
Online Machine-Learning-Based Event Selection for COMET Phase-I †

 ,
,
Abstract
:1. Introduction
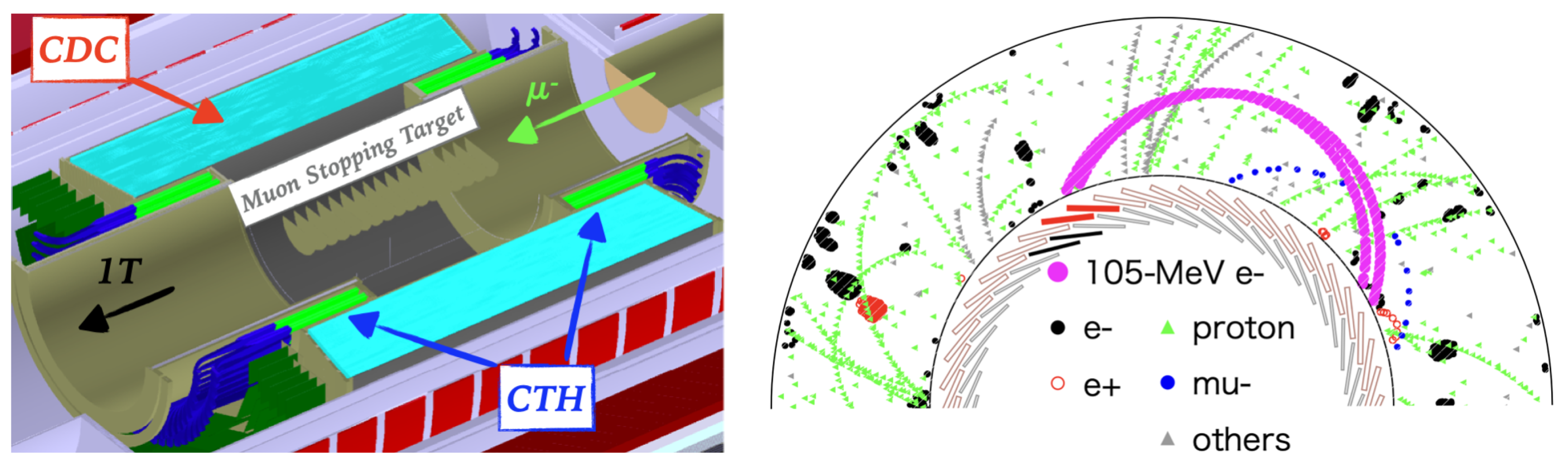
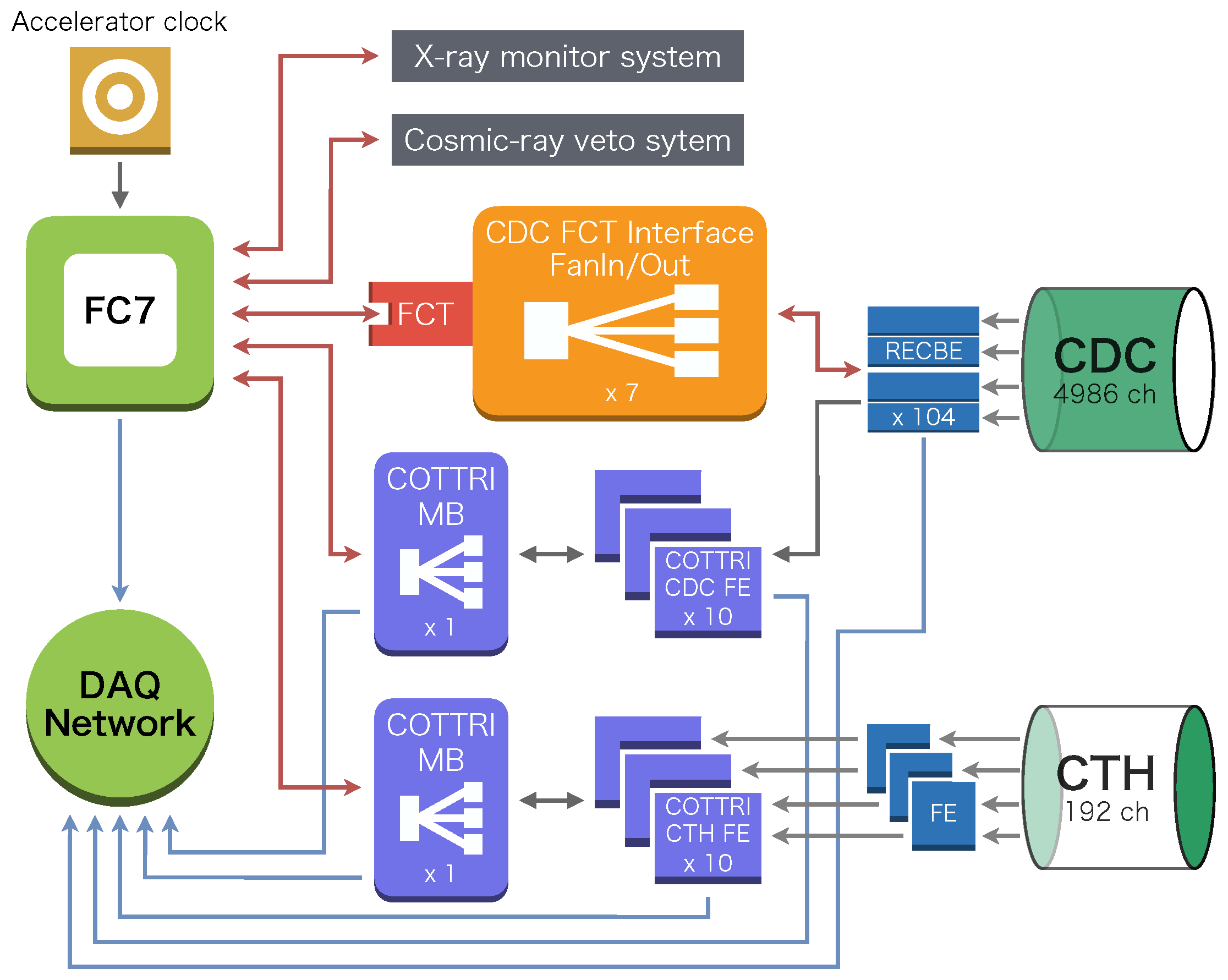
2. The COTTRI System
3. The Event Classification
- Limited FPGA resources for large-sized neural networks, such as a convoluted neural networks.
- The complexity of converting NN models into FPGA firmware using hardware-level synthesis (HLS) language.
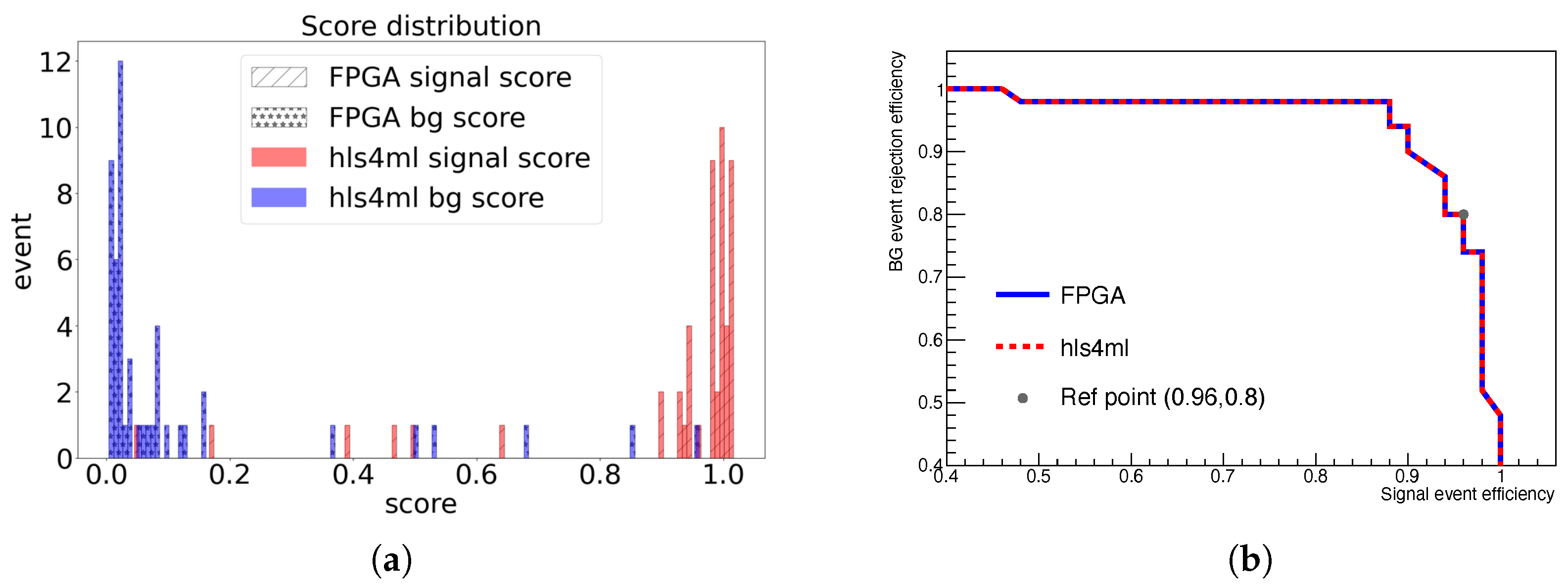
4. The Performance Test
5. Results
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FPGA | Field-Programmable Gate Array |
References
- Adamov, G. COMET Phase-I Technical Design Report. Prog. Theor. Exp. Phys. 2020, 2020, 033C01. [Google Scholar] [CrossRef] [Green Version]
- Dekkers, S. Searching for Muon to Electron with the COMET Experiment. In Proceedings of the 23rd International Workshop on Neutrinos from Accelerators (NuFact2022), Salt Lake City, UT, USA, 30–31 July 2022. [Google Scholar]
- Bernstein, R.H.; Cooper, P.S. Charged lepton flavor violation: An experimenter’s guide. Phys. Rept. 2013, 532, 27–64. [Google Scholar] [CrossRef] [Green Version]
