
Shifting Perspectives on AI Evaluation: The Increasing Role of Ethics in Cooperation

Abstract
:1. Introduction
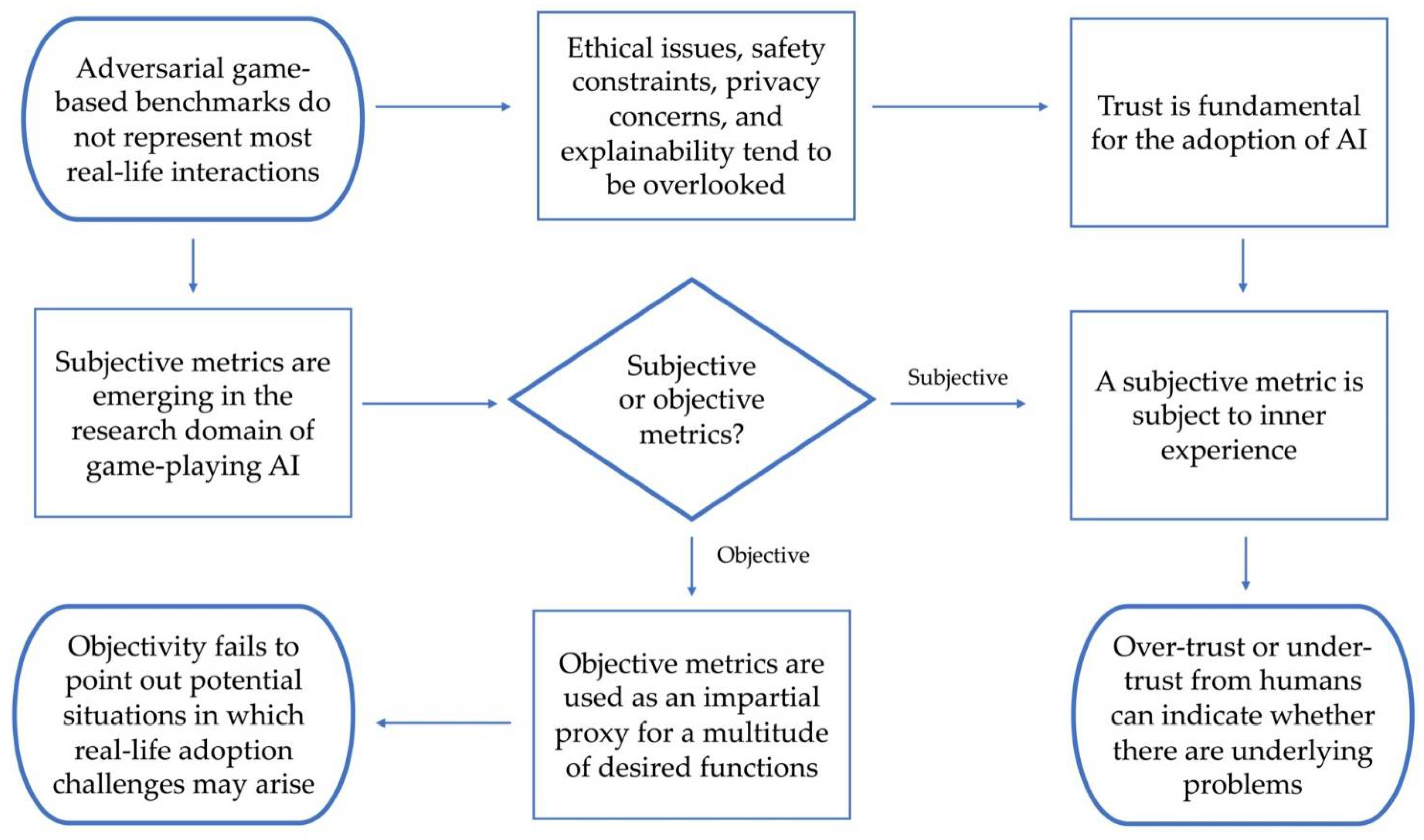
