3.1. Crime Forecasting
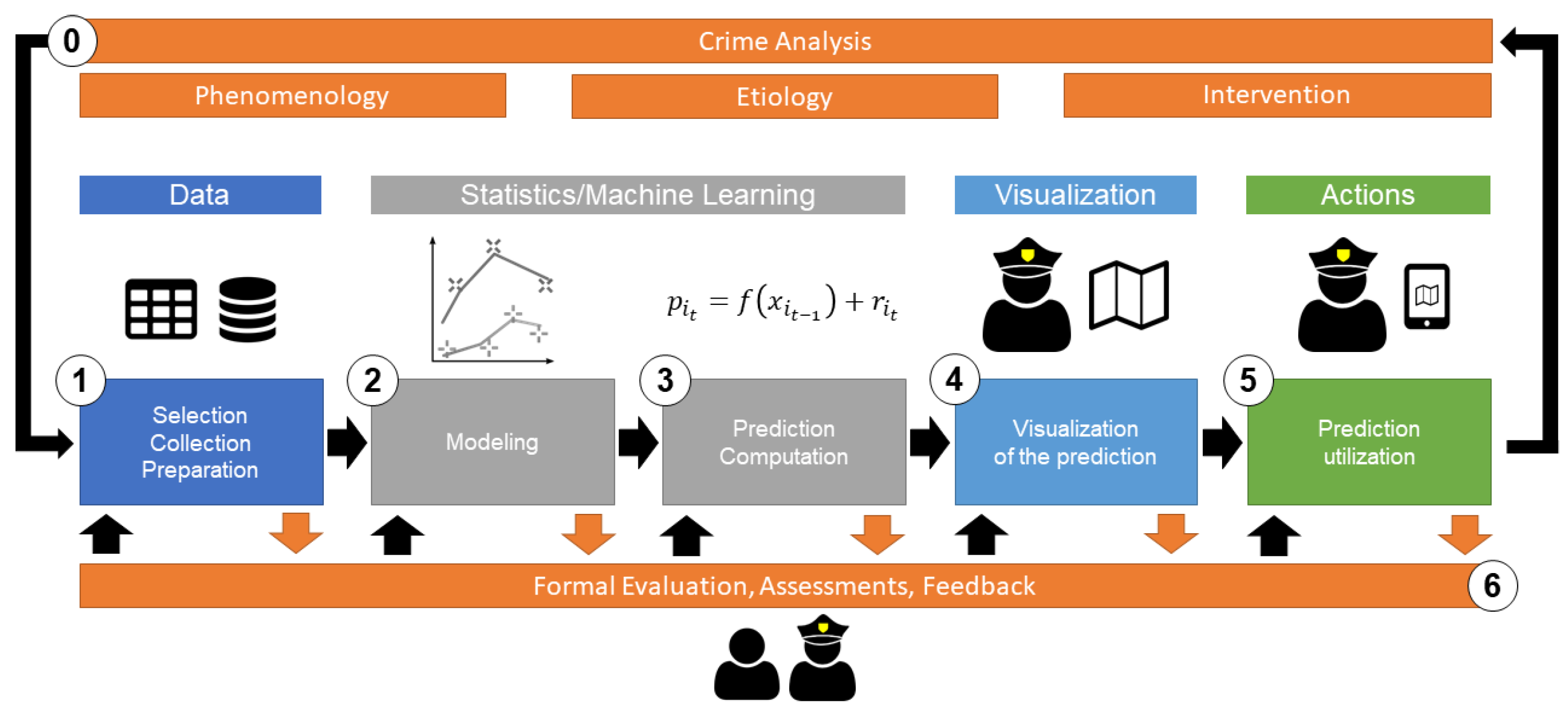
The classical crime forecasting approach in the SKALA project focuses on using predictive policing as a method to compute spatial crime risks. In practice, predictive policing involves several steps and processes that build on each other, starting with analyzing the specific offense and the collection and processing of data required for crime prediction. The illustrated methodical process (
Figure 1) allows an insight into the individual steps for implementing predictive policing from the police department’s point of view, as it also took place in SKALA. Deviations are conceivable, but at least similar designs are likely to be present whenever machine learning technologies are used.).
All process steps depend on the available data, the data acquisition, and the preparation of the data for further processing. For predictive policing, data quality is therefore of crucial importance. In this context, data acquisition problems are conceivable, for example, when recording a residential burglary’s suspected and not precisely determinable time. Moreover, data uncertainties can arise on the side of the police forces if crimes are legally misjudged or reported late by the victims, which cannot be ruled out for the crime of residential burglary, for example. In addition, the fundamental problem is that crime phenomena cannot usually be fully described with the available data, especially when unobservable or unquantifiable effects are important. Thus, when making crime forecasts, the question must be asked whether the anticipated crime event occurred independently of the criminological and mathematical models used.
