1. Introduction
The adoption of software has been progressively observed in the control of various systems, including—but not limited to—automotive software [
1], urban traffic management [
2], and disaster monitoring [
3]. However, despite advancements, the occurrence of coding errors leading to software bugs remains. Such software bugs can yield substantial economic losses, pose threats, and even compromise the well-being of users’ integrity [
4,
5]. Consequently, both researchers and practitioners have invested efforts in the establishment of mechanisms aimed at diminishing the frequency of bugs and enhancing the quality of the delivered software product. In that context, the pivotal role of software testing and debugging (STD) cannot be overstated. Software testing is the systematic process of evaluating a software application to identify defects and ensure it meets specified requirements; whilst debugging is the process of locating and fixing defects or errors in a software program to restore its intended functionality [
6]. These activities constitute fundamental steps of software quality assurance, addressing the identification and rectification of software faults [
7,
8,
9,
10,
11]. Nonetheless, these activities are frequently labor-intensive, prone to errors, and time-demanding, with their complexity escalating when undertaken manually and as the scale of software projects amplifies [
12]. In this vein, STD techniques have been automated with the generation of test cases, pinpointing faults, and facilitating program repair [
10,
13,
14,
15].
Benchmarks recurrently support the evaluation of STD techniques [
16]. In the context of STD techniques, benchmarks comprise a set of programs, faulty versions of these programs, a suite of test cases, and bug reports or logs of test case executions. They can be used to evaluate the effectiveness of those techniques to achieve their aims, such as finding a fault [
17]. A remarkable and popular instance of a benchmark for that context is Defects4J, which is made up of six Java programs with 438 real bugs and test cases that cover the faulty code. Benchmarks are well-accepted means in the state of the practice to support the evaluation of STD techniques [
18,
19]. Benchmarks can increase the reliability of the results obtained from the evaluation of STD techniques because they (i) work as a reference to compare the results delivered by different techniques, (ii) allow replication of the evaluation so that other researchers can reproduce the experiment applied in the evaluation and confirm (or refute) its results, and (iii) reduce threats to the validity of results by bringing a more systematic evaluation and producing data for future evaluation. Indeed, some recent literature reviews have included sections exclusively devoted to benchmarks and have presented examples of studies that use benchmarks in their projects [
18,
19]. However, studies that discuss aspects that motivate or guide the proposition of benchmarks are scarce.
The main contribution of this article is providing an overview of the reasons that have led researchers and practitioners to propose new benchmarks over the years. We analyze the state of the art by using the systematic mapping (SM) approach to collect evidence on this topic [
20]. A total of 25 out of the initially retrieved 1674 studies were included and analyzed. The results reveal that (i) benchmarks have predominantly been proposed for software testing, bug diagnosis, and program repair, with fewer allocations for fault localization. (ii) Over a span of ten years, nine benchmarks were introduced, while the subsequent five years witnessed a notable increase to sixteen, emphasizing their pivotal role in technique evaluation. (iii) Approximately 50% of studies featured benchmarks exclusive to C or Java, while the remainder spanned language diversity. (iv) A substantial 92% of proposed benchmarks integrated real bugs sourced from controlled or production environments. (v) Benchmarks primarily arose due to factors including data absence, the imperative for authentic data, the scarcity of specialized data, incomplete bug understanding, and spontaneous result data provision.
The remainder of the article is organized as follows:
Section 2 establishes a common vocabulary for our research by presenting useful definitions and a background;
Section 3 presents the SM protocol and reporting.
Section 4 presents a summary of contributions and research opportunities extracted from our SM;
Section 5 and
Section 6 conclude this study by discussing threats to validity and final remarks, respectively.
2. Background
Software development is a costly and complex activity. The process involves humans and it is subject to their interpretation, which can lead to
mistakes (i.e., a misinterpretation of the requirements). In turn, mistakes can lead to
defects (
faults) in the code, i.e., an implementation that does not conform to the requirements; and defects in the code can lead to
failures, i.e., program executions that do not match the expected behavior and that generate a perception of one or more defects [
21].
Software testing plays an essential role in software quality [
9]. Unlike static testing, which focuses on reviewing software artifacts such as requirements documents, test plans, and code, dynamic testing is mainly concerned with revealing failures by executing the program. Benchmarks are used frequently in dynamic testing studies. Then, henceforth, we use the term
software testing to refer to dynamic testing. Software testing involves the elaboration and execution of test cases [
21]. Testing software, therefore, involves verifying the behavior delivered during code execution in response to a finite set of test cases. The set of test cases is made up of all possible inputs of a program (input domain) and its expected outputs [
22]. Software is tested in practice through two techniques: functional tests and structural tests [
11]. Functional tests deal with software code as a “black box” (that is, without the tester’s awareness of the internal logic of the software), where possible inputs are provided and evaluated to detect whether the code is being developed in accordance with the stakeholders’ aims. Structural tests, however, handle software as a “white box”, highlighting the internal structure and operation from a developer’s perspective. Structural tests are complementary to functional testing techniques and are used to establish and contribute to software quality, both in internal aspects and to meet requirements [
21,
23]. When the test activities expose failures, the debugging process starts.
The debugging process may be structured into three steps, (i) defect localization, (ii) defect understanding (bug diagnosis), and (iii) defect/program repair [
24,
25,
26]. According to Hailpern et al. [
10], software debugging involves analyzing and modifying a program that does not match its specifications. Thus, the primary goal is to establish a new version of the program that is close enough to the original one but satisfies the previously violated requirements. The first activity (
defect localization), also called fault localization (FL), consists of the precise determination of the location of the defect in the program; the second one (
defect understanding) is related to obtaining knowledge about the fault and its behavior; the last step (
program repair) consists of repairing the defect. Debugging is a time-consuming activity, which motivates the adoption of automated methods to proceed with its inherent steps.
Automated fault localization (FL) techniques are those used in software development to identify the locations or lines of code that are responsible for causing defects or errors in a software program. These techniques aim to narrow down the search for the root cause of a bug, making it easier for developers to locate and fix the issue. By automatically pinpointing faulty code, FL techniques expedite the debugging process and improve the efficiency of software maintenance. Some of the most popular automated fault localization techniques include (i) spectrum-based techniques, which analyze the program’s execution traces, such as test coverage information or execution frequencies, to identify code segments associated with failing test cases. Examples include Tarantula, Ochiai, and DStar; (ii) statistical debugging, which analyzes historical debugging data to identify patterns or correlations between code and defects. Examples include delta debugging and probabilistic models; (iii) mutation-based techniques, which involve creating small changes (mutations) in the code to simulate defects and assess the effectiveness of test cases; (iv) data flow analysis, which tracks how data flows through the program to identify potential error propagation paths and isolate faulty code; (v) constraint-solving techniques, which formulate the debugging problem as a constraint satisfaction problem and use automated solvers to narrow down the possible fault locations; (vi) search-based techniques, which map fault localization to a search problem and explore the code space systematically to find the most likely fault locations; (vii) machine learning-based techniques, which adopt machine learning algorithms to predict potential fault locations in new code; and (viii) program slicing, which involves extracting a subset of codes that directly influence a specific program behavior, aiding in identifying the root cause of defects.
As the first part of the process of debugging, the FL activity aims to indicate the code portions with a high probability of containing the defect. The most popular techniques of automated FL use the information from the test case coverage provided by test case executions. Heuristics are then applied to the coverage data to indicate suspicious code. In addition to reducing costs and increasing the reliability of software, automated FL techniques include a low degree of human intervention in the FL process. Subsequently, once faults are located, the activity to diagnose the defect and understand its behavior starts. The experience of previously known bugs may help the debugging expert to understand the fault already found. Also, the reports generated by developers are an indication of the bug type in some cases; such analysis may support fault correction.
The third step of debugging involves program repair. Program repair consists of the replacement of faulty code by a corrected version of it. This activity is usually manual and repetitive, which leads to the adoption of automated methods, the so-called
automated program repair (APR). APR proposes and adopts automated software bug fixes. APR uses a set of tests to guide the repair process, thereby ensuring better code quality and lower maintenance costs, producing a variant of the program that meets the project specifications. Traditional APR consists of the generation of corrections and validation. FL techniques are performed to identify suspicious code fragments [
27]. Once the fragment was identified, APR techniques can generate corrections. Then, the created code is submitted again to the same set of tests to ensure it is still conforming to them. Fail test cases (reproducing failures), and success test cases (characterizing expected behaviors) are commonly used to validate the correction of the candidate fix [
27]. This procedure is repeatedly performed until a valid variant of the buggy code is found.
Novel fault localization and APR techniques are often proposed. To be reliable, they should be assessed and compared with the existing techniques in the state of the art. For this purpose, a common code foundation and a set of test cases are required to yield results that can serve as a comparison baseline among various techniques. The set of programs used for this purpose is often referred to as benchmarks. The IBM Dictionary of Computing [
17] defines a benchmark as a reference point in which measures can be applied to evaluate software or hardware. In STD, benchmarks are usually a group of programs with some representation of real-world environments along with all the necessary instruments or characteristics of the techniques under evaluation. For instance, these instruments may be an available test case set, available source code, programs in a specific programming language, or a specific number of lines of code (LoC).
The Siemens Suite (SS) [
28] is an example of an artifact that was not built to be specifically used as a benchmark but has become popular and frequently used for FL activities [
29]. It consists of a reduced set of small-sized programs in C formed by seven programs and the largest one has less than 500 LoC. The bugs were artificially inserted in the SS programs through code mutation techniques. These artificial bugs are useful for simulating some real defects [
30], although there are real bugs that are not reachable by inserting single, small faults (first-order mutations), such as a replacement of logical or arithmetic operators [
31]. As the software FL improved, the programs used to demonstrate FL methods also had to be changed, to show the benefits in industry-like environments [
18]. When a novel FL technique is proposed, besides comparing its results to real buggy programs, it is common to use SS as well as a comparison parameter.
The APR community maintains a website ([
32]) where they suggest that the benchmarks
Defects4J [
33],
Codeflaws [
34], and
IntroClass and ManyBugs [
35] be used in research studies. These benchmarks contain real bugs and are often used to apply FL techniques. Although several benchmarks exist, novel benchmarks are still being proposed, which raises the following question:
why are existing benchmarks not enough? The following section presents the protocol developed to guide an investigation on this topic.
For the scope of this article, two terms are important:
motivation and
scope of use. The
motivation for creating a benchmark is understood as what lack has motivated the creation of new benchmarks, such as lack of data or benchmarks composed of code excerpts/programs to enable the testing of a specific platform, technology, or programming language; whilst the
scope of use of the creation of a novel benchmark should be understood as the final target of application for the created benchmark, for instance, for an entire community or a particular research group. An example of motivation for creating a new benchmark is the multi-threaded Java programs [
36]. Initially, there were no real programs to be used as benchmarks. Then, artificial defects were seeded in multi-threaded codes to create the preliminary benchmarks until codes with real bugs were provided to be used. Examples of benchmarks for different scopes of use include Defects4J [
33] and the benchmark by Jooyong Yi et al. benchmark [
34]. The former benchmark was created and delivered for the entire community, whilst the latter was created for the specific scope of research.
3. Systematic Mapping Study
This SM was structured according to the guidelines of Kitchenham and Charters, and Petersen et al. [
20,
37]. The main steps involved
planning,
conduction, and
reporting, as follows.
3.1. Planning
In the planning step, the research questions were established, and the research protocol was defined.
The goal of this SM was to present the state of art on software testing and debugging benchmarks along with a comprehensive analysis of the motivations behind their creation. Hence, the studies of interest include those that introduce benchmarks in the context of STD techniques.
From the established goal, the following research questions (RQ) were defined.
RQ1: What are the proposed benchmarks for STD and their target topics?
