
Do Gridded Weather Datasets Provide High-Quality Data for Agroclimatic Research in Citrus Production in Brazil?
 ,
,  , ,
, ,
Abstract
:
1. Introduction
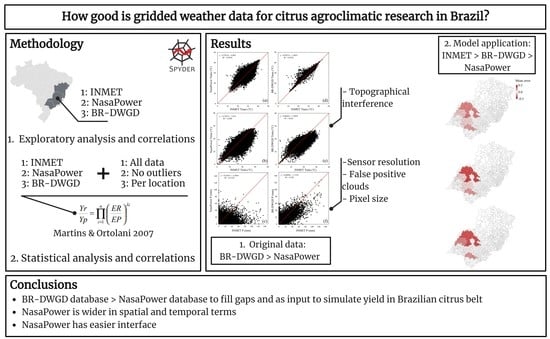
- RQ1: Do gridded data present a high correlation with in situ climatic data, allowing them to serve as a substitute or to fill potential gaps in measured data?
- RQ2: How do gridded data impact simulated sweet orange yield, using in situ data as a baseline for comparison?
1.1. Citrus Yield Prediction: Concepts and Models
1.2. In Situ and Gridded Data for Crop Yield Prediction
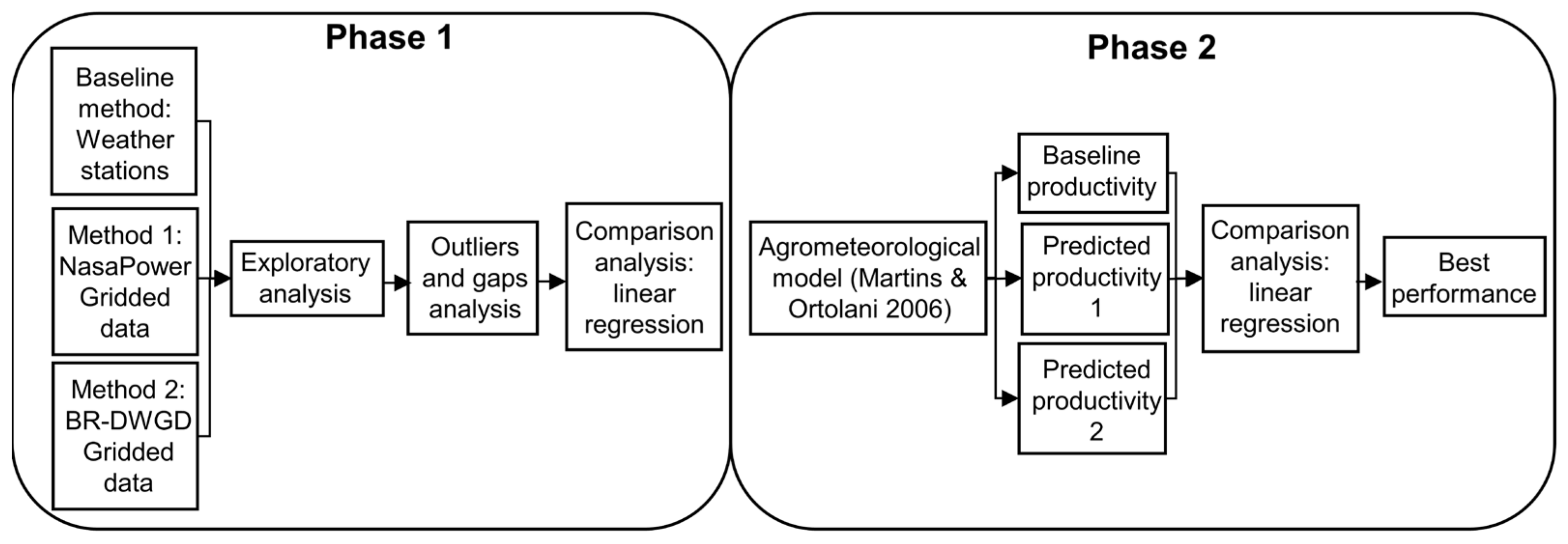
2. Materials and Methods
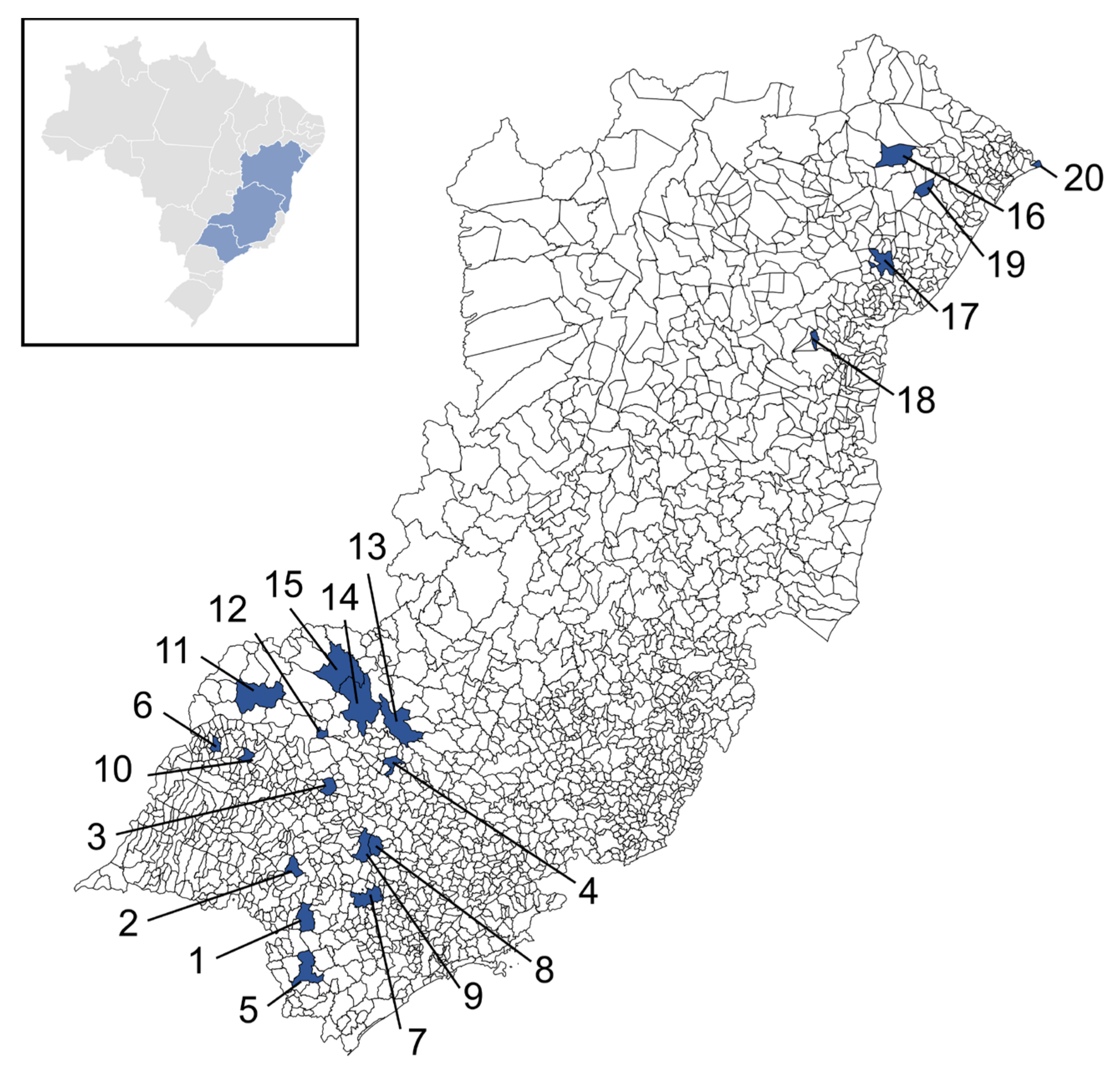
2.1. Study Area
2.2. Data Collection
2.3. Data Processing and Scenario Generation
2.4. Data Quality Analysis
2.5. Agrometeorological Model Application
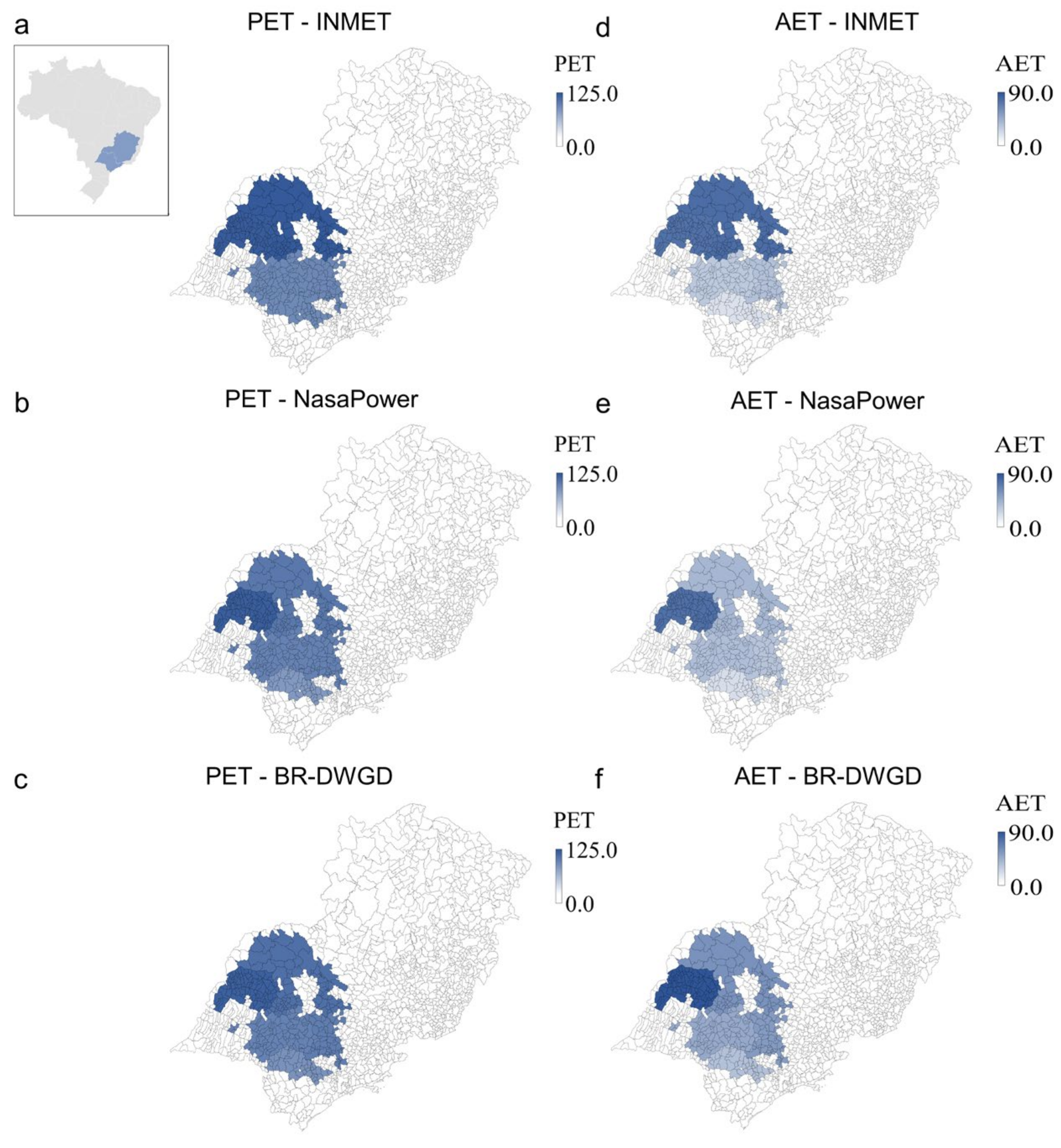
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IPCC. IPCC Summary for Policymakers. In Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of Working Group II to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Pörtner, H.-O., Roberts, D.C., Tignor, M., Poloczanska, E.S., Mintenbeck, K., Alegría, A., Craig, M., Langsdorf, S., Löschke, S., Möller, V., Okem, A., Rama, B., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2022; pp. 3–33. [Google Scholar]
- Sukumar Chakraborty, S.C.; Luck, J.; Hollaway, G.; Freeman, A.; Norton, R.; Garrett, K.A.; Percy, K.; Hopkins, A.; Davis, C.; Karnosky, D.F. Impacts of Global Change on Diseases of Agricultural Crops and Forest Trees. CABI Rev. 2008, 2008, 1–15. [Google Scholar] [CrossRef]
- Pollock, C.J. The Response of Plants to Temperature Change. J. Agric. Sci. 1990, 115, 1–5. [Google Scholar] [CrossRef]
- De Ollas, C.; Morillón, R.; Fotopoulos, V.; Puértolas, J.; Ollitrault, P.; Gómez-Cadenas, A.; Arbona, V. Facing Climate Change: Biotechnology of Iconic Mediterranean Woody Crops. Front. Plant Sci. 2019, 10, 427. [Google Scholar] [CrossRef] [PubMed]
- Vu, J.C.V. Photosynthesis, Growth, and Yield of Citrus at Elevated Atmospheric CO2. J. Crop Improv. 2005, 13, 361–376. [Google Scholar] [CrossRef]
- Morgenthaler, S. Exploratory Data Analysis. WIREs Comp. Stat. 2009, 1, 33–44. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An Introductory Review of Deep Learning for Prediction Models with Big Data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef]