A deliberate decision was made to avoid an exclusively data-driven approach in order to produce crime forecasts, and a theory-driven approach was adopted. Specifically, due to the increasing digital availability of data and the further development in the field of big data processing, data mining approaches—for the prediction of feature characteristics or data points—are also increasingly represented in the methodological discussion on predictive policing [
11] (p. 8). Data mining covers (partially) automated methods for analyzing data sets, which can find statistical correlations and provable patterns [
12]. Data mining approaches go beyond assumption-driven multivariate data analysis. They can also find non-linear or only partially existing correlations that might have remained undetected during the theoretical derivation of hypotheses from tentatively proven theories. An exclusively data-driven approach must be viewed critically, especially in the context of predictive policing, since plausible assumptions about possible causal relationships already exist for the vast majority of criminal phenomena, which cannot simply be ignored. Likewise, methods of data-driven approaches are subject to the assumption that the input data describe the phenomenon to be analyzed to the degree that automatic pattern and group identification do not occur based on spurious correlations. Especially with regard to data protection, principles such as data economy, and the difficulty of analyzing highly complex phenomena such as crime, it becomes clear that purely data-driven methods should not be used alone in the area of predictive policing. This is based on the fact that crime cannot always be clearly objectified and thus represented within a data set [
13].
The theory-driven approach ensured that the used model was based on robust scientific theories and research findings. This distinguished the approach from many other predictive policing methods, which are often based only on the near-repeat approach, which refers to the empirically-proven observation that crime recurs in the same or adjacent locations within a given period [
14] (p. 414) [
15] (pp. 368 ff.). In practice, the probabilities of residential burglaries, burglaries from commercial properties, and motor vehicle offenses were calculated based on spatial data for residential quarters in selected police districts of NRW.
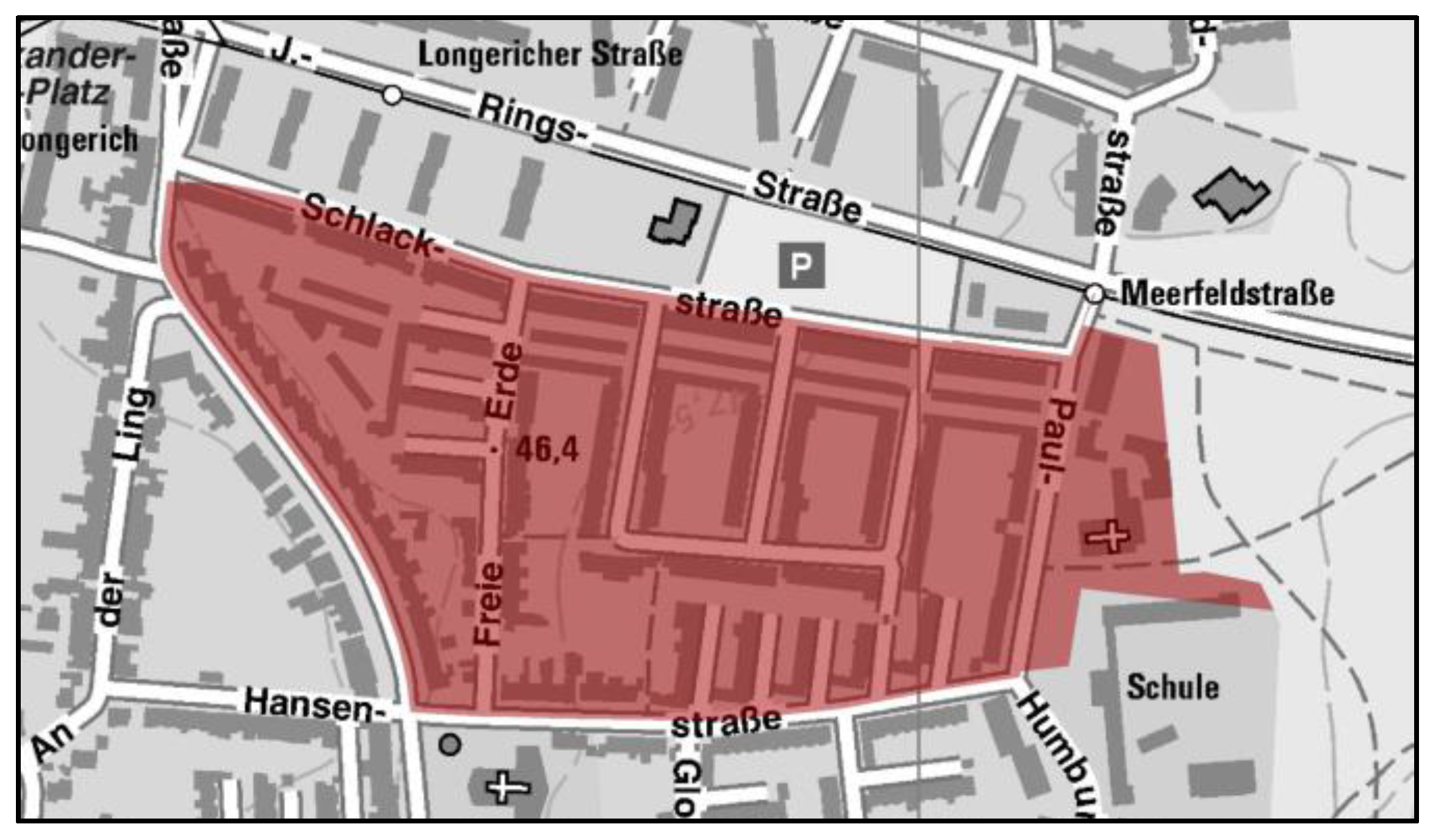
A three-stage procedure was chosen for this purpose. First, spatio-temporal clusters of crime data were calculated based on the near-repeat approach, which refers to a period of 14 days and a radius of 500 m for the residential burglary. The collected crime data mainly included the time and location of the offense, the modus operandi, and the proceeds of the crimes (property stolen). The calculated spatio-temporal clusters were transferred to the residential district level. The residential districts were areas characterized by a number of 400 households per quarter (see
Figure 2). For NRW, this resulted in 18,875 residential districts. A uniform size at the household level was chosen because grid cells can lead to over- or underestimation of offenses.
