
Mastering the Complexity of Incremental Forming: Geometry-Based Accuracy Prediction Using Machine Learning †


Abstract
:1. Introduction
2. Predicting Workpiece Accuracy
2.1. Describing Freeform Geometry
2.2. Gradient Tree Boosting Regression
2.3. Reconstructing a Spif Output Geometry
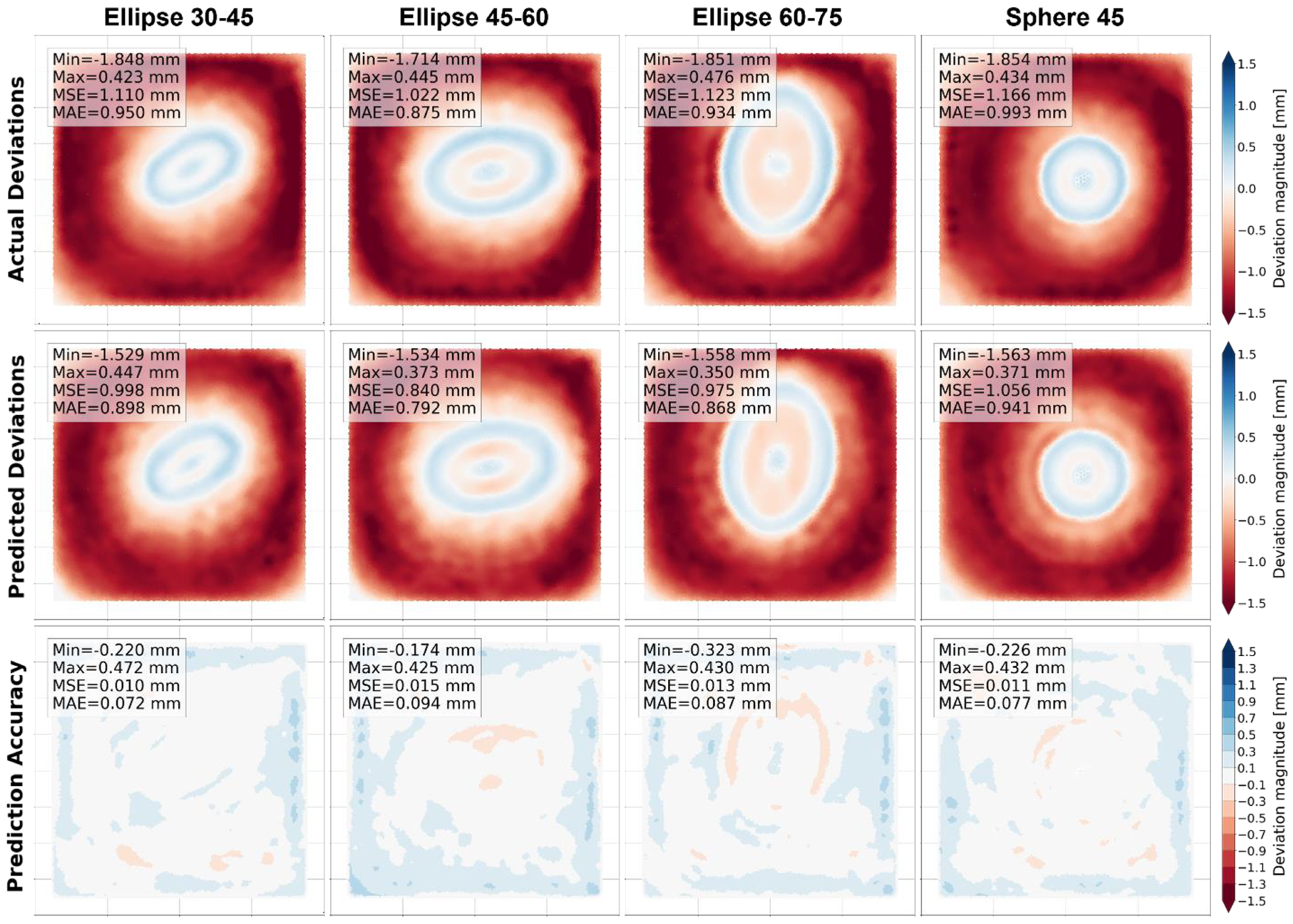
3. Accuracy Prediction Validation for Ellipsoid Geometries
3.1. Geometries and Materials
3.1.1. Training Data
3.1.2. Materials, Production, and Methods
3.2. Training Results
3.3. Testing Results
4. Discussion
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duflou, J.R.; Habraken, A.; Cao, J.; Malhotra, R.; Bambach, M.; Adams, D.; Vanhove, H.; Mohammadi, A.; Jeswiet, J. Single point incremental forming: State-of-the-art and prospects. Int. J. Mater. Form. 2018, 11, 743–773. [Google Scholar] [CrossRef]
- Hirt, G.; Ames, J.; Bambach Kopp, R. Forming strategies and process modelling for CNC incremental sheet forming. CIRP Ann. 2004, 53, 203–206. [Google Scholar] [CrossRef]
- Carette, Y.; Vanhulst, M.; Duflou, J.R. Geometry Compensation Methods for Increasing the Accuracy of the SPIF Process. Key Eng. Mater. 2021, 883, 217–224. [Google Scholar] [CrossRef]
- Verbert, J.; Behera, A.K.; Lauwers, B.; Duflou, J.R. Multivariate adaptive regression splines as a tool to improve the accuracy of parts produced by FSPIF. Key Eng. Mater. 2011, 473, 841–846. [Google Scholar] [CrossRef]
- Behera, A.K.; Verbert, J.; Lauwers, B.; Duflou, J.R. Tool path compensation strategies for single point incremental sheet forming using multivariate adaptive regression splines. Comput. Aided Des. 2013, 45, 575–590. [Google Scholar] [CrossRef]
- Max, N. Weights for computing vertex normals from facet normals. J. Graph. Tools 1999, 4, 1–6. [Google Scholar] [CrossRef]
- Theisel, H.; Rossl, C.; Zayer, R.; Seidel, H.-P. Normal Based Estimation of the Curvature Tensor for Triangular Meshes. In Proceedings of the 12th Pacific Conference on Computer Graphics and Applications, Seoul, Korea, 6–8 October 2004; pp. 288–297. [Google Scholar]
