
Deep Learning for Raman Spectroscopy: A Review



Abstract
:1. Introduction
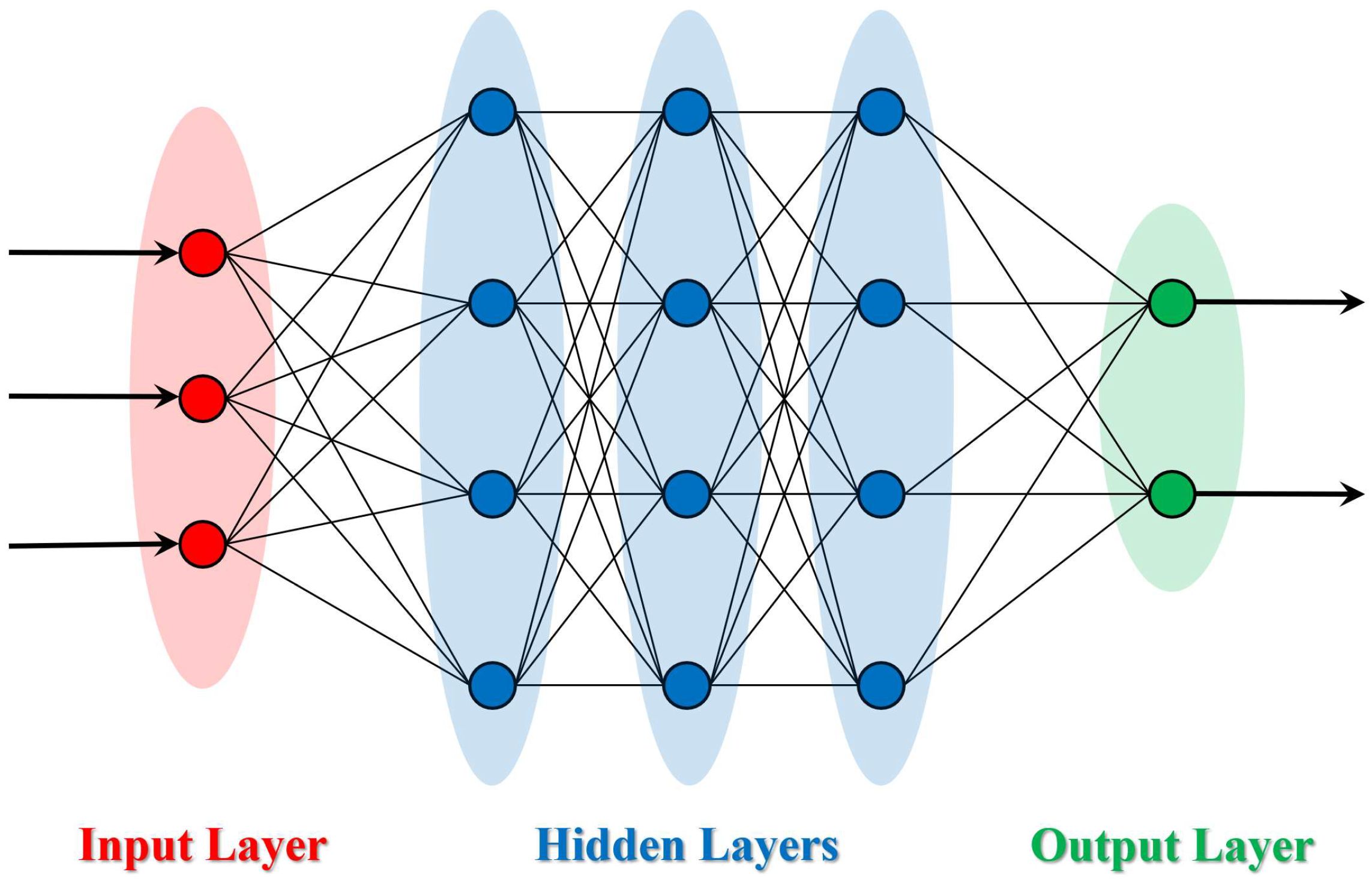
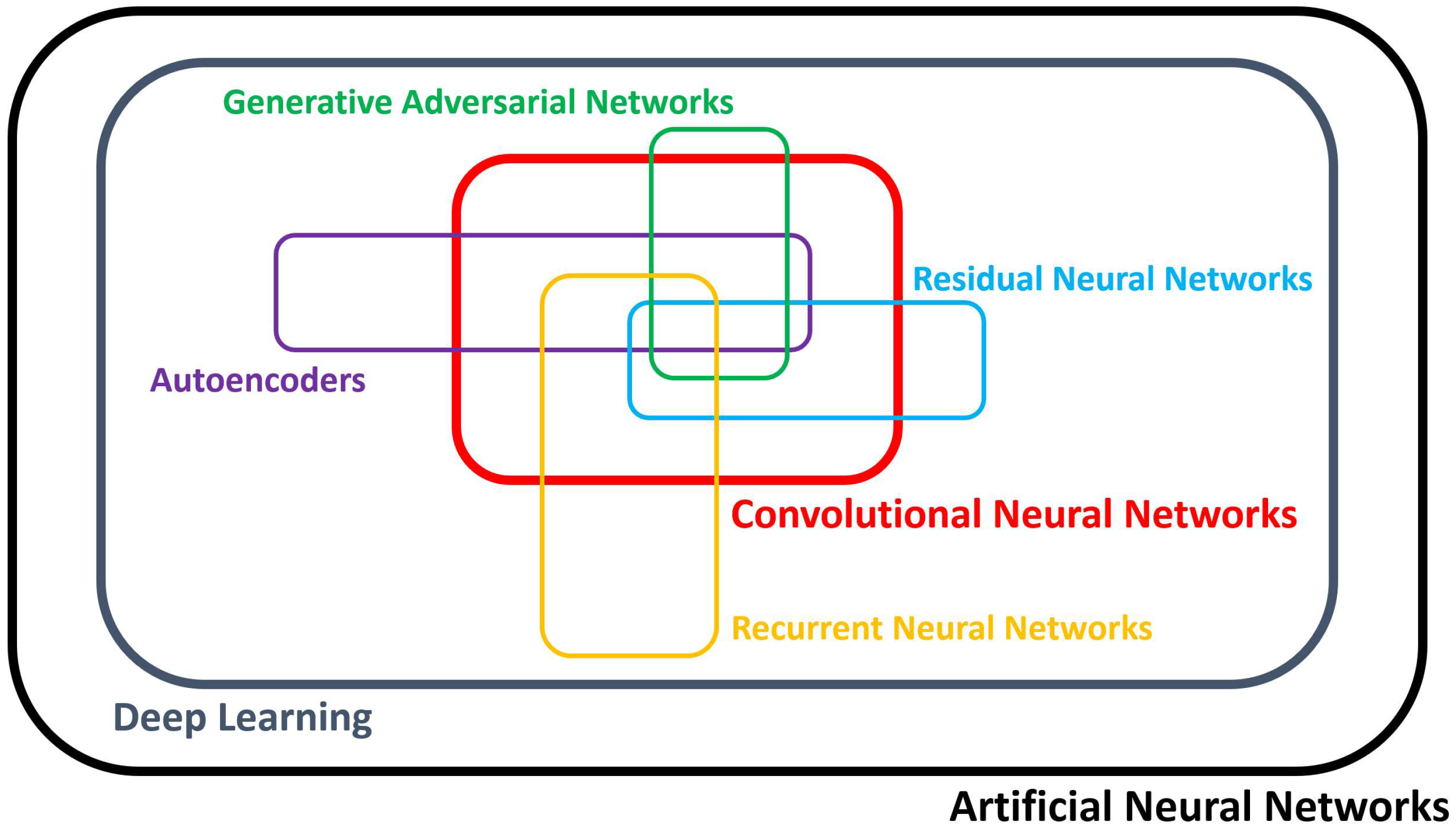
2. Deep Learning—Overview
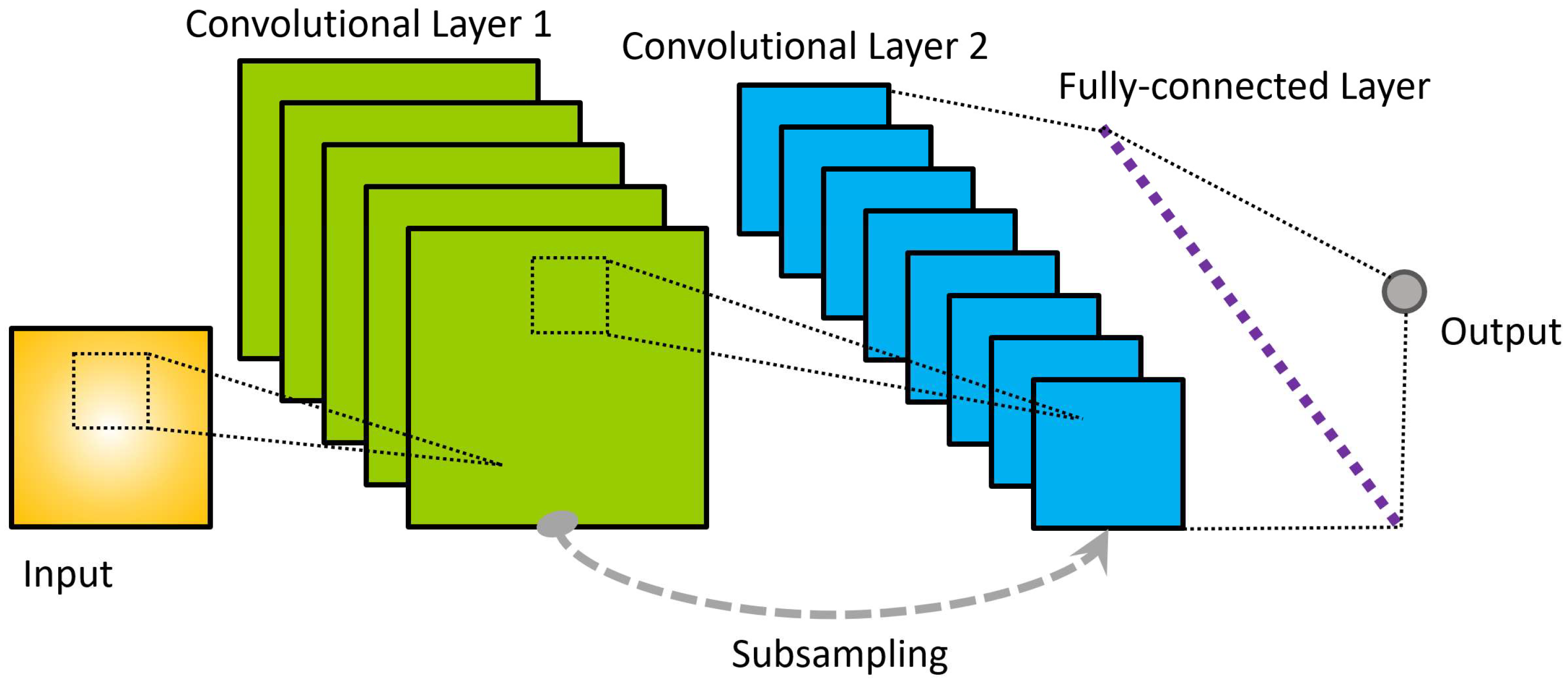
2.1. Convolutional Neural Networks (CNN)
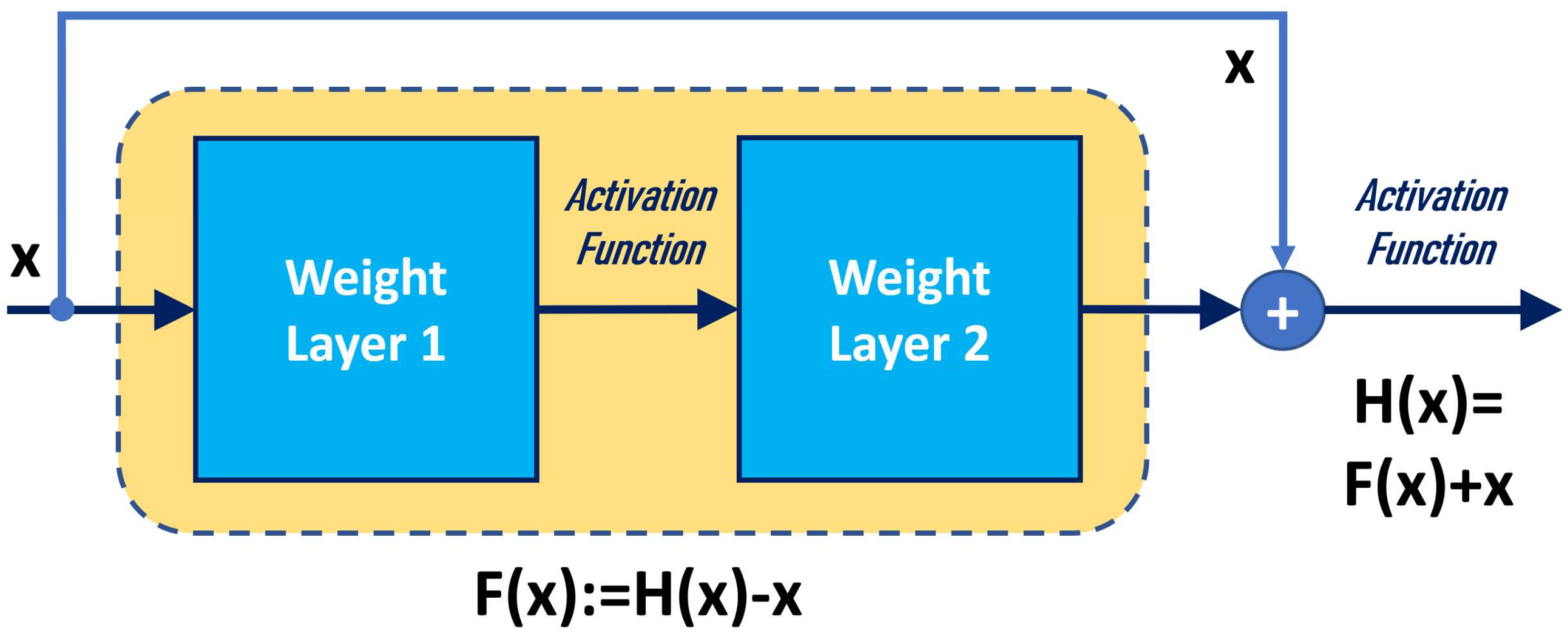
2.2. Residual Network (ResNet)
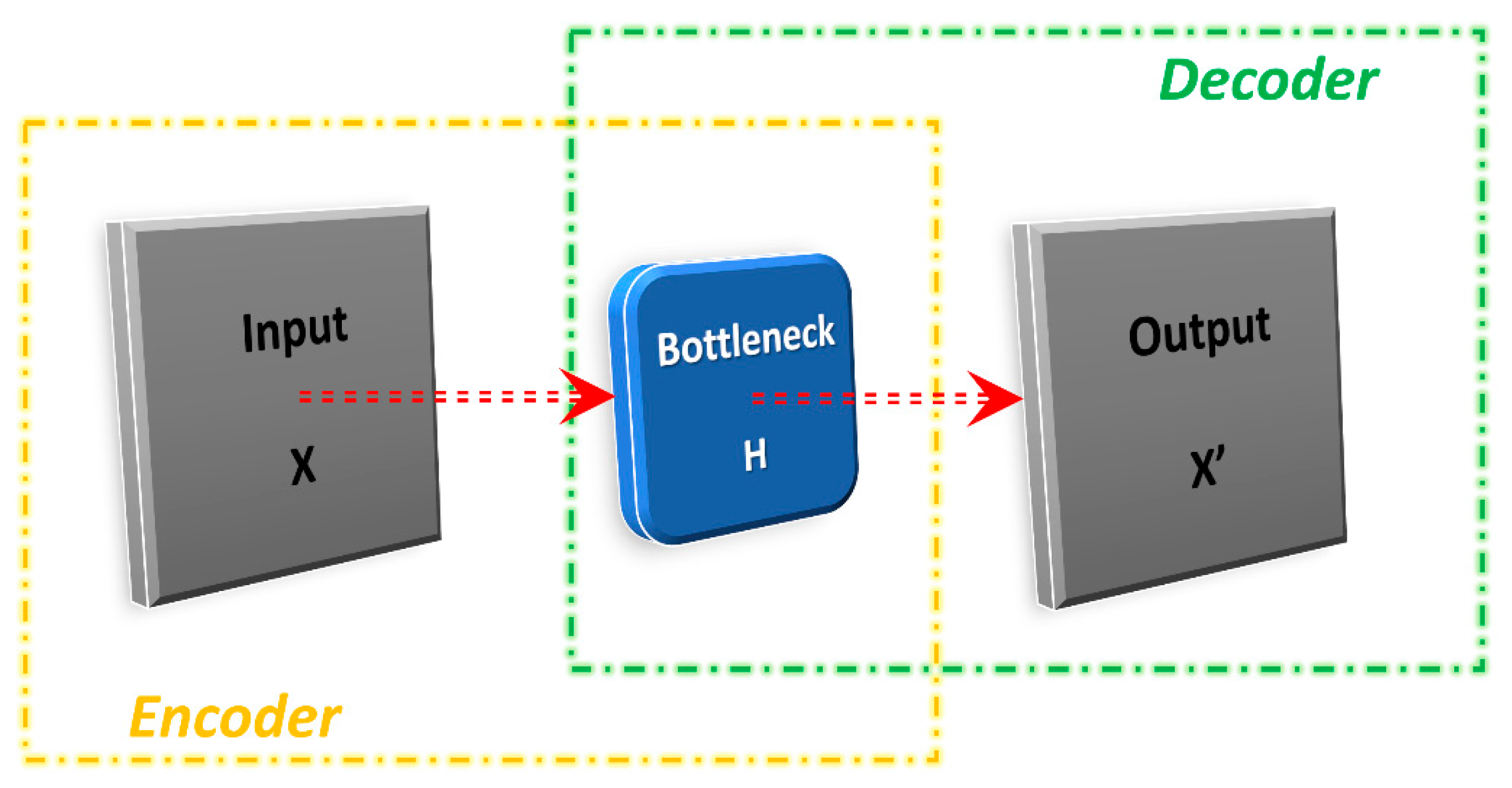
2.3. Autoencoder
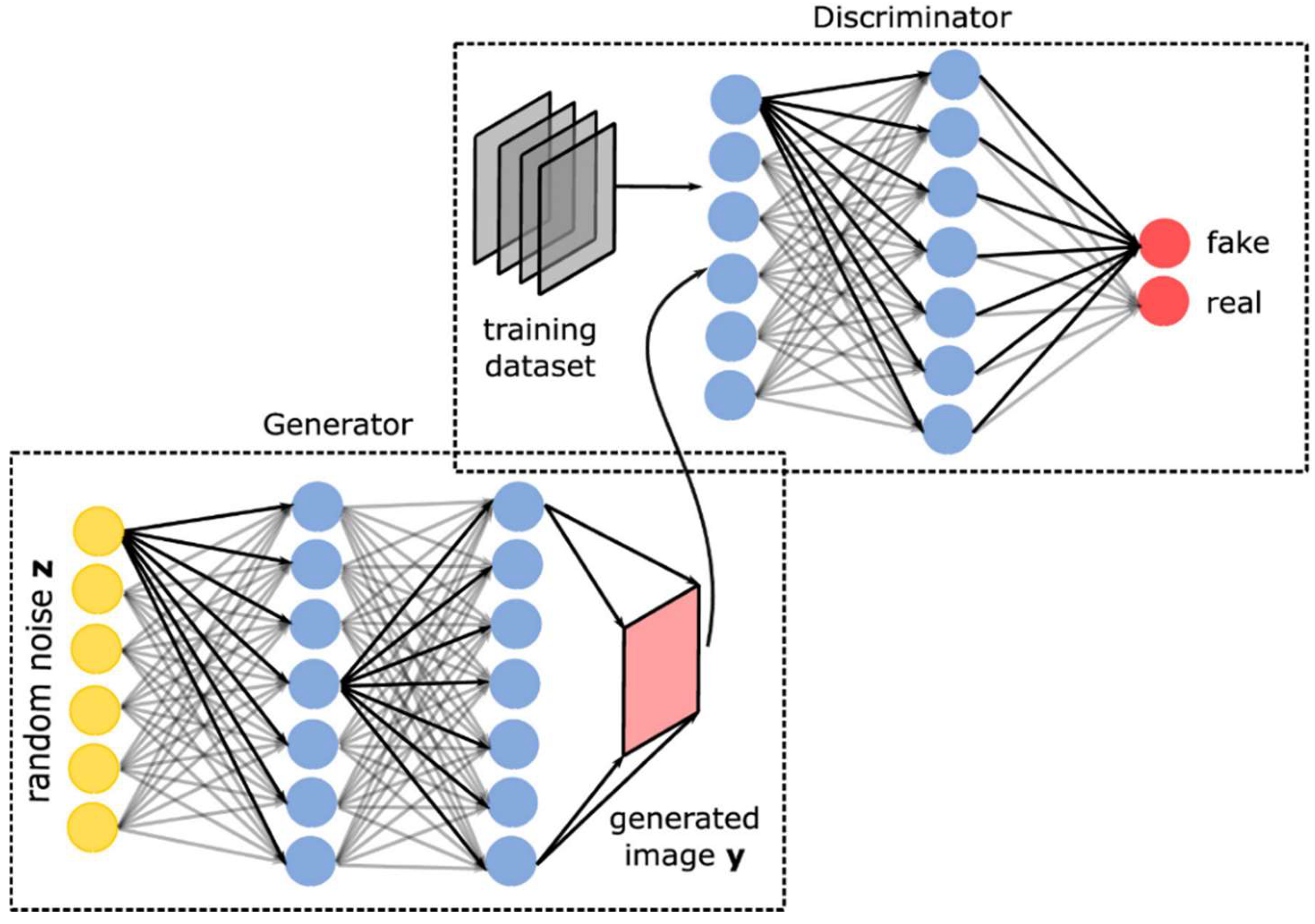
2.4. Generative Adversarial Network (GAN)
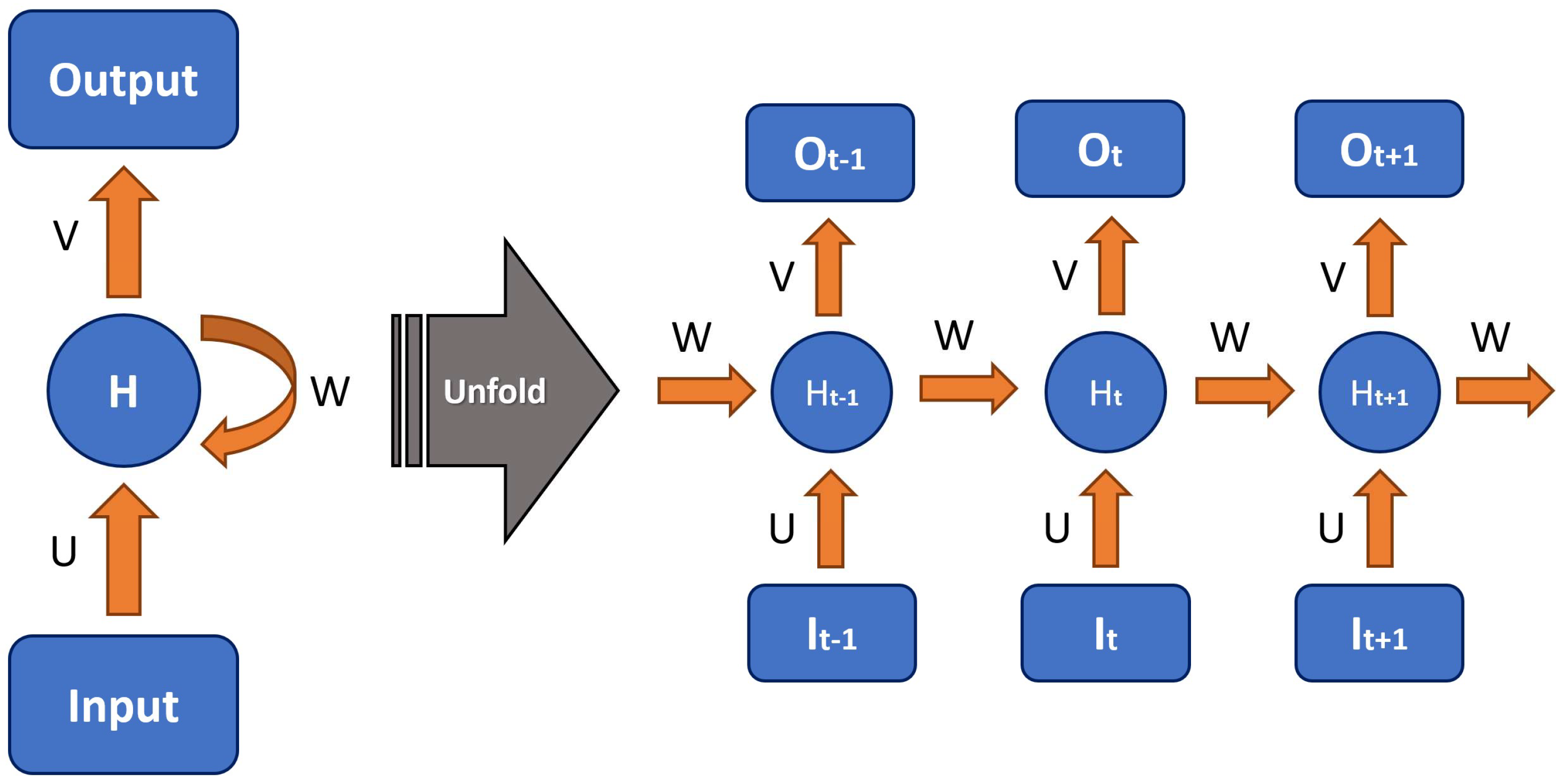
2.5. Recurrent Neural Network (RNN)
3. Recent Applications for Raman Spectroscopy
3.1. Pre-Processing
3.2. Classification and Regression
3.3. Spectral Data Highlighting

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Examples |
|---|---|
| Pre-processing | Wahl et al. [31], Valensise et al. [32], Horgan et al. [33], Gebrekidan et al. [34], Pan et al. [35], and Houhou et al. [36] |
| Classification/ Regression | Boonsit et al. [7], Dong et al. [37], Lee et al. [38], Kirchberger-Tolstik et al. [39], Maruthamuthu et al. [40], Cheng et al. [41], Fan et al. [42], Fu et al. [43], Houston et al. [44], Ho et al. [45], Ding et al. [46], Chen et al. [47], Saifuzzaman et al. [48], Pan et al. [49,50], Sohn et al. [51], Yu et al. [52], Thrift and Ragan [53], and Zhang et al. [54] |
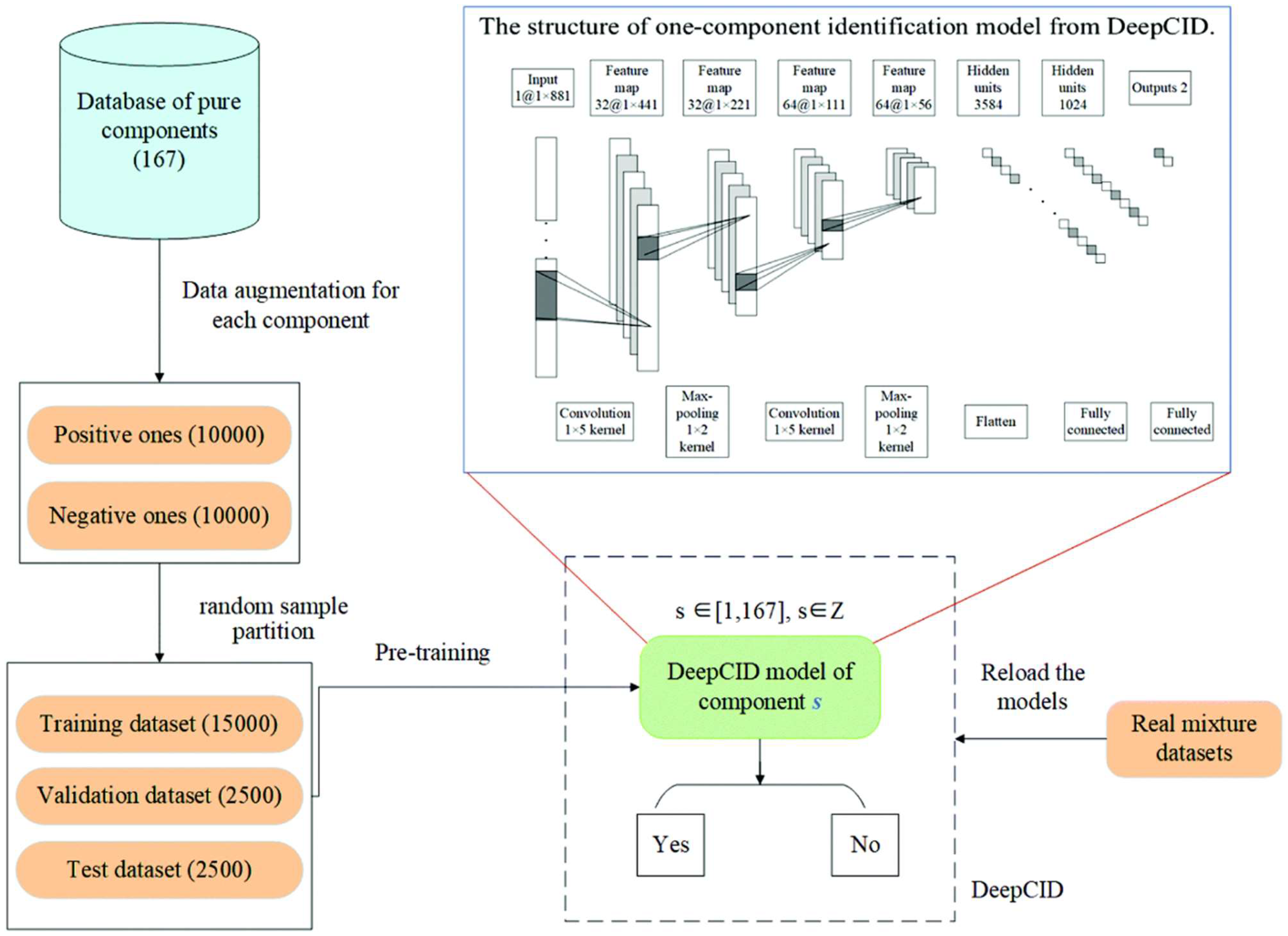
| Highlighting | Fukuhara et al. [55] |
4. Challenges and Shortcomings
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Raman, C.V. A new radiation. Indian J. Phys. 1928, 2, 387–398. [Google Scholar] [CrossRef]