- Everingham, Y.L.; Smyth, C.W.; Inman-Bamber, N.G. Ensemble Data Mining Approaches to Forecast Regional Sugarcane Crop Production. Agric. For. Meteorol. 2009, 149, 689–696. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L. Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 2019, 10, 621. [Google Scholar] [CrossRef]
- Ruß, G.; Kruse, R.; Schneider, M.; Wagner, P. Data Mining with Neural Networks for Wheat Yield Prediction. In Advances in Data Mining. Medical Applications, E-Commerce, Marketing, and Theoretical Aspects; Perner, P., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5077, pp. 47–56. ISBN 978-3-540-70717-2. [Google Scholar]
- Duarte, Y.C.N.; Sentelhas, P.C. NASA/POWER and DailyGridded Weather Datasets—How Good They Are for Estimating Maize Yields in Brazil? Int. J. Biometeorol. 2020, 64, 319–329. [Google Scholar] [CrossRef]
- Monteiro, L.A.; Sentelhas, P.C.; Pedra, G.U. Assessment of NASA/POWER Satellite-Based Weather System for Brazilian Conditions and Its Impact on Sugarcane Yield Simulation: Sugarcane yield simulation with nasa/power satellite-based data. Int. J. Clim. 2018, 38, 1571–1581. [Google Scholar] [CrossRef]
- Van Wart, J.; Grassini, P.; Yang, H.; Claessens, L.; Jarvis, A.; Cassman, K.G. Creating Long-Term Weather Data from Thin Air for Crop Simulation Modeling. Agric. For. Meteorol. 2015, 209–210, 49–58. [Google Scholar] [CrossRef]
- Wart, J.; Grassini, P.; Cassman, K.G. Impact of Derived Global Weather Data on Simulated Crop Yields. Glob. Change Biol. 2013, 19, 3822–3834. [Google Scholar] [CrossRef]
- Shepard, D. A Two-Dimensional Interpolation Function for Irregularly-Spaced Data. In Proceedings of the 1968 23rd ACM National Conference, 23–25 January 1968; pp. 517–524. [Google Scholar]
- King, A.D.; Alexander, L.V.; Donat, M.G. The Efficacy of Using Gridded Data to Examine Extreme Rainfall Characteristics: A Case Study for Australia: Gridded rainfall extremes in Australia. Int. J. Climatol. 2013, 33, 2376–2387. [Google Scholar] [CrossRef]
- Xavier, A.C.; Scanlon, B.R.; King, C.W.; Alves, A.I. New Improved Brazilian Daily Weather Gridded Data (1961–2020). Intl J. Climatol. 2022, 42, 8390–8404. [Google Scholar] [CrossRef]
- Martins, A.N.; Ortolani, A.A. Estimativa de Produção de Laranja Valência Pela Adaptação de Um Modelo Agrometeorológico. Bragantia 2006, 65, 355–361. [Google Scholar] [CrossRef]
