A SOM-Based Membrane Optimization Algorithm for Community Detection

Abstract
:1. Introduction
- The SOM neural network may learn and mine the structure of the current objects in the decision space, which is beneficial for guiding the local and global search of the proposed algorithm;
- The number of membranes of the proposed EMCD-SOM is determined according to the characteristics of SOM mapping similar data to adjacent neurons.
- GA and DE are employed as reaction rules to evolve the objects in the different region of membrane;
- The proposed EMCD-SOM can implement the balance of exploration and exploitation in four real world networks.
2. The Proposed Approach
| Algorithm 1 The pseudo-code of the proposed EMCD-SOM. |
Input: The parameters of the proposed algorithm are initialized, including the number of objects in each elementary membrane, each object within its boundaries. |
Output: The best object is found from the different elementary membranes. |
1: The objects are initialized from the search space. |
2: The fitness of these objects is calculated according to the modularity density function in Equation (3). |
3: while End Condition do |
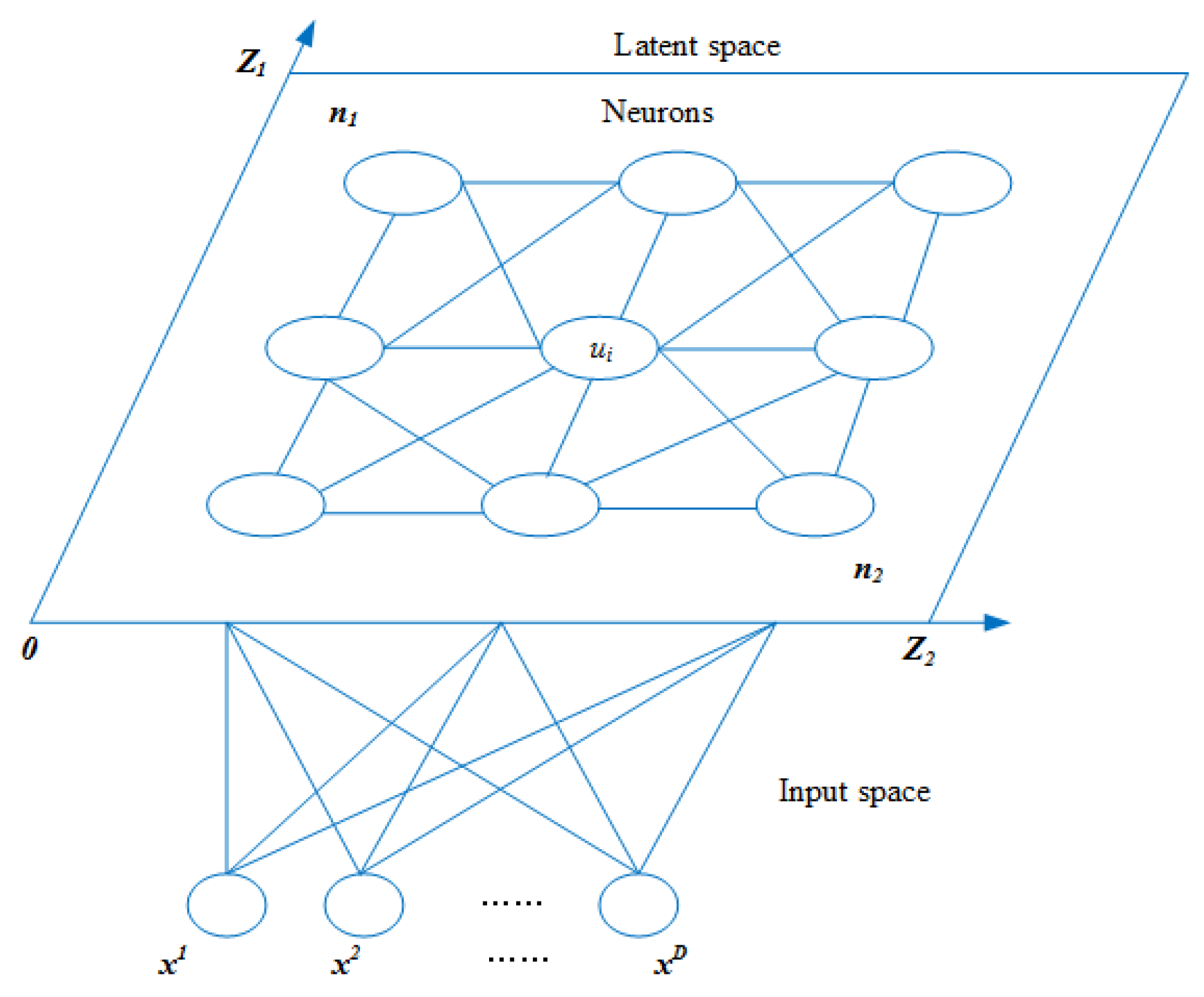
4: Determining the number of membrane (NC) by invoking SOM |
5: for i = 1; i < NC; i++ do |
6: Evolving the objects in the region of elementary membrane according to the DE-based reaction rule. |
7: end for |
8: The objects from the region of elementary membrane are released into the region of skin membrane. |
9: All objects in the region of skin membrane are evolved according to the GA-based reaction rule. |
10: end while |
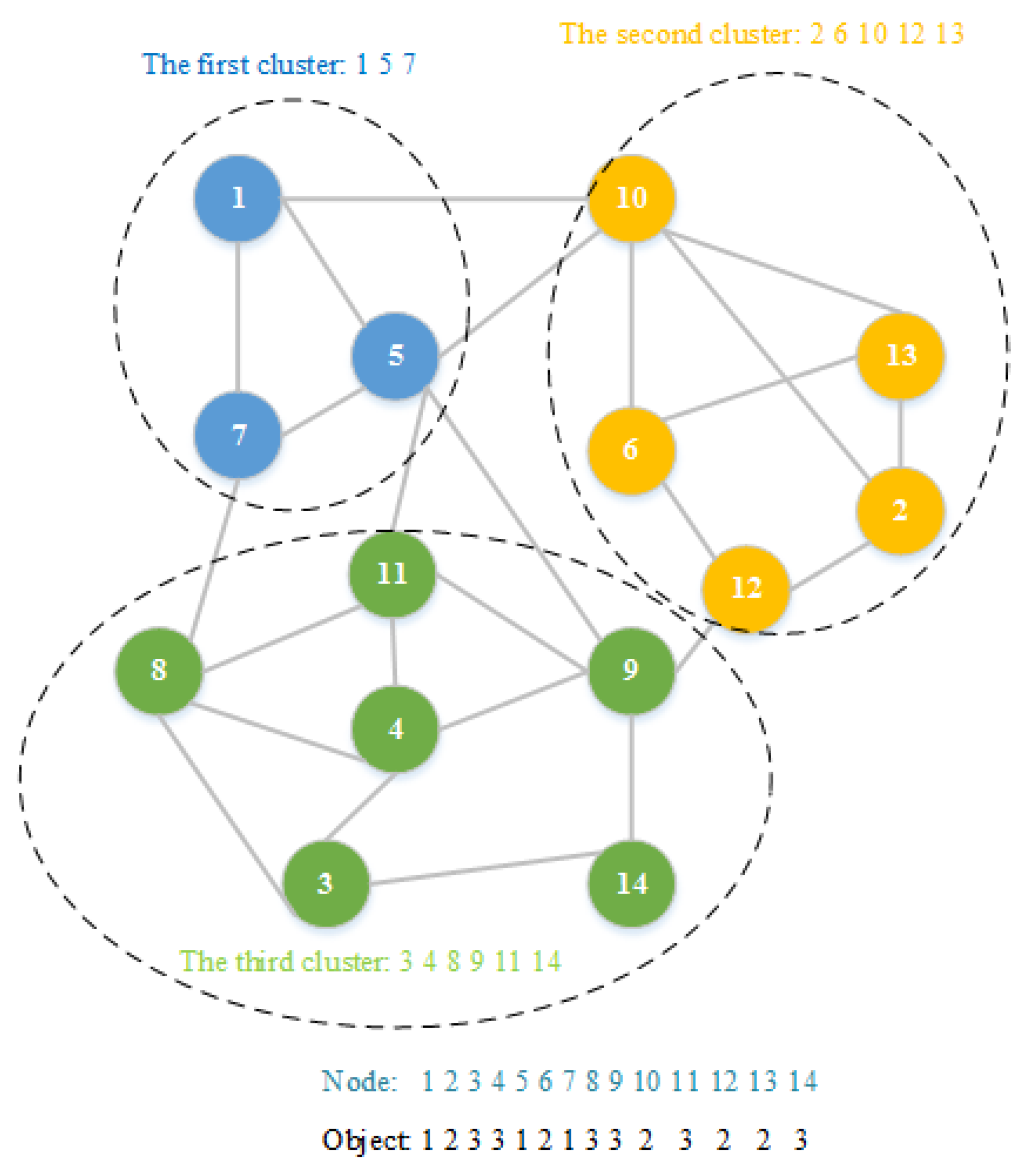
2.1. Object and Its Initialization
2.2. Objective Function
2.3. Membrane Structure
2.4. Reaction Rules
3. Experimental Evaluation
3.1. Synthetic Benchmark Networks and Four Real-World Networks
3.1.1. Description of Synthetic Benchmark Betworks
3.1.2. Description of Four Real-World Networks
3.2. Experimental Conditions
3.3. Evaluation Measures
3.4. Experiments on Synthetic Benchmark Networks
3.5. Experiments on Real-World Networks
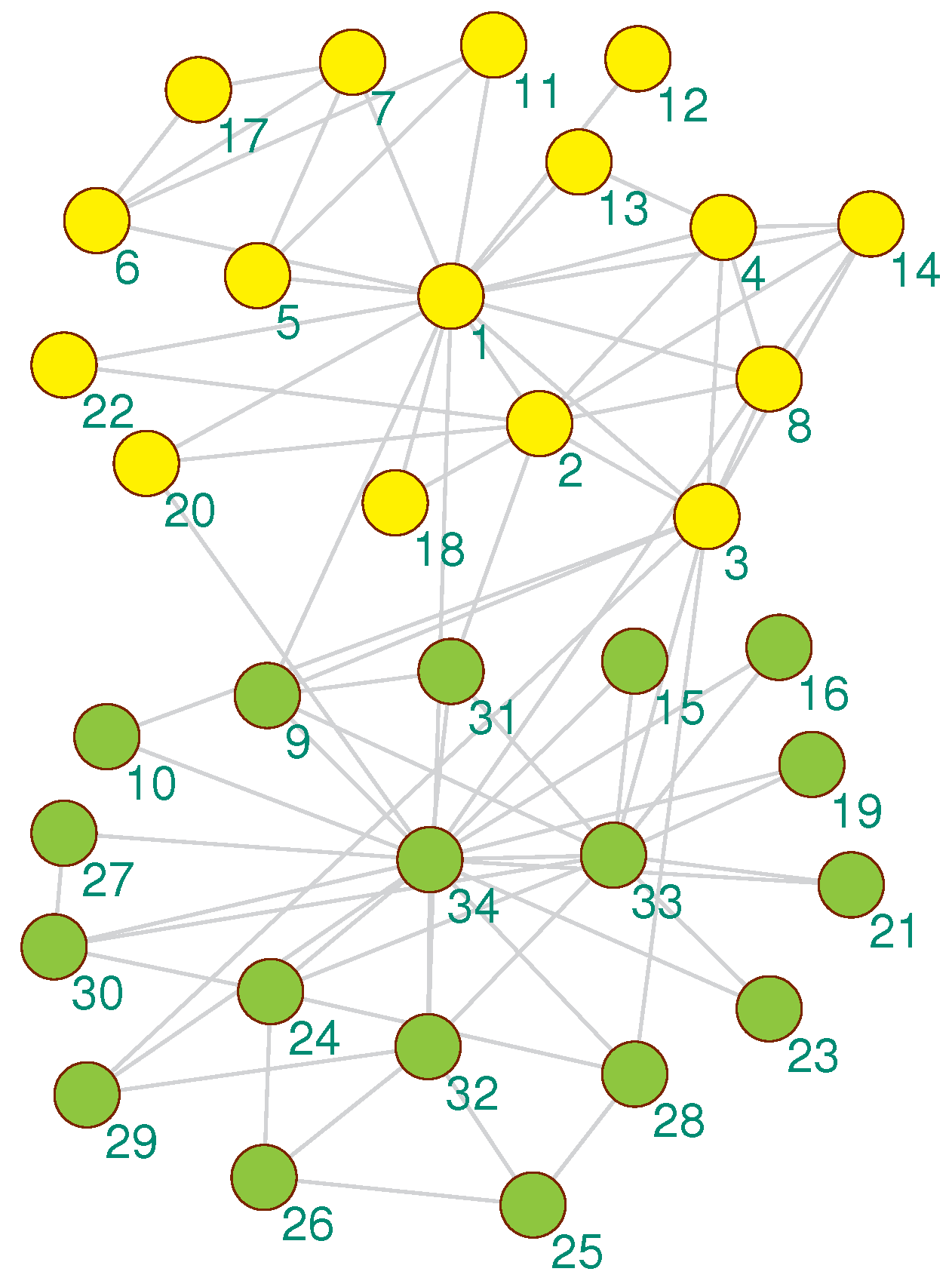
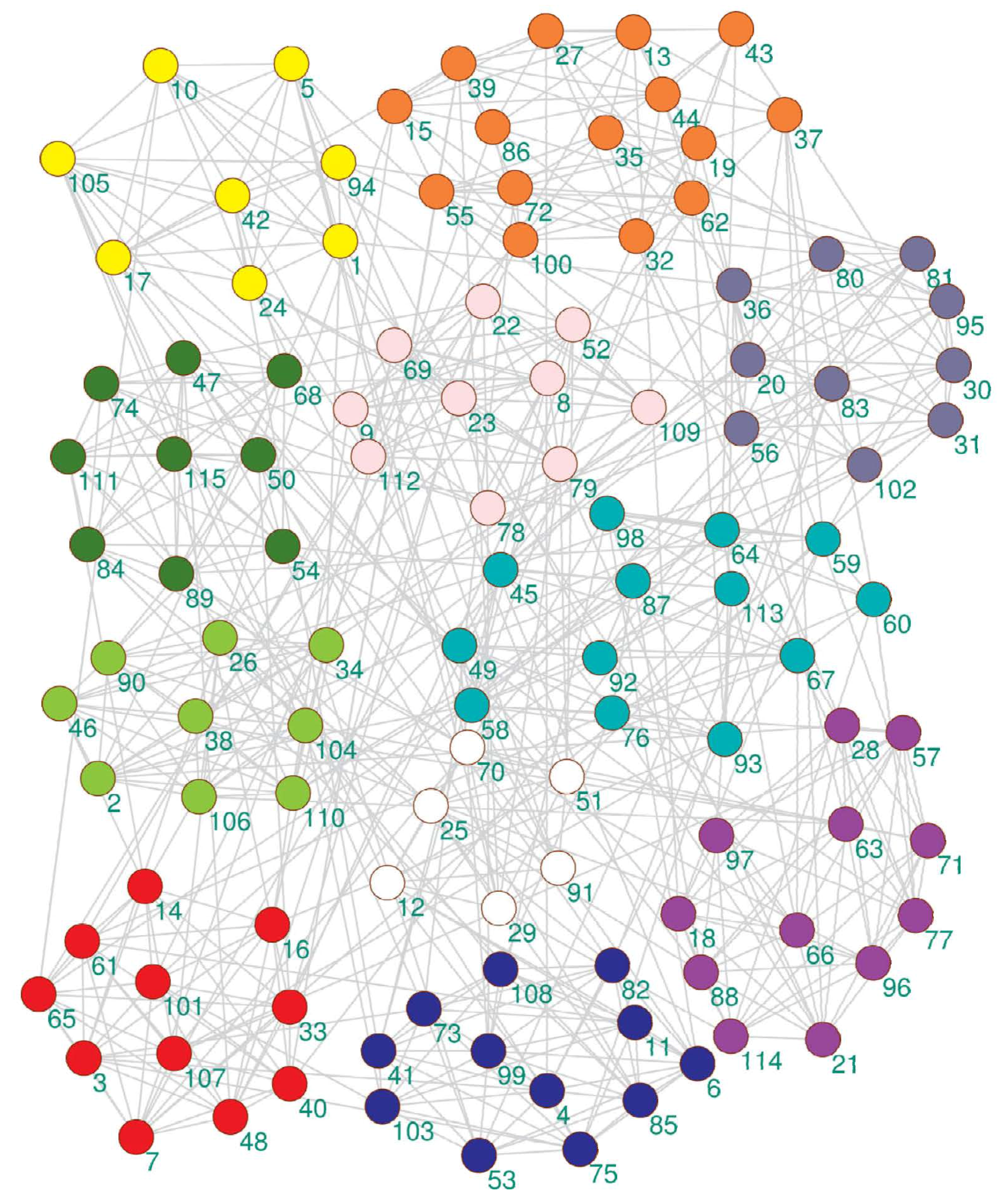
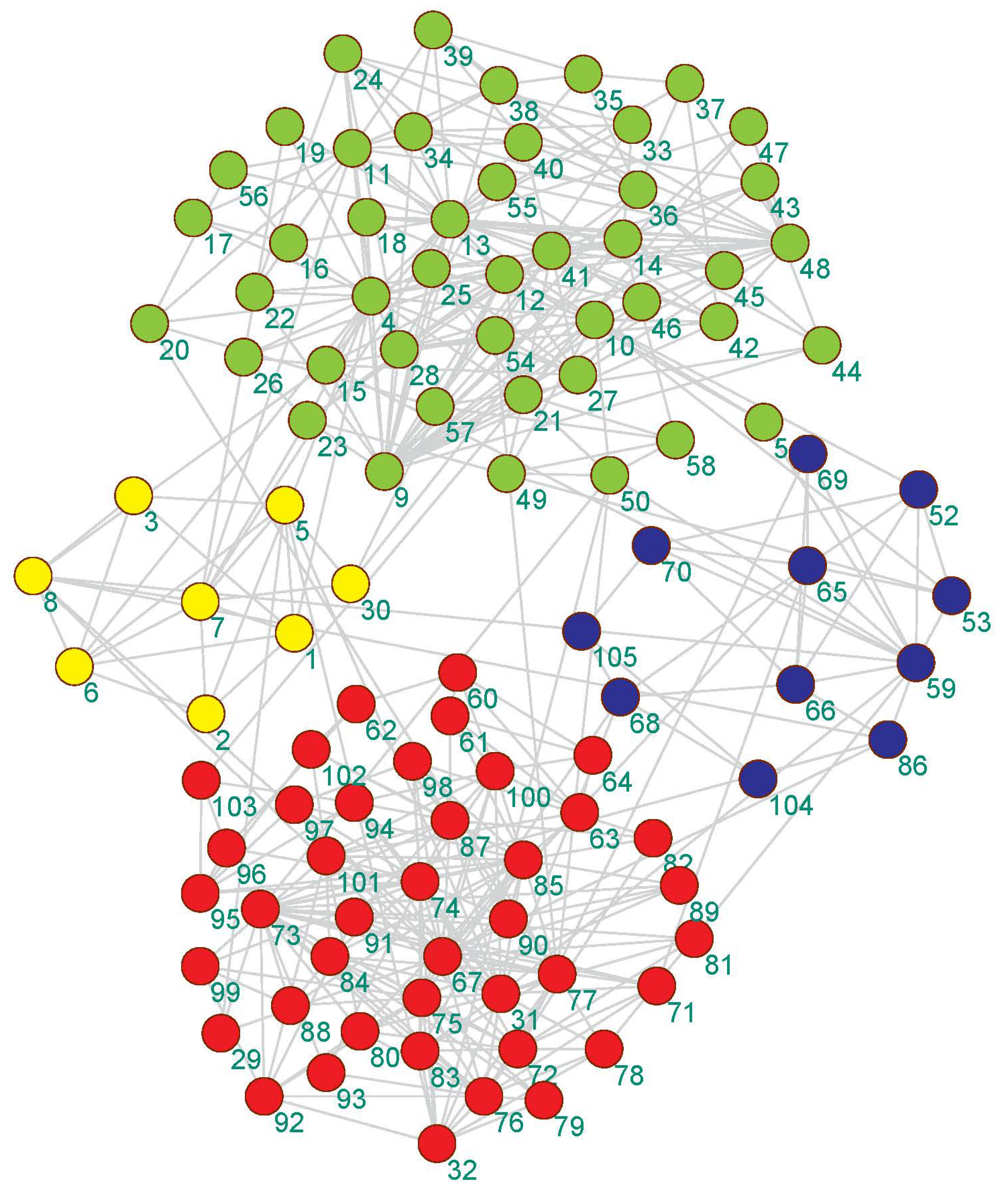
3.5.1. Display Network Partition
3.5.2. Comparison of the Proposed Algorithm with Other Algorithms
