1. Introduction
Recently, there has been increasing interest in modeling using mixture models. This is mainly due to the flexibility for treating heterogeneous populations. Under a data-clustering framework, this model has the advantage of being probabilistic, and then the obtained clusters can have a better interpretation from a statistical point of view [
1]. This contrasts with usual methods, such as k-means or hierarchical clustering, in which clusters are not statistically based, as discussed by [
2].
From a frequentist viewpoint, the standard method to get the maximum likelihood estimates for the parameters of a mixture model is based on the use of the Expectation Maximization (EM) algorithm [
3]. However, for the use of this algorithm, the number of components
k of the mixture model needs to be known a priori. As the resulting model is highly dependent on the choice of this value, the main question is how to set the
k value. Selecting an erroneous
k value may cause the non-convergence of the algorithm and/or a low exploration of the clusterings. In addition, depending on the
k value chosen we may have empty components, and therefore, there are no maximum likelihood estimates for these components.
An approach frequently used to determine the best
k value among a fixed set of values is the use of the stochastic version of the EM algorithm (SEM) with some model selection criterion, such as the Akaike information criterion (AIC) [
4,
5] or the BIC [
6]. In this approach, models are fitted for a set of predefined
k values, and the best model is the one that has the smallest AIC or BIC value.
However, as discussed by [
7], to adjust several models for a predefined set of values for the number of the cluster and compare them using some model selection criterion is not a practical and efficient procedure. Therefore, it is desirable to have an efficient algorithm to calculate the optimal number of clusters together with the estimation of the parameters of each mixture component. In this scenario, the Bayesian approach was successfully performed considering the Markov chain Monte Carlo (MCMC) algorithm with reversible jumps, described by [
8] in the context of univariate normal mixture models. On the other hand, a difficulty often encountered in implementing a reversible jump algorithm (RJ) is the construction of efficient transition proposals that lead to a reasonable acceptance rate.
Following in the line of MCMC algorithms, [
9] proposes a split–merge MCMC procedure for the conjugated Dirichlet process mixture model using a restricted Gibbs sampling scan to determine a split proposal, where the number of scans (tuning parameter) must be previously fixed by the user, and [
10] extend their method to a nonconjugated Dirichlet process mixture model. [
11] proposes a data-driven split-and-merge approach. In this proposal, the number of clusters is updated according to the creation of a new component based on a single observation and using a split–merge strategy, developed based on the use of the Kullback–Leibler divergence. A difficulty encountered for implementing this algorithm is the obtaining of the mathematical expression for the Kullback–Leibler divergence, which does not always have known analytical expression. In addition, the sequential allocation used in the split–merge strategy of these three works may make the algorithm slow when the sample size is great, and the computation implementation of these methods is not so simple.
The present work proposes an integrated approach that, in a joint way, selects the number of clusters and estimates the parameters of interest. With this approach, the mixture weights are integrated out to obtain allocation probabilities that depend on the number of clusters (nonempty components) but do not depend on the number of components k. In addition, considering k tending to infinity, this procedure introduces a positive probability of a new cluster being created by a single observation. When a new cluster is created, the parameters associated with it are generated from its posterior distribution. We then developed the ISEM (integrated stochastic expectation maximization) algorithm to estimate the parameters of interest. This algorithm configures a setting for latent allocation variables according to allocation probabilities, and then the cluster parameters are updated conditionally on as follows: for clusters with at least two observations, the parameter values are the maximum likelihood estimates; for the clusters with only one observation, the parameter values are generated from their posterior distribution.
In order to illustrate the computation implementation of the method and verify its performance, we have considered a specific model in which data are generated from mixtures of univariate normal distributions. This model allows us to avoid the label switching problem by considering the labeling of the components according to the increasing order of the component averages, as done by [
8,
11,
12,
13], among others. But we emphasize that our algorithm is not restricted to this particular model. For instance, for the multivariate case, we may consider the labeling of the components according to the eigenvalues of the current covariance matrix, as done by [
14]. However, a detailed discussion of the multivariate case will be done in a future paper.
We also compare the performance of the ISEM with both SEM and RJ algorithms. The criteria used to compare the methods are the estimated probability of the number of clusters, convergence of the sampled values, mixing, autocorrelation, and computation time. We also applied the three algorithms to two real datasets. The first is the well-known Galaxy data, and the second is a dataset on Acidity.
The remainder of the paper is as follows.
Section 2 describes the mixture model and the estimation process based on the SEM algorithm.
Section 3 develops the integrated approach and describes the ISEM algorithm.
Section 4 shows how we applied the algorithm to simulated datasets in order to assess its performance.
Section 5 describes the application of the three algorithms to two real datasets.
Section 6 is about our final remarks. Additional details are in the
Supplementary Material, which is referred to as “
SM” in this paper.
Table 1 presents the main notations used throughout the article.
2. Mixture Model and SEM Algorithm
Let
be a vector of independent observations from a mixture model with
k components, i.e.,
where
is the density of a family of parametric distributions with parameters
(scalar or vector),
are the parameters of the components, and
,
and
are component weights.
The log-likelihood function for
is given by
The mathematical notation is given as in the book of Casella and Berger (2002).
