1. Introduction
An elastic waveguide with a graded array of resonant bars was proposed for energy harvesting in [
1,
2], with possible applications in microsystems. This metamaterial structure features a spatial variation of mechanical properties allowing for manipulating propagating waves. Specifically, the grading enables both to enhance the wavefield amplitude in the resonator endowed with the harvester, typically realized through a piezoelectric material, and to enhance the interaction time between the waves and the resonators. Our aim is to improve energy harvesting capacities by tuning the lengths of the resonator bars. With a similar goal, refs. [
3,
4] compared different grading laws.
The optimization of a mechanical system can be automatized by relying: on gradient-based methods, genetic algorithms [
5], and particle swarm optimization [
6]. However [
7], the first family of approaches is negatively affected by the nonlinear dependence between the optimization object and the design parameters; the second suffers from a high computational cost; and the third requires constraining some parameters of the optimization algorithm without any clear indications for doing so.
As conducted in [
8], we propose to look at the optimization task as a Markov decision process (MDP), in which states describe specific configurations, and actions represent the modification to the current design. The solution of the MDP is based on the use of RL and, in particular, of the Proximal Policy Optimization (PPO) algorithm [
9]. Finite Element (FE) simulations are exploited to simulate wave propagation in order to provide information to the RL agent. In [
10], experimental data were used with the same goal.
Another aspect of interest is the description adopted for the possible system configurations. Indeed, the physical understanding of the problem has suggested setting the resonator lengths and possibly modifying the number of resonators through few interpolation points and B-spline interpolation, similarly to what was carried out by [
11] for structural shape optimization.
The proposed procedure will be demonstrated to able to lead to suboptimal configurations, enhancing the mechanical system performance with respect to previously proposed configurations. The interest of the approach stays in the possible applications to a large class of optimization problems involved in the design of sensors.
The remainder of the paper is arranged as follows. The proposed methodology is detailed in
Section 2, while the results relevant to the optimization of rainbow-based metamaterial for energy harvesting are reported in
Section 3. Final considerations are collected in
Section 4.
2. Methodology
The metamaterial optimization is organized in a sequence of
T actions
, with
, taken by an agent, producing a modification of the system state
. The performance of the obtained configuration is measured by the reward
, here defined as the average value in time of the elastic energy of the bar endowed with the harvester. This quantity is strictly related to the energy obtained by exploiting a piezoelectric material to convert mechanical into electrical energy. States and rewards define the environment in which the agent plays. Given that the probability to get into a state
depends only on
and on
, an MDP was used to formalize the sequential decision process. Considering a certain state
, the optimization problem coincides with the maximization of the expected return
, defined as
The agents’ actions are guided by a policy
, here treated as a stochastic entity associating a Probability Density Function (PDF) over the set of possible actions to a given state of the system. Stochasticity is required to allow the exploration of the state space. To understand if a policy
is preferable than a second policy
, value functions
are used, where
s is treated as a random variable whose possible realizations at time
t are indicated by
. Value functions are defined as
where
is the expected value of
starting from
and using
to guide the following actions. Other two quantities, namely the action–value function
and the advantage function
, are similarly defined as
The notion of is exploited by PPO, a policy gradient algorithm. This family of RL approaches explicitly looks for the best policy by exploiting a (large) number of agent–environment interactions. The outcome of the procedure is typically a suboptimal policy. However, approximating does not preclude to enhance the system performance with respect to already known configurations.
Before presenting PPO, we discuss the description adopted for the states. The possibility of representing the state through a vector collecting the resonator lengths was discarded because modifying one by one the resonator length produces reward alterations too limited to inform the RL agent. A more convenient option is to employ a limited number
of continuous variables by constraining the state and action spaces through the enforcement of smooth graded patterns of the resonator lengths. This strategy is motivated by the problem insight gained in previous works [
1,
2]. Specifically, the coordinates of a few points were employed as state variables, while the envelope of the resonator array was obtained by interpolating these points through cubic B-splines.
