1. Introduction
With the recent development of deep neural networks (DNNs), people have increasingly realized that these network architectures are extremely vulnerable to attacks by adversarial perturbations [
1,
2,
3]. By adding adversarial perturbations that humans cannot perceive to input images, DNNs [
4] become unable to output correct feedback. Such a unique characteristic gives DNN robustness increasing research value. Based on how much internal network information DNNs provide, adversarial attacks are generally divided into two categories: white-box and black-box. The victim model of white-box attacks provides complete information for attackers, including the outputs of DNNs and all internal neural node gradient information [
2,
5]. This enables attackers to generate corresponding adversarial examples in a targeted manner. Nevertheless, such an attack background and condition do not satisfy the requirements of adversarial attacks in real environments. Thus, due to the harsh conditions of black-box attacks, with less available information, they have gradually become the recent mainstream research direction of adversarial attacks. In a black-box attack, the attacker can only obtain output information of input images from the target model, while the internal information remains hidden. Up to now, black-box adversarial attack methods proposed in academic circles have been mainly divided into three categories: query-based attacks, transfer-based attacks, and meta-learning-based attacks.
For attacks based on query, due to their high attack success rate, people have already made effort to study them under the circumstances that only the label or probability information of each input image can be obtained. Although there is still a problem in that the amount of information obtained by querying the model each time is relatively small, by using massive queries combined with a more accurate gradient estimation algorithm, attackers can still easily generate the required adversarial perturbations. In order to achieve better query results, researchers have begun to pay more attention to query efficiency problems. Various innovative methods for uncovering deeper hidden information [
6,
7,
8,
9] have emerged for increasing the query utilization rate. However, the considerable number of queries required still makes purposeful adversarial attacks detectable in real environment and signals the victim to take defensive actions.
For attacks based on model transfer, the original intention of this design was to decrease the ability of query attacks to be easily defended against. This type of black-box attack transfers part of the queries from the black-box model to the local agent model selected by the attacker in order to decrease the abnormal behavior of high-frequency queries to the black-box model [
10,
11,
12,
13,
14]. Then, it uses existing white-box adversarial attack methods to generate black-box attack perturbations based on the transferred agent model. However, since the success of the attack completely depends on the similarity between the transferred local agent model and the black-box target model, the attack success rate of this method is extremely unstable. To minimize this difference between models as much as possible, a synthetic dataset training method [
15,
16,
17] has been proposed, which cross-uses the training images and the output results of the black-box model to train the local agent model. This method also affects the black-box model’s initiation of defensive mechanisms [
18,
19,
20]. When the training feedback of the local transferred model reaches the set threshold, the local agent model is considered a qualified imitator of the black-box target model and becomes the main target of subsequent queries.
However, this type of black-box attack is still far from reaching the attack success rate of the aforementioned query-based attack.For attacks based on meta-learning, the idea behind this type of attack is very novel. It optimizes and improves the shortages of query-based and transfer-based attacks. Meta-learning-based attacks use the characteristics of meta-learning and knowledge distillation to make the transferred simulator model more adaptable. This model can utilize a limited number of queries in a short time to imitate the target black-box model effectively and can quickly take on the task of acting as an accurate local agent model. As shown by Ma’s work [
21], this method has the advantages of both keeping a high attack success rate and maintaining effective attack capabilities against black-box target models with defensive mechanism. However, such an attack still does not fully utilize the information of each query. For the simulator model object that is queried each time, Ma’s method [
21] ignores internal information obtained by prior meta-learning and treats the model as a black-box during the entire attack process.
