
Primer on Reproducible Research in R: Enhancing Transparency and Scientific Rigor
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Reproducible Research
1.2. Reprodicibility in Sleep and Chronobiology Research
1.3. Reproducible Research and R
2. A Tutorial on Reproducible Research
2.1. Installing the Software
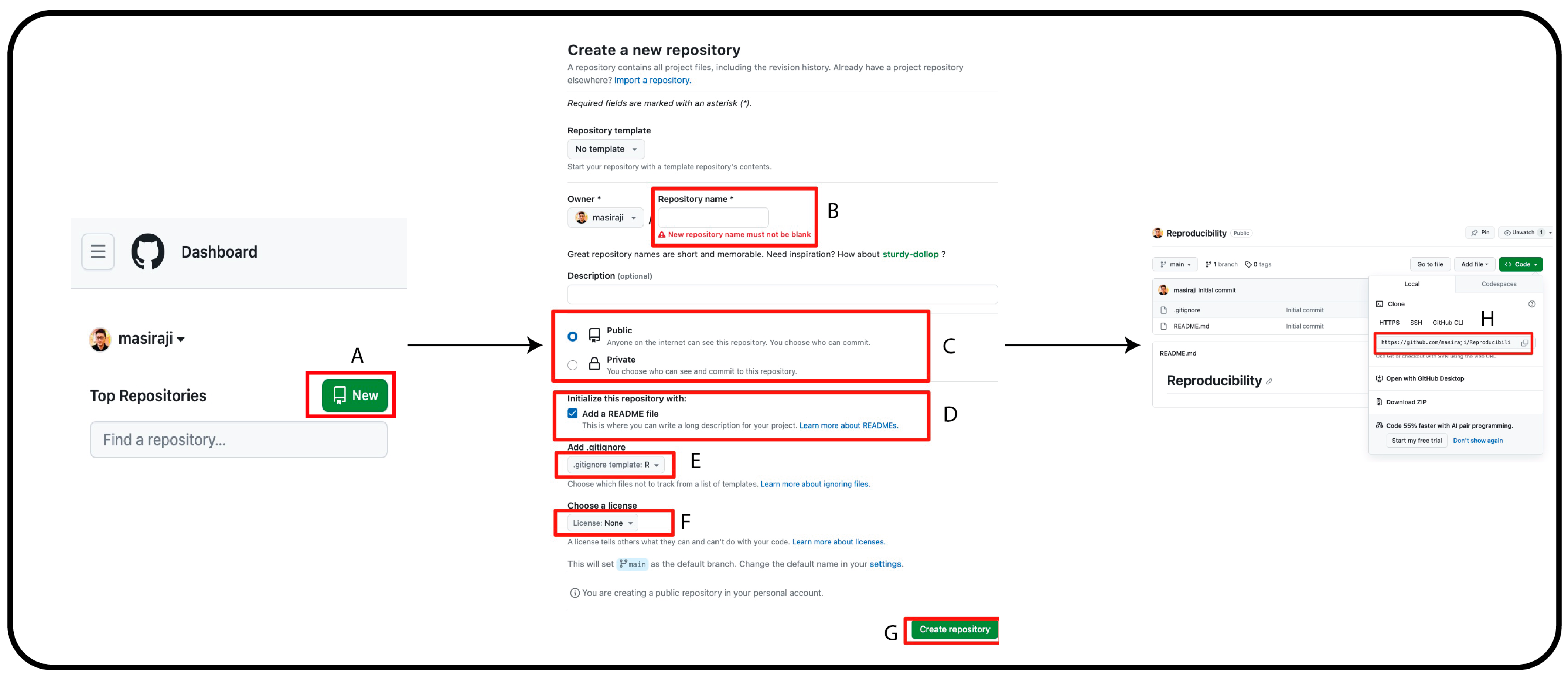
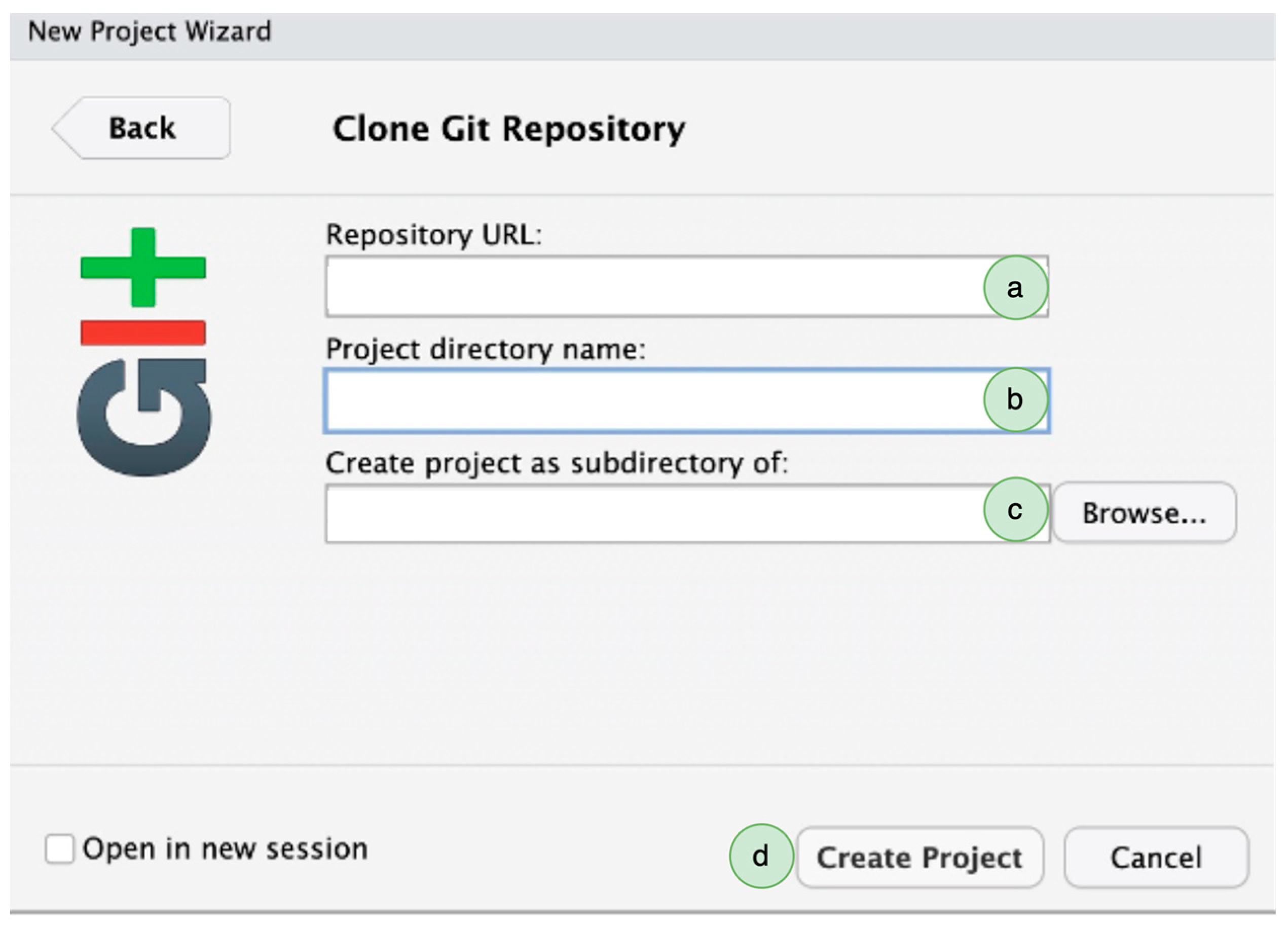
2.2. Version Control
- We open our local project by opening the file that has an “.Rproj” extension. By doing so, our project will open in the RStudio.
