
Supervised and Unsupervised Machine Learning Algorithms for Forecasting the Fracture Location in Dissimilar Friction-Stir-Welded Joints


Abstract
:1. Introduction
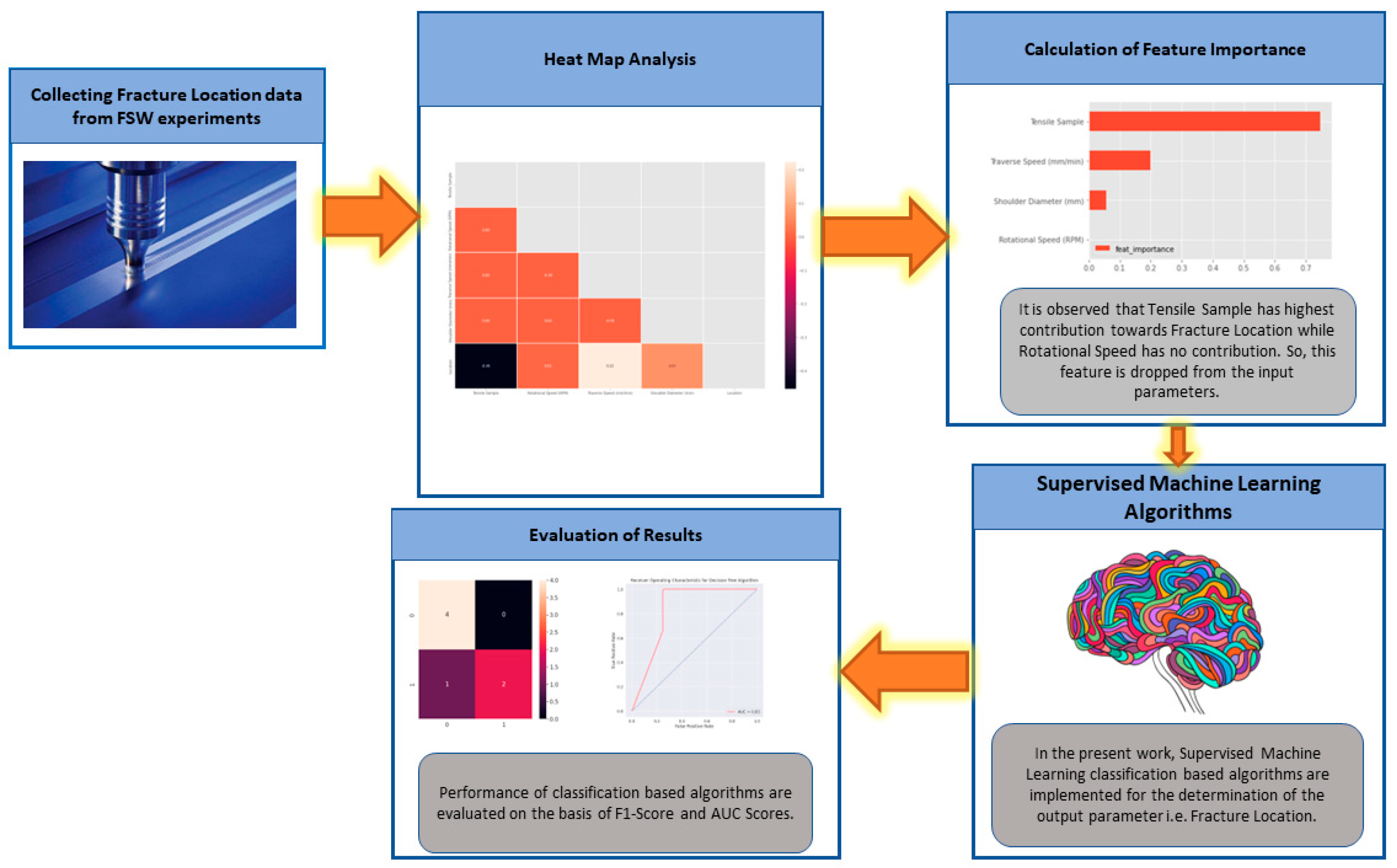
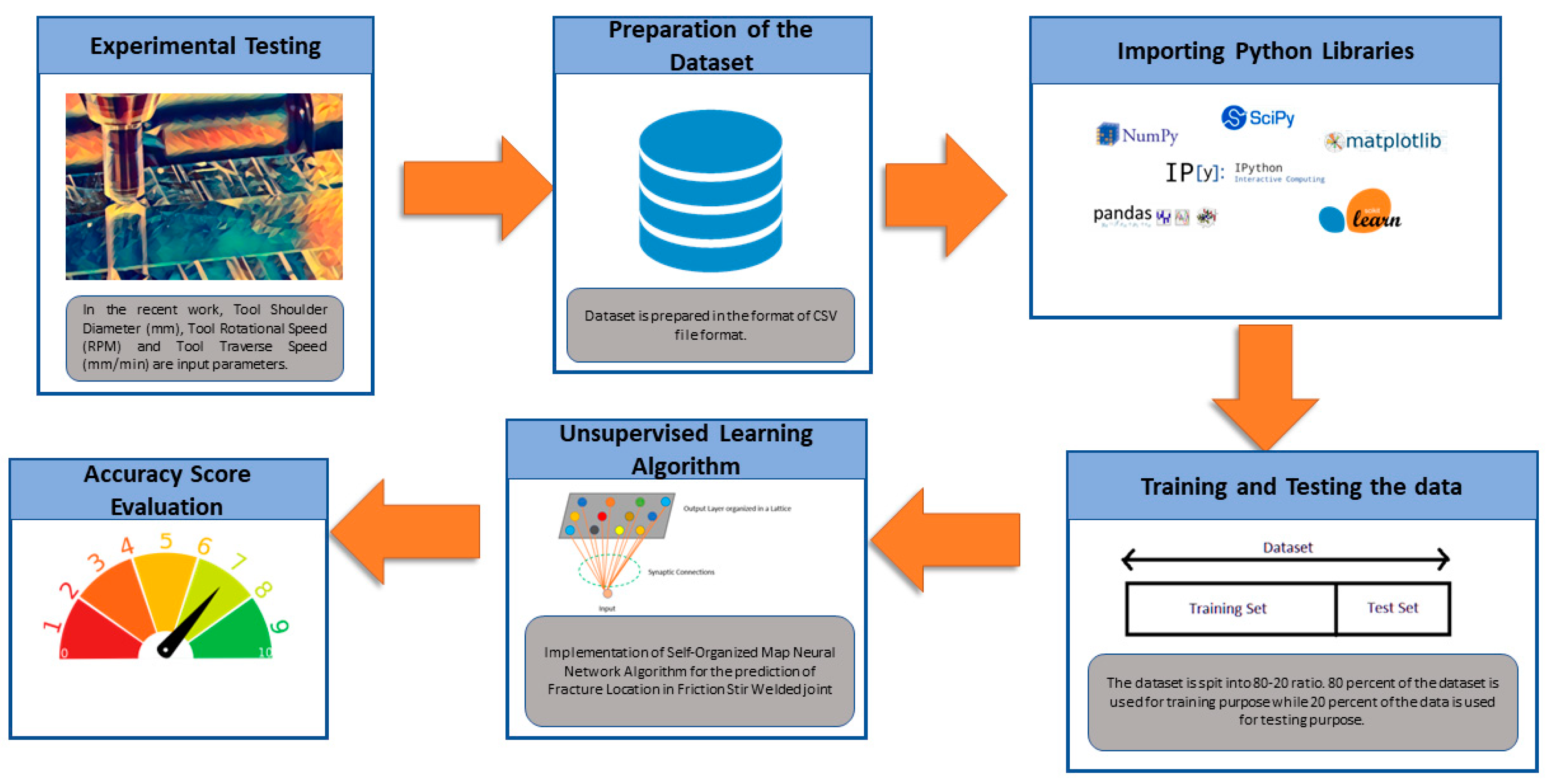