Rationale: By answering this RQ, we aim to provide a list of benchmarks to support researchers in selecting the benchmarks that they could use to exercise their novel STD techniques empirically. Moreover, answering RQ1 also provides a classification of the reported benchmarks according to their target topics, i.e., the context for which it was proposed. The target topics include software testing, bug diagnosis, program repair, and fault localization.
RQ4: What were the identified motivations for proposing the benchmarks?
Rationale: Benchmarks are built to match a set of intentions. This RQ aims to reveal the main motivations and needs that lead the community to create the benchmarks reported in the included studies.
RQ5: What was the identified scope of use for the proposed benchmarks?
Rationale: The aim of answering this RQ is to map the scope of use that led researchers to create benchmarks, as discussed at the beginning of this section.
3.1.1. Search Strategy
A control group was selected, a search string was elaborated, and online databases were chosen to proceed with an automatic search.
Search databases. We conducted searches in the following databases by applying filters on the titles, abstracts, and keywords. The databases were selected between the most common publication databases used to conduct systematic literature studies in software engineering [
38,
39]. The chosen databases comply with the recommendations made by Kitchenham and Charters [
37] and Petersen et al. [
40].
Control studies. The program repair community website provides a set of benchmarks considered relevant for the area [
32]. Apart from benchmarks, the website also provides the corresponding study that reports each benchmark proposition. We used that set of studies as a control group, i.e., a set of studies that should be retrieved by the elaborated search string. The control group includes the following benchmarks.
Manybugs and IntroClass [
35];
Search string and calibration. For the search string elaboration, we adopted the key terms used in the research questions, synonyms, and variations. Initially, the scope of research focused on benchmarks for software debugging, once the use of the word “testing” in the search string could retrieve an intractable number of studies. Then, this word was avoided at the first moment. The search string in the first try was:
“benchmark” AND “software” AND (“fault localization” OR “repair”)
The result was 192 studies from Engineering Village, 248 from Scopus, 128 from IEEE Xplore, and 176 from ACM DL; 744 studies is a reasonable number of studies, but unfortunately, some of the control group elements (e.g., Defects4J [
33]) were originally proposed for software testing and were not retrieved using this string. So we had to expand the scope with the term “testing”. Also, while the control group was retrieved, this also resulted in more than 4000 results in each base. To narrow it down to only software testing that looks for bugs, we added the term “buggy”, resulting in the final search string presented previously. Hence, the words
“benchmark”,
“software”, and either
“testing” or
“debugging” are expected to appear in the relevant primary studies. Since FL and software repair studies might not explicitly use the word
“debugging”, the terms
“fault localization’’ and
“repair” were also included. Furthermore, a term to represent bugs, such as
“buggy”, is expected; for instance, while referring to the number of buggy programs in one benchmark. Thus, the following search string was built:
“benchmark” AND “software” AND (“fault localization” OR “repair” OR “testing” OR “debugging”) AND “buggy”
After identifying relevant synonyms to each term, the string evolved into:
(“benchmark” OR “benchmarking” OR “dataset” OR “dataset” OR “database” OR “datasets” OR “datasets” OR “benchmarks”) AND (“software” OR “program”) AND ((“fault localization” OR “error localization” OR “defect localization” OR “bug localization” OR “error localisation” OR “defect localisation” OR “bug localisation” OR “fault localisation”) OR (“software repair” OR “software fixing” OR “program repair” OR “program fixing” OR “bug fixing” OR “bug-fixing” OR “automatic repair”) OR (“software testing” OR “software test”) OR (“software debugging”)) AND (“bug” OR “defect” OR “buggy” OR “faulty” OR “failing” OR “failed” OR “bugs” OR “defects”)
3.1.2. Selection Criteria
We consider that a study proposes a benchmark when it exposes the obtainment of a new dataset or the grouping of information from different benchmarks. The study should also provide a URL to a repository with this novel dataset. If a study only describes other (existing) benchmarks and offers a link to each of them, we do not consider it as a study that proposes a benchmark, thereby justifying their exclusion.
These criteria are aimed at supporting a proper selection of the relevant studies for this SM, i.e., studies that answer the presented research questions. The following inclusion criteria are defined:
- IC:
The study proposes a benchmark and makes it available as a single project in a URL link.
Conversely, for eliminating non-relevant studies, the following exclusion criteria are defined:
- EC1:
The study is not related to software testing or debugging.
- EC2:
The study does not propose a new benchmark specific to software testing or debugging techniques.
- EC3:
The study is not written in English.
- EC4:
The study is not a full article or is not available for access.
- EC5:
The study does not provide the proposed benchmark for access as a single project in a unique URL.
3.1.3. Data Extraction and Synthesis Method
We defined a form to guide the data extraction process. This data extraction form consists of a set of questions aimed at gathering sufficient data to classify the benchmarks, measure the quality of the studies, and answer all research questions. The form is presented in
Appendix A.
3.2. Conduction and Data Extraction
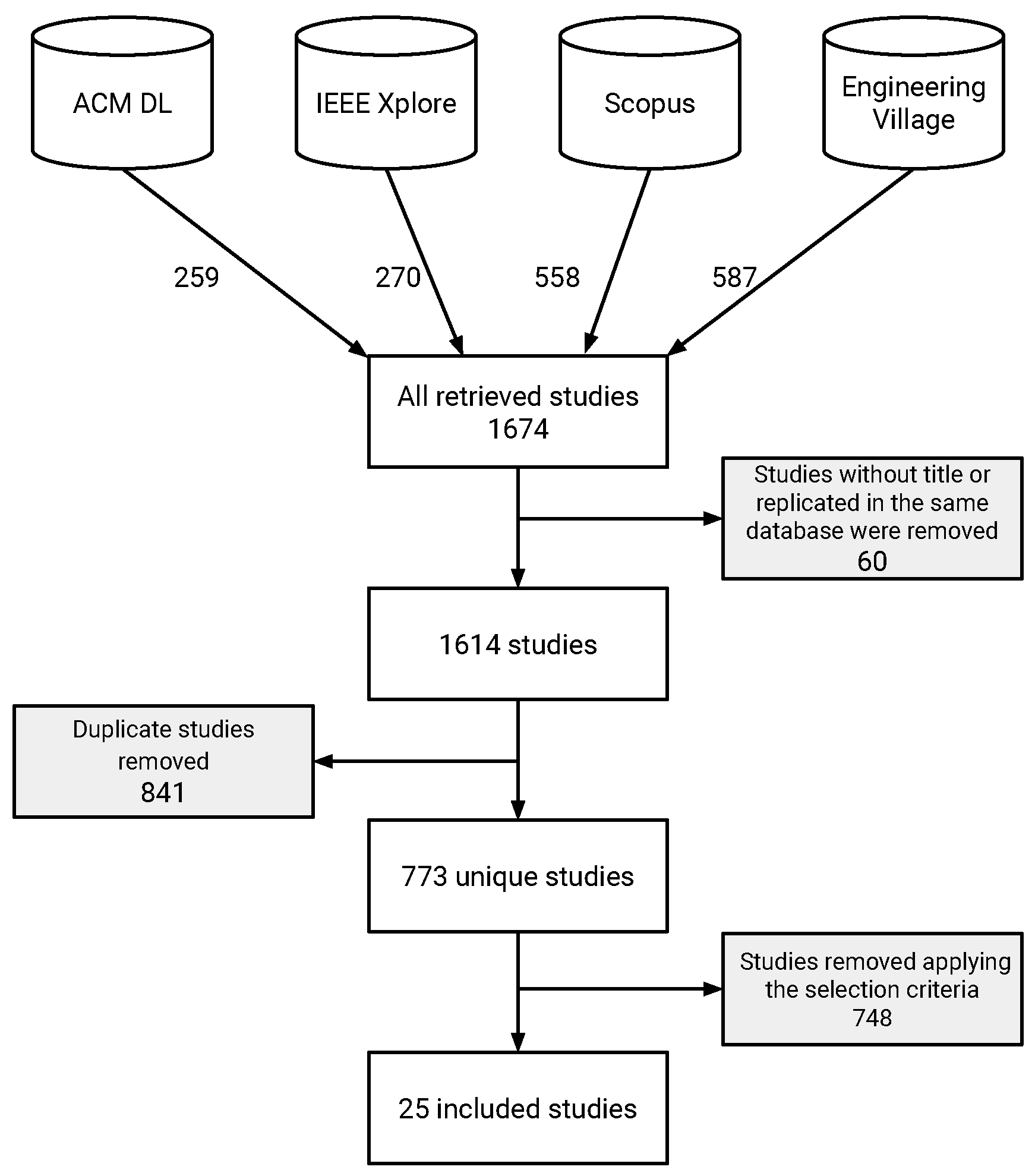
This search process was initially conducted in September 2018 and updated in January 2019, so studies published after January 2019 were not included. During the search, we did not limit the initial year.
Figure 1 shows the number of studies obtained by applying the search string in the selected databases. Initially, the search string retrieved 1674 studies. Some of the retrieved studies did not present even a title, and others were replicated in the same database. After removing them, 1614 studies remained. The study involved five researchers. Two of them were master’s students at that time, and the others were professors holding PhDs, with substantial experience in the software testing area. The professors supervised the students during the activity and contributed to data extraction and synthesis, in addition to resolving conflicts about the selection of studies.
In the third step, duplicated studies were eliminated, i.e., the studies that were retrieved in more than one database search. After that, 773 studies remained to be analyzed. We included 47 studies to be entirely analyzed. After applying the inclusion and exclusion criteria in this set, 25 studies were included (22 only mentioned benchmarks, but did not propose them).
3.3. Reporting
In this section, we report the findings of our SM. We report the quality of the included studies and we answer the research questions and provide data plots and tables to summarize the collected data.
All included studies are listed in
Table 1.