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pizzuti, C. Evolutionary Computation for Community Detection in Networks: A Review. IEEE Trans. Evol. Comput. 2018, 22, 464–483. [Google Scholar] [CrossRef]
- Dakiche, N.; Tayeb, F.B.S.; Slimani, Y.; Benatchba, K. Tracking community evolution in social networks: A survey. Inf. Proc. Manag. 2019, 56, 1084–1102. [Google Scholar] [CrossRef]
- Liu, J.; Abbass, H.A.; Tan, K.C. Evolutionary Community Detection Algorithms. In Evolutionary Computation and Complex Networks; Springer International Publishing: Cham, Switzerland, 2019; pp. 77–115. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2009, 80, 056117. [Google Scholar] [CrossRef]
- Tasgin, M.; Herdagdelen, A.; Bingol, H. Community detection in complex networks using genetic algorithms. arXiv 2007, arXiv:0711.0491. [Google Scholar]
- Pizzuti, C. Ga-net: A genetic algorithm for community detection in social networks. In Parallel Problem Solving from Nature–PPSN X; Springer: Berlin, Germany, 2008; pp. 1081–1090. [Google Scholar]
- Pizzuti, C. A multiobjective genetic algorithm to find communities in complex networks. IEEE Trans. Evol. Comput. 2012, 16, 418–430. [Google Scholar] [CrossRef]
