
BERT (Bidirectional Encoder Representations from Transformers) for Missing Data Imputation in Solar Irradiance Time Series †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- To the best of the authors’ knowledge, the first BERT model trained from scratch with solar irradiance data is introduced;
- (2)
- The implementation is evaluated for time series imputation in two scenarios, namely (1) the imputation of a single missing value at a specific position and (2) imputed a missing value where all values were missing after this position in the sequence.
2. Methodology
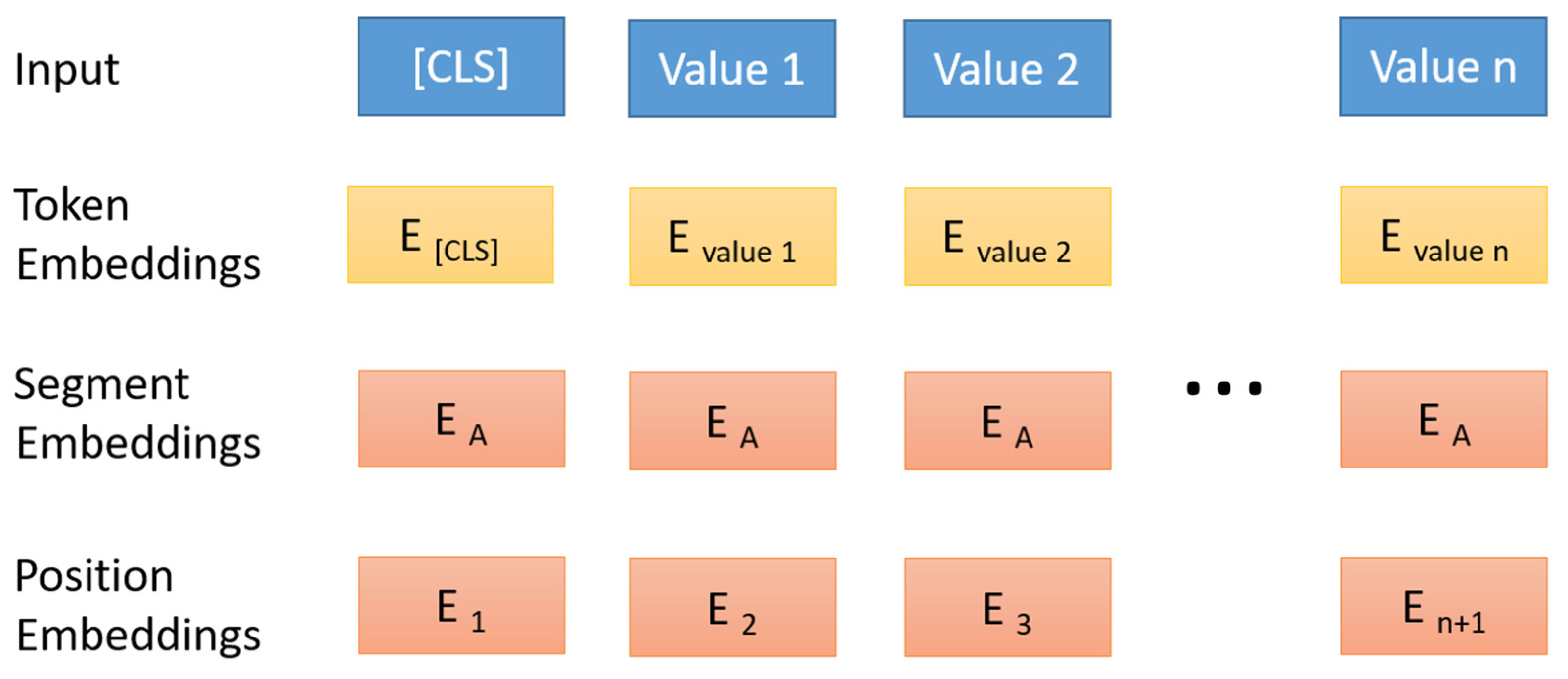
2.1. Studied Model (BERT)
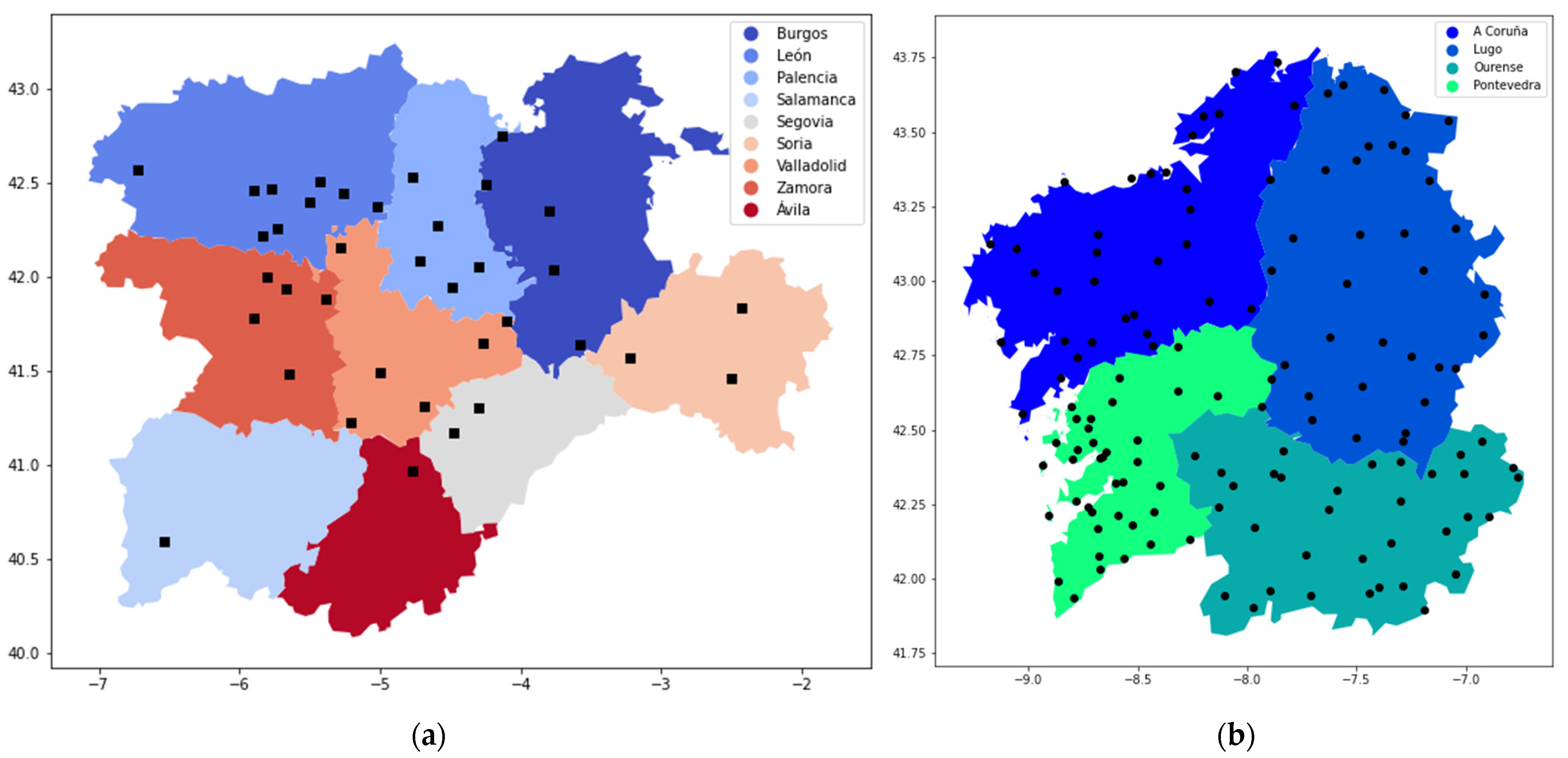
2.2. Data Description
2.3. Methodology
3. Results and Discussion
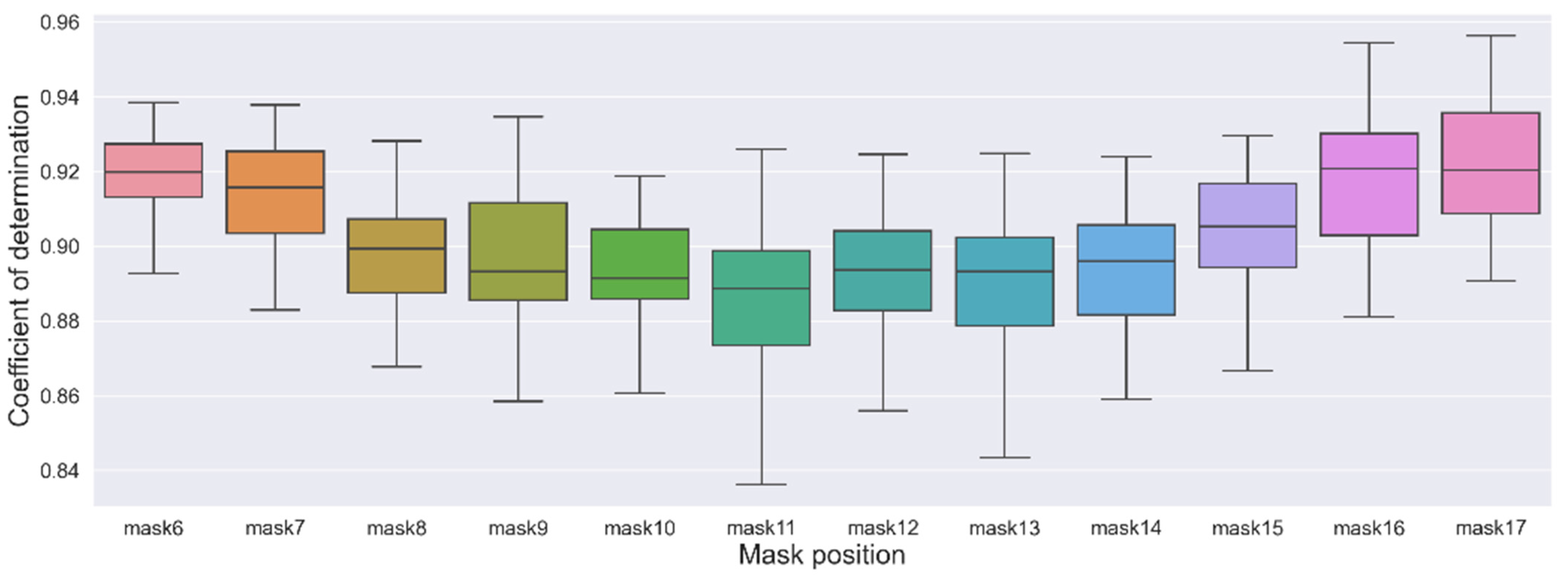
3.1. Scenario 1: Imputation of a Single Missing Value at a Specific Position
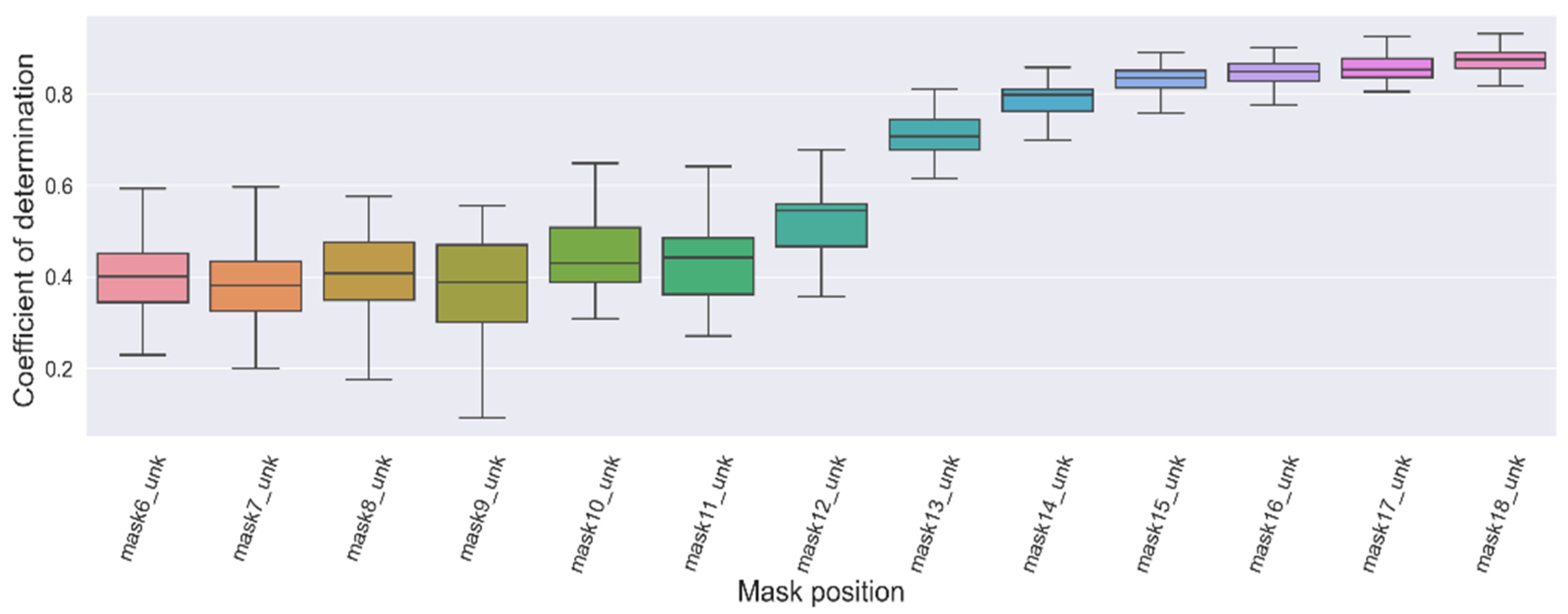
3.2. Scenario 2: Imputation of a Missing Value after Several Unknown Values at a Random Position
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chatfield, C. The Analysis of Time Series, 6th ed.; Chapman and Hall/CRC: New York, NY, USA, 2003; ISBN 9780203491683. [Google Scholar]
- Fang, C.; Wang, C. Time Series Data Imputation: A Survey on Deep Learning Approaches. arXiv 2020, arXiv:2011.11347. [Google Scholar]