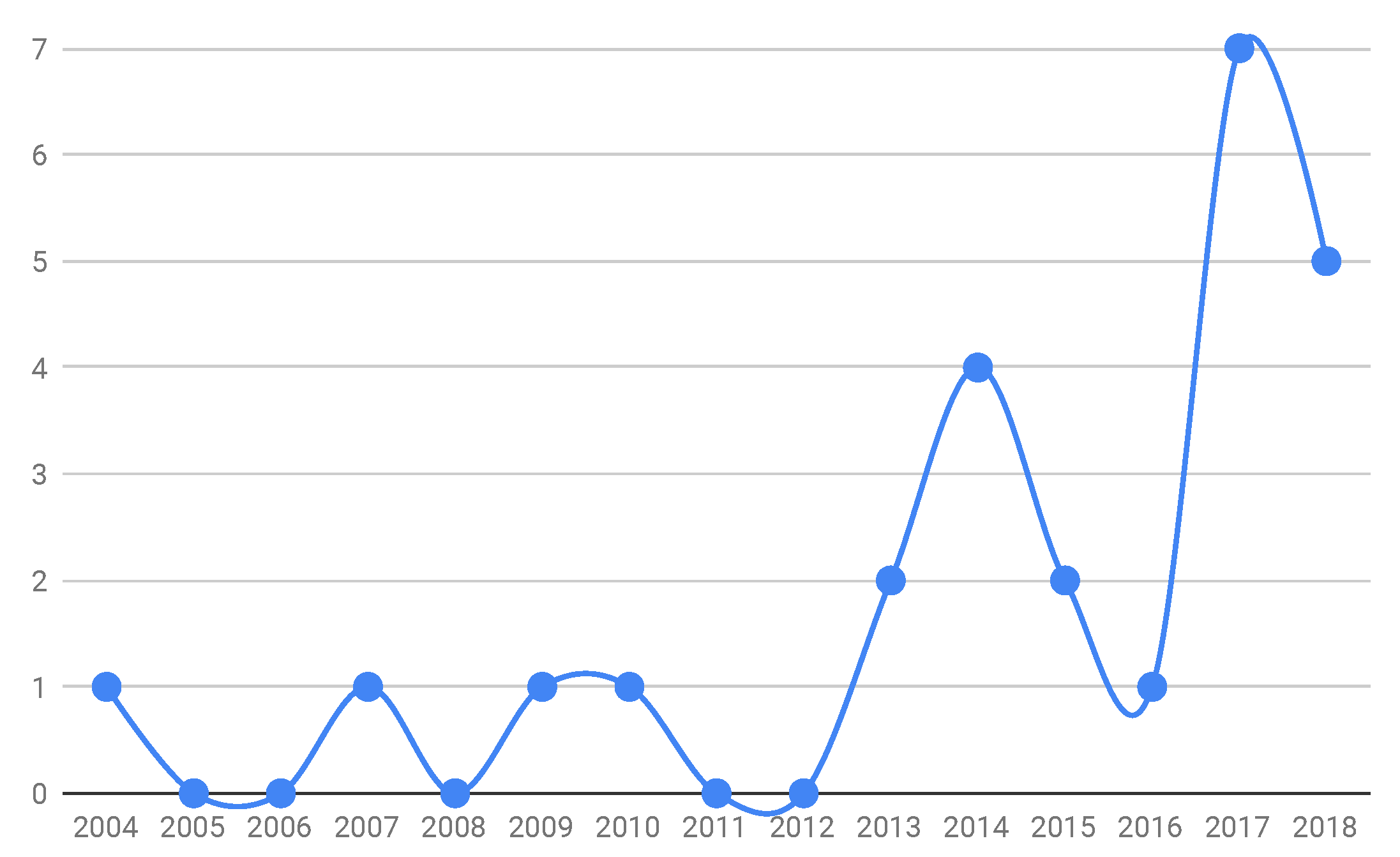
Distribution over the years.Figure 2 shows the distribution of studies that reported the proposition of a benchmark over the years. The first identified benchmark was published in 2004 [
36]. None of the studies included any proposed benchmarks in 2005 and 2006. In 2007, a study on iBugs was published. iBugs comprised the first benchmark with semiautomatic methods to search faulty programs using the GitHub repository [
42]. No relevant studies published in 2008 were found. In 2009, the first identified benchmark for two different languages (Java and C#) was published [
43]. A benchmark created from a mutated code was proposed in 2010 [
44]. During 2011 and 2012, benchmarks were not proposed from the included studies.
From 2013 onward, new benchmarks began to be proposed and were published at least once a year. We observed that the number of proposed benchmarks oscillated throughout the years; from the information plotted in
Figure 2, the data present a waveform with increasing maxima over the years. Moreover, 25 benchmarks were proposed and published during the investigated 15 years, resulting in a publication rate of around 1.6 benchmarks per year. However, the wave amplitude and wavelength subsequently increased over the years, from one benchmark per biennium (one every two years from 2004 to 2011), the number increased over this decade (two benchmarks in 2012 and 2013 (S5 and S6); six benchmarks in 2014 (S7, S8, S9, and S10) and 2015 (S11 and S12); eight from 2016 (S13) to 2017 (S14, S15, S16, S17, S18, S19, and S20); and five in 2018 (S21, S22, S23, S24, and S25)). Hence, the frequency of publication increased, as well as the number of benchmarks proposed. The first decade of analysis produced 9 different benchmarks, while the last five years alone accounted for 16 different benchmarks.
The term ‘Benchmark’ is quite a recent term, which might explain why our search did not find any benchmark before 2004, despite using the term dataset in the search string to alleviate the impact of a single term to denote our research focus. We only considered—as a benchmark proposition—the studies that provided a URL to the dataset, which is also a recent practice. Reference [
49] was published in 2014 at a conference and was expanded in a journal article in 2017. In this case, we only considered the earlier version.
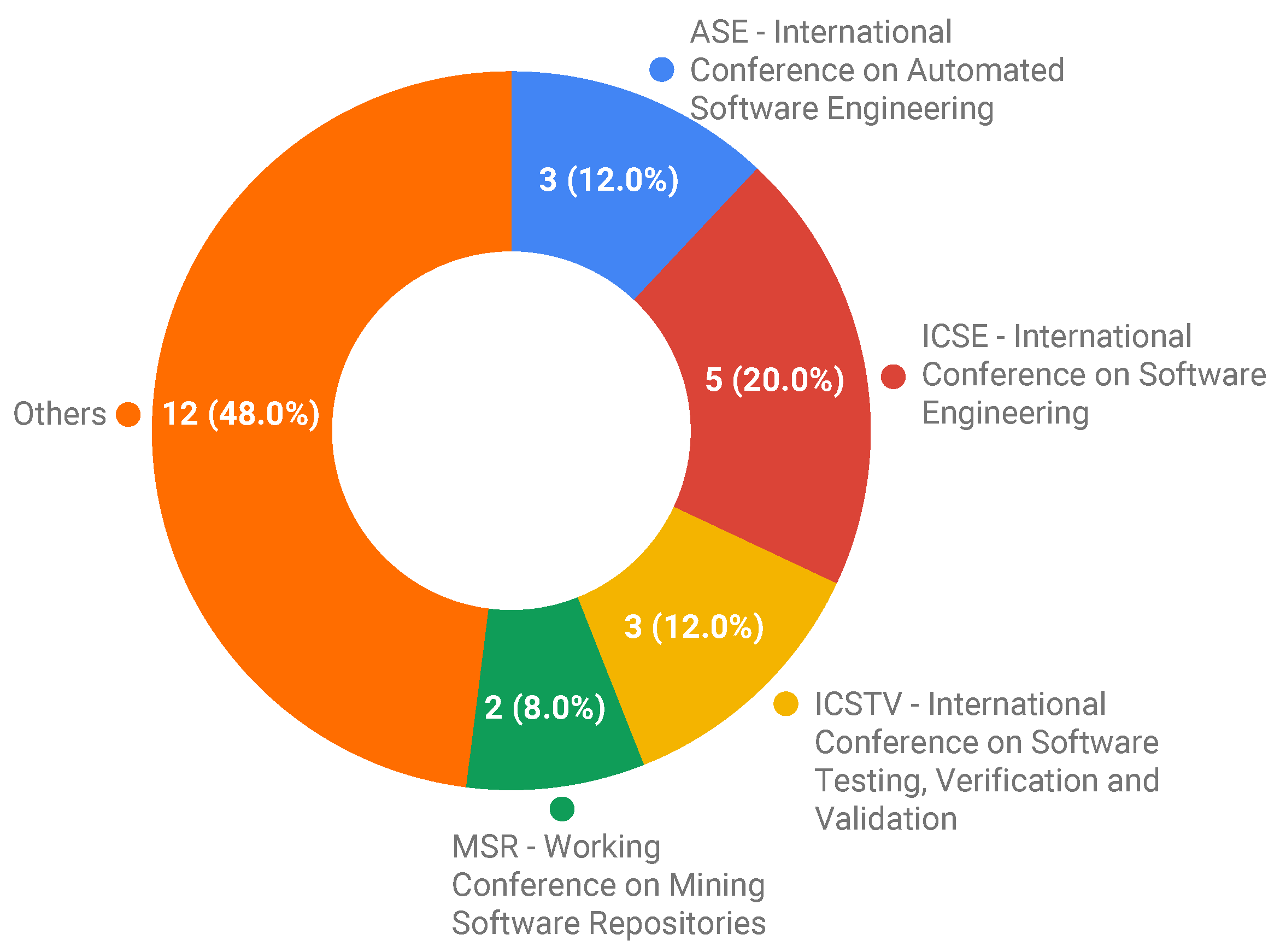
Publication venues and affiliation data. Studies that propose benchmarks for software testing and debugging are mainly published in well-known conferences. Five were published in each of the ICSE, ASE, and ICSTV conferences, with these hosting three studies of benchmark proposals each, as shown in
Figure 3. The four conferences (ICSE, ASE, ICSTV, MSR) represent 48% (12 studies) of the venues used to publish the included studies. However, some of them were not published in the main track. From the 25 included studies, only 4 (S10, S11, S15, S23) were published in journals. From these data, we interpret and conjecture that most of the studies that only propose benchmarks have been published at conferences. Conversely, all the studies published in journals not only propose benchmarks but also use them to support the evaluation of novel techniques for software testing and debugging.
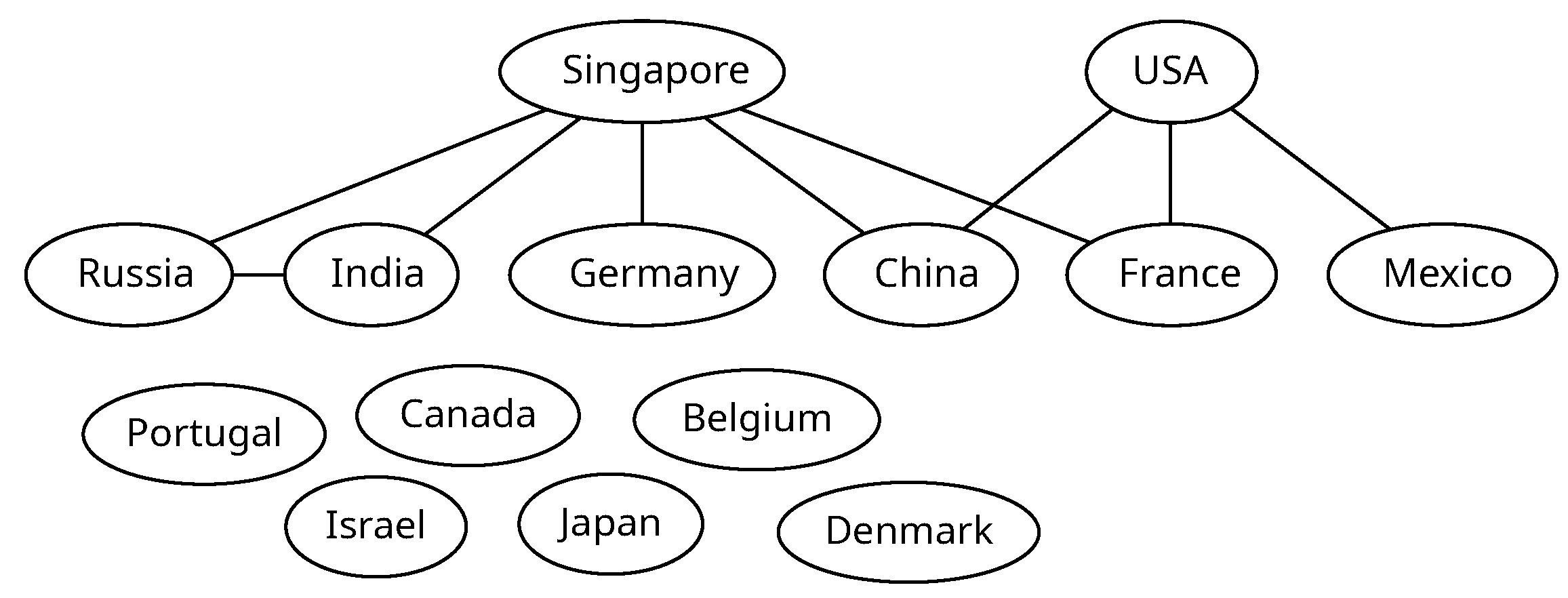
We analyzed the authors’ affiliations to discover the more representative countries related to benchmark proposals in software testing and debugging. Moreover, 8 out of 25 studies included authors from the USA; 6 studies included authors from Singapore; 5 studies involved authors from Germany; 3 studies were authored by researchers from China; and authors from Belgium, Canada, Denmark, France, India, Israel, Japan, Mexico, Portugal, and Russia were included in (up to) two studies. Some of the selected studies are the results of international collaborations.