- Fujii, Y.; Nakazawa, Y.; Gillies, E.L.; Hamada, E.; Ikeno, M.; Lee, M.; Mihara, S.; Miyazaki, Y.; Shoji, M.; Tai, C.T.; et al. Development of the Fast Front-end Trigger System for COMET Phase-I. In Proceedings of the 2018 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), Sydney, NSW, Australia, 10–17 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Nakazawa, Y.; Fujii, Y.; Ikeno, M.; Kuno, Y.; Lee, M.; Mihara, S.; Shoji, M.; Uchida, T.; Ueno, K.; Yoshida, H. An FPGA-Based Trigger System With Online Track Recognition in COMET Phase-I. IEEE Trans. Nucl. Sci. 2021, 68, 2028–2034. [Google Scholar] [CrossRef]
- Zhou, X.; Ito, Y.; Nakano, K. An Efficient Implementation of the One-Dimensional Hough Transform Algorithm for Circle Detection on the FPGA. In Proceedings of the 2014 Second, International Symposium on Computing and Networking, Shizuoka, Japan, 10–12 December 2014; pp. 447–452. [Google Scholar] [CrossRef]
- Buttinger, W. The ATLAS Level-1 Trigger System. J. Phys. Conf. Ser. 2012, 396, 012010. [Google Scholar] [CrossRef]
- The CMS Trigger System. J. Phys. Conf. Ser. 2022, 2375, 012003. [CrossRef]