2. Definition of the Problem
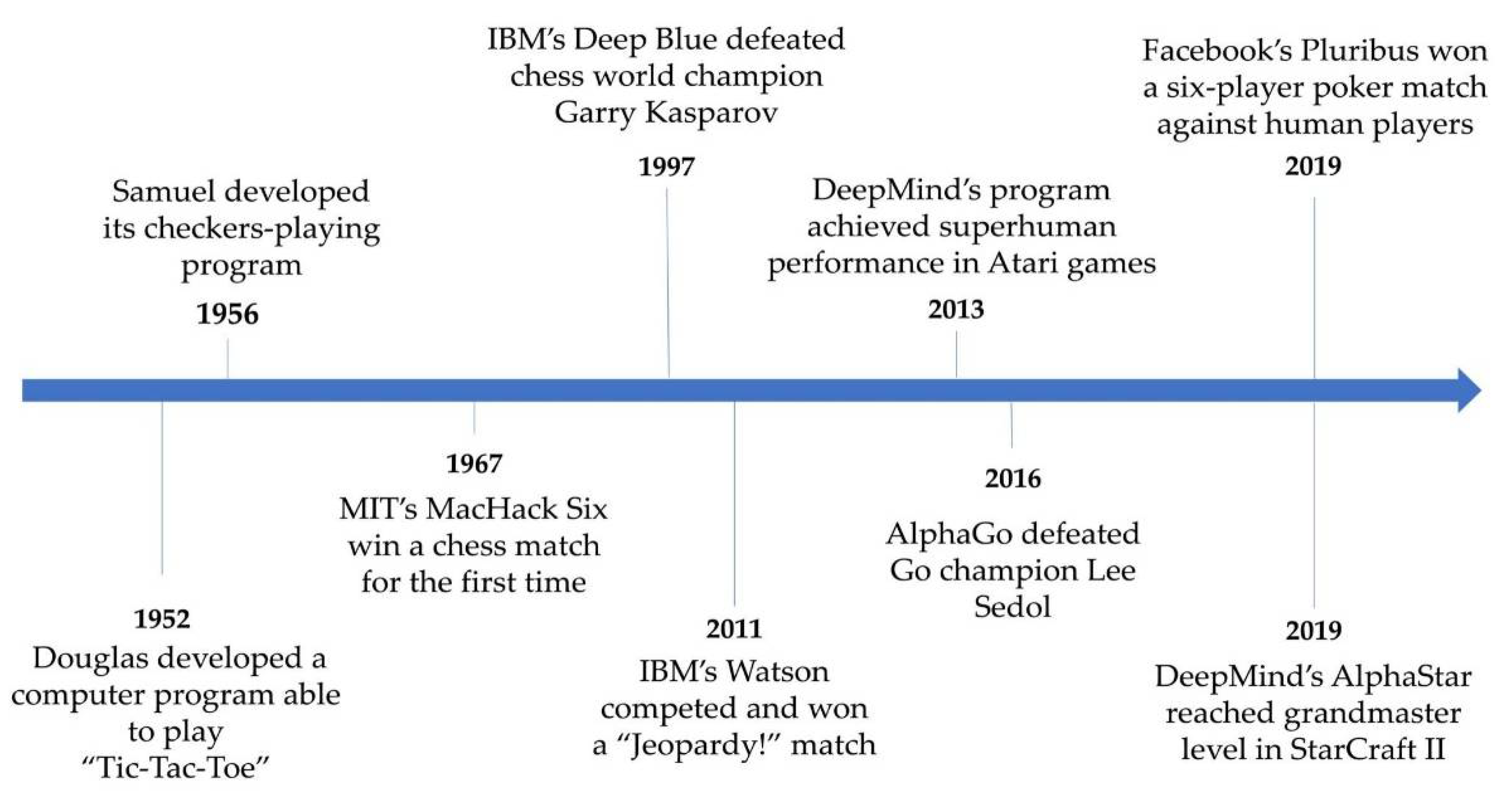
3. Evaluating AI through Games
Are Games Effective Benchmarks?
