

Dynamic Programming BN Structure Learning Algorithm Integrating Double Constraints under Small Sample Condition

Abstract
:1. Introduction
2. Theoretical Basis of Bayesian Network
3. BN Structure Learning Algorithm for Dynamic Programming Integrating Prior-Knowledge
3.1. Dynamic Programming Algorithm
3.2. Expression of Constraints
- means is the parent node of . means cannot be the parent node of . is used to express any edge constraint between and ;
- means is the ancestor node of . means cannot be an ancestor node of . In these two cases, is called a tail node and is a head node. is used to express any path constraint between and ;
- Suppose there is an arbitrary node order and constraint set in which and are consistent. If and only if for arbitrary , there is in , then cannot be an ancestor node of in .
3.3. Integrating Constraints of Edge
3.3.1. Pruning Node Order Graph
| Algorithm 1. Construction algorithm of node order graph. |
| Constructing Node Order Graph Based on Edge Constraint |
| Input: -Sparse parent node graph, -edge constraint graph Output: -Global optimal structure |
| 1. , , 2. 3. for each node In the do 4. 5. Removing variables of And their relative arcs in 6. Root variables of 7. for each variable do 8. 9. 10. if Is null 11. 12. else if > then 13. 14. end if 15. end for 16. end for 17. 18. end for 19. |
3.3.2. Construction and Query of Sparse Parent Node Graph
| Algorithm2. Construction algorithm of sparse parent node graph. |
| Constructing Sparse Parent Node Graph Based on Edge Constraint |
| Input: -set of all variables,-set of constraints,-decomposable score function value Output: -Sparse parent node graph |
| 1. for do 2. 3. for do 4. for each node Such that do 5. 6. if 7. 8. Append [scoreX, parentsX] with 9. end if 10. end for 11. end for 12. Sort with In descending 13. end for 14. return SPG ← [score., patrnts.] |
| Algorithm 3. Query algorithm of best parent node set. |
| The Optimal Parent Node Set Based on Query Constraints |
| Input: -set of all variables, -set of constraints, -sparse parent node graph Output: -The best parent node set, -The corresponding score |
| 1. 2. for each do 3. 4. end for 5. for each do 6. 7. end for 8. 9. return , |
3.4. Integrating Path Constraints
3.4.1. Pruning Node Order Graph
3.4.2. Construction and Query of Sparse Parent Node Graph
