Input Pattern Classification Based on the Markov Property of the IMBT with Related Equations and Contingency Tables

Abstract
:1. Introduction
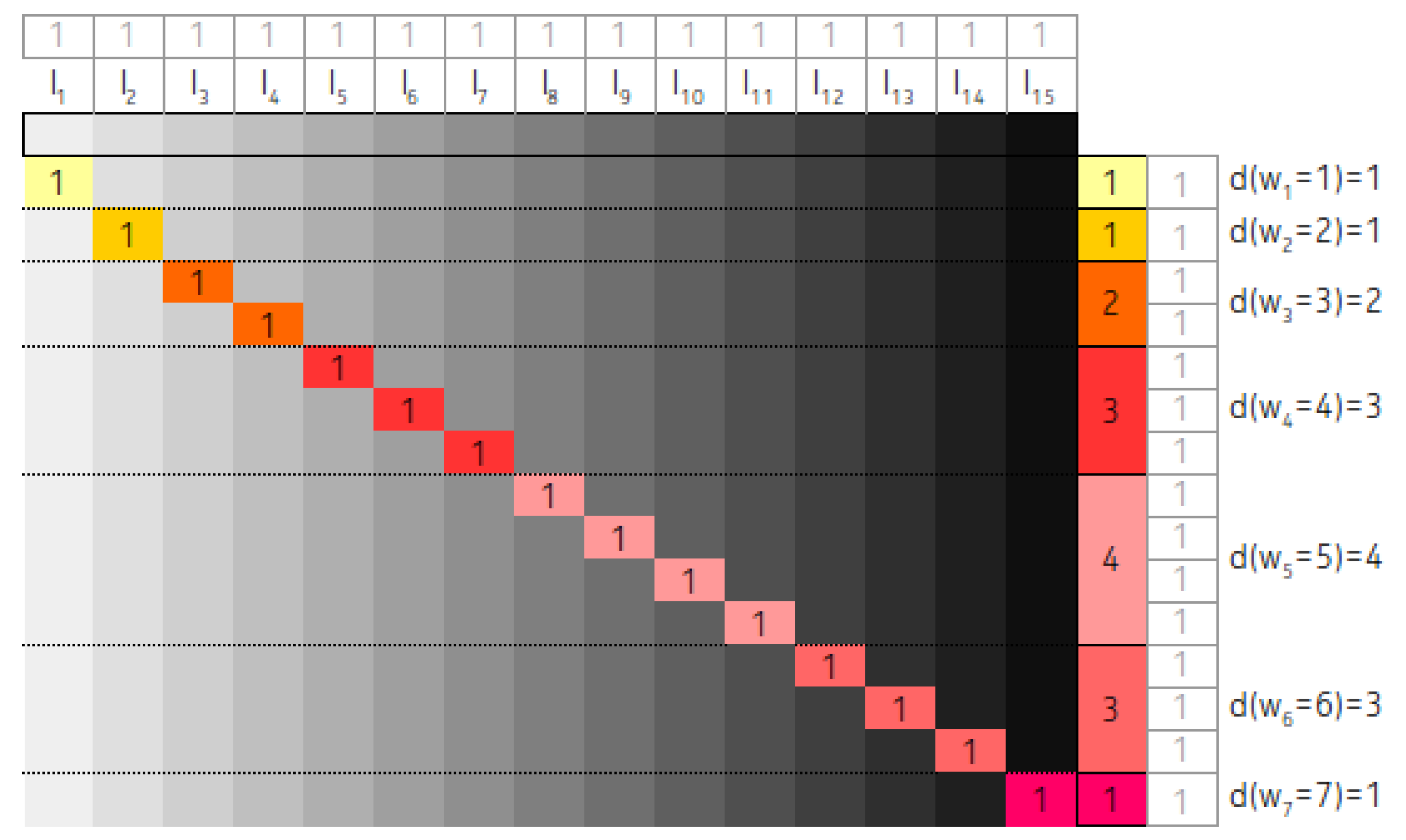
2. Interval Merging Binary Tree and Contingency Table
