
Arabic Aspect-Based Sentiment Classification Using Seq2Seq Dialect Normalization and Transformers


Abstract
:1. Introduction
 ) has many morphemes that express an English sentence, “and they will see it” [8,9].
) has many morphemes that express an English sentence, “and they will see it” [8,9]. ) may have several meanings, “lesson”, “study”, and “taught”. Moreover, the massive number of Arabic dialects and the unavailability of dialectical Arabic (DA) language resources are well-known problems that lead to the lack of training datasets, making research in this field more complicated. Consequently, these dialectical words are considered out-of-vocabulary (OOV) words in many pre-trained language models.
) may have several meanings, “lesson”, “study”, and “taught”. Moreover, the massive number of Arabic dialects and the unavailability of dialectical Arabic (DA) language resources are well-known problems that lead to the lack of training datasets, making research in this field more complicated. Consequently, these dialectical words are considered out-of-vocabulary (OOV) words in many pre-trained language models.- We propose a new solution that improves the results of ABSA by converting the dialectical text into MSA using text normalization.
- We used a pre-trained based model (BERT) with sentence pair input to solve the Arabic ABSA classification task, including MSA and dialect, instead of traditional machine learning (ML) algorithms.
- We adopted a sequence-to-sequence model for normalizing out-of-vocabulary (OOV) words from our dataset.
- We pre-processed and built a training dataset for the normalization model using two well-known public datasets.
2. Related Work
2.1. English Aspect-Based Sentiment Analysis
2.2. Arabic Aspect-Based Sentiment Analysis
3. Proposed Model
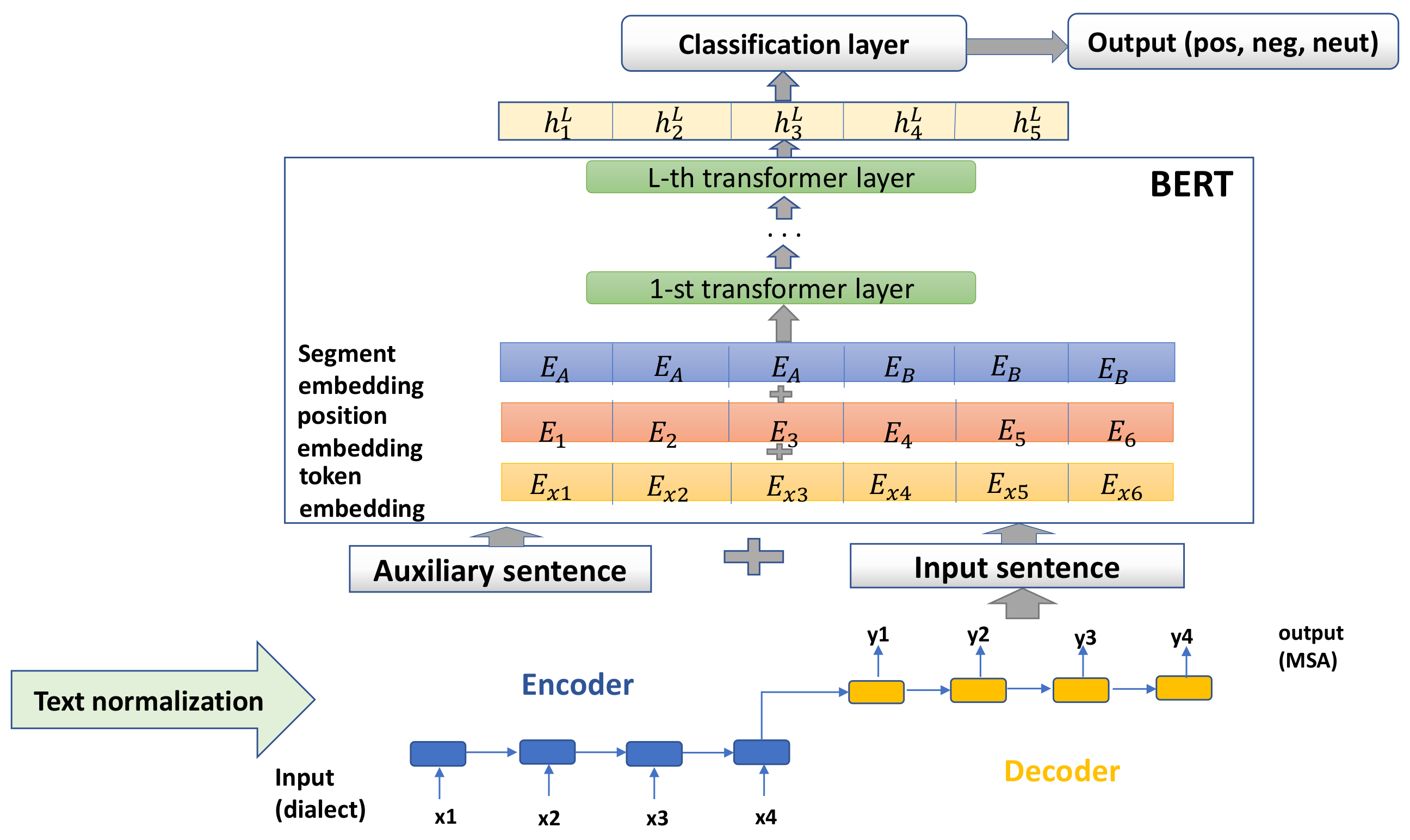
3.1. Encoder–Decoder Architecture
3.2. Explanation of the T2 Model
3.3. Explanation of the T4 Model
- QA-M method: It refers to the question-answering task. The auxiliary sentence generated from the category is a question.As an example (Table 2), for “ رواية رائعة، انا حسيت وكأني عايش”, the category here is “المشاعر”, where the generated sentence is “ما رأيك في المشاعر؟”
- NLI-M method: For the natural language inference (NLI) task, the auxiliary sentence contains only the category of the sentence. For the previous example (Table 3), the auxiliary sentence formed is اْلمشاعرْ.
4. Experimental Setup
4.1. Dataset Description
4.2. Hyper-Parameter Setting
4.3. Performance Measures
5. Results and Discussion
5.1. Experimental Series 1
5.2. Experimental Series 2
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fan, H.; Du, W.; Dahou, A.; Ewees, A.A.; Yousri, D.; Elaziz, M.A.; Elsheikh, A.H.; Abualigah, L.; Al-qaness, M.A.A. Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics 2021, 10, 1332. [Google Scholar] [CrossRef]