| Algorithm 4. Construction algorithm of sparse parent node graph. |
| Constructing Sparse Parent Node Graph Based on Path Constraints |
| Input:-set of all variables,-set of constraints,-decomposable score function value Output:-sparse parent node graph |
| 1.for do 2. if do 3. Construct Full Sparse Parent Graph (, , ) 4. else do 5. Construct Sparse Parent Graph without Constraints (, ) 6.. end if 7. end for 8. return 9. Function Construct Sparse Parent Graph without Constraints (, , ) 10. 11. for do 12. for each node such that do 13. 14. if 15. 16. append with 17. end if 18. end for 19. end for 20. sort with in descending 21. return 22. end function 23. Function Construct Full Sparse Parent Graph (, , ) 24. 25. for each do 26. Append with 27. end for 28. sort with in descending 29. return 30. end function |
| Algorithm 5. Query algorithm of best parent node set. |
| The Best Parent Node Set Based on the Path Constraint Query |
| Input: -set of all variables, set of path constraints, -sparse parent node graph Output: -the best parent node set, -the corresponding score |
| 1. 2. for each do 3. 4. end for 5. for each do 6. 7. for each Holding that in do 8. 9. 10. end for 11. 12. end for 13. for each do 14. for each Holding that in do 15. 16. end for 17. end for 18. 19. return |
4. Algorithm Simulation and Analysis
4.1. Validity Verification
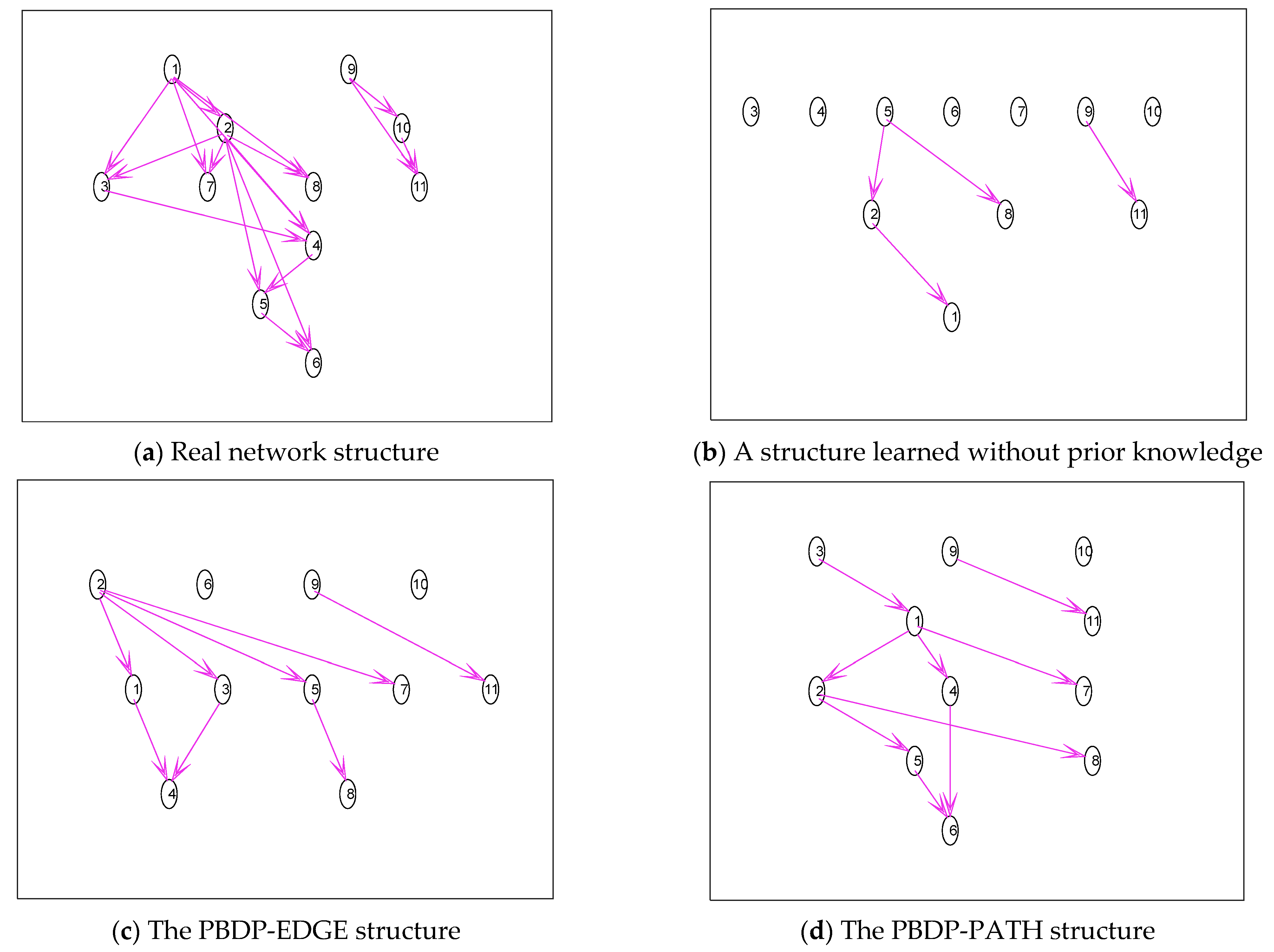
- 1.
- The simulation is carried out with the Asia network. All the edge prior knowledge is given, which is verified by the PBDP-EDGE structure. Part of the path prior knowledge is given, specifically , , , , , , and , which is verified by the PBDP-PATH structure. The results are shown in Figure 4.
- 2.
- The simulation is carried out with the Sachs network. Part of the edge prior knowledge is given, which is verified by the PBDP-EDGE structure. Part of the path prior knowledge is given, specifically , , , , , , , , , , and , which is verified by the PBDP-PATH structure. The results are shown in Figure 5.
- 3.
- The simulation is carried out with the Constructed network. Part of the edge prior knowledge is given, which is verified by the PBDP-EDGE structure. Part of the path prior knowledge is given, specifically , , , , , , , , , , , , , and , which is verified by the PBDP-PATH structure. The results are shown in Figure 6.
