1. Introduction
Bayesian computation uses Bayes’ theorem to revise the probabilities of unknowns based on prior knowledge and data. When the likelihood expressions and prior are available, we can get the expression of the posterior law. However, this expression needs the denominator integral computation of the Bayes formula, called evidence. Approximate Bayesian Computation (ABC) are a class of algorithms used to perform Bayesian computation without exactly computing the evidence. The first class of these methods generate samples from the posterior law. We can mention all of the Monte Carlo sampling methods, such as slice sampling, nested sampling, and Markov chain Monte Carlo (MCMC) methods. The second category of these methods includes those that directly compute the means and variances, such as the Variational Bayesian Approximation (VBA) methods.
MCMC is a class of algorithms for sampling from a probability distribution and estimating the posterior distribution. Metropolis et al. (1953) [
1] introduced the first MCMC algorithm called the Metropolis algorithm. Hastings (1970) [
2] brought it closer to applied statistics, generalizing the Metropolis algorithm for asymmetric proposal distributions.
VBA methods were introduced by Jordan et al. (1998) [
3]. They were motivated by the demand to improve the Bayesian inference for large and complex models intractable by conventional methods such as MCMC. VBA is a fast and robust scheme to perform Bayesian computations in high–dimensional problems. The main idea is to approximate the high–complexity posterior probability law with a simple and lower–complexity probability law using the Kullback–Leibler divergence as the approximation criterion.
In many cases, the VBA methods are faster than the MCMC methods. VBA can release two types of posterior approximations. The first is the free–form product of distributions such as the conjugated exponential family known as the Mean–Field Approximation (MFA). The second one is the fixed–form for posterior distributions like multivariate Gaussian with a proper parametrization for the model, Sarkka and Nummenmaa (2009) [
4]. MFA is a general approach in the graphical models, particularly for the hierarchical Bayesian models.
The foundation of VBA is minimizing the Kullback–Leibler divergence (KL) between the approximated probability distribution and the exact posterior distribution. Rohde and Wand (2016) [
5] worked on semi–parametric Mean–Field Variational Bayesian Approximation (MFVBA) as a combination of the KL measure and MFA. A significant drawback of MFVBA is that it underestimates the variable uncertainties and is uninformed concerning the variable covariance of models. Giordano et al. (2015, 2018) [
6,
7] rectified the MFVBA and named Linear Response Variational Bayes (LRVB) as being able to provide proper uncertainties.
MFVBA is a valuable approximation method for estimating the posterior mean in the Bayesian framework. While using an exponential family for approximation, we get a fixed point algorithm for reckoning the means. In this paper, we show how to use VBA with exponential families to approximate the posterior means and simultaneously evaluate the posterior covariance more precisely. Via an example, we also compare the MFVBA and MCMC posterior distributions.
This paper’s organization is as follows: In
Section 2, we demonstrate the main idea of MFVBA with a particular case in exponential family (EF) distributions. In
Section 3, we modify the covariance matrix resulting from the MFVBA to get a better approximation. In
Section 4, we give details of the covariance matrix expression in EF. We show that the covariance computation needs high–dimensional matrix inversion, which is very costly in high–dimensional problems. In
Section 5, we provide an example of how to compute the posterior distribution and compare the computational costs of the proposed method and the MCMC. In
Section 6, we present the main conclusion on the paper content.
2. Mean–Field Variational Bayesian Approximation (MFVBA)
VBA approximates posterior distributions when the exact expression of the posterior is too complex or costly. MFA simplifies the VBA by assuming that the final distribution is factorized into independent margins, which means that each unknown parameter has its distribution independent of the others.
Suppose that
p is approximated by
and
is the unknown vector of parameters. We define
and
. We know that
.
is a poor estimate (underestimate) of
even if
. The question is how to find a better estimate for
. One solution for
in the case of the exponential family, proposed by Giordano et al.
[
6], is
via the LRVB method, where
and
are an identity matrix and Hessian matrix of the log probability
, respectively. To show this, let us go through the details step by step.
2.2. VBA and Exponential Family
If
q is chosen to be in an exponential family:
then it is entirely characterized by its mean
and so is:
then the same characterization by the mean
.
We can then define the objective
E as a function of
, and the first–order condition of the optimality is:
2.3. MFVBA, Exponential Family (EF) and Fixed Point Algorithm
VBA+exponential family with
:
Iterating on this fixed point algorithm:
converges to
.