Figure 1 is reported to exemplify the adopted state representation. Actions coincide with modifying the coordinates of the light blue starts, as it is further specified in
Section 3.
Handling continuous state and action spaces forces to approximate
and
by parametric functions
whose tunable weights are collected in
and in
, respectively. A similar treatment was performed for the advantage function
.
By associating the PDF characterizing a Gaussian distribution to the policy, a tunable parametric function was exploited to establish a mapping between the state and the statistical moments of the PDF, namely the mean
and the standard deviation
. The weight tuning both the advantage function and the function having as output the policy moments is conducted through PPO. In particular, two fully connected Neural Networks (NN) featuring 32 neurons in each layer were employed for modeling
and the function with output
. Thanks to NN differentiability,
is updated to maximize the objective function of PPO
via Adam [
12], where:
;
and
are computed over
episodes; an episode is a complete sequence of agent–environment interaction
.
Specifically, indicating by
the ratio between
and
, the “min” and “clip” operations allow to define the following probability distribution
whose expected mean is the objective of PPO. The update of
is separately conducted every
episodes according to the actor–critic scheme of the PPO algorithm [
13]. Additional details on PPO can be found in [
9].
3. Results
To compute the reward related to a certain state, wave propagation is simulated through FEs for
s with a time step of
. The waveguide was discretized using 376 Euler Bernoulli beams, while a mass–spring schematization was employed for the resonating bars. The lengths of the FE were set to
m in between the resonators and to
m elsewhere. The mesh refinement was required to catch the effects of the resonator interactions. Two absorbing layers, one at the beginning of the waveguide and the other at the end, were placed to avoid reflections, as suggested in [
14]. The employed material is aluminum with density
and Young’s modulus