- Before introducing any changes, we click on the Git tab in RStudio and click on “pull” to synchronize our local database to the online database.
- Once our local repository is synced, we start working on our local files, commit the changes and click “pull” to get the latest changes made in the repository (if any). Lastly, push your changes to the online repository to synchronize.
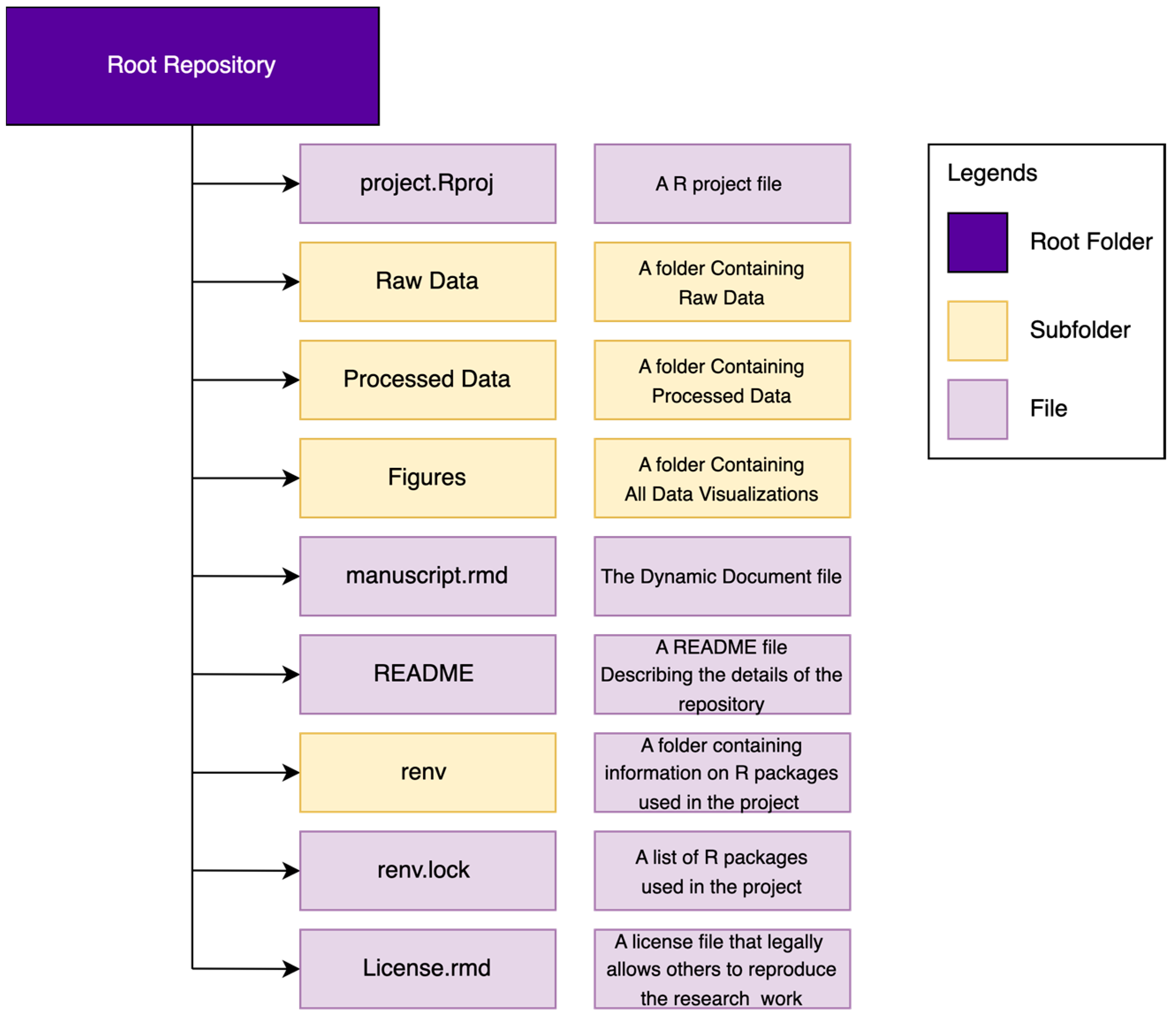
2.3. Creating a Dynamic Document
- Always create a chunk containing all R packages and dependencies used in the analysis and reported in the dynamic document.