Figure 4 represents the collaboration network. Notably, Singapore and the USA boast the highest numbers of international collaborators, yet they do not collaborate with each other. Both China and France have developed research with cooperation from Singapore and the USA. Belgium, Canada, Denmark, Israel, Japan, and Portugal do not exhibit international collaboration in our analysis.
Studies Quality. A set of quality questions (QQs) based on previous mapping studies [
61,
62] was incorporated into the form to allow measurement of the studies’ quality. They can be answered with “Yes”, “To some extent”, or “No”, and enable the assessment of the included studies according to the following parameters.
Table 2 summarizes the answers to the QQs. Most of the studies received “Yes” to the quality questions, which indicates an overall good quality of the included studies. For each QQ, except for QQ6 and QQ7, at least 76% of all articles scored “Yes”. Overall, studies that propose benchmarks do not discuss threats to validity and limitations (QQ6) or future work (QQ7).
- QQ1:
There is a rationale for the study to be undertaken.
- QQ2:
The authors present an overview of the related works and background of the area in which the study is developed.
- QQ3:
There is an adequate description of the context (industry, laboratory setting, products used, etc.) in which the work was carried out.
- QQ4:
The study provides a clear justification of the methods used during the study.
- QQ5:
There is a clear statement of contributions and sufficient data have been presented to support them.
- QQ6:
The authors explicitly discuss the credibility and limitations of their findings.
- QQ7:
The authors discuss perspectives of future works based on the contributions of the study.
Studies S2, S3, S8, S14, S15, S16, S18, S19, S24 received a “no” as the answer to QQ6 (credibility analysis and limitations). For QQ7 (discussion on future work), studies S6, S13, S18 received “no” as the answer, and studies S2, S7, S11, S15, S16, S19, S24 were assessed as “To some extent”.
3.3.1. RQ1: What Are the Benchmarks Proposed in the Software Testing and Debugging Context and Their Target Topics?
As mentioned in
Section 2, benchmarks consist of a group of programs with some representations of real-world environments, along with all the necessary instruments or characteristics for the techniques under evaluation. For instance, these instruments may be available test case sets, available source codes, programs in a specific programming language, or a specific number of lines of code (LoC).
Table 3 presents 25 benchmarks reported in the selected studies. Each benchmark is addressed by only one study once this MS considers studies on benchmark propositions, regardless of their subsequent use. All selected studies provide an external URL link to access the reported benchmark. However, in some cases, the presented link is not accessible. The included studies were grouped into four categories according to the target domain for which the benchmark was proposed. The benchmarks were proposed for applying and evaluating techniques in the following categories: software testing, fault localization, bug diagnosis, and program repair. The categorization of the studies in the four aforementioned categories was performed using a set of items extracted from the studies, including the keywords and classification of the aims of application of each benchmark mentioned by the authors in the study. In studies where the benchmark is related to more than one target topic, we considered only the most mentioned term in the article. Studies S1, S3, S4, S8, S13, S15, S20, S22 report the proposition of benchmarks for software testing. Studies S2, S9, and S24 report the proposition of benchmarks for fault localization. Studies S5, S6, S7, S10, S11, S21, S18 report the proposition of benchmarks for bug diagnosis. Studies S12, S14, S16, S17, S19, S23, S25 report the proposition of benchmarks for program repair. It is also possible to observe that there is a slight dominance from benchmarks proposed for software testing (eight benchmarks, 32% of the total number of proposed benchmarks found) over the other categories. Bug diagnosis and program repair have the same number of benchmarks (seven benchmarks, 28% of the total number of proposed benchmarks found for each topic), and fault localization only has three benchmarks (12% of the total number of proposed benchmarks found).
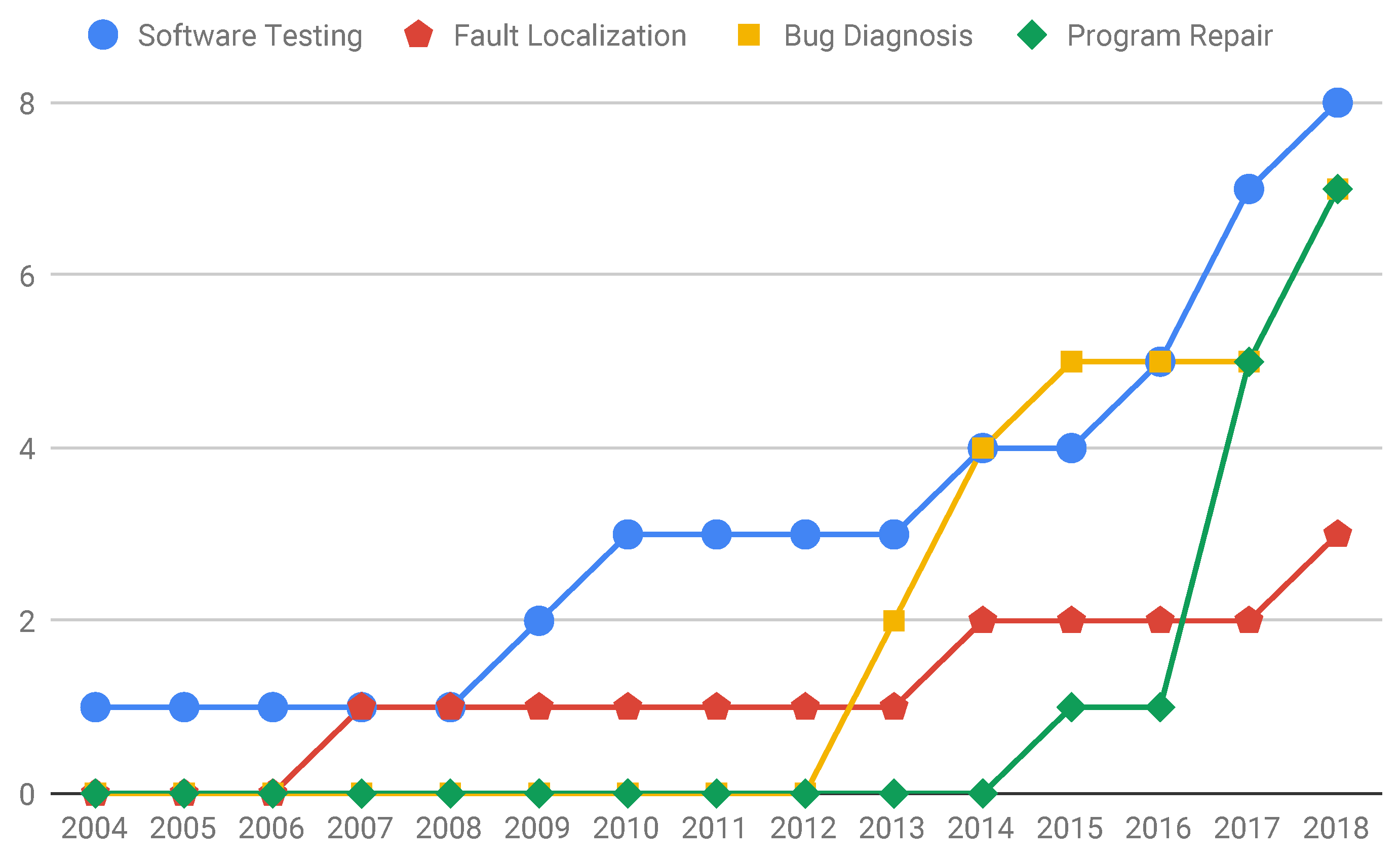
Figure 5 presents a cumulative view of the benchmarks proposed over the years in regard to their target topics (software testing, fault localization, bug diagnosis, and program repair). For exemplification purposes, considering software testing, one benchmark was proposed in 2004, and there was a break of new propositions until 2009 when the cumulative number of benchmarks proposed for software testing increased to two. The same pattern is followed in the other categories, showing the cumulative number of existing benchmarks over the years and none for the other categories. During the first five years (2004 to 2008), only one benchmark for software testing was recovered. From 2009 to 2010, two new benchmarks were proposed, remaining the same until 2013. From 2014 to 2018, the number of different benchmarks proposed for software testing over the years reached eight benchmarks. The same rationale was applied to the other categories. One important finding from this plot is that benchmarks for software testing, fault localization, and bug diagnosis have experienced progressive growth in number over the years. In addition, the program repair category experienced rapid growth, increasing the number of benchmarks from one to seven in just three years.
A likely explanation for the behavior of the plot displayed in
Figure 5 is that the domain of software testing is characterized by its historical precedence, with the progression of associated benchmarks unfolding gradually in parallel with the dissemination of research within this area. Notably, one of the studies included in the mapping reports the first benchmark developed for the software testing domain. For the program repair area, the influence of the study S12 (published in 2015) in the results plotted in
Figure 5 is clear, which is a study published by one of the “creators” of the program repair area, which, in addition to proposing the benchmark, already uses it to empirically validate it. Another factor that may justify the rapid rise in the creation of benchmarks for program repair and bug diagnosis is that these areas are novel and on the rise, but such a conclusion cannot be made definitively and demands further investigation into other mappings.
3.3.2. RQ2: What Are the Languages Used to Write the Programs That Compose the Proposed Benchmarks?
Benchmarks are often composed of programs written in a specific programming language (or platform).
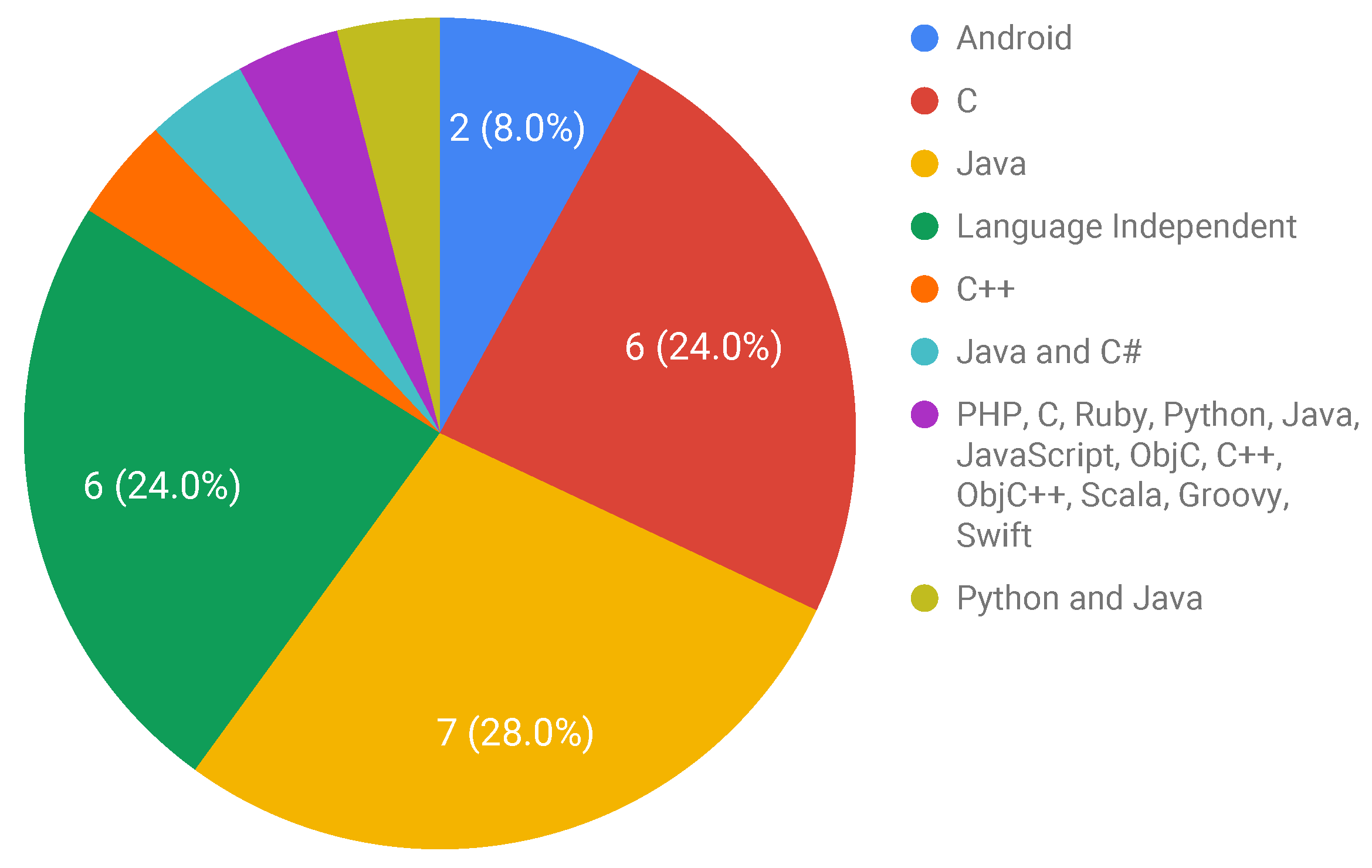
Figure 6 depicts the distribution of the languages over the benchmarks. The most common languages found in the included studies are Java and C. Seven benchmarks were proposed exclusively for Java (S1, S2, S4, S8, S15, S17, S23). In turn, six benchmarks were exclusively proposed for C (S7, S9, S12, S14, S16, S18). It is important to remark that 6 out of the 25 benchmarks are not composed of source code (S5, S6, S11, S10, S13, S21), e.g., the benchmark proposed by Bissyandé et al. [
45] comprises a set of bug reports that can be used in language-independent contexts.