4.2. Complexity Verification
- The integrating edge constraint is simulated by the Halifinder network, a large-scaled network, and half of the real edges are randomly selected as prior knowledge. The training sample size is 200, 500, and 1000, respectively. Table 3 shows the simulation results. PBDP (Priors Based DP) indicates the integrating prior-knowledge method, which is measured in seconds. The space cost refers to the size of the array to be set, and the proportion represents the time and space ratio between the PBDP method and DP method.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann Press: San Mateo, CA, USA, 1988; pp. 1–15. [Google Scholar]
- Bueno, M.L.; Hommersom, A.; Lucas, P.J.; Lappenschaar, M.; Janzing, J.G.E. Understanding disease processes by partitioned dynamic Bayesian networks. J. Biomed. Inform. 2016, 61, 283–297. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Mahadevan, S. Bayesian network modeling of accident investigation reports for aviation safety assessment. Relib. Eng. Syst. Safe 2020, 209, 1–19. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; He, S.; Gu, X.; Yan, Z.F. Fault detection and diagnosis of chillers using Bayesian network merged distance rejection and multi-source non-sensor information. Appl. Energy 2017, 188, 200–214. [Google Scholar] [CrossRef]
- Shenton, W.; Hart, B.; Chan, T. Bayesian network models for environmental flow decision-making: 1. Latrobe River Australia. River Res. Appl. 2015, 27, 283–296. [Google Scholar] [CrossRef]
- Yu, K.; Liu, L.; Li, J.; Ding, W.; Le, T.D. Multi-Source Causal Feature Selection. IEEE Trans. Pattern Anal. Mach. Learn. 2020, 42, 2240–2256. [Google Scholar] [CrossRef] [PubMed]
- McLachlan, S.; Dube, K.; Fenton, N. Bayesian Networks in Healthcare: Distribution by Medical Condition. Artif. Intell. Med. 2020, 107, 101912. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.; Liu, Y. Target Recognition and Behavior Prediction based on Bayesian Network. Inter. J. Perform. Eng. 2019, 15, 1014–1022. [Google Scholar] [CrossRef]
- Sun, H.; Xie, X.; Sun, T.; Zhang, L. Threat assessment method for air defense targets of DBN fleet in the state of missing small sample data. Syst. Eng. Electron. 2019, 41, 1300–1308. [Google Scholar]
- Di, R.; Gao, X.g.; Guo, Z. Small data set BN modeling method and its application in threat assessment. Chin. J. Electron. 2016, 44, 1504–1511. [Google Scholar]
- Su, C.; Zhang, H. The introduction of human reliability in aircraft combat effectiveness evaluation. Acta Aeron Sin. 2006, 27, 262–266. [Google Scholar]
- Wu, Y.; Ren, Z. Mission reliability analysis of multiple-phased systems based on Bayesian network. In Proceedings of the IEEE 2014 Prognostics and System Health Management Conference, Zhangjiajie, China, 24–27 August 2014. [Google Scholar]
- Campos, C.; Ji, Q. Efficient Structure Learning of Bayesian Networks using Constraints. J. Mach. Learn. Res. 2011, 663–689. [Google Scholar]
- Cussens, J. Bayesian network learning with cutting planes. In Proceedings of the Twenty-Seventh Conference on Uncertainty in Artificial Intelligence, Barcelona, Spain, 14–17 July 2011. [Google Scholar]
- Jaakkola, T.; Sontag, D.; Globerson, A.; Meila, M. Learning Bayesian Network Structure using LP Relaxations. J. Mach. Learn. Res. 2010, 9, 358–365. [Google Scholar]
- Ott, S.; Imoto, S.; Miyano, S. Finding optimal models for small gene networks. Pac. Symp. Biocomput. 2004, 9, 557. [Google Scholar]
- Koivisto, M.; Sood, K. Exact Bayesian Structure Discovery in Bayesian Networks. J. Mach. Learn. Res. 2004, 5, 549–573. [Google Scholar]
- Angelopoulos, N.; Cussens, J. Bayesian learning of Bayesian networks with informative priors. Ann. Math. Artif. Intel. 2008, 54, 53–98. [Google Scholar] [CrossRef]
- Zhu, M.; Liu, S.; Wang, C. An optimization method based on prior node order learning Bayesian network structure. Acta Autom. Sin. 2011, 37, 1514–1519. [Google Scholar]
- Campos, L.; Castellanoa, J. Bayesian Network Learning Algorithms using Structural Restrictions. Int. J. Approx. Reason. 2007, 45, 233–254. [Google Scholar] [CrossRef]
- Nicholson, D.; Han, B.; Korb, K.B.; Alam, M.J.; Hope, L.R. Incorporating expert elicited structural information in the CaMML Causal Discovery Program. 2008. Available online: https://bridges.monash.edu/articles/report/Incorporating_Expert_Elicited_Structural_Information_in_the_CaMML_Causal_Discovery_Program/20365395 (accessed on 9 August 2022).
