Impact of Misclassification Rates on Compression Efficiency of Red Blood Cell Images of Malaria Infection Using Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Construction of the Dataset of Malaria-Infected Red Blood Cell Images
2.2. Lossless Compression Using Autoencoders
2.3. Golomb–Rice Coding
- Each non-negative integer n to be coded is decomposed into two numbers, q and r, where , q is the quotient of , and r is the remainder.
- Unary-coding q by generating q “1”s, followed by a “0”.
- Coding of r depends on if m is a power of two:
- If , r can be simply represented using an s-bit binary code.
- If m is not power of two, the following thresholds should be calculated first:If , then r is represented by a B-bit binary code; Otherwise, if , then is represented by a A-bit binary code.
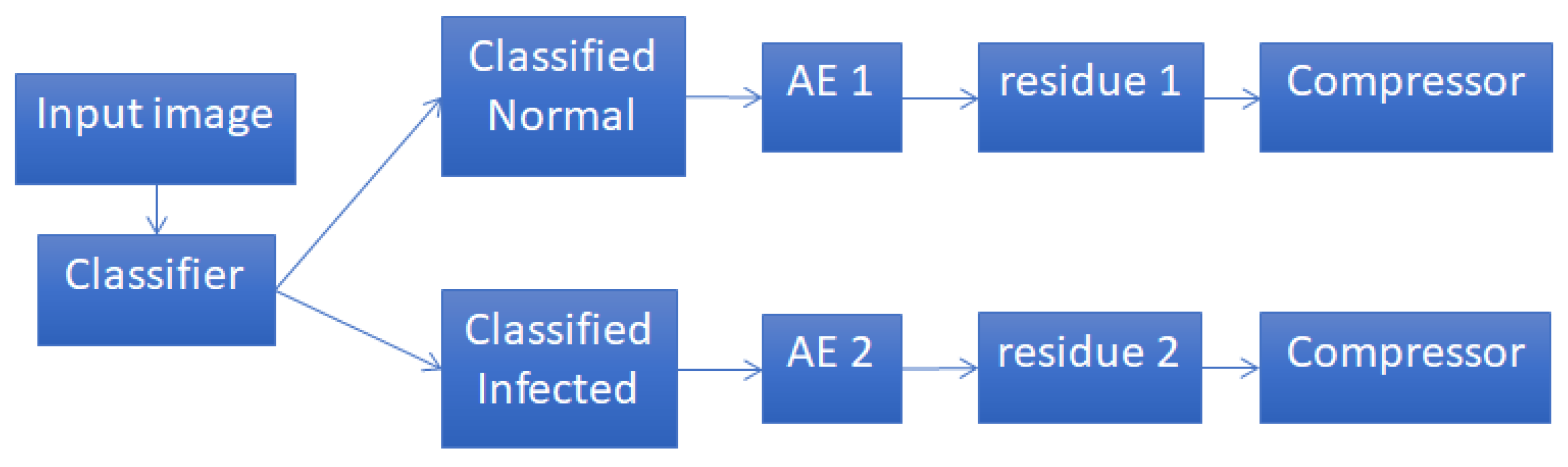
2.4. Joint Classification and Compression Framework
2.5. Theoretical Analysis
3. Results and Discussion
3.1. Conditional Entropies Versus Misclassification Rates
3.2. Joint Entropy Versus Misclassification Rates
3.3. Average Codeword Lengths Versus Misclassification Rates
3.4. Comparisons with Mainstream Lossless Compression Methods
- JPEG2000 [49] is an image compression standard designed to improve the performance of JPEG compression standard, albeit at the cost of increased computational complexity. Instead of using DCT in JPEG, JPEG2000 uses discrete wavelet transform (DWT).
- CALIC (Context-based, adaptive, lossless image codec) uses a large number of contexts to condition a non-linear predictor, which makes it adaptive to varying source statistics [52].
