
Kernel Two-Sample and Independence Tests for Nonstationary Random Processes †

Abstract
:1. Introduction
2. Related Work
3. mmd and hsic for Nonstationary Random Processes
3.1. Notation and Assumptions
3.2. mmd for Nonstationary Random Processes
3.3. hsic for Nonstationary Random Processes
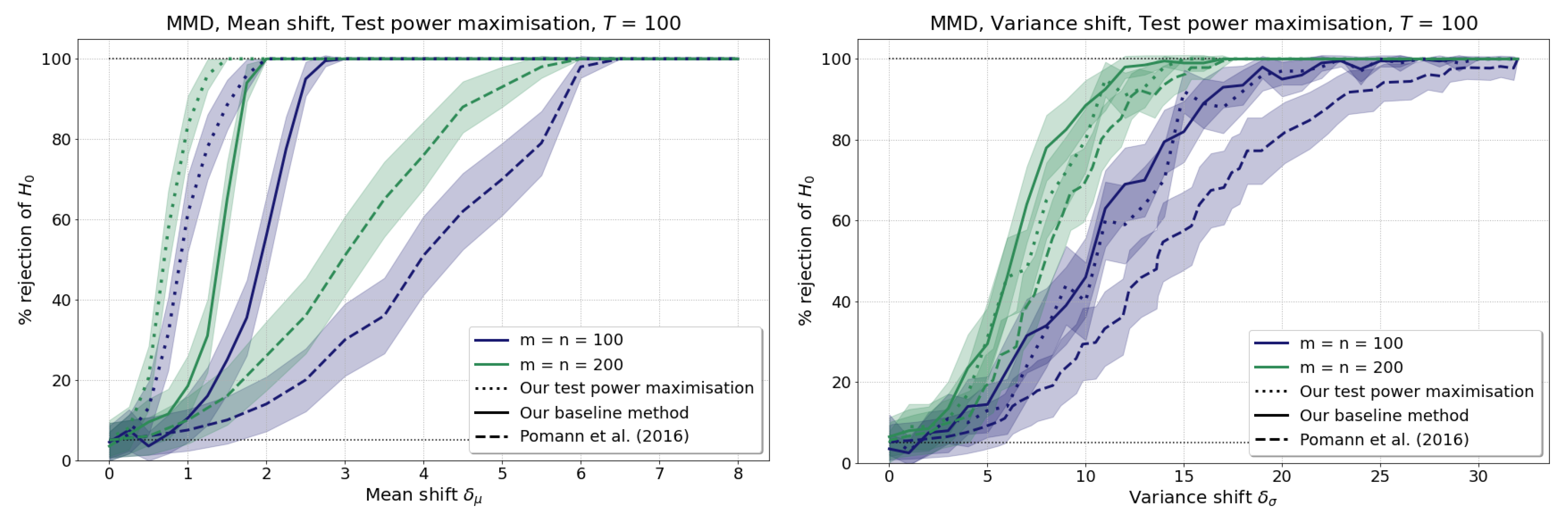