- Bocklitz, T.W.; Guo, S.; Ryabchykov, O.; Vogler, N.; Popp, J. Raman based molecular imaging and analytics: A magic bullet for biomedical applications!? Anal. Chem. 2016, 88, 133–151. [Google Scholar] [CrossRef] [PubMed]
- Maker, P.D.; Terhune, R.W. Study of optical effects due to an induced polarization third order in the electric field strength. Phys. Rev. 1965, 137, 801–818. [Google Scholar] [CrossRef]
- Fleischmann, M.; Hendra, P.J.; McQuillan, A.J. Raman spectra of pyridine adsorbed at a silver electrode. Chem. Phys. Lett. 1974, 26, 163–166. [Google Scholar] [CrossRef]
- Penido, C.A.F.O.; Pacheco, M.T.T.; Lednev, I.K.; Silveira, L., Jr. Raman spectroscopy in forensic analysis: Identification of cocaine and other illegal drugs of abuse. J. Raman Spectrosc. 2016, 47, 28–38. [Google Scholar] [CrossRef]
- Paudel, A.; Raijada, D.; Rantanen, J. Raman spectroscopy in pharmaceutical product design. Adv. Drug Deliv. Rev. 2015, 89, 3–20. [Google Scholar] [CrossRef] [Green Version]
- Boonsit, S.; Kalasuwan, P.; van Dommelen, P.; Daengngam, C. Rapid material identification via low-resolution Raman spectroscopy and deep convolutional neural network. J. Phys. Conf. Ser. 2021, 1719, 012081. [Google Scholar] [CrossRef]
- Ryzhikova, E.; Ralbovsky, N.M.; Sikirzhytski, V.; Kazakov, O.; Halamkova, L.; Quinn, J.; Zimmerman, E.A.; Lednev, I.K. Raman spectroscopy and machine learning for biomedical applications: Alzheimer’s disease diagnosis based on the analysis of cerebrospinal fluid. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 248, 119188. [Google Scholar] [CrossRef]
- Pradhan, P.; Guo, S.; Ryabchykov, O.; Popp, J.; Bocklitz, T.W. Deep learning a boon for biophotonics? J. Biophotonics 2020, 13, e201960186. [Google Scholar] [CrossRef] [Green Version]