Therefore, fully using the internal information in the simulator model, which consumes a great amount of training cost, is worthwhile for further research. As stated by Zhou et al. [
22], the training and learning process of any model can be divided into two stages:
feature representation ability learning and
classification ability learning. Because the learning costs of the simulator model obtained by meta-learning are for various selected mainstream models, the feature representation ability and classification ability of these models to the training dataset have been mastered by the simulator model. When simulator attack begins, the simulator model used as a local agent model attempts to imitate the black-box target model, which has never been seen before. Referring to the transferability of a model [
21], the feature representation ability of the initial simulator model is already especially similar to that of the black-box target model for the same dataset images. However, the gap between the simulator model and the black-box target model does exist in classification ability to a certain extent. Through feature extraction and visualization of the simulator model in the initial state and the model selected as the black-box target, we find that the feature attentional area of an image is almost the same between the two models. Furthermore, by output information extraction and visualization of the two models, we also observe that the initial simulator model and the black-box model have a large gap in classification ability through comparisons. Such results strongly prove the correctness and usability of the feature layer information of the simulator model.
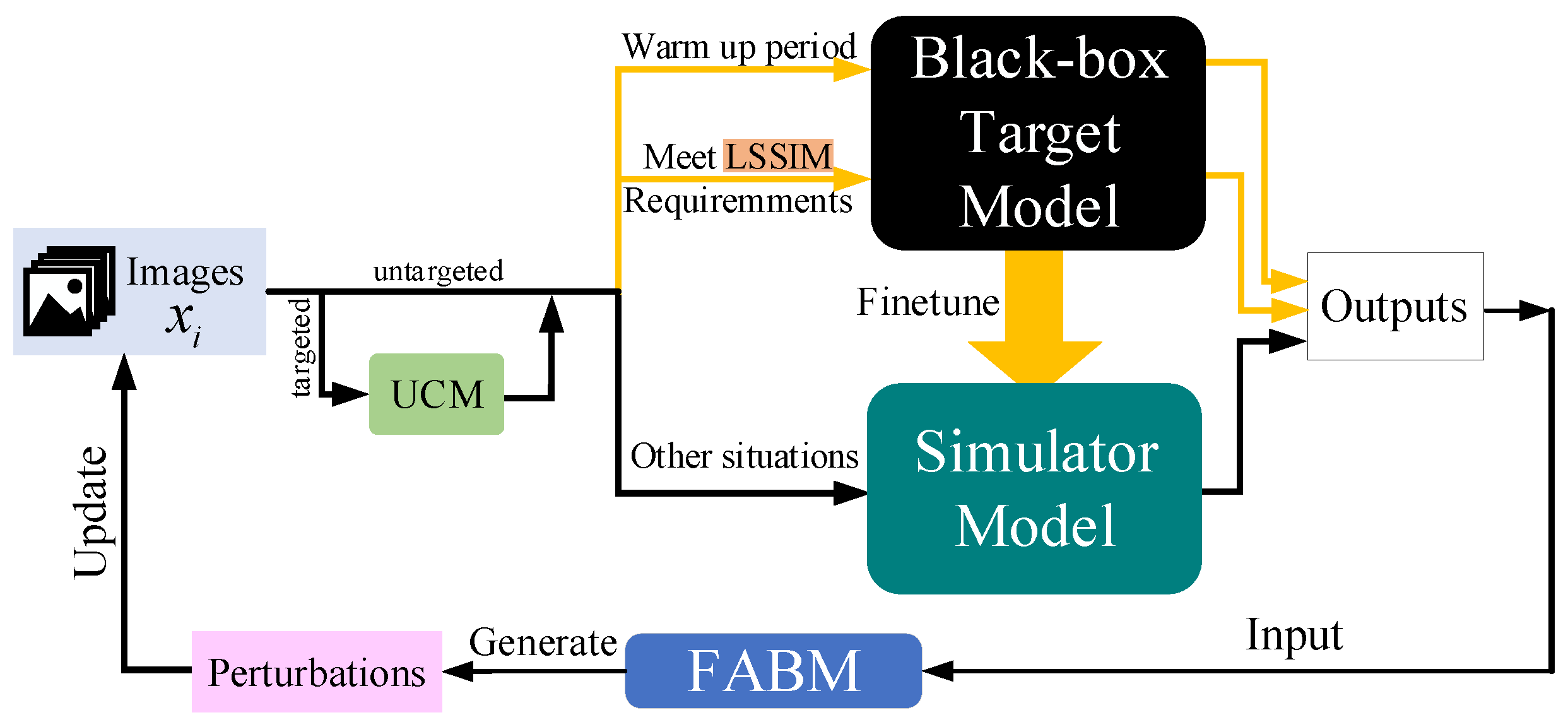
Based on this discovery, we make full use of the feature layer information of the simulator model and propose a feature attentional boosting module (FABM). This module strengthens the adversarial attack of perturbations, which is conducive to our attack framework to find suitable adversarial examples faster than the baseline. We add an
unsupervised clustering module (UCM) and a
linear self-adaptive simulator-predict interval mechanism (LSSIM) to the targeted attack to solve the cold start problem in attack situations requiring a large number of queries.
