
Financial Time Series Modelling Using Fractal Interpolation Functions


Abstract
:1. Introduction
2. Fractal Interpolation
2.1. Iterated Function Systems
2.2. Self-Affine Fractal Interpolation Functions
2.3. Recurrent Fractal Interpolation Functions
3. Financial Time Series Modelling
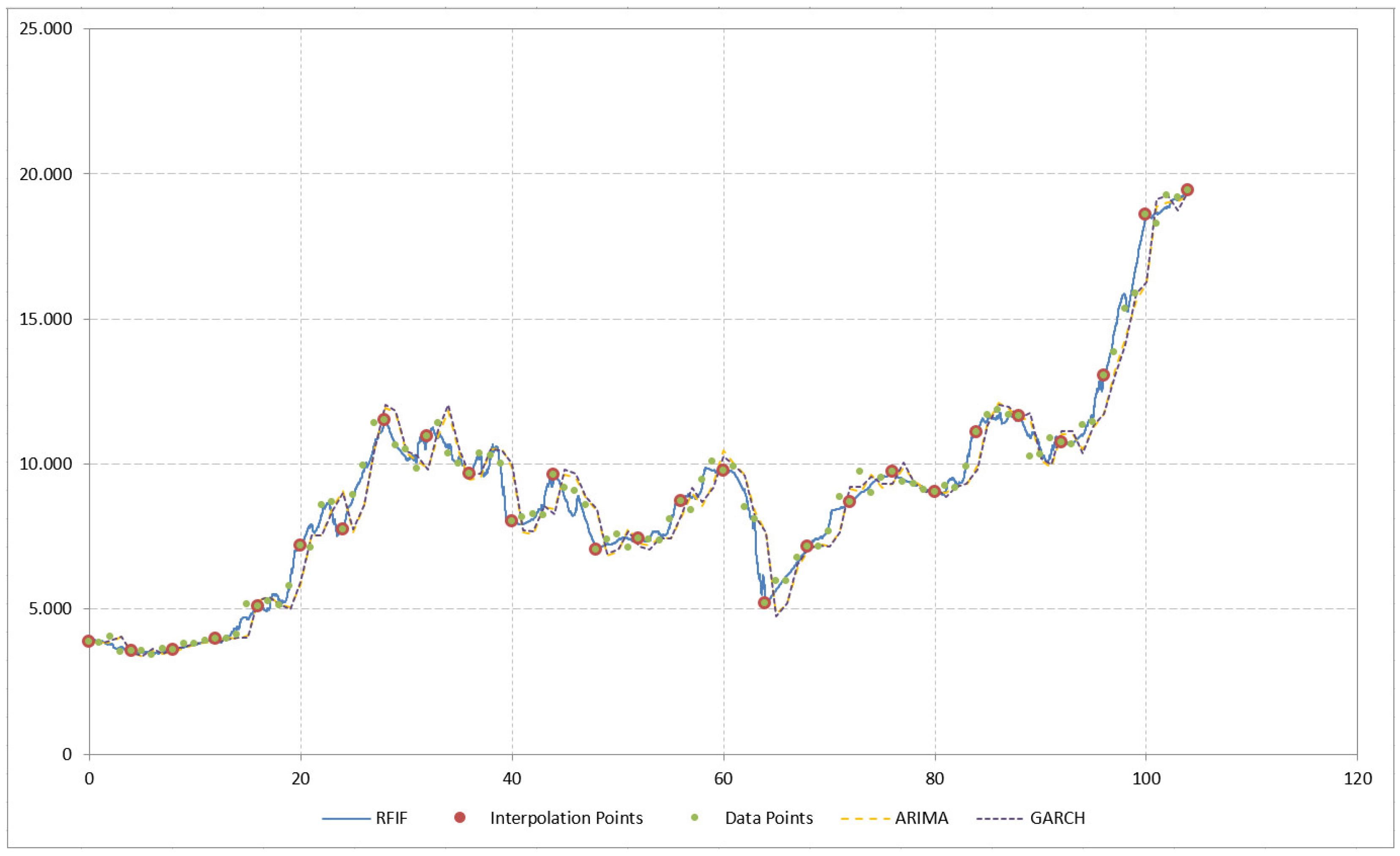
3.1. Dataset 1—Bitcoin Prices
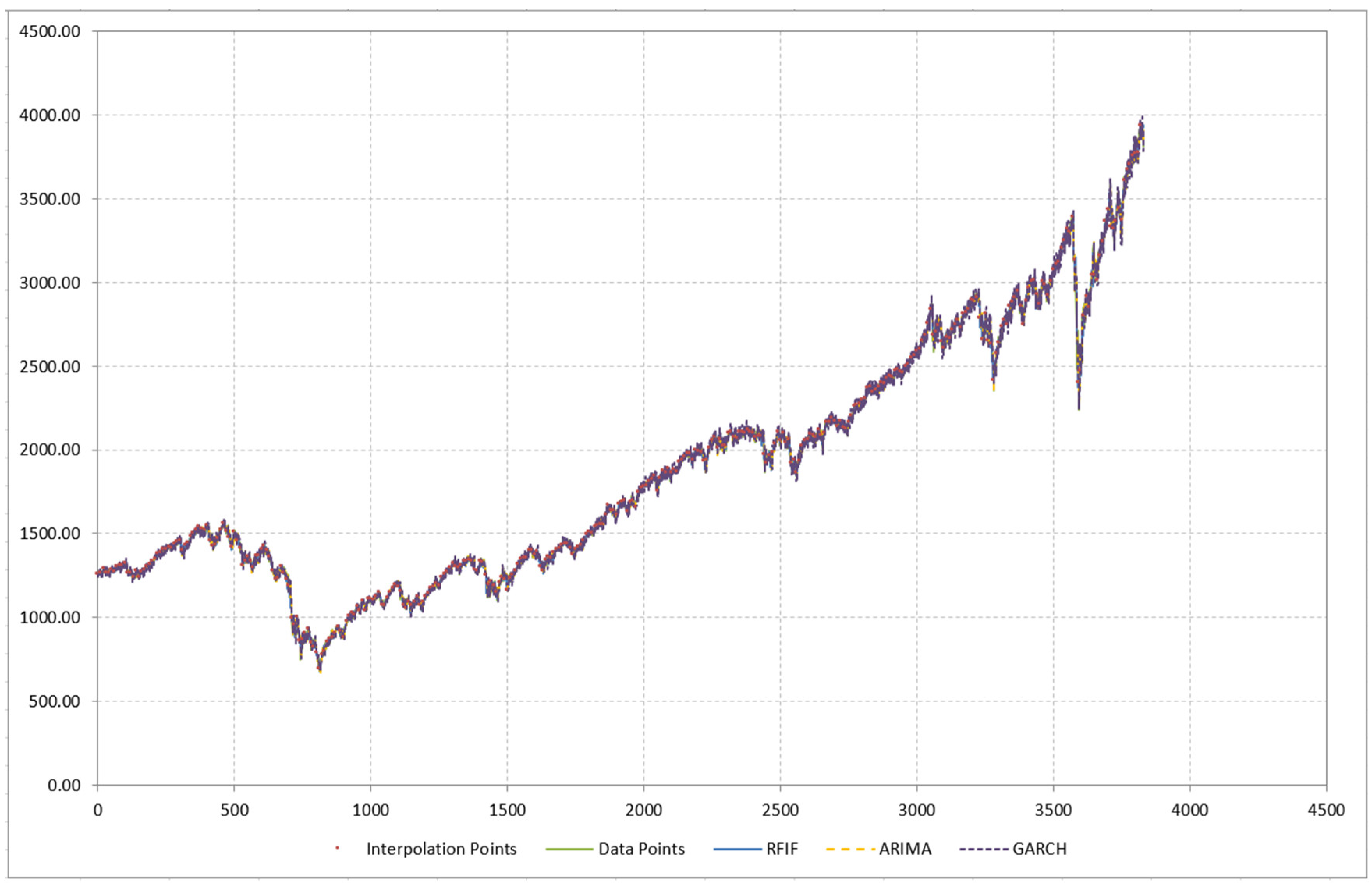
3.2. Dataset 2—S&P 500
3.3. Dataset 3—U.S.A. GDP
3.4. Comparison to Existing Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsay, R.S. Analysis of Financial Time Series, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Taylor, S.J. Modelling Financial Time Series, 2nd ed.; World Scientific Publishing Co.: Singapore, 2008. [Google Scholar]
- Barnsley, M.F. Fractal functions and interpolation. Constr. Approx. 1986, 2, 303–329. [Google Scholar] [CrossRef]
- Barnsley, M.F. Fractals Everywhere, 3rd ed.; Dover Publications: Mineola, NY, USA, 2012. [Google Scholar]
- Manousopoulos, P.; Drakopoulos, V.; Theoharis, T. Curve fitting by fractal interpolation. Trans. Comput. Sci. 2008, 1, 85–103. [Google Scholar]
- Manousopoulos, P.; Drakopoulos, V. On the Application of Fractal Interpolation Functions within the Reliability Engineering Framework, Statistical Modeling of Reliability Structures and Industrial Processes; Taylor & Francis Group; CRC Press: Boca Raton, FL, USA, 2022. [Google Scholar]
- Li, Z.; Han, J.; Song, Y. On the forecasting of high-frequency financial time series based on ARIMA model improved by deep learning. J. Forecast. 2020, 39, 1081–1097. [Google Scholar] [CrossRef]
- Samitas, A.; Kampouris, E.; Polyzos, E.; Spyridou, A. Spillover effects between Greece and Cyprus: A DCC model on the interdependence of small economies. Invest. Manag. Financ. Innov. 2020, 17, 121–135. [Google Scholar]
- Sun, H.; Yu, B. Forecasting financial returns volatility: A GARCH-SVR model. Comput. Econ. 2020, 55, 451–471. [Google Scholar] [CrossRef]
- Pantos, T.; Polyzos, E.; Armenatzoglou, A.; Kampouris, E. Volatility spillovers in electricity markets: Evidence from the United States. Int. J. Energy Econ. Policy 2019, 9, 131–143. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Valavanis, K.P. Surveying stock market forecasting techniques–Part II: Soft computing methods. Expert Syst. Appl. 2009, 36, 5932–5941. [Google Scholar] [CrossRef]