The usual procedure to obtain the maximum likelihood estimators consists of getting partial derivatives of
in relation to
and then equalizing the result to zero, i.e.,
for
.
But, note that in (
2), the maximization procedure consists of a weighted maximization process of the log-likelihood function with each observation
having a weight associated to component
j given by
for
and
. However, these weights depend on the parameters that we are trying to estimate. In this way, we cannot obtain a “closed” mathematical expression that allows the direct maximization of the log-likelihood function. Due to this, the mixture problem is reformulated as a complete-data problem [
12,
15].
Complete-Data Formulation
Consider associated to each observation
a latent indicator variable
not known, so that if
, then
is from component
j, for
and
. The probability of
is
,
, for
and
. Letting
be the number of observations from component
j (i.e., the number of
s equals to
j), the joint probability for
given
and
k is
The distribution of the number of observations assigned to each component, , called the occupation number, is multinomial, , where .
Thus, under this augmented framework, we have that
- (1)
the probability of
, conditional on observation
and on component parameters
, is
, i.e.,
, for
given in Equation (
3), for
and
. That is, although the indicator variables are nonobservable, they are implicitly present in the estimation procedure given in Equation (
2).
- (2)
the log-likelihood function for
, conditional on complete data
, is given by
where
is the log-likelihood function for component
j, for
. Thus, the estimation procedure of the
k component parameters reduce to
k independent problems of estimation. For example, for a normal mixture model, the maximum likelihood estimates for component parameters
is
, where
and
are, respectively, the average and variance of the observations allocated to component
j, for
.
From this complete-data formulation, the estimation procedure is given by an iterative process with two steps. In the first one, the allocation indicator variables are updated conditional on component parameters, and in the subsequent step, the component parameters are updated conditional on configuration of the allocation indicator variables.
The usual algorithm used to implement these two steps is the EM algorithm [
3]. The stochastic version of the EM algorithm (SEM) can be implemented according to Algorithm 1.
| Algorithm 1 SEM Algorithm |
| 1: Initialize the algorithm with a configuration for allocation indicator variables. |
| 2: procedure For the s-th iteration of the algorithm, |
| 3: get the maximum likelihood estimates and conditional on configuration ; |
| 4: if , where is a threshold value previously fixed, then stop the algorithm. Otherwise, go to item (iii); |
| 5: conditional on and , update as follows. For and do the following: |
| 6: Let be a indicator vector, so that or ; |
| 7: Generate , where and is obtained from Equation (3) doing and . If , then do ; |
| 8: Do and return to step (3). |
Although it is simple to implement computationally, the SEM algorithm may present some practical problems. As discussed by [
16], the algorithm may present a slow convergence. Due to this, some authors, such as [
17,
18], discuss how to set up the start values in order to increase the convergence. In addition, [
15] discusses the non-existence of the global maximum estimator.
Moreover, in this algorithm, the
k value must be known previously. For the cases in which
k is an unknown quantity, the best
k value is chosen by fitting a set of models associated with a set of predefined
k values and comparing them according to AIC [
4,
5] or BIC [
6] criteria. Furthermore, given a sample of size
n and fixed a
k value, there exists a positive probability, given by
, of the
j-th component not having observations allocated in an iteration of the algorithm. In this case, we have an empty component, and the maximum likelihood estimates cannot be calculated for these components. Thus, in order to avoid the practical problems presented by the EM algorithm, we propose an integrated approach.
3. Integrated Approach
We start our integrated approach linking data clustering to a mixture model. For this, consider a sampling process from a heterogeneous population that is subdivided into k sub-populations. Thus, it is natural to assume that the sampling process consists of the realization of the following steps:
- (i)
choose a sub-population j with probability , where is the relative frequency of the j-th sub-population in relation to the overall population;
- (ii)
sample a value of this sub-population,
for and , where n is the sample size.
Let
be a sample unit, where
is an indicator allocation variable that assumes a value of the set
with probabilities
, respectively. Thus, assuming that subpopulation
j is modeled by a probability distribution
indexed by parameter
(scalar or vector), we have that
for
and
.
However, in clustering problems, the
’s values are non-observable. Thus, the probability of
is
, and the marginal probability density function for
is given by Equation (
1).
In addition, as the model in Equation (
1) is a population model; so there exists a non-null probability
that the
j-th component is an empty component. Thus, the number of clusters (i.e., non-empty components) is smaller than the number of components
k. As viewed in the description of the EM algorithm, the number of clusters is defined by the configuration of the latent allocation variables
; thus hereafter, we will denote the number of clusters by
, for
.
Since the interest lies in the configuration of
, let us marginalize out the weights of the mixture model. Thus, integrating density (
4) with respect to the prior
distribution of the weights, denoted by
, the joint probability for
is given by (see
Appendix 3 of the SM)
Similarly, the conditional probability for
given
, is given by
where
is the number of observations allocated to the
j-th component, excluding the
i-th observation, for
and
.
As the main interest is in
and not
k, we remove
k from Equation (
6) by letting
k tend to infinity. Under this assumption, the probability reaches the following limit:
when
, for
and
, where
is the number of clusters defined by configuration
. In addition, we now have a probability of the
i-th observation being allocated to one of the other infinite components, which is given by
for
. This is the probability of the observation
creating a new cluster, for
. The probabilities in (
7) and (
8) are equivalent to the update probabilities of a Dirichlet process mixture model. See, for example, [
19,
20,
21].