- Hoang, M.; Bihorac, O.A.; Rouces, J. Aspect-based sentiment analysis using bert. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 31 May 2019; pp. 187–196. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-qaness, M.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Abdelgwad, M.M.; Soliman, T.H.A.; Taloba, A.I.; Farghaly, M.F. Arabic aspect based sentiment analysis using bidirectional GRU based models. J. King Saud-Univ.-Comput. Inf. Sci. 2021; in press. [Google Scholar]
- Al-Smadi, M.; Qawasmeh, O.; Talafha, B.; Quwaider, M. Human annotated arabic dataset of book reviews for aspect based sentiment analysis. In Proceedings of the 2015 3rd International Conference on Future Internet of Things and Cloud, Rome, Italy, 24–26 August 2015; pp. 726–730. [Google Scholar]
- Obaidat, I.; Mohawesh, R.; Al-Ayyoub, M.; AL-Smadi, M.; Jararweh, Y. Enhancing the determination of aspect categories and their polarities in Arabic reviews using lexicon-based approaches. In Proceedings of the 2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Adel, H.; Dahou, A.; Mabrouk, A.; Abd Elaziz, M.; Kayed, M.; El-Henawy, I.M.; Alshathri, S.; Amin Ali, A. Improving Crisis Events Detection Using DistilBERT with Hunger Games Search Algorithm. Mathematics 2022, 10, 447. [Google Scholar] [CrossRef]
- Obied, Z.; Solyman, A.; Ullah, A.; Fat’hAlalim, A.; Alsayed, A. BERT Multilingual and Capsule Network for Arabic Sentiment Analysis. In Proceedings of the 2020 International Conference On Computer, Control, Electrical, and Electronics Engineering (ICCCEEE), Khartoum, Sudan, 26 February–1 March 2021; pp. 1–6. [Google Scholar]
- Oueslati, O.; Cambria, E.; HajHmida, M.B.; Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Hamada, S.; Marzouk, R.M. Developing a transfer-based system for Arabic Dialects translation. In Intelligent Natural Language Processing: Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 121–138. [Google Scholar]
- Al-Ibrahim, R.; Duwairi, R.M. Neural machine translation from Jordanian Dialect to modern standard Arabic. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 173–178. [Google Scholar]
- Torjmen, R.; Haddar, K. Translation system from Tunisian Dialect to Modern Standard Arabic. Concurr. Comput. Pract. Exp. 2022, 34, e6788. [Google Scholar] [CrossRef]
- Hegazi, M.O.; Al-Dossari, Y.; Al-Yahy, A.; Al-Sumari, A.; Hilal, A. Preprocessing Arabic text on social media. Heliyon 2021, 7, e06191. [Google Scholar] [CrossRef]
- Tachicart, R.; Bouzoubaa, K. Moroccan data-driven spelling normalization using character neural embedding. Vietnam J. Comput. Sci. 2021, 8, 113–131. [Google Scholar] [CrossRef]
- Husain, F.; Uzuner, O. Investigating the Effect of Preprocessing Arabic Text on Offensive Language and Hate Speech Detection. Trans. Asian-Low-Resour. Lang. Inf. Process. 2022, 21, 1–20. [Google Scholar] [CrossRef]