Second, random forest models got a subset of influencing variables out of the socio-economic data. These data were chosen because of their statistical impact on the occurrence of crime. They included information on the residential location, such as population structure, building construction, income, infrastructure connections, and mobility indicators. In this step, random forest models were used to avoid overfitting [
16,
17]. The advantage of this application is the relatively easy operability and the possibility to perform initial data analysis tasks in a short time, including model and forecast generation. The decision tree models had a comparatively good performance. In addition, they are transparent and comprehensible, so they were favored within this framework. Third, the modeling and forecasting were performed based on the previous results and selected data within a linear regression model.
The areas for which the highest crime probabilities were calculated compared with other areas of the entire forecast area are defined as forecast areas. Their share was limited to about 1.5 percent of the total number of quarters in each police district for practical reasons, such as planning policy measures and allocating and distributing limited police resources.
The calculation of crime probabilities was based on the total area of every single police authority. This procedure ensured that the individual risk of residential burglary for each residential quarter could be determined in the forecast week, as many other predictive policing methods only refer to sub-areas of cities or regions.
The methodological implementation of the model and forecast generation described above focuses primarily on long-term statistical considerations. In the course of SKALA, the pilot authorities repeatedly criticized that future crime series, such as a particular modus operandi, was not reflected in the forecasts. Analyses based on the available series of crimes from the police authorities showed that differentiation from other series or individual crimes was not possible based on the available data material. However, the homogeneity of the characteristics within the respective series was always high. Nevertheless, as a supplement to the statistical and decision tree-based approach of the model and prognosis generation, a second forecast model was developed, which focused on possible series of crimes. This so-called analytical model was independent of the more comprehensive statistical model and supplemented it, depending on the data situation.
3.2. Risk Terrain Modelling
The Risk Terrain Modelling (RTM) approach is a method used to compute the future risk of crime in specific places. Unlike other methods such as hotspot mapping, the calculations with RTM are not, or rather not only, based on crime data but also include geographical characteristics of places [
6] (p. 50). RTM is a classification approach that characterizes an area’s risk for crime based on its environmental characteristics [
6] (p. 51). Therefore, new hotspots are predicted based on their similarities to other ‘known’ hotspots. The result might be a map of places that did not see any crime but should be considered risky places because of their similar spatial risks compared to crime hotspots. The spatial risk profiles generated are derived from the respective geographic characteristics of the space, which can be identified as risk factors for crime. Studies suggest that the prediction accuracy of the RTM models is better than that of classic hotspot models [
18]. However, the correlations found in such models do not necessarily imply a meaningful and substantively justifiable causality. They are usually the results of the “unsupervised learning” method, intended to identify previously unknown correlations or patterns without categorizing the data [
19].
In SKALA, the RTM instrument should primarily be made available to police forces with a deficient number of cases in relation to their area (rural regions), as this makes it difficult to use the previously described crime forecasting model, which particularly results from the fact that the models are primarily based on patterns of crime events that are close in time and space. Therefore, alternative model approaches were sought that are more strongly based on the influence and distribution of socio-economic, building-specific, and infrastructural attributes and their distribution in space.
In the classical RTM, risk factors are determined from a large number of space-specific attributes using statistical methods, which significantly influence the risk burden (number of events per unit of space and time) for a selected offense. The mathematical model underlying the relationship between the significant characteristics and the risk burden enables a forecast calculation of the expected risk of crime. Following this, a risk map can be generated for the entire space of a selected authority. The temporal validity of such a map is strictly linked to changes in the area-specific characteristics and the number of cases, which in rural regions are subject to relatively minor changes on short time scales.
