
A Simplified Quantum Walk Model for Predicting Missing Links of Complex Networks

Abstract
:1. Introduction
- (i)
- Compared to existing quantum walk models on a complex network, the complexity and the negative effects generated by the interference effect of quantum walk are minimised in the proposed simplified quantum walk model. In contrast, since the construction method entirely depends on direct product operation and restricts by strict unitary evolution, other quantum walks on the complex network do not circumvent these effects and cannot effectively develop the structural characteristics of networks.
- (ii)
- The proposed model can be utilised for predicting the missing links of complex networks, which has a high accuracy in two indices on link prediction, because the common neighbour and similarity between nodes are effectively contained in the evolution operator of the proposed model. Experimental validation of the proposed model indicates that, despite limiting its walk to two steps, the proposed simplified quantum walk model outperforms other random walk-based algorithms as well as global similarity-based algorithms in the prediction of missing links.
2. Predicting Missing Links and the Proposed Simplified Quantum Walk Model
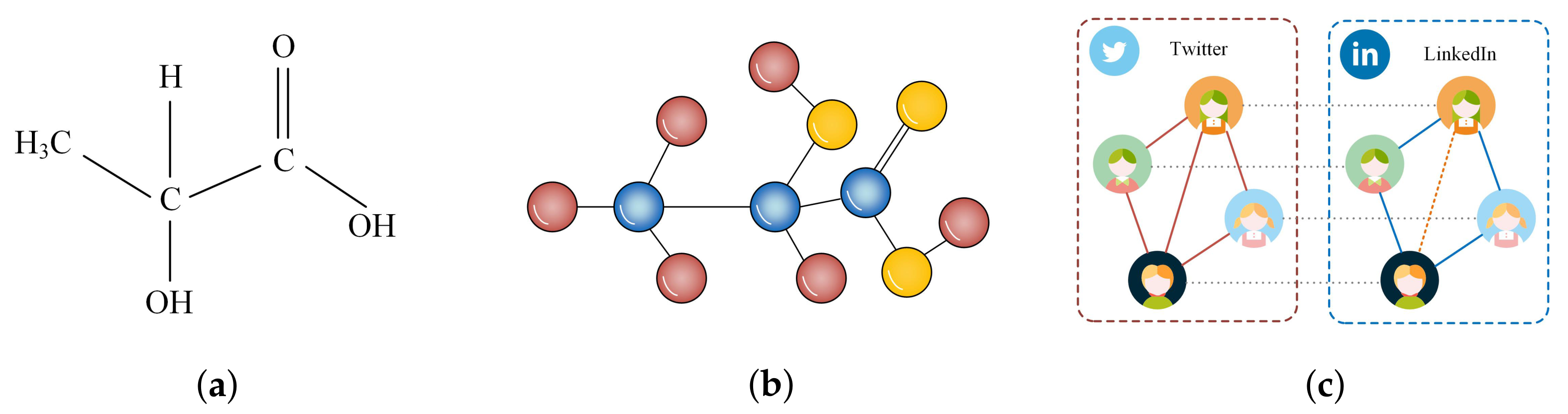
2.1. Prediction of Missing Links in Complex Networks
