1. Introduction
Machine learning is central to the ongoing technological advancement. Drawing inspiration from human cognitive and learning processes, the concept behind artificial neural networks (ANNs) was developed. ANNs are essential for forecasting environmental variables, renewable generation, and energy demand, all of which are crucial for effective power management.
Recent studies [
1,
2] suggest that wind and solar power forecasting techniques can be categorized into image-based approaches, statistical models, machine learning-based techniques, and decomposition-based methods:
Image-based methods utilize ground-based systems such as sky cameras, Doppler weather radar systems, LiDAR optical systems, or satellite imagery to predict the cloud cover essential for solar irradiance and power forecasting. Within this category, scientists often incorporate physical models or numerical weather predictions.
Statistical models focus on analyzing the intrinsic characteristics of the target time series. Commonly employed methods in this category include the auto-regressive method and its vectorial variant, the Markov chain approach, and the analog ensemble.
Machine learning-based techniques encompass methods that employ ANNs, like extreme learning machines or convolutional neural networks, to capture the non-linear characteristics of the variable under prediction. Other techniques in this category include support vector machines, decision trees, and Gaussian processes.
Decomposition-based methods cover variational, empirical, and wavelet decompositions, as well as approaches reliant on the Fourier transform.
Furthermore, hybrid models can be developed by merging the aforementioned approaches. Such hybrid strategies can be categorized into stacking-based models and weighted-based techniques. Mixed or combined methods not only pertain to the merging of forecasting techniques but also to how data are handled or pre-processed to enhance prediction outcomes, such as algorithms used for data clustering or feature selection.
Energy demand is another variable for which prediction is highly sought-after. Statistical models, machine learning-based techniques, decomposition-based methods, and their combinations have been successfully applied [
3,
4]. Additionally, the component estimation technique [
5] and the functional data approach [
6] have been introduced recently, demonstrating promising results for short- and medium-term electricity demand.
In machine learning methodologies, computer scientists frame the learning process as an optimization problem aimed at minimizing the discrepancy between input and output datasets. This problem is commonly addressed using gradient-based optimization. While most available methodologies offer users a satisfactory solution, they do not guarantee global optimality. In other words, training methods often converge to a solution without definitive knowledge of whether it is a local or global optimum. This uncertainty arises because we lack concrete information about the objective function’s shape under investigation. The challenge of achieving global optimality is intrinsically linked to the struggle algorithms face in moving from a local to a global optimum—a phenomenon termed stagnation around a local optimum. Consequently, the local optimum reached during a specific training attempt of an ANN is influenced by its initially chosen starting point, which is often selected at random.
Training ANNs using heuristic techniques has been proposed as a solution to the stagnation problem. While heuristic techniques can also experience stagnation around local optima [
7,
8], they explore and exploit the objective function in ways distinct from gradient-based methods. Several researchers have endeavored to enhance the search capabilities of these techniques. Dlugosz and Kolasa [
9] examined the Kohonen network and devised a training strategy to circumvent stagnation. Their method analyzes the convergence process by employing the neighborhood radius—a topological parameter that determines how network nodes are considered. They found that the training process stagnates when the neighborhood radius exceeds a certain critical value. Furthermore, they noted an active phase in the training error immediately after the neighborhood radius drops below this value. This active phase is then followed by a stagnation phase, during which the neighborhood radius remains static. The researchers introduced filters on the error signal to eradicate the stagnation phases and implemented a decision mechanism to decrease the neighborhood radius once the active phase concludes. Based on the results, this approach accelerates the training process by a factor of 16 compared to traditional methods, where the neighborhood radius diminishes linearly.
Researchers working with the competitive coevolutionary team-based particle swarm optimizer (CCPSO) have also highlighted concerns regarding stagnation. Scheepers and Engelbrecht [
10] conducted an in-depth analysis of the stagnation issue, linking the stagnation phenomenon to the saturation of network weights. To counteract weight saturation, they proposed ensuring that the global best particle’s position remains within the active region of the activation function. This idea is realized by imposing a constraint on the cognitive component of the algorithm. Therefore, a particular particle would update its personal best position only if its current position meets the aforementioned constraint and if this update results in a solution with superior fitness. This adaptation of the CCPSO algorithm prevents the weights from departing from the active region of the activation function, thereby mitigating stagnation. Moreover, the researchers introduced a time-varying perception limit—a variable that diminishes to zero after a specified number of epochs—to encourage better exploitation of available solutions. The team reported encouraging outcomes concerning swarm diversity during the training of a soccer-playing robot team.
Particle swarm optimization (PSO) has been successfully applied to ANN training. Mendes et al. [
11] and Gudise and Venayagamoorthy [
12] were among the pioneers to demonstrate promising results using PSO. Zhang et al. [
13] investigated the characteristics of both backpropagation (BP) and PSO in terms of convergence speed and searching capabilities, leading to a combined approach. While PSO excels in searching for the global optimum, its computational speed is somewhat modest. In contrast, BP rapidly converges to a local minimum, but its capacity to identify the global optimum is limited. Given this backdrop, the authors proposed a hybrid approach leveraging the strengths of both BP and PSO. The methodology involves using PSO to identify a potential global solution, and when optimization begins to stagnate, BP is introduced to refine the local search. Based on a case study analysis, the hybrid BP-PSO method efficiently achieves a high-accuracy trained network compared to either BP or PSO used separately.
Mirjalili et al. [
14] integrated the gravitational search algorithm (GSA) with PSO, capitalizing on PSO’s social perspective and GSA’s searching prowess. The combined algorithm was tested on several benchmark problems, successfully navigating around stagnation at local minima. Tarkhaneh and Shen [
15] crafted an algorithm that combined PSO operators with the Mantegna Levy distribution to reduce optimization stagnation. Cansu et al. [
16] introduced a training algorithm for long short-term memory (LSTM) neural networks, modifying PSO to address the stagnation challenge. Their approach, when compared to the Adam algorithm, displayed promising outcomes. Xue et al. [
17] put forward a hybrid gradient descent search algorithm (HGDSA) that explores optimization spaces using gradient descent strategies, subsequently employing BP for localized refinement. Furthermore, HGDSA incorporates a self-adaptive mechanism for strategic selection and updating the learning rate.
The training algorithms’ reliance on random initialization of network parameters introduces a source of uncertainty. This step can significantly influence the local minimum where the training algorithm becomes trapped, a phenomenon intrinsically linked to the training procedure known as procedural variability [
18]. Presently, there is a heightened focus on developing a formal approach to address uncertainties in deep neural networks. Typically, uncertainties are categorized as either aleatoric or epistemic. The aleatoric component arises from the intrinsic characteristics of the data under consideration. In contrast, epistemic uncertainty pertains to the absence of knowledge or insufficient information about the model in development [
19]. Therefore, the aforementioned procedural variability can be linked to the epistemic facet of uncertainty. Epistemic uncertainty can be quantified through Bayesian and ensemble methods. Bayesian techniques express uncertainty using probability distributions to diminish the generalization error. Conversely, ensemble approaches generate multiple models and a variety of forecasting outcomes, which are then amalgamated to yield a more refined prediction [
20,
21].
This study seeks to address the following questions:
How can scientists accurately estimate local minima during network training?
What quantitative advantages are gained by identifying the local minima of the objective function during network training?
How do existing training methods in the literature leverage detailed knowledge of the objective function’s local minima?
In relation to the first question, comprehensive access to local minima has received limited attention in the technical literature related to ANN training, especially concerning the probability of identifying them. In our research, we drew upon the work of Finch et al. [
22] and employed the Monte Carlo simulation (MCS) approach with a stopping criterion to seek out the local minima of the ANN training optimization problem. Specifically, we repeatedly trained and validated the ANN from various random starting points (RSPs) until a satisfactory probability distribution approximation emerged. Subsequently, we computed the probability of identifying an additional, previously unseen solution (local optimum). This helps determine how comprehensively the local optima have been identified. To our knowledge, this approach to estimating the likelihood of having uncovered all local minima is not commonly employed in ANN training. It ties directly to the aforestated issue of stagnation, the initial point of the training procedure, and is thus linked with epistemic uncertainty.
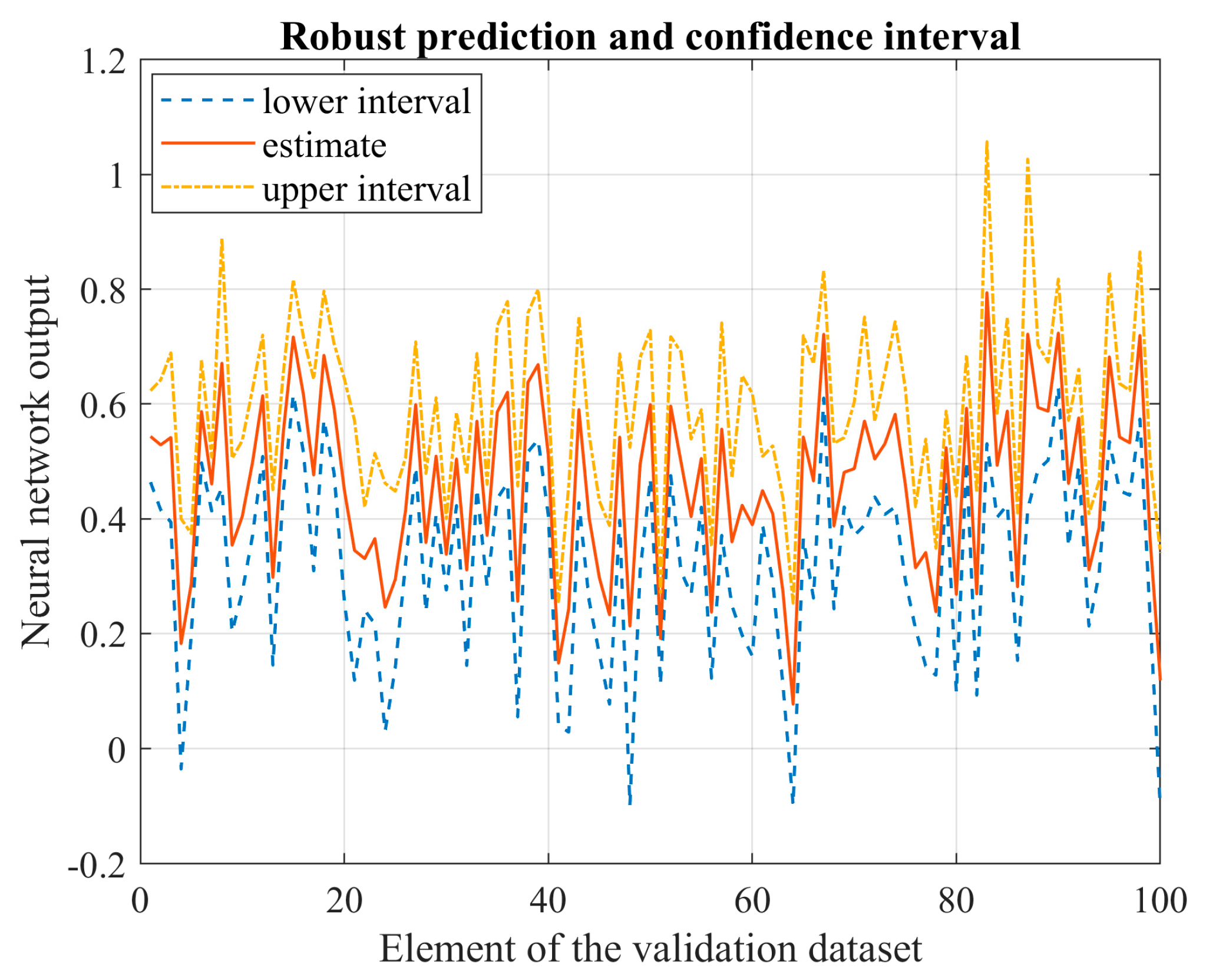
In relation to the second question, we compare the output derived from using the parameter set, which has a high likelihood of being the global optimum, to the average performance. This comparison allows us to determine the improvement rate over average conditions. This method is applied to various variables of interest, including wind speed, power, and electricity demand.