Figure 1 below clearly presents the whole process of Simulator Attack+.
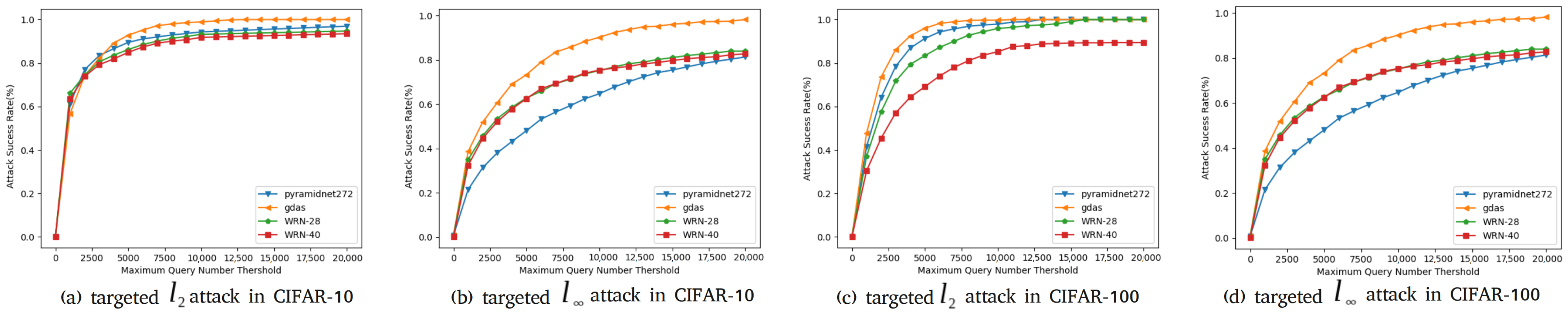
In this paper, for the purpose of comparing the performance of our attack framework with the baseline explicitly, we follow the settings of Ma et al. [
21] to conduct adversarial attacks [
8,
9,
23,
24,
25] against the same black-box target models using the CIFAR-10 [
26] and CIFAR-100 [
26] datasets. The experimental results show that, compared with the baseline [
21], our framework achieves a certain degree of improvement in query information utilization while maintaining a high attack success rate.
The main contributions of this paper are summarized in the following points:
(1) We find and prove that the feature representation ability of the simulator model in black-box attacks based on meta-learning is correct and usable. The simulator model obtained through meta-learning can already represent the features and characteristics of an object in the image relatively correctly in the initial state. So the internal feature information of such a model can be used as a basis for generating and updating the perturbations that we require in the adversarial attack.
(2)
Combined with the finding of (1), we analyze and optimize Ma’s Simulator Attack [21] and propose its improved version, Simulator Attack+. Our black-box attack framework makes specific adjustments to the three shortcomings of the baseline method by adding
FABM, LSSIM, and
UCM separately to solve the above mentioned problems:
The correct feature layer information of the simulator model obtained by meta-learning is ignored in the baseline, whereas it is actually valuable for acquiring proper adversarial perturbations;
Ma’s attack framework [
21] has an imbalance in the imitation effect before and after the simulator model is fully fine-tuned;
Adversarial perturbation changing only considers global adjustment without specialization enhancement.