- Ben Mechlia, N.; Carroll, J.J. Agroclimatic Modeling for the Simulation of Phenology, Yield and Quality of Crop Production. II. Citrus Model Implementation and Verification. Int. J. Biometeorol. 1989, 33, 52–65. [Google Scholar] [CrossRef]
- Moreto, V.B.; de Rolim, G.S.; Zacarin, B.G.; Vanin, A.P.; de Souza, L.M.; Latado, R.R. Agrometeorological Models for Forecasting the Qualitative Attributes of “Valência” Oranges. Theor. Appl. Climatol. 2017, 130, 847–864. [Google Scholar] [CrossRef]
- Tubelis, A.; Salibe, A.A.; Pessim, G. Relações Entre a Produção de Laranjeira ‘Westin’ e as Precipitações Em Botucatu, SP. Pesqui. Agropecuária Bras. 1999, 34, 771–779. [Google Scholar] [CrossRef]
- Tubelis, A.; Salibe, A.A. Relações Entre a Produção de Laranjeira ‘Hamlin’ Sobre Porta-Enxerto de Laranjeira ‘Caipira’ e as Precipitações Mensais No Altiplano de Botucatu, SP. Pesqui. Agropecuária Bras. 1988, 23, 239–246. [Google Scholar]
- Paulino, S.E.P.; Mourão Filho, F.d.A.A.; de Holanda Nunes Maia, A.; Avilés, T.E.C.; Dourado Neto, D. Agrometeorological Models for “Valencia” and “Hamlin” Sweet Oranges to Estimate the Number of Fruits per Plant. Sci. Agric. (Piracicaba Braz.) 2007, 64, 1–11. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A Multiscalar Drought Index Sensitive to Global Warming: The Standardized Precipitation Evapotranspiration Index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- Da Silva, R.F.; Gesualdo, G.C.; Benso, M.R.; Fava, M.C.; Mendiondo, E.M.; Saraiva, A.M.; Botazzo Delbem, A.C. A Data-Driven Framework for Identifying Productivity Zones and the Impact of Agricultural Droughts in Sugarcane Using SPI and Unsupervised Learning. In Proceedings of the 2021 IEEE International Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Trento-Bolzano, Italy, 3 November 2021; pp. 226–231. [Google Scholar]
- Camargo, M.B.P.D.; Ortolani, A.A.; Pedro Júnior, M.J.; Rosa, S.M. Modelo Agrometeorológico de Estimativa de Produtividade Para o Cultivar de Laranja Valência. Bragantia 1999, 58, 171–178. [Google Scholar] [CrossRef]
- Dourado-Neto, D.; Teruel, D.A.; Reichardt, K.; Nielsen, D.R.; Frizzone, J.A.; Bacchi, O.O.S. Principles of Crop Modeling and Simulation: I. Uses of Mathematical Models in Agricultural Science. Sci. Agric. 1998, 55, 46–50. [Google Scholar] [CrossRef]
- Pereira, F.F.S.; Sánchez-Román, R.M.; Orellana González, A.M.G. Simulation Model of the Growth of Sweet Orange (Citrus sinensis L. Osbeck) Cv. Natal in Response to Climate Change. Clim. Change 2017, 143, 101–113. [Google Scholar] [CrossRef]