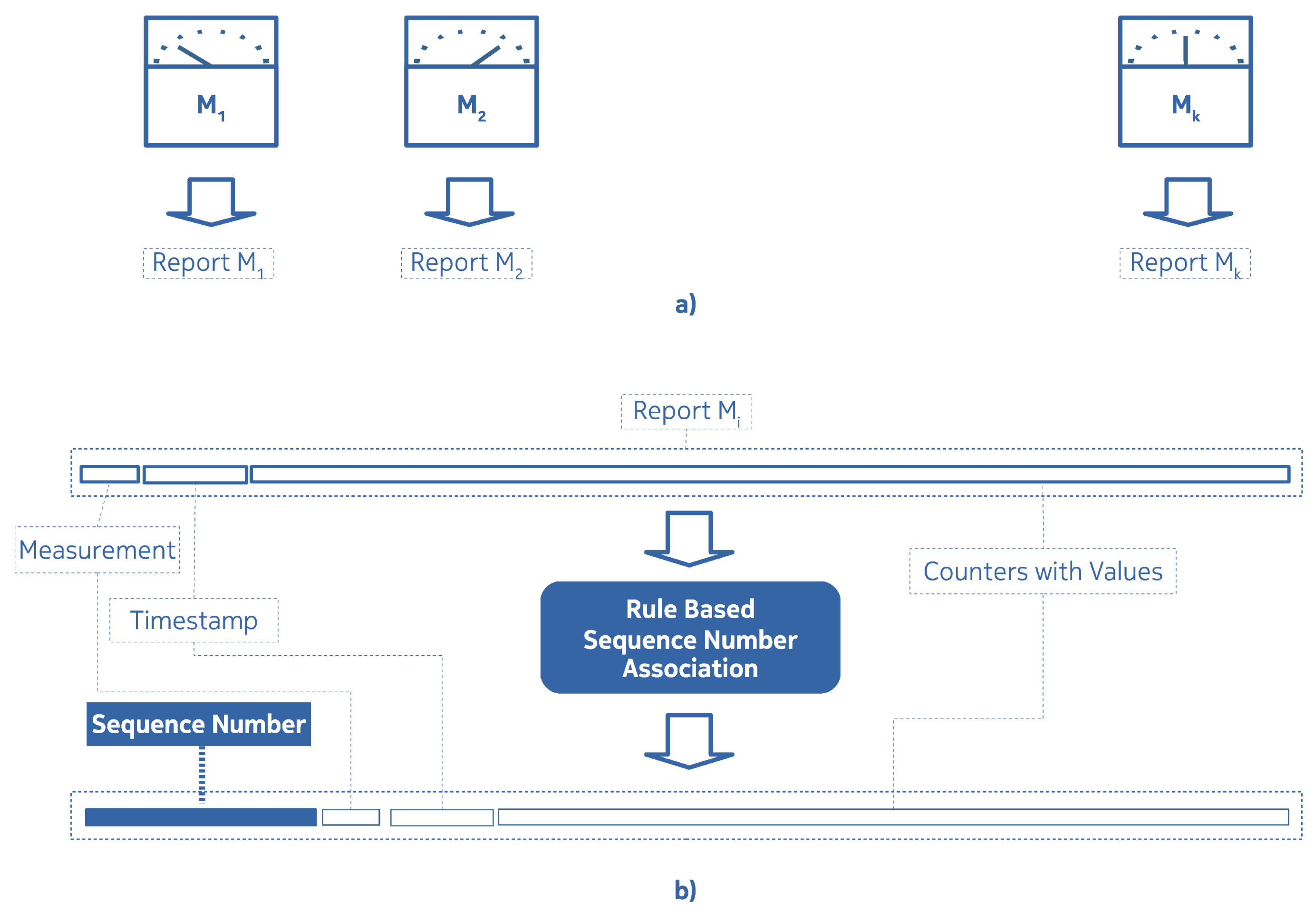
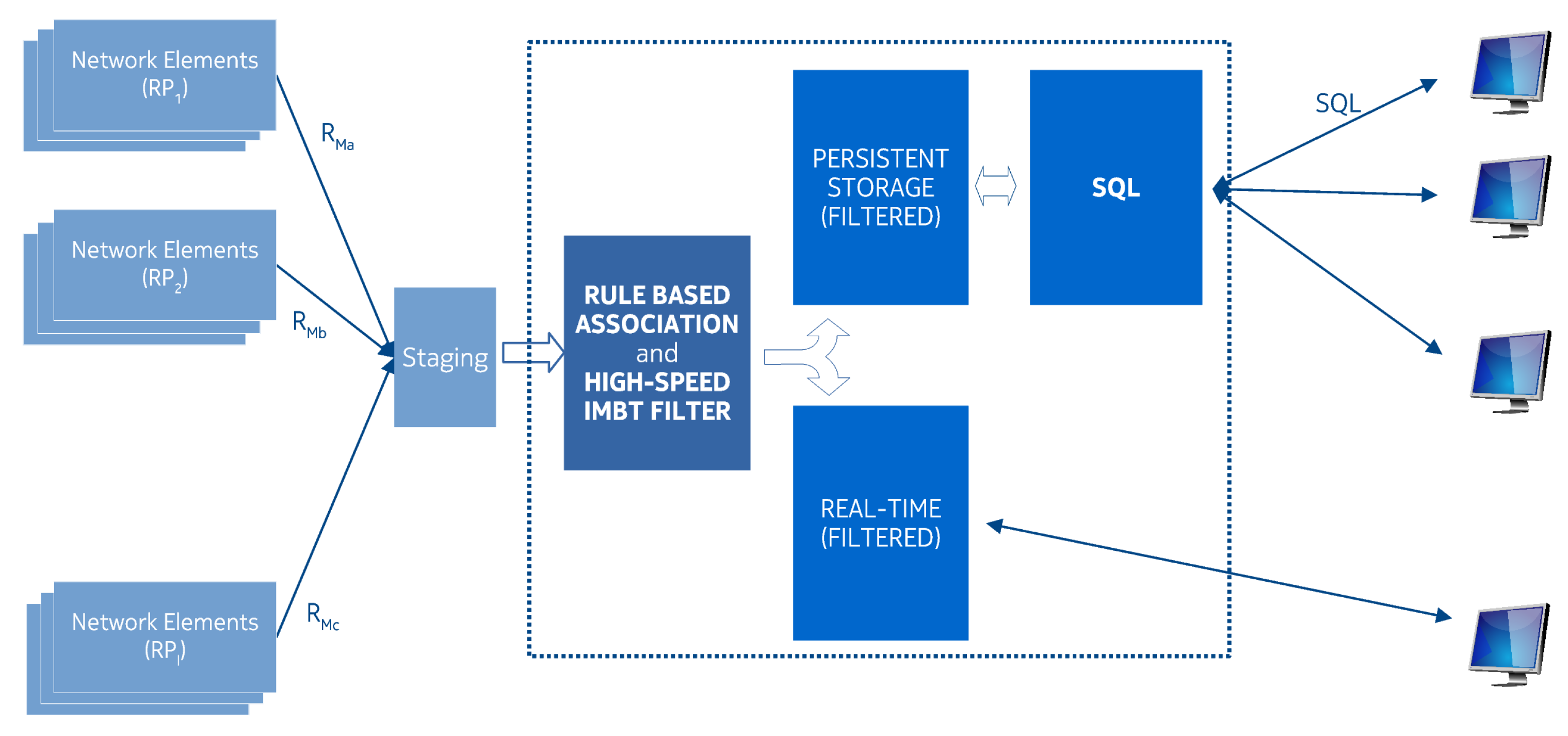
2.1. The Data Processing Environment and the Motivation Behind IMBT
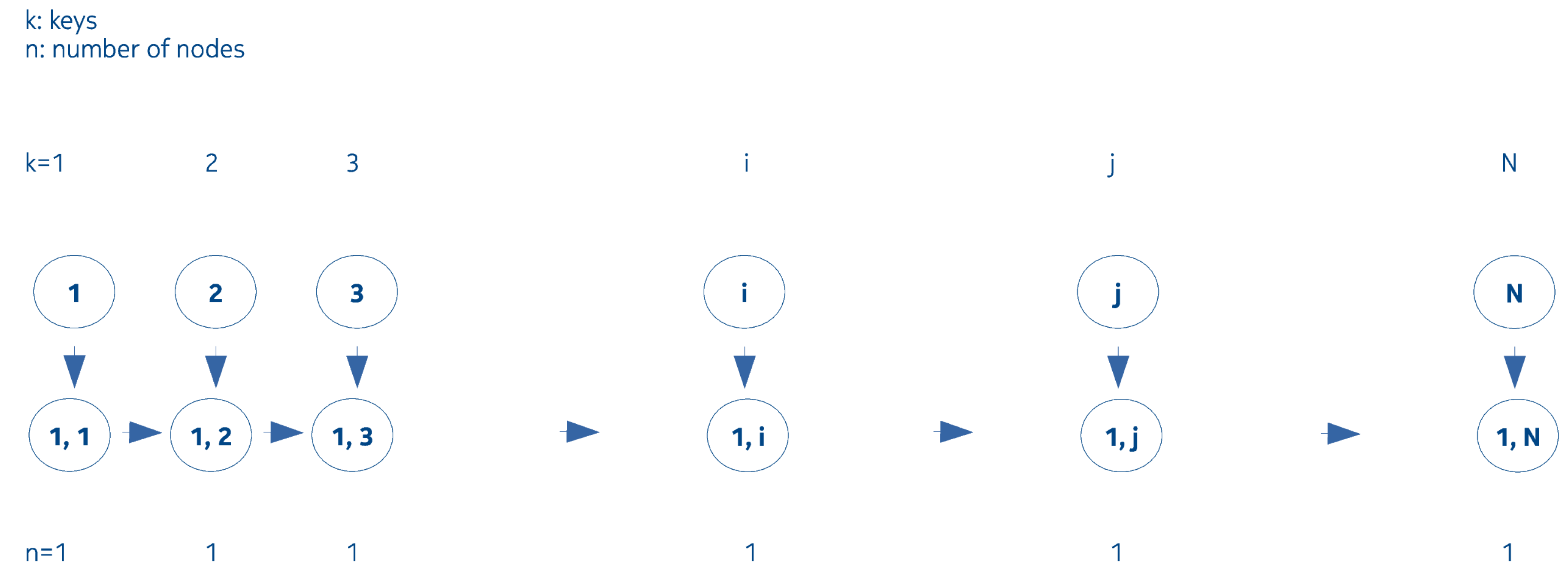
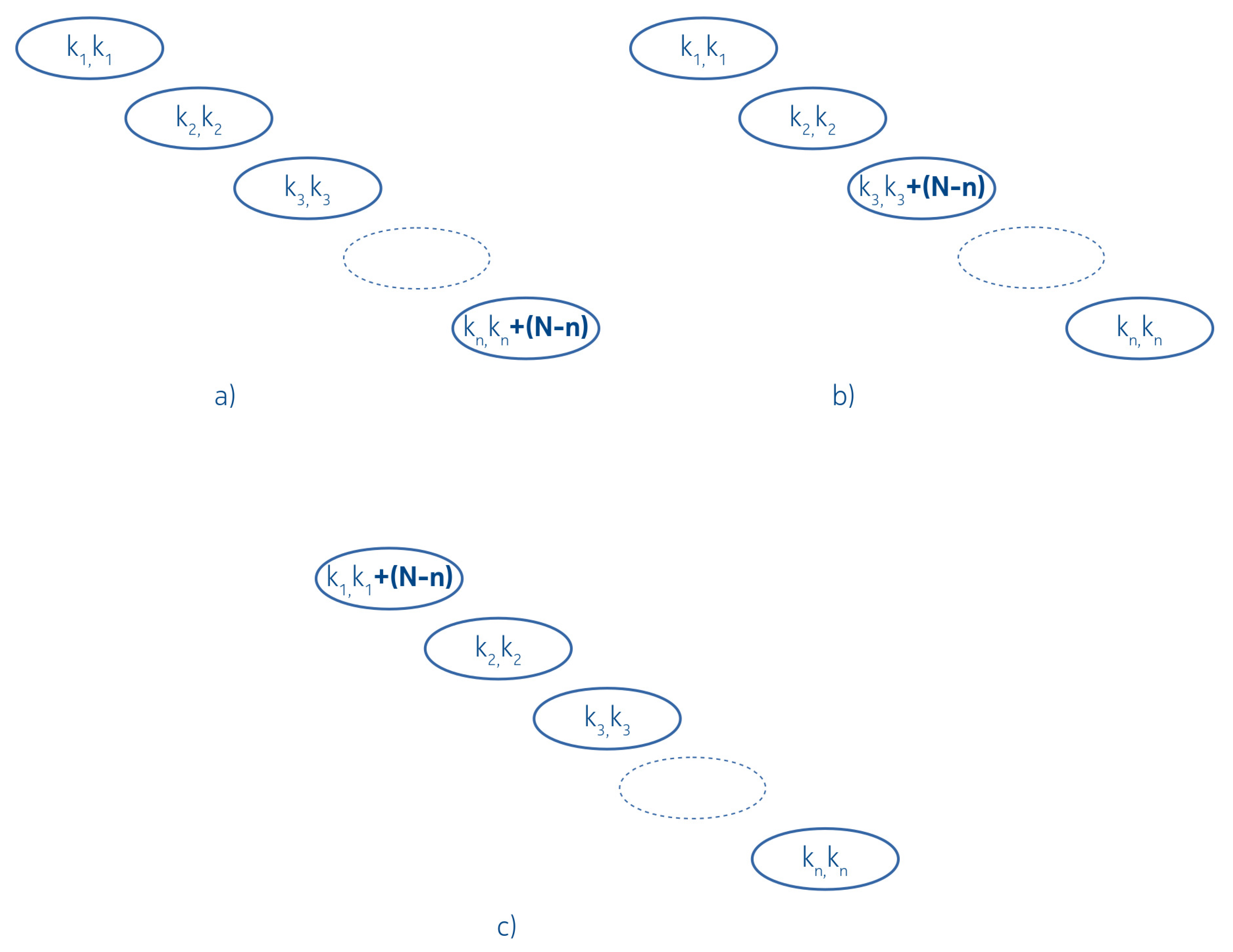
2.2. Interval Merging Binary Tree
- None of the keys are neighbors of each other,
- Two of them are neighbors and the other two are not,
- Two of them are neighbors and the remaining two are neighbors as well,
- Three of them are neighbors and one is not,
- All the keys are neighbors of each other.