- Kowalski, B.R. Chemometrics: Views and propositions. J. Chem. Inf. Comput. Sci. 1975, 15, 201–203. [Google Scholar] [CrossRef]
- Zhao, J.; Lui, H.; McLean, D.I.; Zeng, H. Automated autofluorescence background subtraction algorithm for biomedical Raman spectroscopy. Appl. Spectrosc. 2007, 61, 1225–1232. [Google Scholar] [CrossRef] [PubMed]
- Witjes, H.; van den Brink, M.; Melssen, W.J.; Buydens, L.M.C. Automatic correction of peak shifts in Raman spectra before PLS regression. Chemom. Intell. Lab. Syst. 2000, 52, 105–116. [Google Scholar] [CrossRef]
- Goetz, M.J., Jr.; Coté, G.L.; Erckens, R.; March, W.; Motamedi, M. Application of a multivariate technique to Raman spectra for quantification of body chemicals. IEEE Trans. Biomed. Eng. 1995, 42, 728–731. [Google Scholar] [CrossRef]
- Hedegaard, M.; Krafft, C.; Ditzel, H.J.; Johansen, L.E.; Hassing, S.; Popp, J. Discriminating isogenic cancer cells and identifying altered unsaturated fatty acid content as associated with metastasis status, using K-means clustering and partial least squares-discriminant analysis of Raman maps. Anal. Chem. 2010, 82, 2797–2802. [Google Scholar] [CrossRef]
- Guo, S.; Rösch, P.; Popp, J.; Bocklitz, T. Modified PCA and PLS: Towards a better classification in Raman spectroscopy-based biological applications. J. Chemom. 2020, 34, e3202. [Google Scholar] [CrossRef] [Green Version]
- Manoharan, R.; Shafer, K.; Perelman, L.; Wu, J.; Chen, K.; Deinum, G.; Fitzmaurice, M.; Myles, J.; Crowe, J.; Dasari, R.R.; et al. Raman spectroscopy and fluorescence photon migration for breast cancer diagnosis and imaging. Photochem. Photobiol. 1998, 67, 15–22. [Google Scholar] [CrossRef]