- Lee, M.; Chen, C.D. The intraday behaviors and relationships with its underlying assets: Evidence on option market in Taiwan. Int. Rev. Financ. Anal. 2005, 14, 587–603. [Google Scholar] [CrossRef]
- Bhattacharjee, B.; Kumar, R.; Senthilkumar, A. Unidirectional and bidirectional LSTM models for edge weight predictions in dynamic cross-market equity networks. Int. Rev. Financ. Anal. 2022, 84, 102384. [Google Scholar] [CrossRef]
- Polyzos, E.; Fotiadis, A.; Samitas, A. COVID-19 Tourism Recovery in the ASEAN and East Asia Region: Asymmetric Patterns and Implications; ERIA Discussion Paper Series, Paper No. 379; ERIA: Jakarta, Indonesia, 2021. [Google Scholar]
- Ozbayoglu, A.M.; Gudelek, M.U.; Sezer, O.B. Deep learning for financial applications: A survey. Appl. Soft Comput. 2020, 93, 106384. [Google Scholar] [CrossRef]
- Henrique, B.M.; Sobreiro, V.A.; Kimura, H. Literature review: Machine learning techniques applied to financial market prediction. Expert Syst. Appl. 2019, 124, 226–251. [Google Scholar] [CrossRef]
- Bailey, D.H.; Borwein, J.M.; de Prado, M.L.; Zhu, Q.J. Pseudomathematics and financial charlatanism: The effects of backtest over fitting on out-of-sample performance. Not. AMS 2014, 61, 458–471. [Google Scholar]
- Chen, D.; Ye, J.; Ye, W. Interpretable selective learning in credit risk. Res. Int. Bus. Financ. 2023, 65, 101940. [Google Scholar] [CrossRef]
- Ghosh, I.; Alfaro-Cortés, E.; Gámez, M.; García-Rubio, N. Prediction and interpretation of daily NFT and DeFi prices dynamics: Inspection through ensemble machine learning & XAI. Int. Rev. Financ. Anal. 2023, 87, 102558. [Google Scholar]
- Goodell, J.W.; Jabeur, S.B.; Saâdaoui, F.; Nasir, M.A. Explainable artificial intelligence modeling to forecast bitcoin prices. Int. Rev. Financ. Anal. 2023, 88, 102702. [Google Scholar] [CrossRef]
- Evertsz, C.J.G. Fractal geometry of financial time series. Fractals 1995, 3, 609–616. [Google Scholar] [CrossRef]
- Richards, G.R. A fractal forecasting model for financial time series. J. Forecast. 2004, 23, 586–601. [Google Scholar] [CrossRef] [Green Version]