4. Evaluating AI through Cooperation
5. Ethical Concerns in Human–Machine Cooperation
5.1. The S Scenario: A Soccer Match
5.2. The B Scenario: A Battlefield
5.3. The R Scenario: A Restaurant
5.4. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fidora, A.; Sierra, C.; Institut d’Investigació en Intelligència Artificial (Eds.) Ramon Llull: From the Ars Magna to Artificial Intelligence; Artificial Intelligence Research Institute: Barcelona, Spain, 2011; Volume IIIA. [Google Scholar]
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, LIX, 433–460. [Google Scholar] [CrossRef]
- Goertzel, B. What Counts as a Conscious Thinking Machine? New Scientist. Available online: https://www.newscientist.com/article/mg21528813-600-what-counts-as-a-conscious-thinking-machine/ (accessed on 3 January 2022).
- Nilsson, N.J. Human-Level Artificial Intelligence? Be Serious! AI Mag. 2005, 26, 68. [Google Scholar]
- Kušić, M.; Nurkić, P. Artificial morality: Making of the artificial moral agents. Belgrade Philos. Annu. 2019, 32, 27–49. [Google Scholar] [CrossRef]
- Jobin, A.; Ienca, M.; Vayena, E. The global landscape of AI ethics guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Halsband, A. Sustainable AI and Intergenerational Justice. Sustainability 2022, 14, 3922. [Google Scholar] [CrossRef]
- Khosravy, M.; Nakamura, K.; Hirose, Y.; Nitta, N.; Babaguchi, N. Model Inversion Attack by Integration of Deep Generative Models: Privacy-Sensitive Face Generation from a Face Recognition System. IEEE Trans. Inf. Forensics Secur. 2022, 17, 357–372. [Google Scholar] [CrossRef]
- Khosravy, M.; Nakamura, K.; Hirose, Y.; Nitta, N.; Babaguchi, N. Model Inversion Attack: Analysis under Gray-box Scenario on Deep Learning based Face Recognition System. KSII Trans. Internet Inf. Syst. 2021, 15, 1100–1118. [Google Scholar] [CrossRef]
- Kang, S.; Haas, C.T. Evaluating artificial intelligence tools for automated practice conformance checking. ISARC Proc. Int. Symp. Autom. Robot. Constr. 2018, 35, 1–8. [Google Scholar]
- Ish, D.; Ettinger, J.; Ferris, C. Evaluating the Effectiveness of Artificial Intelligence Systems in Intelligence Analysis; RAND Corp.: Santa Monica, CA, USA, 2021; Available online: https://www.rand.org/pubs/research_reports/RRA464-1.html (accessed on 6 March 2022).
- Babbage, C.; Campbell-Kelly, M. Passages from the Life of a Philosopher; Rutgers University Press: New Brunswick, NJ, USA; IEEE Press: Piscataway, NJ, USA, 1994. [Google Scholar]
- Bromley, A.G. Charles Babbage’s Analytical Engine, 1838. IEEE Ann. Hist. Comput. 1998, 20, 29–45. [Google Scholar] [CrossRef]
- Shannon, C.E. Programming a Computer for Playing Chess. In Computer Chess Compendium; Levy, D., Ed.; Springer: New York, NY, USA, 1988; pp. 2–13. [Google Scholar] [CrossRef]
- Samuel, A.L. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Ensmenger, N. Is chess the drosophila of artificial intelligence? A social history of an algorithm. Soc. Stud. Sci. 2011, 42, 5–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bory, P. Deep new: The shifting narratives of artificial intelligence from Deep Blue to AlphaGo. Converg. Int. J. Res. New Media Technol. 2017, 25, 627–642. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Madan, C. Considerations for Comparing Video Game AI Agents with Humans. Challenges 2020, 11, 18. [Google Scholar] [CrossRef]
- Chollet, F. On the Measure of Intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Perez-Liebana, D.; Samothrakis, S.; Togelius, J.; Schaul, T.; Lucas, S.; Couetoux, A.; Lee, J.; Lim, C.-U.; Thompson, T. The 2014 General Video Game Playing Competition. IEEE Trans. Comput. Intell. AI Games 2015, 8, 229–243. [Google Scholar] [CrossRef] [Green Version]