Lastly, we present a discussion on a comprehensive approach to evaluate the implications of possessing detailed information about the objective function. Specifically, we delve into how the probability of having identified all local minima integrates with existing methodologies. This addresses the third question.
This paper is structured as follows:
Section 2 describes the stopping criterion employed and the evaluation of the trained ANN. In
Section 3, we present various case studies related to wind speed, power, and load prediction, accompanied by a discussion on robust forecasting. The primary conclusions are outlined in
Section 4.
2. Materials and Methods
A typical ANN consists of input, hidden, and output layers, each containing several interconnected units. Feedforward neural networks (FFNNs) and recurrent neural networks (RNNs) with only one hidden layer (often referred to as shallow neural networks) and
units are represented in (1) and (2), respectively. The network operates on a dataset of size
, which considers
features and
outputs. Input and output variables are denoted by the vectors
and
, respectively, as described in (3).
The structure of an ANN is mathematically represented by matrices, which are dimensioned appropriately based on the number of layers and units. These matrices serve as weighting factors and are determined during the training process. The activation function represented as in (1) and (2), adjusts the output values and is typically a sigmoid, hyperbolic tangent, or rectified linear unit function. Equations (1)–(3) describe the input-output relationships for an FFNN and an RNN, respectively. The matrices and vectors , , , , and are determined during the training process, which is initialized from various randomly selected points. The index refers to each of these starting points.
The practical implementation of an ANN requires training and validation datasets. Combined with a computational procedure or training algorithm, these datasets facilitate the estimation of the weighting factors , , , , and . This ensures that the ANN accurately captures the characteristics of the model of interest. The learning capabilities of the trained network are then assessed using an independent dataset, referred to as the testing dataset.
The training process entails solving an optimization problem to minimize the discrepancies between the ANN output and the values from the training dataset. The validation dataset is used to evaluate the network’s generalization capabilities at specific stages of the learning process, helping to prevent overfitting.
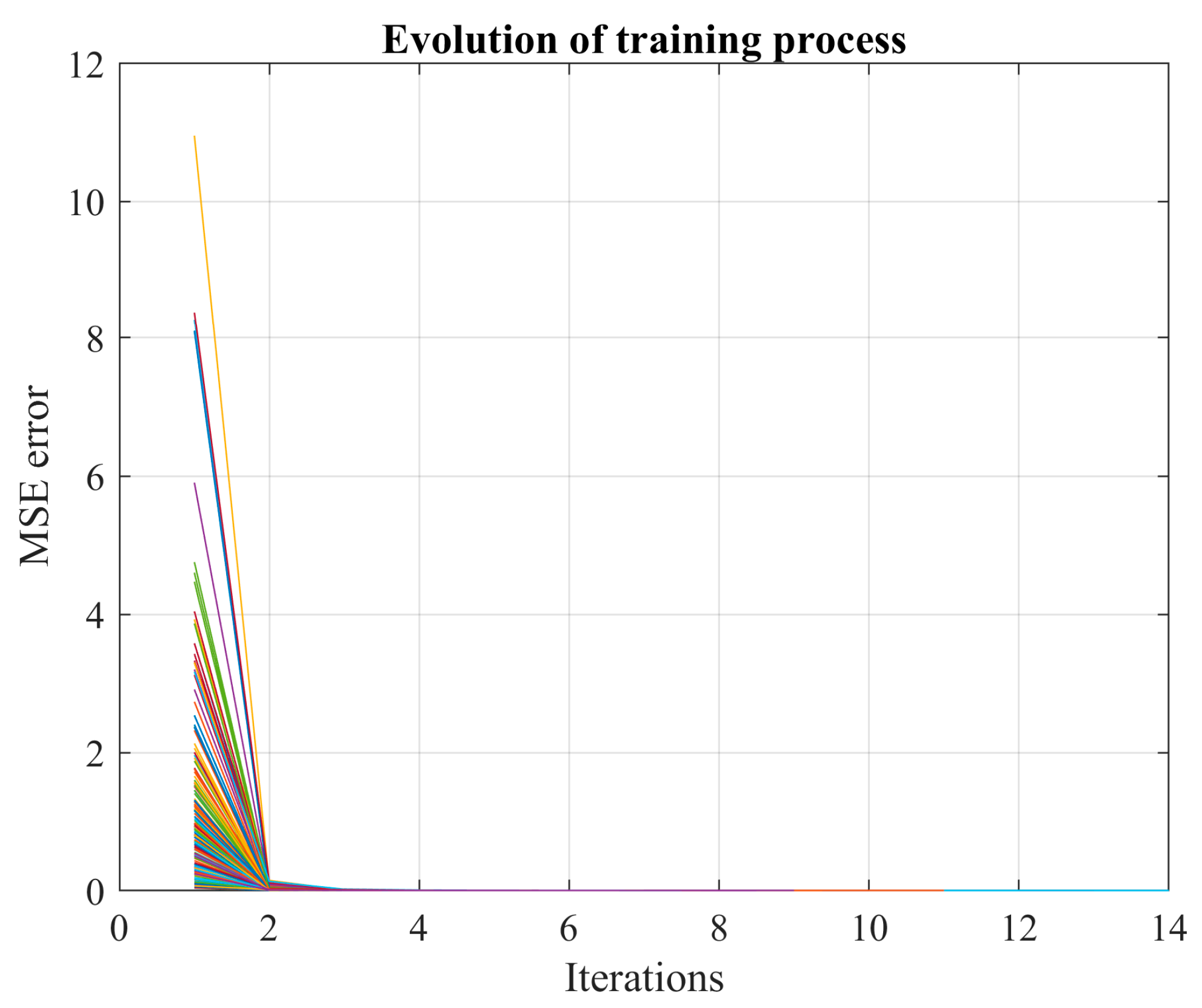
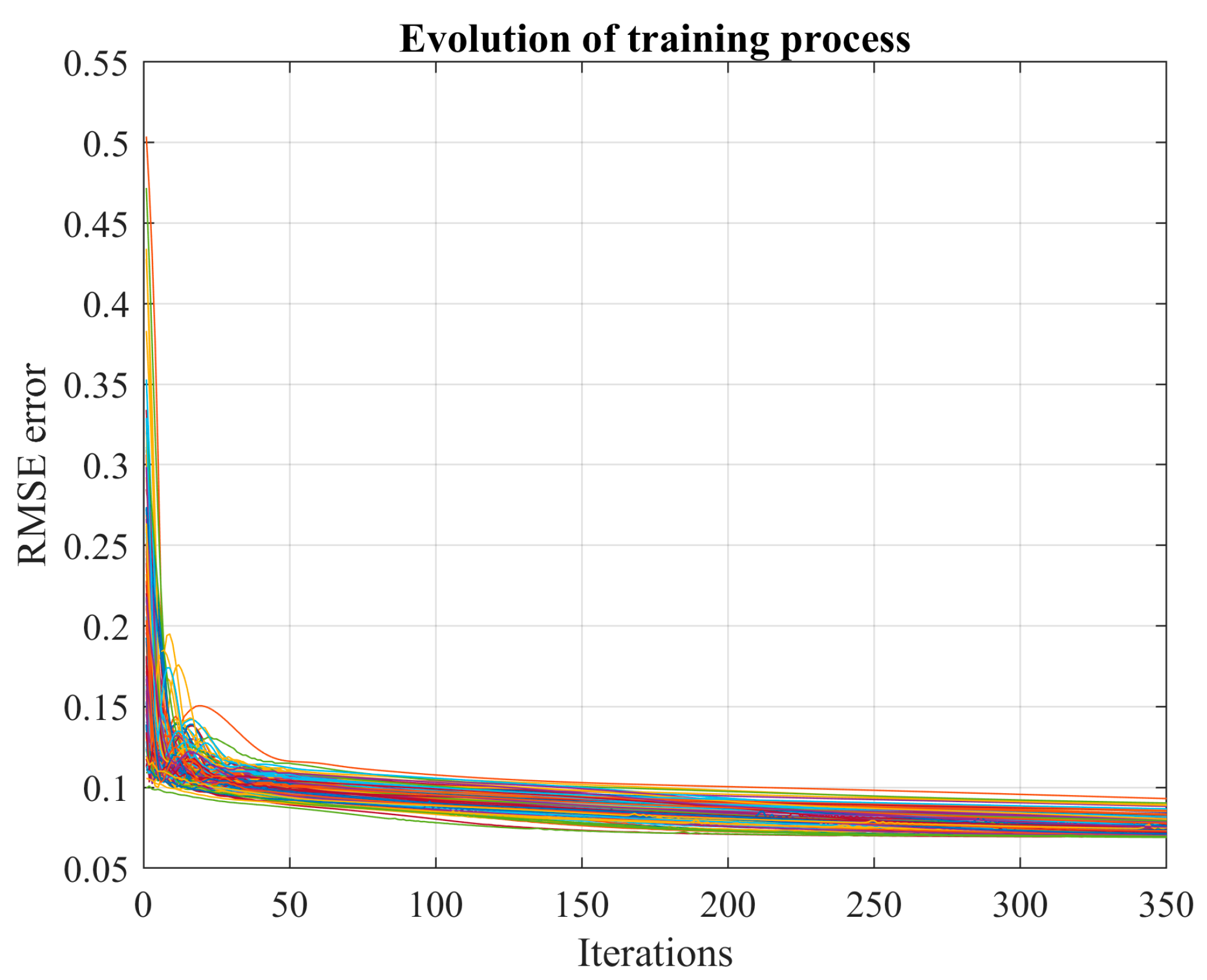
Most training methods used to determine the matrices , , , , and rely on initial values that are randomly set. These initial values significantly impact the learning process as the resultant solution (i.e., the matrices , , , , and ) differs for each initialization point (). Consequently, these commonly used training methods often find a local minimum. In this work, we conduct an extensive search for local minima using the MCS approach, combined with a stopping criterion to conserve computational resources.
Regarding the stopping criterion for the MCS technique, numerous approaches exist. Ata [
23] proposed a strategy that utilizes a user-defined convergence band to increase estimation confidence. Benedetti et al. [
24] adopted certain elements from the methodology put forth by Ata. Bayer et al. [
25] introduced a stopping methodology that leverages the higher moments of the random variable in question. They observed dependable results, especially in heavy-tailed probability distributions, and effectively circumvented premature convergence.