Given
, the conditional probability for
, such that
, is
for
and
, where
is the number of clusters excluding the
i-th observation. At this point, it is important to note that if an observation
is allocated to a component
j,
, and
, then
and
. But if
and
, then
and
.
In order to define the conditional probability of the
i-th observation creating a new cluster
, we integrate parameters out for this case, for
. This was done because that probability does not depend on the parameter value
. Thus, the conditional posterior probability for
is
where
and
is the density of the prior distribution for
, for
.
As is known from the literature, the likelihood function for a mixture model is non-identifiable, i.e., any permutation of the components’ labels lead to the same likelihood function (see, for example, [
8,
11,
22,
23,
24]). Thus, in order to get identifiability, we assume that
are the component means for clusters and that
. However, it does not prevent the algorithm described in the next Section from being applicable to another labeling criterion. Additional discussion about label switching can be found in [
22,
23].
Integrated SEM Algorithm
Using probabilities given in Equations (
9) and (
10), we update the allocation indicator variables according to Algorithm 2.
Conditional on a configuration , we have clusters. So, we update parameters of interest according to Algorithm 3. We then join Algorithms 2 and 3 to get the Algorithm 4.
After the S iterations, we discard the first B iterations as a burn-in. In the following, we also consider “jumps” of size h, i.e., only one draw every h is extracted from the original sequence in order to obtain a sub-sequence of size to make inferences. Denote this sub-sequence by .
Consider
to be the number of times that
in
, for
, where
is the maximum
value sampled in the course of iterations. Thus,
is the estimated probability for
. We then consider
as being the estimates for the number of components
.
Appendix 1 of the SM presents the mathematical expression used to determine a configuration for
and estimates for the parameters of the clusters, conditional on the estimate
.
| Algorithm 2 Updating |
| 1: Let be the current configuration for latent allocation variables. Then, update as follows. |
| 2: procedure For : |
| 3: Remove from the current state , obtaining and ; |
| 4: Generate a variable where for given in (9) and given in (10), for and ; |
| 5: If , for , set up and do ; |
| 6: If , do and . As this new cluster has just one observation allocated, set as component parameter , where is a value generated from posterior distribution , where is the probability density function for conditional on and is the density of the prior distribution for . Relabel the clusters in order to maintain the adjacency condition. If the component mean of the new cluster is such that: |
| 7: , then do and relabel all other clusters doing ; |
| 8: , then do and keep all other clusters labels; |
| 9: , for , then do and relabel all other clusters doing . |
| Algorithm 3 Updating cluster parameters |
| 1: Let be the current parameter values of the clusters. Conditional on configuration , get as follows: |
| 2: if cluster j is such that , then do , where are the maximum likelihood estimates of the j-th cluster; |
| 3: if cluster j is such that , then generate from conditional posterior distribution and set ; |
| 4: Do only if the adjacency condition is met. Otherwise, keep as the current value. |
| Algorithm 4 ISEM Algorithm |
| 1: Initialize the algorithm with a configuration for allocation indicator variables. |
| 2: procedure For the s-th iteration of the algorithm, , do the following. |
| 3: Conditional on , update the parameters of the clusters according to algorithm 3; |
| 4: Obtain a new configuration for the allocation of indicator variables using algorithm 2. |
4. Simulation Study
In this section, we describe the results from a simulation study carried out to verify the performance of the proposed algorithm. To generate the artificial datasets, we considered univariate normal mixture models. We set up the number of clusters and parameter values according to the specified values in
Table 2. We also fixed the sample size equal to
.
The procedure for generating the datasets is given by the following steps:
- (i)
For
, generate
; if
, generate
, with fixed parameter values according to
Table 2, for
and
.
- (ii)
In order to record from which component each observation is generated, we define such that if , for and .
Having generated the datasets, we need to define the the probability of creating a new cluster and the posterior distribution for
given
, for
. For this, consider the following conjugated prior distributions for component parameters
:
where
,
,
, and
are hyperparameters. The parametrization of the gamma distribution is such that the mean is
and the variance is
.
Following [
11,
24], we consider the following procedure to define the values for the hyperparameters. Let
R be the observed variation interval of the data and
its midpoint. Then, we set up
and
. Thus, we obtain
, and we fix
. In addition, to obtain a prior distribution with a large variance, we fixed
, and for the hyperparameter
, we consider the value
,
.
Thus, the probability of creating a new cluster is given by Equation (
10), in which
and
, for
.
When a new cluster is created, the new parameter values
are generated from the following conditional posterior distributions,
and
for
.
We run the ISEM algorithm for S = 55,000, B = 5000, and h = 10. From these values, we got a sub-sequence of size 5000 to make inferences. The algorithm was initialized with and parameter values and , the sample mean and variance of the generated dataset, respectively.