- Clearly document the sources of data, including file names, URLs, or database connections. Provide details about data preprocessing steps, transformations, and any modifications applied.
- While coding, practice a reproducible coding style with relevant comments and descriptions of each code chunk. Remember to set seed values for random number generation and capture the session information, including the R version, package versions, and system details, at the beginning of the document.
2.4. Managing R Packages Dependencies
- renv can be installed by running install.packages(“renv”) in the RStudio console.
- To enable renv-based package dependency, navigate towards the project folder in the local computer and open the R project file with an “.Rporj” extension. Once the project is open in RStudio, run renv::init() and initiate renv. This will create a new renv folder in your project directory.
- To make a record of your current status, i.e., the R version, the packages used and the corresponding version number, run renv::snapshot() in the console. This will take a snapshot of the current status of the R environment and create a renv.lock file in the project directory, which lists the packages and their specific versions used in the project.
- Once the renv.lock file is created, remember to update it whenever a new package is added or existing packages are updated within the project. To do this, simply run the renv::snapshot() command. This ensures that the renv.lock file accurately reflects the current state of the project’s package dependencies.
- Make sure the GitHub online project repository contains the updated renv folder and renv.lock file.
- To recreate the project environment on another system or to revert to a previous state, run renv::restore() in the R console. This will install the packages specified in the renv.lock file.
2.5. Sharing the Reproducible Work
2.6. Reproducible Research: Sleep and Chronobiology
- Pre-registration: Pre-registration of research work involves making research goals, theories, and analysis procedures available to the public before data collection. This practice encourages openness, reduces bias, and prevents selective reporting, ultimately facilitating reproducibility. The Open Science Framework (OSF) is a collaborative research management platform that supports open and reproducible scientific practices. With its pre-registration tool, researchers can publicly document their research plans, hypotheses, and analysis protocols prior to conducting the study, ensuring transparency and minimizing biases.
- Standardized Assessment Methods: Using and developing standardized assessment methods for evaluating the parameters of sleep and chronobiology is essential. Utilizing standardized tools and methods helps with reproducibility and assures comparability between investigations.
- Providing a Detailed Study Protocol: For sleep and chronobiology research to be reproducible, it is crucial to provide complete descriptions of the research protocols. This includes thorough documentation of inclusion–exclusion criteria, the methods used to collect the data (such as actigraphy and polysomnography), the actions involved in data preprocessing and the demographics of the participants. Tir and White [35] provide a detailed guideline on how to report the demographics of the participants in sleep and chronobiology experiments. Special attention should be given if the research is involved with light exposure. For a detailed guideline on how to report on light exposure in human sleep and chronobiology experiments, please see the work of Spitschan and Stefani [36].
- Open Access to Datasets: Using open access procedures for disseminating sleep and chronobiology data encourages reproducibility. By making anonymized data accessible, other researchers are able to confirm results, carry out their own analyses, and consider new lines of inquiry. Utilizing repositories such as GitHub or the Open Science Framework (OSF) for publicly storing data promotes field-wide transparency, collaboration and reproducibility.
- Sharing Sleep Monitoring Tools and Algorithms: Researchers should disclose details regarding the hardware configurations and data processing methods of the monitoring devices they utilized in their studies to improve repeatability. Guaranteeing the consistency and reproducibility of results makes it possible for others to reproduce data collection procedures and use comparative analysis approaches.