- Tubiello, F.; Rosenzweig, C.; Goldberg, R.; Jagtap, S.; Jones, J. Effects of Climate Change on US Crop Production: Simulation Results Using Two Different GCM Scenarios. Part I: Wheat, Potato, Maize, and Citrus. Clim. Res. 2002, 20, 259–270. [Google Scholar] [CrossRef]
- Jensen, M.E. Water Consumption by Agricultural Plants; Chapter 1; Academic Press: Cambridge, MA, USA, 1968. [Google Scholar]
- Doorenbos, J.; Kassam, A.H. Yield Response to Water; Food and Agriculture Organization of the United Nations: Rome, Italy, 1979; p. 179. [Google Scholar]
- Fadel, R.E.S. Influência Das Condições Agrometeorológicas Na Fenologia, Qualidade e Produtividade de Tangerinas Na Região de Capão Bonito. Ph.D. Thesis, Instituto Agronômico, Campinas, Brazil, 2011. [Google Scholar]
- Fader, M.; von Bloh, W.; Shi, S.; Bondeau, A.; Cramer, W. Modelling Mediterranean Agro-Ecosystems by Including Agricultural Trees in the LPJmL Model. Geosci. Model Dev. 2015, 8, 3545–3561. [Google Scholar] [CrossRef]
- Fares, A.; Bayabil, H.K.; Zekri, M.; Mattos-Jr, D.; Awal, R. Potential Climate Change Impacts on Citrus Water Requirement across Major Producing Areas in the World. J. Water Clim. Change 2017, 8, 576–592. [Google Scholar] [CrossRef]
- Sugiura, T.; Sakamoto, D.; Koshita, Y.; Sugiura, H.; Asakura, T. Changes in Locations Suitable for Satsuma Mandarin and Tankan Cultivation Due to Global Warming in Japan. Acta Hortic. 2016, 91–94. [Google Scholar] [CrossRef]
- Zabihi, H.; Ahmad, A.; Vogeler, I.; Said, M.N.; Golmohammadi, M.; Golein, B.; Nilashi, M. Land Suitability Procedure for Sustainable Citrus Planning Using the Application of the Analytical Network Process Approach and GIS. Comput. Electron. Agric. 2015, 117, 114–126. [Google Scholar] [CrossRef]
- Ben Mechlia, N.; Carroll, J.J. Agroclimatic Modeling for the Simulation of Phenology, Yield and Quality of Crop Production. I. Citrus Response Formulation. Int. J. Biometeorol. 1989, 33, 36–51. [Google Scholar] [CrossRef]
- Bai, J.; Chen, X.; Dobermann, A.; Yang, H.; Cassman, K.G.; Zhang, F. Evaluation of NASA Satellite- and Model-Derived Weather Data for Simulation of Maize Yield Potential in China. Agron. J. 2010, 102, 9–16. [Google Scholar] [CrossRef]