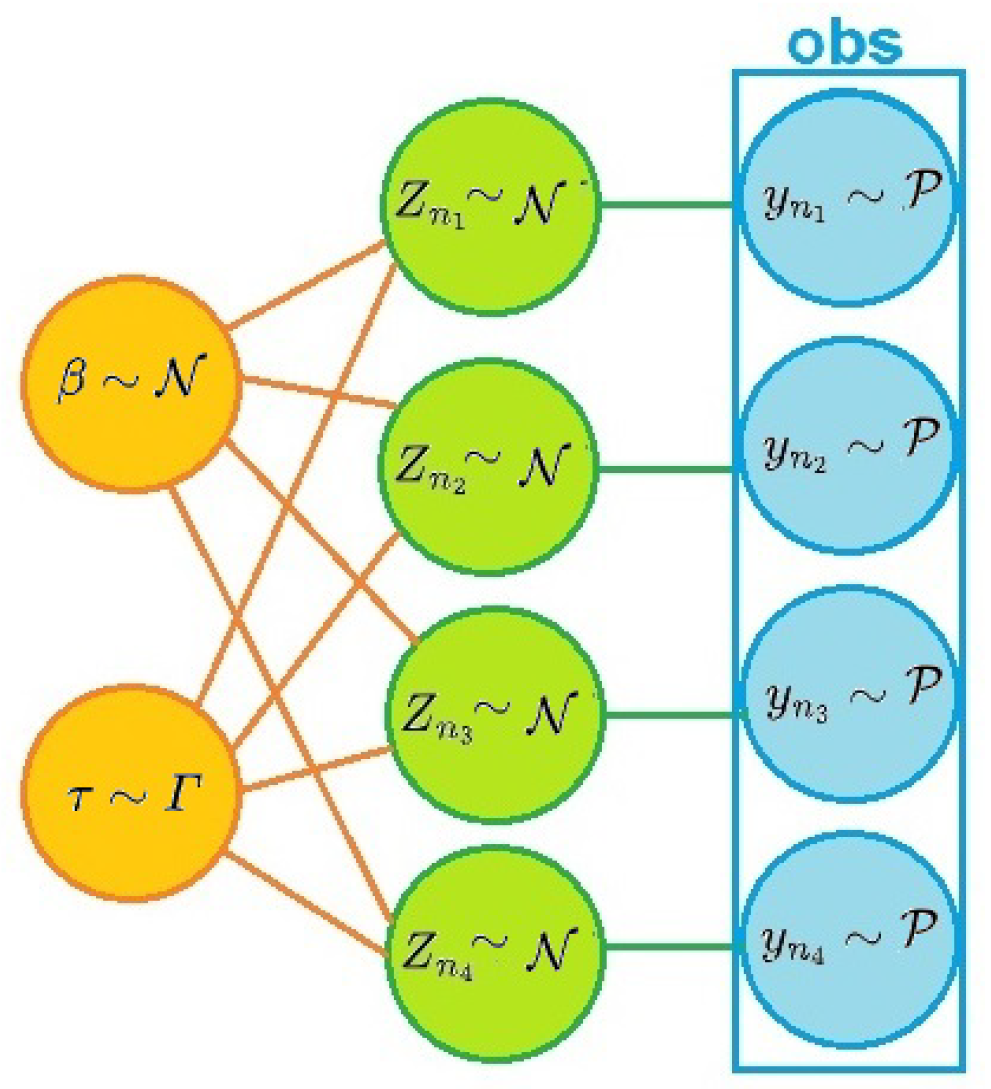
5. Numerical Experimentations of Normal–Poisson Distribution
The Normal–Poisson example is a non–conjugacy generalized mix model. The observed data are from a Poisson distribution named
and a design vector
, for
. The considered model is in
Figure 1:
where
In the first step, we approximate the posterior joint distribution of
,
and
for
via MFVBA:
We need to write
:
where
C is a constant and does not depend on unknown variables. We start with computing the distributions of
for
. For the simplicity of notations, we assume that
n is a natural number in the interval
, and
means all
distribution items except the
nth one, and
means the expectation over density
q. Thus,
, the density of
, is equivalent to the following:
Since this expression does not follow a specific distribution because of the existence of
, we omit this part according to its expectation, which is a function of
and
. We can calculate the expectations using the Normal moment–generating distribution function. The logical reason is that its expectation depends only on
and
. Moreover, we have
and
. Thus,
which means a Normal distribution for
,
for