(3) Conducting multi-group experiments on the CIFAR-10 and CIFAR-100 datasets, our well-designed meta-learning-based black-box attack framework greatly improves the utilization of query information compared with the original version, and also raises query efficiency to a certain extent while reducing the number of queries.
3. Methods
To improve the query efficiency and decrease the total number of queries consumed, we propose FABM, LSSIM, and UCM and then attach these modules to our Simulator Attack+ framework. These attachments follow our discovery that similarity feature layer information between two models can help optimize the baseline method.
3.1. Feature Attentional Boosting Module
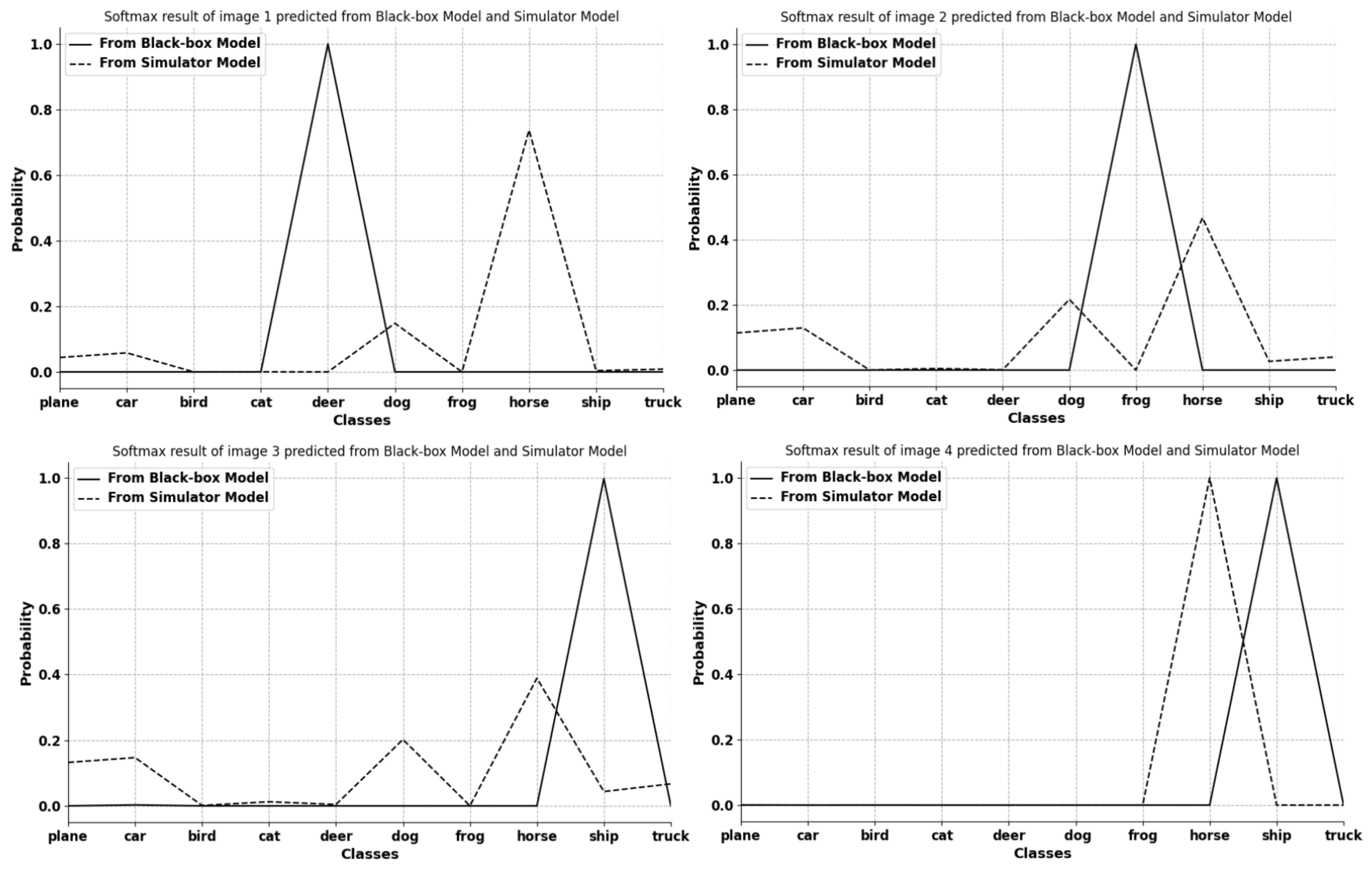
As a consensus, a meta simulator model trained from meta-learning can quickly imitate another model by finetuning itself and shares generality with other mainstream models. However, such a meta simulator model applied in Simulator Attack is treated the same as the black-box model. Its internal information is ignored during an attack. In order to find the usability of this information, we extract and visualize the feature layer of a simulator model (
Figure 2). After comparing the feature attentional regions between the simulator model and the black-box target model, we find that the attentional areas of both models nearly overlap. Thus, we conclude that some of the feature layer information in the meta simulator model can be used in the black-box attack due to their similarity. However,
Figure 3 also indicates that the classification ability varies between the initial simulator model and the black-box target model, and this classification ability is the key point that the simulator model needs to learn during the finetuning process.
In the baseline, Ma et al. [
21] only use random normal distribution noise as their step-size in the image changing process. This method has strong randomness in searching for proper adversarial perturbations. Furthermore, for how to change the adversarial images properly, Ma [
21] merely provides a global direction for all pixels in an image to transform without optimizing specific areas or using any corrected feature information based on prior knowledge. To improve the usage of information from queries more rationally, we add an extra adversarial effect inspired by the attention mechanism to reduce the randomness as much as possible. At the same time, such additional adversarial perturbations