- Rivington, M.; Bellocchi, G.; Matthews, K.B.; Buchan, K. Evaluation of Three Model Estimations of Solar Radiation at 24 UK Stations. Agric. For. Meteorol. 2005, 132, 228–243. [Google Scholar] [CrossRef]
- Ali, M.F.; Abdul Aziz, A.; Williams, A. Assessing Yield and Yield Stability of Hevea Clones in the Southern and Central Regions of Malaysia. Agronomy 2020, 10, 643. [Google Scholar] [CrossRef]
- Barbosa dos Santos, V.; Moreno Ferreira dos Santos, A.; da Silva Cabral de Moraes, J.R.; de Oliveira Vieira, I.C.; de Souza Rolim, G. Machine Learning Algorithms for Soybean Yield Forecasting in the Brazilian Cerrado. J. Sci. Food Agric. 2022, 102, 3665–3672. [Google Scholar] [CrossRef]
- Torsoni, G.B.; de Oliveira Aparecido, L.E.; dos Santos, G.M.; Chiquitto, A.G.; da Silva Cabral Moraes, J.R.; de Souza Rolim, G. Soybean Yield Prediction by Machine Learning and Climate. Theor. Appl. Clim. 2023, 151, 1709–1725. [Google Scholar] [CrossRef]
- Bender, F.D.; Sentelhas, P.C. Solar Radiation Models and Gridded Databases to Fill Gaps in Weather Series and to Project Climate Change in Brazil. Adv. Meteorol. 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Battisti, R.; Bender, F.D.; Sentelhas, P.C. Assessment of Different Gridded Weather Data for Soybean Yield Simulations in Brazil. Appl Clim. 2019, 135, 237–247. [Google Scholar] [CrossRef]
- Ruane, A.C.; Goldberg, R.; Chryssanthacopoulos, J. Climate Forcing Datasets for Agricultural Modeling: Merged Products for Gap-Filling and Historical Climate Series Estimation. Agric. For. Meteorol. 2015, 200, 233–248. [Google Scholar] [CrossRef]
- Yang, J.; Rahardja, S.; Fränti, P. Outlier Detection: How to Threshold Outlier Scores? In Proceedings of the International Conference on Artificial Intelligence, Information Processing and Cloud Computing, Sanya, China, 19–21 December 2019; pp. 1–6. [Google Scholar]
- Willmott, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Camargo, A.P.; Sentelhas, P.C. Avaliação Do Desempenho de Diferentes Métodos de Estimativa da Evapotranspiração Potencial No Estado de São Paulo, Brasil. Rev. Bras. Agrometeorol. 1997, 5, 89–97. [Google Scholar]
- Thornthwaite, C.W.; Mather, J.R. The Water Balance. Open J. Ecol. 2012, 2, 3. [Google Scholar]
- Mammoliti, E.; Fronzi, D.; Mancini, A.; Valigi, D.; Tazioli, A. WaterbalANce, a WebApp for Thornthwaite–Mather Water Balance Computation: Comparison of Applications in Two European Watersheds. Hydrology 2021, 8, 34. [Google Scholar] [CrossRef]
