

A Pilot Study on the Use of Generative Adversarial Networks for Data Augmentation of Time Series

Abstract
:1. Introduction
- 1
- Type of data: Data may be tabular, images, time series, chemical structures, etc. The different types of data may require different data augmentation methods specifically designed to take into account the particular structure and intricacies of that type of data.
- 2
- Downstream task: The downstream processing of the augmented data affects the choice of the data augmentation method. For example, the type of neural network architecture will influence the choice of the data augmentation method, and also if the task is a classification task or not.
- 3
- Performance evaluation metrics: In order to select an optimal data augmentation method, it is necessary to be able to compare its performance against competing methods by using formally defined performance evaluation metrics. There is a need for more research studies to address in depth the related topic of comparison of data augmentation methods.
- 4
- Computation time, latency and determinism constraints: These constraints, regarding the nature and execution of the method, will affect the choice of the data augmentation method. Testing is required to identify the optimal data augmentation method for a given situation. As above, more research is needed regarding these important operational constraints.
- 1
- Transformation-based methods
- 2
- Pattern-mixing methods
- 3
- Generative models
- 4
- Decomposition methods
2. Materials and Methods
2.1. Datasets
2.2. Architecture
2.3. Experiments
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| GAN | Generative Adversarial Network |
| MLP | MultiLayer Perceptron |
| LSTM | Long Short Time Memory |
References
- Tanner, M.A.; Wong, W.H. The Calculation of Posterior Distributions by Data Augmentation. J. Am. Stat. Assoc. 1987, 82, 528–540. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image Data Augmentation for Deep Learning: A Survey. arXiv 2022, arXiv:2204.08610v1. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–27 August 2021; Zhou, Z.H., Ed.; pp. 4653–4660. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. arXiv 2017, arXiv:1711.09020. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2018, arXiv:1812.04948. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Ghorbani, A.; Natarajan, V.; Coz, D.; Liu, Y. DermGAN: Synthetic Generation of Clinical Skin Images with Pathology. arXiv 2019, arXiv:1911.08716. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based Synthetic Medical Image Augmentation for increased CNN Performance in Liver Lesion Classification. arXiv 2018, arXiv:1803.01229. [Google Scholar] [CrossRef]
- Gupta, A.; Venkatesh, S.; Chopra, S.; Ledig, C. Generative Image Translation for Data Augmentation of Bone Lesion Pathology. arXiv 2019, arXiv:1902.02248. [Google Scholar]
- Brophy, E.; Wang, Z.; She, Q.; Ward, T. Generative adversarial networks in time series: A survey and taxonomy. arXiv 2021, arXiv:2107.11098. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Yoon, J.; Jarrett, D.; van der Schaar, M. Time-series Generative Adversarial Networks. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Bahrpeyma, F.; Roantree, M.; Cappellari, P.; Scriney, M.; McCarren, A. A Methodology for Validating Diversity in Synthetic Time Series Generation. MethodsX 2021, 8, 101459. [Google Scholar] [CrossRef] [PubMed]
- Xi, X.; Keogh, E.; Shelton, C.; Wei, L.; Ratanamahatana, C. Fast Time Series Classification Using Numerosity Reduction. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Volume 2006, pp. 1033–1040. [Google Scholar] [CrossRef]
- Pkalska, E.; Duin, R.P.W.; Paclík, P. Prototype Selection for Dissimilarity-Based Classifiers. Pattern Recogn. 2006, 39, 189–208. [Google Scholar] [CrossRef]
- Wilson, D.; Martinez, T. Instance Pruning Techniques. In Proceedings of the Fourteenth International Conference (ICML’97), Nashville, TN, USA, 8–12 July 1997; pp. 403–411. [Google Scholar]