- Widjaja, E.; Zheng, W.; Huang, Z. Classification of colonic tissues using near-infrared Raman spectroscopy and support vector machines. Int. J. Oncol. 2008, 32, 653–662. [Google Scholar] [CrossRef] [Green Version]
- Seifert, S. Application of random forest based approaches to surface-enhanced Raman scattering data. Sci. Rep. 2020, 10, 5436. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 1–481. ISBN 978-026-203-561-3. [Google Scholar]
- Ma, W.; Liu, Z.; Kudyshev, Z.A.; Boltasseva, A.; Cai, W.; Liu, Y. Deep learning for the design of photonic structures. Nat. Photonics 2021, 15, 77–90. [Google Scholar] [CrossRef]
- Mater, A.C.; Coote, M.L. Deep learning in chemistry. J. Chem. Inf. Model. 2019, 59, 2545–2559. [Google Scholar] [CrossRef]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dechter, R. Learning while searching in constraint-satisfaction-problems. In Proceedings of the 5th National Conference on Artificial Intelligence (AAAI-86), Philadelphia, PA, USA, 11–15 August 1986; pp. 178–183. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2006), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–12. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Guo, S.; Popp, J.; Bocklitz, T. Chemometric analysis in Raman spectroscopy from experimental design to machine learning-based modeling. Nat. Protoc. 2021, 16, 5426–5459. [Google Scholar] [CrossRef]