We also apply to the generated datasets the SEM algorithm, as describe in
Section 2, and the RJ algorithm as proposed by [
8]. In order to choose the number of clusters using the SEM algorithm, we consider the AIC and BIC model selection criteria. In addition, the algorithm was initialized using a configuration
obtained via the
k-means algorithm [
25]. As stop criterion, we set up the threshold
. For the RJ algorithm, we consider the same number of iterations, burn-in, and thin value used in the ISEM algorithm.
In order to compare the three algorithms in terms of the estimation of the number of clusters, we consider
simulated datasets.
Table 3 shows the proportion of times that the ISEM and RJ algorithms put the highest estimated probability on the
values presented. This table also show the proportion of times that the AIC and BIC indicated the
value as the best among the tested values. The values highlighted in bold are the proportions on the
true value. As one can note, the ISEM shows a better performance, i.e., higher proportion of the
true value than the other two algorithms, especially in relation to the SEM algorithm with the selection of
via the AIC and BIC. The results also show that the AIC and BIC model selection criteria have a low success ratio, with a proportion of the
true value smaller than
.
4.1. Results from a Single Simulated Data Set
We also analyze the results from a single dataset selected at random from the
generated datasets in each situation
to
. Then, we discuss the convergence of the ISEM and RJ algorithms based on the sample generated across iterations, using graphical tools. In general, the graphical tools show whether the simulated chain stabilizes in some sense and provide useful feedback about the convergence [
26].