can create extra radical attacks on attentional regions where both the meta simulator model and the black-box model focus. We give two different options of adversarial perturbation type: normal distribution boosting and momentum boosting. Normal distribution boosting follows the method of the baseline to search for the proper adversarial perturbation randomly by using a common distribution. Because the information supplied by black-box model outputs is so sparse, we have to use additional perturbations when they are random, as in Ma et al. [
21], to enhance the adversarial effect on specific regions while reducing randomness of inappropriate values in significant positions. However, different from the baseline, we consider different concrete distributions that are smoother to highlight the attentional area and keep the original distribution working as previously. As Wu et al. [
40] conclude, the local oscillation of a loss surface can be suppressed by the smoothing effect. Our smoother distribution reduces harmful effects to the utmost and makes valid emphasis of attentional regions. Equations (
1) and (
2) show how the feature attentional boosting module works compared to a random normal distribution:
where
and
refer to the attack image in the current attack step and previous attack step, respectively,
represents the final adversarial perturbation in the current attack step,
is the original adversarial perturbation the baseline creates, and
is the additional adversarial perturbation belonging to another distribution we designed to strengthen the effect on the attentional region.
Momentum boosting replaces the original random normal distribution in attentional regions by an adversarial perturbation updating strategy based on momentum. This method takes both the descent direction achieved in the current attack step and all previous directions into consideration. By consulting these factors comprehensively, the additional adversarial perturbation emphasizes the adversarial effect in the attentional region and hastens the image-changing process. Equations (
3) and (
4) define the momentum boosting module in detail:
where
is the final momentum boosting adversarial perturbation added via the original random normal process, and parameter
controls the effect generated by the current adversarial perturbation direction
and the average direction
calculated from all previous adversarial perturbations; the value of
should be set in the range from zero to one.