- Gerretzen, J.; Szymańska, E.; Jansen, J.J.; Bart, J.; van Manen, H.J.; van den Heuvel, E.R.; Buydens, L.M. Simple and effective way for data preprocessing selection based on design of experiments. Anal. Chem. 2015, 87, 12096–12103. [Google Scholar] [CrossRef] [Green Version]
- Wahl, J.; Sjödahl, M.; Ramser, K. Single-step preprocessing of Raman spectra using convolutional neural networks. Appl. Spectrosc. 2020, 74, 427–438. [Google Scholar] [CrossRef]
- Valensise, C.M.; Giuseppi, A.; Vernuccio, F.; de la Cadena, A.; Cerullo, G.; Polli, D. Removing non-resonant background from CARS spectra via deep learning. APL Photonics 2020, 5, 061305. [Google Scholar] [CrossRef]
- Horgan, C.C.; Jensen, M.; Nagelkerke, A.; St-Pierre, J.P.; Vercauteren, T.; Stevens, M.M.; Bergholt, M.S. High-Throughput molecular imaging via deep learning enabled Raman spectroscopy. Anal. Chem. 2021, 93, 15850–15860. [Google Scholar] [CrossRef]
- Gebrekidan, M.T.; Knipfer, C.; Braeuer, A.S. Refinement of spectra using a deep neural network: Fully automated removal of noise and background. J. Raman Spectrosc. 2021, 52, 723–736. [Google Scholar] [CrossRef]
- Pan, L.; Pipitsunthonsan, P.; Daengngam, C.; Channumsin, S.; Sreesawet, S.; Chongcheawchamnan, M. Noise reduction technique for Raman spectrum using deep learning network. arXiv 2020, arXiv:2009.04067. [Google Scholar]
- Houhou, R.; Barman, P.; Schmitt, M.; Meyer, T.; Popp, J.; Bocklitz, T. Deep learning as phase retrieval tool for CARS spectra. Opt. Express 2020, 28, 21002–21024. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Hong, M.; Xu, Y.; Zheng, X. A practical convolutional neural network model for discriminating Raman spectra of human and animal blood. J. Chemom. 2019, 33, e3184. [Google Scholar] [CrossRef]