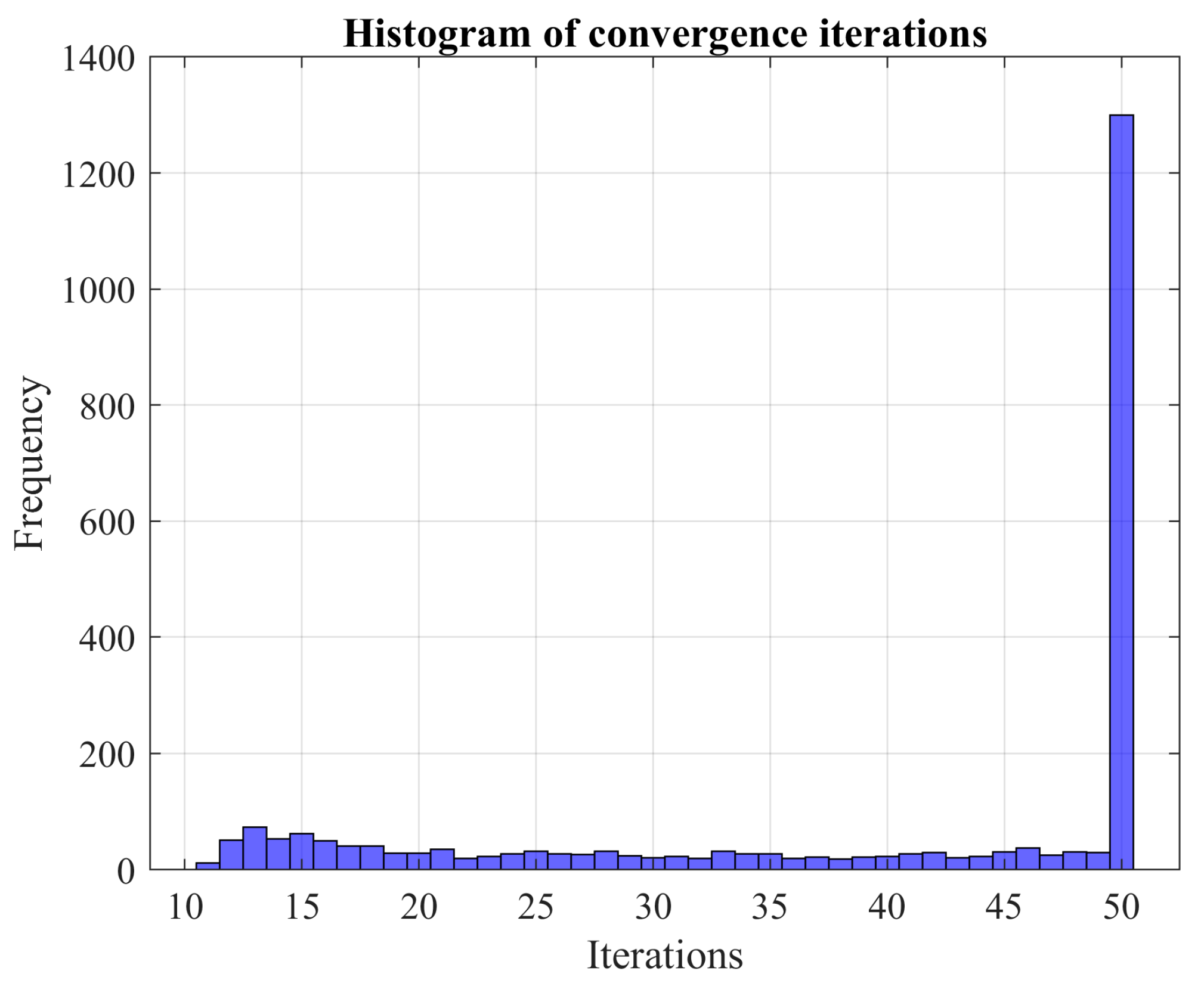
In this study, we apply the MCS method by sequentially adding batches of a designated size. Define as the number of Monte Carlo experiments per batch and as the total number of batches. As a result, the cumulative number of experiments equals . Before utilizing the MCS technique, one must specify:
The number of experiments per batch ()
The total number of batches ()
The number of discretization bins ()
The vector to retain the similarity index values ()
The tolerance threshold, .
We determine the cumulative distribution function (CDF) of the targeted random variable by adhering to the subsequent procedure:
Step 1: Build a matrix () to specify the seeds belonging to each batch. The seed matrix is with rows () and columns (). Similarly, create another matrix () with the same dimensions as to store the values obtained from the ANN validation process. The root mean square error (RMSE) value obtained from validating the network from the RSP of the batch is to be stored in . Each RSP is identified by the seed, which is the corresponding value .
Step 2: Analyze the first batch by setting and go to Step 2.1.
Step 2.1: Consider the first seed value by setting . Go to Step 2.2.
Step 2.2: If go to Step 2.3; else, go to Step 3.
Step 2.3: Train the ANN and store the validation RMSE value in the element of the matrix . Go to Step 2.4.
Step 2.4: Set and go to Step 2.2.
Step 3: Create a column vector () with elements. Then, assign the first column of the matrix to . In other words, assign with and .
Step 4: Set the stopping variable to zero (). Then, go to Step 5.
Step 5: while and go to Step 5.1; else, stop.
Step 5.1: Analyze the next batch by setting . Then, go to Step 5.2.
Step 5.2: Consider the first seed value of batch by setting . Then, go to Step 5.3.
Step 5.3: If go to Step 5.4; else, go to Step 6.
Step 5.4: Train the ANN and store the validation RMSE value in the element of the matrix . Then, go to Step 5.5.
Step 5.5: Set and go to Step 5.3.
Step 6: Build a column vector () with elements. This vector is fulfilled with some elements of the matrix . Reshape the sub-matrix with and into a column vector with elements. Then, store the resulting vector in . Go to Step 7.
Step 7: Create a vector (
) using the values of
. The vector
discretizes the interval between the minimum and the maximum observed validation RMSE value until this point. The vector
is built using (4), where
, and
are the minimum and maximum values of
, and
is the discretization interval with
elements. The vector
is used later to construct the CDF. Once
is obtained, go to Step 8.
Step 8: Create a column vector with elements (). Build the CDF of the vector using the intervals of vector previously determined in Step 7. The corresponding probabilities are assigned to . Then, go to Step 9.
Step 9: Create a column vector with elements (). Build the CDF of the vector using the intervals of vector previously determined in Step 7. The corresponding probabilities are assigned to . Then, go to Step 10.
Step 10: Calculate the Euclidean distance (
) between
and
according to (5).
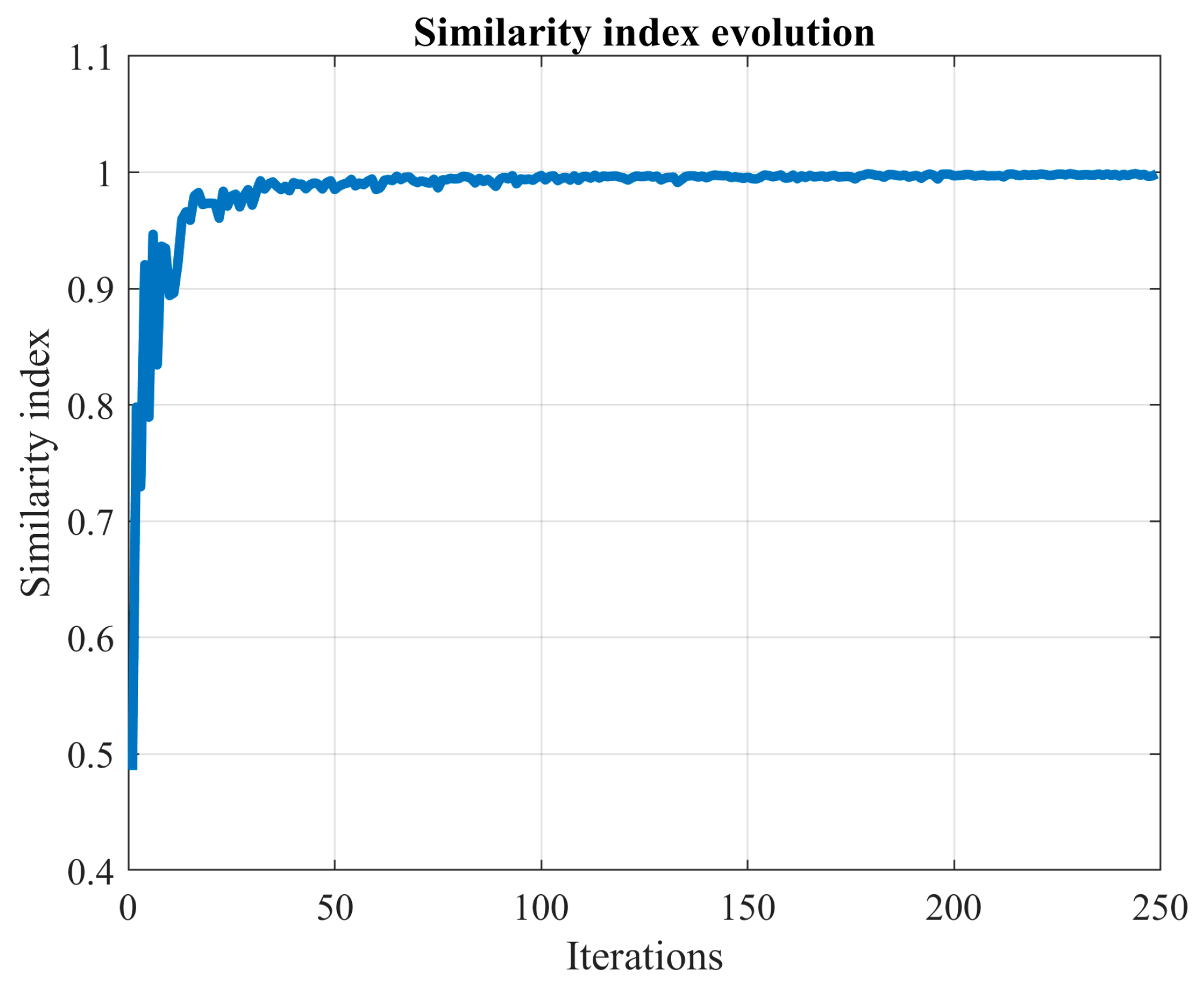
Then, calculate the similarity (
) between
and
using (6).
Once has been calculated, go to Step 11.
Step 11: If the average of the last -values of the similarity index of (6) is higher than , assign and go to Step 5; else, set , , and go to Step 5. The parameter is a tolerance the user sets according to its confidence and reliability requirements.
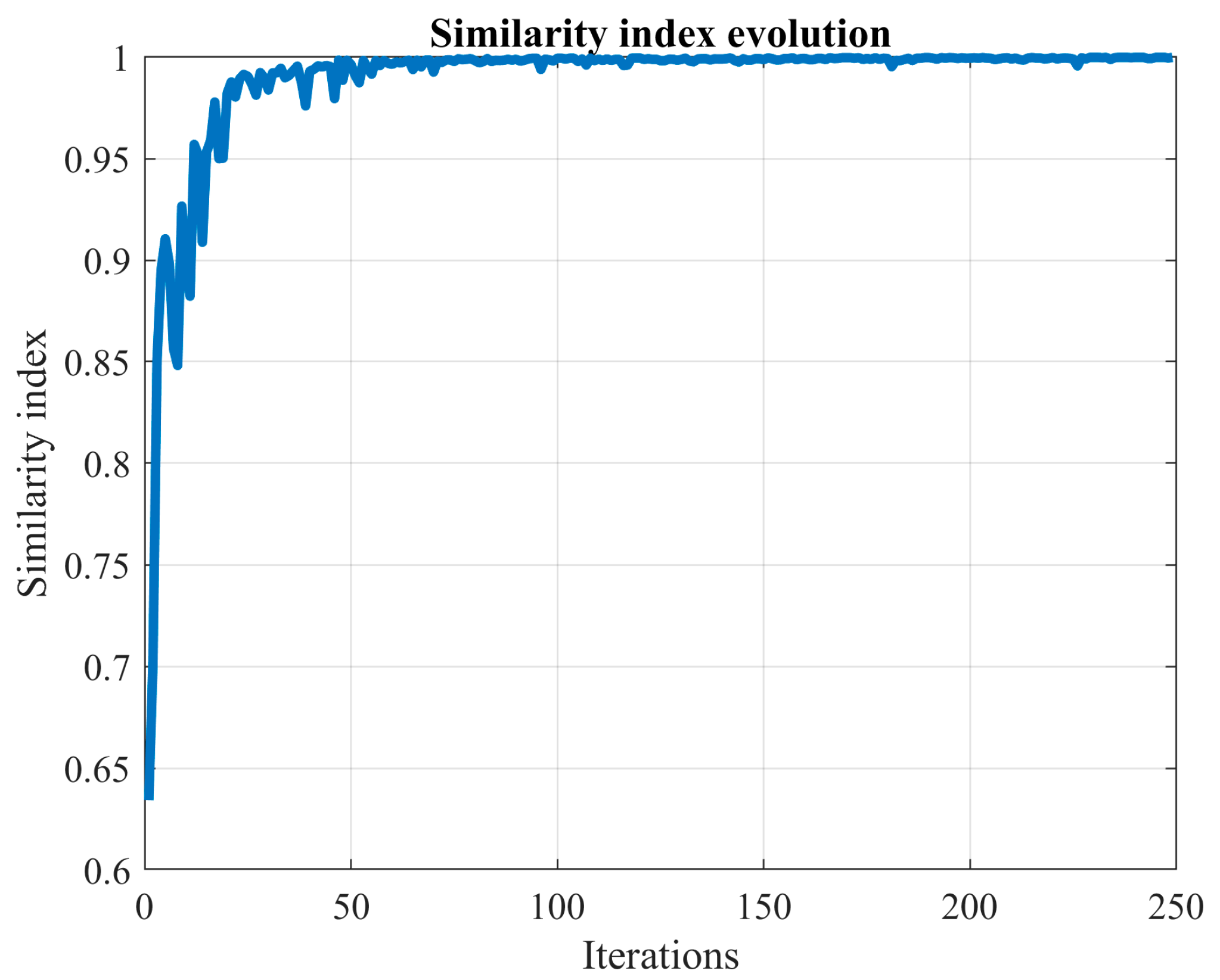
In summary, the stopping rule in this study introduces one batch at a time and gauges the change in the CDF. The MCS process halts when this variation aligns closely with user preferences, as denoted by the parameter . Instead of relying solely on the CDF variation (), we employ a similarity index () for enhanced comprehensibility. This index gravitates towards 1 as the MCS advances. Moreover, to mitigate the impact of minor fluctuations on decision-making, we smooth out the similarity index by averaging the last values. Notably, some researchers address this issue by incorporating a convergence band.