- Friedman, J. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Parameter | Calculation Details |
|---|---|---|
| Curvature | Parallel Curvature | Locally parallel to backing plate plane |
| Normal Curvature | Locally normal to backing plate plane | |
| Position | XY-Backing distance | Closest XY-distance to backing plate |
| XY-Top distance | Closest XY-distance to deepest point | |
| Z height relative | (0, 1), within workpiece | |
| Z height absolute | Height in mm, for comparison between different workpieces | |
| Roll direction factor | Angle between local toolpath direction and sheet rolling direction | |
| Process limits | Wall angle | Local angle defined by vertex normals |
| Wall thickness factor | Residual thickness fraction using sine rule | |
| Geometric features | Planar factor | Small principal curvatures |
| Saddle factor | Large negative first principal curvature and large positive second principal curvature | |
| Parabolic Convex factor | Large positive first principal curvature and small second principal curvature | |
| Convex factor | Large positive principal curvatures | |
| Parabolic Concave factor | Large negative first principal curvature and small second principal curvature | |
| Concave factor | Large negative principal curvatures |
| Geometric Feature Score | Curvature Condition | Score Calculation | |||||
|---|---|---|---|---|---|---|---|
| Planar factor | - | flatness(κ1) × flatness(κ2) | |||||
| Saddle factor | κ1 × κ2 ≤ 0 | curvedness(κ1) × curvedness(κ2) | |||||
| Parabolic Convex factor | κ1 ≥ 0 | curvedness(κ1) × flatness(κ2) | |||||
| Convex factor | κ1, κ2 ≥ 0 | curvedness(κ1) × curvedness(κ2) | |||||
| Parabolic Concave factor | κ2≤ 0 | flatness(κ1) × curvedness(κ2) | |||||
| Concave factor | κ1, κ2≤ 0 | curvedness(κ1) × curvedness(κ2) | |||||
| Examples | (L = 0.01, H = 0.02) | ||||||
| κ1 | κ2 | Plan. | Sad. | Par. Conv. | Conv. | Par. Conc. | Conc. |
| 0 | - | 0 | 6.250 | - | - | ||
| 0.050 | 0.020 | (0%) | (0%) | (0%) | (100%) | (0%) | (0%) |
| 0 | - | 0.500 | 0.063 | - | - | ||
