Finite-Length Analyses for Source and Channel Coding on Markov Chains †


Abstract
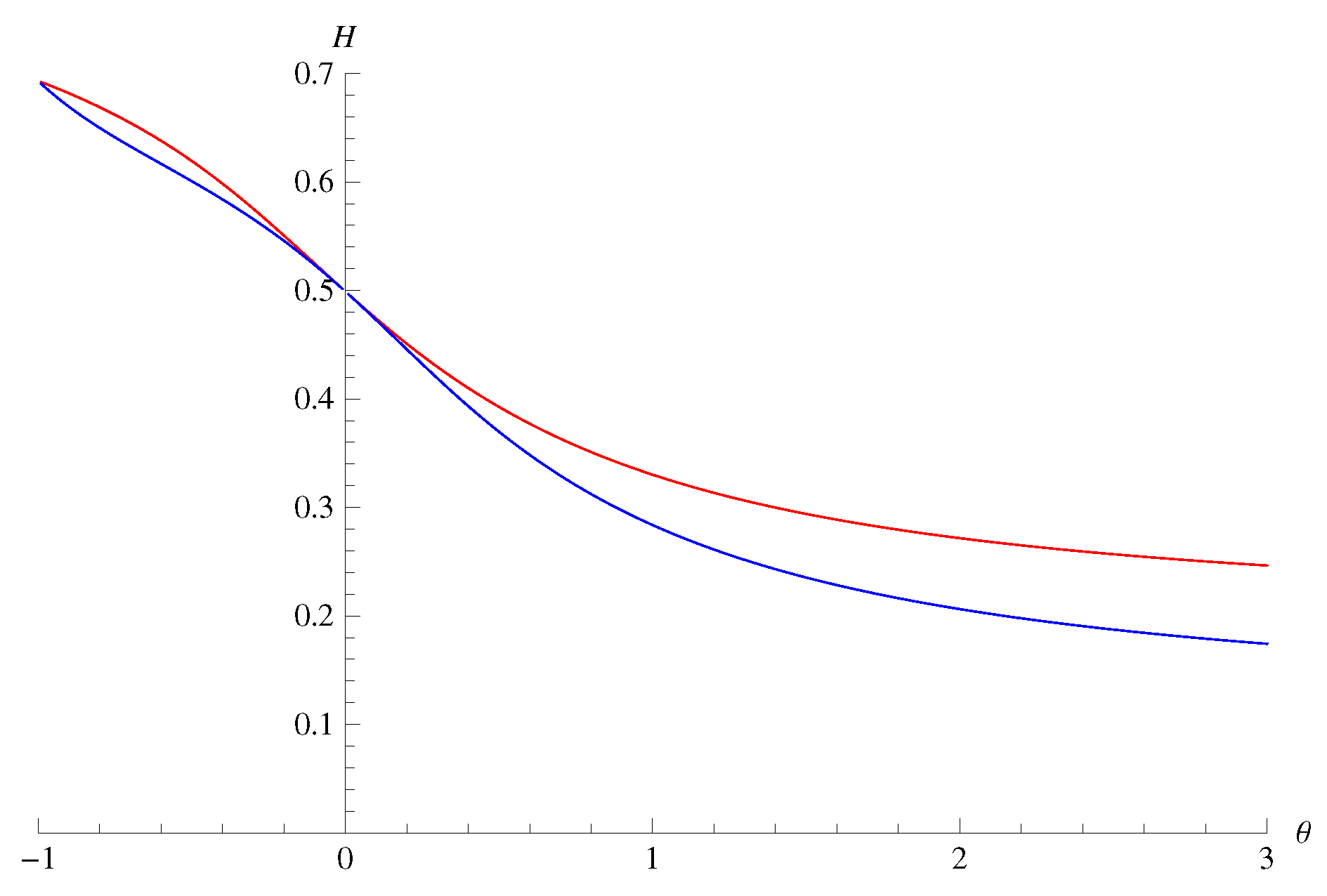
:1. Introduction
1.1. Two Aspects of Finite-Length Analysis
- (A1)
- Computational complexity for the bound and
- (A2)
- Asymptotic tightness for the bound.