On the one hand, averaging the similarity index over the last iterations helps in reducing its variability. On the other hand, the factor , when is small, primarily serves as a stopping condition. A smaller value of the parameter indicates a more extended MCS process.
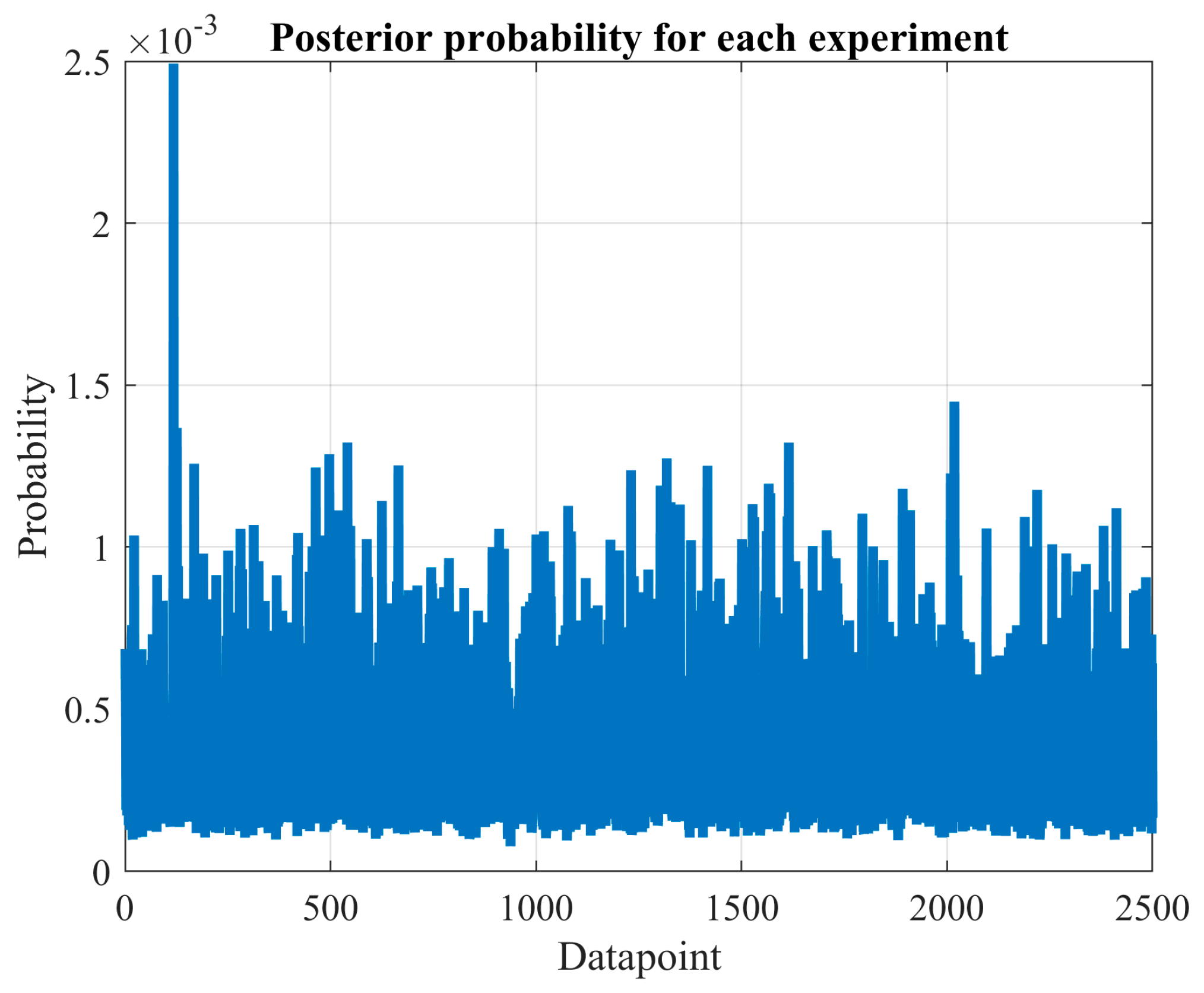
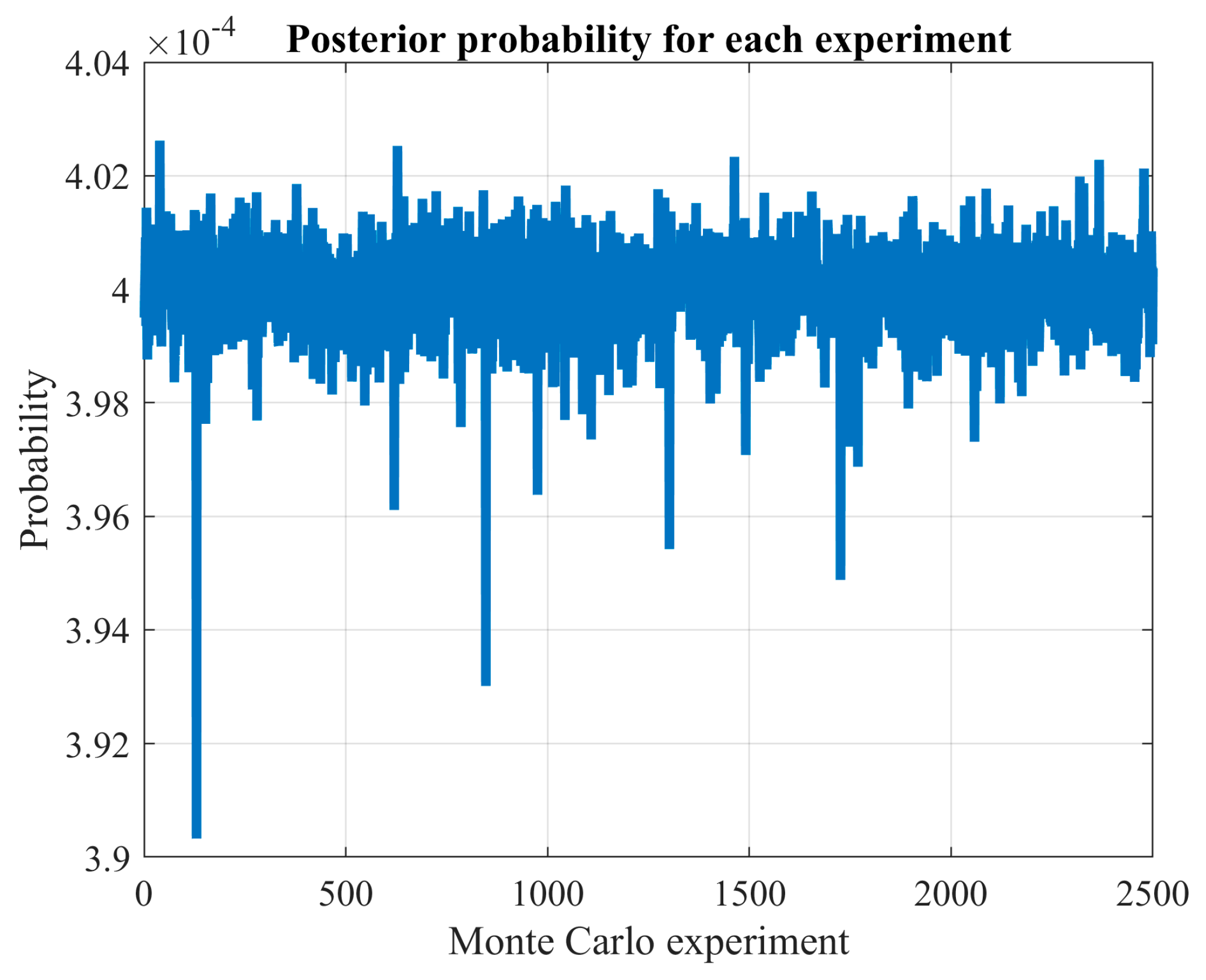
After estimating the probability distribution using an appropriate number of experiments, we can identify the solutions obtained and evaluate them probabilistically. To achieve this, we compute the probability of discovering previously unidentified solutions or species () if the Monte Carlo procedure is repeated once.
The literature has extensively covered this research area [
26,
27,
28,
29]. The probability of finding a new solution is contingent upon the number of recently identified local minima. Let
and
represent the bins and the frequency associated with each bin, respectively, where
. The number of newly discovered solutions or species (
) is determined using (7) [
22].
where
is a function given by (8) [
22].
Then, the probability of finding a new local minimum (
) is approximated using (9) [
22].
The subsequent section demonstrates the implementation of the MCS approach, using the aforementioned stopping criterion, to search for local minima during ANN training for predictive purposes.