. Concerning the cross-sectional area and moment of inertia, the ones of the waveguide are
and
, while the relevant moment of inertia
of the resonating bars is equal to
. An initial number of 25 resonators with spacing close to
was considered, where
m is the length of the flexural wave traveling on the elastic beam without resonators.
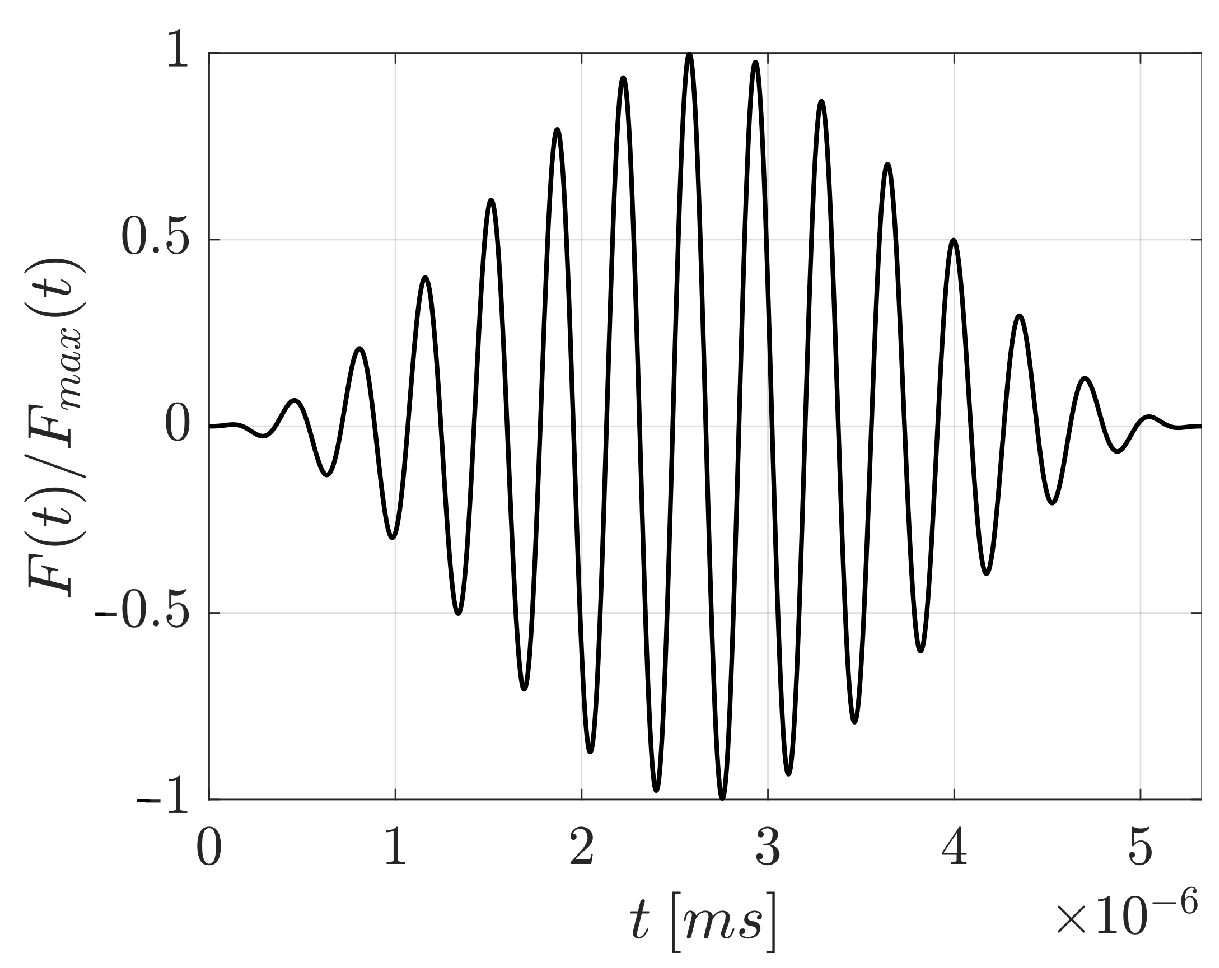
The excitation generating the propagating wave is reported in
Figure 2. It mimics the one experimentally adopted by [
2]. The frequency content of the excitation matches the first bending frequency
MHz of the resonator endowed with the harvester. The four points depicted as light blue markers in
Figure 1 were employed to define the arrangement of the resonating bars. Specifically, the number
of continuous variables was set to 4. They coincide with the
z coordinates of the first and fourth points and with the
coordinates of the second point. The third point, placed at the tip of the bar equipped with the harvester, is fixed. The order of the agent action was set, too; see
Table 1.
Except for the way in which the state space was constrained, no other physical knowledge of the system was exploited. As starting state, the
z coordinates of all the points were set equal to the length of the harvester bar
. The range of variation of the coordinate points is also reported in
Table 1. The value
allows to have a
attenuation of the forced response of a bar with length
and moment of inertia
excited by an oscillating force with frequency equal to
. If bars with lengths smaller than
result by the interpolation, they are removed from the system, in this way enabling to modify the number of resonators.
The outcomes of the optimization process are evaluated in terms of the reward
of the last episode configuration. This value was divided by the reward
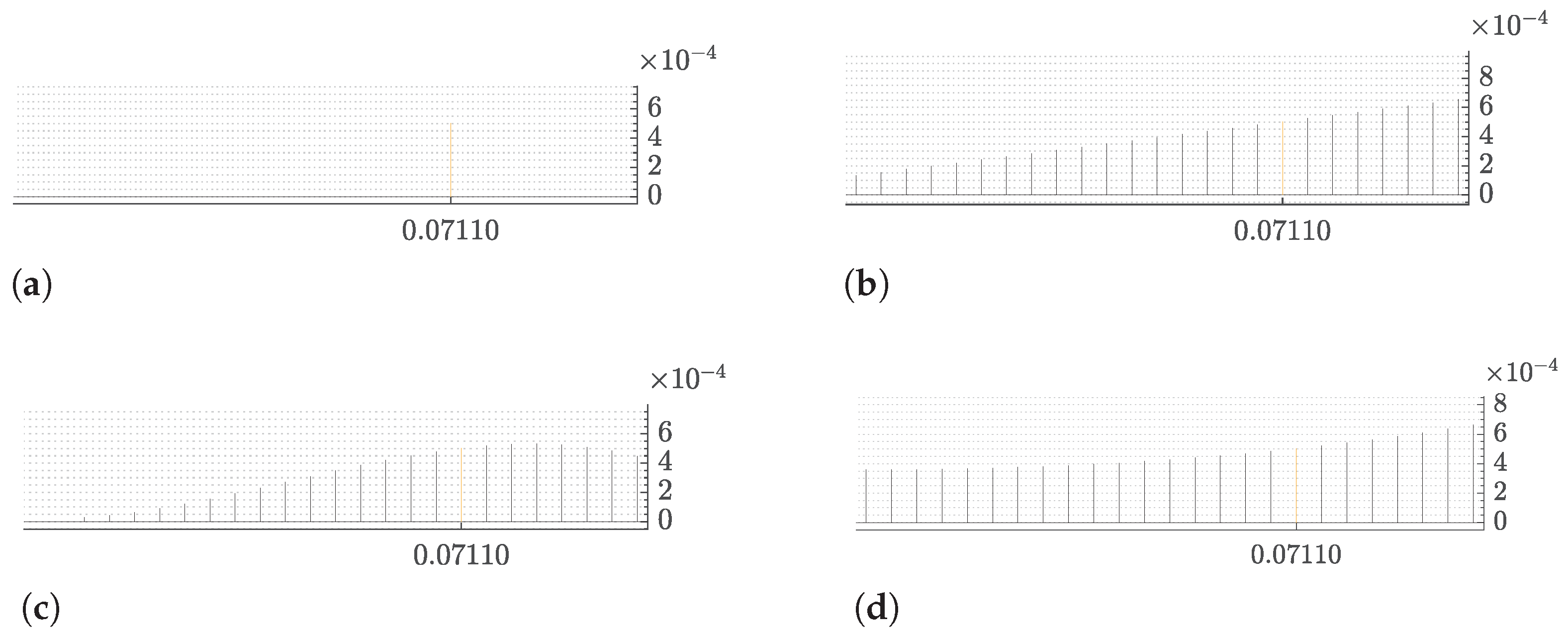
featuring the waveguide with just one resonator. The interest is to judge the performance improvement with respect to the configuration featuring a linear grading reported in
Figure 3b, originally proposed by [
1] on the basis of physical considerations.
Two resonator arrangements were found out by the RL agent. The best discovered configuration depicted in