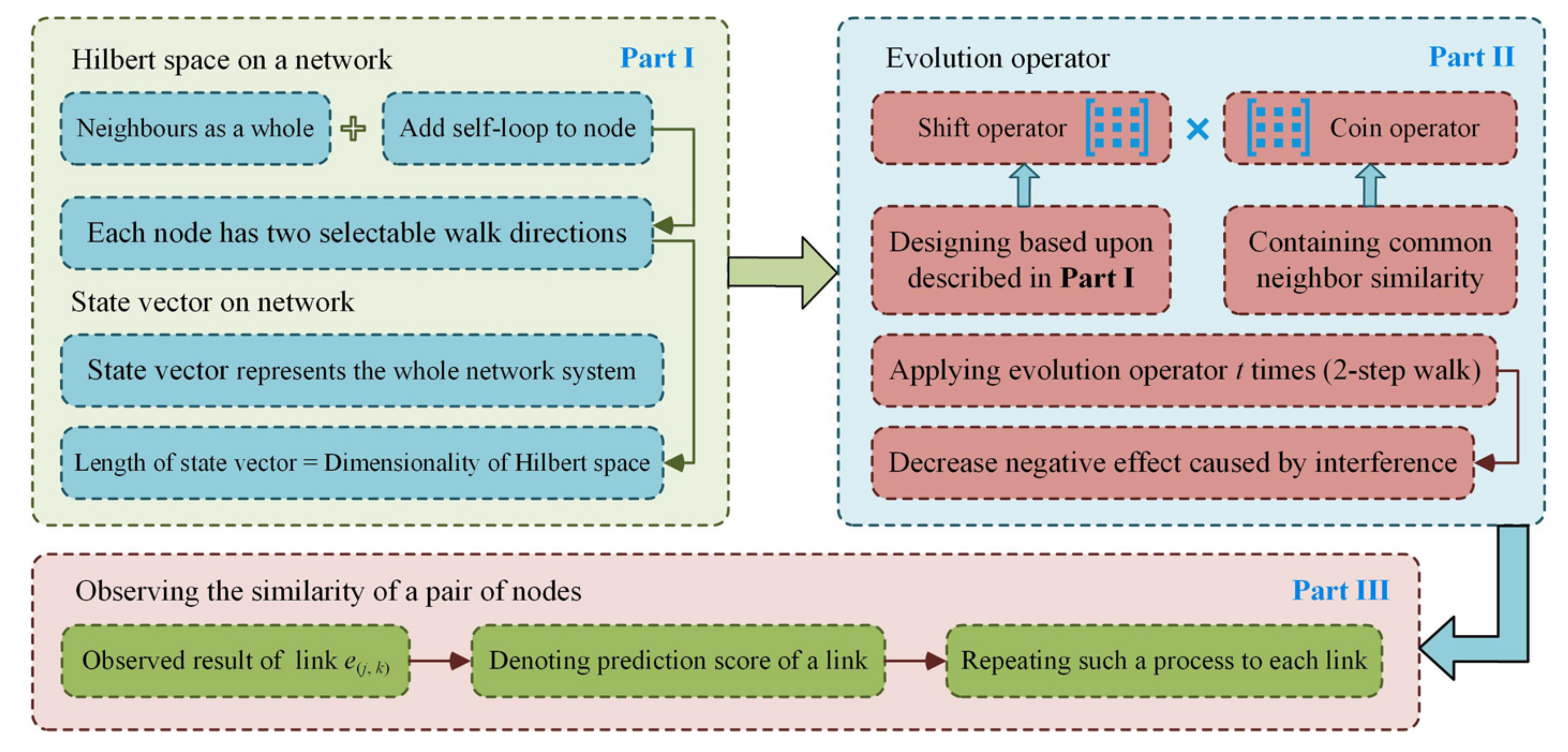
2.2. Application of the Proposed Model in Link Prediction
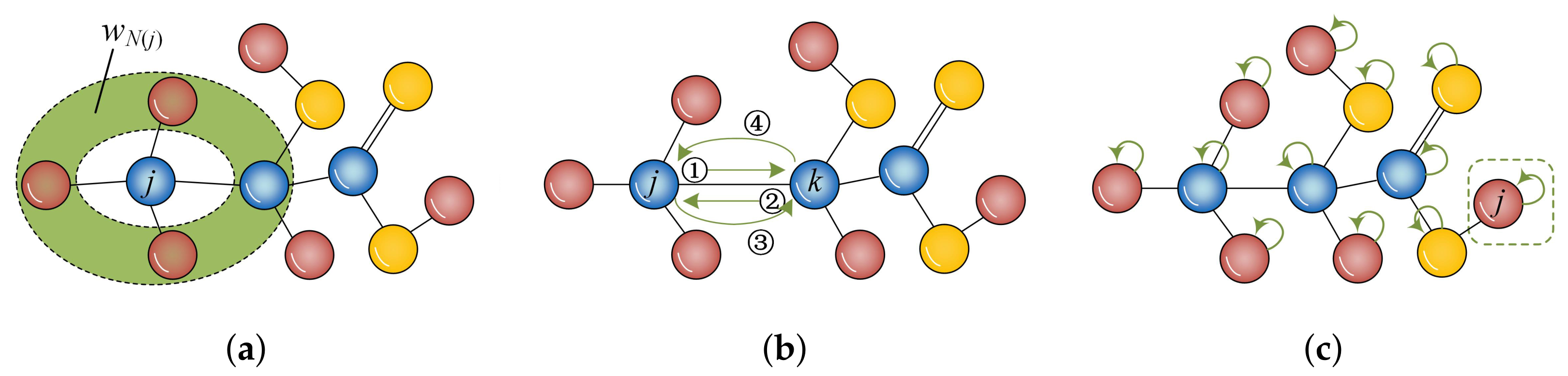
2.2.1. Hilbert Space and State Vector on a Complex Network
2.2.2. Construction of Evolution Operator in the Proposed Model
2.2.3. Observation of Similarity between Two Nodes
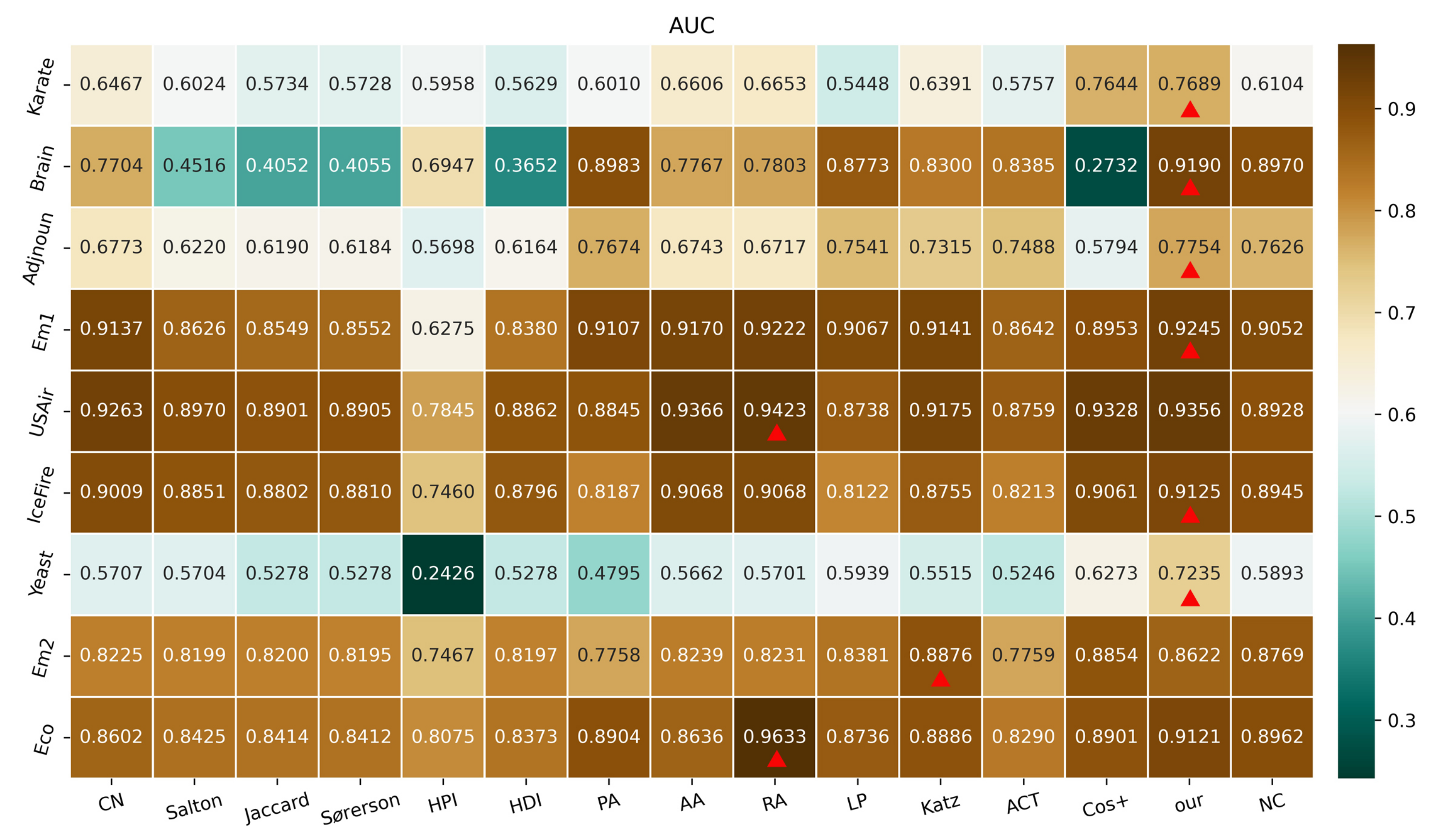
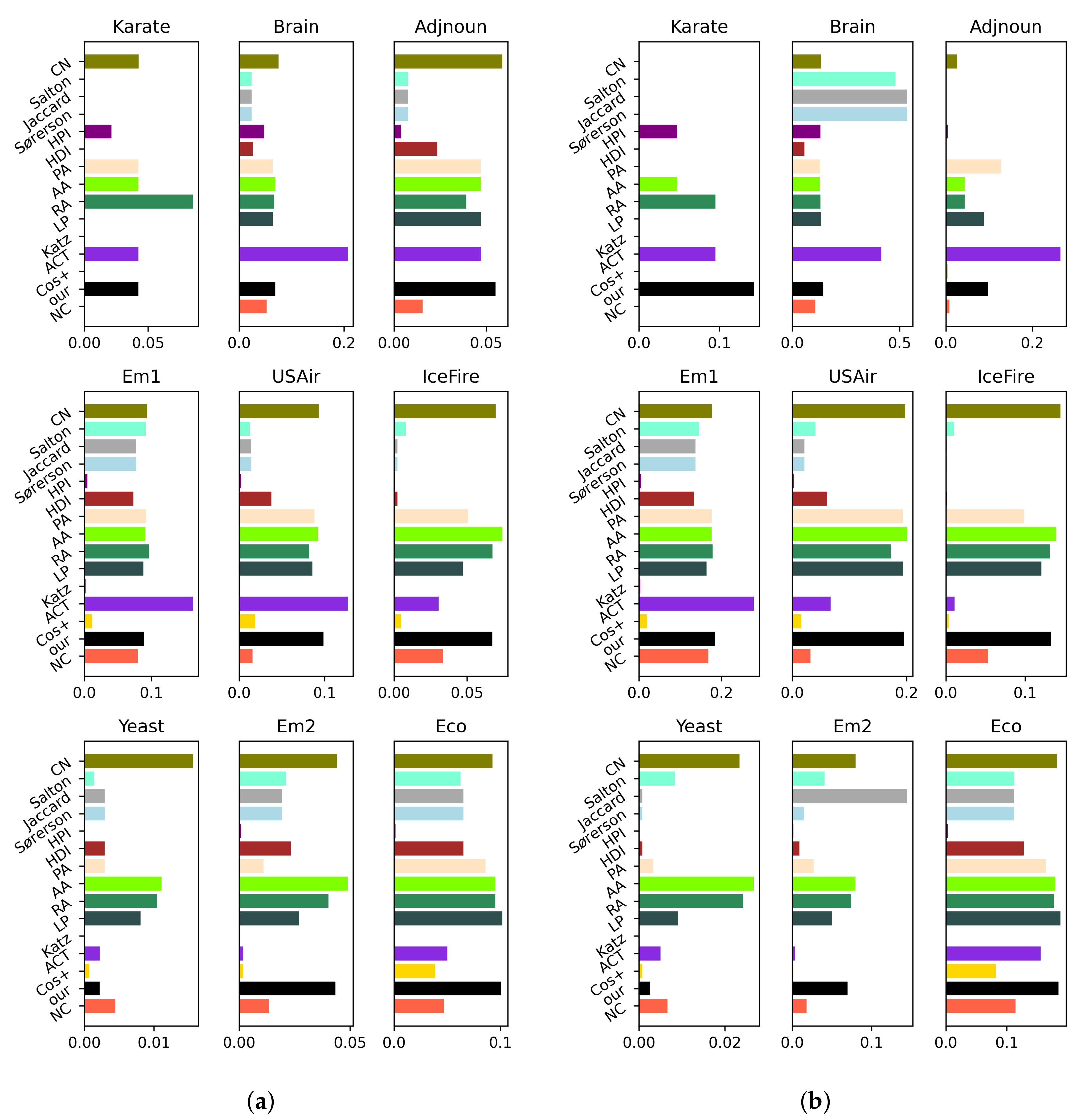
3. Prediction of Missing Links Using the Proposed Model
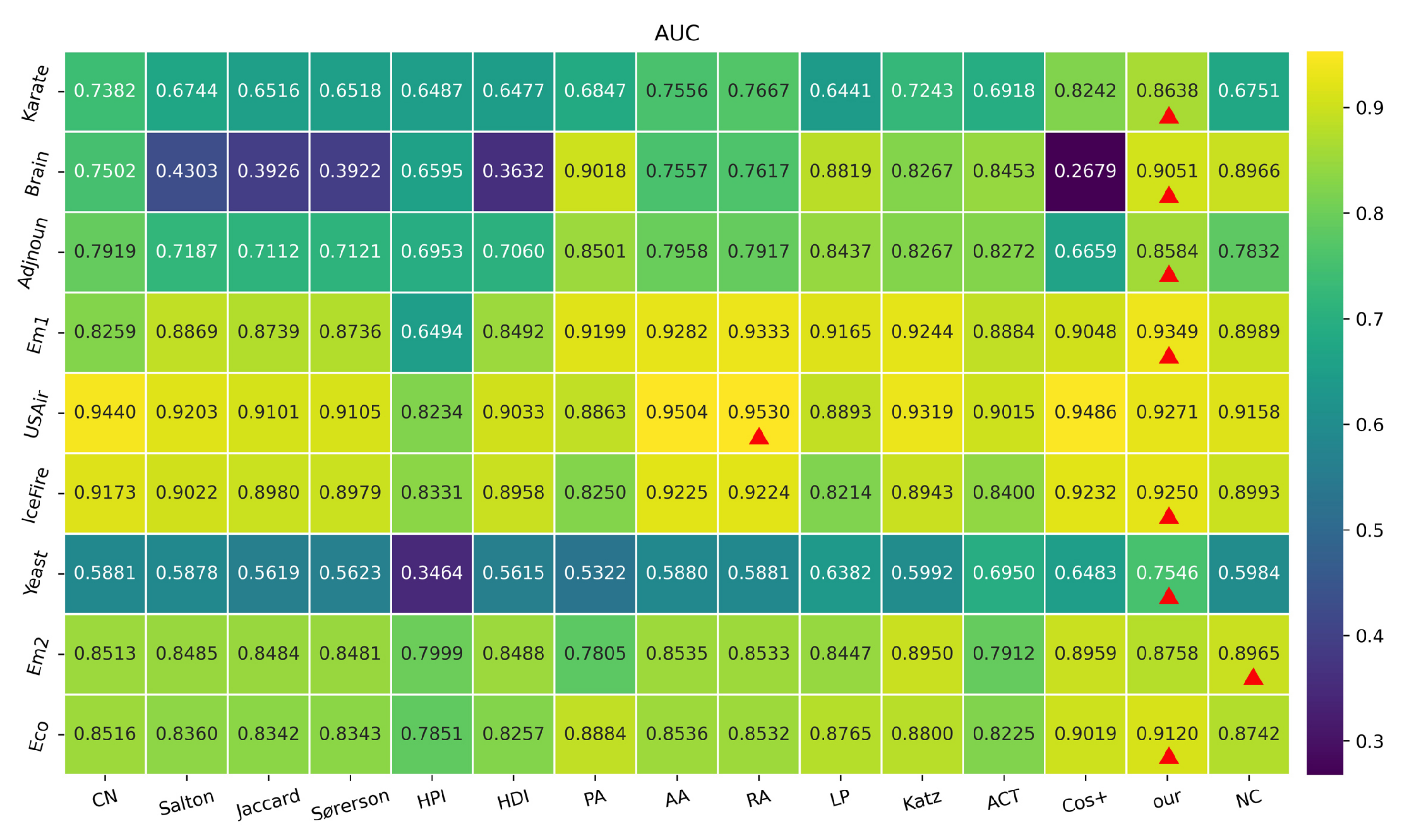
3.1. Performance Analysis Using the AUC Index for Different Values of
3.2. Experiment on Precision Index under Various
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Du, X.; Yan, J.; Zhang, R.; Zha, H. Cross-network Skip-gram embedding for joint network alignment and link prediction. IEEE Trans. Knowl. Data Eng. 2022, 34, 1080–1095. [Google Scholar] [CrossRef]
- Daud, N.; Ab Hamid, S.; Saadoon, M.; Sahran, F.; Anuar, N. Applications of link prediction in social networks: A review. J. Netw. Comput. Appl. 2020, 166, 102716. [Google Scholar] [CrossRef]
- Mori, L.; OHara, K.; Pujol, T.A.; Ventresca, M. Examining supervised machine learning methods for integer link weight prediction using node metadata. Entropy 2022, 24, 842. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Singh, S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. Stat. Mech. Its Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, P. Broad Learning Through Fusions, An Application on Social Networks; Springer: Berlin, Germany, 2019. [Google Scholar]