3.4. Maximising the Test Power
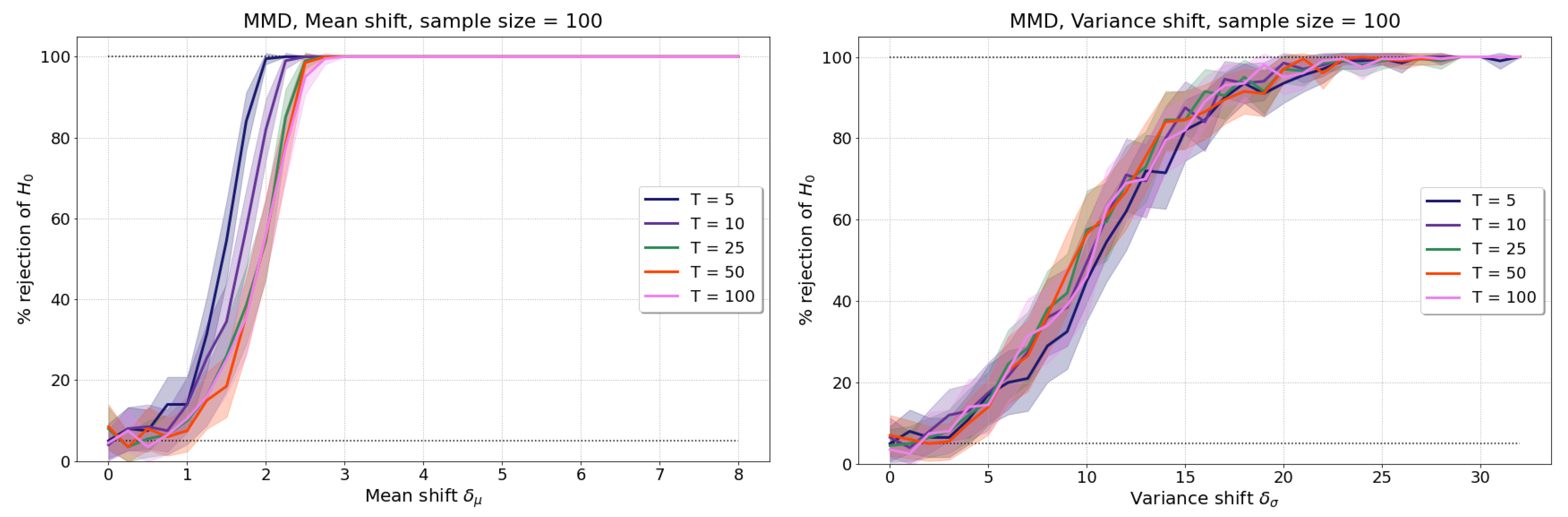
4. Experimental Results on Synthetic Data
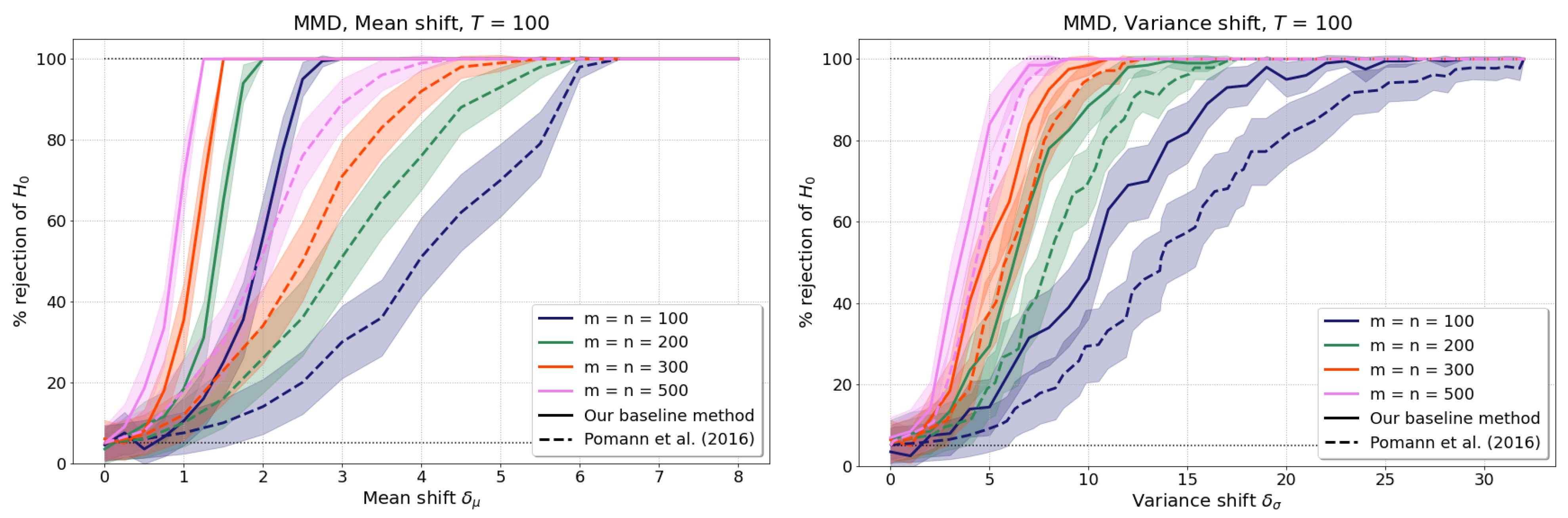
4.1. Homogeneity Tests with mmd
4.1.1. Setup
- Mean shift: and . The basis coefficients are sampled as and , and the additive noises are sampled as .