4. Conclusions
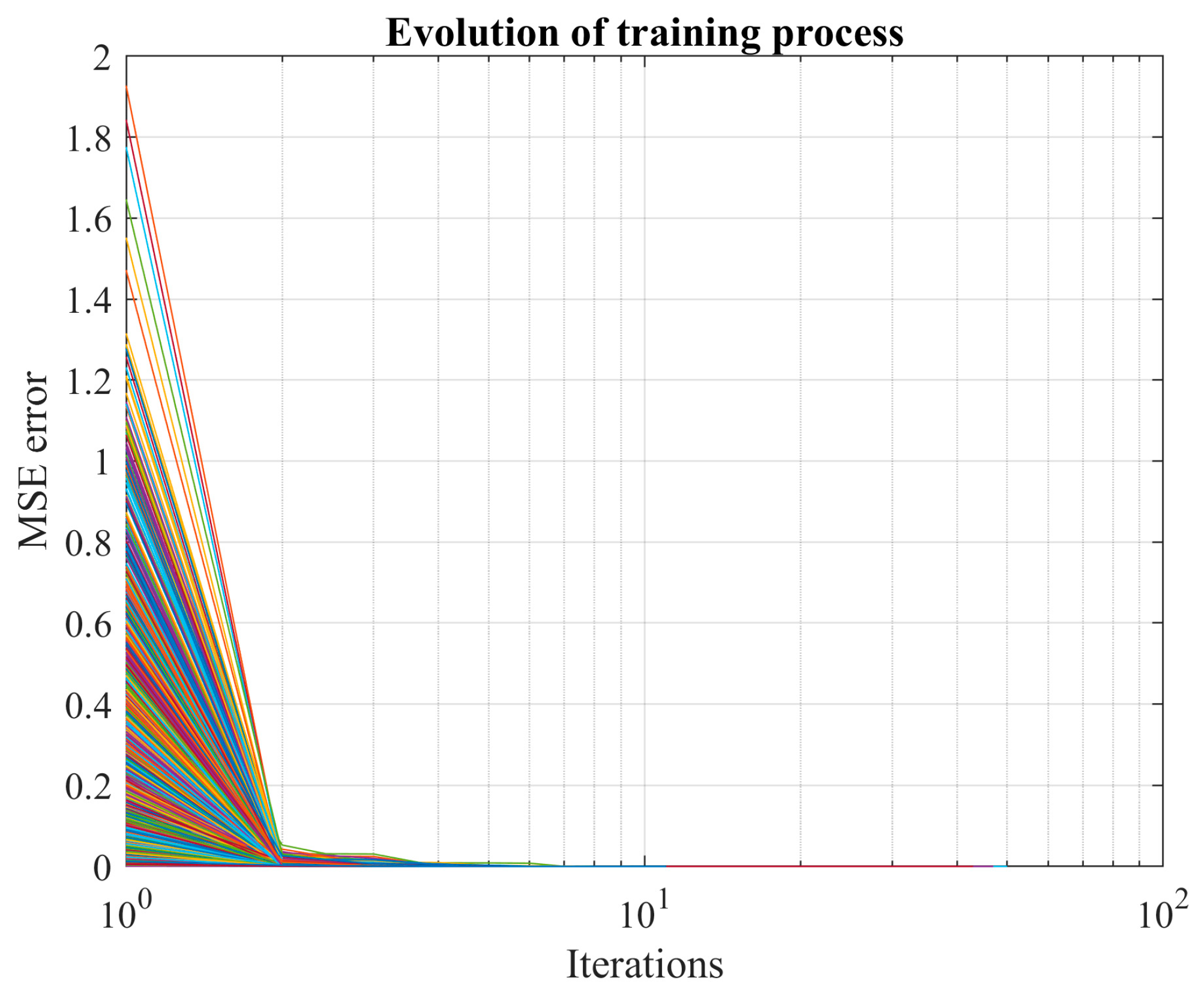
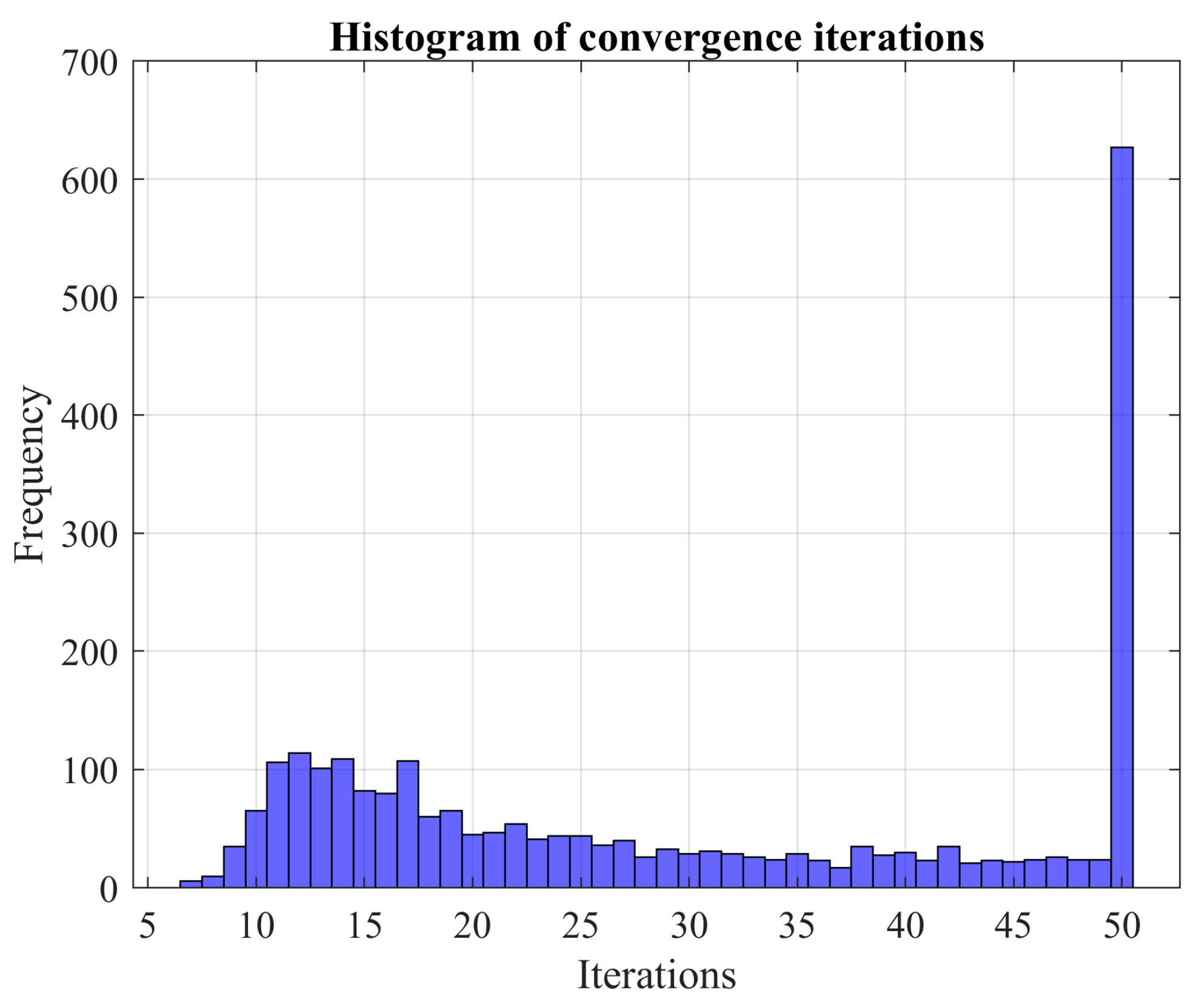
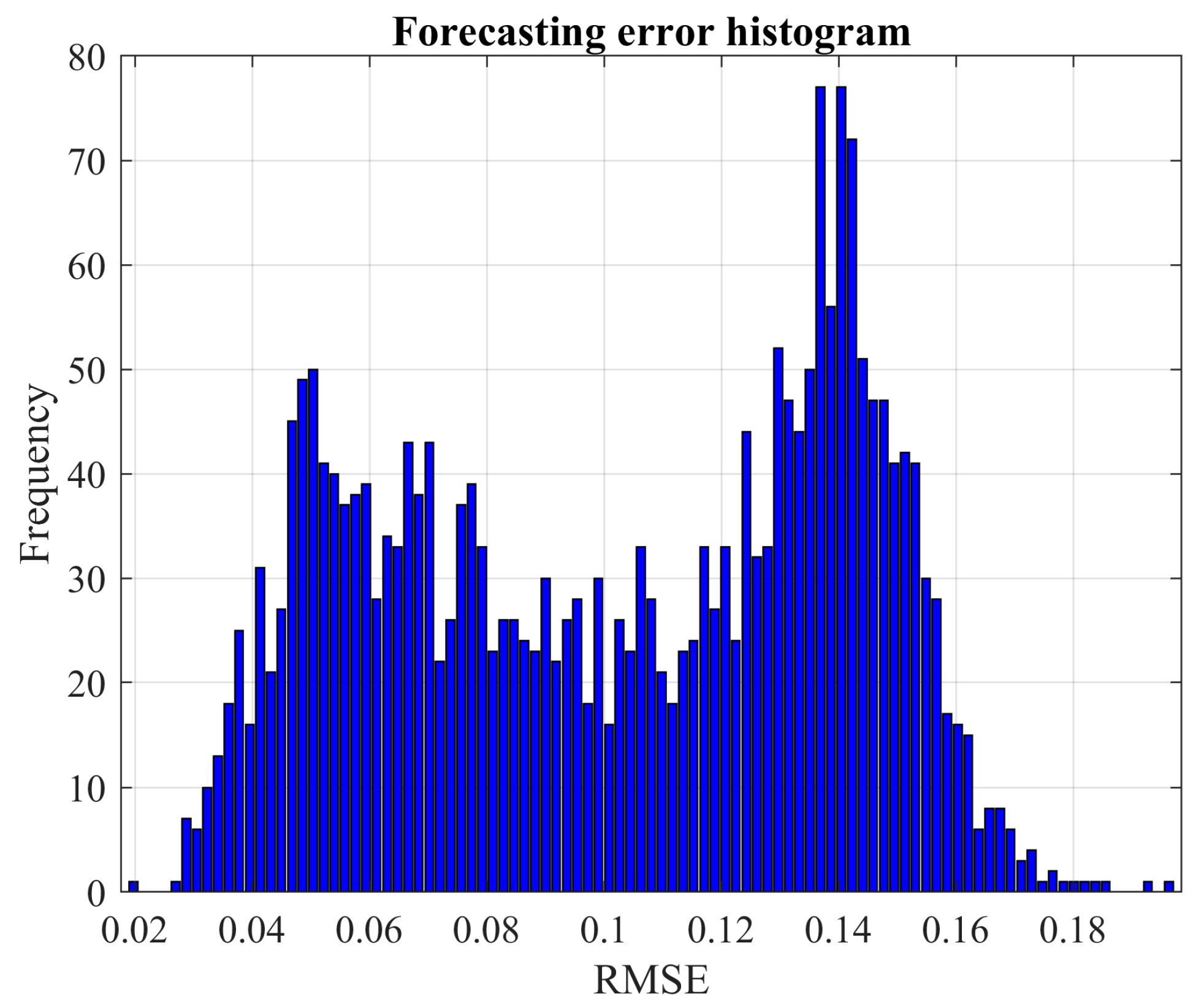
This paper employs the Monte Carlo simulation technique coupled with a stopping criterion to construct the probability distribution of the learning error for an ANN used in short-term forecasting. In essence, the learning process (LM for FFNN and Adam for LSTM network) initiates from a distinct point for each Monte Carlo realization, aiming to identify the local minima. Subsequently, we estimate the probability of discovering a new local minimum if the Monte Carlo process were extended.
We applied this procedure to wind power, load demand, and wind speed time series from various European locations. The enhancement gained from a thorough search of an FFNN with superior performance, when compared to an average trained network, is 0.7% for wind power prediction, 8.6% for load demand forecasting, and 3% for wind speed prediction. Moreover, when using an LSTM network—a type of recurrent neural network—for wind speed prediction, the improvement rate rises to 9.5%.
The FFNN, when trained exhaustively, delivers a performance that is 20.3% better than the persistent model for wind power forecasting, 5.5% for load demand prediction, and 6.5% for wind speed forecasting. When predicting wind speed using an LSTM, the performance improves by 6% compared to the persistent approach.