- Campbell, M.; Hoane, A.J., Jr.; Hsu, F.-H. Deep Blue. Artif. Intell. 2002, 134, 57–83. [Google Scholar] [CrossRef] [Green Version]
- Tesauro, G. Programming backgammon using self-teaching neural nets. Artif. Intell. 2002, 134, 181–199. [Google Scholar] [CrossRef] [Green Version]
- Dutta, P.K. Strategies and Games: Theory and Practice; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Brown, N.; Sandholm, T. Superhuman AI for multiplayer poker. Science 2019, 365, 885–890. [Google Scholar] [CrossRef] [PubMed]
- Brockman, G.; Chan, B.; Cheung, V.; Debiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Farisco, M.; Evers, K.; Salles, A. Towards Establishing Criteria for the Ethical Analysis of Artificial Intelligence. Sci. Eng. Ethics 2020, 26, 2413–2425. [Google Scholar] [CrossRef] [PubMed]
- Siu, H.C.; Pena, J.D.; Chang, K.C.; Chen, E.; Zhou, Y.; Lopez, V.J.; Palko, K.; Allen, R.E. Evaluation of Human-AI Teams for Learned and Rule-Based Agents in Hanabi. arXiv 2021, arXiv:2107.07630. [Google Scholar]
- Millot, P.; Lemoine, M. An attempt for generic concepts toward human-machine cooperation. In SMC’98 Conference Proceedings, Proceedings of the 1998 IEEE International Conference on Systems, Man, and Cybernetics (Cat. No.98CH36218), San Diego, CA, USA, 14 October 1998; IEEE: Piscataway, NJ, USA, 1998; Volume 1, pp. 1044–1049. [Google Scholar] [CrossRef]
- March, C. Strategic interactions between humans and artificial intelligence: Lessons from experiments with computer players. J. Econ. Psychol. 2021, 87, 102426. [Google Scholar] [CrossRef]
- Cesta, A.; Orlandini, A.; Umbrico, A. Fostering Robust Human-Robot Collaboration through AI Task Planning. Procedia CIRP 2018, 72, 1045–1050. [Google Scholar] [CrossRef]
- Mörtl, A.; Lawitzky, M.; Kucukyilmaz, A.; Sezgin, M.; Basdogan, C.; Hirche, S. The role of roles: Physical cooperation between humans and robots. Int. J. Robot. Res. 2012, 31, 1656–1674. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Yang, X.J. Modeling and Predicting Trust Dynamics in Human–Robot Teaming: A Bayesian Inference Approach. Int. J. Soc. Robot. 2020, 13, 1899–1909. [Google Scholar] [CrossRef]
- Chong, L.; Zhang, G.; Goucher-Lambert, K.; Kotovsky, K.; Cagan, J. Human confidence in artificial intelligence and in themselves: The evolution and impact of confidence on adoption of AI advice. Comput. Hum. Behav. 2021, 127, 107018. [Google Scholar] [CrossRef]
- Bender, N.; Faramawy, S.E.; Kraus, J.M.; Baumann, M. The role of successful human-robot interaction on trust—Findings of an experiment with an autonomous cooperative robot. arXiv 2021, arXiv:2104.06863. [Google Scholar]
- Hanoch, Y.; Arvizzigno, F.; García, D.H.; Denham, S.; Belpaeme, T.; Gummerum, M. The Robot Made Me Do It: Human–Robot Interaction and Risk-Taking Behavior. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 337–342. [Google Scholar] [CrossRef]
- Compagna, D.; Weidemann, A.; Marquardt, M.; Graf, P. Sociological and Biological Insights on How to Prevent the Reduction in Cognitive Activity that Stems from Robots Assuming Workloads in Human–Robot Cooperation. Societies 2016, 6, 29. [Google Scholar] [CrossRef] [Green Version]
- Formosa, P. Robot Autonomy vs. Human Autonomy: Social Robots, Artificial Intelligence (AI), and the Nature of Autonomy. Minds Mach. 2021, 31, 595–616. [Google Scholar] [CrossRef]
- Karpus, J.; Krüger, A.; Verba, J.T.; Bahrami, B.; Deroy, O. Algorithm exploitation: Humans are keen to exploit benevolent AI. iScience 2021, 24, 102679. [Google Scholar] [CrossRef]