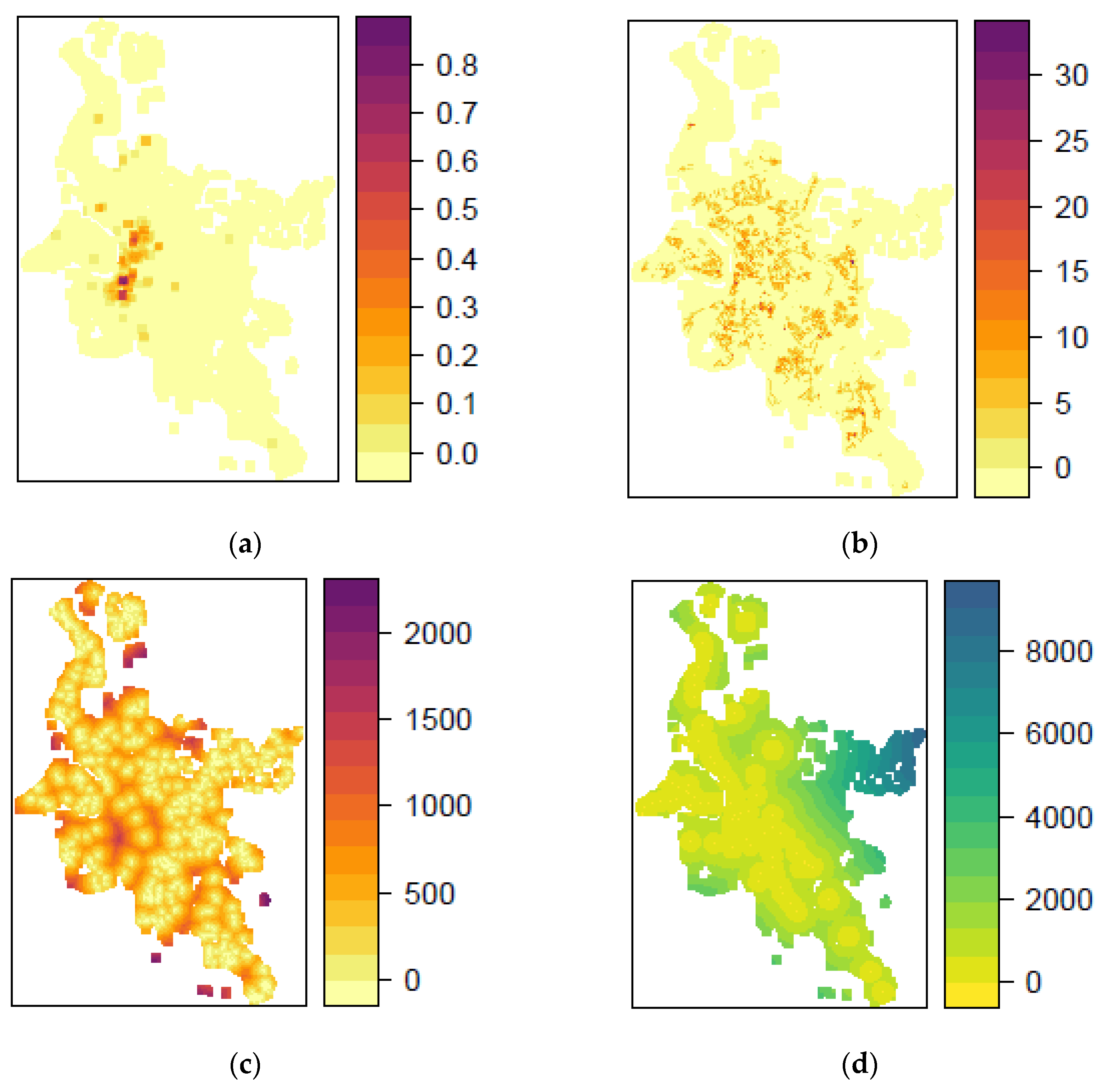
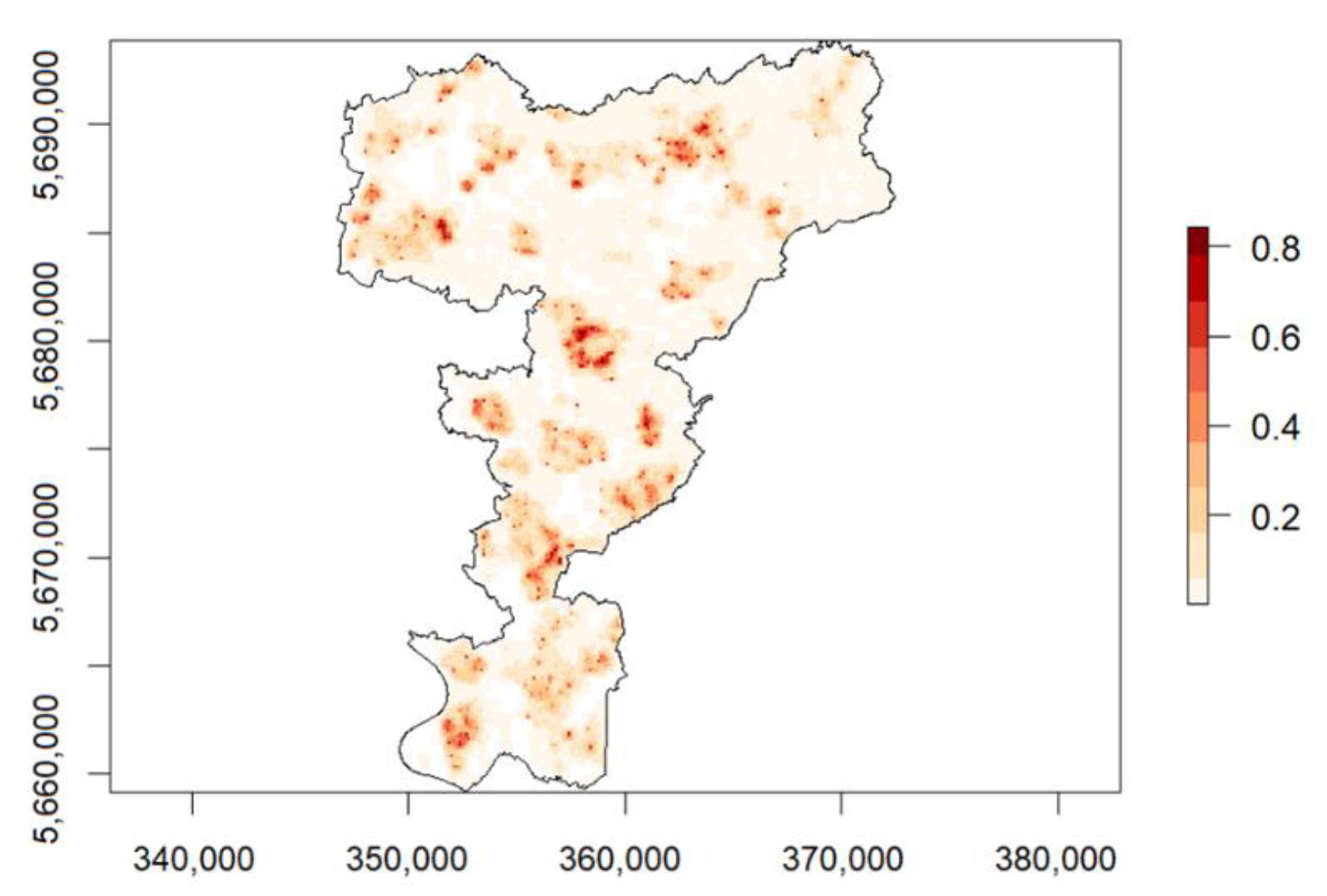
The existing socio-economic and other freely available data, such as point data of bus stops, banks, and supermarkets, were processed, calculated, and aggregated for a uniform grid of 100 × 100 m to test the RTM approach.
Figure 3 shows example density maps of different variables for the same city. In the classic RTM approach, the individual input variables are processed in binary form for each raster cell. This means that for each variable and raster cell, it is determined whether the variable is present in the raster cell or not. In the course of development, it quickly became apparent that this approach was insufficient to provide satisfactory results. Therefore, a modified approach was used to convert the existing variables to density-based units, allowing better differentiation of the individual variables’ spatial distribution. Another deviation from the classical RTM is the inclusion of variables calculated from the characteristics of the historical processes, such as the average distance of residential burglary to the three nearest residential burglaries (relative to the center of each grid cell).
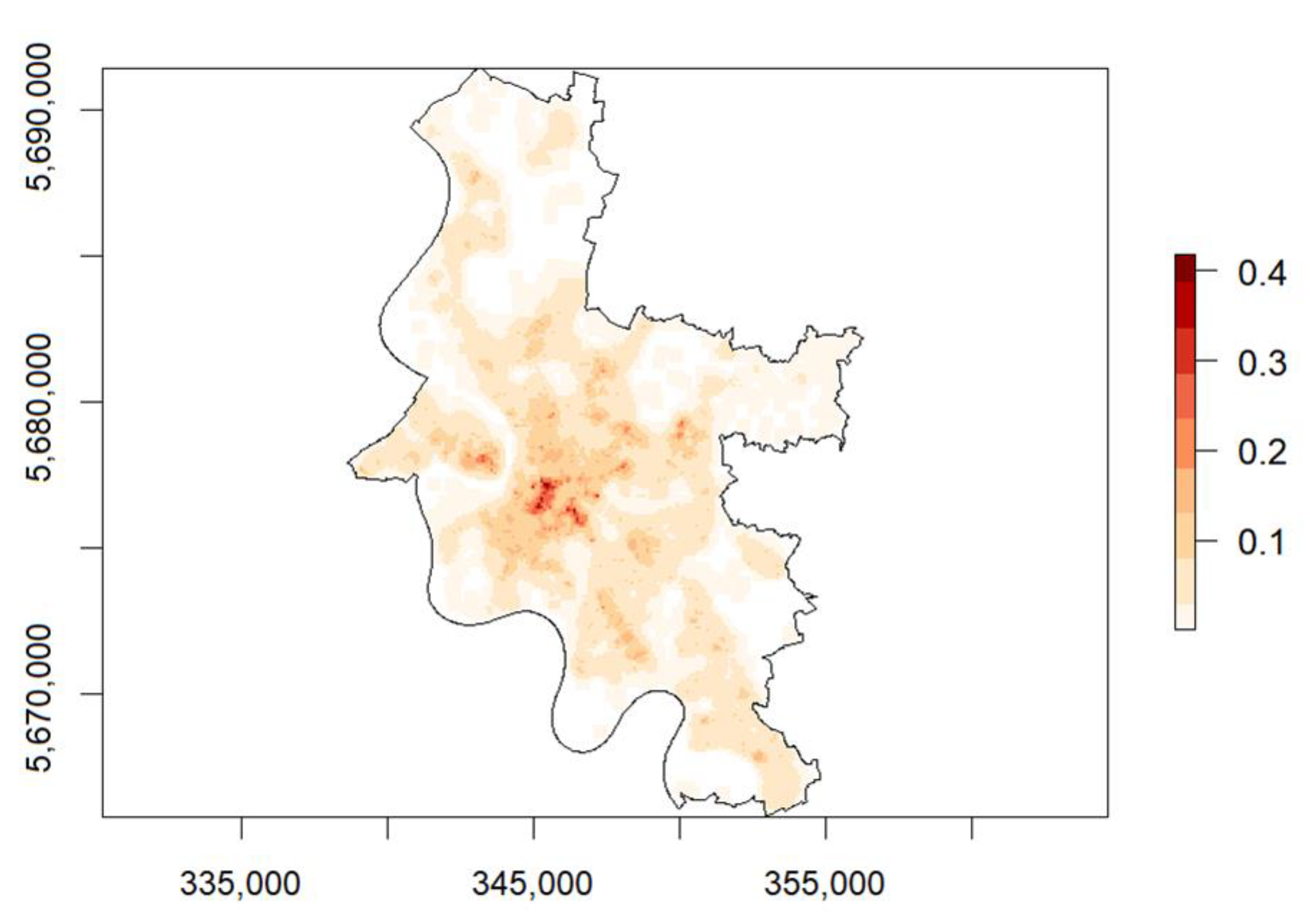
The result for a risk map depends significantly on the assumed relationship between the target variable and the input variables. The different model algorithms realize the mathematical formulation of this problem. The classical RTM formulation is based on Poisson regression.
