

A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems



Abstract
:1. Introduction
- Providing the most challenging highway videos. To make an acceptable assessment, they must cover various states of vehicles, such as occlusion, weather conditions (i.e., rainy), low- to high-quality video frames, and different resolutions and illuminations (images collected during the day and at night). Also, the videos must be recorded from diverse viewing angles with cameras installed on top of road infrastructures, in order to determine the best locations. Section 2 covers this first contribution;
- Making a comprehensive comparison between the deep learning algorithms in terms of acquiring accuracy in both vehicle detection and classification. The vehicles are categorized into the three classes of car, truck, and bus. The computation time of the algorithms is also assessed to determine which one presents a better potential usability in real-time situations. Section 3 covers this second contribution.
2. Traffic Video Data
3. Deep Learning Methodologies Applied to Vehicle Detection
- Training Data
- Region Proposals
- Feature Extraction
- Layer Selection and Classifier
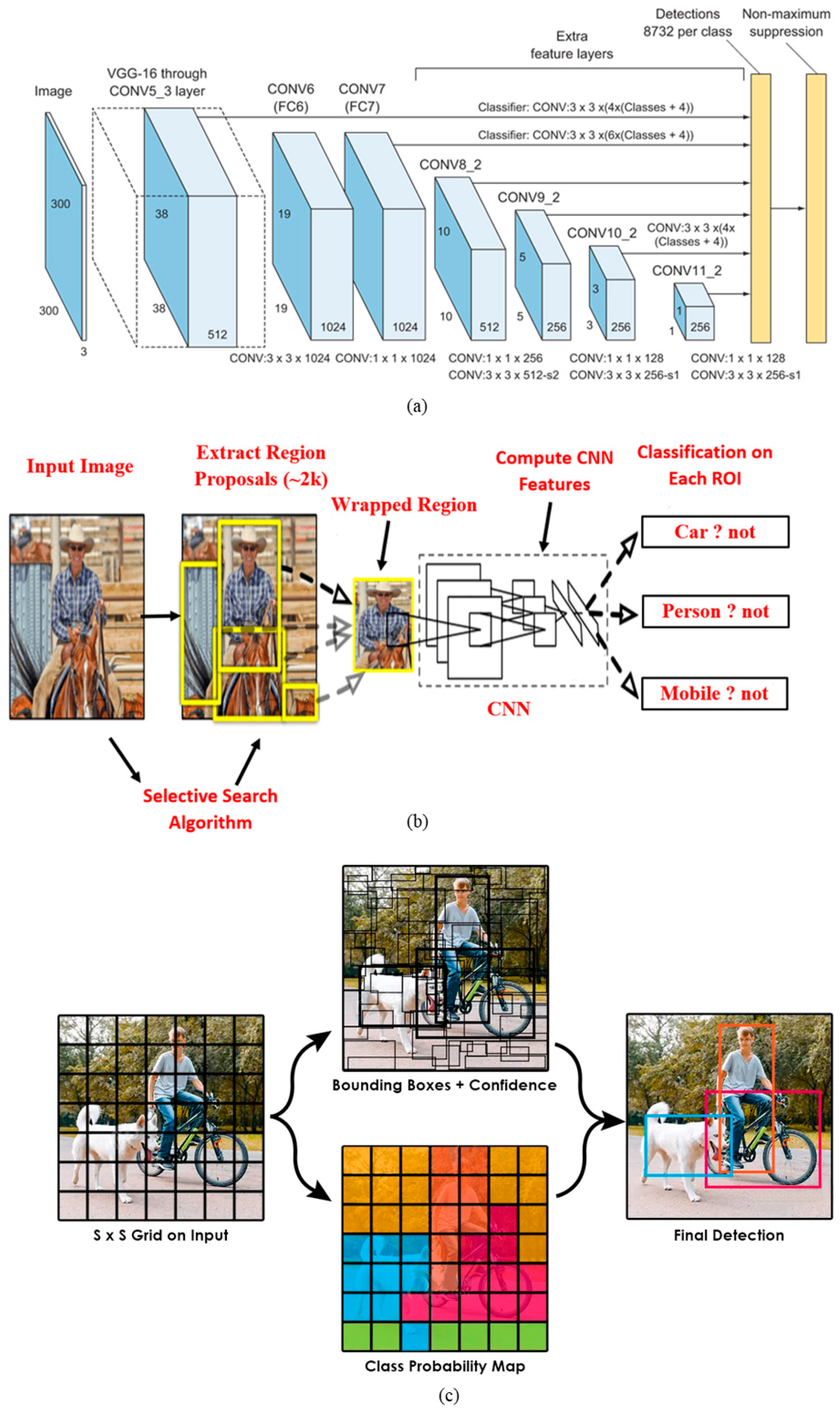
3.1. Single Shot Multi-Box Detector (SSD)
3.2. You Only Look Once (YOLO)
3.3. Region-Based Convolutional Neural Network (RCNN)
4. Experimental Results
4.1. Accuracy Evaluation
4.2. Localization Accuracy
4.3. Running Time
4.4. Vehicle Classification
5. Discussion
5.1. Datasets Challenges and Advantages
5.2. Parameters Sensitivity
5.3. Algorithms Comparison
5.4. Comparison with Previous Studies
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lv, Z.; Shang, W. Impacts of intelligent transportation systems on energy conservation and emission reduction of transport systems: A comprehensive review. Green Technol. Sustain. 2023, 1, 100002. [Google Scholar] [CrossRef]
- Pompigna, A.; Mauro, R. Smart roads: A state of the art of highways innovations in the Smart Age. Eng. Sci. Technol. Int. J. 2022, 25, 100986. [Google Scholar] [CrossRef]
- Regragui, Y.; Moussa, N. A real-time path planning for reducing vehicles traveling time in cooperative-intelligent transportation systems. Simul. Model. Pract. Theory 2023, 123, 102710. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, L.; Cai, H. A deep learning approach to secure vehicle to road side unit communications in intelligent transportation system. Comput. Electr. Eng. 2023, 105, 108542. [Google Scholar] [CrossRef]
- Zuo, J.; Dong, L.; Yang, F.; Guo, Z.; Wang, T.; Zuo, L. Energy harvesting solutions for railway transportation: A comprehensive review. Renew. Energy 2023, 202, 56–87. [Google Scholar] [CrossRef]