A relevant finding refers to the benchmarks dedicated to the Android platform (S22 and S25). Although these benchmarks involve Java code, different coding libraries and tools are needed to deal with this specific platform, which motivates the creation of those new benchmarks and restricts the use of Java’s existing ones.
Then some benchmarks are specific to a programming language, whilst some of them target a specific platform, such as Android. A remarkable benchmark reported by one of the included studies (S20) deals with a specific type of software fault, i.e., this benchmark brings a set of test cases on security vulnerabilities. Furthermore, such a benchmark is not focused on a specific programming language but covers several of them (PHP, C, Ruby, and others).
Table 4 complements
Figure 6 by explicitly showing the programming languages and their respective included studies. A single benchmark was proposed for C++ (S24). It is also important to remark that 10 out of 25 (40% of the studies) report benchmarks for Java, being exclusive or also applicable to other languages (C# in S3 and Python in S19).
Figure 6 shows a clear predominance of C and Java datasets. Moreover, 52% of the benchmarks (13 of them) are exclusively for Java or C techniques. A likely explanation for C and Java having the highest values is that these are popular languages that ended up becoming mainstream in the areas of testing and debugging, which could be considered an expected/predictable result. This results corroborate prior studies, with the status of data being preserved. In particular, in 2015, a systematic mapping study showed that these languages were already the most present in testing activities, with 50% of the included studies reporting the use of JUnit as the main framework [
63]. This information highlights the point that researchers, who wish to explore aspects not provided by certain languages (such as bugs related to functional languages), may not be able to use existing datasets, and need to create new benchmarks to evaluate their research studies.
Table 4 shows the programming language related to each study.
3.3.3. RQ3: Are the Bugs That Compose the Proposed Benchmarks Real or Artificial?
The origin of bugs was divided between real and artificial bugs. However, during the review, we noticed that the real bugs originate from two different contexts:
a controlled environment and
a production environment. The former comprises situations where code and bugs are derived from student exercises or programming competitions. The latter involves most of the benchmarks and contains programs in production with real defects, e.g., Defects4J [
33], compiled from large-scale open-source projects.
It is important to highlight that before access to open-source projects was widely provided through a development platform such as GitHub (
https://github.com/ (accessed on 9 Ocotober 2023)), the most used bug benchmarks had artificial bugs or were based on student-made programs.
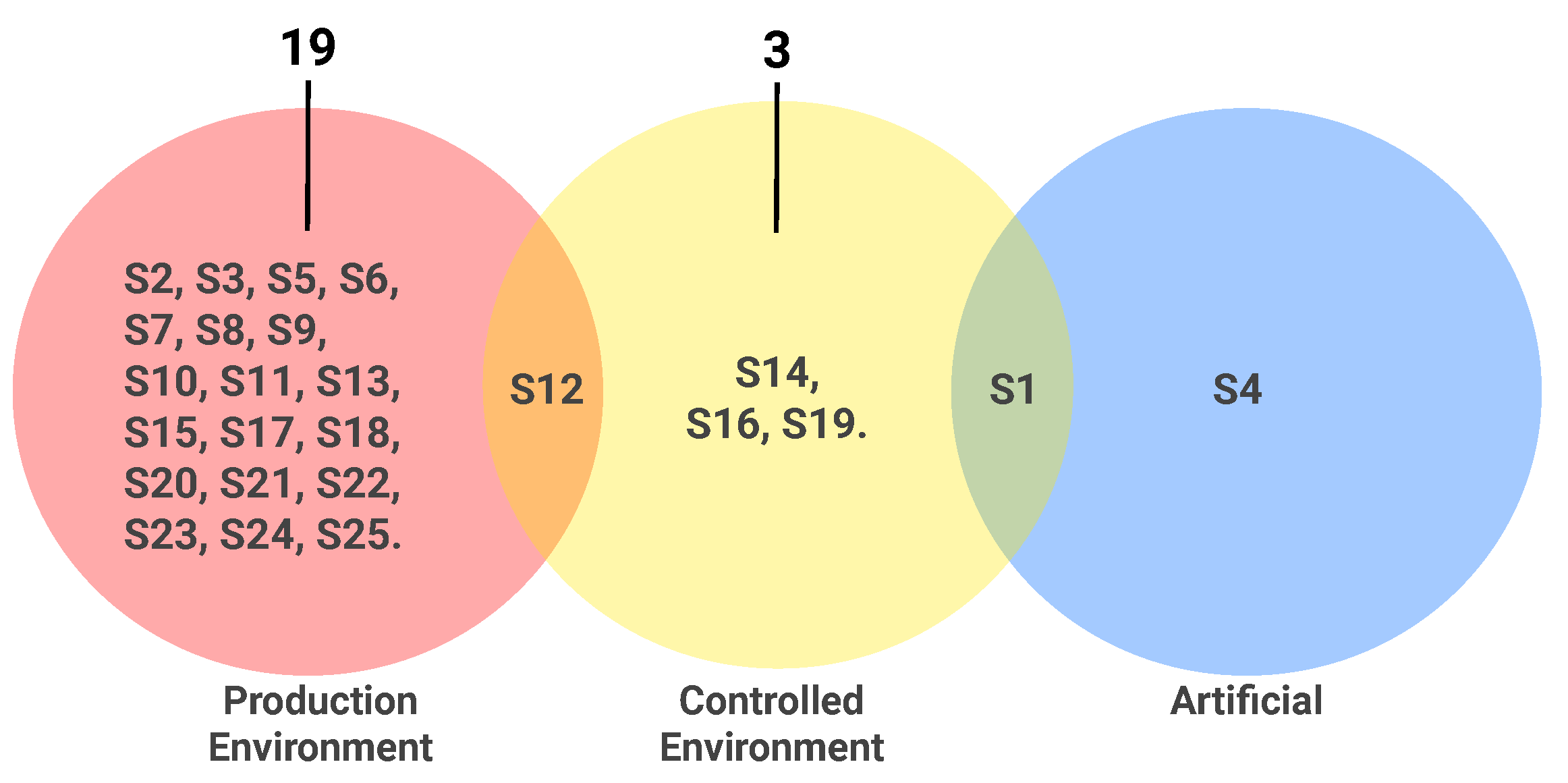
Figure 7 shows that except for S4, which proposes a benchmark for mutant evaluation (purely artificial bugs), and S1, which contains bugs that are intentionally but artificially provided by students in a controlled environment, all the benchmarks present real bugs. Three studies report benchmarks exclusively elaborated with bugs from a controlled environment (S14, S16, and S19). S16 and S19 were obtained from programming competitions. S14, in turn, comprises a dataset with 661 programs obtained from students of an undergraduate course on programming foundations. S12 is the study that combines two different sets of programs for the same benchmark: one set with programs obtained from students, and another set with programs provided from a production environment. The remaining 19 benchmarks correspond to a production environment or are provided as bug reports of existing tools.
3.3.4. RQ4: What Were the Identified Motivations for Proposing the Benchmarks?
From the data extracted regarding motivations, it was possible to categorize the motivations for the benchmarks into five types, as follows.
Absence of data: This motivation comprises the situation where a testing or debugging technique exists, and an expert intends to assess the technique. Once the evaluation of those techniques requires a dataset, the absence of data motivates the creation of a new benchmark. In this scenario, even simple datasets with synthetic data are useful. For instance, Eytani et al. show that concurrency defects are difficult to cover and analyze without a standard dataset. To evaluate and compare techniques developed to deal with these types of defects, Eytani et al. proposed the first benchmark of multi-thread programs in 2004 [
36]. Only study S1 falls into this class.
Lack of real data: This motivation targets techniques whose evaluations overcome artificial data or are restricted to real data. With this motivation, iBugs was proposed in 2007 [
42]. The authors highlight that until that moment, the benchmarks available for debugging only had artificially seeded defects. Due to the difficulty of validating whether artificial bugs represent reality, it was necessary to create a new benchmark with real defects in large programs. Studies S2, S3, S6, S8, S13, and S23 fit into this class.
Lack of specialized data: Some methods need specific information to be evaluated. For instance, the evaluation of crashes in a mobile platform inherently requires code and data that are specific to that platform. Hence, highly specialized data are demanded in some categories of software, which motivates the creation of new benchmarks. This motivation is related to benchmarks that aim to fulfill this lack and to make the specialized data available. For instance, in 2013, Bissyandé et al. [
45] proposed a benchmark that contains bug reports. Until that moment, techniques of bug localization that use such information could not be evaluated or straightforwardly compared to other techniques due to the lack of specialized data. Android crash automated repair techniques also match this category, since it exposed the need for specialized data available in benchmarks, as reported in S25 (Droixbench benchmark). Benchmarks that fall into this type of motivation often require much attention to avoid biased data, since a technique can be beneficial when the same people create both the benchmark and the technique under evaluation. This is actually a recurrent threat to the validity reported by the included studies themselves as they address the need to develop new benchmarks to evaluate a technique also created by the same authors (e.g., [
48,
52]). Studies S5, S9, S12, S14, S15, S16, S17, S19, S21, S24, and S26 belong to this class of motivation.
Lack of bug understanding: This motivation refers to structuring data and providing additional data aiming to support the understanding of classes and origins of bugs. For instance, Reis and Abreu [
55] propose a set of security bugs, created specifically to support the analysis of such a defect type. Apart from the previous types of motivation, this one comprises the lack of more in-depth information about bugs. Studies S7, S11, S18, S20, S23 belong to this class.
Spontaneously providing results data: This motivation refers to a spontaneous contribution by creating a basis for the evaluation of further techniques; i.e., the authors made their results available as benchmark data. Studies S4 and S10 made their study results (respectively, mutated code and run-time log) available for community use to compare other techniques in the same context. Only studies S4 and S10 belong to this class.