Figure 4 shows an example of a risk map based on Poisson regression. Alternatively, the risk determination can be conceived as a classification problem using common methods such as RF (random forest) or SVM (support vector machine). The main difference between the two formulations in a risk map is the interpretation of the risk load. While a Poisson regression gives a non-scalable risk number for a grid cell that is only valid for the respective authority (for example, a grid cell with a risk number of 5.7 in one city would have a different meaning than a grid cell with the same risk number in another city), the classification gives a probability for the occurrence of an event for each grid cell similar to the previous forecast model used in SKALA (see
Figure 5).
As quality criteria for the comparison of the different models, the quality measure of deviance was chosen for the Poisson regression. Deviance indicates how well the significant variables and model parameters determined in the model can describe or reproduce the original statistical distribution of the target variable. For the RF and SVM classification models, the quality measures AUC and PrecRec were chosen. For the AUC value, the closer the AUC value is to 1, the better the model prediction. An AUC value of 0.5 would mean that the model does not predict better than chance. A maximum AUC value of 1 means that all areas were predicted exactly correctly. PrecRec stands for the sum of the quality measures Precision and Recall.
3.3. Time Series Analysis
Time series analysis offers the possibility to detect patterns in the temporal change of crime data, which play a major role, especially in crime prediction and prevention. Methods such as time series decomposition and autoregressive integrated moving average (ARIMA) modeling can be used for this purpose. A decomposed crime time series consists of the original time series and the three decomposed parts with the estimated trend component, seasonal component, and remainder component. The calculation of trends and seasonality are used for the long-term prediction of crime events to facilitate strategic planning in police agencies [
20,
21]. Several studies, e.g., Malik et al. [
22] and Borges et al. [
23], use STL as an initial time series analysis for later modeling a predictive policing approach. Furthermore, this approach allows statements about recurring and changing temporal components of crime without considering socioeconomic or demographical information.
ARIMA modeling is a powerful tool for time series analysis and short-term forecasting. Since ARIMA was successfully applied for predictions in economics, marketing, industry production, and social problems, it was also applied for forecasting property crime [
20]. In this study, the ARIMA model was used to predict one week in advance from the observations on property crime, but only for the whole city and not for districts. ARIMA has the potential to enable crime prediction by only using offense data, as well as analyzing temporal crime patterns on different spatial scales by spatial data aggregation [
24]. In crime research and strategic planning in police work, information on possible future events in crime data enables short- and long-term orientation and the recognition of changes and recurring patterns.