- Yang, Z.; Peng, J.; Wu, L.; Ma, C.; Zou, C.; Wei, N.; Zhang, Y.; Liu, Y.; Andre, M.; Li, D.; et al. Speed-guided intelligent transportation system helps achieve low-carbon and green traffic: Evidence from real-world measurements. J. Clean. Prod. 2020, 268, 122230. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Ribeiro, D.A.; Melgarejo, D.C.; Saadi, M.; Rosa, R.L.; Rodríguez, D.Z. A novel deep deterministic policy gradient model applied to intelligent transportation system security problems in 5G and 6G network scenarios. Phys. Commun. 2023, 56, 101938. [Google Scholar] [CrossRef]
- Sirohi, D.; Kumar, N.; Rana, P.S. Convolutional neural networks for 5G-enabled Intelligent Transportation System: A systematic review. Comput. Commun. 2020, 153, 459–498. [Google Scholar] [CrossRef]
- Lackner, T.; Hermann, J.; Dietrich, F.; Kuhn, C.; Angos, M.; Jooste, J.L.; Palm, D. Measurement and comparison of data rate and time delay of end-devices in licensed sub-6 GHz 5G standalone non-public networks. Procedia CIRP 2022, 107, 1132–1137. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, G.; Pan, L. Multiple-GPU accelerated high-order gas-kinetic scheme for direct numerical simulation of compressible turbulence. J. Comput. Phys. 2023, 476, 111899. [Google Scholar] [CrossRef]
- Sharma, H.; Kumar, N. Deep learning based physical layer security for terrestrial communications in 5G and beyond networks: A survey. Phys. Commun. 2023, 57, 102002. [Google Scholar] [CrossRef]
- Ounoughi, C.; Ben Yahia, S. Data fusion for ITS: A systematic literature review. Inf. Fusion 2023, 89, 267–291. [Google Scholar] [CrossRef]
- Afat, S.; Herrmann, J.; Almansour, H.; Benkert, T.; Weiland, E.; Hölldobler, T.; Nikolaou, K.; Gassenmaier, S. Acquisition time reduction of diffusion-weighted liver imaging using deep learning image reconstruction. Diagn. Interv. Imaging 2023, 104, 178–184. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Yoon, S.; Fuentes, A.; Park, D.S. A Comprehensive Survey of Image Augmentation Techniques for Deep Learning. Pattern Recognit. 2023, 137, 109347. [Google Scholar] [CrossRef]
- Zhou, Y.; Ji, A.; Zhang, L.; Xue, X. Sampling-attention deep learning network with transfer learning for large-scale urban point cloud semantic segmentation. Eng. Appl. Artif. Intell. 2023, 117, 105554. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, Z.; Li, H.; Sun, J.; Xu, Z. Meta-learning-based adversarial training for deep 3D face recognition on point clouds. Pattern Recognit. 2023, 134, 109065. [Google Scholar] [CrossRef]
- Kim, C.; Ahn, S.; Chae, K.; Hooker, J.; Rogachev, G. Noise signal identification in time projection chamber data using deep learning model. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2023, 1048, 168025. [Google Scholar] [CrossRef]
- Zhang, X.; Zhai, D.; Li, T.; Zhou, Y.; Lin, Y. Image inpainting based on deep learning: A review. Inf. Fusion 2023, 90, 74–94. [Google Scholar] [CrossRef]
- Mo, W.; Zhang, W.; Wei, H.; Cao, R.; Ke, Y.; Luo, Y. PVDet: Towards pedestrian and vehicle detection on gigapixel-level images. Eng. Appl. Artif. Intell. 2023, 118, 105705. [Google Scholar] [CrossRef]
