
Examining the Efficacy of ChatGPT in Marking Short-Answer Assessments in an Undergraduate Medical Program
 , ,
, ,  ,
,
Abstract
:1. Introduction
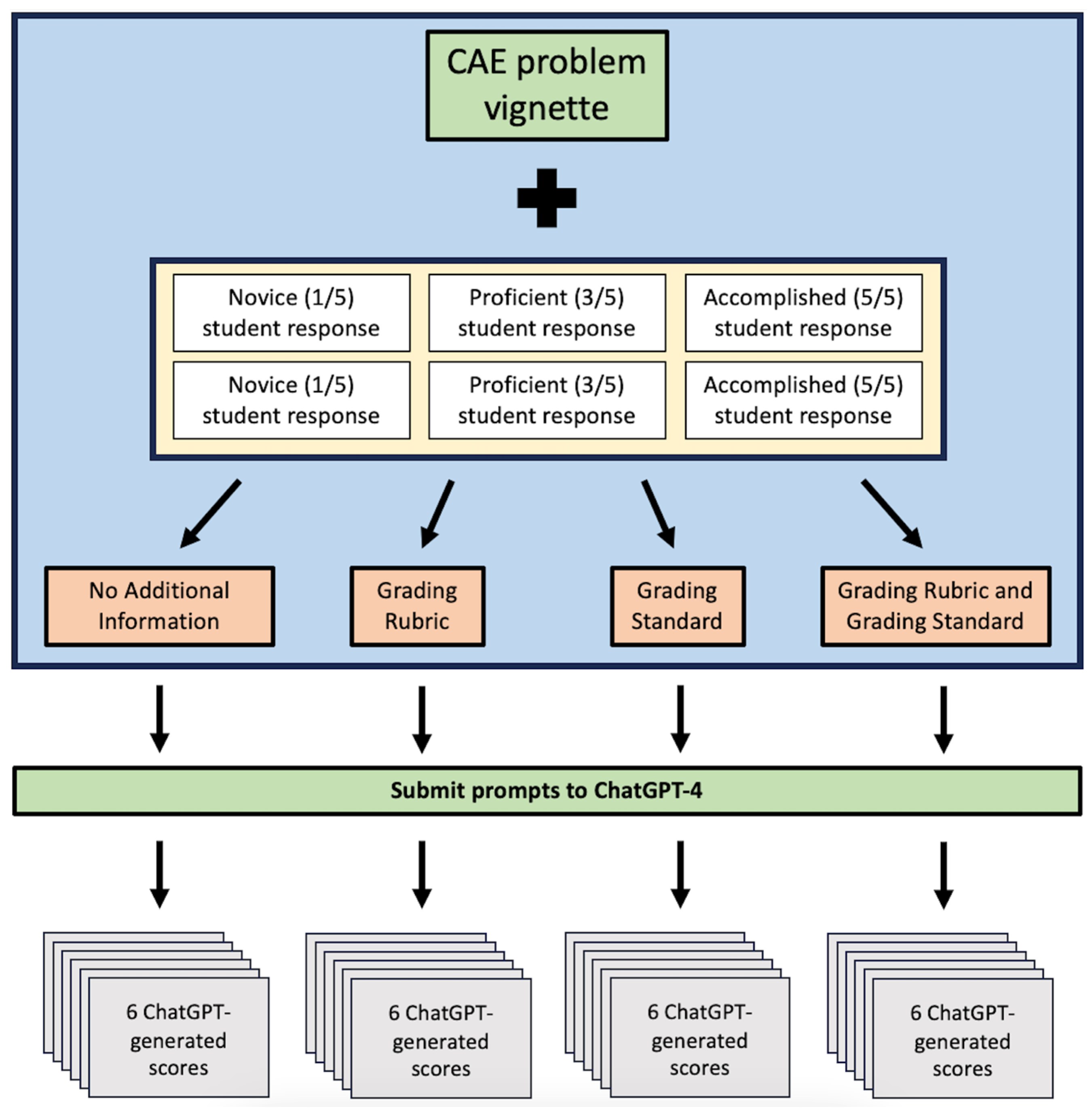
2. Materials and Methods
2.1. Context
2.2. Data Collection
2.3. Analysis
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wartman, S.; Combs, C.D. Reimagining Medical Education in the Age of AI. AMA J. Ethics 2019, 21, E146–E152. [Google Scholar] [CrossRef] [PubMed]
- Masters, K. Artificial intelligence in medical education. Med. Teach. 2019, 41, 976–980. [Google Scholar] [CrossRef] [PubMed]
- Khan, R.A.; Jawaid, M.; Khan, A.R.; Sajjad, M. ChatGPT—Reshaping medical education and clinical management. Pak. J. Med. Sci. 2023, 39, 605. [Google Scholar] [CrossRef] [PubMed]
- Lee, H. The rise of ChatGPT: Exploring its potential in medical education. Anat. Sci. Educ. 2023, ase.2270. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Kumah-Crystal, Y.; Mankowitz, S.; Embi, P.; Lehmann, C.U. ChatGPT and the clinical informatics board examination: The end of unproctored maintenance of certification? J. Am. Med. Inform. Assoc. 2023, 30, 1558–1560. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Humar, P.; Asaad, M.; Bengur, F.B.; Nguyen, V. ChatGPT Is Equivalent to First-Year Plastic Surgery Residents: Evaluation of ChatGPT on the Plastic Surgery In-Service Examination. Aesthet. Surg. J. 2023, 43, NP1085–NP1089. [Google Scholar] [CrossRef]
- Huynh, L.M.; Bonebrake, B.T.; Schultis, K.; Quach, A.; Deibert, C.M. New Artificial Intelligence ChatGPT Performs Poorly on the 2022 Self-assessment Study Program for Urology. Urol. Pract. 2023, 10, 409–415. [Google Scholar] [CrossRef]
- Morreel, S.; Mathysen, D.; Verhoeven, V. Aye, AI! ChatGPT passes multiple-choice family medicine exam. Med. Teach. 2023, 45, 665–666. [Google Scholar] [CrossRef] [PubMed]
- Cohen, A.; Alter, R.; Lessans, N.; Meyer, R.; Brezinov, Y.; Levin, G. Performance of ChatGPT in Israeli Hebrew OBGYN national residency examinations. Arch. Gynecol. Obstet. 2023, 308, 1797–1802. [Google Scholar] [CrossRef] [PubMed]
- Borchert, R.J.; Hickman, C.R.; Pepys, J.; Sadler, T.J. Performance of ChatGPT on the Situational Judgement Test—A Professional Dilemmas–Based Examination for Doctors in the United Kingdom. JMIR Med. Educ. 2023, 9, e48978. [Google Scholar] [CrossRef] [PubMed]
- Cheung, B.H.H.; Lau, G.K.K.; Wong, G.T.C.; Lee, E.Y.P.; Kulkarni, D.; Seow, C.S.; Wong, R.; Co, M.T.H. ChatGPT versus human in generating medical graduate exam multiple choice questions—A multinational prospective study (Hong Kong S.A.R., Singapore, Ireland, and the United Kingdom). PLoS ONE 2023, 18, e0290691. [Google Scholar] [CrossRef]