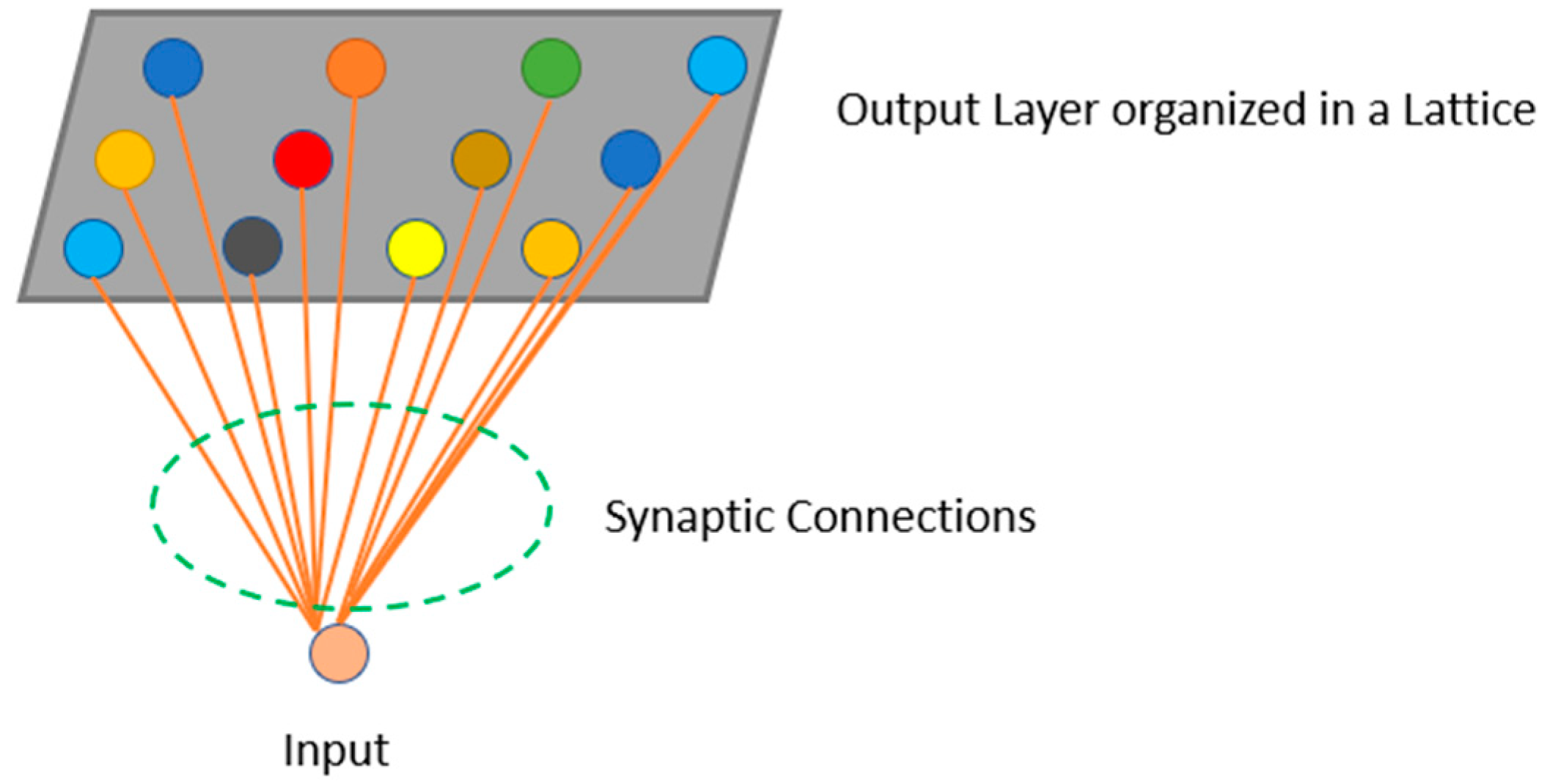
2. Materials and Methods