- Bie, M.; Liu, Y.; Li, G.; Hong, J.; Li, J. Real-time vehicle detection algorithm based on a lightweight You-Only-Look-Once (YOLOv5n-L) approach. Expert Syst. Appl. 2023, 213, 119108. [Google Scholar] [CrossRef]
- Liang, Z.; Huang, Y.; Liu, Z. Efficient graph attentional network for 3D object detection from Frustum-based LiDAR point clouds. J. Vis. Commun. Image Represent. 2022, 89, 103667. [Google Scholar] [CrossRef]
- Tian, Y.; Guan, W.; Li, G.; Mehran, K.; Tian, J.; Xiang, L. A review on foreign object detection for magnetic coupling-based electric vehicle wireless charging. Green Energy Intell. Transp. 2022, 1, 100007. [Google Scholar] [CrossRef]
- Yang, Z.; Pun-Cheng, L.S. Vehicle detection in intelligent transportation systems and its applications under varying environments: A review. Image Vis. Comput. 2018, 69, 143–154. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Zhang, Y. Review of pixel-level remote sensing image fusion based on deep learning. Inf. Fusion 2023, 90, 36–58. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision and Pattern Recogniti; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Ramachandran, A.; Sangaiah, A.K. A review on object detection in unmanned aerial vehicle surveillance. Int. J. Cogn. Comput. Eng. 2021, 2, 215–228. [Google Scholar] [CrossRef]
- Kim, J.A.; Sung, J.Y.; Park, S.H. Comparison of Faster-RCNN, YOLO, and SSD for Real-Time Vehicle Type Recognition. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics—Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020. [Google Scholar]
- Qiu, Q.; Lau, D. Real-time detection of cracks in tiled sidewalks using YOLO-based method applied to unmanned aerial vehicle (UAV) images. Autom. Constr. 2023, 147, 104745. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural Greenhouses Detection in High-Resolution Satellite Images Based on Convolutional Neural Networks: Comparison of Faster R-CNN, YOLO v3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef] [PubMed]
- Azimjonov, J.; Özmen, A. A real-time vehicle detection and a novel vehicle tracking systems for estimating and monitoring traffic flow on highways. Adv. Eng. Inform. 2021, 50, 101393. [Google Scholar] [CrossRef]
- Han, X.; Chang, J.; Wang, K. Real-time object detection based on YOLO-v2 for tiny vehicle object. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar] [CrossRef]
- Tao, C.; He, H.; Xu, F.; Cao, J. Stereo priori RCNN based car detection on point level for autonomous driving. Knowl. -Based Syst. 2021, 229, 107346. [Google Scholar] [CrossRef]
- Zhang, Q.; Hu, X.; Yue, Y.; Gu, Y.; Sun, Y. Multi-object detection at night for traffic investigations based on improved SSD framework. Heliyon 2022, 8, e11570. [Google Scholar] [CrossRef]
- Shawon, A. Road Traffic Video Monitoring. 2020. Available online: https://www.kaggle.com/datasets/shawon10/road-traffic-video-monitoring?select=traffic_detection.mp4 (accessed on 1 January 2021).