- A large deviation regime in which the error probability asymptotically behaves as for some ;
- A moderate deviation regime in which asymptotically behaves as for some and ; and
- A second-order regime in which is a constant.
1.2. Main Contribution for Finite-Length Analysis
1.3. Main Contribution for Channel Coding
1.4. Asymptotic Bounds and Asymptotic Tightness for Finite-Length Bounds
1.5. Related Work on Markov Chains
1.6. Organization of the Paper
1.7. Notations
2. Information Measures
2.1. Information Measures for the Single-Shot Setting
- 1.
- For fixed , is a concave function of θ, and it is strict concave iff .
- 2.
- For fixed , is a monotonically decreasing (Technically, is always non-increasing, and it is monotonically decreasing iff strict concavity holds in Statement 1. Similar remarks are also applied for other information measures throughout the paper.) function of θ.
- 3.
- The function is a concave function of θ, and it is strict concave iff .
- 4.
- is a monotonically decreasing function of θ.
- 5.
- The function is a concave function of θ, and it is strict concave iff .
- 6.
- is a monotonically decreasing function of θ.
- 7.
- For every , we have .
- 8.
- For fixed , the function is a concave function of θ, and it is strict concave iff .
- 9.
- For fixed , is a monotonically decreasing function of θ.
- 10.
- We have:
- 11.
- We have:
- 12.
- For every , is maximized at .
2.2. Information Measures for the Transition Matrix
- 1.
- The function is a concave function of θ, and it is strict concave iff .
- 2.
- is a monotonically decreasing function of θ.
- 3.
- The function is a concave function of θ, and it is strict concave iff .
- 4.
- is a monotonically decreasing function of θ.
- 5.
- For every , we have .
- 6.
- For fixed , the function is a concave function of θ, and it is strict concave iff .
- 7.
- For fixed , is a monotonically decreasing function of θ.
- 8.
- We have:
- 9.
- We have:
- 10.
- For every , is maximized at , i.e.,
2.3. Information Measures for the Markov Chain
3. Source Coding with Full Side-Information
3.1. Problem Formulation
3.2. Single-Shot Bounds
3.3. Finite-Length Bounds for Markov Source
3.4. Second-Order
3.5. Moderate Deviation
3.6. Large Deviation
3.7. Numerical Example
3.8. Summary of the Results
4. Channel Coding
4.1. Formulation for the Conditional Additive Channel
4.1.1. Single-Shot Case
4.1.2. n-Fold Extension
4.2. Conversion from the Regular Channel to the Conditional Additive Channel
4.3. Conversion of the BPSK-AWGN Channel into the Conditional Additive Channel
4.4. Achievability Bound Derived by Source Coding with Side-Information
4.5. Converse Bound
4.6. Finite-Length Bound for the Markov Noise Channel
4.7. Second-Order
4.8. Moderate Deviation
4.9. Large Deviation
4.10. Summary of the Results
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| RCU | random coding union |
| BSC | binary symmetric channel |
| DMC | discrete memoryless channel |
| DT | dependence testing |
| LDPC | low-density parity check |
| BPSK | binary phase shift keying |
| AWGN | additive white Gaussian noise |
| CGF | cumulant generating function |
| MPSK | M-ary phase shift keying |
| CC | channel coding |
| SC | source coding |
| SI | side-information |
Appendix A. Preparation for the Proofs
Appendix A.1. Single-Shot Setting
Appendix A.2. Transition Matrix
Appendix A.3. Markov Chain
Appendix B. Relation Between CGF and Conditional Rényi Entropies
Appendix B.1. Single-Shot Setting
Appendix B.2. Transition Matrix
Appendix C. Proof of Lemma 2
Appendix D. Proof of Lemma 3
Appendix E. Proof of Lemma 4