. The process is quite similar for
and
. The corresponding equivalents of distributions for
and
are shown below, respectively:
and
In the second step, we calculate the variance diagonal matrix
:
where
and
Thus,
. The third step is to compute the Hessian matrix
:
Since
is symmetric in our case study, we need to calculate the main diagonal and the upper triangle. This covariance matrix depends on the values of
:
Thus, the diagonal of
as a function of
is shown below:
where
L is defined in Equation (
17). The upper triangle is:
The last step is to compute
using (
15). For numerical experimentation, we generate data from the Normal–Poisson model with these descriptions:
We generate
for
from the Normal distribution
. The number of the reputation for vector
is 100, so
is a matrix
. The only data we use are the observation matrix
and vector
. The covariance matrix
from MFVBA is a diagonal matrix:
where
and
are the zero vector with
N dimensions and the identity matrix with
dimensions, respectively. The Hessian matrix
and matrix
are:
and
The covariance matrix via LRVBA is:
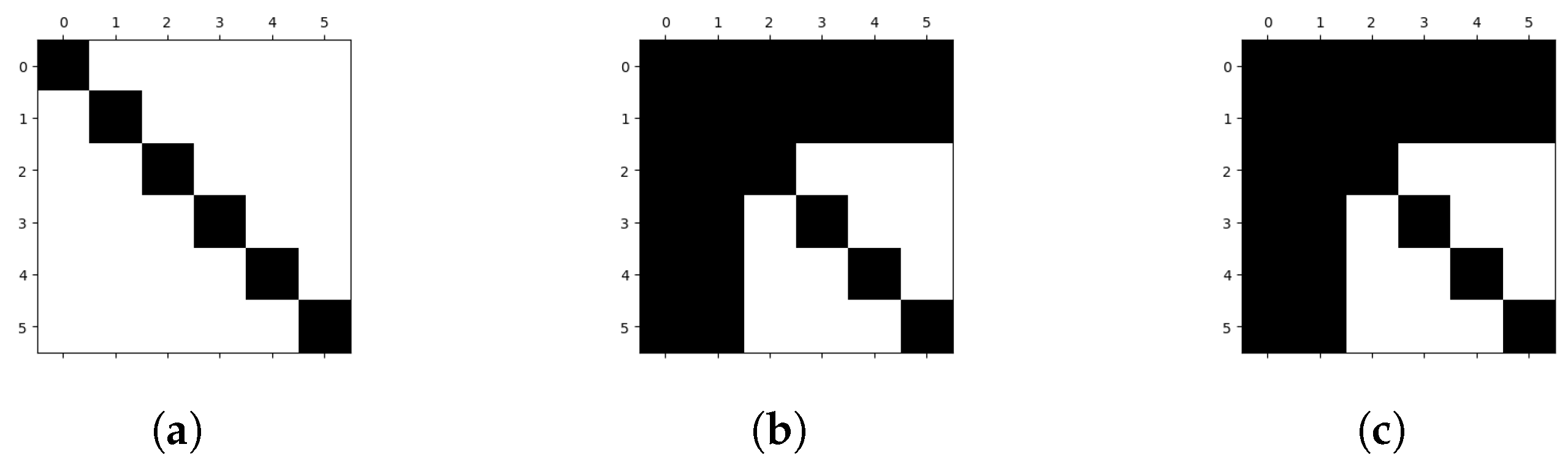
The sparsity patterns for the
,
and
matrixes are shown in
Figure 2.