- Shah, A. Highway Traffic Videos Dataset. 2020. Available online: https://www.kaggle.com/datasets/aryashah2k/highway-traffic-videos-dataset (accessed on 1 March 2020).
- Saha, S. A Comprehensive Guide to Convolutional Neural Networks—The ELI5 Way. 2018. Available online: https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53 (accessed on 15 December 2018).
- Ding, J.; Li, X.; Kang, X.; Gudivada, V.N. Augmentation and evaluation of training data for deep learning. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017. [Google Scholar]
- Phuong, T.M.; Diep, N.N. Speeding Up Convolutional Object Detection for Traffic Surveillance Videos. In Proceedings of the 2018 10th International Conference on Knowledge and Systems Engineering (KSE), Ho Chi Minh City, Vietnam, 1–3 November 2018. [Google Scholar]
- Tian, Y.; Su, D.; Lauria, S.; Liu, X. Recent advances on loss functions in deep learning for computer vision. Neurocomputing 2022, 497, 129–158. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Yolov5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 July 2020).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Chen, X.; Gupta, A. An implementation of faster rcnn with study for region sampling. arXiv 2017, arXiv:1702.02138. [Google Scholar]
- Powers, D.M. Evaluation: From precision, Recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Vostrikov, A.; Chernyshev, S. Training sample generation software. In Intelligent Decision Technologies 2019, Proceedings of the 11th KES International Conference on Intelligent Decision Technologies (KES-IDT 2019), St. Julians, Malta, 17–19 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 2. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Bathija, A.; Sharma, G. Visual object detection and tracking using Yolo and sort. Int. J. Eng. Res. Technol. 2019, 8, 705–708. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Real-Time Vehicle Classification and Tracking Using a Transfer Learning-Improved Deep Learning Network. Sensors 2022, 22, 3813. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Day/Night | Frames | FPS | Height | Width | Rear/Front | Quality | Angle of View (AoV) | Link (accessed on 12 September 2023) |
|---|---|---|---|---|---|---|---|---|---|
| Dataset I | Both | 2250 | 15 | 352 | 240 | Both | Low | Vertical-Low-High | https://www.quebec511.info/fr/Carte/Default.aspx |
| Dataset II | Day | 1525 | 25 | 1364 | 768 | Both | Medium | Low | https://www.kaggle.com/datasets/shawon10/road-traffic-video-monitoring |
| Dataset III | Day | 250 | 10 | 320 | 240 | Rear | Low | Vertical | https://www.kaggle.com/datasets/aryashah2k/highway-traffic-videos-dataset |