Appendix F. Proof of Lemma 6
Appendix G. Proof of (63)
Appendix H. Proof of Lemma 7
Appendix I. Proof of Lemma 9
Appendix J. Proof of Lemma 11
Appendix K. Proof of Theorem 5
Appendix L. Proof of Theorem 16
References
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Verdú, S.; Han, T.S. A general fomula for channel capacity. IEEE Trans. Inform. Theory 1994, 40, 1147–1157. [Google Scholar] [CrossRef] [Green Version]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Hayashi, M.; Nagaoka, H. General formulas for capacity of classical-quantum channels. IEEE Trans. Inf. Theory 2003, 49, 1753–1768. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Renner, R. One-shot classical-quantum capacity and hypothesis testing. Phys. Rev. Lett. 2012, 108, 200501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gallager, R.G. A simple derivation of the coding theorem and some applications. IEEE Trans. Inf. Theory 1965, 11, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Polyanskiy, Y. Channel coding: Non-Asymptotic Fundamental Limits. Ph.D. Dissertation, Princeton University, Princeton, NJ, USA, November 2010. [Google Scholar]
- Tomamichel, M.; Hayashi, M. A hierarchy of information quantities for finite block length analysis of quantum tasks. IEEE Trans. Inform. Theory 2013, 59, 7693–7710. [Google Scholar] [CrossRef] [Green Version]
- Matthews, W.; Wehner, S. Finite blocklength converse bounds for quantum channels. IEEE Trans. Inf. Theory 2014, 60, 7317–7329. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons: Hoboken, NJ, USA, 1968. [Google Scholar]
- Hayashi, M. Information spectrum approach to second-order coding rate in channel coding. IEEE Trans. Inf. Theory 2009, 55, 4947–4966. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, M. Second-order asymptotics in fixed-length source coding and intrinsic randomness. IEEE Trans. Inf. Theory 2008, 54, 4619–4637. [Google Scholar] [CrossRef] [Green Version]
- Altug, Y.; Wagner, A.B. Moderate deviation analysis of channel coding: Discrete memoryless case. In Proceedings of the IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 265–269. [Google Scholar]
- He, D.; Lastras-Montano, L.A.; Yang, E.; Jagmohan, A.; Chen, J. On the redundancy of slepian-wolf coding. IEEE Trans. Inf. Theory 2009, 55, 5607–5627. [Google Scholar] [CrossRef]
- Tan, V.Y.F. Moderate-deviations of lossy source coding for discrete and gaussian sources. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 920–924. [Google Scholar]
- Kuzuoka, S. A simple technique for bounding the redundancy of source coding with side-information. In Proceedings of the 2012 IEEE International Symposium on Information Theory, Cambridge, MA, USA, 1–6 July 2012; pp. 915–919. [Google Scholar]
- Yang, E.; Meng, J. New nonasymptotic channel coding theorems for structured codes. IEEE Trans. Inf. Theory 2015, 61, 4534–4553. [Google Scholar] [CrossRef]
- Arimoto, S. Information measures and capacity of order α for discrete memoryless channels. In Colloquia Mathematica Societatis Janos Bolyai, 16. Topics in Information Theory; Elsevier: Amsterdam, The Netherlands, 1975; pp. 41–52. [Google Scholar]
- Hayashi, M. Exponential decreasing rate of leaked information in universal random privacy amplification. IEEE Trans. Inf. Theory 2011, 57, 3989–4001. [Google Scholar] [CrossRef] [Green Version]
- Teixeira, A.; Matos, A.; Antunes, L. Conditional Rényi entropies. IEEE Trans. Inf. Theory 2012, 58, 4273–4277. [Google Scholar] [CrossRef]