- Variance shift: We take , and introduce a shift in variance in the first basis function coefficients via and . The second coefficients are sampled as , and the noises as .
4.1.2. Baseline Results without Test Power Optimisation
4.1.3. Results of the Optimised Test
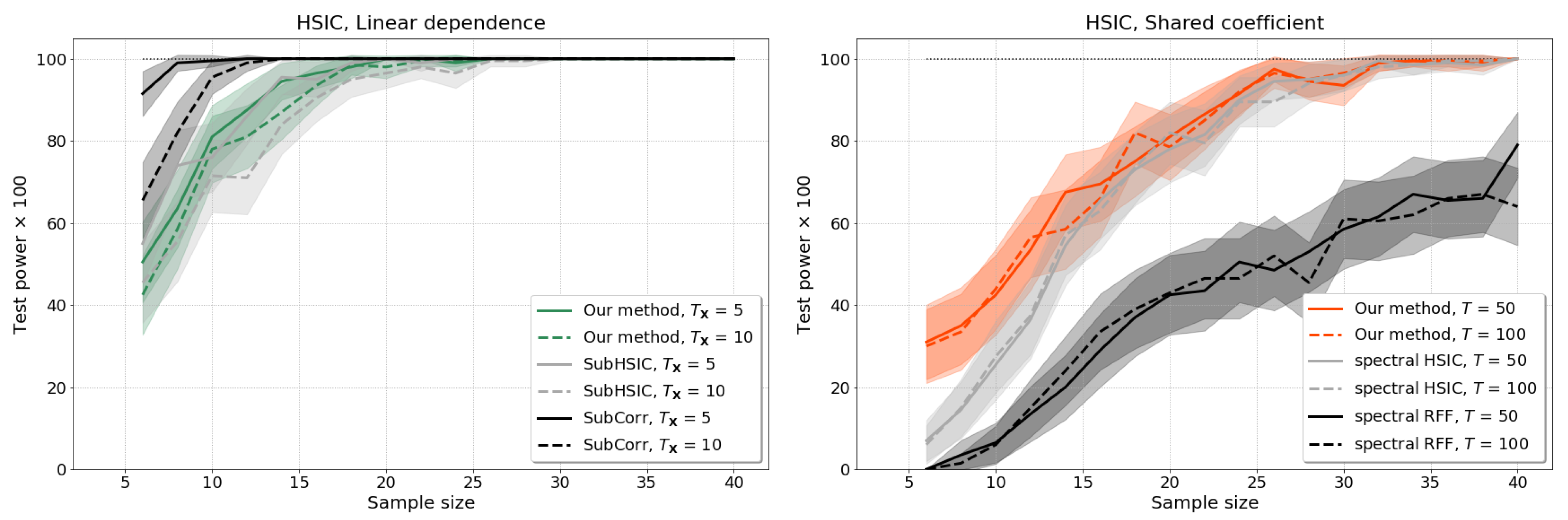
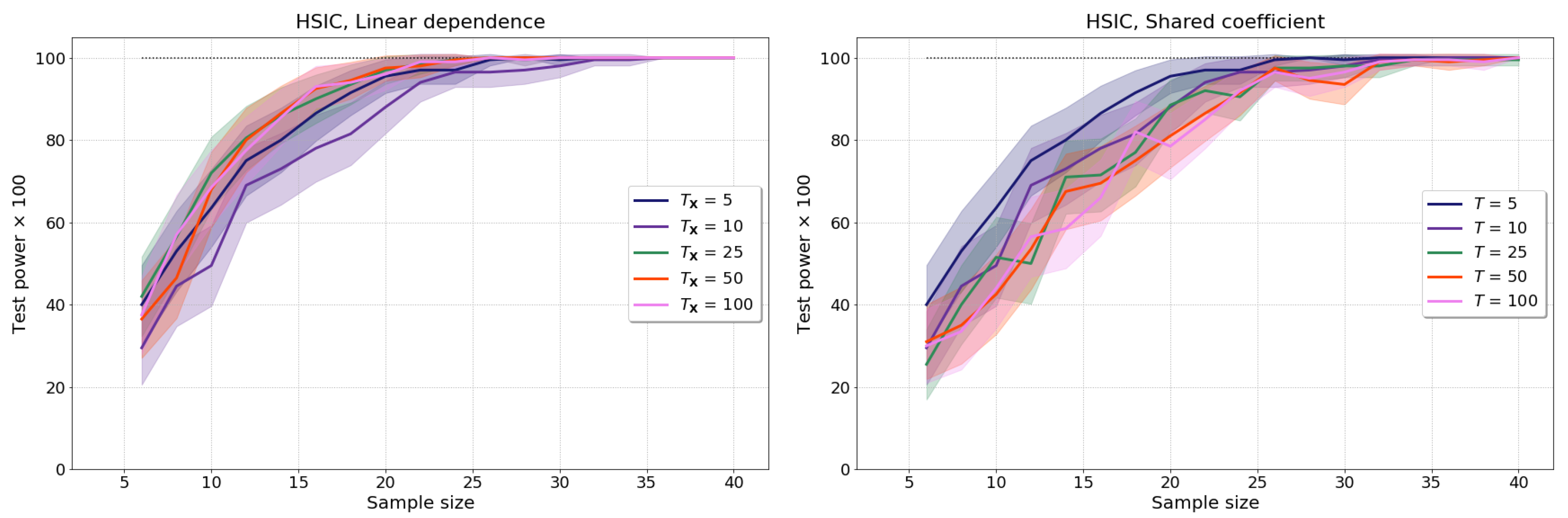
4.2. Independence Tests with hsic
4.2.1. Setup