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, R.D. Reproducible research and Biostatistics. Biostatistics 2009, 10, 405–408. [Google Scholar] [CrossRef] [PubMed]
- Gandrud, C. Reproducible Research with R and RStudio, 3rd ed.; Chapman and Hall; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Mesirov, J.P. Accessible reproducible research. Science 2010, 327, 415–416. [Google Scholar] [CrossRef] [PubMed]
- Donoho, D.L. An invitation to reproducible computational research. Biostatistics 2010, 11, 385–388. [Google Scholar] [CrossRef] [PubMed]
- Hardwicke, T.E.; Mathur, M.B.; MacDonald, K.; Nilsonne, G.; Banks, G.C.; Kidwell, M.C.; Hofelich Mohr, A.; Clayton, E.; Yoon, E.J.; Henry Tessler, M. Data availability, reusability, and analytic reproducibility: Evaluating the impact of a mandatory open data policy at the journal Cognition. R. Soc. Open Sci. 2018, 5, 180448. [Google Scholar] [CrossRef] [PubMed]
- Obels, P.; Lakens, D.; Coles, N.A.; Gottfried, J.; Green, S.A. Analysis of open data and computational reproducibility in registered reports in psychology. Adv. Methods Pract. Psychol. Sci. 2020, 3, 229–237. [Google Scholar] [CrossRef]
- Bacon, R. Opera Quædam Hactenus Inedita. v. 1; Longman, Green, Longman, and Roberts: London, UK; Cambridge Library Collection-Rolls, Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Braude, S.E. ESP and Psychokinesis: A Philosophical Examination; Universal-Publishers: Irvine, CA, USA, 2002. [Google Scholar]
- Stodden, V. The Legal Framework for Reproducible Scientific Research. Comput. Sci. Eng. 2009, 11, 35–40. [Google Scholar] [CrossRef]
- Makel, M.C.; Plucker, J.A. Facts are more important than novelty: Replication in the education sciences. Educ. Res. 2014, 43, 304–316. [Google Scholar] [CrossRef]
- Schmidt, S. Shall we really do it again? The powerful concept of replication is neglected in the social sciences. Rev. Gen. Psychol. 2009, 13, 90–100. [Google Scholar] [CrossRef]
- Ball, R.; Medeiros, N. Teaching integrity in empirical research: A protocol for documenting data management and analysis. J. Econ. Educ. 2012, 43, 182–189. [Google Scholar] [CrossRef]
- Vandewalle, P. Code sharing is associated with research impact in image processing. Comput. Sci. Eng. 2012, 14, 42–47. [Google Scholar] [CrossRef]
- Piwowar, H.A.; Day, R.S.; Fridsma, D.B. Sharing detailed research data is associated with increased citation rate. PLoS ONE 2007, 2, e308. [Google Scholar] [CrossRef] [PubMed]
- Siraji, M.; Kalavally, V.; Schaefer, A.; Haque, S. Effects of Daytime Electric Light Exposure on Human Alertness and Higher Cognitive Functions: A Systematic Review. Front. Psychol. 2022, 12, 765750. [Google Scholar] [CrossRef]
- Schöllhorn, I.; Stefani, O.; Blume, C.; Cajochen, C. Seasonal Variation in the Responsiveness of the Melanopsin System to Evening Light: Why We Should Report Season When Collecting Data in Human Sleep and Circadian Studies. Clocks Sleep 2023, 5, 651–666. [Google Scholar] [CrossRef] [PubMed]
- Grant, L.K.; Kent, B.A.; Mayer, M.D.; Stickgold, R.; Lockley, S.W.; Rahman, S.A. Daytime Exposure to Short Wavelength-Enriched Light Improves Cognitive Performance in Sleep-Restricted College-Aged Adults. Front. Neurol. 2021, 12, 624217. [Google Scholar] [CrossRef]
- Lok, R.; Joyce, D.S.; Zeitzer, J.M. Impact of daytime spectral tuning on cognitive function. J. Photochem. Photobiol. B Biol. 2022, 230, 112439. [Google Scholar] [CrossRef] [PubMed]
- Knuth, D.E. TEX and METAFONT: New Directions in Typesetting; Digital Press: Providence, RI, USA; American Mathematical Society: Bedford, MA, USA, 1979. [Google Scholar]
- Gentleman, R.; Temple Lang, D. Statistical analyses and reproducible research. J. Comput. Graph. Stat. 2007, 16, 1–23. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Xie, Y.; Allaire, J.J.; Grolemund, G. R Markdown: The Definitive Guide; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Peikert, A.; Van Lissa, C.J.; Brandmaier, A.M. Reproducible research in R: A tutorial on how to do the same thing more than once. Psych 2021, 3, 836–867. [Google Scholar] [CrossRef]
- Chacon, S.; Straub, B. Pro Git; Springer Nature: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Ushey, K.; Wickham, H. renv: Project Environments. 2023. Available online: https://github.com/rstudio/renv (accessed on 14 December 2023).
