivariate multiscale sample entropy RGB | 70.64% | 78.11% |
| Multivariate multiscale fuzzy entropy RGB | 66.45% | 72.96% |
| Epistroma | KTH-TIPS2-a | Alot | |
| 10-layers CNN | 91.03% | 85.32% | 67.25% |
| Resnet50 with fully connected layer | 93.05% | 94.98% | 81.04% |
| Resnet50 with SVM classification | 92.22% | 96.54% | 81.08% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lhermitte, E.; Hilal, M.; Furlong, R.; O’Brien, V.; Humeau-Heurtier, A. Deep Learning and Entropy-Based Texture Features for Color Image Classification. Entropy 2022, 24, 1577. https://doi.org/10.3390/e24111577
Lhermitte E, Hilal M, Furlong R, O’Brien V, Humeau-Heurtier A. Deep Learning and Entropy-Based Texture Features for Color Image Classification. Entropy. 2022; 24(11):1577. https://doi.org/10.3390/e24111577
Chicago/Turabian StyleLhermitte, Emma, Mirvana Hilal, Ryan Furlong, Vincent O’Brien, and Anne Humeau-Heurtier. 2022. "Deep Learning and Entropy-Based Texture Features for Color Image Classification" Entropy 24, no. 11: 1577. https://doi.org/10.3390/e24111577