Table 4 shows the estimated probabilities of
obtained with ISEM and RJ and the AIC and BIC values from the SEM algorithm for the selected dataset. In this table, the values highlighted in bold are the highest estimated probabilities and the smallest AIC and BIC values. As we can note, the ISEM algorithm set up a maximum probability for the
true value for the four simulated cases.
The RJ algorithm puts a higher probability on the true value for datasets and . However, the probability on the true value is smaller than that estimated by ISEM. This indicates a higher precision for the ISEM algorithm. For datasets and , the RJ attributes maximum probability to the wrong values, and , respectively. Moreover, the probabilities estimated by RJ do not evidence a single value for as being the best value since there are different values for with similar probabilities. For example, for dataset , the maximum is at with , but one can argue that the estimated probabilities favor or . For dataset , there is similar support for between 4 and 7, and for between 5 and 7.
Analogously to ISEM and RJ, the AIC and BIC model selection criteria indicate the true value as the best value for datasets and . For dataset , similar to the RJ, the AIC indicates the wrong value as the best value, while the BIC indicates the true value as the best value. For dataset , the AIC and BIC indicate the wrong value as the best model.
4.2. An Empirical Check of the Convergence
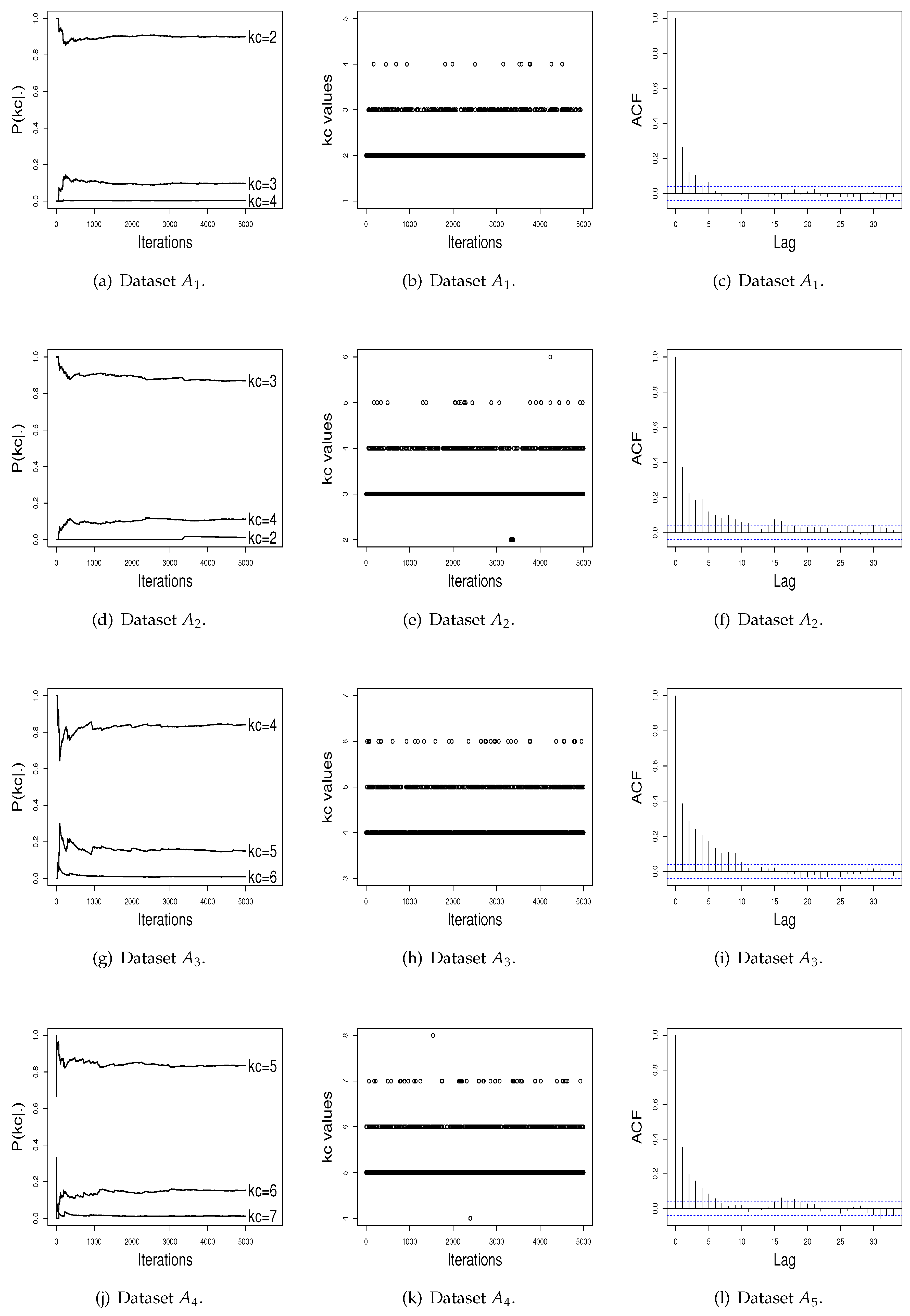
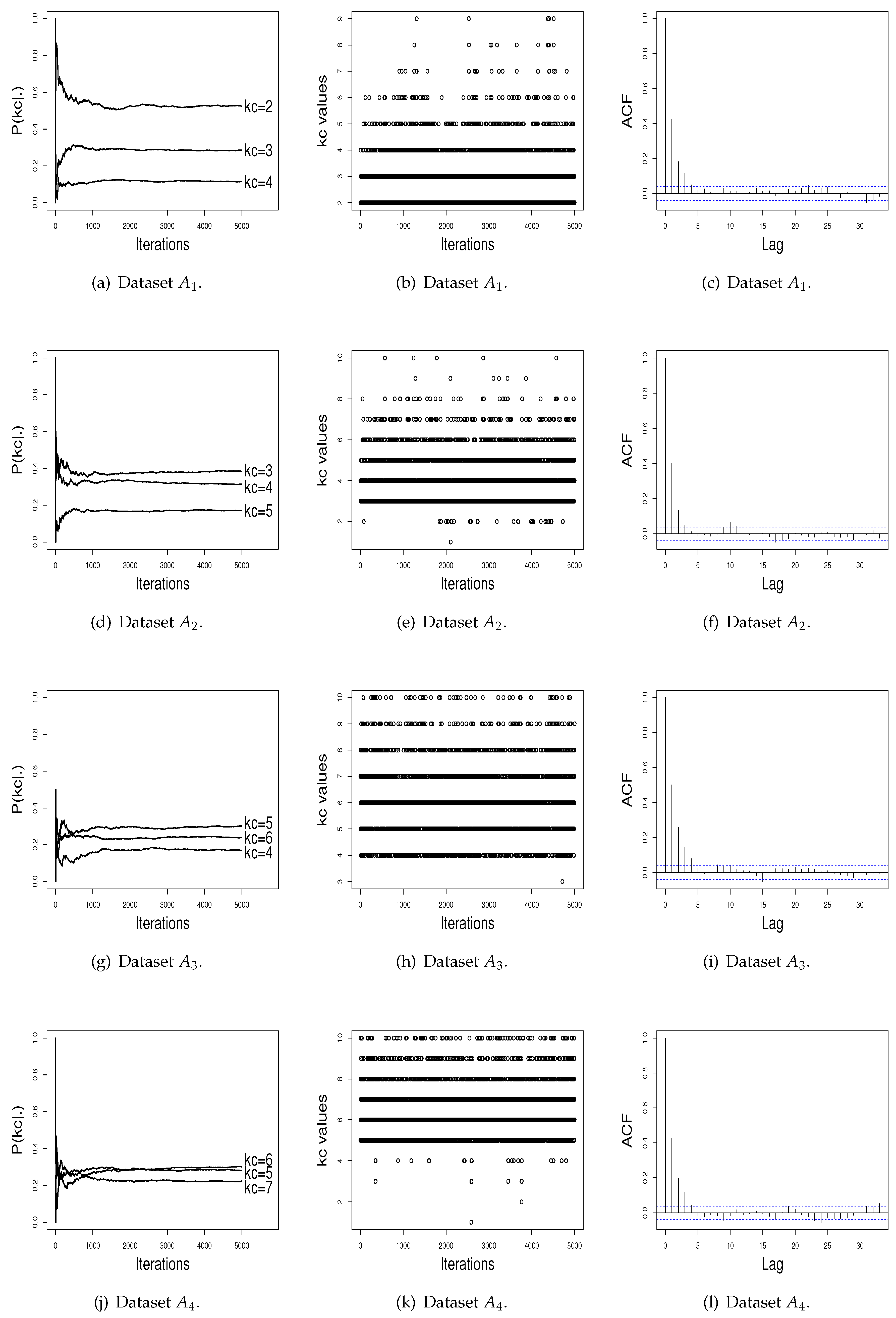
We now empirically check the convergence of the sequence of the probability for across iterations, the capacity to move for different values of in the course of the iterations, and the estimated autocorrelation function the (acf) for the ISEM and RJ algorithms.