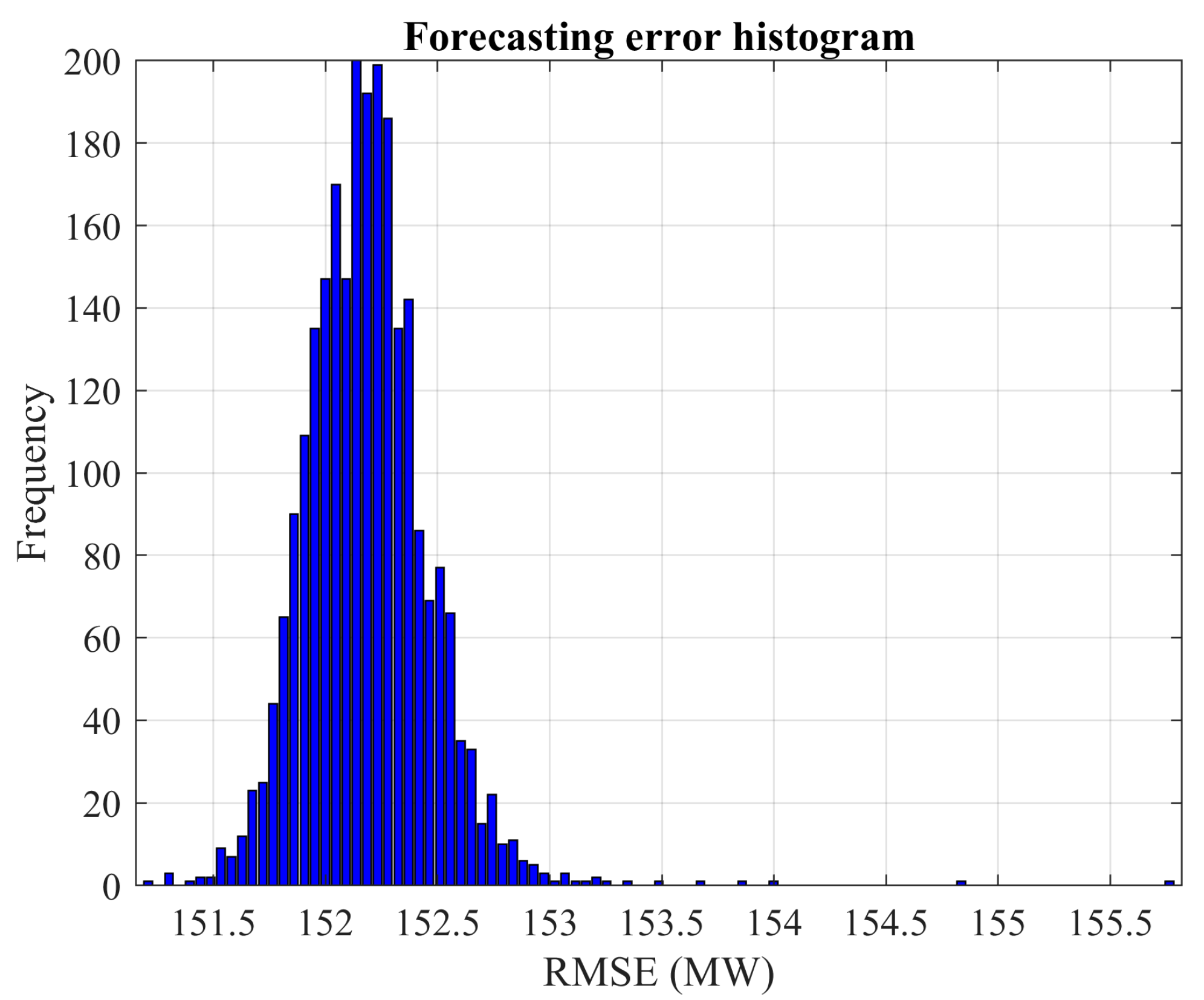
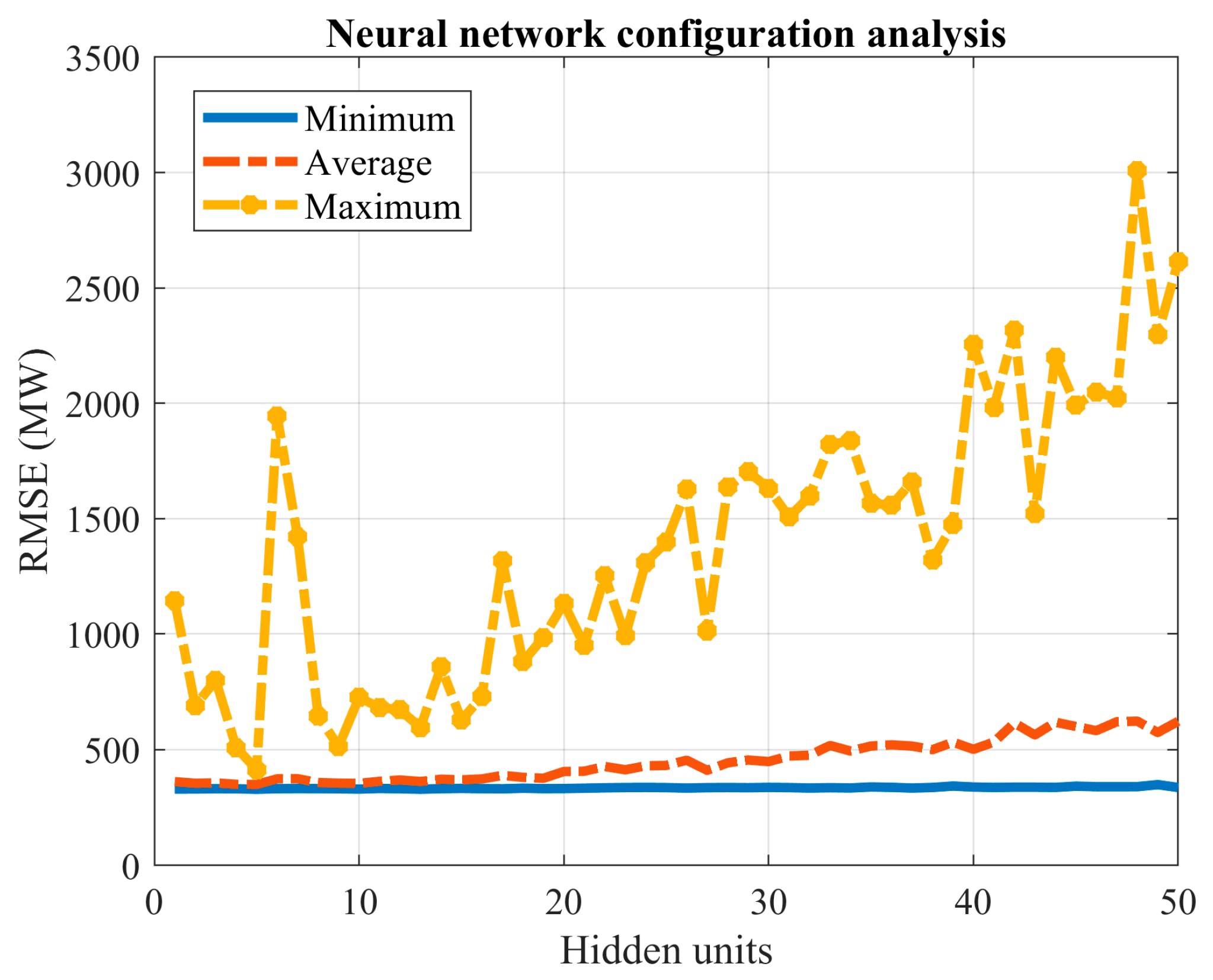
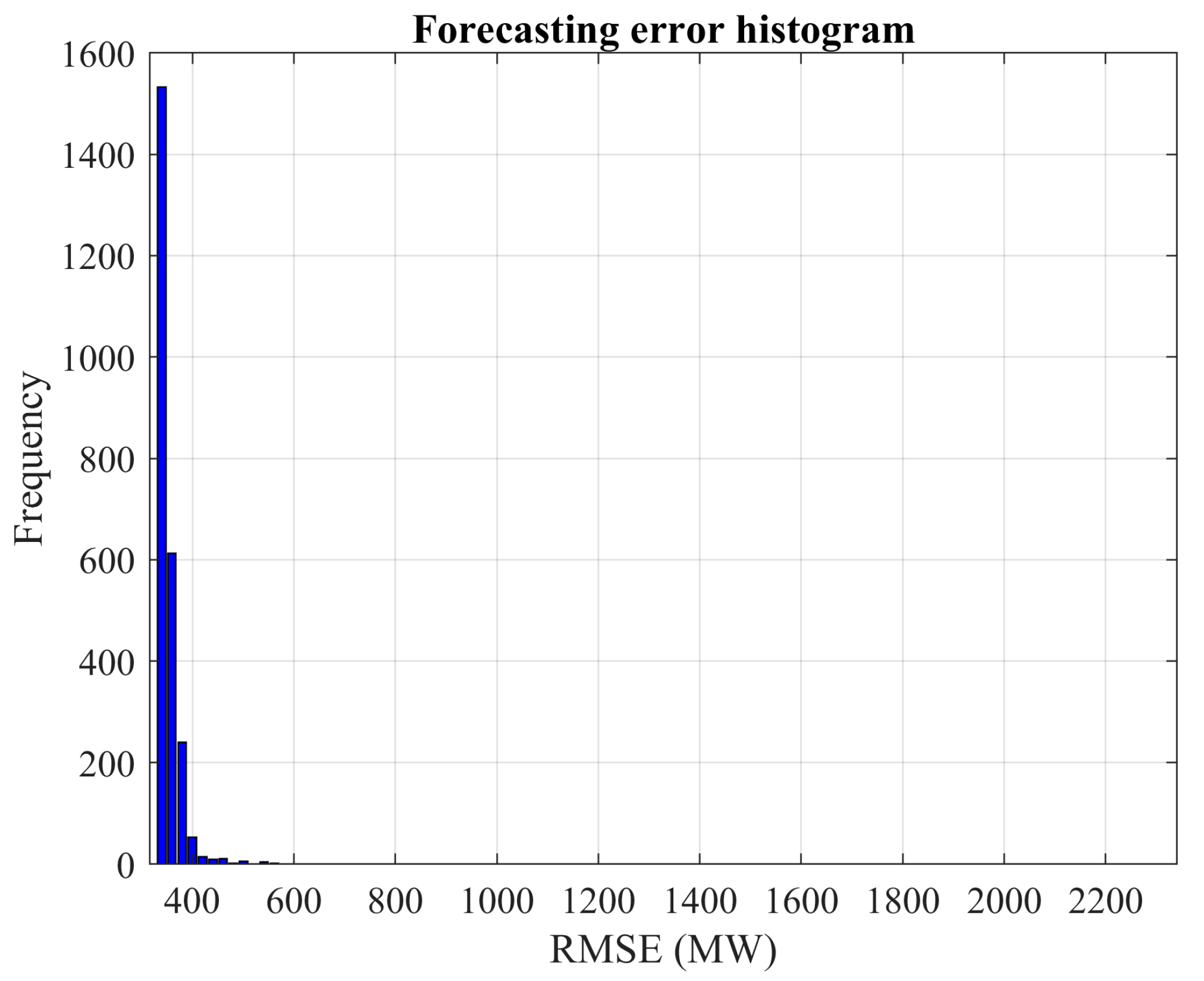
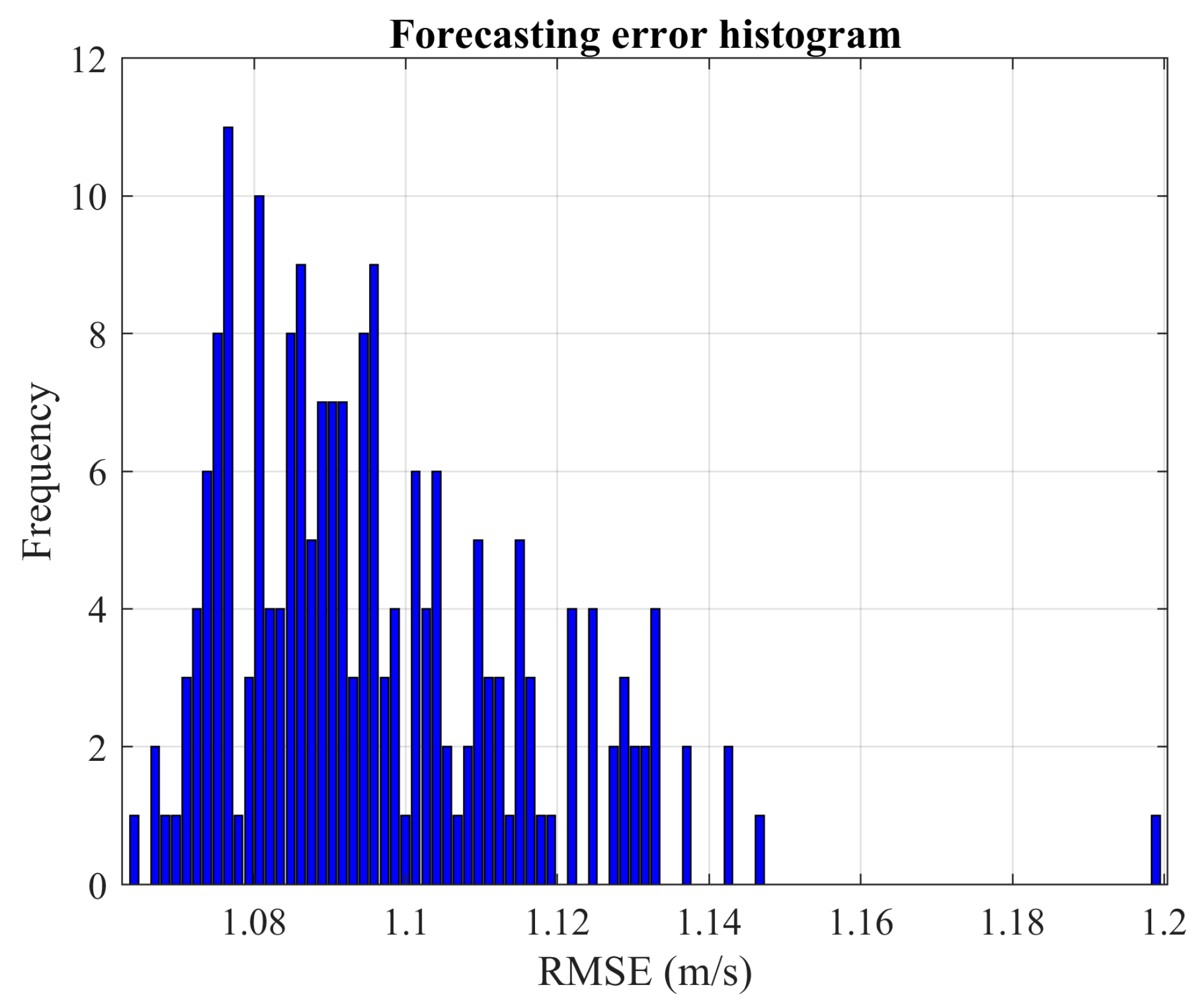
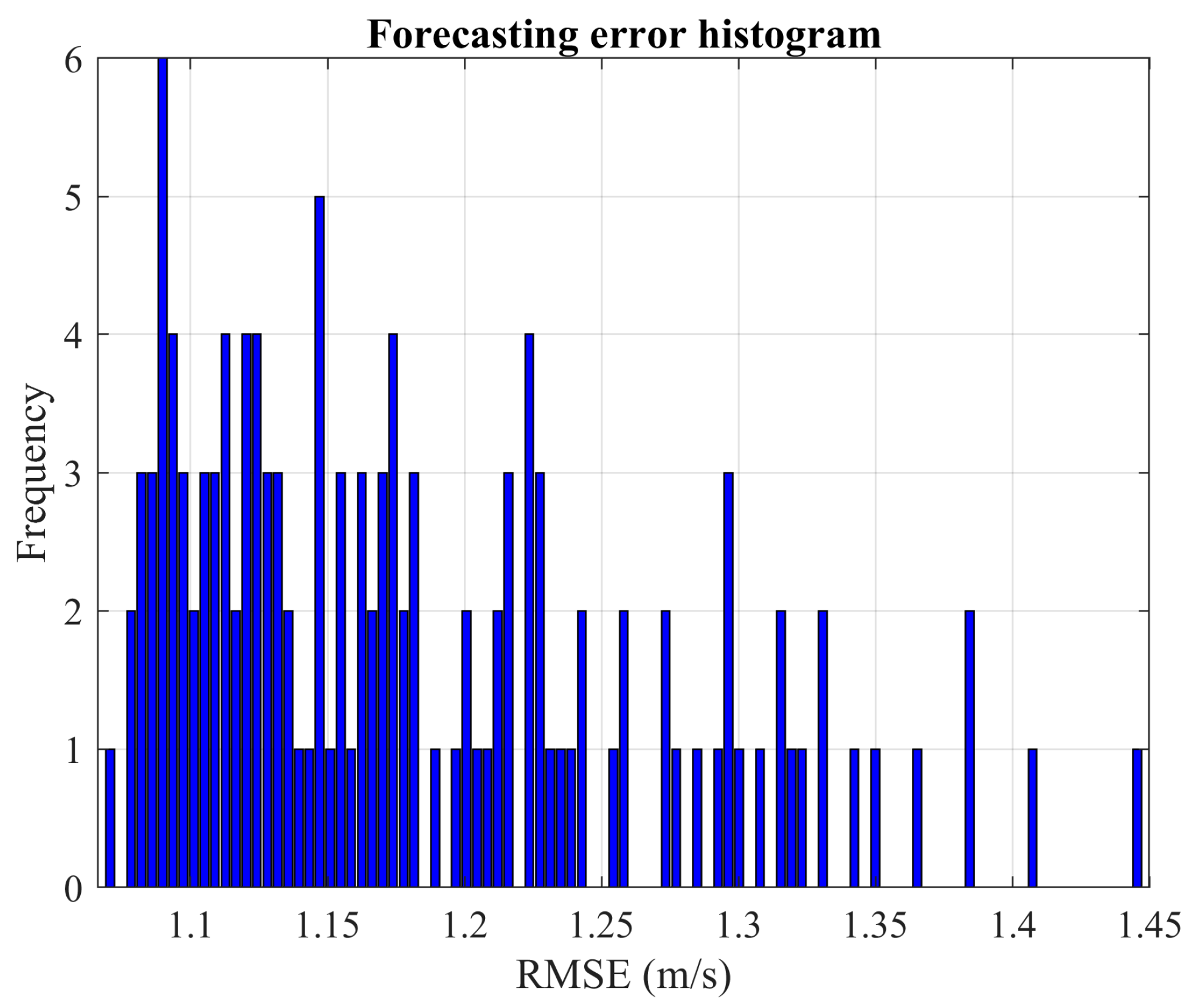
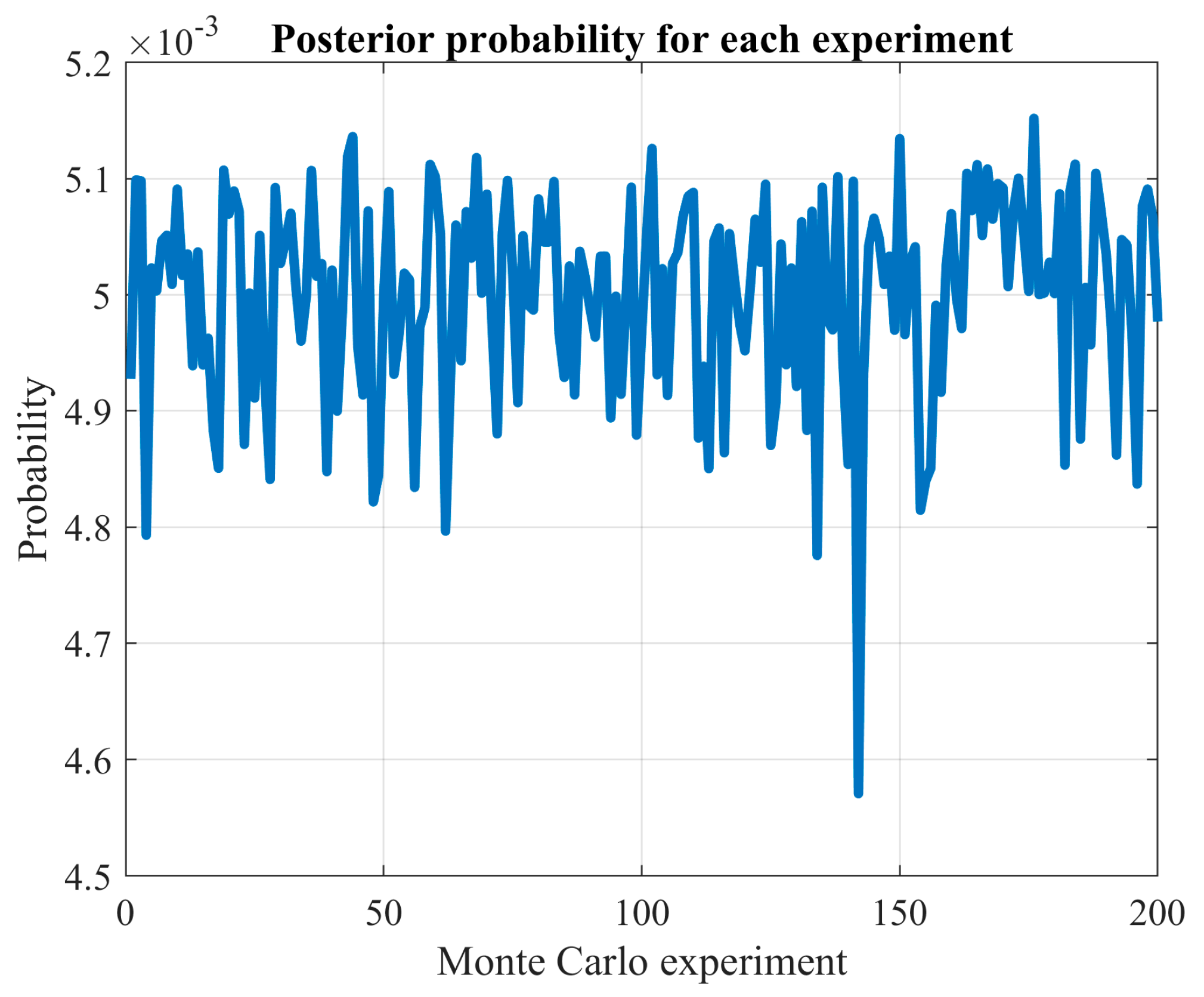
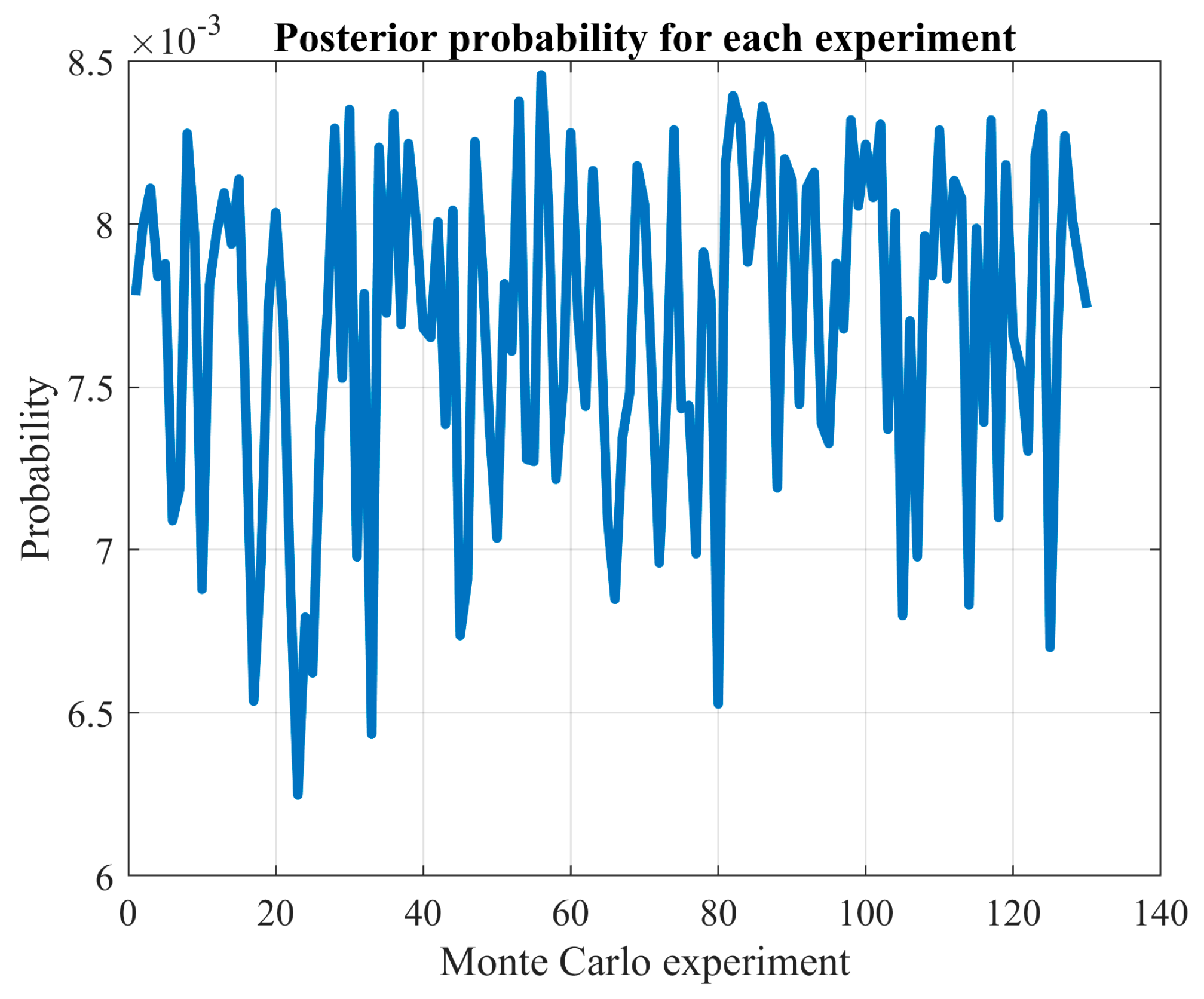
These results indicate that the advantages of exhaustive search vary significantly based on the problem being analyzed and the specific network type used. By increasing the number of Monte Carlo experiments, the confidence in the observed solutions is bolstered. For instance, the probability of discovering a new local optimum drops significantly in the cases of wind power and load demand when the number of experiments is increased. Specifically, for wind power prediction, it drops from 4.375% with 160 experiments to 0.52% with 2500 experiments. Similarly, for load demand forecasting, the decline is from 12.77% with 160 experiments to 0.48% with 2500 experiments.