- Lee, W.; Lenferink, A.T.M.; Otto, C.; Offerhaus, H.L. Classifying Raman spectra of extracellular vesicles based on convolutional neural networks for prostate cancer detection. J. Raman Spectrosc. 2020, 51, 293–300. [Google Scholar] [CrossRef]
- Kirchberger-Tolstik, T.; Pradhan, P.; Vieth, M.; Grunert, P.; Popp, J.; Bocklitz, T.W.; Stallmach, A. Towards an interpretable classifier for characterization of endoscopic Mayo scores in ulcerative colitis using Raman spectroscopy. Anal. Chem. 2020, 92, 13776–13784. [Google Scholar] [CrossRef]
- Maruthamuthu, M.K.; Raffiee, A.H.; de Oliveira, D.M.; Ardekani, A.M.; Verma, M.S. Raman spectra-based deep learning: A tool to identify microbial contamination. Microbiol. Open 2020, 9, e1122. [Google Scholar] [CrossRef]
- Cheng, N.; Fu, J.; Chen, D.; Chen, S.; Wang, H. An antibody-free liver cancer screening approach based on nanoplasmonics biosensing chips via spectrum-based deep learning. Nano Impact 2021, 21, 100296. [Google Scholar] [CrossRef]
- Fan, X.; Ming, W.; Zeng, H.; Zhang, Z.; Lu, H. Deep learning-based component identification for the Raman spectra of mixtures. Analyst 2019, 144, 1789–1798. [Google Scholar] [CrossRef]
- Fu, X.; Zhong, L.; Cao, Y.; Chen, H.; Lu, F. Quantitative analysis of excipient dominated drug formulations by Raman spectroscopy combined with deep learning. Anal. Methods 2021, 13, 64–68. [Google Scholar] [CrossRef]