- Kulms, P.; Kopp, S. More Human-Likeness, More Trust? In Proceedings of the Mensch und Computer 2019, Hamburg, Germany, 8 September 2019; pp. 31–42. [Google Scholar] [CrossRef]
- Maehigashi, A.; Tsumura, T.; Yamada, S. Comparison of human trust in an AI system, a human, and a social robot as a task partner. arXiv 2022, arXiv:2202.01077. [Google Scholar]
- Salles, A.; Evers, K.; Farisco, M. Anthropomorphism in AI. AJOB Neurosci. 2020, 11, 88–95. [Google Scholar] [CrossRef] [PubMed]
- Dafoe, A.; Bachrach, Y.; Hadfield, G.; Horvitz, E.; Larson, K.; Graepel, T. Cooperative AI: Machines must learn to find common ground. Nature 2021, 593, 33–36. [Google Scholar] [CrossRef] [PubMed]
- Gillies, R.M. Cooperative Learning: Review of Research and Practice. Aust. J. Teach. Educ. 2016, 41, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Dong, M.; Sun, Z. On human machine cooperative learning control. In Proceedings of the 2003 IEEE International Symposium on Intelligent Control ISIC-03, Houston, TX, USA, 8 October 2003; pp. 81–86. [Google Scholar] [CrossRef]
- Mackworth, A.K. On Seeing Robots. In Computer Vision: Systems, Theory and Applications; World Scientific: Singapore, 1993; pp. 1–13. [Google Scholar] [CrossRef]
- Martins, F.B.; Machado, M.G.; Bassani, H.F.; Braga, P.H.M.; Barros, E.S. rSoccer: A Framework for Studying Reinforcement Learning in Small and Very Small Size Robot Soccer. arXiv 2022, arXiv:2106.12895. [Google Scholar]
- Anderson, J.; Baltes, J.; Cheng, C.T. Robotics competitions as benchmarks for AI research. Knowl. Eng. Rev. 2011, 26, 11–17. [Google Scholar] [CrossRef] [Green Version]
- Grush, L. Amazon’s Alexa and Cisco’s Webex Are Heading to Deep Space on NASA’s Upcoming Moon Mission. The Verge. 5 January 2022. Available online: https://www.theverge.com/2022/1/5/22866746/nasa-artemis-i-amazon-alexa-cisco-webex-lockheed-martin-orion (accessed on 14 January 2022).
- Zhang, Y. A Big-Data Analysis of Public Perceptions of Robotic Services Amid COVID-19. Adv. Hosp. Tour. Res. 2021, 9, 234–242. [Google Scholar] [CrossRef]
- Garcia-Haro, J.M.; Oña, E.D.; Hernandez-Vicen, J.; Martinez, S.; Balaguer, C. Service Robots in Catering Applications: A Review and Future Challenges. Electronics 2020, 10, 47. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Person/Group/Society | Proposed Definition of Intelligence | Time |
|---|---|---|
| Ramon Llull | Ars Magna, intelligence emerges from learning based on mnemonic skills | 1305–1308 |
| Renè Descartes | Mind and body are separated. Intelligence in animals is unlikely | 1641 |
| Enlightenment | Rational thought (i.e., Newton’s Principia Mathematica) | 1685 |
| American Psychological Association | Intelligence can emerge in different ways, and it should be measured according to different techniques | 1892 |
| Alan Turing | Intelligence as a mechanical process. The imitation game | 1950 |
| Dartmouth manifesto | Mind as software executed in the brain | 1956 |
| Edward Feigenbaum | Capability to perform inferences on a set of rules and a knowledge base | 1965 |
| Jobin et al. | Rational behavior associated with moral principles | 2019 |
| Origin | Proposed Evaluation Criteria |
|---|---|
| Dartmouth School | Not clearly defined |
| Meta-Rationality | Hard to achieve because of the incommensurability of the different disciplines |
| IEEE Spectrum | Review classic measures (such as accuracy) in the light of baselines |
| Forbes | Data connectors, flexibility, ease-of-use, and ethics vs bias |
| GoDataDriven | Analytical capability (data, people, and technology) and business adoption (executive support, funding and implementation) |
| Kang and C. T. Haas | Qualitative criteria |