- Iwamoto, M.; Shikata, J. Information theoretic security for encryption based on conditional Rényi entropies. In Information Theoretic Security ICITS 2013; Padró, C., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 103–121. [Google Scholar]
- Hayashi, M.; Watanabe, S. Information geometry approach to parameter estimation in Markov chains. Ann. Stat. 2016, 44, 1495–1535. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, S.; Hayashi, M. Finite-length analysis on tail probability and simple hypothesis testing for Markov chain. Ann. Appl. Probab. 2017, 27, 811–845. [Google Scholar] [CrossRef] [Green Version]
- Wyner, A.D. Recent results in the shannon theory. IEEE Trans. Inf. Theory 1974, 20, 2–10. [Google Scholar] [CrossRef]
- Csiszár, I. Linear codes for sources and source networks: Error exponents, universal coding. IEEE Trans. Inf. Theory 1982, 28, 585–592. [Google Scholar] [CrossRef]
- Ahlswede, R.; Dueck, G. Good codes can be produced by a few permutations. IEEE Trans. Inf. Theory 1982, 28, 430–443. [Google Scholar] [CrossRef]
- Chen, J.; He, D.-K.; Jagmohan, A.; Lastras-Montano, L.A.; Yang, E. On the linear codebook-level duality between Slepian-Wolf coding and channel coding. IEEE Trans. Inf. Theory 2009, 55, 5575–5590. [Google Scholar] [CrossRef]
- Hayashi, M. Tight exponential analysis of universally composable privacy amplification and its applications. IEEE Trans. Inf. Theory 2013, 59, 7728–7746. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, E.N. Capacity of burst-noise for codes on burst-noise channels. Bell Syst. Tech. J. 1960, 39, 1253–1265. [Google Scholar] [CrossRef]
- Elliott, E.O. Estimates of error rates for codes on burst-noise channels. Bell Syst. Tech. J. 1963, 42, 1977–1997. [Google Scholar] [CrossRef]
- Delsarte, P.; Piret, P. Algebraic construction of shannon codes for regular channels. IEEE Trans. Inf. Theory 1982, 28, 593–599. [Google Scholar] [CrossRef]
- Tomamichel, M.; Tan, V.Y.F. Second-order coding rates for channels with state. IEEE Trans. Inf. Theory 2014, 60, 4427–4448. [Google Scholar] [CrossRef] [Green Version]
- Kemeny, J.G.; Snell, J. Finite Markov Chains; Springer: Berlin/Heidelberg, Germany, 1976. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; Wiley: Hoboken, NJ, USA, 1971. [Google Scholar]
- Tikhomirov, A.N. On the convergence rate in the central limit theorem for weakly dependent random variables. Theory Probab. Appl. 1980, 25, 790–890. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Meyn, P. Spectral theory and limit theorems for geometrically ergodic Markov processes. Ann. Appl. Probab. 2003, 13, 304–362. [Google Scholar] [CrossRef]
- Hervé, L.; Ledoux, J.; Patilea, V. A uniform Berry-Esseen theorem on m-estimators for geometrically ergodic Markov chains. Bernoulli 2012, 18, 703–734. [Google Scholar] [CrossRef]
- Watanabe, S.; Hayashi, M. Non-asymptotic analysis of privacy amplification via Rényi entropy and inf-spectral entropy. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 2715–2719. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Davisson, L.D.; Longo, G.; Sgarro, A. The error exponent for the noiseless encoding of finite ergodic Markov sources. IEEE Trans. Inform. Theory 1981, 27, 431–438. [Google Scholar] [CrossRef]
- Vašek, K. On the error exponent for ergodic Markov source. Kybernetika 1980, 16, 318–329. [Google Scholar]
- Zhong, Y.; Alajaji, F.; Campbell, L.L. Joint source-channel coding error exponent for discrete communication systems with Markovian memory. IEEE Trans. Inf. Theory 2007, 53, 4457–4472. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Poor, H.V.; Verdu, S. Dispersion of the Gilbert-Elliott channel. IEEE Trans. Inf. Theory 2011, 57, 1829–1848. [Google Scholar] [CrossRef] [Green Version]