- Kao, Y.S.; Chuang, W.K.; Yang, J. Use of ChatGPT on Taiwan’s Examination for Medical Doctors. Ann. Biomed. Eng. 2023. [Google Scholar] [CrossRef] [PubMed]
- Friederichs, H.; Friederichs, W.J.; März, M. ChatGPT in medical school: How successful is AI in progress testing? Med. Educ. Online 2023, 28, 2220920. [Google Scholar] [CrossRef]
- Takagi, S.; Watari, T.; Erabi, A.; Sakaguchi, K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: Comparison Study. JMIR Med. Educ. 2023, 9, e48002. [Google Scholar] [CrossRef]
- Alfertshofer, M.; Hoch, C.C.; Funk, P.F.; Hollmann, K.; Wollenberg, B.; Knoedler, S.; Knoedler, L. Sailing the Seven Seas: A Multinational Comparison of ChatGPT’s Performance on Medical Licensing Examinations. Ann. Biomed. Eng. 2023. [Google Scholar] [CrossRef]
- Bird, J.B.; Olvet, D.M.; Willey, J.M.; Brenner, J. Patients don’t come with multiple choice options: Essay-based assessment in UME. Med. Educ. Online 2019, 24, 1649959. [Google Scholar] [CrossRef]
- Tabish, S.A. Assessment methods in medical education. Int. J. Health Sci. 2008, 2, 3–7. [Google Scholar]
- Sinha, R.K.; Deb Roy, A.; Kumar, N.; Mondal, H. Applicability of ChatGPT in Assisting to Solve Higher Order Problems in Pathology. Cureus 2023, 15, e35237. [Google Scholar] [CrossRef] [PubMed]
- Das, D.; Kumar, N.; Longjam, L.A.; Sinha, R.; Roy, A.D.; Mondal, H.; Gupta, P. Assessing the Capability of ChatGPT in Answering First- and Second-Order Knowledge Questions on Microbiology as per Competency-Based Medical Education Curriculum. Cureus 2023, 15, e36034. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Bir, A. Evaluating ChatGPT’s Ability to Solve Higher-Order Questions on the Competency-Based Medical Education Curriculum in Medical Biochemistry. Cureus 2023, 15, e37023. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, M.; Sharma, P.; Goswami, A. Analysing the Applicability of ChatGPT, Bard, and Bing to Generate Reasoning-Based Multiple-Choice Questions in Medical Physiology. Cureus 2023, 15, e40977. [Google Scholar] [CrossRef] [PubMed]
- Ayub, I.; Hamann, D.; Hamann, C.R.; Davis, M.J. Exploring the Potential and Limitations of Chat Generative Pre-trained Transformer (ChatGPT) in Generating Board-Style Dermatology Questions: A Qualitative Analysis. Cureus 2023, 15, e43717. [Google Scholar] [CrossRef]
- Neville, A.J.; Cunnington, J.; Norman, G.R. Development of clinical reasoning exercises in a problem-based curriculum. Acad. Med. 1996, 71, S105–S107. [Google Scholar] [CrossRef]
- Norman, G. Likert scales, levels of measurement and the “laws” of statistics. Adv. Health Sci. Educ. 2010, 15, 625–632. [Google Scholar] [CrossRef]