- Gong, M.; Fu, B.; Jiao, L.; Du, H. Memetic algorithm for community detection in networks. Phys. Rev. E 2011, 84, 056101. [Google Scholar] [CrossRef] [Green Version]
- Pizzuti, C.; Socievole, A. Many-objective optimization for community detection in multi-layer networks. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), San Sebastian, Spain, 5–8 June 2017; pp. 411–418. [Google Scholar]
- Meo, P.D.; Ferrara, E.; Fiumara, G.; Provetti, A. Mixing local and global information for community detection in large networks. J. Comput. Syst. Sci. 2014, 80, 72–87. [Google Scholar] [CrossRef]
- Grass-Boada, D.H.; Pérez-Suárez, A.; Gago-Alonso, A.; Bello, R.; Rosete, A. Multi-objective Overlapping Community Detection by Global and Local Approaches. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Mendoza, M., Velastín, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 272–280. [Google Scholar]
- Berahmand, K.; Bouyer, A.; Vasighi, M. Community Detection in Complex Networks by Detecting and Expanding Core Nodes Through Extended Local Similarity of Nodes. IEEE Trans. Comput. Social Syst. 2018, 5, 1021–1033. [Google Scholar] [CrossRef]
- Shi, P.; He, K.; Bindel, D.; Hopcroft, J.E. Locally-biased spectral approximation for community detection. Knowl. Syst. 2019, 164, 459–472. [Google Scholar] [CrossRef]
- Moradi, M.; Parsa, S. An evolutionary method for community detection using a novel local search strategy. Physica A Stat. Mech. Appl. 2019, 523, 457–475. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theor. Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Xu, J. Convexified modularity maximization for degree-corrected stochastic block models. Ann. Stat. 2018, 46, 1573–1602. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Zhang, S.; Wang, R.S.; Zhang, X.S.; Chen, L. Quantitative function for community detection. Phys. Rev. E 2008, 77, 036109. [Google Scholar] [CrossRef]
- Jin, H.D.; Leung, K.S.; Wong, M.L.; Xu, Z.B. An efficient self-organizing map designed by genetic algorithms for the traveling salesman problem. IEEE Trans. Syst. Man. Cybernet. 2003, 33, 877–888. [Google Scholar] [CrossRef]