- Dependence through a shared coefficient: and are generated as in (9) with and independently sampled , , , as in the mean shift experiments of Section 4.1, but where the stochastic processes now share the second basis function coefficient: .
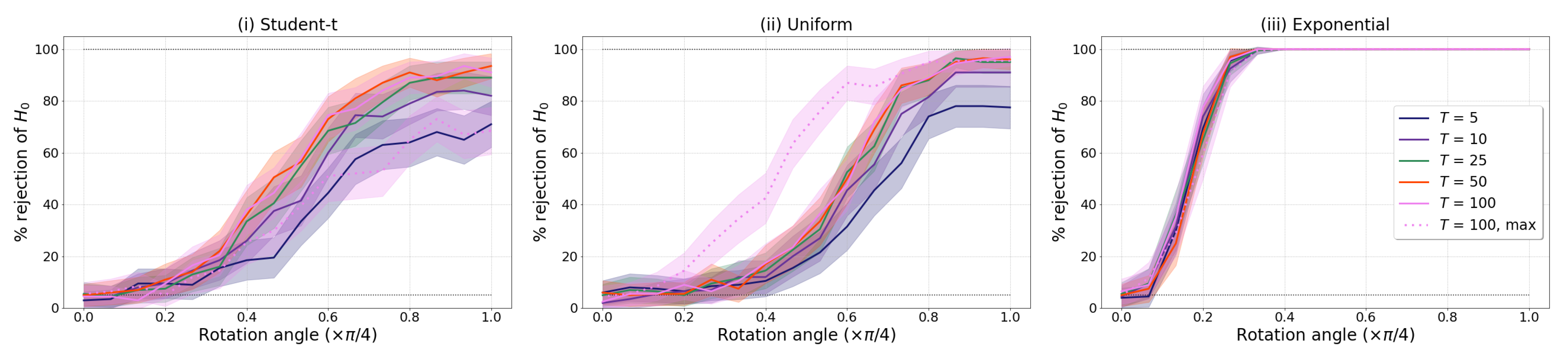
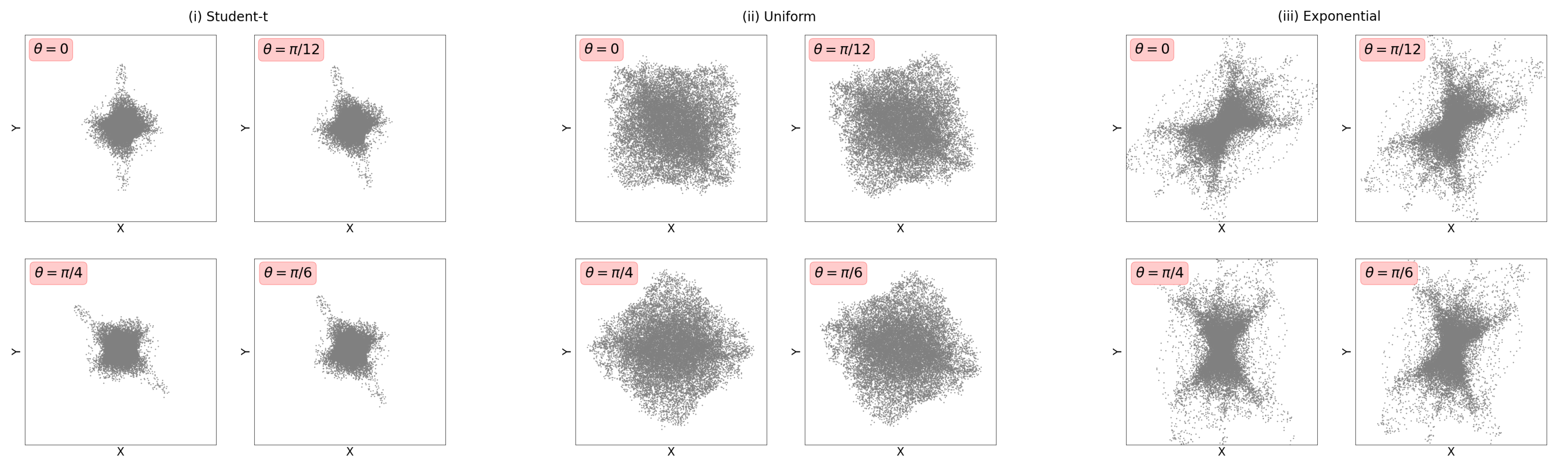
- Dependence through rotation: We start by generating independent and as in (9) with and , but with and drawn from: (i) student-t, (ii) uniform, or (iii) exponential distributions [28] (Table 3). We next multiply by a rotation matrix with to generate new rotated samples , which we then test for independence. Clearly, for our samples are independent and as is increased their dependence becomes easier to detect (see [7] (Section 4) and Figure A3 for implementation details).