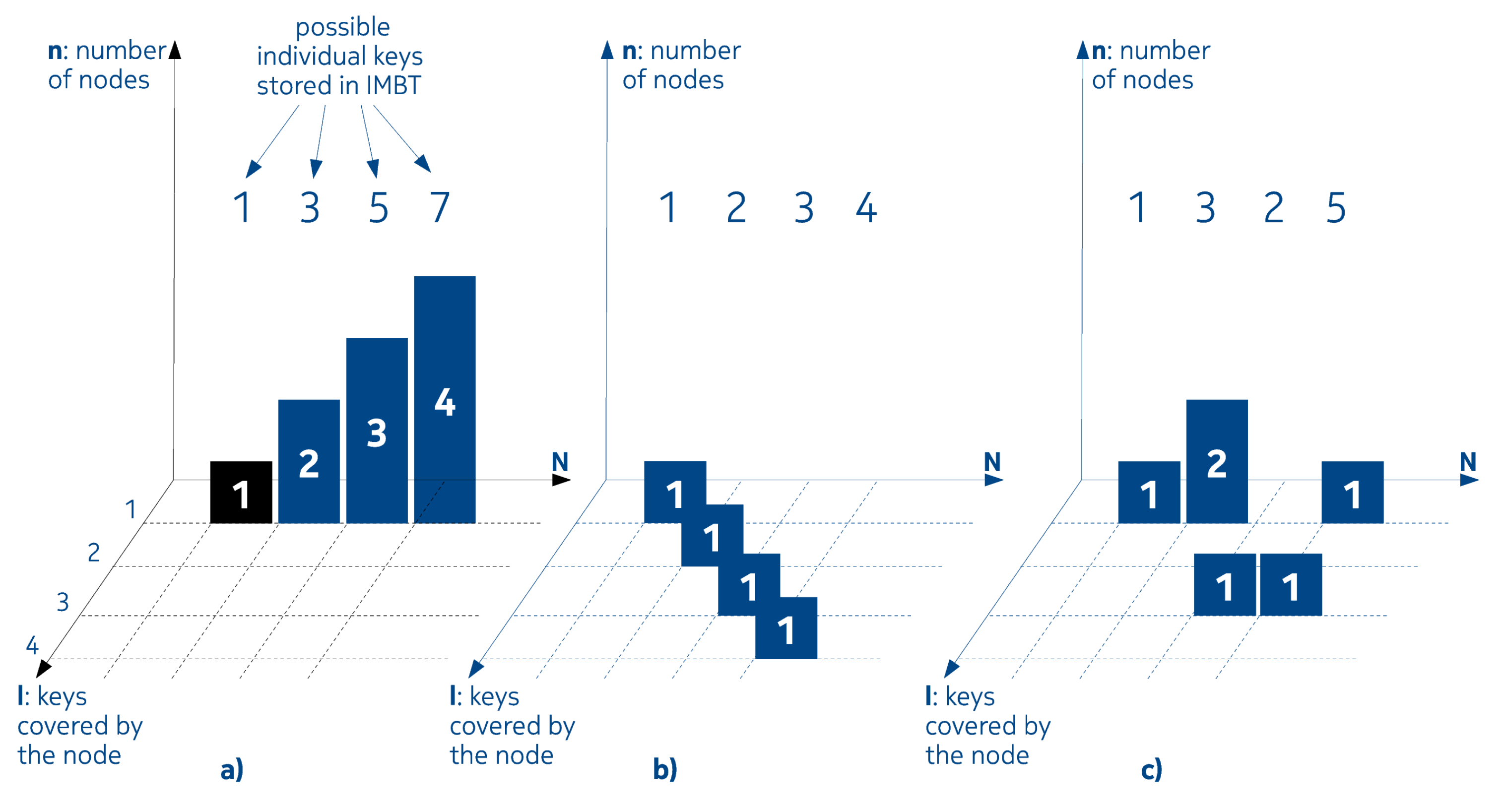
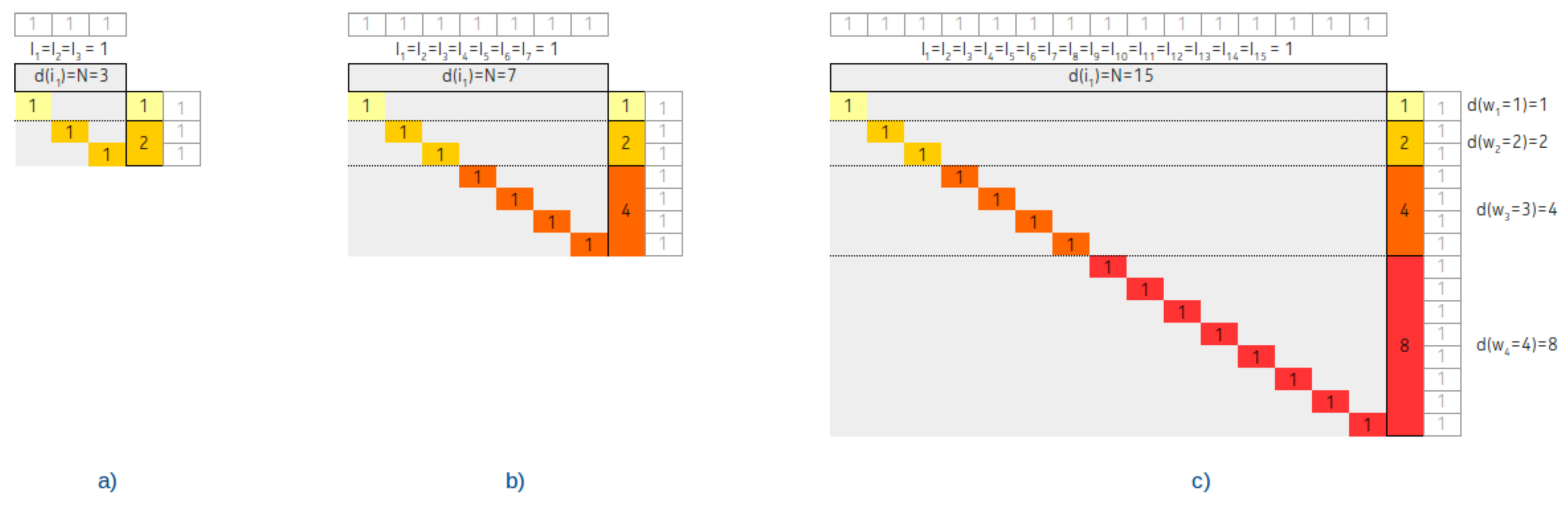
2.3. The Role of Contingency Tables on the Analysis of IMBT
3. Arrangements Related Conditions, Theorems, and Equations
- There is an expected value a, to which the individual random variables, , stochastically converge to as N tends to infinity, where ….