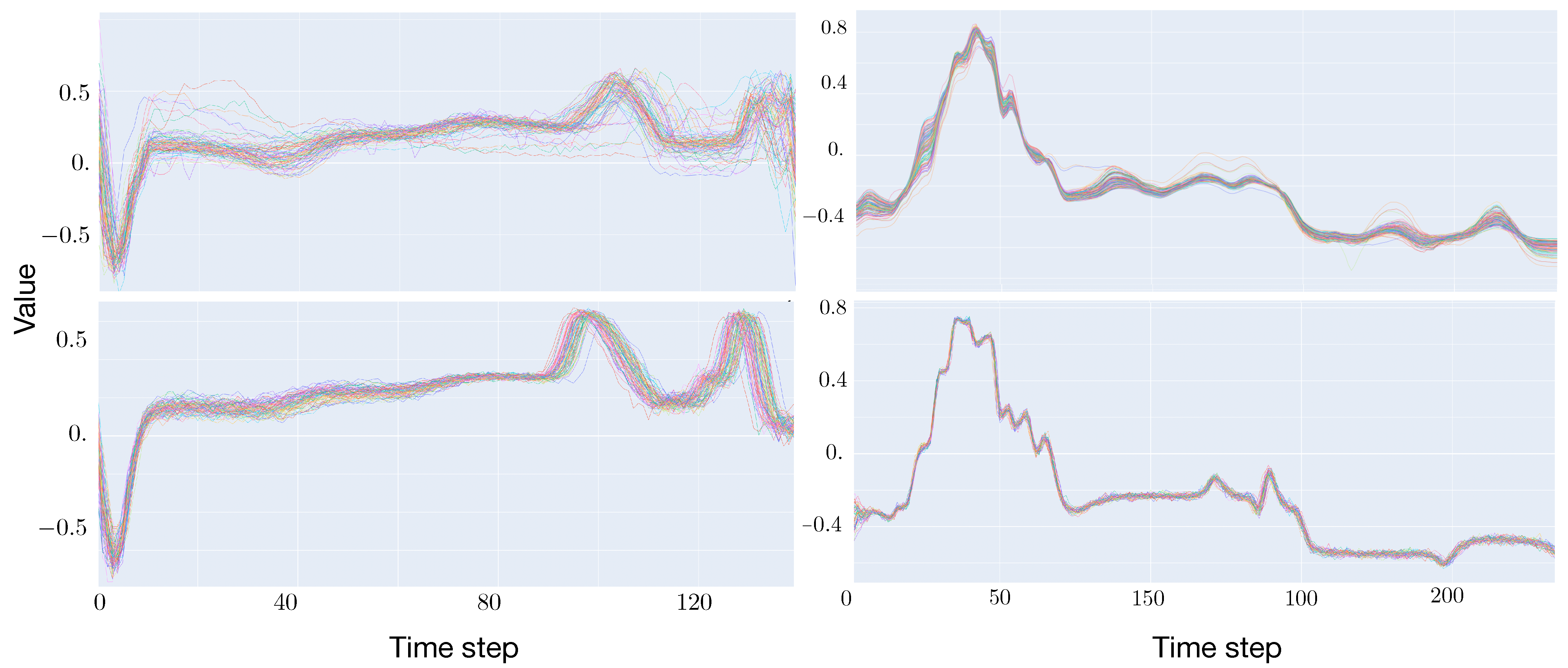{kind=link}
| Dataset | Type | Train | Test | Class | Length |
|---|---|---|---|---|---|
| FordB (D1) | Sensor | 3636 | 810 | 2 | 500 |
| ECG5000 (D2) | ECG | 500 | 4500 | 5 | 140 |
| Strawberry (D3) | Spectro | 613 | 370 | 2 | 235 |
| Dataset | Classifier | None | Jittering | SPAWNER | GAN |
|---|---|---|---|---|---|
| D1 | MLP | 71.27% ± 0.06 | 72.23% ± 0.04 | 69.15% ± 0.19 | 53.85% ± 0.26 |
| LSTM | 50.22% ± 0.09 | 50.48% ± 0.10 | 50.70% ± 0.11 | 49.65% | |
| D2 | MLP | 93.96% | 93.98% | 93.40% | 94.09% |
| LSTM | 92.76% ± 0.01 | 93.07% ± 0.02 | 93.21% ± 0.01 | 58.37% | |
| D3 | MLP | 89.46% | 85.95% | 75.35% ± 0.11 | 83.78% ± 0.14 |
| LSTM | 64.32% | 64.32% | 64.32% | 74.30% ± 0.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morizet, N.; Rizzato, M.; Grimbert, D.; Luta, G. A Pilot Study on the Use of Generative Adversarial Networks for Data Augmentation of Time Series. AI 2022, 3, 789-795. https://doi.org/10.3390/ai3040047
Morizet N, Rizzato M, Grimbert D, Luta G. A Pilot Study on the Use of Generative Adversarial Networks for Data Augmentation of Time Series. AI. 2022; 3(4):789-795. https://doi.org/10.3390/ai3040047
Chicago/Turabian StyleMorizet, Nicolas, Matteo Rizzato, David Grimbert, and George Luta. 2022. "A Pilot Study on the Use of Generative Adversarial Networks for Data Augmentation of Time Series" AI 3, no. 4: 789-795. https://doi.org/10.3390/ai3040047