4.2.2. Baseline Results without Test Power Optimisation
4.2.3. Results of the Optimised Test
5. Application to a Socioeconomic Dataset
6. Discussion and Conclusions
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Appendix A
Appendix A.1. Results for Realisations with Varying Number of Time Points, T


Appendix A.2. Test Power Maximisation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0–2 | 2.25–3 | 3.25–5 | 5.5–8 | 0–4 | 5–14 | 15–32 | ||
| Step Size = 0.25 | Step Size = 0.5 | Step Size = 1 | ||||||
| search space for | 1 | 6 | 11 | 16 | search space for | 10 | 20 | 30 |
| 3 | 8 | 13 | 18 | 12 | 22 | 32 | ||
| 5 | 10 | 15 | 20 | 14 | 24 | 34 | ||
| 7 | 12 | 17 | 22 | 16 | 26 | 36 | ||
| 9 | 14 | 19 | 24 | 18 | 28 | 38 | ||
| 11 | 16 | 21 | 26 | 20 | 30 | 40 | ||
| 13 | 18 | 23 | 28 | 22 | 32 | 42 | ||
| 15 | 20 | 25 | 30 | 24 | 34 | 44 | ||
| 17 | 22 | 27 | 32 | 26 | 36 | 46 | ||
| 19 | 24 | 29 | 34 | 28 | 38 | 48 | ||
| 21 | 26 | 31 | 36 | 30 | 40 | 50 | ||
Appendix A.3. Distribution Specifications for Basis Function Coefficients in Rotation Mixing
| Distribution | Fourier Basis Function Coefficients | |
|---|---|---|
| Exponential | ||
| Student-t | ||
| Uniform | ||

Appendix A.4. SDG Dataset
References
- Christakis, N.A.; Fowler, J.H. The spread of obesity in a large social network over 32 years. N. Engl. J. Med. 2007, 357, 370–379. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barabási, A.L.; Gulbahce, N.; Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 2011, 12, 56–68. [Google Scholar] [CrossRef] [Green Version]
- Bond, R. Complex networks: Network healing after loss. Nat. Hum. Behav. 2017, 1, 1–2. [Google Scholar] [CrossRef]
- Battiston, S.; Mandel, A.; Monasterolo, I.; Schütze, F.; Visentin, G. A climate stress-test of the financial system. Nat. Clim. Chang. 2017, 7, 283–288. [Google Scholar] [CrossRef]
- Muandet, K.; Fukumizu, K.; Sriperumbudur, B.; Schölkopf, B. Kernel mean embedding of distributions: A review and beyond. Found. Trends Mach. Learn. 2017, 10, 1–141. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A.J. A kernel method for the two-sample-problem. arXiv 2008, arXiv:0805.2368. [Google Scholar]
- Gretton, A.; Fukumizu, K.; Teo, C.H.; Song, L.; Schölkopf, B.; Smola, A.J. A kernel statistical test of independence. NIPS 2008, 20, 585–592. [Google Scholar]
- Besserve, M.; Logothetis, N.K.; Schölkopf, B. Statistical analysis of coupled time series with Kernel Cross-Spectral Density operators. In Advances in Neural Information Processing Systems 26; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2535–2543. [Google Scholar]
- Chwialkowski, K.; Sejdinovic, D.; Gretton, A. A wild bootstrap for degenerate kernel tests. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3608–3616. [Google Scholar]
- Davis, R.A.; Matsui, M.; Mikosch, T.; Wan, P. Applications of distance correlation to time series. Bernoulli 2018, 24, 3087–3116. [Google Scholar] [CrossRef] [Green Version]
- Székely, G.J.; Rizzo, M.L.; Bakirov, N.K. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Horváth, L.; Kokoszka, P.; Reeder, R. Estimation of the mean of functional time series and a two-sample problem. J. R. Stat. Soc. Ser. B 2012, 75, 103–122. [Google Scholar] [CrossRef] [Green Version]
- Fremdt, S.; Steinbach, J.G.; Horváth, L.; Kokoszka, P. Testing the Equality of Covariance Operators in Functional Samples. Scand. J. Stat. 2012, 40, 138–152. [Google Scholar] [CrossRef] [Green Version]
- Panaretos, V.M.; Kraus, D.; Maddocks, J.H. Second-Order Comparison of Gaussian Random Functions and the Geometry of DNA Minicircles. J. Am. Stat. Assoc. 2010, 105, 670–682. [Google Scholar] [CrossRef] [Green Version]