- Houston, J.; Glavin, F.G.; Madden, M.G. Robust classification of high-dimensional spectroscopy data using deep learning and data synthesis. J. Chem. Inf. Model. 2020, 60, 1936–1954. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ho, C.S.; Jean, N.; Hogan, C.A.; Blackmon, L.; Jeffrey, S.S.; Holodniy, M.; Banaei, N.; Saleh, A.A.E.; Ermon, S.; Dionne, J. Rapid identification of pathogenic bacteria using Raman spectroscopy and deep learning. Nat. Commun. 2019, 10, 4927. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Yu, M.; Zhu, L.; Zhang, T.; Xia, J.; Sun, G. Diverse spectral band-based deep residual network for tongue squamous cell carcinoma classification using fiber optic Raman spectroscopy. Photodiagn. Photodyn. Ther. 2020, 32, 102048. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Chen, C.; Wang, H.; Chen, C.; Guo, Z.; Tong, D.; Li, H.; Li, H.; Si, R.; Lai, H.; et al. Serum Raman spectroscopy combined with a multi-feature fusion convolutional neural network diagnosing thyroid dysfunction. Optik 2020, 216, 164961. [Google Scholar] [CrossRef]
- Saifuzzaman, T.A.; Lee, K.Y.; Radzol, A.R.M.; Wong, P.S.; Looi, I. Optimal scree-CNN for detecting NS1 molecular fingerprint from salivary SERS spectra. In Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC 2020), Montreal, QC, Canada, 20–24 July 2020; pp. 180–183. [Google Scholar]
- Pan, L.; Pipitsunthonsan, P.; Daengngam, C.; Channumsin, S.; Sreesawet, S.; Chongcheawchamnan, M. Method for classifying a noisy Raman spectrum based on a wavelet transform and a deep neural network. IEEE Access 2020, 8, 202716–202727. [Google Scholar] [CrossRef]
- Pan, L.; Pipitsunthonsan, P.; Daengngam, C.; Channumsin, S.; Sreesawet, S.; Chongcheawchamnan, M. Identification of complex mixtures for Raman spectroscopy using a novel scheme based on a new multi-label deep neural network. IEEE Sens. J. 2021, 21, 10834–10843. [Google Scholar] [CrossRef]