- Elnagar, A.; Yagi, S.; Nassif, A.B.; Shahin, I.; Salloum, S.A. Sentiment analysis in dialectal Arabic: A systematic review. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 22–24 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 407–417. [Google Scholar]
- Xue, W.; Li, T. Aspect based sentiment analysis with gated convolutional networks. arXiv 2018, arXiv:1805.07043. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; Al-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 Task 5: Aspect basEd Sentiment Analysis. In Proceedings of the International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 19–30. [Google Scholar]
- Liu, N.; Shen, B. Aspect-based sentiment analysis with gated alternate neural network. Knowl.-Based Syst. 2020, 188, 105010. [Google Scholar] [CrossRef]
- Li, X.; Bing, L.; Zhang, W.; Lam, W. Exploiting BERT for End-to-End Aspect-based Sentiment Analysis. arXiv 2019, arXiv:1910.00883. [Google Scholar] [CrossRef]
- Li, X.; Bing, L.; Li, P.; Lam, W. A unified model for opinion target extraction and target sentiment prediction. AAAI Conf. Artif. Intell. 2019, 33, 6714–6721. [Google Scholar] [CrossRef]
- Xu, B.; Wang, X.; Yang, B.; Kang, Z. Target embedding and position attention with lstm for aspect based sentiment analysis. In Proceedings of the 2020 5th International Conference on Mathematics and Artificial Intelligence, Chengdu, China, 10–13 April 2020; pp. 93–97. [Google Scholar]
- Trueman, T.E.; Cambria, E. A convolutional stacked bidirectional LSTM with a multiplicative attention mechanism for aspect category and sentiment detection. Cogn. Comput. 2021, 13, 1423–1432. [Google Scholar]
- Abdelgwad, M.M. Arabic aspect based sentiment analysis using BERT. arXiv 2021, arXiv:2107.13290. [Google Scholar]
- Al-Sarhan, H.; Al-So’ud, M.; Al-Smadi, M.; Al-Ayyoub, M.; Jararweh, Y. Framework for affective news analysis of arabic news: 2014 gaza attacks case study. In Proceedings of the 2016 7th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 5–7 April 2016; pp. 327–332. [Google Scholar]
- Ashi, M.M.; Siddiqui, M.A.; Nadeem, F. Pre-trained word embeddings for Arabic aspect-based sentiment analysis of airline tweets. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 3–5 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 241–251. [Google Scholar]
- Al-Dabet, S.; Tedmori, S.; Mohammad, A.S. Enhancing Arabic aspect-based sentiment analysis using deep learning models. Comput. Speech Lang. 2021, 69, 101224. [Google Scholar] [CrossRef]
- Mohammad, A.S.; Hammad, M.M.; Sa’ad, A.; Saja, A.T.; Cambria, E. Gated Recurrent Unit with Multilingual Universal Sentence Encoder for Arabic Aspect-Based Sentiment Analysis. Knowl.-Based Syst. 2021, 107540. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Talafha, B.; Al-Ayyoub, M.; Jararweh, Y. Using long short-term memory deep neural networks for aspect-based sentiment analysis of Arabic reviews. Int. J. Mach. Learn. Cybern. 2019, 10, 2163–2175. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep Recurrent neural network vs. support vector machine for aspect-based sentiment analysis of Arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Javaloy, A.; García-Mateos, G. Text normalization using encoder–decoder networks based on the causal feature extractor. Appl. Sci. 2020, 10, 4551. [Google Scholar] [CrossRef]