Figure 1a,d,g,j presents the graphics of the probability for
in the course of the iterations, for the four simulated datasets. To maintain a better visualization, we plot in these graphics only the three higher
estimates. Observing at these figures, it can be seen that the L iterations and the burn-in value
B used were adequate to achieve stability for
. In addition,
Figure 1b,e,h,k shows that the ISEM algorithm mixes well over
, i.e., “visits” mixture models with different values of
across iterations. As shown by
Figure 1c,f,i,l, the sampled
values also do not have significant autocorrelation function (ACF). Thus, based on these graphical tools, there is no evidence against the convergence of the generated values by the ISEM algorithm.
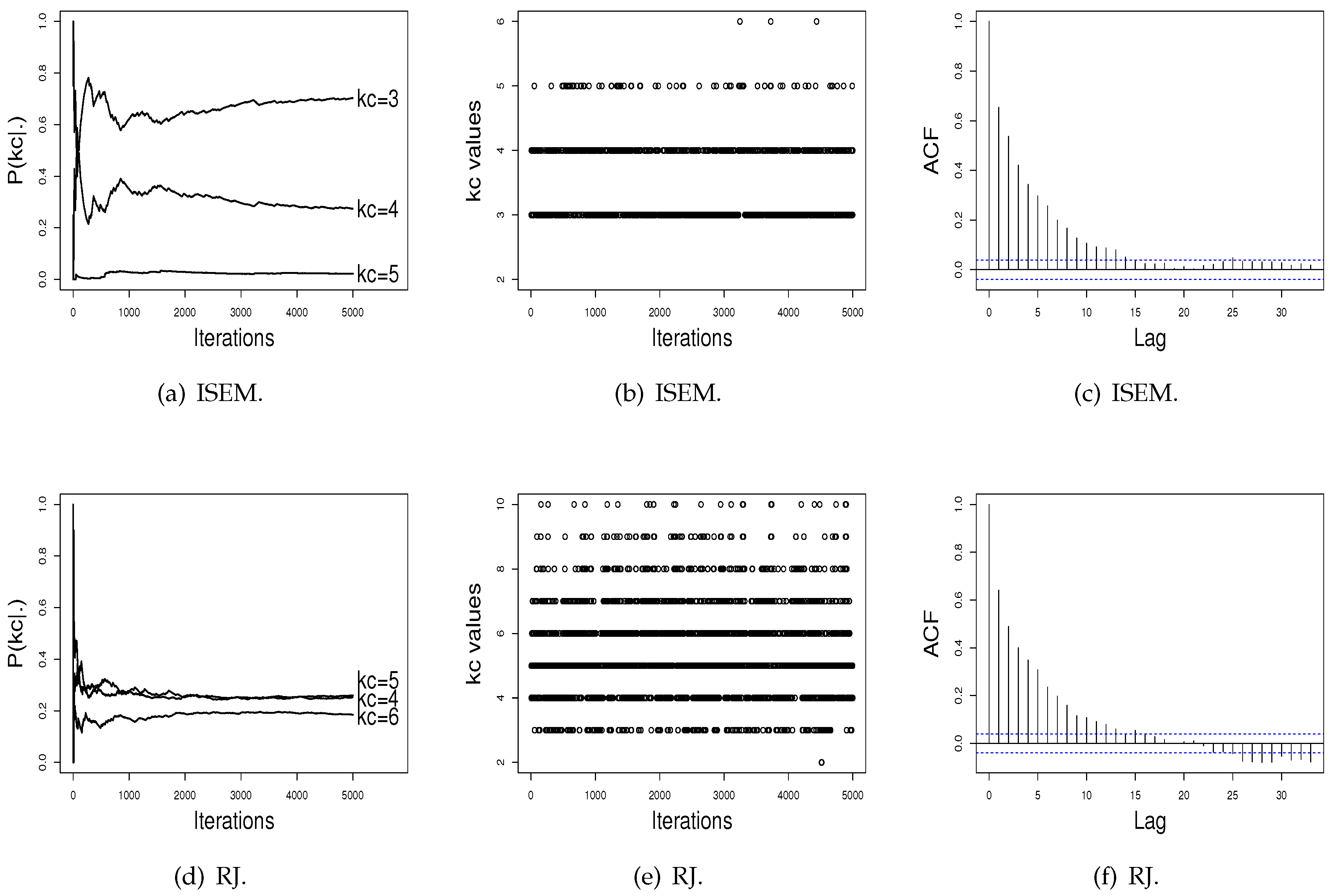
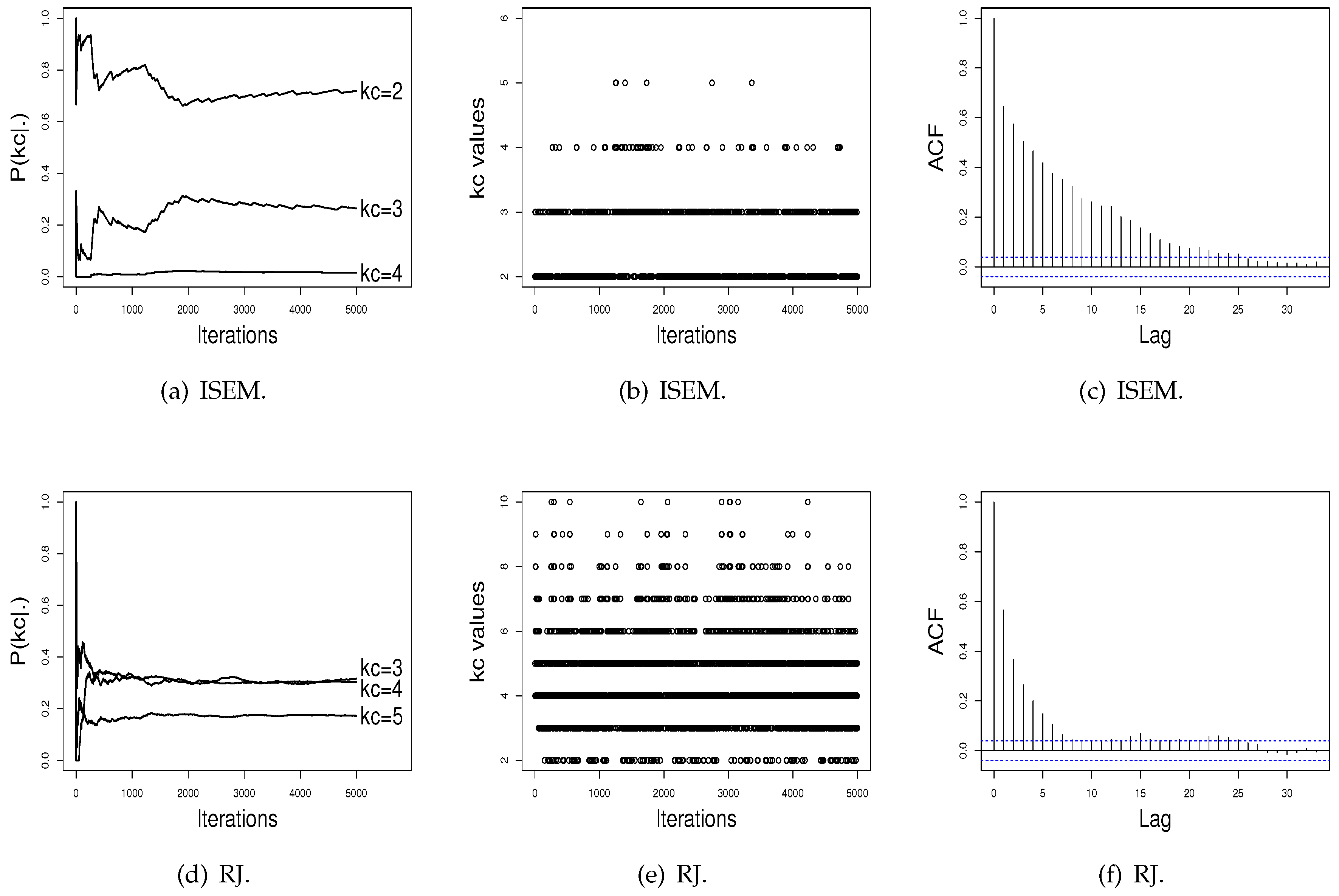
Figure 2 shows the performance of the RJ algorithm. The probabilities of
present a satisfactory stability. The sampled
values have a satisfactory mix, and the estimated autocorrelation is non-significant. In addition, as can be noted in
Figure 2, probabilities for the number of clusters do not differentiate a value of
in order to be chosen as the better value, as done by ISEM. This may happen due the fact that the performance of the RJ depends on the choice of the transition functions to do “good” jumping, meaning that a transition function that is adequate for one dataset may be not for another one. As the ISEM algorithm does not need the specification of transition functions to propose a change of the