- Morjaria, L.; Burns, L.; Bracken, K.; Ngo, Q.N.; Lee, M.; Levinson, A.J.; Smith, J.; Thompson, P.; Sibbald, M. Examining the Threat of ChatGPT to the Validity of Short Answer Assessments in an Undergraduate Medical Program. J. Med. Educ. Curric. Dev. 2023, 10, 23821205231204178. [Google Scholar] [CrossRef]
- Xie, Y.; Seth, I.; Hunter-Smith, D.J.; Rozen, W.M.; Seifman, M.A. Investigating the impact of innovative AI chatbot on post-pandemic medical education and clinical assistance: A comprehensive analysis. ANZ J. Surg. 2023, ans.18666. [Google Scholar] [CrossRef]
- Wang, H.; Wu, W.; Dou, Z.; He, L.; Yang, L. Performance and exploration of ChatGPT in medical examination, records and education in Chinese: Pave the way for medical AI. Int. J. Med. Inf. 2023, 177, 105173. [Google Scholar] [CrossRef] [PubMed]
- Karabacak, M.; Ozkara, B.B.; Margetis, K.; Wintermark, M.; Bisdas, S. The Advent of Generative Language Models in Medical Education. JMIR Med. Educ. 2023, 9, e48163. [Google Scholar] [CrossRef] [PubMed]
- Fischetti, C.; Bhatter, P.; Frisch, E.; Sidhu, A.; Helmy, M.; Lungren, M.; Duhaime, E. The Evolving Importance of Artificial Intelligence and Radiology in Medical Trainee Education. Acad. Radiol. 2022, 29, S70–S75. [Google Scholar] [CrossRef] [PubMed]
- Winkler-Schwartz, A.; Bissonnette, V.; Mirchi, N.; Ponnudurai, N.; Yilmaz, R.; Ledwos, N.; Siyar, S.; Azarnoush, H.; Karlik, B.; Del Maestro, R.F. Artificial Intelligence in Medical Education: Best Practices Using Machine Learning to Assess Surgical Expertise in Virtual Reality Simulation. J. Surg. Educ. 2019, 76, 1681–1690. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; AlSaad, R.; Alhuwail, D.; Ahmed, A.; Healy, P.M.; Latifi, S.; Aziz, S.; Damseh, R.; Alrazak, S.A.; Sheikh, J. Large Language Models in Medical Education: Opportunities, Challenges, and Future Directions. JMIR Med. Educ. 2023, 9, e48291. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Vignette | You are seeing Henry Baker and Ali Khan in follow-up in your office. You review your notes from the previous visit. Mr. Baker is a 57-year-old man with chronic musculoskeletal pain, the causes of which are multifactorial. He has used a number of different medications in the past including both long-acting Oxycodone and short-acting Oxycodone for flare-ups. Ali is an 8-year-old boy with cerebral palsy who experiences pain with vomiting. Vomiting usually follows straining with passing a bowel motion, one to two times weekly. Ali recently began treatment for gastroesophageal reflux disease. Henry Baker and Ali Khan both experience pain, however they are experiencing different types of pain with different characteristics. Provide a brief description of the relevant nociceptive pathways that contribute to each patient’s pain. |