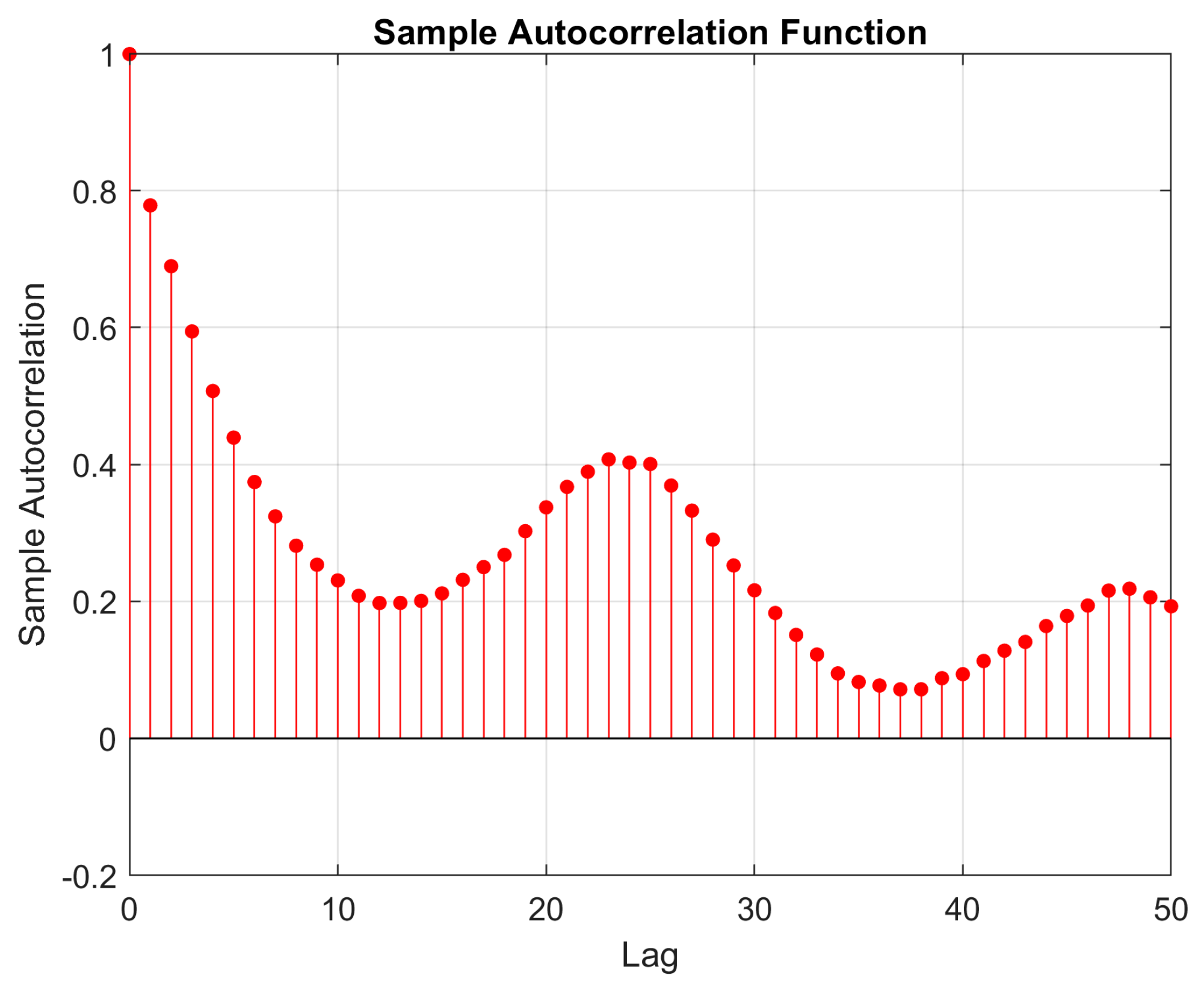
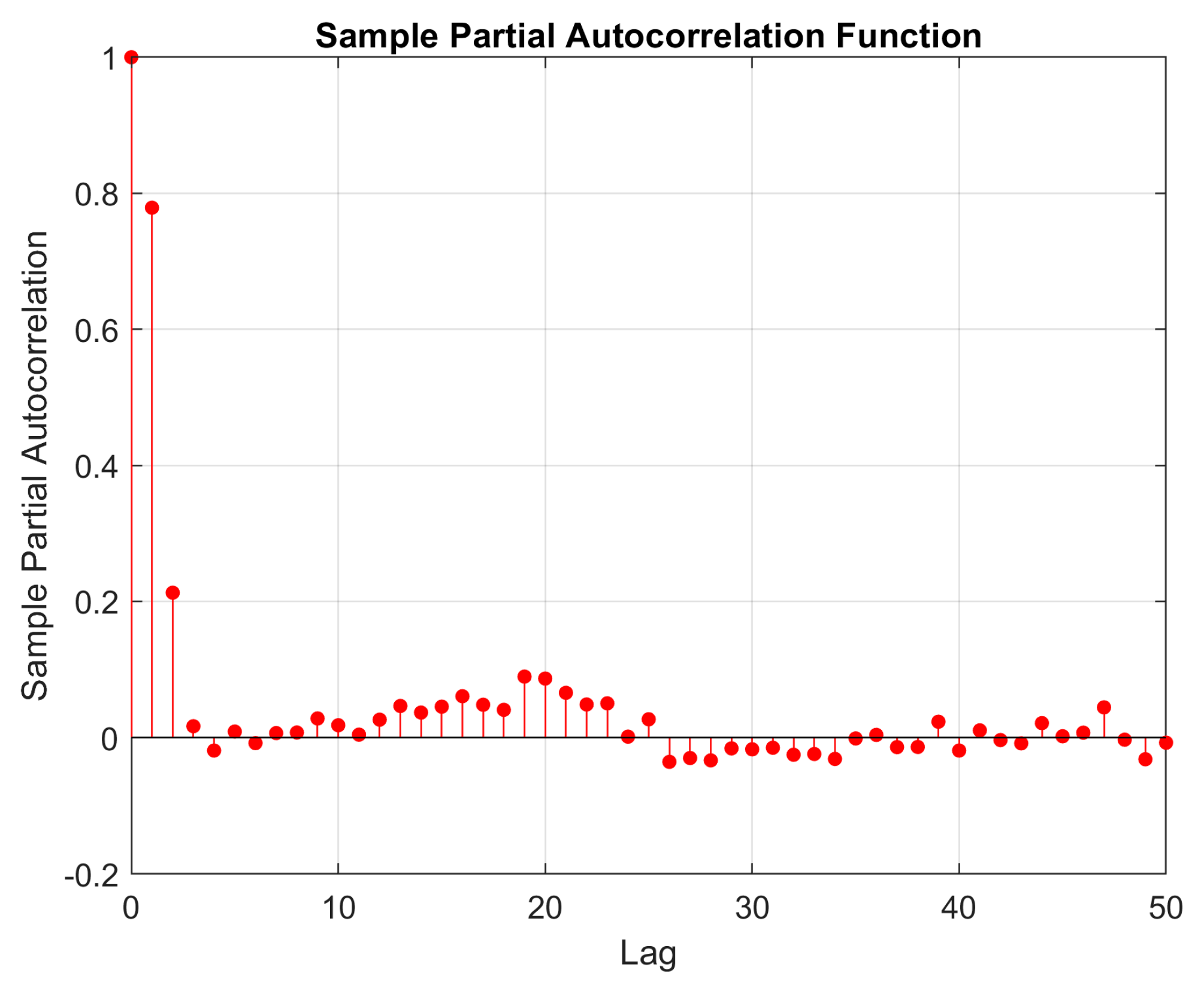
Based on the results presented in
Figure 3 and
Figure 10, the network trained for load demand forecasting appears more susceptible to overfitting compared to the one used for wind power prediction.
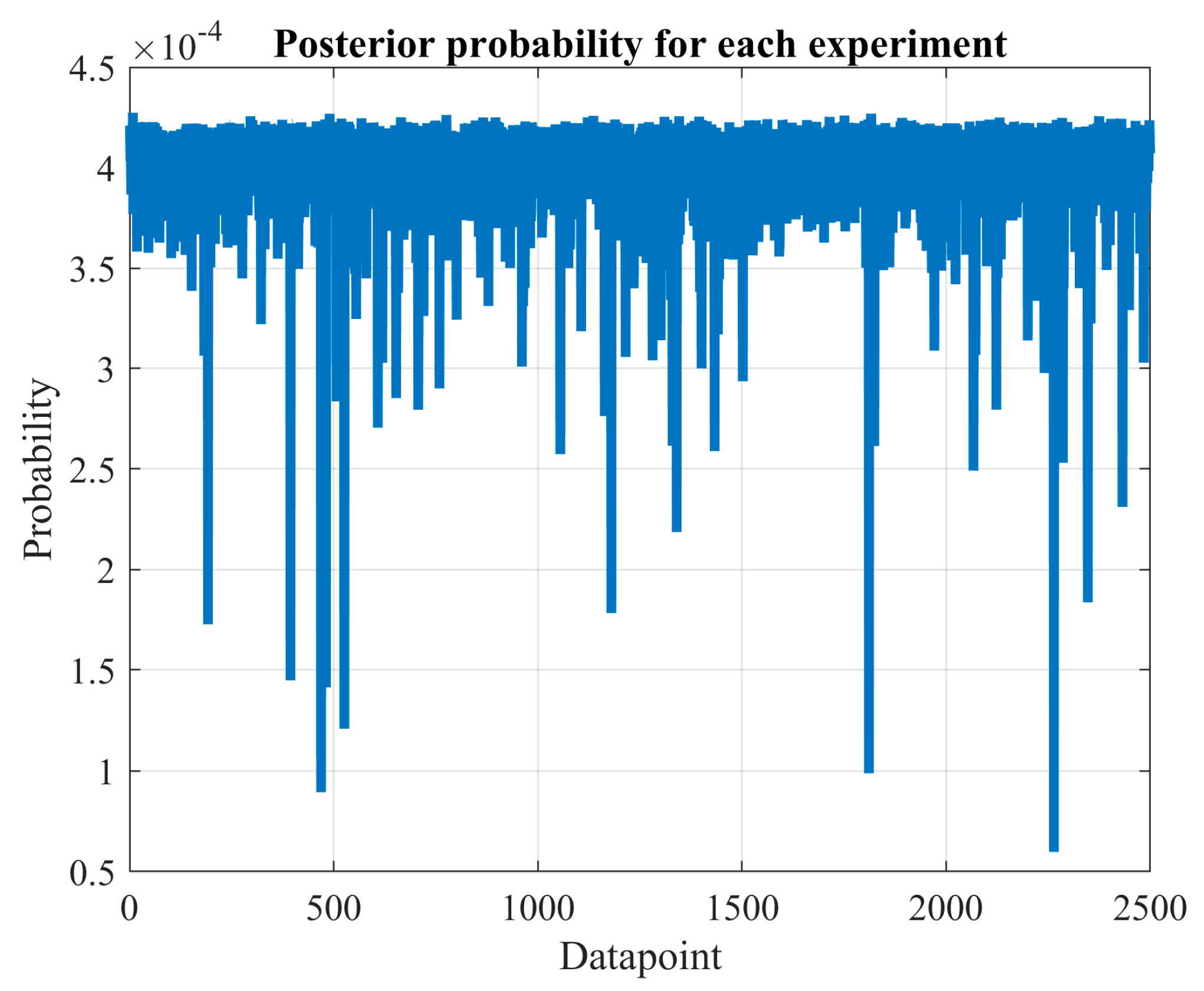
The MCS method introduced in this study can be utilized to formally validate the assumption of accessing all local optima used in Bayesian theory for model selection. This was demonstrated in
Section 3.4, where the hypothesis with the lowest error consistently exhibited the most promising evidence.
In future work, parallel computing can be employed to decrease the computational time required. Additionally, a more precise estimation of the probability of discovering an unseen solution () can be explored. Other neural network architectures might also be considered.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}