- FastML Team. fastmachinelearning/hls4ml; Zenodo: Genève, Switzerland, 2021. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vivado Design Suite: Logic Simulation (UG900); Xilinx: San Jose, CA, USA, 2023.
- Integrated Logic Analyzer v6.2; Xilinx: San Jose, CA, USA, 2016.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BRAM Usage (%) | DSP Usage (%) | FF Usage (%) | LUT Usage (%) | Latency |
|---|---|---|---|---|
| 0 | 0 | 5 | 32 | 26 clock cycles |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fujii, Y.; Miyataki, M.; Lee, M.; Nakazawa, Y.; Pinchbeck, L.; Ueno, K.; Yoshida, H. Online Machine-Learning-Based Event Selection for COMET Phase-I. Phys. Sci. Forum 2023, 8, 32. https://doi.org/10.3390/psf2023008032
Fujii Y, Miyataki M, Lee M, Nakazawa Y, Pinchbeck L, Ueno K, Yoshida H. Online Machine-Learning-Based Event Selection for COMET Phase-I. Physical Sciences Forum. 2023; 8(1):32. https://doi.org/10.3390/psf2023008032
Chicago/Turabian StyleFujii, Yuki, Masaki Miyataki, MyeongJae Lee, Yu Nakazawa, Liam Pinchbeck, Kazuki Ueno, and Hisataka Yoshida. 2023. "Online Machine-Learning-Based Event Selection for COMET Phase-I" Physical Sciences Forum 8, no. 1: 32. https://doi.org/10.3390/psf2023008032