- Xavier, A.C.; King, C.W.; Scanlon, B.R. Daily Gridded Meteorological Variables in Brazil (1980–2013): Daily gridded meteorological variables in Brazil (1980–2013). Int. J. Climatol. 2016, 36, 2644–2659. [Google Scholar] [CrossRef]
- Contractor, S.; Alexander, L.V.; Donat, M.G.; Herold, N. How Well Do Gridded Datasets of Observed Daily Precipitation Compare over Australia? Adv. Meteorol. 2015, 2015, 1–15. [Google Scholar] [CrossRef]
- White, J.W.; Hoogenboom, G.; Stackhouse, P.W.; Hoell, J.M. Evaluation of NASA Satellite- and Assimilation Model-Derived Long-Term Daily Temperature Data over the Continental US. Agric. For. Meteorol. 2008, 148, 1574–1584. [Google Scholar] [CrossRef]
- AghaKouchak, A.; Behrangi, A.; Sorooshian, S.; Hsu, K.; Amitai, E. Evaluation of Satellite-Retrieved Extreme Precipitation Rates across the Central United States. J. Geophys. Res. 2011, 116, D02115. [Google Scholar] [CrossRef]
- Sylla, M.B.; Giorgi, F.; Coppola, E.; Mariotti, L. Uncertainties in Daily Rainfall over Africa: Assessment of Gridded Observation Products and Evaluation of a Regional Climate Model Simulation: Uncertainties in observed and simulated daily rainfall over africa. Int. J. Climatol. 2013, 33, 1805–1817. [Google Scholar] [CrossRef]
- Aggarwal, P.K. Uncertainties in Crop, Soil and Weather Inputs Used in Growth Models: Implications for Simulated Outputs and Their Applications. Agric. Syst. 1995, 48, 361–384. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Cultivar | Inputs | Data Source | Outputs |
|---|---|---|---|---|
| [28] | ‘Natal’ sweet orange | Tmax, Tmin, CO2 | In situ | WP (g/m2 mm) |
| [18] | ‘Valencia’ sweet orange | Tmax, Tmin, P | In situ | Yield (fruits/box) |
| [29] | ‘Valencia’ and ‘Navel’ sweet oranges | Tmax, Tmin, P, SR, W, RH | Gridded | NF and FS |
| [26] | ‘Valencia’ sweet orange | Tmax, Tmin, P | In situ | Yield (fruits/box) |
| [19,21] | ‘Valencia’ and ‘Navel’ sweet oranges | Tmax, Tmin, P, SR, W, RH | In situ | NF and FS |
| State | City/ID | Lat (°) | Long (°) | Alt (m) | Y (t/ha) | Tmax (°C) | Tmin (°C) | P (mm) |
|---|---|---|---|---|---|---|---|---|
| SP | Avaré/1 | −23.1 | −48.9 | 766 | 44.82 | 27.4 | 21.1 | 977.8 |
| Bauru/2 | −22.4 | −49.0 | 537 | 31.32 | 29.7 | 17.7 | 839.8 | |
| Bebedouro/3 | −20.9 | −48.5 | 573 | 32.38 | 31.3 | 24.5 | 1362.6 | |
| Franca/4 | −20.6 | −47.4 | 1040 | 32.38 | 28.3 | 18.5 | 1304.4 | |