- WebP [53] is an image format currently developed by Google. WebP is based on block prediction, and a variant of LZ77-Huffman coding is used for entropy coding.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chan, C. World Malaria Report; Technical Report; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Kettelhut, M.M.; Chiodini, P.L.; Edwards, H.; Moody, A. External quality assessment schemes raise standards: Evidence from the UKNEQAS parasitology subschemes. J. Clin. Pathol. 2003, 56, 927–932. [Google Scholar] [CrossRef] [PubMed]
- Delahunt, C.B.; Mehanian, C.; Hu, L.; McGuire, S.K.; Champlin, C.R.; Horning, M.P.; Wilson, B.K.; Thompon, C.M. Automated microscopy and machine learning for expert-level malaria field diagnosis. In Proceedings of the 2015 IEEE Global Humanitarian Technology Conference (GHTC), Seattle, WA, USA, 8–11 October 2015; pp. 393–399. [Google Scholar]
- Muralidharan, V.; Dong, Y.; Pan, W.D. A comparison of feature selection methods for machine learning based automatic malarial cell recognition in wholeslide images. In Proceedings of the 2016 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Las Vegas, NV, USA, 24–27 February 2016; pp. 216–219. [Google Scholar]
- Park, H.S.; Rinehart, M.T.; Walzer, K.A.; Chi, J.T.A.; Wax, A. Automated Detection of P. falciparum Using Machine Learning Algorithms with Quantitative Phase Images of Unstained Cells. PLoS ONE 2016, 11, e0163045. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, C.S. Deep Learning for Identifying Malaria Parasites in Images. Master’s Thesis, University of Edinburgh, Edinburgh, UK, 2015. [Google Scholar]
- Quinn, J.A.; Nakasi, R.; Mugagga, P.K.B.; Byanyima, P.; Lubega, W.; Andama, A. Deep Convolutional Neural Networks for Microscopy-Based Point of Care Diagnostics. In Proceedings of the International Conference on Machine Learning for Health Care, Los Angeles, CA, USA, 19–20 August 2016. [Google Scholar]
- Center for Devices and Radiological Health. Technical Performance Assessment of Digital Pathology Whole Slide Imaging Devices; Technical Report; Center for Devices and Radiological Health: Silver Spring, MD, USA, 2015. [Google Scholar]
- Farahani, N.; Parwani, A.V.; Pantanowitz, L. Whole slide imaging in pathology: Advantages, limitations, and emerging perspectives. Pathol. Lab. Med. Int. 2015, 23–33. [Google Scholar]
- University of Alabama at Birmingham. PEIR-VM. Available online: http://peir-vm.path.uab.edu/about.php (accessed on 6 May 2019).
- Cornish, T.C. An Introduction to Digital Wholeslide Imaging and Wholeslide Image Analysis. Available online: https://docplayer.net/22756037-An-introduction-to-digital-whole-slide-imaging-and-whole-slide-image-analysis.html (accessed on 6 May 2019).
- Al-Janabii, S.; Huisman, A.; Nap, M.; Clarijs, R.; van Diest, P.J. Whole Slide Images as a Platform for Initial Diagnostics in Histopathology in a Medium-sized Routine Laboratory. J. Clin. Pathol. 2012, 65, 1107–1111. [Google Scholar] [CrossRef] [PubMed]
- Pantanowitz, L.; Valenstein, P.; Evans, A.; Kaplan, K.; Pfeifer, J.; Wilbur, D.; Collins, L.; Colgan, T. Review of the current state of whole slide imaging in pathology. J. Pathol. Inform. 2011, 2, 36. [Google Scholar] [CrossRef] [PubMed]
- Tek, F.B.; Dempster, A.G.; Kale, I. Computer vision for microscopy diagnosis of malaria. Malar. J. 2009, 8, 1–14. [Google Scholar] [CrossRef]
- World Health Organization. Microscopy. Available online: http://www.who.int/malaria/areas/diagnosis/microscopy/en/ (accessed on 6 May 2019).
- Halim, S.; Bretschneider, T.R.; Li, Y.; Preiser, P.R.; Kuss, C. Estimating malaria parasitaemia from blood smear images. In Proceedings of the IEEE International Conference on Control, Automation, Robotics and Vision, Singapore, 5–8 December 2006; pp. 1–6. [Google Scholar]
- Das, D.; Ghosh, M.; Chakraborty, C.; Pal, M.; Maity, A.K. Invariant Moment based feature analysis for abnormal erythrocyte segmentation. In Proceedings of the International Conference on Systems in Medicine and Biology (ICSMB), Kharagpur, India, 16–18 December 2010; pp. 242–247. [Google Scholar]
- Das, D.K.; Ghosh, M.; Pal, M.; Maiti, A.K.; Chakraborty, C. Machine learning approach for automated screening of malaria parasite using light microscopic images. J. Micron 2013, 45, 97–106. [Google Scholar] [CrossRef]
- Tek, F.B.; Dempster, A.G.; Kale, I. Parasite detection and identification for automated thin blood film malaria diagnosis. J. Comput. Vis. Image Underst. 2010, 114, 21–32. [Google Scholar] [CrossRef]
- Di Ruberto, C.; Dempster, A.; Khan, S.; Jarra, B. Analysis of infected blood cell images using morphological operators. J. Comput. Vis. Image Underst. 2002, 20, 133–146. [Google Scholar] [CrossRef]