Figure 8 shows the accumulated evolution of motivation for the proposition of benchmarks over the years. One interesting finding is related to the accelerated increase in the diversity of motivations for proposing benchmarks over the years. For instance, benchmarks proposed due to the
lack of specialized data increased in the last three years. Those benchmarks were proposed to support the evaluation of specific characteristics of a software testing or debugging techniques that have not been exploited by existent benchmarks yet according to the authors. One example is S19, which was created to enable researchers to analyze the same defect in programs written in different languages. Then the authors proposed a benchmark with equivalent programs with the same defect but written in two different languages (Java and Python). This was a different motivation when compared to the previous ones. Another example is S24, which reported a benchmark for techniques to be applied in C++ since none of the previous benchmarks could be used for that purpose.
Benchmarks motivated by the
lack of real data have emerged over the years. They were motivated by the lack of real data and were created to be applied in techniques where artificial data were not enough. One example of a lack of real data was the dataset crash analysis [
57], created for Android crash repair techniques. This was the first benchmark of the area that supported the evaluation of techniques with real data for that context.
3.3.5. RQ5: What Were the Identified Scopes of Use for the Proposed Benchmarks?
Multiple objectives can guide the designing of benchmarks. However, those purposes can be classified into two general categories, which are:
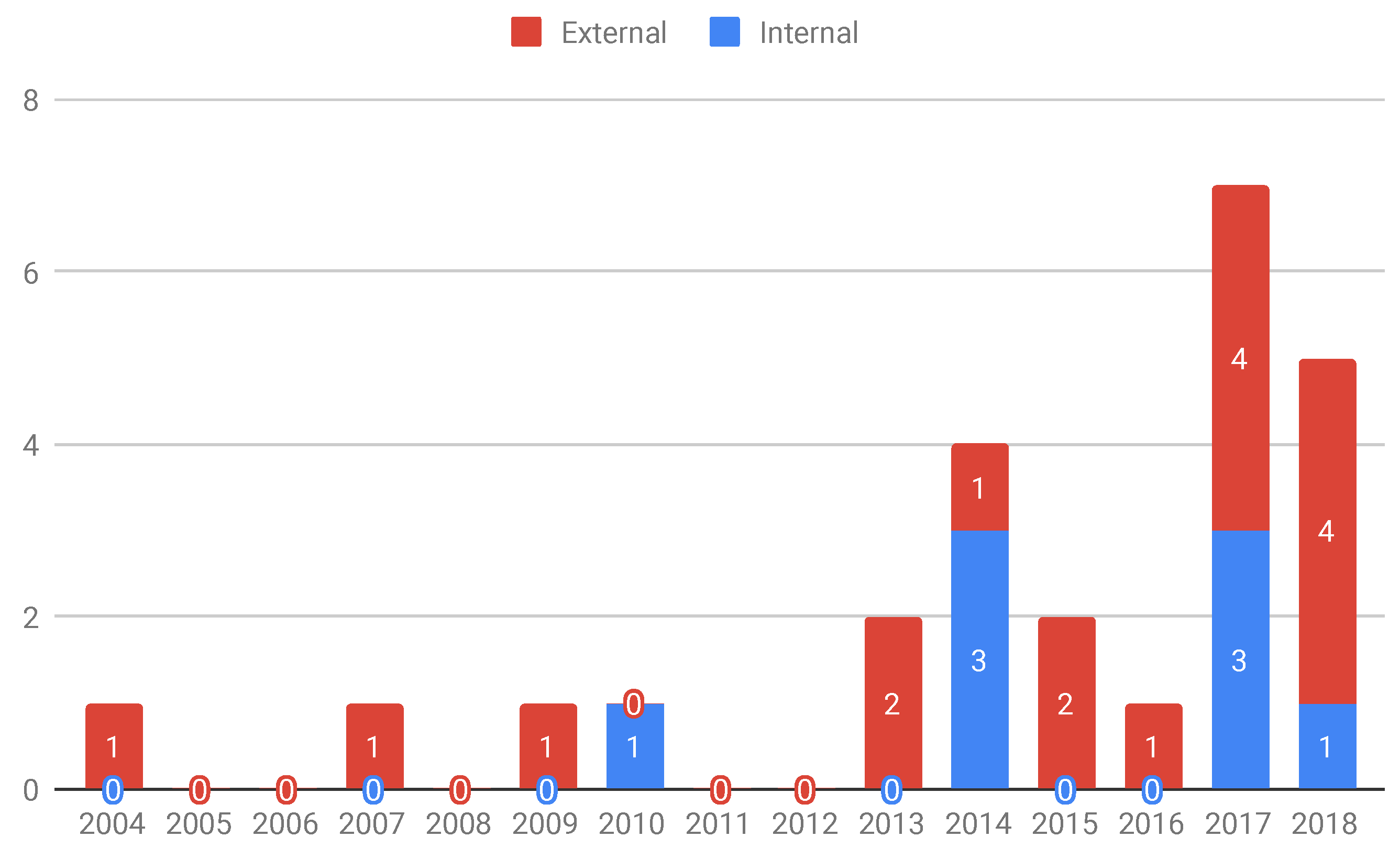
External: This is the case where benchmarks are made available to supply the community needs. For instance, Pairika (S24) is a benchmark proposed for the bug diagnosis of C++ programs, i.e., it was not created for a specific technique, but an open-accessed use of an entire programming community. Several research studies can use the datasets provided by benchmarks of this category. We identified 17 studies that are addressed to this category: S1, S2, S3, S5, S6, S8, S11, S12, S13, S16, S18, S19, S20, S21, S22, S23, and S24.
Internal: This class of objectives represents the benchmarks built to evaluate the technique of a particular research group. In general, they may be used in other related studies but the main objective was to provide a benchmark because no other existing one could be used in the study. In those cases, the included study actually presents testing or debugging techniques, and the benchmark is jointly proposed to introduce the technique being reported. Eight studies are addressed to this category, S4, S7, S9, S10, S14, S15, S17, and S25.
Figure 9 shows the predominance of the external scope of use among the reported benchmarks. This shows that most of the proposed benchmarks are available for the entire community, not being specific to a particular technique or method.
3.4. Synthesis
This section provides synthesis results obtained from (i) additional findings that are not directly related to the answers to the research questions (
Section 3.4.1), and (ii) information extracted from crossing two or more research questions (
Section 3.4.2). Also,
Appendix B presents a table that compiles the information obtained by answering each RQ, which allows the reader to confirm the findings reported here and obtain more useful data from them. We provide a repository with a complete list of the studies and the URL link to their reported benchmarks (
https://github.com/I4Soft/Testing_and_Debugging_Benchs (accessed on 9 Ocotober 2023)).
3.4.1. Additional Findings
The additional findings refer to the information obtained from the included studies as a subjective perception that may be relevant to testing and debugging practitioners, as follows.
Create benchmarks regardless of software testing and debugging techniques. New techniques may have no data in the literature that support their assessment in regard to other techniques (for instance, study S9 proposes a dataset with bug reports and codes and uses it to validate a novel bug localization technique), which require the creation of new benchmarks. Then a recurrent threat reported in the included studies is the creation of benchmarks along with the creation and evaluation of techniques: a benchmark was created ‘for’ that technique, and the benchmark is suitable for the technique, not evaluating it at large. To avoid such excessive fit, benchmarks should be unbiased, i.e., when comparing different techniques on the same dataset, the dataset should not positively or negatively influence the results of the techniques. Thus, from the review of the included studies, a possible perception is that benchmarks should be proposed independently of the techniques they are used to evaluate.
Benchmarks are often surpassed. A motivational example comprises the use of benchmarks composed of programs with artificial bugs. The proposition of iBugs [
42], for instance, was motivated by the lack of real data. Specifically, they report that the existent benchmarks, such as Siemens Suite [
28], were wholly composed of programs with artificial bugs. Then, at some moment, the techniques were well-succeeded to deal with artificial bugs but not validated with real bugs. In turn, the iBugs was not exhaustive about real bugs since it was only one program with multiple versions of real bugs. This characteristic raised the need to create Defects4J (initially composed of five programs) [
33], superseding iBugs since novel techniques demanded benchmarks with a larger number of programs with real bugs to deliver a better evaluation of testing techniques. In line with this perspective, in
Section 3.3, we observed a tendency for benchmarks to be created in a wave pattern, i.e., in regular periods (about every two years, and increasing). We conjecture that this pattern will be repeated in forthcoming years, as novel techniques can be created in future years due to similar motivations: lack of data, novel techniques, and existing benchmarks being deprecated.
Out-of-the-box use. Another interesting finding is the fact that benchmarks can be used in other areas—even if they are not explicitly created for that purpose. An instance is Defects4J, which is recurrently used in program repair [
64] and fault localization [
65], despite the fact that software testing was its original target topic. Other benchmarks exhibit this same phenomenon, reinforcing the out-of-the-box usage of them. For instance, ‘Codeflaws’, which was proposed for program repair, has also been utilized in fault localization [
14].
3.4.2. Triangulation
Triangulation is a procedure that combines results obtained from answering the elaborated individual research questions, but that could not be found by analyzing them in isolation.