value, these results shows us that ISEM may be an effective alternative in relation to RJ and SEM algorithms for the joint estimation of
and the cluster parameters of a mixture model.
Figure 1 in
Appendix 2 of the SM shows the generated values for datasets
to
. This Figure also shows the clusters identified by the ISEM algorithm. As can be seen, clusters are satisfactorily identified by the proposed algorithm.
We also compare ISEM and RJ algorithms in terms of CPU computation time. The simulations were realized on a MacBook Pro, 2.5 GHz Intel Core i5 dual core, 4 Gb MHz DDR3.
Table 5 shows a summary of the times of iterations for the ISEM and RJ algorithms. The column denoted by s.d. presents the standard deviation values. For dataset
, the average time that RJ takes to run one iteration is
times greater than the average time that ISEM takes to run an iteration. For datasets
,
, and
, the average time that RJ needs to run one iteration is
,
, and
times greater than the average time that ISEM takes to run an iteration, respectively. These results show a better performance of the ISEM algorithm. The higher iteration times of the RJ algorithm are mainly due to the split–merge step used to increase the mixing of the Markov chain in relation to the number of clusters.
The results from these simulated datasets show that the ISEM algorithm may be an effective alternative to the RJ and SEM algorithms for data clustering in situations where the number of clusters is a unknown quantity.