- Kontoyiannis, I. Second-order noiseless source coding theorems. IEEE Trans. Inform. Theory 1997, 43, 1339–1341. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Verdú, S. Optimal lossless data compression: Non-asymptotic and asymptotics. IEEE Trans. Inf. Theory 2014, 60, 777–795. [Google Scholar] [CrossRef]
- Scarlett, J.; Martinez, A.; Fábregas, A.G.i. Mismatched decoding: Error exponents, second-order rates and saddlepoint approximations. IEEE Trans. Inform. Theory 2014, 60, 2647–2666. [Google Scholar] [CrossRef] [Green Version]
- Scarlett, J.; Martinez, A.; i Fabregas, A.G. The saddlepoint approximation: A unification of exponents, dispersions and moderate deviations. arXiv 2014, arXiv:1402.3941. [Google Scholar]
- Ben-Ari, I.; Neumann, M. Probabilistic approach to Perron root, the group inverse, and applications. Linear Multilinear Algebra 2010, 60, 39–63. [Google Scholar] [CrossRef]
- Lalley, S.P. Ruelle’s Perron-Frobenius theorem and the central limit theorem for additive functionals of one-dimensional Gibbs states. Adapt. Stat. Proced. Relat. Top. 1986, 8, 428–446. [Google Scholar]
- Kato, T. Perturbation Theory for Linear Operators; Springer: New York, NY, USA, 1980. [Google Scholar]
- Häggström, O.; Rosenthal, J.S. On the central limit theorem for geometrically ergodic markov chains. Electron. Commun. Probab. 2007, 12, 454–464. [Google Scholar]
- Kipnis, C.; Varadhan, S.R.S. Central limit theorem for additive functionals of reversible markov processes and applications to simple exclusions. Commun. Math. Phys. 1986, 104, 1–19. [Google Scholar] [CrossRef]
- Komorowski, C.L.T.; Olla, S. Fluctuations in Markov Processes: Time Symmetry and Martingale Approximation; Springer: Berlin, Germany, 2012. [Google Scholar]
- Meyn, S.P.; Tweedie, R.L. Markov Chains and Stochastic Stability; Springer: London, UK, 1993. [Google Scholar]
- Jones, G.L. On the Markov chain central limit theorem. Probab. Surv. 2004, 1, 299–320. [Google Scholar] [CrossRef]
- Tomamichel, M.; Berta, M.; Hayashi, M. Relating different quantum generalizations of the conditional Rényi entropy. J. Math. Phys. 2014, 55, 082206. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, M. Large deviation analysis for classical and quantum security via approximate smoothing. IEEE Trans. Inf. Theory 2014, 60, 6702–6732. [Google Scholar] [CrossRef]
- Csiszár, I. Generalized cutoff rates and Rényi’s information measures. IEEE Trans. Inf. Theory 1995, 41, 6–34. [Google Scholar] [CrossRef]
- Polyanskiy, Y.; Verdú, S. Arimoto channel coding converse and Rényi divergence. In Proceedings of the 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Allerton, IL, USA, 29 September–1 October 2010; pp. 1327–1333. [Google Scholar]
- Hayashi, M.; Watanabe, S. Uniform random number generation from Markov chains: Non-asymptotic and asymptotic analyses. IEEE Trans. Inform. Theory 2016, 62, 1795–1822. [Google Scholar] [CrossRef] [Green Version]
- Kemeny, J.G.; Snell, J.L. Finite Markov Chains; Springer: New York, NY, USA, 1960. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Express: Cambridge, UK, 1985. [Google Scholar]
- Wegman, M.N.; Carter, J.L. New hash functions and their use in authentication and set equality. J. Comput. Syst. Sci. 1981, 22, 265–279. [Google Scholar] [CrossRef] [Green Version]
- Gallager, R.G. Source coding with side-information and universal coding. Proc. IEEE Int. Symp. Inf. Theory 1976. Available online: http://web.mit.edu/gallager/www/papers/paper5.pdf (accessed on 5 April 2020).