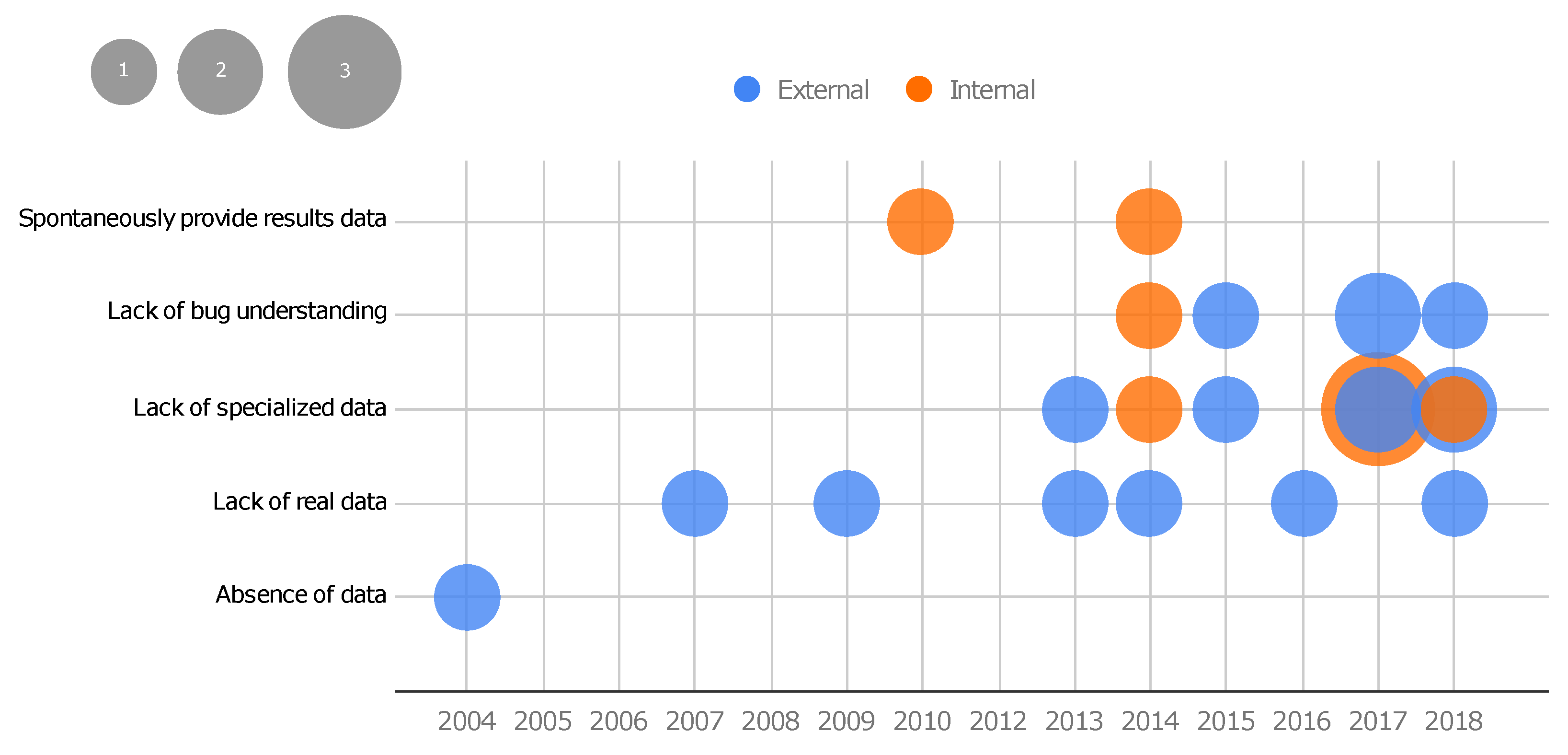
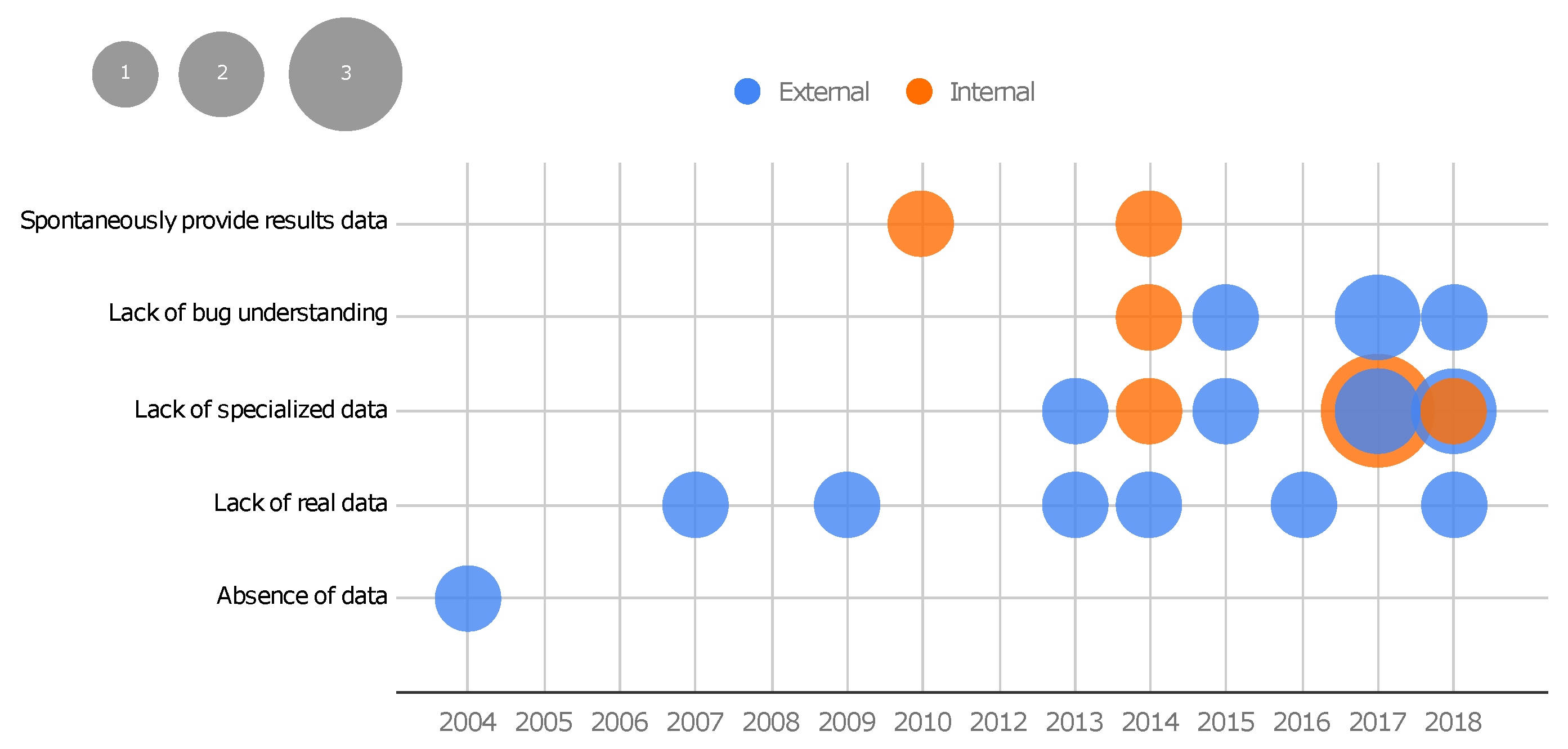
Figure 10 shows a bubble plot that combines results obtained from RQ4 and RQ5 over the years, i.e., the plot shows how the motivation type (absence of data, lack of real data, lack of specialized data, lack of bug understanding, and spontaneously providing results data) impacts the scope of use of the benchmark proposition (internal and external) over time.
From the data, it is possible to observe that, throughout the years, all the benchmarks motivated by a wish to spontaneously provide results data were conceived for an internal scope of use, which means that the benchmarks were created in association with a particular technique and it was used to support the evaluation of the associated technique. However, they were made available to the community. On the other hand, all the proposed benchmarks motivated by the absence of data and lack of real data have an external scope of use, i.e., the main aim of their creation was to make them available to the community. Among the seven benchmark propositions in 2017, three were motivated by the lack of specialized data and with an internal scope of use.
We also exploited the relationship between RQ1 and RQ4, respectively, related to the target topic and motivation.
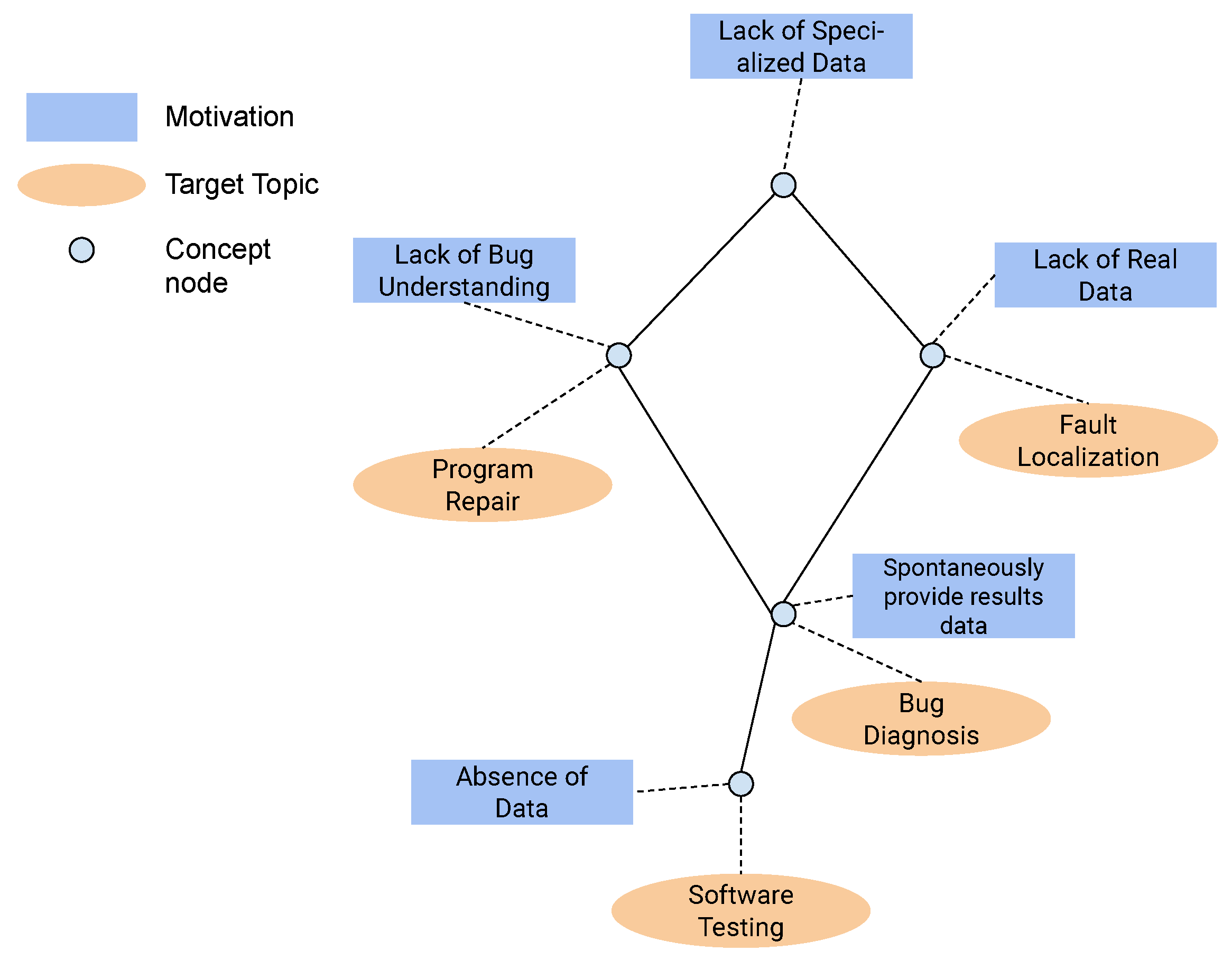
Figure 11 presents a formal concept analysis (FCA) of the literature on benchmark proposals. FCA [
66] is an analysis technique that can be applied to data that report objects, attributes, and binary relationships between them. Ellipses represent the objects, and rectangles illustrate the attributes.
A concept is illustrated as a node, and it is not associated with a name. However, it links a set of objects (target topics) to a set of attributes (motivations). An additional recommendation for reading such a plot is as follows: if the plot is read from top to bottom, a motivation was applied (in the included studies) to all the target topics underneath it in the diagram and all of them that could be reached through some edge from it. For instance, reading the plot, we can infer that the motivation ‘lack of specialized data’ was a motivation for all four target topics (program repair, fault localization, bug diagnosis, and software testing). In turn, the motivation ‘spontaneously provides results data’ was used in studies that report bug diagnosis and software testing, but not for fault localization and program repair. From this plot, we can also infer that the ‘lack of real data’ was used for all target topics, except program repair. Conversely, ‘lack of bug understanding’ was used for all target topics, except for fault localization. In turn, the ‘absence of data’ was found as a motivation in the included studies only in benchmarks proposed for software testing.