- Castelo, R.; Siebes, A. Priors on network structures. Biasing the search for Bayesian networks. Int. J. Approx. Reason. 2000, 24, 39–57. [Google Scholar] [CrossRef] [Green Version]
- Borboudakis, G.; Tsamardinos, I. Scoring and searching over Bayesian networks with causal and associative priors. In Proceedings of the 29th International Conference on Uncertainty in Artificial Intelligence, Washington, DC, USA, 12–14 July 2013. [Google Scholar]
- Parviainen, P.; Koivisto, M. Finding optimal Bayesian networks using precedence constraints. J. Mach. Learn. Res. 2013, 14, 1387–1415. [Google Scholar]
- Chen, E.; Shen, Y.; Choi, A.; Darwiche, A. Learning Bayesian networks with ancestral constraints. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Li, A.; Beek, P. Bayesian network structure learning with side constraints. In Proceedings of the 9th International Conference on Probabilistic Graphical Models, Prague, Czech, 11–14 September 2018. [Google Scholar]
- Bartlett, M.; Cussens, J. Integer linear programming for the Bayesian network structure learning problem. Artif. Intell. 2017, 244, 258–271. [Google Scholar] [CrossRef]
- Zhang, L.; Guo, H. Introduction to Bayesian Nets; Science Press: Beijing, China, 2006. [Google Scholar]
- Malone, B.; Yuan, C.; Hansen, E. Memory-Efficient Dynamic Programming for Learning Optimal Bayesian Networks. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1 | { } | |||||
| 2 | 5 | 4 | 3 | 2 | 1 | |
| 3 | 1 | 1 | 1 | 0 | 1 | |
| 4 | 0 | 1 | 1 | 0 | 0 | |
| 5 | 0 | 1 | 0 | 0 | 0 | |
| 6 | 1 | 0 | 1 | 0 | 0 | |
| 7 | Operation of | 0 | 1 | 1 | 0 | 0 |
| 8 | 1 | 0 | 1 | 1 | 1 | |
| 9 | 0 | 0 | 1 | 0 | 0 |
| 1 | { } | |||||
| 2 | 5 | 4 | 3 | 2 | 1 | |
| 3 | 0 | 0 | 0 | 0 | 0 | |
| 4 | 1 | 0 | 0 | 0 | 0 | |
| 5 | 0 | 0 | 1 | 0 | 1 | |
| 6 | 1 | 1 | 1 | 0 | 0 | |
| 7 | 0 | 0 | 1 | 0 | 1 | |
| 8 | 1 | 1 | 1 | 0 | 1 | |
| 9 | 0 | 0 | 1 | 0 | 1 |
| Sample Size | Approach | PBDP-EDGE | DP | Proportion |
|---|---|---|---|---|
| 200 | PIC Score | −670,352.217 | −696,271.251 | |
| Runtime | 3723.053 | 31,114.242 | 0.12 | |
| Space | 52,223 | 262143 | 0.199 | |
| 500 | PIC Score | −629,520.727 | −635,543.295 | |
| Runtime | 3141.870 | 31,925.566 | 0.098 | |
| Space | 52,223 | 262143 | 0.199 | |
| 1000 | PIC Score | −629,520.727 | −630,672.929 | |
| Runtime | 3218.295 | 30,909.447 | 0.104 | |
| Space | 52,223 | 262,143 | 0.199 |
| Sample Size | Approach | PBDP-PATH | DP | Proportion |
|---|---|---|---|---|
| 200 | PIC Score | −654,151.15 | −684,005.61 | |
| Runtime | 5486.113 | 29,359.588 | 0.187 | |
| Space | 44,159 | 262,143 | 0.168 | |
| 500 | PIC Score | −633,710.86 | −637,161.52 | |
| Runtime | 5035.867 | 29,785.541 | 0.169 | |
| Space | 44,159 | 262,143 | 0.168 | |
| 1000 | PIC Score | −629,561.51 | −630,698.96 | |
| Runtime | 5323.846 | 27,892.218 | 0.191 | |
| Space | 44,159 | 262,143 | 0.168 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, Z.; Chen, Y.; Di, R.; Wang, H.; Sun, X.; He, C.; Li, X. Dynamic Programming BN Structure Learning Algorithm Integrating Double Constraints under Small Sample Condition. Entropy 2022, 24, 1354. https://doi.org/10.3390/e24101354
Lv Z, Chen Y, Di R, Wang H, Sun X, He C, Li X. Dynamic Programming BN Structure Learning Algorithm Integrating Double Constraints under Small Sample Condition. Entropy. 2022; 24(10):1354. https://doi.org/10.3390/e24101354
Chicago/Turabian StyleLv, Zhigang, Yiwei Chen, Ruohai Di, Hongxi Wang, Xiaojing Sun, Chuchao He, and Xiaoyan Li. 2022. "Dynamic Programming BN Structure Learning Algorithm Integrating Double Constraints under Small Sample Condition" Entropy 24, no. 10: 1354. https://doi.org/10.3390/e24101354