| Rubric | Henry Baker: Chronic somatic pain arising from the musculoskeletal system with hyperalgesia; multiple contributing factors. Nociception via somatic A-delta and C-fibers, enters the CNS via the dorsal horn and synapses at second order neurons in Lamina II (Substantia Gelatinosa). There is enhanced transmission of nociceptive impulses due to nociplastic changes within the CNS arising from enhanced NMDA receptor activation, neurogenic inflammation, loss of segmental and supraspinal inhibitory control and probably opioid-induced hyperalgesia. Pain is then transmitted supraspinally via the spinothalamic tracts and spinoreticular tracts to the thalamus for both tracts and also to the parabrachial nuclei and amygdala for the spinoreticular tract. Ultimately projection onto the sensory cortex results in perception of pain, however this will be exaggerated and provoke significant additional distress in the case of this patient. Ali Khan: Acute bouts of visceral pain arising from distention or spasm of elements of the GI tract. This may involve the esophagus or stomach as GERD is present and gastric distension may be a factor in vomiting. Potentially the large bowel or rectum may be involved since constipation is suggested on history. Nociception is via thinly myelinated A-delta and C-fibers, but these travel with autonomic nerves towards the CNS. In the case of the esophagus and stomach this is shared with the vagus nerve (parasympathetic) and sympathetic fibers to the celiac plexus and then to the sympathetic chain with segmental input into the spinal cord from about T5-12. In the case of the large bowel this too can be via sympathetic pathways; Inferior mesenteric ganglion via sympathetic chain to L1-3 levels, also some towards celiac plexus via superior mesenteric ganglion. The rectum is innervated by the sacral parasympathetic fibers to S2-4. It is noteworthy that the sparse innervation by nociceptors on the viscera, and their inputs diverging widely into the CNS result in poorly localized pain and contribute to the phenomenon of referred pain. Novice: The student will be able to describe some of the major differences between somatic and visceral nociception, specifically the course of visceral nociception along autonomic fibers, and the poor localization of visceral pain. They will be able to describe some of the key elements of the nociceptive pathways. They will be able to identify that chronic pain and opioid use may result in hyperalgesia. Proficient: In addition to the components of a novice response, the student will be able to provide further details of the afferent