- Lourentzou, I.; Manghnani, K.; Zhai, C. Adapting sequence to sequence models for text normalization in social media. Int. AAAI Conf. Web Soc. Media 2019, 13, 335–345. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence. arXiv 2019, arXiv:1903.09588. [Google Scholar]
- Meftouh, K.; Harrat, S.; Jamoussi, S.; Abbas, M.; Smaili, K. Machine translation experiments on PADIC: A parallel Arabic dialect corpus. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 26–34. [Google Scholar]
- Bouamor, H.; Habash, N.; Salameh, M.; Zaghouani, W.; Rambow, O.; Abdulrahim, D.; Obeid, O.; Khalifa, S.; Eryani, F.; Erdmann, A.; et al. The MADAR Arabic Dialect Corpus and Lexicon. In Proceedings of the LREC, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Safaya, A.; Abdullatif, M.; Yuret, D. Kuisail at semeval-2020 task 12: Bert-cnn for offensive speech identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 2054–2059. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Obeid, O.; Zalmout, N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. CAMeL tools: An open source python toolkit for Arabic natural language processing. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 7022–7032. [Google Scholar]
- Ruder, S.; Ghaffari, P.; Breslin, J.G. INSIGHT-1 at SemEval-2016 Task 5: Deep Learning for Multilingual Aspect-based Sentiment Analysis. arXiv 2016, arXiv:1609.02748. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Task | Model | Dataset |
|---|---|---|---|
| Aspect-based sentiment analysis in English | |||
| Xue et al. [17] | ACSA and ATSA | CNN and gating mechanism | SemEval2014 datasets |
| Liu et al. [19] | ABSA | Gated Alternate NN (GANN) | SemEval2014, four Chinese and Tweeter dataset |
| Li et al. [20] | Aspect term (E2E-ABSA) | BERT | Two review datasets from SemEval |
| Xu et al. [22] | ATSA and ACSA | RNN and Target embedding | SemEval and a twitter dataset |
| Trueman et al. [23] | ACSA and SPD | convolutional stacked bi-LSTM and attention mechanism | SemEval-2015 and SemEval-2016 |
| Aspect-based sentiment analysis in Arabic | |||
| Abdelgwad et al. [24] | ASPC | Pre-trained model BERT | HAAD, Arabic News and Arabic Hotel Reviews datasets |
| Abdelgwad et al. [4] | ASPC and AOTE | GRU and CNN | Arabic hotel reviews dataset |
| Ashi et al. [26] | AE and ASPC | Word embedding | Arabic airline-related tweets |
| Al-Dabet et al. [27] | OTE extraction and ASPC | CNN and LSTM | Arabic SemEval-2016 dataset |
| Mohammad et al. [28] | AE and ASPC | (GRU) | Arabic hotel reviews |