The whole feature attentional boosting module (FABM) only works after visiting the black-box target model. As the adversarial perturbation direction obtained by the black-box target model is definitely correct, using this direction on attentional regions helps the adversarial attack succeed faster. If this module works at every stage of the attack, the total number of queries will increase instead. When the simulator model has not been fine-tuned well, it may give wrong directions for attentional module guidance. This would cause the adversarial model to require more queries to attack successfully.
3.2. Linear Self-Adaptive Simulator-Predict Interval Mechanism
While the simulator model acquired from meta-learning can imitate any model by finetuning itself in limited steps, the simulator model in its initial state is not well-prepared for coming queries. It still has a weak ability to give similar outputs to those of the black-box target at the early period. This leads to the fact that the first several queries to the simulator model might misdirect the changing of adversarial perturbations due to the difference between the two models, as shown in
Figure 3. Thus, the whole attack process may waste queries finding the right direction, which can make the query number reasonably large. To solve this problem, we design a linear self-adaptive simulator-predict interval mechanism (LISSIM) in our simulator attack. The mechanism is divided into two parts: a linear self-adaptive function guided by a gradually increasing parameter, and a threshold value to give a maximum to the simulator-predict interval. Equation (
5) describes this mechanism in detail.
where
is the final interval for every visit to the black-box target model,
refers to the upper bound value of the interval for whole attack process,
is the index of steps, and
is the adaptive factor we designed to control the pace of interval increases.
By using this mechanism, our simulator will have plenty of time to adjust itself to be more similar to the black-box target model. At the same time, adversarial perturbations also have enough opportunities to move further along in the appropriate direction precisely by visiting the black-box model with a high frequency during the beginning.
3.3. Unsupervised Clustering Module
Based on the usability of simulator model internal feature information, we add an unsupervised clustering module (UCM) as warm boot at the beginning to accelerate the whole simulator attack process. This module helps other images in the same clustering group quickly find adversarial perturbations based on the prior knowledge of clustering centers. We select a low-dimension feature clustering algorithm in this module. For the clustering mechanism, we focus on the distance between features extracted from simulator models and specific processes.