5. Application
The three algorithms are now applied to two real datasets. The first real dataset refers to velocity in km/s of
galaxies from 6 well-separated conic sections of an unfilled survey of the Corona Borealis region. This dataset is known in the literature as the Galaxy data and has already been analyzed by [
8,
13,
22,
27], among others. This dataset is available in the R software. The second real dataset refers to an acidity index measured in a sample of
lakes in central-north Wisconsin. This dataset was downloaded from the website
https://people.maths.bris.ac.uk/∼mapjg/mixdata.
For application of ISEM and RJ algorithms, we consider the same number
L = 5500,
B = 5000, and
h = 10.
Table 6 shows the estimated probabilities for
obtained with ISEM and RJ and the AIC and BIC values from EM algorithm for each dataset. The maximum probability from ISEM and RJ and the minimum AIC and BIC values are highlighted in bold.
For the Galaxy dataset, the ISEM and RJ algorithms put highest probability on and , respectively. However, analogously to the simulation study, the probabilities estimated by RJ do not evidence a single value for as being the best value. For this dataset, the estimated probabilities indicate a value between 3 and 7. The AIC and BIC also indicate as the best value. For the Acidity dataset, ISEM, AIC, and BIC indicate as the best value. The probabilities estimated by RJ attribute similar values for and .
Figure 3 and
Figure 4 show the performance of the ISEM and RJ algorithms across iterations for the Galaxy and Acidity datasets. The values sampled by the ISEM algorithm present satisfactory stability for estimated probability across iterations, mix well among different
values, and present no significant autocorrelation. That is, we do not have evidence against the convergence of the generated chain by the ISEM algorithm. In relation to the RJ, the sampled values mix well and do not present significant autocorrelation. However, although the values sampled by RJ present stability for
, the estimated probabilities do not differentiate a value of
in order to be chosen as the better value, as done by ISEM. This result shows the need to run RJ for a greater number of iterations. With this, we have that for both real datasets, ISEM presents faster convergence than the RJ algorithm.
Table 7 shows a summary of the iteration times for the ISEM and RJ algorithms. For the Galaxy data, the average time that ISEM takes to run an iteration is
s; while the average time for RJ is
s. That is, the average time that RJ takes to run one iteration is
times greater than the average time that ISEM takes to run an iteration. For the Acidity data, the average times that the ISEM and RJ algorithms take to run an iteration are
and
s, respectively. For this dataset, the average time that RJ needs to run an iteration is
times greater than the average time that ISEM runs. Similarly to results from the simulation study, ISEM presents better results, i.e., a shorter time to run the iterations.
6. Final Remarks
This article presents a discussion of how to estimate the parameters of a mixture model in the context of data clustering. We propose an alternative algorithm to the EM algorithm called ISEM. This algorithm was developed through an integrated approach in order to allow to be estimated jointly with the other parameters of interest. In the ISEM algorithm, the allocation probabilities depend on the number of clusters and are independent of the number of components k of the mixture model.
In addition, there exists a positive probability of a new cluster being created by a single observation. This is an advantage of the algorithm because it creates a new cluster without the need to specify transition functions. In addition, the cluster parameters are updated according to the number of allocated observations. For the clusters with at least two of these observations, the values of the parameters are taken by the maximum likelihood estimates. For a cluster with just one observation, the parameter values are generated from the posterior distribution.
In order to illustrate the performance of the ISEM algorithm, we developed a simulation study. In this simulation study, we considered four scenarios with artificial data generated from Gaussian mixture models. In addition, each one of the four scenarios was replicated times, and the proportion of times that ISEM put a higher probability on the true value was recorded. We applied this same procedure to the EM algorithm, choosing the number of clusters via the AIC and BIC, and to the RJ algorithm. Then, the three algorithms were compared in terms of proportion of times that the true value was selected as the best value. The results obtained show that the ISEM algorithm outperforms the RJ and SEM algorithms. Moreover, the results also show that the AIC and BIC model selection criteria should not be used to determine the number of clusters in a mixture model due to a low success rate.
We also compared the performance of ISEM and RJ in terms of empirical convergence of the sequence of values generated using graphical tools. For this, we selected at random an artificial dataset from each scenery, and then we plotted the probability estimates for
across iterations, the generated
values, and the estimated autocorrelation of the sampled values (see
Figure 1 and
Figure 2). Again, the results show a better performance for the ISEM algorithm. While ISEM presents satisfactory stability for the probability of
and differentiates the true
as the best value, the probabilities estimated by RJ do not differentiate a value of
in order to be chosen as the better value.
In order to illustrate the practical use of the proposed algorithm and compare its performance with the SEM and RJ algorithms, we applied the three algorithms to two real datasets: the Galaxy and Acidity datasets. For the Galaxy dataset, ISEM indicates
with probability
, while the RJ algorithm, the AIC, and the BIC indicate
. However, as shown in
Figure 3d, the RJ algorithm again does not differentiate a value of
, while ISEM differentiates the
value, and the generated values across iterations present satisfactory stability. For the Acidity dataset, the ISEM, AIC, and BIC indicate
as the best value, while RJ attributes similar probabilities for
and
.
As mentioned in the Introduction, the generalization of the proposed algorithm for the multivariate case is the next step of our research. The simulation study and the application were done in R software, and the computational codes can be obtained by emailing the authors.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}