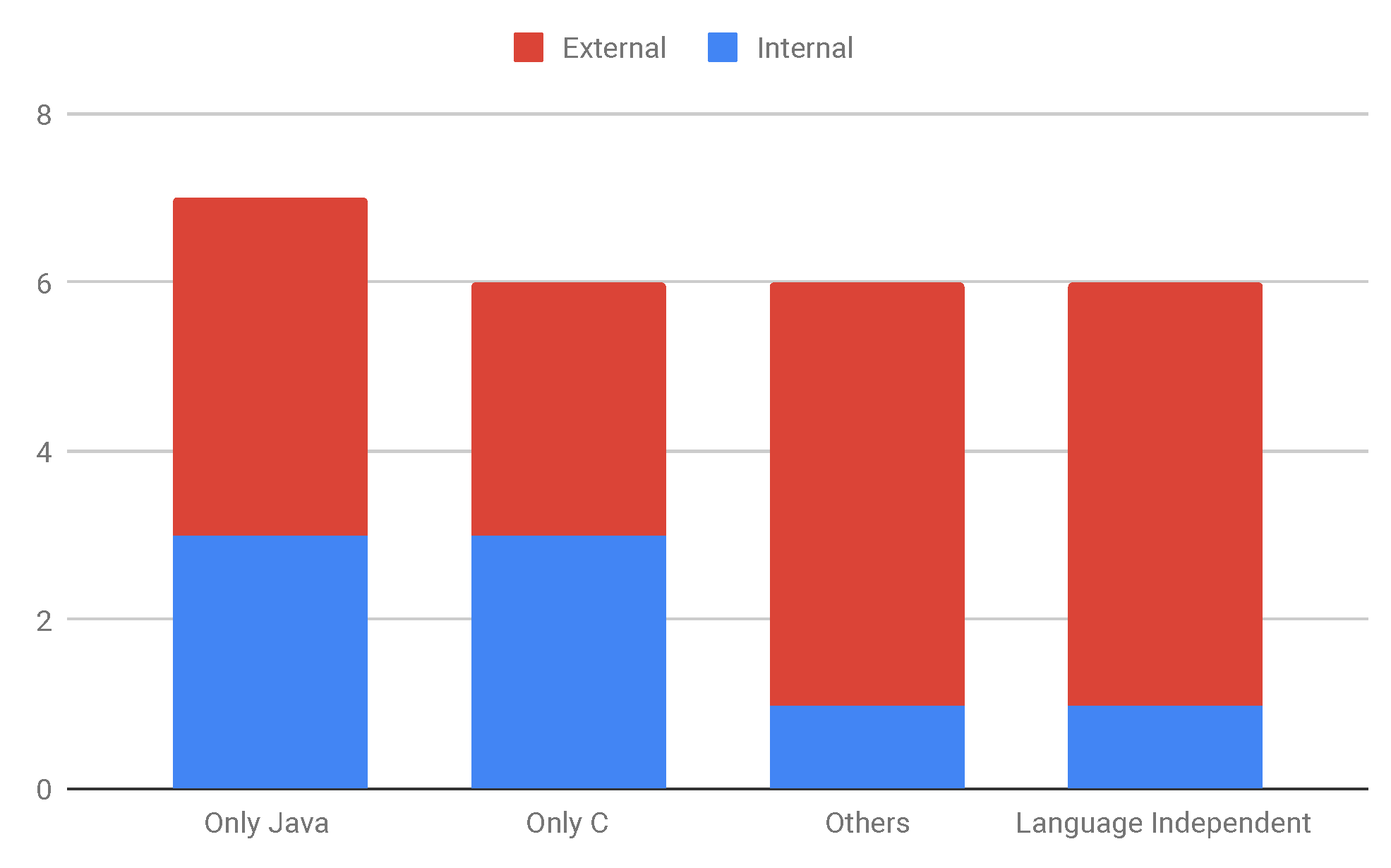
Figure 12 shows the relationship between RQ2 (programming language) and RQ5 (scope of use). The aim of combining those answers was to understand the relationship between the programming language communities and the benchmark’s scope of use. Among the seven benchmarks exclusively proposed for Java, three (43% of them) are for the internal scope of use, and four (57% of them) for the external scope of use. Six benchmarks were proposed for C: three (50%) for internal and three (50%) for external scope of use. In turn, among the six benchmarks proposed for programming languages that are not only Java and C, such as C++, Python, and C#, five of them (83% of them) are proposed for external scope of use. The same happens for language-independent (or technology-independent) benchmarks. We noticed that benchmarks that are not exclusively proposed for Java or C languages were mostly created to supply the needs of particular communities that did not have so many possible benchmarks as Java and C.
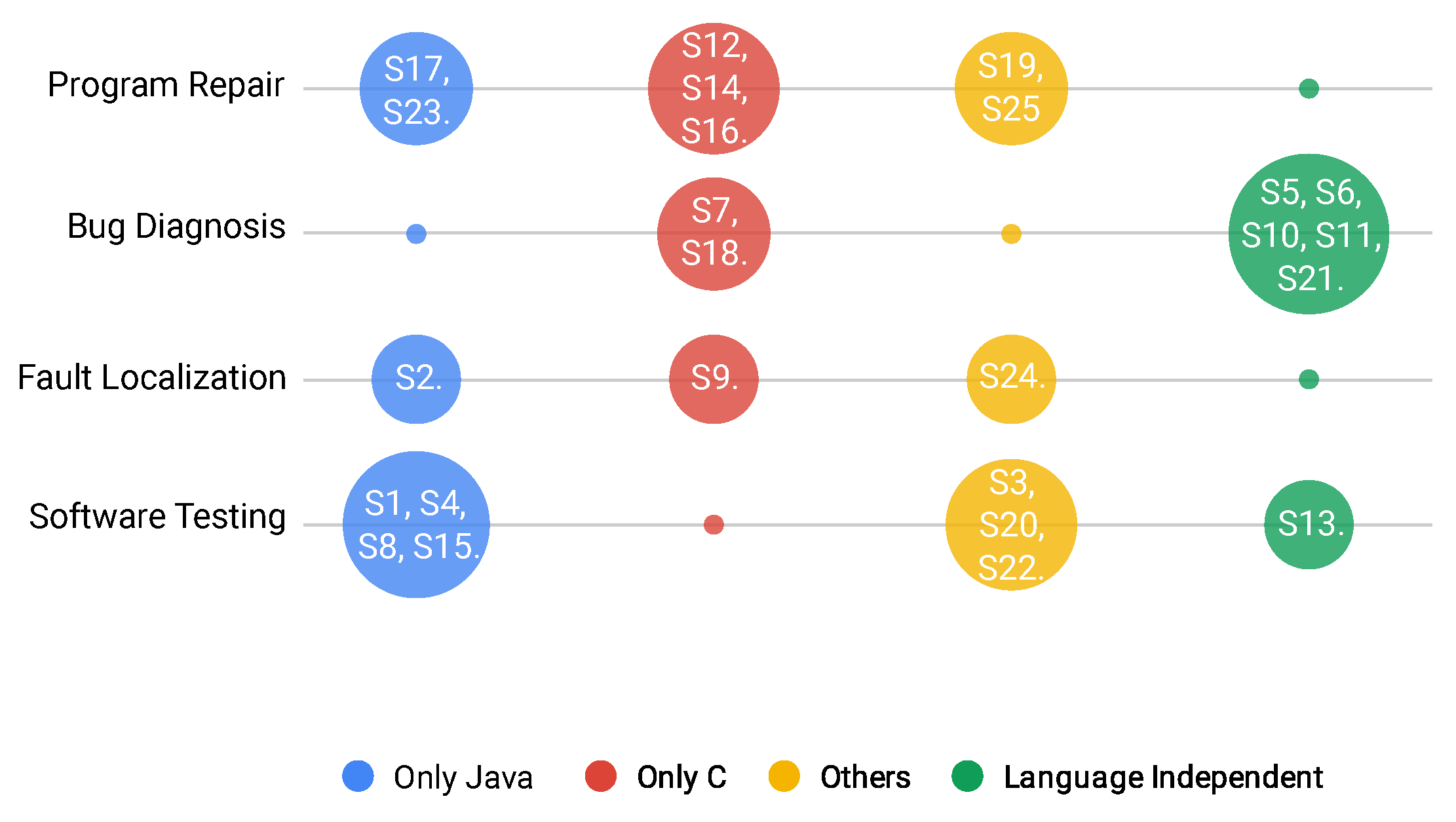
Figure 13 uses data from RQ1 (target topic) and RQ2 (programming languages). Bubble sizes represent the number of studies for each target topic (rows) displayed according to their respective programming language colors (columns). We can observe that bug diagnosis is the main target topic for benchmarks proposed for language-independent contexts. An example of this is bug reports, which do not require specific code, but only information about the bug. Other important findings are that (i) benchmarks with only Java programs (four studies) are tightly related to software testing, and Benchmarks in the class Others (three studies) are also highly related to software testing, likely attempting to offer an alternative for software testing beyond Java. (ii) C is closely related to programming repair (three studies).
6. Final Remarks and Future Work
This article reported the results of a systematic mapping carried out to offer a broad panorama on the proposition of benchmarks to support the evaluation of software testing and debugging techniques. Twenty-five primary studies were selected and analyzed. From the analysis, we extracted important lessons that can be used to support testing and debugging techniques. We bring the following conclusions:
Benchmarks are mainly proposed for software testing, bug diagnosis, and program repair, rather than fault localization (only three studies reported the proposition of benchmarks for this domain);
The first decade of analysis produced nine different benchmarks, whilst the period 2013–2018 was responsible for 16 different benchmarks, showing a significant increase in the number of benchmarks being proposed. This result endorses the importance of benchmarks for supporting the evaluation of software testing and debugging techniques and an increase in the interest over the years;
Approximately 50% of the retrieved studies report benchmarks proposed for exclusively C or Java. The other half refers to language-independent benchmarks or benchmarks proposed for other languages;
Most of the proposed benchmarks (92% of the studies, 23 out of 25) are composed of real bugs from a controlled environment (we understand a controlled environment as a non-commercial situation in which software testing activities are carried out, such as in academic environments and competitions) or a production environment (a production environment comprises the software testing environment for commercial software in production);
The motivation for a proposition of benchmarks could be classified into five different categories: (i) absence of data, representing benchmarks proposed because there are no available data (such as a set of buggy programs or execution logs) until that moment to support the proper evaluation of a testing or debugging technique; (ii) lack of real data, revealing that several techniques demanded real data and the use of programs with real defects; (iii) Lack of specialized data, which indicates that while some benchmarks do exist, they may not be composed of programs in a specific programming language or contain descriptive data about bug fixes, revealing a lack of specialized data that motivates the proposition of novel benchmarks; (iv) lack of bug understanding, since some benchmarks exist, but their data are not structured or provided in a way that supports understanding the classes and origins of bugs, thereby motivating the proposition of new ones, and (v) spontaneously providing results data, as some benchmarks are obtained through the execution of techniques and are provided to the community as a public dataset.
The scope of use for the creation of benchmarks can be split into two classes: internal and external. The former refers to an inner evaluation of particular testing or debugging techniques, which demand the creation of a benchmark. The latter refers to benchmarks created to be available for community needs.
Although new benchmarks have recently been proposed, the field still demands the proposition and consolidation of guidelines to support the introduction of further benchmarks. Our investigation revealed that, in numerous instances, new benchmarks were developed due to the deficiencies of existing ones; however, the newly created benchmarks neither exhibited a high degree of quality nor showed substantial potential for reuse or adaptability. Hence, a more in-depth understanding of customization, quality, and reuse of benchmarks is also needed.
Nevertheless, this study contributed through an analysis of the recent history of benchmark propositions and unveiled several vital characteristics of existing ones. Moreover, a list of numerous benchmarks, along with their characteristics, was made available to the community. This availability enables researchers and practitioners to identify benchmarks that align with the requirements of their testing or debugging techniques, thereby fostering evaluation activities within that domain, and preventing professionals from developing novel benchmarks instead of using existing ones.
From the results obtained in this mapping, we could also raise some important future work in the field. We observed a latent need to define standards and guidelines for the creation of new benchmarks in testing and debugging, reinforcing the need for them to be reusable in different contexts in order to allow the comparison between the results obtained in each case. In parallel, it is also important to ensure the neutrality of the datasets used so that bias is not inserted, in order to favor metrics (such as accuracy) or better performance for specific methods. In addition, strategies to measure these biases should also be investigated and proposed.
We hope that the results of this research not only present consistent information and provide a panorama of available benchmarks for supporting the evaluation of software testing and debugging techniques, but also support researchers and practitioners to understand the characteristics of those benchmarks better to foster reuse, customization, and productivity by avoiding unnecessary efforts, saving both time and costs for real projects.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