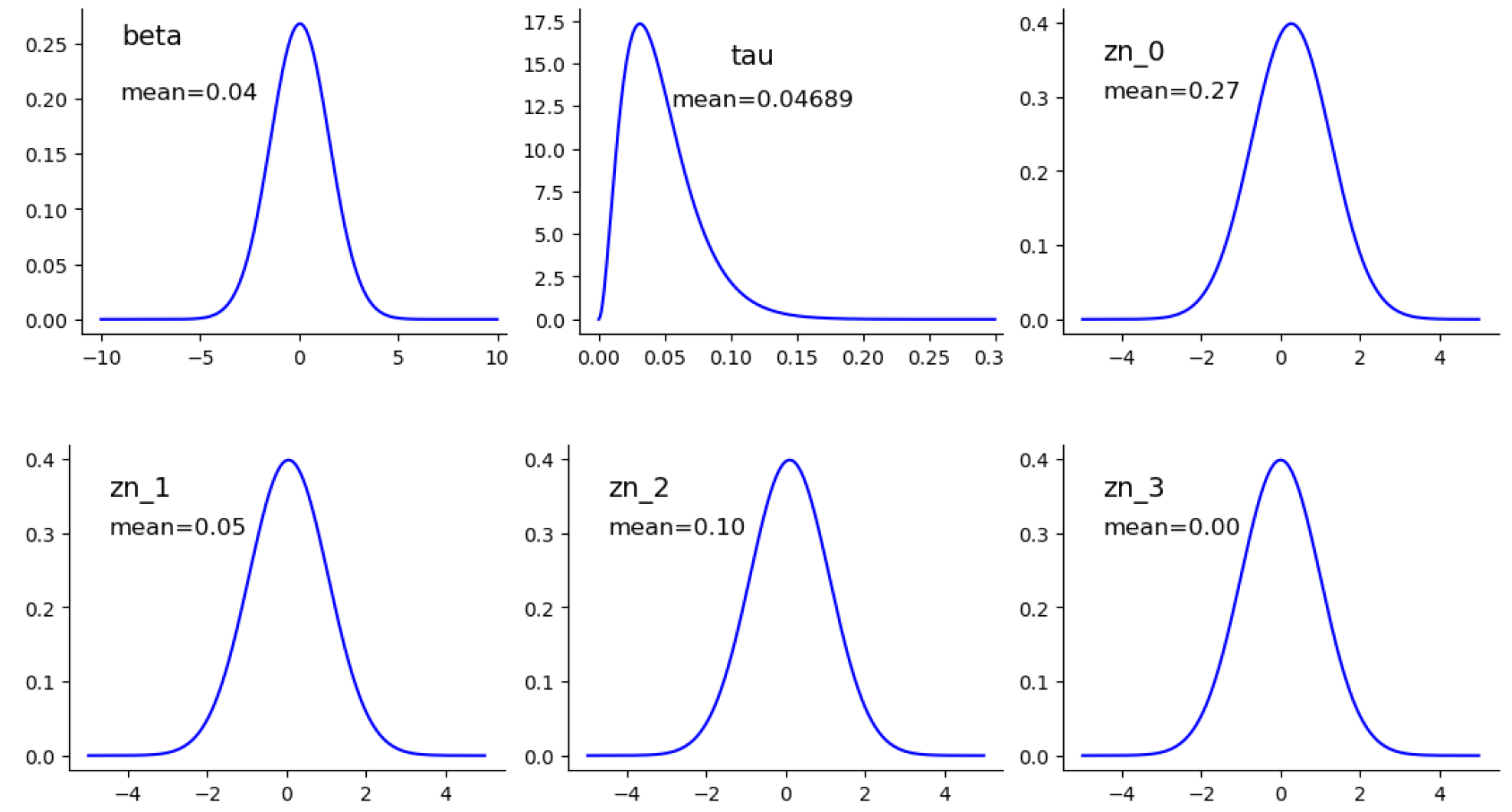
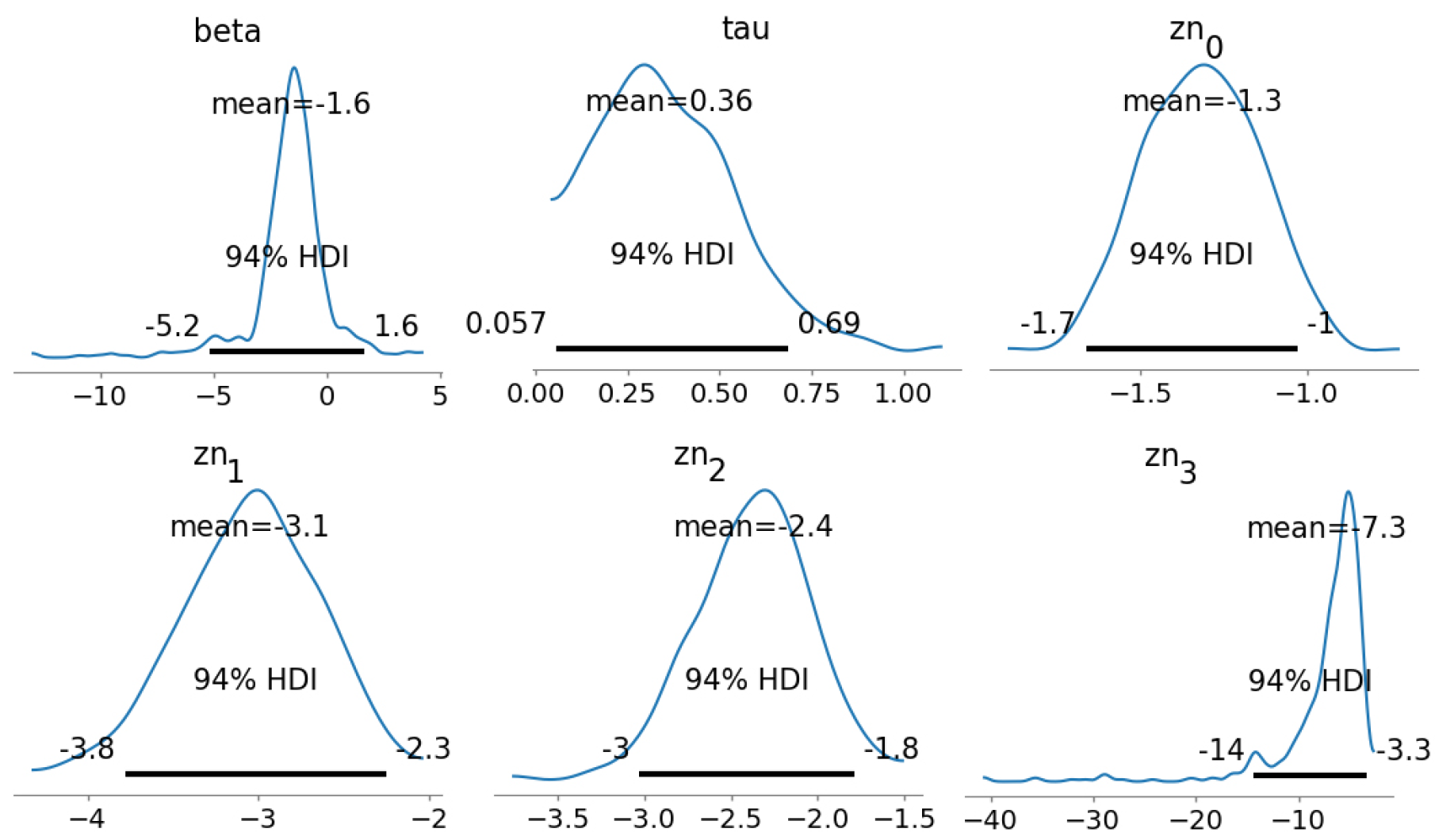
In addition, we simulate the posterior distribution via MCMC. This simulation has five chains and one divergence. The estimated marginal distribution for each unknown variable is shown in
Figure 3 and
Figure 4 via MFVBA and MCMC, respectively. More details are in
Table 1. The joint distribution of unknown variables is approximated via MFVBA and MCMC. The MFVBA distribution is the marginal density factorial of the unknown variables. Therefore, the variables are independent in MFVBA, and the covariance matrix is diagonal. LRVBA is a correction method on the covariance matrix. Thus, the matrix is no longer diagonal as presented in (
18). Also, we add more details about the MCMC results in
Table 1. The Monte Carlo Standard Error (MCSE) is a chain–accurate measure and provides a quantitative suggestion of how big the estimation noise is. The noises are small based on the mean and sd of the MCSE. The ess–bulk column delivers an evaluated bulk influential sample size using rank–normalised draws. The ess–tail column creates an approximated tail practical sample size by computing the effective minimum sample sizes between the
and
quantiles. The last column is the r–hat convergence diagnostic, which compares the between and within–chain estimation for model variables and other univariate quantities.
6. Conclusions
Bayesian computations are used to infer unknown parameters from data. ABC methods are applied to perform approximate computation, particularly in high–dimensional problems. Two classes of approximate computational methods are MCMC and VBA. MCMC generates samples from the probability function to approximate the posterior distribution. It generates a sequence of samples that converges to the target distribution. The VBA approximates the expression of the joint posterior distribution of unknown parameters in a complex model using a simple expression. VBA has some advantages over MCMC, such as being faster, more scalable and versatile. It also guarantees convergence to a local minimum of KL divergence.
VBA’s drawback is that it underestimates the covariance matrix of the unknowns. For this aim, we use LRVB to approximate the covariance more precisely. However, the LRVB computations still need the inversion of some matrixes, which is costly when the unknown parameters’ dimensions are high. We work on a numerical example to show the whole process of VBA and LRVB as well as the performance and ability of the proposed method and compare it with the classical MCMC results. As a result of the numerical example, the VBA implementation was much shorter than the MCMC, and we had an explicit form of joint distribution with a modified covariance matrix with the LRVB aid.









{kind=link}
{kind=link}
{kind=link}
{kind=link}