- Cannistraci, C.; Alanis-Lobato, G.; Ravasi, T. From link-prediction in brain connectomes and protein interactomes to the local-community-paradigm in complex networks. Sci. Rep. 2013, 3, 1613. [Google Scholar] [CrossRef] [Green Version]
- Lorrain, F.; White, H. Structural equivalence of individuals in social networks. J. Math. Sociol. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Torey Bot. Club 1901, 37, 547–579. [Google Scholar]
- Salton, G.; McGill, M. Introduction to Modern Information Retrieval; McGraw Hill: New York, NY, USA, 1983. [Google Scholar]
- Sørensen, T. Method of establishing groups of equal amplitude in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish Commons. Biol. Skr. 1948, 5, 1–34. [Google Scholar]
- Xie, Y.; Tao, Z.; Wang, B. Scale-free networks without growth. Phys. Stat. Mech. Its Appl. 2017, 387, 1683–1688. [Google Scholar] [CrossRef] [Green Version]
- Adamic, L.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef]
- Liu, X.; Meng, D.; Zhu, X.; Tian, Y. Link prediction based on contribution of neighbors. Int. J. Mod. Phys. C 2020, 31, 2050158. [Google Scholar] [CrossRef]
- Klein, D.; Randić, M. Resistance distance. J. Math. Chem. 1993, 12, 81–95. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98–101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Airoldi, E.; Blei, D.; Fienberg, S.; Xing, E. Mixed-membership stochastic blockmodels. J. Mach. Learn. Res. 2008, 9, 1981–2014. [Google Scholar]
- Pan, L.; Zhou, T.; Lü, L.; Hu, C. Predicting missing links and identifying spurious links via likelihood analysis. Sci. Rep. 2016, 6, 22955. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Mishra, S.; Kumar, A.; Biswas, B. CLP-ID: Community-based link prediction using information diffusion. Inf. Sci. 2020, 514, 402–433. [Google Scholar] [CrossRef]
- Li, J.; Peng, X.; Wang, J.; Zhao, N. A method for improving the accuracy of link prediction algorithms. Complexity 2021, 2021, 8889441. [Google Scholar] [CrossRef]
- Mukai, K.; Hatano, N. Discrete-time quantum walk on complex networks for community detection. Phys. Rev. Res. 2020, 2, 023378. [Google Scholar] [CrossRef]
- Liang, W.; Yan, F.; Iliyasu, A.M.; Salama, A.S.; Hirota, K. A Hadamard walk model and its application in identification of important edges in complex networks. Comput. Commun. 2022, 193, 378–387. [Google Scholar] [CrossRef]