- Glasbey, C.A. Imputation of Missing Values in Spatio-Temporal Solar Radiation Data. Environmetrics 1995, 6, 363–371. [Google Scholar] [CrossRef]
- Layanun, V.; Suksamosorn, S.; Songsiri, J. Missing-Data Imputation for Solar Irradiance Forecasting in Thailand. In Proceedings of the 2017 56th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Kanazawa, Japan, 19–22 September 2017; pp. 1234–1239. [Google Scholar]
- Demirhan, H.; Renwick, Z. Missing Value Imputation for Short to Mid-Term Horizontal Solar Irradiance Data. Appl. Energy 2018, 225, 998–1012. [Google Scholar] [CrossRef]
- Zhang, W.; Luo, Y.; Zhang, Y.; Srinivasan, D. SolarGAN: Multivariate Solar Data Imputation Using Generative Adversarial Network. IEEE Trans. Sustain. Energy 2021, 12, 743–746. [Google Scholar] [CrossRef]
- de-Paz-Centeno, I.; García-Ordás, M.T.; García-Olalla, Ó.; Alaiz-Moretón, H. Imputation of Missing Measurements in PV Production Data within Constrained Environments. Expert Syst. Appl. 2023, 217, 119510. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Yldz, A.Y.; Koc, E.; Koc, A. Multivariate Time Series Imputation With Transformers. IEEE Signal Process. Lett. 2022, 29, 2517–2521. [Google Scholar] [CrossRef]