- Xie, Y. TinyTeX: A lightweight, cross-platform, and easy-to-maintain LaTeX distribution based on TeX Live. TUGboat 2019, 40, 30–32. [Google Scholar]
- Siraji, M.; Haque, S. Psychometric evaluation of the Bangla-Translated Rotter’s Internal-External Scale through classical test theory and item response theory. Front. Psychol. 2022, 13, 1023856. [Google Scholar] [CrossRef]
- Siraji, M.A.; Lazar, R.R.; van Duijnhoven, J.; Schlangen, L.J.M.; Haque, S.; Kalavally, V.; Vetter, C.; Glickman, G.L.; Smolders, K.C.H.J.; Spitschan, M. An inventory of human light exposure behaviour. Sci. Rep. 2023, 13, 22151. [Google Scholar] [CrossRef]
- Knuth, D.E. Literate programming. Comput. J. 1984, 27, 97–111. [Google Scholar] [CrossRef]
- Aust, F.; Barth, M. papaja: Create APA manuscripts with R Markdown. 2018. Available online: https://github.com/crsh/papaja (accessed on 14 December 2023).
- Siraji, M. Tabledown: Create Publication Quality Tables and Plots. 2022. Available online: https://cran.r-project.org/web/packages/tabledown/tabledown.pdf (accessed on 14 December 2023).
- Hlavac, M. Stargazer: Beautiful LATEX, HTML and ASCII Tables from R statistical Output. 2022. Available online: https://cran.r-project.org/web/packages/stargazer/vignettes/stargazer.pdf (accessed on 14 December 2023).
- Xie, Y.; Dervieux, C.; Riederer, E. R Markdown Cookbook; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Stodden, V.; McNutt, M.; Bailey, D.H.; Deelman, E.; Gil, Y.; Hanson, B.; Heroux, M.A.; Ioannidis, J.P.; Taufer, M. Enhancing reproducibility for computational methods. Science 2016, 354, 1240–1241. [Google Scholar] [CrossRef] [PubMed]
- Tir, S.; White, R.; Spitschan, M. Inclusion, reporting and analysis of demographic variables in chronobiology and sleep research. bioRxiv 2023. [Google Scholar] [CrossRef]
- Spitschan, M.; Stefani, O.; Blattner, P.; Gronfier, C.; Lockley, S.W.; Lucas, R.J. How to report light exposure in human chronobiology and sleep research experiments. Clocks Sleep 2019, 1, 280–289. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siraji, M.A.; Rahman, M. Primer on Reproducible Research in R: Enhancing Transparency and Scientific Rigor. Clocks & Sleep 2024, 6, 1-10. https://doi.org/10.3390/clockssleep6010001
Siraji MA, Rahman M. Primer on Reproducible Research in R: Enhancing Transparency and Scientific Rigor. Clocks & Sleep. 2024; 6(1):1-10. https://doi.org/10.3390/clockssleep6010001
Chicago/Turabian StyleSiraji, Mushfiqul Anwar, and Munia Rahman. 2024. "Primer on Reproducible Research in R: Enhancing Transparency and Scientific Rigor" Clocks & Sleep 6, no. 1: 1-10. https://doi.org/10.3390/clockssleep6010001