- Kapecka, A. Fractal Analysis of Financial Time Series Using Fractal Dimension and Pointwise Holder Exponents. Dyn. Econ. Model. 2013, 13, 107–126. [Google Scholar]
- Bhatt, S.J.; Dedania, H.V.; Shah Vipul, R. Fractal Dimensional Analysis in Financial Time Series. Int. J. Financ. Manag. 2015, 5, 46–52. [Google Scholar] [CrossRef]
- Leon-Ogazon, M.A.; Romero-Flores, E.A.; Morales-Acoltzi, T.; Machorro-Rodriguez, A.; Salazar-Medina, M. Fractal Interpolation in the Financial Analysis of a Company. Int. J. Bus. Adm. 2017, 8, 80–86. [Google Scholar] [CrossRef]
- Bianchi, S.; Pianese, A. Time-varying Hurst–Hölder exponents and the dynamics of (in)efficiency in stock markets. Chaos Solitons Fractals 2018, 109, 64–75. [Google Scholar] [CrossRef]
- Cho, P.; Kim, K. Global Collective Dynamics of Financial Market Efficiency Using Attention Entropy with Hierarchical Clustering. Fractal Fract. 2022, 6, 562. [Google Scholar] [CrossRef]
- Lee, M.; Cho, Y.; Ock, S.E.; Song, J.W. Analyzing Asymmetric Volatility and Multifractal Behavior in Cryptocurrencies Using Capital Asset Pricing Model Filter. Fractal Fract. 2023, 7, 85. [Google Scholar] [CrossRef]
- Li, X.; Su, F. The Dynamic Effects of COVID-19 and the March 2020 Crash on the Multifractality of NASDAQ Insurance Stock Markets. Fractal Fract. 2023, 7, 91. [Google Scholar] [CrossRef]
- Lu, K.-C.; Chen, K.-S. Uncovering Information Linkages between Bitcoin, Sustainable Finance and the Impact of COVID-19: Fractal and Entropy Analysis. Fractal Fract. 2023, 7, 424. [Google Scholar] [CrossRef]
- Mazel, D.S.; Hayes, M.H. Using iterated function systems to model discrete sequences. IEEE Trans. Signal Process. 1992, 40, 1724–1734. [Google Scholar] [CrossRef]
- Manousopoulos, P.; Drakopoulos, V.; Theoharis, T. Parameter identification of 1D fractal interpolation functions using bounding volumes. J. Comput. Appl. Math. 2009, 233, 1063–1082. [Google Scholar] [CrossRef] [Green Version]
- Manousopoulos, P.; Drakopoulos, V.; Theoharis, T. Parameter Identification of 1D Recurrent Fractal Interpolation Functions with Applications to Imaging and Signal Processing. J. Math. Imaging Vis. 2011, 40, 162–170. [Google Scholar] [CrossRef]