- There is a … independently from N, where is the standard deviation of the interval lengths at time instant i.
- There is a non-negative function for which …, and additionally , .
- In the first case only a nonrecurring, transient, infinite state stochastic matrix can be composed based on the associated states . Additionally we assume that the Bernstein-theorem is true for the series of ,
- In the second case, we assume that based on the state , it is possible to create a stochastic matrix which has a finite state-space, is aperiodic, irreducible (that is ergodic), and recurrent.
3.1. Permanent Gaps
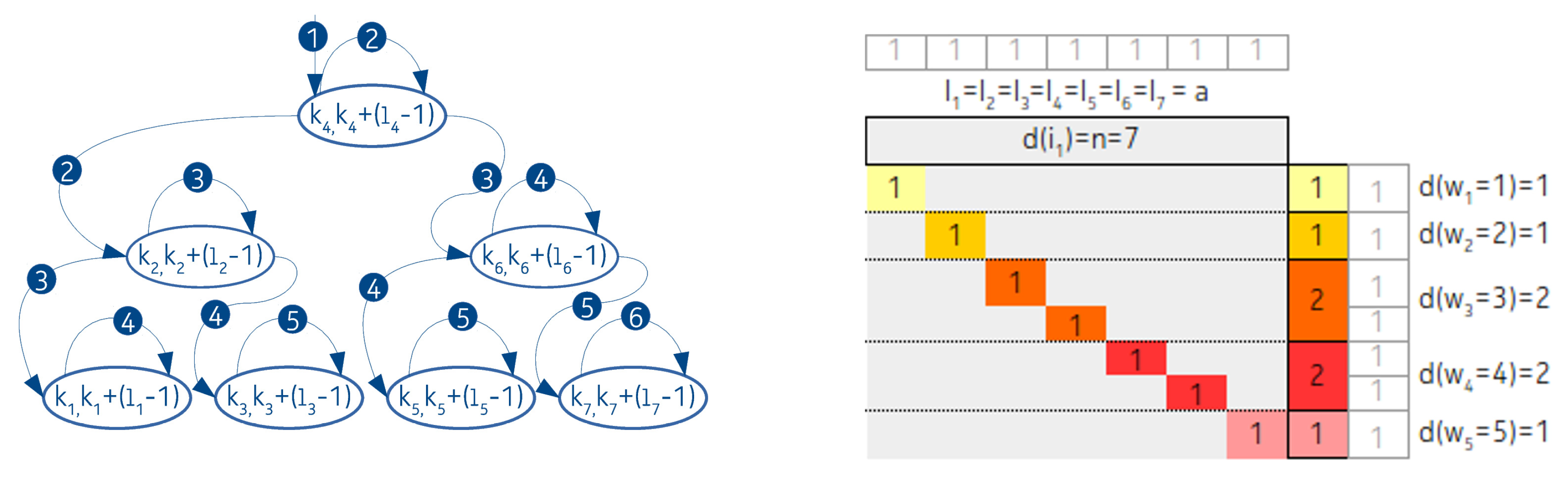
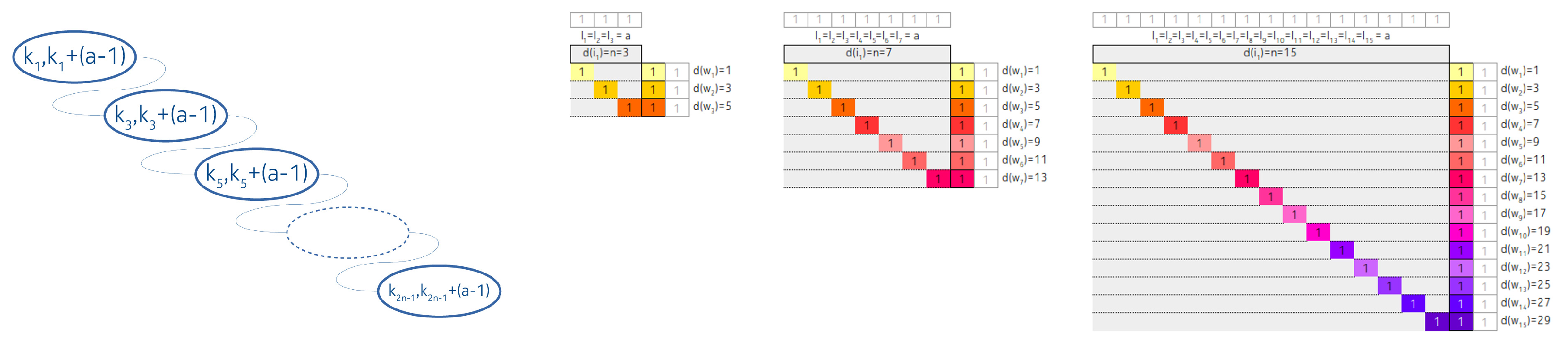
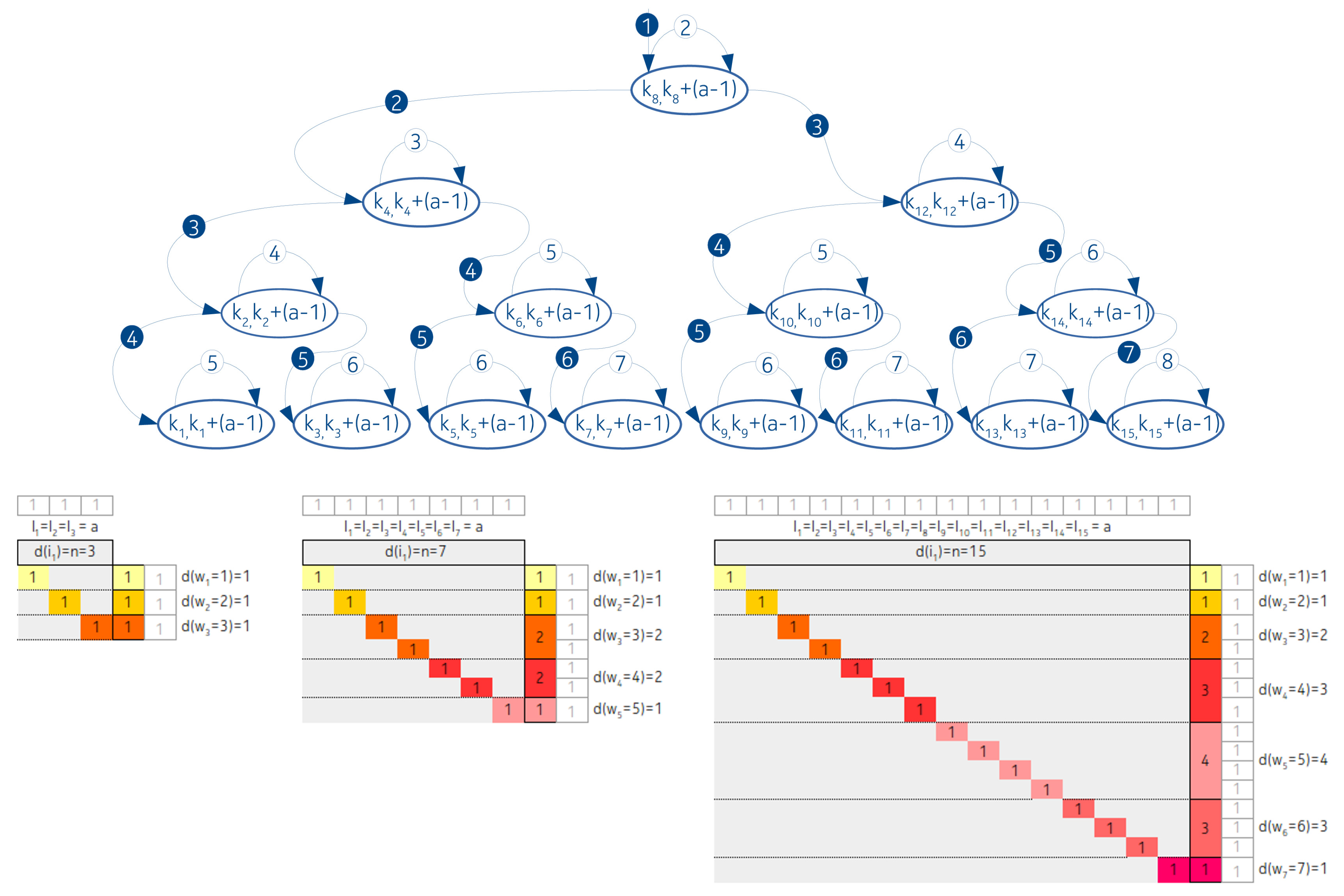
3.1.1. Linked List Arrangement
3.1.2. Completely Balanced Arrangement
3.2. Temporary Gaps Only
- In the first realization we suppose that the increasing interval lengths are uniformly distributed to nodes, the number of which is fixed.
- In the second realization the distribution is not uniform.
3.2.1. Linked List Like Arrangement
3.2.2. Completely Balanced Arrangement
- The increasing lengths of intervals are uniformly distributed across the tree,
- The distribution of lengths follows an exponential distribution.
3.2.3. An Exception: Completely Balanced Arrangement, Temporary Gaps, Infinite Nodes, and Increasing Average
- -
- Any key can be the subject of the search operation with equal probability,
- -
- The key is already in the tree.