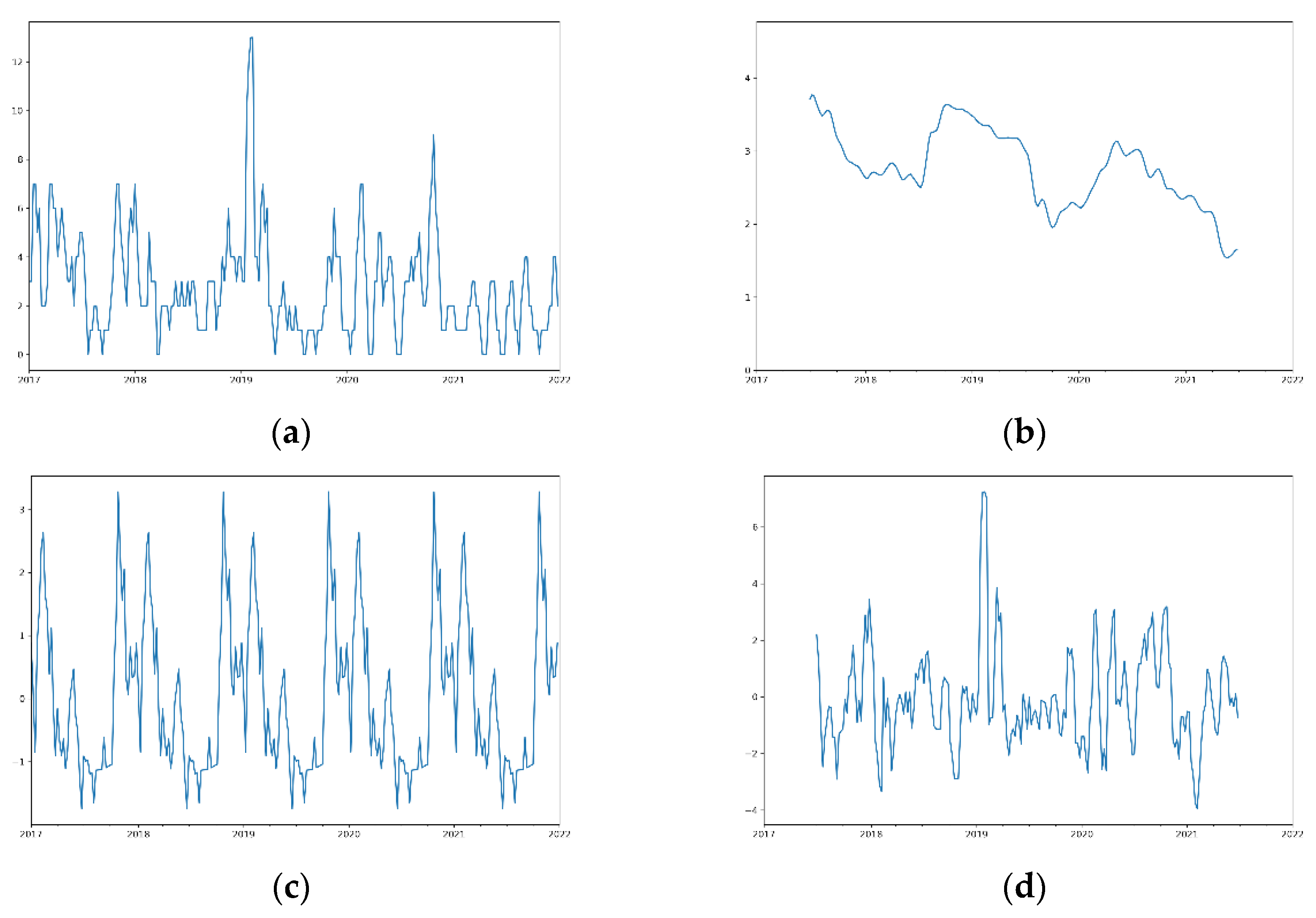
For time series analysis, a raw time-series signal was constructed out of the criminal records for each analyzed offense, e.g., residential burglary, over a period of five years from 1 January 2017 to 31 December 2021. The number of cases per offense per time unit was aggregated for a sub-region. Thus, only the time and location information of the offense were used. Weekly aggregated offense data on residential district and city level were considered for the time series analysis. Analyses based on daily data were considered problematic due to the small offense numbers.
In the first step, a time series decomposition was performed on daily aggregated offense data. The Seasonal Time Series Decomposition based on Loess (STL) is a filtering method for separating three components from a seasonal time series, namely trend (T), season (S), and the remainder (R) [
25]. The first component, the trend at the time, indicates the series’ long-term increase or decrease. The second component, the seasonality, indicates whether the time series is modified by seasonal influences, referring to one cycle per year in this case. The third component, the remainder, represents any residual noise in the data. Since STL is an additive model, the time series (Y) at the time (t) can be described as follows [
23]:
The output of this process is the separation of the original time series of criminal record entries into two distinct derivatives: the trend and the season.