pathways pertaining to the different portions of the GI tract, differentiating between sympathetic and parasympathetic input, and naming a reasonable portion of the nerves and structures involved, and correlate them to Ali Khan’s clinical presentation. The students will be able to describe how A-delta and C-fibers synapse within the spinal cord, name the ascending spinal pathways, and their connection to the thalamus. There will be some understanding and description of nociplastic changes in the pain pathways resulting in enhanced nociception in the case of Henry Baker. Accomplished: Further to a proficient response, there will be a more detailed and complete account of somatic and visceral nociception and the processes involved in hyperalgesia, referred pain, and evidence of clinical correlation with the two cases. Though not expected of the students, reference to descending inhibition via the periaqueductal gray, and more detailed reference to structures in the brain making up the “Pain Matrix” beyond the thalamus can suggest a more accomplished response if some details are lacking otherwise. |
| Score | Proficiency Level | Score Description |
|---|---|---|
| 5 | Accomplished | Student was able to describe a deep and complete understanding of the concepts/mechanisms and was able to explain how new information or concepts related to topics discussed in previous subunits or foundations, or encountered in other areas of the program. Mastered the learning objectives of the MF. |
| 4 | Student demonstrated a comprehensive understanding of the concepts/mechanisms central to the MF. Demonstrated excellent organization and integration of material. Demonstrated superior achievement of the learning objectives in the MF. | |
| 3 | Proficient (passing score) | Student was able to describe the key concepts/mechanisms to a degree sufficient for the MF. Demonstrated an understanding of the importance or relevance of the concepts/mechanisms. Information was appropriately organized and prioritized. Demonstrated acceptable achievement of the learning objectives of the MF. Most students’ responses on CAE questions are expected to be consistent with this level of achievement. |
| 2 | Novice | Student was able to describe most but not all of the key concepts/mechanisms. Understanding of some of the material was incomplete. Student was in the early stages of achieving the learning objectives in the MF. |
| 1 | Student was able to describe some but not all of the concepts/mechanisms. Seemed unclear/uncomfortable with at least some of the material. Understanding of some concepts was superficial. Difficulty organizing and prioritizing information. Achievement of the learning objectives of the MF was not yet adequate. |