- Villmann, T.; Villmann, B.; Slowik, V. Evolutionary algorithms with neighborhood cooperativeness according to neural maps. Neurocomputing 2004, 57, 151–169. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, A.; Song, S.; Zhang, Q.; Gao, X.Z.; Zhang, J. A Self-Organizing Multiobjective Evolutionary Algorithm. IEEE Trans. Evol. Comput. 2016, 20, 792–806. [Google Scholar] [CrossRef]
- Liang, J.; Guo, Q.; Yue, C.; Qu, B.; Yu, K. A self-organizing multi-objective particle swarm optimization algorithm for multimodal multi-objective problems. In Advances in Swarm Intelligence; Tan, Y., Shi, Y., Tang, Q., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 550–560. [Google Scholar]
- Jia, G.; Cai, Z.; Musolesi, M.; Wang, Y.; Tennant, D.A.; Weber, R.J.M.; Heath, J.K.; He, S. Community Detection in Social and Biological Networks Using Differential Evolution. In Learning and Intelligent Optimization; Hamadi, Y., Schoenauer, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 71–85. [Google Scholar]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [Green Version]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. PNAS 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]
- Newman, M. Mark Newman’s Network Data Collection. Available online: http://www-personal.umich.edu/~mejn/netdata/ (accessed on 24 May 2019).