- Loke, T.; Tang, J.; Rodriguez, J.; Small, M.; Wang, J. Comparing classical and quantum PageRanks. Quantum Inf. Process. 2017, 16, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Yan, F.; Liang, W.; Hirota, K. An information propagation model for social networks based on continuous-time quantum walk. Neural Comput. Appl. 2022, 34, 13455–13468. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, L.; Wilson, R.; Liu, K. An R-convolution graph kernel based on fast discrete-time quantum walk. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 292–303. [Google Scholar] [CrossRef]
- Paparo, G.; Müller, M.; Comellas, F.; Martin-Delgado, M. Quantum Google in a complex network. Sci. Rep. 2013, 3, 2773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, S.; Wang, J. Quantum walk-based search and centrality. Phys. Rev. A 2010, 82, 042333. [Google Scholar] [CrossRef] [Green Version]
- Grover, L. Quantum computers can search arbitrarily large databases by a single query. Phys. Rev. Lett. 1997, 79, 4703. [Google Scholar] [CrossRef] [Green Version]
- Inui, N.; Konno, N.; Segawa, E. One-dimensional three-state quantum walk. Phys. Rev. E 2005, 72, 056112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Machida, T.; Chandrashekar, C. Localization and limit laws of a three-state alternate quantum walk on a two-dimensional lattice. Phys. Rev. A 2015, 92, 062307. [Google Scholar] [CrossRef] [Green Version]
- Falkner, S.; Boettcher, S. Weak limit of the three-state quantum walk on the line. Phys. Rev. A 2014, 90, 012307. [Google Scholar] [CrossRef] [Green Version]