| Dataset IV | Night | 61,840 | 30 | 1280 | 720 | Both | Very High | Vertical | https://www.youtube.com/watch?v=xEtM1I1Afhc |
| Dataset V | Night | 178,125 | 25 | 1280 | 720 | Both | Low | Vertical | https://www.youtube.com/watch?v=iA0Tgng9v9U |
| Dataset VI | Day | 62,727 | 30 | 854 | 480 | Rear | Medium | Vertical | https://youtu.be/QuUxHIVUoaY |
| Dataset VII | Day | 9180 | 30 | 1920 | 1080 | Front | Very High | Low | https://www.youtube.com/watch?v=MNn9qKG2UFI&t=7s |
| Dataset VIII | Day | 107,922 | 30 | 1280 | 720 | Front | High | High | https://youtu.be/TW3EH4cnFZo |
| Dataset IX | Day | 1525 | 25 | 1280 | 720 | Both | High | Vertical | https://www.youtube.com/watch?v=wqctLW0Hb_0&t=10s |
| Yolov8 | Yolov7 | Yolov6 | Yolov5 | Faster RCNN | SSD | ||
|---|---|---|---|---|---|---|---|
| Dataset I | Precision | 43.03 | 96.33 | 48.96 | 54.98 | 2.00< | 2.00< |
| Recall | 55.41 | 100.00 | 78.39 | 65.40 | 2.00< | 2.00< | |
| F1-score | 48.44 | 98.13 | 60.27 | 59.74 | 2.00< | 2.00< | |
| Dataset II | Precision | 99.38 | 100.00 | 100.00 | 100.00 | 92.49 | 2.00< |
| Recall | 100.00 | 100.00 | 96.78 | 99.11 | 100.00 | 2.00< | |
| F1-score | 99.69 | 100.00 | 98.36 | 99.55 | 96.10 | 2.00< | |
| Dataset III | Precision | 87.84 | 97.36 | 98.25 | 96.74 | 2.00< | 2.00< |
| Recall | 83.56 | 100.00 | 99.69 | 100.00 | 2.00< | 2.00< | |
| F1-score | 85.65 | 98.66 | 98.96 | 98.34 | 2.00< | 2.00< | |
| Dataset IV | Precision | 98.42 | 100.00 | 100.00 | 100.00 | 37.24 | 2.00< |
| Recall | 99.68 | 99.47 | 96.54 | 96.55 | 98.44 | 2.00< | |
| F1-score | 99.05 | 99.73 | 98.24 | 98.24 | 54.04 | 2.00< | |
| Dataset V | Precision | 96.33 | 97.77 | 95.87 | 94.38 | 2.00< | 2.00< |
| Recall | 97.96 | 98.69 | 93.14 | 96.73 | 2.00< | 2.00< | |
| F1-score | 97.14 | 98.23 | 94.49 | 95.54 | 2.00< | 2.00< | |
| Dataset VI | Precision | 100.00 | 100.00 | 99.18 | 100.00 | 88.92 | 2.00< |
| Recall | 96.57 | 99.98 | 100.00 | 99.23 | 100.00 | 2.00< | |
| F1-score | 98.26 | 99.99 | 99.59 | 99.61 | 94.14 | 2.00< | |
| Dataset VII | Precision | 99.82 | 99.85 | 98.67 | 100.00 | 97.57 | 2.00< |
| Recall | 78.36 | 86.14 | 80.22 | 85.64 | 98.61 | 2.00< | |
| F1-score | 87.80 | 92.49 | 88.49 | 92.26 | 98.09 | 2.00< | |
| Dataset VIII | Precision | 96.28 | 99.43 | 97.65 | 99.44 | 96.73 | 2.00< |
| Recall | 56.47 | 100.00 | 80.25 | 97.82 | 99.37 | 2.00< | |
| F1-score | 71.19 | 99.71 | 88.10 | 98.62 | 98.03 | 2.00< | |
| Dataset IX | Precision | 100.00 | 98.23 | 98.00 | 99.11 | 73.29 | 2.00< |
| Recall | 93.66 | 98.37 | 84.36 | 99.86 | 85.37 | 2.00< | |