- Ross, N.E.; Pritchard, C.J.; Rubin, D.M.; Duse, A.G. Automated image processing method for the diagnosis and classification of malaria on thin blood smears. Med. Biol. Eng. Comput. 2005, 44, 427–436. [Google Scholar] [CrossRef]
- Makkapati, V.V.; Rao, R.M. Segmentation of malaria parasites in peripheral blood smear images. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1361–1364. [Google Scholar]
- Tek, F.B.; Dempster, A.G.; Kale, I. Malaria parasite detection in peripheral blood images. In Proceedings of the British Machine Vision Conference 2006, Edinburgh, UK, 4–7 September 2006. [Google Scholar]
- Linder, N.; Turkki, R.; Walliander, M.; Mårtensson, A.; Diwan, V.; Rahtu, E.; Pietikäinen, M.; Lundin, M.; Lundin, J. A Malaria Diagnostic Tool Based on Computer Vision Screening and Visualization of Plasmodium falciparum Candidate Areas in Digitized Blood Smears. PLoS ONE 2014, 9, e104855. [Google Scholar] [CrossRef] [PubMed]
- Pan, W.D.; Dong, Y.; Wu, D. Classification of Malaria-Infected Cells Using Deep Convolutional Neural Networks. In Machine Learning—Advanced Techniques and Emerging Applications; Farhadi, H., Ed.; IntechOpen: London, UK, 2018. [Google Scholar] [Green Version]
- Shen, H.; Pan, W.D.; Dong, Y.; Alim, M. Lossless compression of curated erythrocyte images using deep autoencoders for malaria infection diagnosis. In Proceedings of the IEEE Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Duh, D.J.; Jeng, J.H.; Chen, S.Y. DCT based simple classification scheme for fractal image compression. Image Vis. Comput. 2005, 23, 1115–1121. [Google Scholar] [CrossRef]
- Fahmy, G.; Panchanathan, S. A lifting based system for optimal compression and classification in the JPEG2000 framework. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS 2002), Phoenix-Scottsdale, AZ, USA, 26–29 May 2002; Volume 4. [Google Scholar]
- Kim, H.; Yazicioglu, R.F.; Merken, P.; Van Hoof, C.; Yoo, H.J. ECG signal compression and classification algorithm with quad level vector for ECG holter system. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 93–100. [Google Scholar] [PubMed]
- Jha, C.K.; Kolekar, M.H. Classification and Compression of ECG Signal for Holter Device. In Biomedical Signal and Image Processing in Patient Care; IGI Global: Hershey, PA, USA, 2018; pp. 46–63. [Google Scholar]
- Minguillón, J.; Pujol, J.; Serra, J.; Ortimo, I. Influence of lossy compression on hyperspectral image classification accuracy. WIT Trans. Inf. Commun. Technol. 2000, 25. [Google Scholar] [CrossRef]
- Garcia-Vilchez, F.; Muñoz-Marí, J.; Zortea, M.; Blanes, I.; González-Ruiz, V.; Camps-Valls, G.; Plaza, A.; Serra-Sagristà, J. On the impact of lossy compression on hyperspectral image classification and unmixing. IEEE Geosci. Remote Sens. Lett. 2011, 8, 253–257. [Google Scholar] [CrossRef]
- Gelli, G.; Poggi, G. Compression of multispectral images by spectral classification and transform coding. IEEE Trans. Image Process. 1999, 8, 476–489. [Google Scholar] [CrossRef]
- Peng, K.; Kieffer, J.C. Embedded image compression based on wavelet pixel classification and sorting. IEEE Trans. Image Process. 2004, 13, 1011–1017. [Google Scholar] [CrossRef]
- Oehler, K.L.; Gray, R.M. Combining image classification and image compression using vector quantization. In Proceedings of the IEEE Data Compression Conference (DCC’93), Snowbird, UT, USA, 30 March–2 April 1993; pp. 2–11. [Google Scholar]
- Oehler, K.L.; Gray, R.M. Combining image compression and classification using vector quantization. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 461–473. [Google Scholar] [CrossRef]
- Li, J.; Gray, R.M.; Olshen, R. Joint image compression and classification with vector quantization and a two dimensional hidden Markov model. In Proceedings of the Data Compression Conference, DCC’99, Snowbird, UT, USA, 29–31 March 1999; pp. 23–32. [Google Scholar]
- Baras, J.S.; Dey, S. Combined compression and classification with learning vector quantization. IEEE Trans. Inf. Theory 1999, 45, 1911–1920. [Google Scholar] [CrossRef]
- Ayoobkhan, M.U.A.; Chikkannan, E.; Ramakrishnan, K.; Balasubramanian, S.B. Prediction-Based Lossless Image Compression. In Proceedings of the International Conference on ISMAC in Computational Vision and Bio-Engineering 2018 (ISMAC-CVB), Palladam, India, 16–17 May 2018; pp. 1749–1761. [Google Scholar]
- Fu, D.; Guimaraes, G. Using Compression to Speed Up Image Classification in Artificial Neural Networks. Available online: http://www.danfu.org/files/CompressionImageClassification.pdf (accessed on 6 October 2019).