| Ish et al. | Accuracy of the classification and average time spent on the datapoint |
| Type of Theoretical Game | Example of the Game | Solution | Limitations to A Real-World Application |
|---|---|---|---|
| Perfect two-player zero-sum game | Chess (IBM’s Deep Blue) | Predict the outcome by backward induction and settle on the Nash equilibrium strategy | Most real-life interactions cannot be described as two-player zero-sum games, except one between buyers and sellers |
| Two-player zero-sum game with incomplete information (stochastic component) | Backgammon (Tesauro’s TD-Gammon) | Find a Nash equilibrium, given that the probabilities of the different outcomes can be computed | In real-life, all outcomes of uncertainty are rarely known, and, consequently, it is not possible to account for each one of them |
| Multiplayer games with imperfect information | Poker (Facebook’s Pluribus) | A subgame Nash equilibrium can be found for each turn | The results are bound to simplified turn-based interactions |
| Real-time multiplayer games with imperfect information | Dota2 (OpenAI’s OpenAI Five) | Even if the choice of the action happens simultaneously, it is still possible to find subgame Nash equilibriums | A more realistic environment with a high branching factor does not entail considering real-world challenges |
| Scenario | Concerns | Realizations |
|---|---|---|
| Soccer match | Cooperative Learning within a humans/robots scenario is hard to achieve because of violation of expectations (i.e., robots would play rationally, humans could play on an emotional basis) | RoboCup, though players are not humans yet |
| Battlefield | Lack of ethical programming could lead to casualties for both parties. Logical contradictions might occur when ethical programming is applied, due to the difficulty of differentiating human hostiles from artificial hostiles (i.e., tanks, planes) | Boston Dynamics, though some side problems (such as noise) need to be resolved |
| Restaurant | Cooperative learning relies on the confidence that humans will not be replaceable. It is necessary that teaming up with a robot should not cause frustration and not be a source of problems inside. Free riding could be likely from the human counterpart. | Robot waiters have been introduced in various locations around the world such as at Pizza Hut (https://www.businessinsider.com/pepper-robot-to-start-work-at-pizza-hut-2016-5?op=1&r=US&IR=T, accessed on 6 March 2022), Denny’s (https://thetakeout.com/dennys-robot-waiter-automation-server-replace-humans-la-1848132060, accessed on 6 March 2022), or a local restaurant in The Netherlands (https://www.theverge.com/2020/5/31/21276318/restaurant-netherlands-robot-waiters-social-distancing-pandemic, accessed on 6 March 2022). |
| Factor | Depends on |
|---|---|
| Trust | Explainability and Reliability |
| Autonomy | Responsibility, ethical behavior social awareness |
| Cooperative Learning | Reinforcement learning, possible contradictions resulting in lack of action |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barbierato, E.; Zamponi, M.E. Shifting Perspectives on AI Evaluation: The Increasing Role of Ethics in Cooperation. AI 2022, 3, 331-352. https://doi.org/10.3390/ai3020021
Barbierato E, Zamponi ME. Shifting Perspectives on AI Evaluation: The Increasing Role of Ethics in Cooperation. AI. 2022; 3(2):331-352. https://doi.org/10.3390/ai3020021
Chicago/Turabian StyleBarbierato, Enrico, and Maria Enrica Zamponi. 2022. "Shifting Perspectives on AI Evaluation: The Increasing Role of Ethics in Cooperation" AI 3, no. 2: 331-352. https://doi.org/10.3390/ai3020021