| F1-score | 96.73 | 98.30 | 91.52 | 99.48 | 78.87 | 2.00< | |
| Average | Precision | 91.23 | 98.77 | 92.95 | 93.85 | 54.69 | 2.00< |
| Recall | 84.63 | 98.07 | 89.93 | 93.37 | 65.31 | 2.00< | |
| F1-score | 87.10 | 98.42 | 91.42 | 93.61 | 58.36 | 2.00< |
| Actual | |||||
|---|---|---|---|---|---|
| Car | Truck | Bus | Commission Error | ||
| Predicted | Car | ||||
| Truck | |||||
| Bus | |||||
| Omission Error | Overall Accuracy | ||||
| Yolov8 | Yolov7 | Yolov6 | Yolov5 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Car | Truck | Bus | Car | Truck | Bus | Car | Truck | Bus | Car | Truck | Bus | ||||||
| Car | 115 | 12 | 0 | 9.45 | 255 | 3 | 0 | 1.16 | 131 | 6 | 0 | 4.38 | 144 | 6 | 0 | 4.00 | |
| Dataset I | Truck | 3 | 14 | 0 | 17.65 | 7 | 29 | 0 | 19.44 | 3 | 22 | 0 | 12.00 | 12 | 17 | 0 | 41.38 |
| Bus | 0 | 0 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 3 | 0 | N/A | |
| 2.54 | 46.15 | N/A | 88.97 | 2.67 | 9.38 | N/A | 96.60 | 2.24 | 21.43 | N/A | 94.44 | 7.69 | 34.62 | N/A | 89.94 | ||
| Car | 63 | 0 | 0 | 0.00 | 63 | 0 | 0 | 0.00 | 62 | 3 | 0 | 4.62 | 60 | 0 | 0 | 0.00 | |
| Dataset II | Truck | 0 | 10 | 0 | 0.00 | 0 | 11 | 0 | 0.00 | 1 | 8 | 0 | 11.11 | 3 | 11 | 0 | 21.43 |
| Bus | 0 | 1 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 0 | 0 | N/A | |
| d | 0.00 | 9.09 | N/A | 98.65 | 0.00 | 0.00 | N/A | 100.00 | 1.59 | 27.27 | N/A | 94.59 | 4.76 | 0.00 | N/A | 95.95 | |
| Car | 50 | 4 | 0 | 7.41 | 59 | 1 | 0 | 1.67 | 51 | 4 | 0 | 7.27 | 49 | 6 | 0 | 10.91 | |
| Dataset III | Truck | 2 | 10 | 0 | 16.67 | 2 | 11 | 0 | 15.38 | 3 | 11 | 0 | 21.43 | 1 | 12 | 0 | 7.69 |
| Bus | 2 | 3 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 1 | 0 | N/A | 3 | 4 | 0 | N/A | |
| 7.41 | 41.18 | N/A | 84.51 | 3.28 | 8.33 | N/A | 95.89 | 5.56 | 26.67 | N/A | 88.57 | 7.55 | 45.45 | N/A | 81.33 | ||
| Car | 1405 | 66 | 17 | 5.58 | 1402 | 55 | 7 | 4.23 | 1410 | 62 | 14 | 5.11 | 1408 | 60 | 6 | 4.48 | |
| Dataset IV | Truck | 9 | 264 | 16 | 8.65 | 12 | 284 | 11 | 7.49 | 6 | 276 | 15 | 7.07 | 8 | 272 | 18 | 8.72 |
| Bus | 0 | 18 | 27 | 40.00 | 0 | 9 | 42 | 17.65 | 0 | 10 | 31 | 24.39 | 0 | 16 | 36 | 30.77 | |
| 0.64 | 23.26 | 55.00 | 93.08 | 0.85 | 18.39 | 30.00 | 94.84 | 0.42 | 20.69 | 48.33 | 94.13 | 0.56 | 21.84 | 40.00 | 94.08 | ||
| Car | 2758 | 2 | 1 | 0.11 | 2758 | 2 | 0 | 0.07 | 2758 | 3 | 0 | 0.11 | 1750 | 2 | 0 | 0.11 | |
| Dataset V | Truck | 0 | 6 | 1 | 14.29 | 0 | 6 | 1 | 14.29 | 0 | 5 | 2 | 28.57 | 6 | 6 | 1 | 14.29 |
| Bus | 0 | 0 | 3 | 0.00 | 0 | 0 | 4 | 0.00 | 0 | 0 | 3 | 0.00 | 0 | 0 | 4 | 0.00 | |