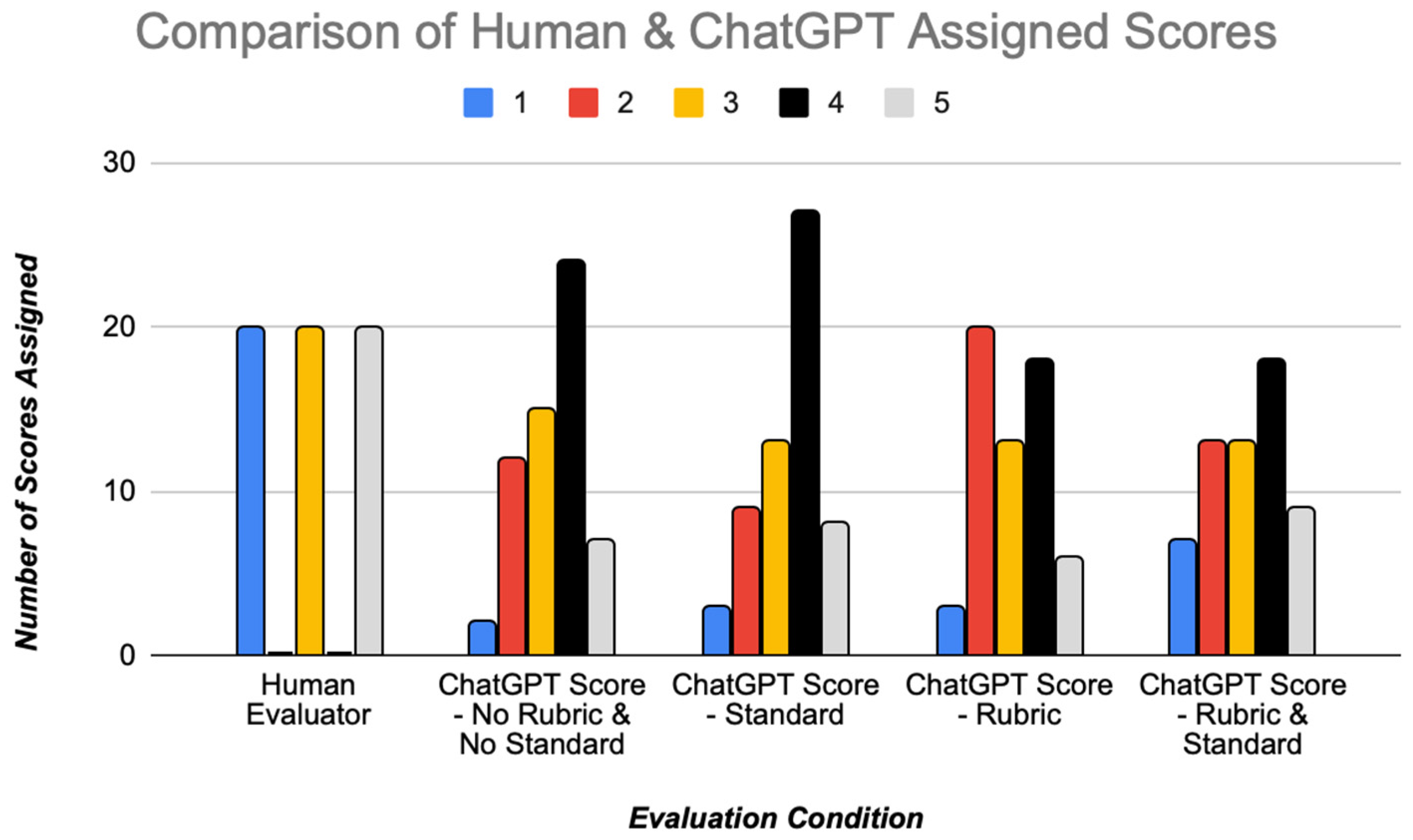
| Evaluation Condition | Mean | Std. Error | 95% CI | Mean Difference | Std. Error | p-Value | |
|---|---|---|---|---|---|---|---|
| Human-Assigned Score | N/A | 3.00 | 0.21 | (2.58, 3.43) | N/A | N/A | N/A |
| ChatGPT-Assigned Score | No Rubric and No Standard | 3.37 | 0.13 | (3.10, 3.64) | −0.37 | 0.15 | 0.015 |
| Standard Only | 3.47 | 0.48 | (3.19, 3.74) | −0.47 | 0.17 | 0.008 | |
| Rubric Only | 3.07 | 0.14 | (2.78, 3.36) | −0.07 | 0.16 | 0.67 | |
| Rubric and Standard | 3.15 | 0.16 | (2.83, 3.48) | −0.15 | 0.17 | 0.37 |
| Average ChatGPT-Assigned Scores | No Rubric and No Standard | Standard Only | Rubric Only | Rubric and Standard | |||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Stdev | Mean | Stdev | Mean | Stdev | Mean | Stdev | ||
| Tutor Rating | 1 (Novice) | 2.30 | 0.66 | 2.55 | 0.94 | 2.00 | 0.65 | 2.00 | 0.86 |
| 3 (Proficient) | 3.65 | 0.81 | 3.75 | 0.85 | 3.35 | 1.04 | 3.50 | 1.10 | |
| 5 (Accomplished) | 4.15 | 0.59 | 4.10 | 0.72 | 3.85 | 0.67 | 3.95 | 0.89 | |
| Correlation coefficient (with 95% CI) | 0.732 (0.587, 0.831) p < 0.001 | 0.599 (0.407, 0.740) p < 0.001 | 0.681 (0.517, 0.797) p < 0.001 | 0.637 (0.457, 0.767) p < 0.001 | |||||
| Scoring Difference | No Rubric and No Standard | Standard Only | Rubric Only | Rubric and Standard |
|---|---|---|---|---|
| −4 | 0 | 0 | 0 | 0 |
| −3 | 0 | 7 | 10 | 2 |
| −2 | 3 | 22 | 27 | 10 |
| −1 | 25 | 17 | 20 | 18 |
| 0 | 20 | 33 | 35 | 27 |
| +1 | 35 | 17 | 7 | 30 |
| +2 | 17 | 5 | 2 | 12 |
| +3 | 0 | 0 | 0 | 2 |
| +4 | 0 | 0 | 0 | 0 |
| Change by 1 or more points (%) | 80 | 67 | 65 | 73 |
| Change by 2 or more points (%) | 20 | 33 | 38 | 25 |
| Change by 1 or more marking categories (%) | 42 | 57 | 34 | 45 |
| Evaluation Condition | Concept | Illustrative Quotes from ChatGPT Comments |
|---|---|---|
| All Conditions | Depth of understanding | “This student thoroughly considers both central and peripheral causes of vertigo” “This response provides an in-depth explanation of both the thyroid uptake and thyroid scan but contains a few errors and confusions in the explanations” “However, the explanation lacks depth in describing the clinical relevance in Maria’s case”. |
| Accuracy | “The response correctly acknowledges that genetics can play a role in cancer, but the assertion that ‘His cancer risk is high because 3 of his first relatives were diagnosed with cancer’ might be an oversimplification”. “Accuracy: Correct information regarding the ascending and descending pathways and opioid effects”. “The mention of BRCA genes in relation to Mr. Steel’s family history is accurate, but the connection between BRCA and melanoma is not clear”. | |