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | Communities |
|---|---|---|---|
| Zachary’s karate club network | 34 | 78 | 2 |
| American college football club network | 115 | 613 | 12 |
| Krebs America political book network | 105 | 441 | 3 |
| Bottlenose dolphins network | 62 | 60 | 2 |
| Metrics | Statistics | FastNewman [16] | LconDanon [17] | GA-NET [6] | CMM [18] | Meme-Net [8] | EMCD-SOM |
|---|---|---|---|---|---|---|---|
| NMI | Mean | 0.952684 | 0.945996 | 0.872757 | 0.939711 | - | 0.992237 |
| Std | 5.64601 × 10−16 | 0 | 0.0186498 | 0.0136735 | - | 0.0115922 | |
| Worst | 0.952684 | 0.945996 | 0.827308 | 0.915167 | - | 0.947601 | |
| Best | 0.952684 | 0.945996 | 0.899495 | 0.969452 | - | 1 | |
| F-measure | Mean | 0.881533 | 0.943461 | 0.858099 | 0.86981 | - | 0.976459 |
| Std | 3.38761 × 10−16 | 0 | 0.0256338 | 0.0270183 | - | 0.0337187 | |
| Worst | 0.881533 | 0.943461 | 0.79845 | 0.825811 | - | 0.854329 | |
| Best | 0.881533 | 0.943461 | 0.898216 | 0.937594 | - | 1 | |
| RI | Mean | 0.986993 | 0.992146 | 0.983747 | 0.975294 | - | 0.996954 |
| Std | 3.38761 × 10−16 | 4.51681 × 10−16 | 0.00267911 | 0.00821687 | - | 0.00554023 | |
| Worst | 0.986993 | 0.992146 | 0.977668 | 0.960883 | - | 0.971924 | |
| Best | 0.986993 | 0.992146 | 0.988004 | 0.993564 | - | 1 |
| Networks | NMI | FastNewman [16] | LconDanon [17] | GA-NET [6] | CMM [18] | Meme-Net [8] | EMCD-SOM |
|---|---|---|---|---|---|---|---|
| Karate Club | Mean | 0.692467 | 0.530471 | 0.662719 | 1 | 0.759591 | 0.729539 |
| Std | 2.25841e × 10−16 | 0 | 0.041038 | 0 | 0.12226 | 0.0916947 | |
| Worst | 0.692467 | 0.530471 | 0.593038 | 1 | 0.699488 | 0.6895798 | |
| Best | 0.692467 | 0.530471 | 0.707135 | 1 | 1 | 1 | |
| Football Club | Mean | 0.697732 | 0.72976 | 0.36438 | 0.900688 | 0.877428 | 0.900987 |
| Std | 1.1292 × 10−16 | 3.38761 × 10−16 | 0.0326597 | 0.00603723 | 0.0338035 | 0.0128863 | |
| Worst | 0.697732 | 0.72976 | 0.287833 | 0.896274 | 0.757927 | 0.858186 | |
| Best | 0.697732 | 0.72976 | 0.432277 | 0.914376 | 0.924195 | 0.91137 | |
| Political Book | Mean | 0.530814 | 0.522288 | 0.407465 | 0.454128 | 0.46474 | 0.528597 |
| Std | 4.51681 × 10−16 | 2.25841 × 10−16 | 0.0204818 | 3.38761 × 10−16 | 0.0283599 | 0.0190332 | |
| Worst | 0.530814 | 0.522288 | 0.361427 | 0.454128 | 0.425702 | 0.482507 | |
| Best | 0.530814 | 0.522288 | 0.449338 | 0.454128 | 0.522001 | 0.553662 | |
| Dolphins | Mean | 0.5727 | 0.574277 | 0.431174 | 0.814113 | 0.52687 | 0.567711 |
| Std | 1.1292 × 10−16 | 2.25841 × 10−16 | 0.0350064 | 1.1292 × 10−16 | 0.0510336 | 0.0432212 | |
| Worst | 0.5727 | 0.574277 | 0.363285 | 0.814113 | 0.396634 | 0.501266 | |
| Best | 0.5727 | 0.574277 | 0.523461 | 0.814113 | 0.612508 | 0.660154 |
| Networks | F-measure | FastNewman [16] | LconDanon [17] | GA-NET [6] | CMM [18] | Meme-Net [8] | EMCD-SOM |
|---|---|---|---|---|---|---|---|
| Karate Club | Mean | 0.828011 | 0.758621 | 0.810516 | 0.812349 | 0.907227 | 0.89563 |
| Std | 4.51681 × 10−16 | 3.38761 × 10−16 | 0.0345437 | 0.0292515 | 0.0471795 | 0.0353847 | |
| Worst | 0.828011 | 0.758621 | 0.761594 | 0.771371 | 0.884034 | 0.884034 | |