| 0.020 | 0.005 | (0%) | (0%) | (89%) | (11%) | (0%) | (0%) |
| 0 | 0.015 | 5.625 | - | 0 | - | ||
| 0.020 | −0.001 | (0%) | (<1%) | (>99%) | (0%) | (0%) | (0%) |
| 0.400 | <0.001 | 0.050 | - | 0.005 | - | ||
| 0.005 | −0.002 | (>87%) | (<1%) | (11%) | (0%) | (1%) | (0%) |
| 0.400 | - | - | - | 0.050 | <0.001 | ||
| −0.002 | −0.005 | (>88%) | (0%) | (0%) | (0%) | (11%) | (<1%) |
| 0 | - | - | - | 0.500 | 0.063 | ||
| −0.005 | −0.020 | (0%) | (0%) | (0%) | (0%) | (89%) | (11%) |
| 0 | - | - | - | 0 | 6.25 | ||
| −0.020 | −0.050 | (0%) | (0%) | (0%) | (0%) | (0%) | (100%) |
| d [mm] | D [mm] | h [mm] | x [mm] | y [mm] | α [°] | |
|---|---|---|---|---|---|---|
| Min | 30 | 30 | 30 | 0 | 0 | 0 |
| Max | 75 | 75 | 40 | 15 | 15 | 45 |
| Training geometries | ||||||
| Sphere 30 1 | 30 | 30 | 30 | 15 | 15 | 45 |
| Ellipse 30-75 1 | 75 | 30 | 30 | 0 | 0 | 45 |
| Ellipse 30-75 2 | 30 | 75 | 30 | 0 | 15 | 0 |
| Sphere 75 1 | 75 | 75 | 30 | 15 | 0 | 0 |
| Sphere 30 2 | 30 | 30 | 40 | 15 | 0 | 0 |
| Ellipse 30-75 3 | 75 | 30 | 40 | 0 | 15 | 0 |
| Ellipse 30-75 4 | 30 | 75 | 40 | 0 | 0 | 45 |
| Sphere 75 2 | 75 | 75 | 40 | 15 | 15 | 45 |
| Test geometries | ||||||
| Ellipse 30-45 | 30 | 45 | 35 | 8 | 8 | 30 |
| Ellipse 45-60 | 45 | 60 | 38 | 10 | 5 | 10 |
| Ellipse 60-75 | 60 | 75 | 34 | 5 | 10 | 35 |
| Sphere 45 | 45 | 45 | 32 | 12 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carette, Y.; Duflou, J.R. Mastering the Complexity of Incremental Forming: Geometry-Based Accuracy Prediction Using Machine Learning. Eng. Proc. 2022, 26, 12. https://doi.org/10.3390/engproc2022026012
Carette Y, Duflou JR. Mastering the Complexity of Incremental Forming: Geometry-Based Accuracy Prediction Using Machine Learning. Engineering Proceedings. 2022; 26(1):12. https://doi.org/10.3390/engproc2022026012
Chicago/Turabian StyleCarette, Yannick, and Joost R. Duflou. 2022. "Mastering the Complexity of Incremental Forming: Geometry-Based Accuracy Prediction Using Machine Learning" Engineering Proceedings 26, no. 1: 12. https://doi.org/10.3390/engproc2022026012