| Completeness | “Overall, it’s a strong response with a slight lack of completeness in the second part”. “Completeness: The student emphasizes the importance of UV exposure and the need for shared decision-making”. | |
| No Rubric and No Standard | Organization | “The response may be slightly less organized, and there’s some ambiguity in Ali’s description, with the student noting a lack of case information”. “The answer might benefit from a more structured and clear presentation of the physiological mechanisms involved”. |
| Standard Only | Thoroughness of knowledge | “The response is thorough and emphasizes the biological and social factors contributing to the pain experienced by Henry Baker and Ali Khan”. |
| Rubric Only | Meeting of criteria | “The student correctly identifies Angiotensin II’s role in the RAAS system and its impact on fluid retention. However, the explanation regarding its effect on the afferent and efferent arterioles is not as detailed as in the guide, and the student doesn’t mention ACE inhibitors’ impact on GFR or provide the expected side effect”. “This answer is thorough and matches much of the evaluation guide” |
| Rubric and Standard | Combination of success on both evaluation frameworks | “Demonstrates an understanding of the potential benefits of genetic testing for family members and not just the patient. Recognizes the importance of genetics but also acknowledges the multifactorial causes of cancer. Provides a balanced perspective of risks and benefits. Rating: 3 (Proficient)—This student sufficiently describes the key concepts and prioritizes the importance of genetics and other factors but doesn’t dive deep into specifics or the broader understanding of cancer genetics”. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morjaria, L.; Burns, L.; Bracken, K.; Levinson, A.J.; Ngo, Q.N.; Lee, M.; Sibbald, M. Examining the Efficacy of ChatGPT in Marking Short-Answer Assessments in an Undergraduate Medical Program. Int. Med. Educ. 2024, 3, 32-43. https://doi.org/10.3390/ime3010004
Morjaria L, Burns L, Bracken K, Levinson AJ, Ngo QN, Lee M, Sibbald M. Examining the Efficacy of ChatGPT in Marking Short-Answer Assessments in an Undergraduate Medical Program. International Medical Education. 2024; 3(1):32-43. https://doi.org/10.3390/ime3010004
Chicago/Turabian StyleMorjaria, Leo, Levi Burns, Keyna Bracken, Anthony J. Levinson, Quang N. Ngo, Mark Lee, and Matthew Sibbald. 2024. "Examining the Efficacy of ChatGPT in Marking Short-Answer Assessments in an Undergraduate Medical Program" International Medical Education 3, no. 1: 32-43. https://doi.org/10.3390/ime3010004