| Al-Smadi et al. [29] | Aspect OTE and ASPC | LSTM | Arabic Hotels’ reviews |
| Al-Smadi et al. [30] | ACSA, aspect OTE extraction and ASPC | RNN and SVM | Arabic Hotels’ reviews |
| Sentence | Auxiliary Sentence | Sentiment |
|---|---|---|
| S1 | ما رأيك في الاسلوب ؟ | Positive |
| S1 | ما رأيك في المشاعر ؟ | None |
| S1 | ما رأيك في الحبكة ؟ | None |
| S1 | ما رأيك في السياق ؟ | None |
| Sentence | Auxiliary Sentence | Sentiment |
|---|---|---|
| S1 | الاسلوب | Positive |
| S1 | الهوامش | None |
| S1 | السياق | None |
| S1 | الخاتمة | None |
| Dataset | Total Samples | Selected Samples |
|---|---|---|
| PADIC | 32,060 | 16,978 |
| MADAR | 100,000 | 18,994 |
| Dataset | Task Model | Label | Training Set | Valid Set | Test Set |
|---|---|---|---|---|---|
| HAAD | T2 | Pos | 1054 | 37 | 285 |
| Neg | 972 | 52 | 263 | ||
| Neut | 118 | 5 | 24 | ||
| T4 | Pos | 586 | / | 137 | |
| Neg | 590 | / | 161 | ||
| Neut | 16 | / | 3 | ||
| conf | 18 | / | 2 | ||
| SemEval-2016 | T2 | Pos | 5747 | 72 | 1426 |
| Neg | 3119 | 22 | 784 | ||
| Neut | 654 | 6 | 162 |
| Experiment | Normalization Training Dataset | Normalization Training Accuracy | Task Model Training
Dataset |
|---|---|---|---|
| Exp 1 | Cairo dialect from MADAR | 91.1% | HAAD and SemEval with only normalized Egyptian samples |
| Exp 2 | All PADIC and MADAR | 95% | HAAD and SemEval with only normalized Egyptian samples |
| Exp 3 | All PADIC and MADAR | 95% | All normalized samples from HAAD and SemEval |
| Dataset | HAAD | SemEval-2016 |
|---|---|---|
| Without Norm | 73.42% | 83.76% |
| Exp 1 | 74.85% | 83.81% |
| Exp 2 | 74.77% | 84.65% |
| Exp 3 | 66.39% | 79.76% |
| Method | NLI-M | QA-M |
|---|---|---|
| Without Norm | 75.90% | 75.08% |
| Exp 1 | 76.89% | 75.49% |
| Exp 2 | 76.50% | 76.48% |
| Exp 3 | 75.42% | 75.24% |
| Model | HAAD | SemEval-2016 |
|---|---|---|
| T2: Aspect term polarity | ||
| Abdelgawad et al. [4] | NA | 83.98 |
| Abdelgawad et al. [24] | 73.23 | NA |
| Al-Smadi et al. [29] | NA | 82.6 |
| Ruder et al. [42] | NA | 82.7 |
| Our model | 74.85 | 84.65 |
| T4: Aspect category polarity | ||
| Obaidat et al. [6] | 71 | NA |
| Our model | 76.48 | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chennafi, M.E.; Bedlaoui, H.; Dahou, A.; Al-qaness, M.A.A. Arabic Aspect-Based Sentiment Classification Using Seq2Seq Dialect Normalization and Transformers. Knowledge 2022, 2, 388-401. https://doi.org/10.3390/knowledge2030022
Chennafi ME, Bedlaoui H, Dahou A, Al-qaness MAA. Arabic Aspect-Based Sentiment Classification Using Seq2Seq Dialect Normalization and Transformers. Knowledge. 2022; 2(3):388-401. https://doi.org/10.3390/knowledge2030022
Chicago/Turabian StyleChennafi, Mohammed ElAmine, Hanane Bedlaoui, Abdelghani Dahou, and Mohammed A. A. Al-qaness. 2022. "Arabic Aspect-Based Sentiment Classification Using Seq2Seq Dialect Normalization and Transformers" Knowledge 2, no. 3: 388-401. https://doi.org/10.3390/knowledge2030022