- Bansal, P.; Deshpande, P.; Sarawagi, S. Missing Value Imputation on Multidimensional Time Series. Proc. VLDB Endow. 2021, 14, 2533–2545. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Koroteev, M.V. BERT: A Review of Applications in Natural Language Processing and Understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Dong, X.; Bao, J.; Zhang, T.; Chen, D.; Zhang, W.; Yuan, L.; Chen, D.; Wen, F.; Yu, N. Bootstrapped Masked Autoencoders for Vision BERT Pretraining. In Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 247–264. [Google Scholar]
- Wang, R.; Chen, D.; Wu, Z.; Chen, Y.; Dai, X.; Liu, M.; Jiang, Y.-G.; Zhou, L.; Yuan, L. BEVT: BERT Pretraining of Video Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14713–14723. [Google Scholar]
- Lee, H.; Lee, S.; Lee, I.; Nam, H. AMP-BERT: Prediction of Antimicrobial Peptide Function Based on a BERT Model. Protein Sci. 2023, 32, e4529. [Google Scholar] [CrossRef] [PubMed]
- Ghazikhani, H.; Butler, G. TooT-BERT-M: Discriminating Membrane Proteins from Non-Membrane Proteins Using a BERT Representation of Protein Primary Sequences. In Proceedings of the 2022 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Ottawa, ON, Canada, 15 August 2022; pp. 1–8. [Google Scholar]