- Rossi, R.; Ahmed, N. The network data repository with interactive graph analytics and visualization. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29, pp. 4292–4293. [Google Scholar]
- Newman, M. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 036104. [Google Scholar] [CrossRef] [Green Version]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Jeong, H.; Tombor, B.; Albert, R.; Oltvai, Z.; Barabási, A. The large-scale organization of metabolic networks. Nature 2000, 407, 651–654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y. Predicting missing links via local information. Eur. Phys. J. B-Condens. Matter Complex Syst. 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Fouss, F.; Pirotte, A.; Renders, J.; Saerens, M. Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans. Knowl. Data Eng. 2007, 19, 355–369. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | N | M | d | c | |||
|---|---|---|---|---|---|---|---|
| Karate [33] | 34 | 78 | 4.588 | 17 | 5 | 0.256 | −0.475 |
| Brain [33] | 91 | 1989 | 43.714 | 248 | 3 | 1.304 | −0.343 |
| Adjnoun [34] | 112 | 425 | 7.589 | 49 | 5 | 0.190 | −0.129 |
| Em1 [33] | 167 | 3251 | 38.934 | 139 | 5 | 0.685 | −0.295 |
| Eco [33] | 259 | 2942 | 19.560 | 108 | 6 | 0.395 | 0.018 |
| USAir [33] | 332 | 2126 | 12.807 | 139 | 6 | 0.749 | −0.207 |