| Itapeva/5 | −24.0 | −48.9 | 717 | 44.82 | 26.8 | 16.3 | 1257.6 | |
| Jales/6 | −20.2 | −50.6 | 478 | 25.69 | 31.7 | 18.8 | 694.0 | |
| Piracicaba/7 | −22.7 | −47.6 | 554 | 33.28 | 29.1 | 16.8 | 1059.2 | |
| Porto Ferreira/8 | −21.9 | −47.5 | 559 | 33.28 | 29.3 | 15.8 | 1078.2 | |
| São Carlos/9 | −22.0 | −47.9 | 856 | 31.32 | 28.0 | 16.9 | 1408.2 | |
| Votuporanga/10 | −20.4 | −50.0 | 525 | 25.69 | 32.5 | 18.9 | 1125.4 | |
| MG | Campina Verde/11 | −19.5 | −49.5 | 532 | 32.38 | 31.8 | 24.5 | 1284.8 |
| Planura/12 | −20.2 | −48.7 | 492 | 32.38 | 31.9 | 21.2 | 2522.1 | |
| Sacramento/13 | −19.9 | −47.4 | 832 | 32.38 | 29.5 | 22.5 | 1299.4 | |
| Uberaba/14 | −19.7 | −48.0 | 823 | 32.38 | 30.1 | 17.9 | 1661.6 | |
| Uberlândia/15 | −18.9 | −48.3 | 863 | 32.38 | 29.9 | 19.4 | 1260.0 | |
| BA | Euclides da Cunha/16 | −10.5 | −39.0 | 472 | 13.07 | 31.8 | 20.9 | 446.0 |
| Feira de Santana/17 | −12.2 | −39.0 | 234 | 13.07 | 31.3 | 20.5 | 736.4 | |
| Itiruçu/18 | −13.5 | −40.1 | 820 | 13.07 | 28.1 | 17.2 | 683.4 | |
| Ribeira do Amparo/19 | −11.1 | −38.4 | 186 | 13.07 | 32.9 | 20.6 | 476.2 | |
| SE | Brejo Grande/20 | −10.5 | −36.5 | 30 | 13.97 | 31.6 | 26.4 | 1040.2 |
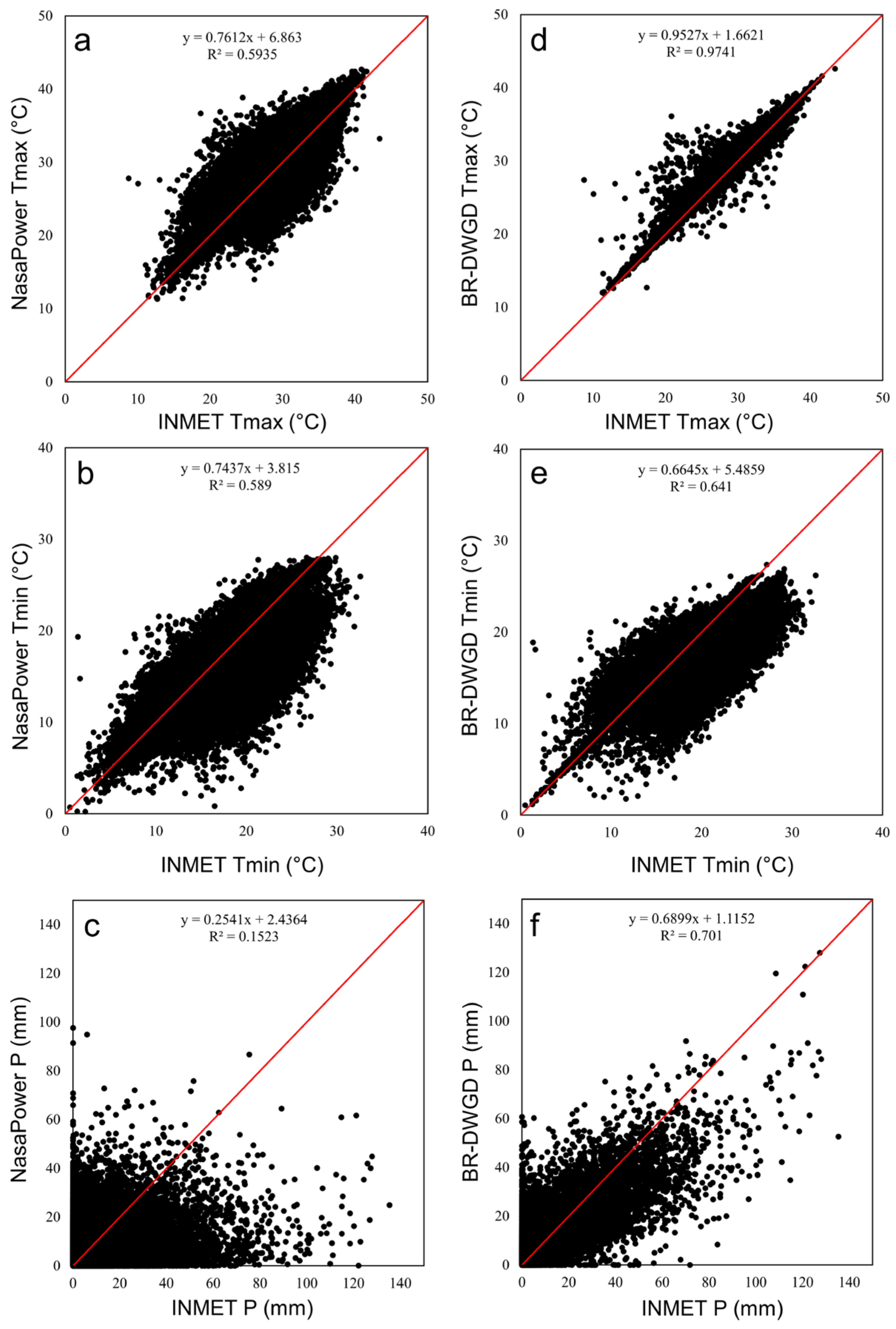
| Source | Variable | Scale | Mean (±s.d.) | C.V. | r | R2 | d | C |
|---|---|---|---|---|---|---|---|---|
| NasaPower | P | Daily | 3.3 (±6.2) | 1.88 | 0.39 | 0.15 | 0.57 | 0.22 |
| Monthly | 95.4 (±83.1) | 0.87 | 0.85 | 0.72 | 0.91 | 0.78 | ||
| Annual | 1047.7 (±384.6) | 0.37 | 0.83 | 0.68 | 0.89 | 0.74 | ||
| Tmax | Daily | 28.9 (±3.8) | 0.13 | 0.77 | 0.59 | 0.88 | 0.67 | |
| Monthly | 28.9 (±3.1) | 0.11 | 0.80 | 0.65 | 0.89 | 0.72 | ||
| Annual | 29 (±1.9) | 0.07 | 0.71 | 0.51 | 0.84 | 0.60 | ||
| Tmin | Daily | 17.9 (±3.9) | 0.21 | 0.77 | 0.59 | 0.86 | 0.66 | |
| Monthly | 17.9 (±3.5) | 0.19 | 0.80 | 0.64 | 0.87 | 0.69 | ||
| Annual | 18 (±2.4) | 0.13 | 0.69 | 0.48 | 0.79 | 0.55 | ||
| BR-DWGD | P | Daily | 3.5 (±7.9) | 2.24 | 0.84 | 0.70 | 0.90 | 0.76 |
| Monthly | 101.8 (±95.8) | 0.94 | 0.95 | 0.90 | 0.97 | 0.92 | ||
| Annual | 1121.3 (±434.4) | 0.39 | 0.94 | 0.88 | 0.97 | 0.91 | ||
| Tmax | Daily | 29.3 (±3.7) | 0.13 | 0.99 | 0.97 | 0.99 | 0.98 | |
| Monthly | 29.3 (±2.7) | 0.09 | 0.99 | 0.97 | 0.99 | 0.98 | ||
| Annual | 29.3 (±1.7) | 0.06 | 0.98 | 0.96 | 0.98 | 0.96 | ||
| Tmin | Daily | 18.1 (±3.3) | 0.18 | 0.80 | 0.64 | 0.87 | 0.70 | |
| Monthly | 18.1 (±2.8) | 0.15 | 0.77 | 0.60 | 0.85 | 0.66 | ||