| 0.00 | 25.00 | 40.00 | 99.86 | 0.00 | 20.00 | 20.00 | 99.89 | 0.00 | 37.50 | 40.00 | 99.82 | 0.34 | 25.00 | 20.00 | 99.49 | ||
| Car | 494 | 13 | 0 | 2.56 | 503 | 11 | 0 | 2.14 | 496 | 13 | 0 | 2.55 | 481 | 16 | 0 | 3.22 | |
| Dataset VI | Truck | 44 | 72 | 0 | 37.93 | 35 | 76 | 0 | 31.53 | 39 | 69 | 0 | 36.11 | 57 | 71 | 0 | 44.53 |
| Bus | 0 | 9 | 5 | 64.29 | 0 | 7 | 5 | 58.33 | 0 | 10 | 5 | 66.67 | 0 | 7 | 5 | 58.33 | |
| 8.18 | 23.40 | 0.00 | 89.64 | 6.51 | 19.15 | 0.00 | 91.68 | 7.29 | 25.00 | 0.00 | 90.19 | 10.59 | 24.47 | 0.00 | 87.44 | ||
| Car | 183 | 13 | 0 | 6.63 | 282 | 3 | 0 | 1.05 | 237 | 6 | 0 | 2.47 | 245 | 6 | 0 | 2.39 | |
| Dataset VII | Truck | 17 | 29 | 0 | 36.96 | 5 | 61 | 0 | 7.58 | 11 | 50 | 0 | 18.03 | 13 | 48 | 0 | 21.31 |
| Bus | 87 | 23 | 4 | 3.51 | 0 | 1 | 4 | 20.00 | 39 | 9 | 4 | 7.69 | 29 | 11 | 4 | 90.91 | |
| 36.24 | 55.38 | 0.00 | 60.67 | 1.74 | 4.69 | 0.00 | 97.47 | 17.42 | 23.08 | 0.00 | 91.80 | 14.63 | 26.15 | 0.00 | 90.83 | ||
| Car | 438 | 20 | 0 | 4.37 | 438 | 0 | 0 | 0.00 | 438 | 0 | 0 | 0.00 | 438 | 0 | 0 | 0.00 | |
| Dataset VIII | Truck | 0 | 58 | 0 | 0.00 | 0 | 268 | 0 | 0.00 | 0 | 263 | 0 | 0.00 | 0 | 266 | 0 | 0.00 |
| Bus | 0 | 214 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 5 | 0 | N/A | 0 | 2 | 0 | N/A | |
| 0.00 | 79.86 | N/A | 67.95 | 0.00 | 0.00 | N/A | 100.00 | 0.00 | 1.87 | N/A | 99.29 | 0.00 | 0.75 | N/A | 99.72 | ||
| Car | 149 | 2 | 0 | 1.32 | 152 | 0 | 0 | 0.00 | 151 | 7 | 0 | 4.43 | 150 | 8 | 0 | 5.06 | |
| Dataset IX | Truck | 3 | 14 | 0 | 17.65 | 0 | 19 | 0 | 0.00 | 1 | 12 | 0 | 7.69 | 2 | 9 | 0 | 18.18 |
| Bus | 0 | 3 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 0 | 0 | N/A | 0 | 2 | 0 | N/A | |
| 1.97 | 26.32 | N/A | 95.32 | 0.00 | 0.00 | N/A | 100.00 | 0.66 | 36.84 | N/A | 95.32 | 1.32 | 52.63 | N/A | 92.98 |
| Model | Size (Pixels) | mAPval | Speed CPU ONNX | Speed A100 Tensor RT | Params (M) | FLOPs |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 | 68.2 | 257.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shokri, D.; Larouche, C.; Homayouni, S. A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems. Smart Cities 2023, 6, 2982-3004. https://doi.org/10.3390/smartcities6050134
Shokri D, Larouche C, Homayouni S. A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems. Smart Cities. 2023; 6(5):2982-3004. https://doi.org/10.3390/smartcities6050134
Chicago/Turabian StyleShokri, Danesh, Christian Larouche, and Saeid Homayouni. 2023. "A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems" Smart Cities 6, no. 5: 2982-3004. https://doi.org/10.3390/smartcities6050134