| IceFire [35] | 796 | 2823 | 81.982 | 122 | 9 | 0.209 | −0.115 |
| Em2 [33] | 1133 | 5451 | 9.622 | 71 | 8 | 0.254 | 0.078 |
| Yeast [36] | 1870 | 2277 | 2.435 | 56 | 19 | 0.055 | −0.161 |
| Algorithm (Indices) | Mathematical Expression |
|---|---|
| Common Neighbours [7] (CN) | |
| Salton Index [9] | |
| Jaccard Index [8] | |
| Sorenson Index [10] | |
| Hub Promoted Index [36] (HPI) | |
| Hub Depresses Index [37] (HDI) | |
| Preferential Attachment [11] (PA) | |
| Admic-Adar [12] (AA) | |
| Resource Allocation [37] (RA) | |
| Local Path [37] (LP) | |
| Katz [38] | |
| Average commute time [16] (ACT) | |
| Random walk similarity by cosine [39] (Cos+) | |
| Neighbour Contribution [15] (NC) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, W.; Yan, F.; Iliyasu, A.M.; Salama, A.S.; Hirota, K. A Simplified Quantum Walk Model for Predicting Missing Links of Complex Networks. Entropy 2022, 24, 1547. https://doi.org/10.3390/e24111547
Liang W, Yan F, Iliyasu AM, Salama AS, Hirota K. A Simplified Quantum Walk Model for Predicting Missing Links of Complex Networks. Entropy. 2022; 24(11):1547. https://doi.org/10.3390/e24111547
Chicago/Turabian StyleLiang, Wen, Fei Yan, Abdullah M. Iliyasu, Ahmed S. Salama, and Kaoru Hirota. 2022. "A Simplified Quantum Walk Model for Predicting Missing Links of Complex Networks" Entropy 24, no. 11: 1547. https://doi.org/10.3390/e24111547