- Sohn, W.B.; Lee, S.Y.; Kim, S. Single-layer multiple-kernel-based convolutional neural network for biological Raman spectral analysis. J. Raman Spectrosc. 2020, 51, 414–421. [Google Scholar] [CrossRef]
- Yu, S.; Li, H.; Li, X.; Fu, Y.V.; Liu, F. Classification of pathogens by Raman spectroscopy combined with generative adversarial networks. Sci. Total Environ. 2020, 726, 138477. [Google Scholar] [CrossRef]
- Thrift, W.J.; Ragan, R. Quantification of analyte concentration in the single molecule regime using convolutional neural network. Anal. Chem. 2019, 91, 13337–13342. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Xie, H.; Cai, S.; Hu, Y.; Liu, G.; Hong, W.; Tian, Z. Transfer-Learning-Based Raman spectra identification. J. Raman Spectrosc. 2020, 51, 176–186. [Google Scholar] [CrossRef]
- Fukuhara, M.; Fujiwara, K.; Maruyama, Y.; Itoh, H. Feature visualization of Raman spectrum analysis with deep convolutional neural network. Anal. Chim. Acta 2019, 1087, 11–19. [Google Scholar] [CrossRef] [PubMed]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, R.; Popp, J.; Bocklitz, T. Deep Learning for Raman Spectroscopy: A Review. Analytica 2022, 3, 287-301. https://doi.org/10.3390/analytica3030020
Luo R, Popp J, Bocklitz T. Deep Learning for Raman Spectroscopy: A Review. Analytica. 2022; 3(3):287-301. https://doi.org/10.3390/analytica3030020
Chicago/Turabian StyleLuo, Ruihao, Juergen Popp, and Thomas Bocklitz. 2022. "Deep Learning for Raman Spectroscopy: A Review" Analytica 3, no. 3: 287-301. https://doi.org/10.3390/analytica3030020