| Best | 0.828011 | 0.758621 | 0.846678 | 0.878937 | 1 | 1 | |
| Football Club | Mean | 0.607997 | 0.624275 | 0.357385 | 0.888643 | 0.829276 | 0.881271 |
| Std | 3.38761 × 10−16 | 4.51681 × 10−16 | 0.0259086 | 0.0102019 | 0.0593904 | 0.0222667 | |
| Worst | 0.607997 | 0.624275 | 0.304809 | 0.866702 | 0.654615 | 0.806481 | |
| Best | 0.607997 | 0.624275 | 0.415762 | 0.902567 | 0.914482 | 0.896491 | |
| Political Book | Mean | 0.819664 | 0.792252 | 0.631611 | 0.778402 | 0.721159 | 0.810397 |
| Std | 1.1292 × 10−16 | 2.25841 × 10−16 | 0.0476347 | 1.1292 × 10−16 | 0.0532029 | 0.0256946 | |
| Worst | 0.819664 | 0.792252 | 0.541227 | 0.778402 | 0.617422 | 0.736497 | |
| Best | 0.819664 | 0.792252 | 0.700829 | 0.778402 | 0.806321 | 0.834708 | |
| Dolphins | Mean | 0.786624 | 0.70509 | 0.549487 | 0.968117 | 0.671548 | 0.721252 |
| Std | 0 | 3.38761 × 10−16 | 0.056409 | 0 | 0.0584518 | 0.0520816 | |
| Worst | 0.786624 | 0.70509 | 0.444878 | 0.968117 | 0.567638 | 0.665973 | |
| Best | 0.786624 | 0.70509 | 0.753607 | 0.968117 | 0.778187 | 0.88149 |
| Networks | RI | FastNewman [16] | LconDanon [17] | GA-NET [6] | CMM [18] | Meme-net [8] | EMCD-SOM |
|---|---|---|---|---|---|---|---|
| Karate Club | Mean | 0.841355 | 0.707665 | 0.770291 | 0.762686 | 0.88164 | 0.866845 |
| Std | 2.25841 × 10−16 | 2.25841 × 10−16 | 0.0276138 | 0.0295904 | 0.0601917 | 0.0451438 | |
| Worst | 0.841355 | 0.707665 | 0.730838 | 0.734403 | 0.85205 | 0.85205 | |
| Best | 0.841355 | 0.707665 | 0.802139 | 0.834225 | 1 | 1 | |
| Football Club | Mean | 0.880702 | 0.887109 | 0.836476 | 0.971647 | 0.953755 | 0.973221 |
| Std | 4.51681 × 10−16 | 5.64601 × 10−16 | 0.0252958 | 0.00177524 | 0.0241369 | 0.00652113 | |
| Worst | 0.880702 | 0.887109 | 0.762319 | 0.972387 | 0.886651 | 0.949352 | |
| Best | 0.880702 | 0.887109 | 0.88177 | 0.979863 | 0.984744 | 0.978032 | |
| Political Book | Mean | 0.828205 | 0.804212 | 0.703199 | 0.759341 | 0.757045 | 0.820733 |
| Std | 2.25841 × 10−16 | 1.1292 × 10−16 | 0.0192073 | 5.64601 × 10−16 | 0.034364 | 0.0203903 | |
| Worst | 0.828205 | 0.804212 | 0.6663 | 0.759341 | 0.707692 | 0.764103 | |
| Best | 0.828205 | 0.804212 | 0.730403 | 0.759341 | 0.817216 | 0.843223 | |
| Dolphins | Mean | 0.713908 | 0.684294 | 0.570739 | 0.936542 | 0.645672 | 0.679129 |
| Std | 3.38761 × 10−16 | 2.25841 × 10−16 | 0.0295801 | 0 | 0.0288785 | 0.0398455 | |
| Worst | 0.713908 | 0.684294 | 0.52935 | 0.936542 | 0.597039 | 0.640402 | |
| Best | 0.713908 | 0.684294 | 0.700159 | 0.936542 | 0.718139 | 0.814384 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Du, Y.; Lei, J. A SOM-Based Membrane Optimization Algorithm for Community Detection. Entropy 2019, 21, 533. https://doi.org/10.3390/e21050533
Liu C, Du Y, Lei J. A SOM-Based Membrane Optimization Algorithm for Community Detection. Entropy. 2019; 21(5):533. https://doi.org/10.3390/e21050533
Chicago/Turabian StyleLiu, Chuang, Yingkui Du, and Jiahao Lei. 2019. "A SOM-Based Membrane Optimization Algorithm for Community Detection" Entropy 21, no. 5: 533. https://doi.org/10.3390/e21050533