- Hayashi, M. Quantum Information: An Introduction; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Renner, R.; Wolf, S. Simple and tight bound for information reconciliation and privacy amplification. In Advances in Cryptology – ASIACRYPT 2005; ser. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 199–216. [Google Scholar]
- Billingsley, P. Probability and Measure; JOHN WILEY & SONS: Hoboken, NJ, USA, 1995. [Google Scholar]
- Cover, T. A proof of the data compression theorem of Slepian and Wolf for ergodic sources. IEEE Trans. Inf. Theory 1975, 21, 226–228. [Google Scholar] [CrossRef] [Green Version]
- Dembo, A.; Zeitouni, O. Large Deviations Techniques and Applications, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Hayashi, M. Error exponent in asymmetric quantum hypothesis testing and its application to classical-quantum channel coding. Phys. Rev. A 2007, 76, 062301. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, M. Security analysis of ε-almost dual universal2 hash functions. IEEE Trans. Inf. Theory 2016, 62, 3451–3476. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem | First-Order | Large Deviation | Moderate Deviation | Second-Order |
|---|---|---|---|---|
| SC with SI | Solved (Ass. 1) | (Ass. 2) | Solved (Ass. 1), | Solved (Ass. 1) |
| Tail | ||||
| CC for Conditional | Solved (Ass. 1) | (Ass. 2) | Solved (Ass. 1) | Solved (Ass. 1) |
| Additive Channels | Tail |
| Ach./Conv. | Markov | Single-Shot | / | Complexity | Large Deviation | Moderate Deviation | Second Order |
|---|---|---|---|---|---|---|---|
| Achievability | Theorem 6 (Ass. 1) | Lemma 15 | 🗸 | ||||
| Theorem 9 (Ass. 2) | Lemma 14 | 🗸 | 🗸 | ||||
| Theorem 7 (No-side) | Lemma 16 | 🗸 | 🗸 | ||||
| Lemma 13 | Tail | 🗸 | 🗸 | ||||
| Converse | Theorem 8 (Ass. 1) | (Theorem 5) | 🗸 | ||||
| Theorem 10 (Ass. 2) | Corollary 1 | 🗸 | 🗸 | ||||
| Theorem 8 (No-side) | (Theorem 5) | 🗸 | 🗸 | ||||
| Lemma 18 | Tail | 🗸 | 🗸 | ||||
| Ach./Conv. | Markov | Single-Shot | / | Complexity | Large Deviation | Moderate Deviation | Second Order |
|---|---|---|---|---|---|---|---|
| Achievability | Theorem 17 (Ass. 1) | Lemma 22 | 🗸 | ||||
| Theorem 19 (Ass. 2) | Lemma 21 | 🗸 | 🗸 | ||||
| Theorem 21 (Additive) | Lemma 23 | 🗸 | 🗸 | ||||
| Lemma 20 | Tail | 🗸 | 🗸 | ||||
| Converse | Theorem 18 (Ass. 1) | (Theorem 16) | 🗸 | ||||
| Theorem 20 (Ass. 2) | Theorem 16 | 🗸 | 🗸 | ||||
| Theorem 18 (Additive) | (Theorem 16) | 🗸 | 🗸 | ||||
| Lemma 25 | Tail | 🗸 | 🗸 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayashi, M.; Watanabe, S. Finite-Length Analyses for Source and Channel Coding on Markov Chains. Entropy 2020, 22, 460. https://doi.org/10.3390/e22040460
Hayashi M, Watanabe S. Finite-Length Analyses for Source and Channel Coding on Markov Chains. Entropy. 2020; 22(4):460. https://doi.org/10.3390/e22040460
Chicago/Turabian StyleHayashi, Masahito, and Shun Watanabe. 2020. "Finite-Length Analyses for Source and Channel Coding on Markov Chains" Entropy 22, no. 4: 460. https://doi.org/10.3390/e22040460