Daily aggregated offense data on residential districts were used for time series decomposition.
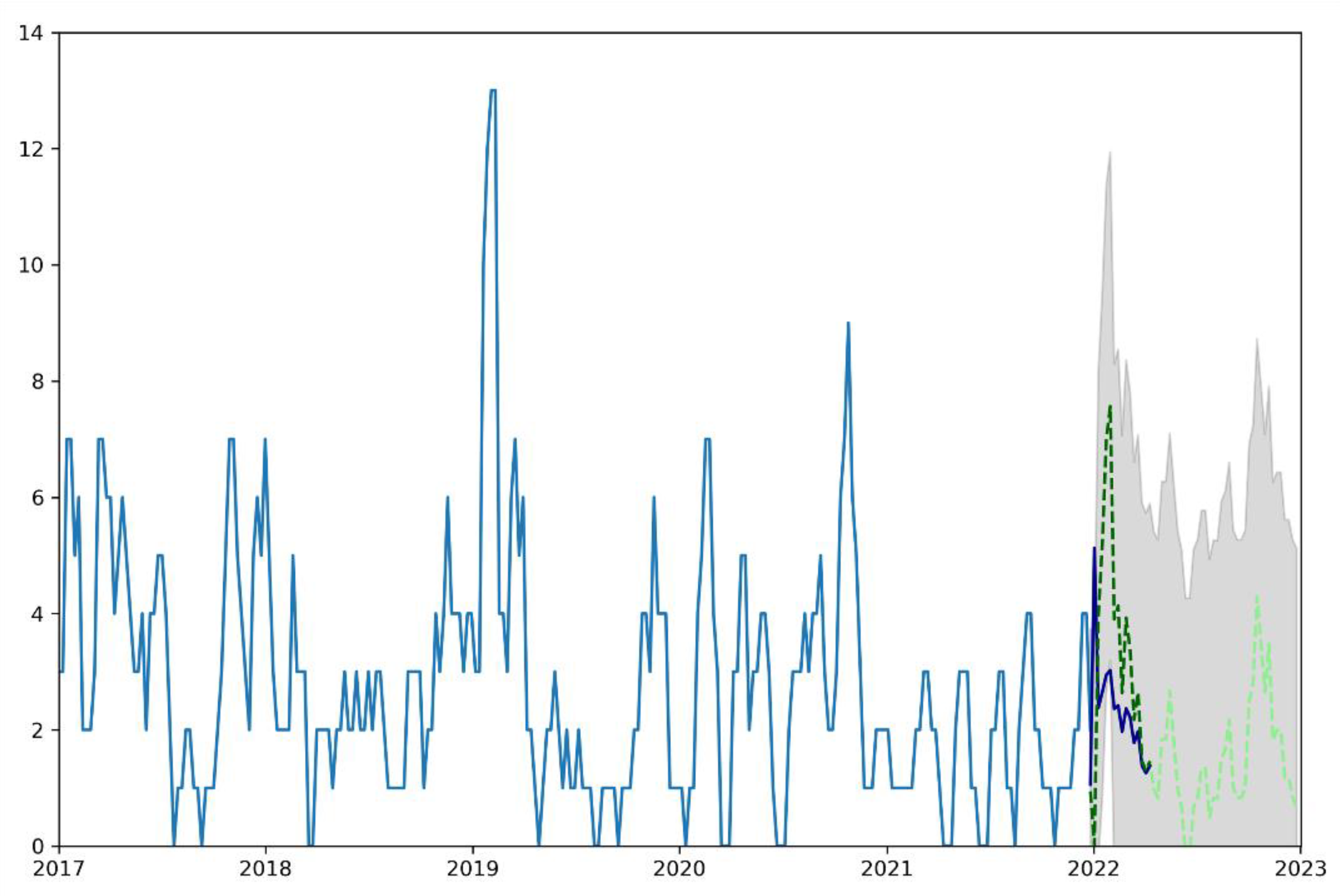
Time series analysis can also be utilized in the process of prediction. In a second step, the autoregressive integrated moving average (ARIMA) model introduced by Box and Jenkins [
26] was used to forecast the number of crime events for periods of one week and one month. This model can provide accurate forecasts over relatively short periods [
20].
The autoregressive (AR) models attribute current observations only to past observations. In moving average (MA) processes, however, observations are attributed not only to the observations but also to the non-observed error of the past periods, which also influences future observations. Thus, ARIMA models take advantage not only of the observed past observations but also of information that is not described directly in the time series but is defined as the error of the prediction. ARIMA models combine AR models and MA processes as follows:
Here,
yd is the
d-fold differentiated observations that can follow an AR process with
p orders and an MA process with
q orders. Therefore, the task is to specify the parameters
d, i.e., the order of the necessary integration or differentiation, as well as
p and
q in the ARIMA (
p,
d, and
q) model [
20,
27].
The ARIMA model was applied for weekly aggregated offense data at the residential district and city levels.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