4. Proofs and Deductions
4.1. Permanent Gaps
4.1.1. Linked List Arrangement
4.1.2. Completely Balanced Arrangement
4.2. Temporary Gaps Only
4.2.1. Linked List Arrangement
4.2.2. Completely Balanced Arrangement
5. Evaluations and Simulations
5.1. Evaluations
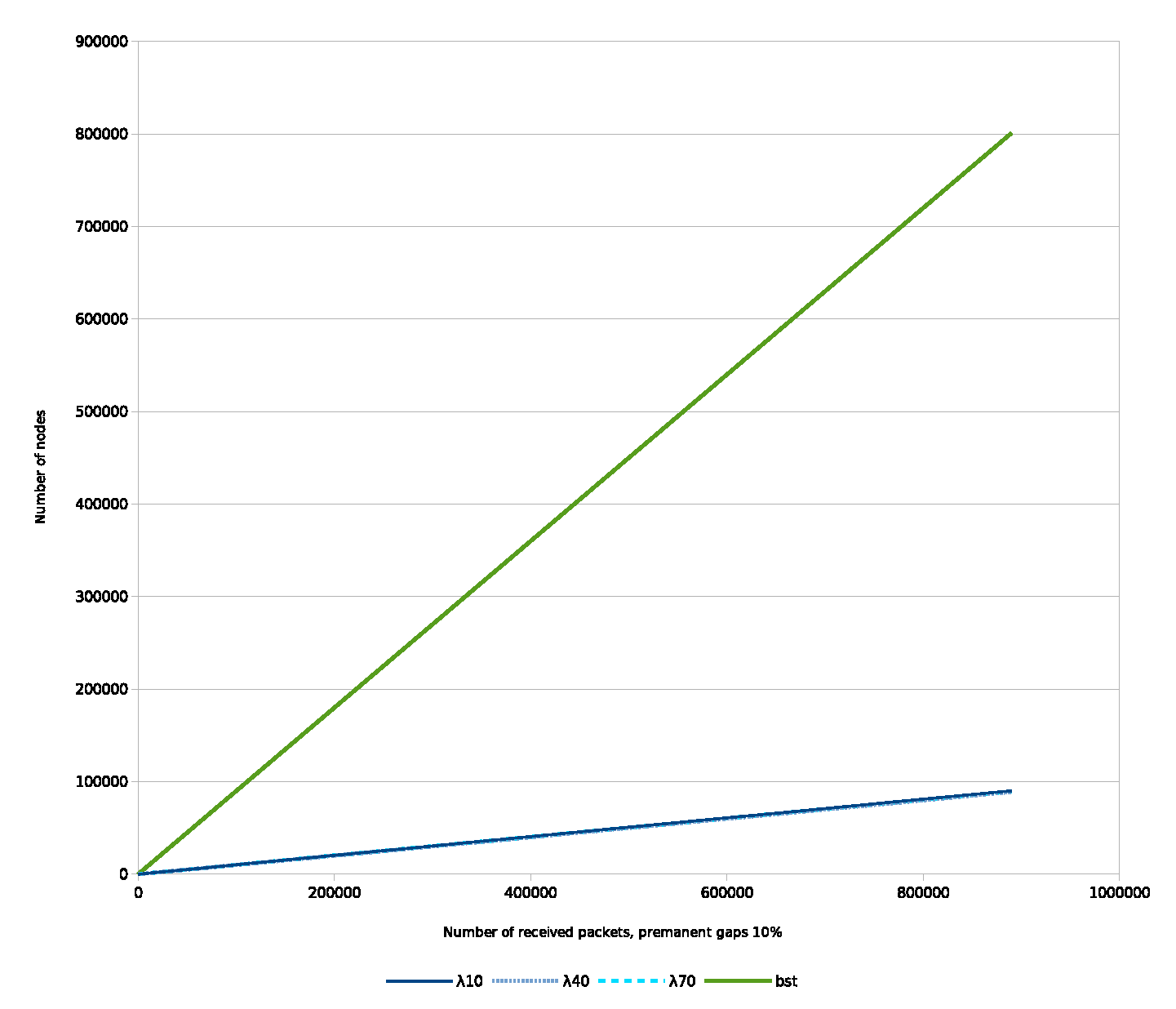
5.1.1. Permanent Gaps
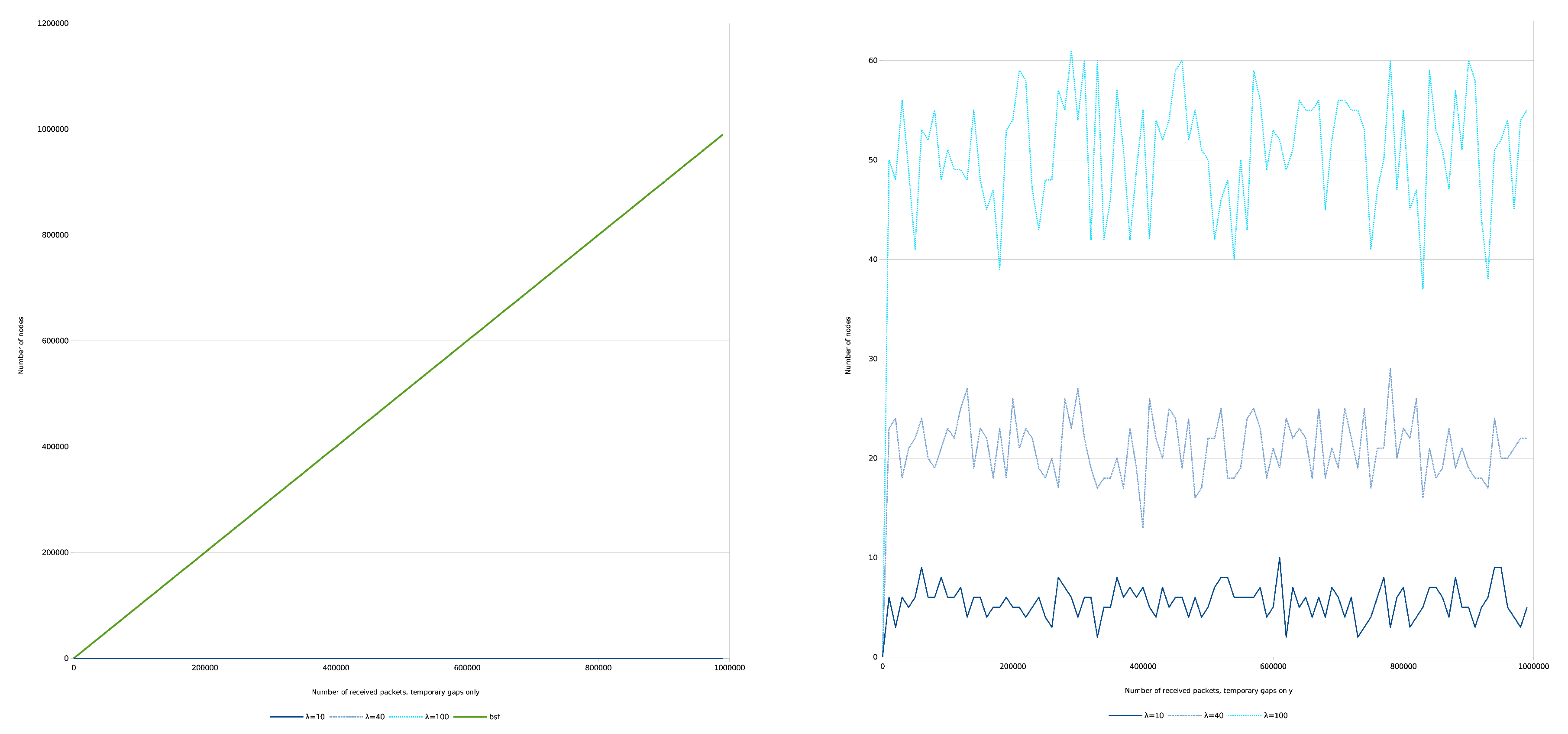
5.1.2. Temporary Gaps Only
5.2. Simulations
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; MIT Press and McGraw-Hill: London, UK, 2009; ISBN 0-262-03384-4. [Google Scholar]
- Stoica, I.; Morris, R.; Liben-Nowell, D.; Karger, D.R.; Kaashoek, M.F.; Dabek, F.; Balakrishnan, H. Chord: A Scalable Peer-to-peer Lookup Protocol for Internet Applications. IEEE/ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar] [CrossRef]
- Finta, I.; Farkas, L.; Sergyán, S.; Szénási, S. Interval Merging Binary Tree. In Proceedings of the ICA3PP 2017, Helsinki, Finland, 21–23 August 2017. [Google Scholar] [CrossRef]
- Finta, I.; Élias, G.; Illés, J. Packet Loss and Duplication Handling in Stream Processing Environment. In Proceedings of the CINTI 2018, Budapest, Hungary, 21–22 Novermber 2018. [Google Scholar] [CrossRef]
- STORM—A Distributed Real-Time Computation System. Available online: http://storm.apache.org/documentation/Home.html (accessed on 28 November 2019).
- Finta, I.; Szénási, S. State-space Analysis of the Interval Merging Binary Tree. Acta Polytech. Hung. 2019, 16, 71–85. [Google Scholar] [CrossRef]
- Adelson-Velsky, G.; Landis, E. An algorithm for the organization of information. In Doklady Akademii Nauk; Russian Academy of Sciences: Moscow, Russia, 1962; pp. 263–266. [Google Scholar]
- Bayer, R. Symmetric binary B-Trees: Data structure and maintenance algorithms. Acta Inform. 1972, 1, 290–306. [Google Scholar] [CrossRef]
- Lauritzen, S.L. Lectures on Contingency Tables, 2002, Electronic edition, Aalborg University. Available online: http://www.stats.ox.ac.uk/~steffen/papers/cont.pdf (accessed on 28 November 2019).
- Barvionk, A. Enumerating Contingency Tables via Random Permanents. Comb. Probab. Comput. 2008, 17, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Barvinok, A.; Luria, A.; Samorodnitsky, A.; Yong, A. An approximation algorithm for counting contingency tables. Random Struct. Algorithms 2010, 37, 25–66. [Google Scholar] [CrossRef] [Green Version]
- Chung, K.L. Markov Chains with Stationary Transition Probabilities; Springer: Berlin/Heidelberg, Germany, 1960. [Google Scholar]