- Pomann, G.M.; Staicu, A.M.; Ghosh, S. A two-sample distribution-free test for functional data with application to a diffusion tensor imaging study of multiple sclerosis. J. R. Stat. Soc. Ser. C 2016, 65, 395–414. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wynne, G.; Duncan, A.B. A kernel two-sample test for functional data. arXiv 2020, arXiv:2008.11095. [Google Scholar]
- Górecki, T.; Krzyśko, M.; Wołyński, W. Independence test and canonical correlation analysis based on the alignment between kernel matrices for multivariate functional data. Artif. Intell. Rev. 2018, 53, 475–499. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Filippi, S.; Gretton, A.; Sejdinovic, D. Large-scale kernel methods for independence testing. Stat. Comput. 2018, 28, 113–130. [Google Scholar] [CrossRef] [Green Version]
- Sriperumbudur, B.K.; Gretton, A.; Fukumizu, K.; Schölkopf, B.; Lanckriet, G.R. Hilbert space embeddings and metrics on probability measures. J. Mach. Learn. Res. 2010, 11, 1517–1561. [Google Scholar]
- Sriperumbudur, B.K.; Fukumizu, K.; Lanckriet, G.R. Universality, Characteristic Kernels and RKHS Embedding of Measures. J. Mach. Learn. Res. 2011, 12, 2389–2410. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A.J. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Gretton, A.; Fukumizu, K.; Harchaoui, Z.; Sriperumbudur, B.K. A fast, consistent kernel two-sample test. NIPS 2009, 23, 673–681. [Google Scholar]
- Song, L.; Smola, A.J.; Gretton, A.; Bedo, J.; Borgwardt, K. Feature selection via dependence maximization. J. Mach. Learn. Res. 2012, 13, 1393–1434. [Google Scholar]
- Ramdas, A.; Reddi, S.J.; Póczos, B.; Singh, A.; Wasserman, L. On the decreasing power of kernel and distance based nonparametric hypothesis tests in high dimensions. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Reddi, S.; Ramdas, A.; Póczos, B.; Singh, A.; Wasserman, L. On the high dimensional power of a linear-time two sample test under mean-shift alternatives. Artif. Intell. Stat. 2015, 38, 772–780. [Google Scholar]
- Serfling, R.J. Approximation Theorems of Mathematical Statistics; Wiley Series in Probability and Mathematical Statistics; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Sutherland, D.J.; Tung, H.Y.; Strathmann, H.; De, S.; Ramdas, A.; Smola, A.J.; Gretton, A. Generative models and model criticism via optimized maximum mean discrepancy. arXiv 2016, arXiv:1611.04488. [Google Scholar]
- Gretton, A.; Herbrich, R.; Smola, A.J.; Bousquet, O.; Schölkopf, B. Kernel methods for measuring independence. J. Mach. Learn. Res. 2005, 6, 2075–2129. [Google Scholar]
- World Bank. World Bank Country and Lending Groups. 2020. Available online: https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups (accessed on 28 January 2020).
- World Bank. Sustainable Development Goals. 2020. Available online: https://datacatalog.worldbank.org/dataset/sustainable-development-goals (accessed on 28 January 2020).




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laumann, F.; Kügelgen, J.v.; Barahona, M. Kernel Two-Sample and Independence Tests for Nonstationary Random Processes. Eng. Proc. 2021, 5, 31. https://doi.org/10.3390/engproc2021005031
Laumann F, Kügelgen Jv, Barahona M. Kernel Two-Sample and Independence Tests for Nonstationary Random Processes. Engineering Proceedings. 2021; 5(1):31. https://doi.org/10.3390/engproc2021005031
Chicago/Turabian StyleLaumann, Felix, Julius von Kügelgen, and Mauricio Barahona. 2021. "Kernel Two-Sample and Independence Tests for Nonstationary Random Processes" Engineering Proceedings 5, no. 1: 31. https://doi.org/10.3390/engproc2021005031