- Wen, N.; Liu, G.; Zhang, J.; Zhang, R.; Fu, Y.; Han, X. A Fingerprints Based Molecular Property Prediction Method Using the BERT Model. J. Cheminform. 2022, 14, 71. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Xiong, Y.; Wang, S.; Wang, H. GeoBERT: Pre-Training Geospatial Representation Learning on Point-of-Interest. Appl. Sci. 2022, 12, 12942. [Google Scholar] [CrossRef]
- Benavides Cesar, L.; Manso Callejo, M.Á.; Cira, C.-I.; Alcarria, R. CyL-GHI: Global Horizontal Irradiance Dataset Containing 18 Years of Refined Data at 30-Min Granularity from 37 Stations Located in Castile and León (Spain). Data 2023, 8, 65. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cesar, L.B.; Manso-Callejo, M.-Á.; Cira, C.-I. BERT (Bidirectional Encoder Representations from Transformers) for Missing Data Imputation in Solar Irradiance Time Series. Eng. Proc. 2023, 39, 26. https://doi.org/10.3390/engproc2023039026
Cesar LB, Manso-Callejo M-Á, Cira C-I. BERT (Bidirectional Encoder Representations from Transformers) for Missing Data Imputation in Solar Irradiance Time Series. Engineering Proceedings. 2023; 39(1):26. https://doi.org/10.3390/engproc2023039026
Chicago/Turabian StyleCesar, Llinet Benavides, Miguel-Ángel Manso-Callejo, and Calimanut-Ionut Cira. 2023. "BERT (Bidirectional Encoder Representations from Transformers) for Missing Data Imputation in Solar Irradiance Time Series" Engineering Proceedings 39, no. 1: 26. https://doi.org/10.3390/engproc2023039026