Figure 3c was generated after roughly 5000 agent–environment interactions, much before the total number
of interactions, here set to
100,000, ran out. Instead, the converged RL policy configuration shown in
Figure 3d was produced by the quasi-deterministic policy obtained at the end of the agent training. This policy is a suboptimal solution of the MDP. They both outperform the linear grading rule by ≈4.7% and by ≈1.0%, respectively.
The suboptimality of the converged RL policy and the better performance of the other discovered configuration should not appear to undermine the value of the method. Indeed, the obtained configurations are close in terms of
; they confirm the physical intuition of the problem. Discovering the reported best configuration is allowed by the first policy updates; the closest approximation of the optimal policy could have been obtained, but only at the cost of a huge increase in the computational time [
13]. On the contrary, the small number of agent–environment interactions needed to discover the configuration in
Figure 3c promises a successful application of this RL- and MDP-based optimization approach to other sensor design problems, possibly involving more complex and time demanding simulations, even in the realm of multiphysics.
Moreover, it is worth to remember that these configurations were obtained without exploiting the physical understanding of the problem, such as the notion that an initial linear ascending grading both enhances the interaction time between the waves and the resonators and increases the wavefield amplitude in the resonator endowed with the harvester. On the contrary, a greater insight into the surface wave propagation in rainbow-based structures should be obtained by explaining the reason behind the improved performances of the discovered configurations. For example, the concave curvature reported at the beginning of the grading deserves deeper comprehension. Moreover, it is shown that the best performance was obtained when the number of resonators was reduced to 23. These and other aspects are currently under investigation.






{kind=link}
{kind=link}
{kind=link}