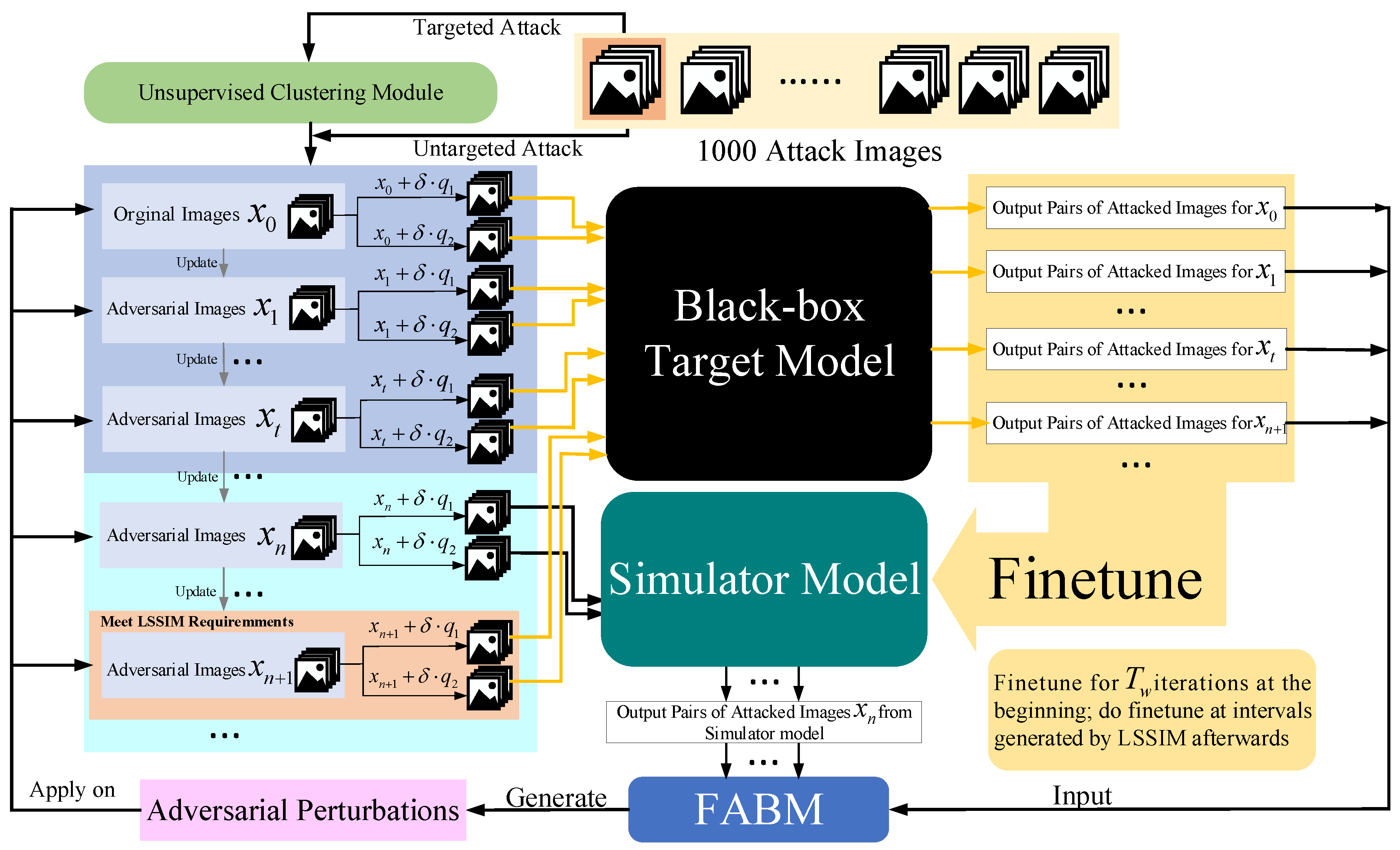
By applying an unsupervised clustering module to simulator attack, samples close to clustering centers rapidly finish their attack during the beginning of the attack process. Then we change the adversarial perturbation back to the initial state to achieve a cold boot for other unfinished images. Because these images are far from clustering centers, using prior knowledge will interference with their generating of correct adversarial perturbation. The whole process of Simulator Attack+ is exhibited in
Figure 4. Firstly, the generation of adversarial perturbations relies on the estimation of image general gradient direction by adding noise
and
.
If the attacker chooses to conduct a targeted attack, all the attack images are input into our unsupervised clustering module (UCM) to learn clustering center prior knowledge based on feature layer information. Otherwise, if the attacker chooses to conduct an untargeted attack, the attack images are immediately ready.
In the first steps, images visit the black-box target model to provide accurate information to finetune the pre-trained initial simulator model. Through this operation, our simulator model can gradually master the classification ability similar to that of the black-box target model and give precise results for any image input. When the step index meets the requirements of the interval value calculated by the linear self-adaptive simulator-predict interval mechanism (LSSIM), the attack images in the figure also visit the black-box target model in order to finetune the simulator model at a certain frequency. In the finetuning stage, influences making the simulator similar to the black-box target model. Further, other attack images such as query our finetuned simulator model for how to adjust the pixels.
The feature attentional boosting module (FABM) is utilized to enhance the adversarial effect of perturbations that are generated by the outputs of the two models. Such new perturbations are used to update the attack images from global and local perspectives in this iteration. Through constantly updating iterations, the attack images finally make the black-box target model unable to recognize them correctly. Additionally, the whole simulator attack is also shown in Algorithm 1.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}