- Meyn, S.P.; Tweedie, R.L. Markov Chains and Stochastic Stability; Springer: London, UK, 2012; ISBN 9781447132677. [Google Scholar]
- Bernstein, S.N. Theory of Probabilities. Moskva/Leningrad, Russia, 1946. [Google Scholar]
- Doukhan, P.; Louhichi, S. A new weak dependence condition and applications to moment inequalities. Stoch. Process. Their Appl. 1999, 84, 313–342. [Google Scholar] [CrossRef] [Green Version]
- Lawder, J.; King, P. Querying Multi-dimensional Data Indexed Using Hilbert Space-Filling Curve. ACM Sigmod Rec. 2000, 30, 19–24. [Google Scholar] [CrossRef]
- Bóna, M. A Walk Through Combinatorics: An Introduction to Enumeration and Graph Theory; World Scientific Publishing: Singapore, 2002; pp. 145–164. ISBN 981-02-4900-4. [Google Scholar]
- Hardy, G.H.; Ramanujan, S. Asymptotic Equatione in Combinatory Analysis. Proc. Lond. Math. Soc. 1918, 2, 75–115. [Google Scholar] [CrossRef]
- Sleator, D.D.; Tarjan, R.E. Self-Adjusting Binary Search Trees. J. ACM 1985, 32, 652–686. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Keys | Number of Nodes | Space Complexity | Search Operation Time Complexity (Average) | Search Operation Time Complexity (Worst Case) | |
|---|---|---|---|---|---|
| AVL Balanced BST | N | ||||
| Splay tree | N | ||||
| Hash | N | ||||
| IMBT-LLD | N | ||||
| IMBT-B | N |
| Number of Keys | Number of Nodes | Space Complexity | Search Operation Time Complexity (Average) | Search Operation Time Complexity (Worst Case) | |
|---|---|---|---|---|---|
| AVL Balanced BST | N | ||||
| Splay tree | N | ||||
| Hash | N | ||||
| Middle node-heavy IMBT-LLD | N | = | = | = | |
| IMBT-B | N | = | = | = |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Finta, I.; Szénási, S.; Farkas, L. Input Pattern Classification Based on the Markov Property of the IMBT with Related Equations and Contingency Tables. Entropy 2020, 22, 245. https://doi.org/10.3390/e22020245
Finta I, Szénási S, Farkas L. Input Pattern Classification Based on the Markov Property of the IMBT with Related Equations and Contingency Tables. Entropy. 2020; 22(2):245. https://doi.org/10.3390/e22020245
Chicago/Turabian StyleFinta, István, Sándor Szénási, and Lóránt Farkas. 2020. "Input Pattern Classification Based on the Markov Property of the IMBT with Related Equations and Contingency Tables" Entropy 22, no. 2: 245. https://doi.org/10.3390/e22020245