| Annual | 18.2 (±1.7) | 0.09 | 0.61 | 0.37 | 0.61 | 0.44 |
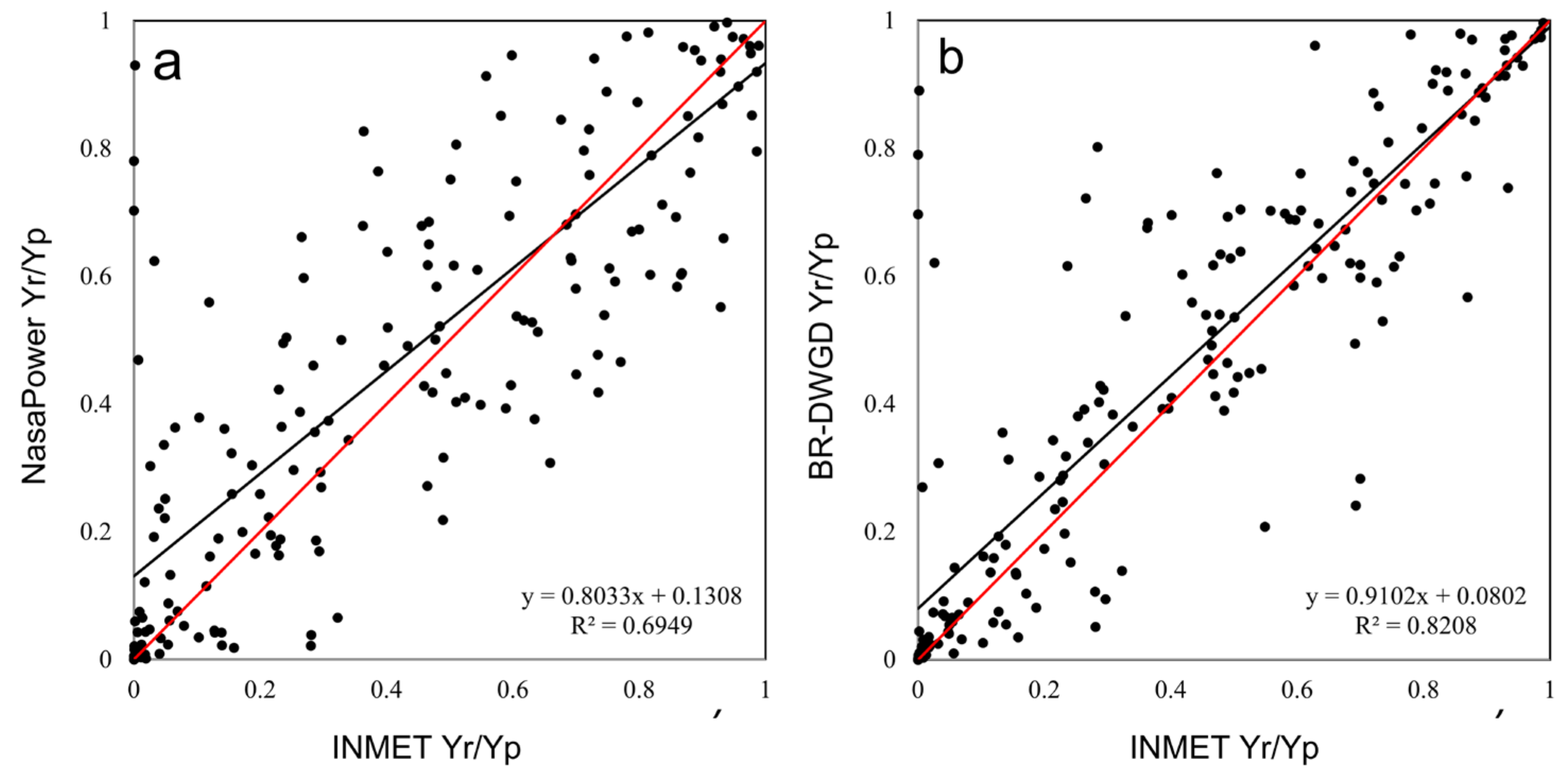
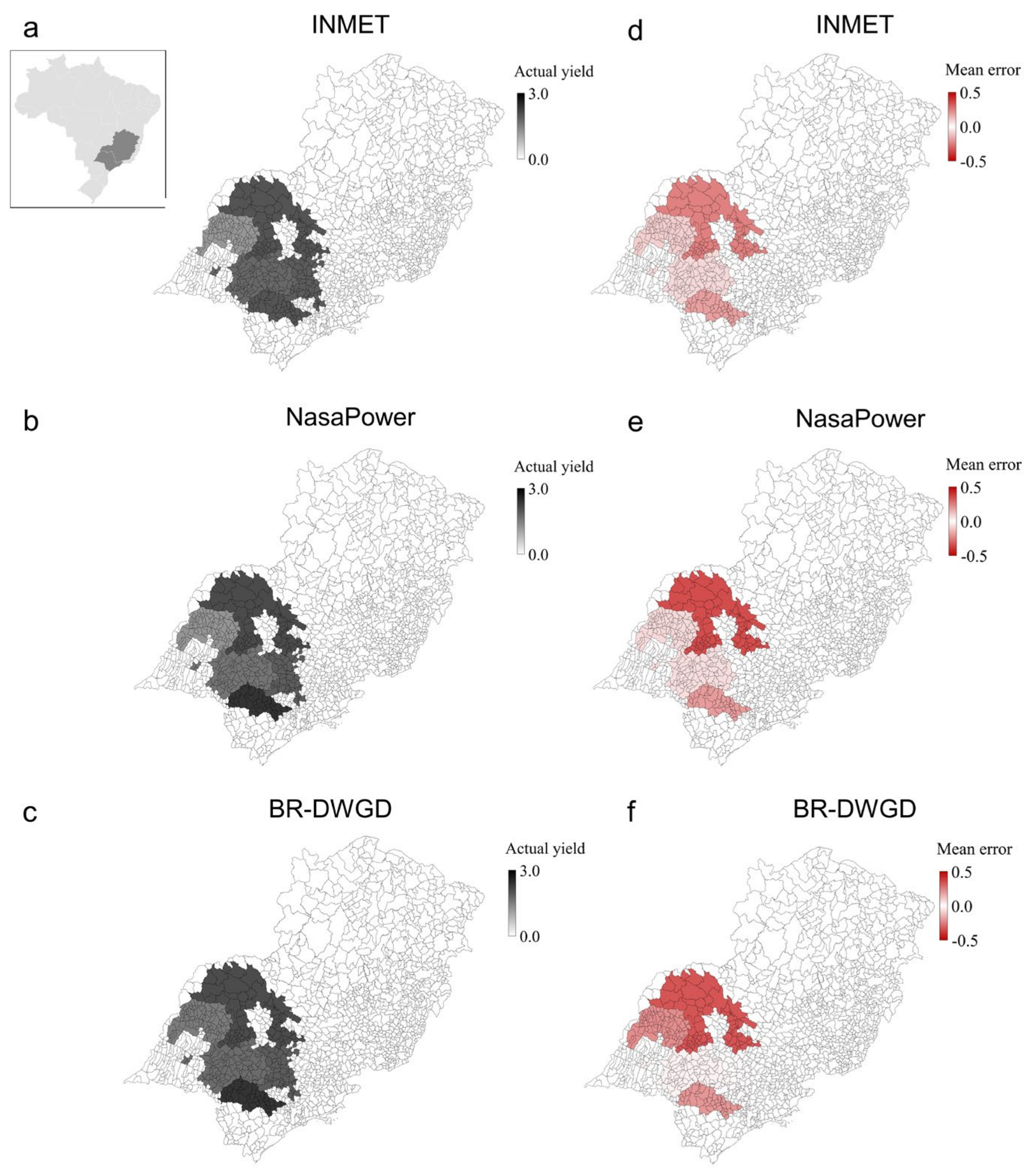
| Source | Scenario | Index | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | ME | ME (kg/Plant) | MAE | MAE (kg/Plant) | d | r | R2 | C | ||
| NasaPower | (i) All data | 0.21 | 0.03 | 9.86 | 0.15 | 43.77 | 0.91 | 0.83 | 0.69 | 0.76 |
| (ii) Outliers removed | 0.12 | 0.07 | 21.15 | 0.07 | 21.53 | 0.39 | 0.49 | 0.24 | 0.19 | |
| (iii) Separated by states—SP | 0.22 | −0.01 | −4.14 | 0.14 | 42.45 | 0.8 | 0.64 | 0.4 | 0.51 | |
| (iii) Separated by states—BA + SE | 0.21 | 0.04 | 11.46 | 0.14 | 41.55 | 0.6 | 0.37 | 0.14 | 0.22 | |
| (iii) Separated by states—MG | 0.3 | 0.15 | 43.27 | 0.24 | 71.7 | 0.77 | 0.66 | 0.43 | 0.51 | |
| BR-DWGD | (i) All data | 0.17 | 0.04 | 10.6 | 0.1 | 28.67 | 0.95 | 0.91 | 0.82 | 0.86 |
| (ii) Outliers removed | 0.03 | 0.01 | 2.61 | 0.01 | 3.96 | 0.9 | 0.84 | 0.71 | 0.76 | |
| (iii) Separated by states—SP | 0.16 | 0.05 | 15.44 | 0.09 | 27.43 | 0.89 | 0.81 | 0.66 | 0.73 | |
| (iii) Separated by states—BA + SE | 0.15 | −0.04 | −11.41 | 0.09 | 27.49 | 0.66 | 0.54 | 0.29 | 0.36 | |
| (iii) Separated by states—MG | 0.21 | 0.09 | 27.15 | 0.15 | 44.07 | 0.88 | 0.83 | 0.69 | 0.73 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasera, J.B.; Silva, R.F.d.; Piedade, S.; Mourão Filho, F.d.A.A.; Delbem, A.C.B.; Saraiva, A.M.; Sentelhas, P.C.; Marques, P.A.A. Do Gridded Weather Datasets Provide High-Quality Data for Agroclimatic Research in Citrus Production in Brazil? AgriEngineering 2023, 5, 924-940. https://doi.org/10.3390/agriengineering5020057
Rasera JB, Silva RFd, Piedade S, Mourão Filho FdAA, Delbem ACB, Saraiva AM, Sentelhas PC, Marques PAA. Do Gridded Weather Datasets Provide High-Quality Data for Agroclimatic Research in Citrus Production in Brazil? AgriEngineering. 2023; 5(2):924-940. https://doi.org/10.3390/agriengineering5020057
Chicago/Turabian StyleRasera, Júlia Boscariol, Roberto Fray da Silva, Sônia Piedade, Francisco de Assis Alves Mourão Filho, Alexandre Cláudio Botazzo Delbem, Antonio Mauro Saraiva, Paulo Cesar Sentelhas, and Patricia Angélica Alves Marques. 2023. "Do Gridded Weather Datasets Provide High-Quality Data for Agroclimatic Research in Citrus Production in Brazil?" AgriEngineering 5, no. 2: 924-940. https://doi.org/10.3390/agriengineering5020057