- Andono, P.N.; Supriyanto, C.; Nugroho, S. Image compression based on SVD for BoVW model in fingerprint classification. J. Intell. Fuzzy Syst. 2018, 34, 2513–2519. [Google Scholar] [CrossRef]
- Mohanty, I.; Pattanaik, P.A.; Swarnkar, T. Automatic Detection of Malaria Parasites Using Unsupervised Techniques. In Proceedings of the International Conference on ISMAC in Computational Vision and Bio-Engineering 2018 (ISMAC-CVB), Palladam, India, 16–17 May 2018; pp. 41–49. [Google Scholar]
- Whole Slide Image Data. Available online: http://peir-vm.path.uab.edu/debug.php?slide=IPLab11Malaria (accessed on 6 May 2019).
- Dong, Y.; Jiang, Z.; Shen, H.; Pan, W.D.; Williams, L.A.; Reddy, V.V.; Benjamin, W.H.; Bryan, A.W. Evaluations of deep convolutional neural networks for automatic identification of malaria infected cells. In Proceedings of the 2017 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Orlando, FL, USA, 16–19 February 2017; pp. 101–104. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Link to the Dataset Used. Available online: http://www.ece.uah.edu/~dwpan/malaria_dataset/ (accessed on 6 May 2019).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Golomb, S. Run-length encodings (Corresp.). IEEE Trans. Inf. Theory 1966, 12, 399–401. [Google Scholar] [CrossRef] [Green Version]
- JPEG2000 Home Page. Available online: https://jpeg.org/jpeg2000/ (accessed on 6 May 2019).
- JPEG-LS Home Page. Available online: https://jpeg.org/jpegls/ (accessed on 6 May 2019).
- Weinberger, M.J.; Seroussi, G.; Sapiro, G. The LOCO-I lossless image compression algorithm: Principles and standardization into JPEG-LS. IEEE Trans. Image Process. 2000, 9, 1309–1324. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Memon, N. CALIC—A context based adaptive lossless image codec. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP-96), Atlanta, GA, USA, 9 May 1996; Volume 4, pp. 1890–1893. [Google Scholar]
- WebP Home Page. Available online: https://developers.google.com/speed/webp/ (accessed on 6 May 2019).
- Toderici, G.; O’Malley, S.M.; Hwang, S.J.; Vincent, D.; Minnen, D.; Baluja, S.; Covell, M.; Sukthankar, R. Variable Rate Image Compression with Recurrent Neural Networks. arXiv 2015, arXiv:1511.06085. [Google Scholar]
- Toderici, G.; Vincent, D.; Johnston, N.; Hwang, S.; Minnen, D.; Shor, J.; Covell, M. Full Resolution Image Compression with Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5435–5443. [Google Scholar]
- Jiang, F.; Tao, W.; Liu, S.; Ren, J.; Guo, X.; Zhao, D. An End-to-End Compression Framework Based on Convolutional Neural Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3007–3018. [Google Scholar] [CrossRef]
- Li, M.; Zuo, W.; Gu, S.; Zhao, D.; Zhang, D. Learning Convolutional Networks for Content-Weighted Image Compression. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3214–3223. [Google Scholar]
- Agustsson, E.; Tschannen, M.; Mentzer, F.; Timofte, R.; Van Gool, L. Generative Adversarial Networks for Extreme Learned Image Compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2587–2590. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Meaning |
|---|---|
| Source probability of a normal cell image | |
| Source probability of an infected cell image | |
| Conditional probability of a normal cell being correctly classified | |
| Cond. prob. of a normal cell being incorrectly classified as an infected cell | |
| Cond. prob. of an infected cell being incorrectly classified as a normal cell | |
| Cond. prob. of an infected cell being correctly classified | |
| Joint probability of a cell being normal and correctly classified | |
| Joint prob. of a cell being normal but incorrectly classified as an infected cell | |
| Joint prob. of a cell being infected but incorrectly classified as a normal cell | |
| Joint prob. of a cell being infected and correctly classified |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Pan, W.D.; Wu, D. Impact of Misclassification Rates on Compression Efficiency of Red Blood Cell Images of Malaria Infection Using Deep Learning. Entropy 2019, 21, 1062. https://doi.org/10.3390/e21111062
Dong Y, Pan WD, Wu D. Impact of Misclassification Rates on Compression Efficiency of Red Blood Cell Images of Malaria Infection Using Deep Learning. Entropy. 2019; 21(11):1062. https://doi.org/10.3390/e21111062
Chicago/Turabian StyleDong, Yuhang, W. David Pan, and Dongsheng Wu. 2019. "Impact of Misclassification Rates on Compression Efficiency of Red Blood Cell Images of Malaria Infection Using Deep Learning" Entropy 21, no. 11: 1062. https://doi.org/10.3390/e21111062