- Uemura, S.; Haseyama, M.; Kitajima, H. Efficient contour shape description by using fractal interpolation functions. In Proceedings of the IEEE Proceedings of International Conference on Image Processing, Rochester, NY, USA, 22–25 September; 2002; pp. 485–488. [Google Scholar]
- Brinks, R. A hybrid algorithm for the solution of the inverse problem in fractal interpolation. Fractals 2005, 13, 215–226. [Google Scholar] [CrossRef]
- Walther, T.; Klein, T.; Bouri, E. Exogenous drivers of Bitcoin and Cryptocurrency volatility–A mixed data sampling approach to forecasting. J. Int. Financ. Mark. Inst. Money 2019, 63, 101133. [Google Scholar] [CrossRef]
- Martens, M. Measuring and forecasting S&P 500 index-futures volatility using high-frequency data. J. Futures Mark. Futures Options Other Deriv. Prod. 2002, 22, 497–518. [Google Scholar]
- Yoon, J. Forecasting of real GDP growth using machine learning models: Gradient boosting and random forest approach. Comput. Econ. 2021, 57, 247–265. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 2 December 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1—Bitcoin Prices | |||
|---|---|---|---|
| Mean Abs. Error | Mean Abs. % Error | RMSE | |
| ARIMA | 547.71 | 6.46% | 740.16 |
| GARCH | 557.96 | 6.55% | 762.67 |
| RFIF | 198.40 | 2.34% | 289.18 |
| Dataset 2—S&P 500 | |||
|---|---|---|---|
| Mean Abs. Error | Mean Abs. % Error | RMSE | |
| ARIMA | 13.95 | 0.80% | 22.57 |
| GARCH | 23.91 | 1.31% | 32.12 |
| RFIF | 10.42 | 0.59% | 17.65 |
| Dataset 3—U.S.A. GDP | |||
|---|---|---|---|
| Mean Abs. Error | Mean Abs. % Error | RMSE | |
| ARIMA | 55.51 | 1.10% | 158.42 |
| GARCH | 88.11 | 1.52% | 171.20 |
| RFIF | 20.07 | 0.35% | 92.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manousopoulos, P.; Drakopoulos, V.; Polyzos, E. Financial Time Series Modelling Using Fractal Interpolation Functions. AppliedMath 2023, 3, 510-524. https://doi.org/10.3390/appliedmath3030027
Manousopoulos P, Drakopoulos V, Polyzos E. Financial Time Series Modelling Using Fractal Interpolation Functions. AppliedMath. 2023; 3(3):510-524. https://doi.org/10.3390/appliedmath3030027
Chicago/Turabian StyleManousopoulos, Polychronis, Vasileios Drakopoulos, and Efstathios Polyzos. 2023. "Financial Time Series Modelling Using Fractal Interpolation Functions" AppliedMath 3, no. 3: 510-524. https://doi.org/10.3390/appliedmath3030027