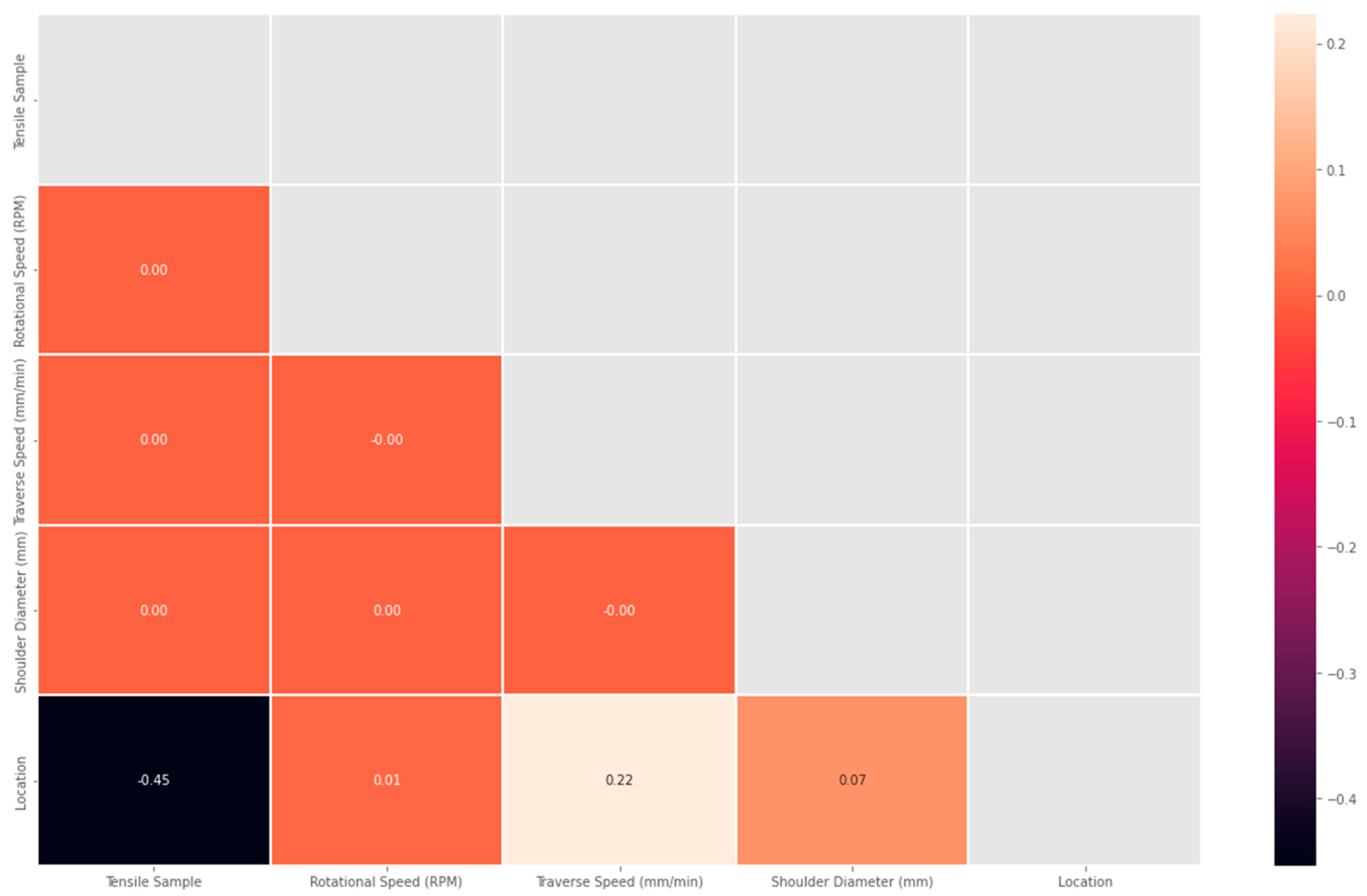
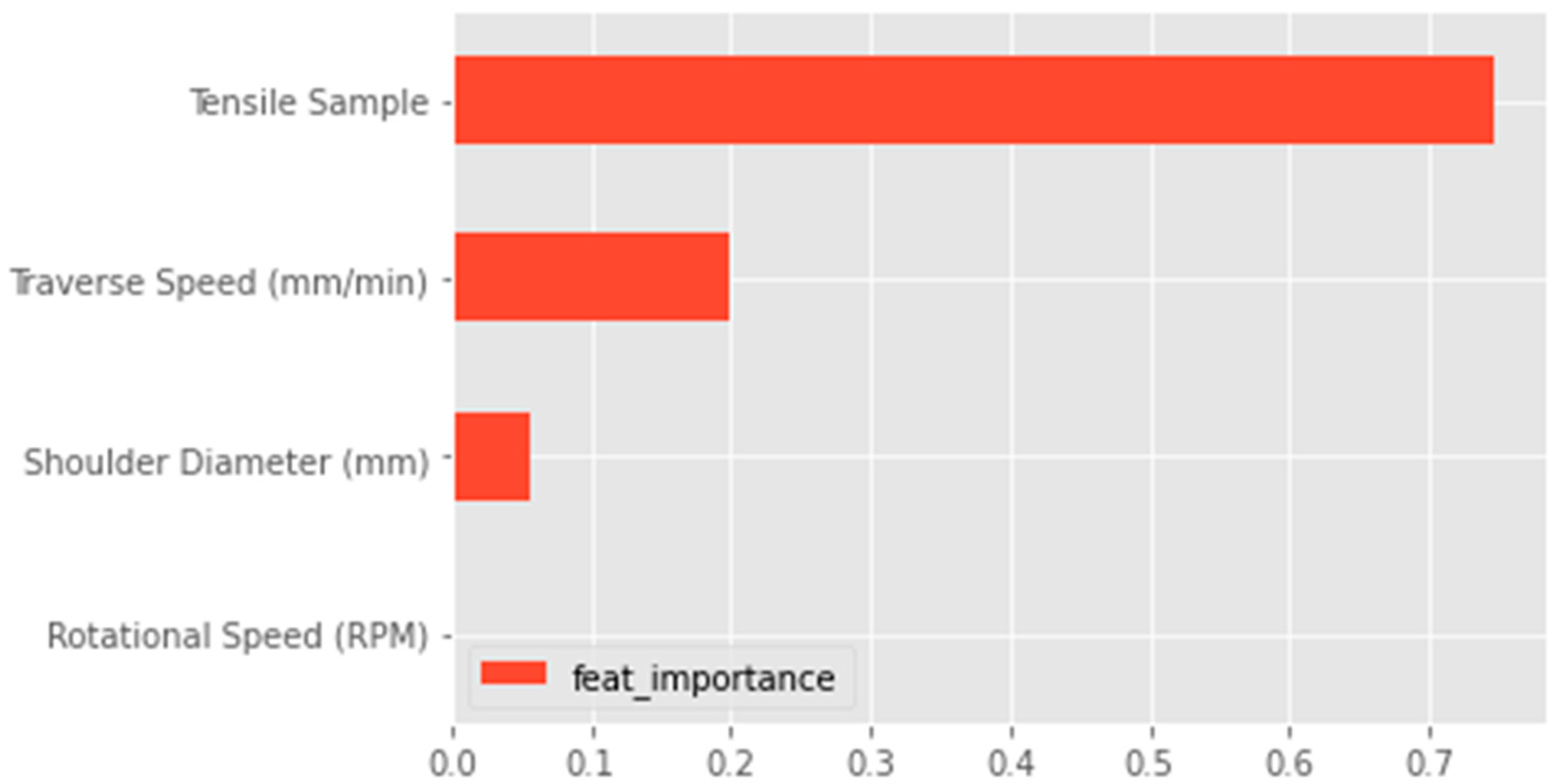
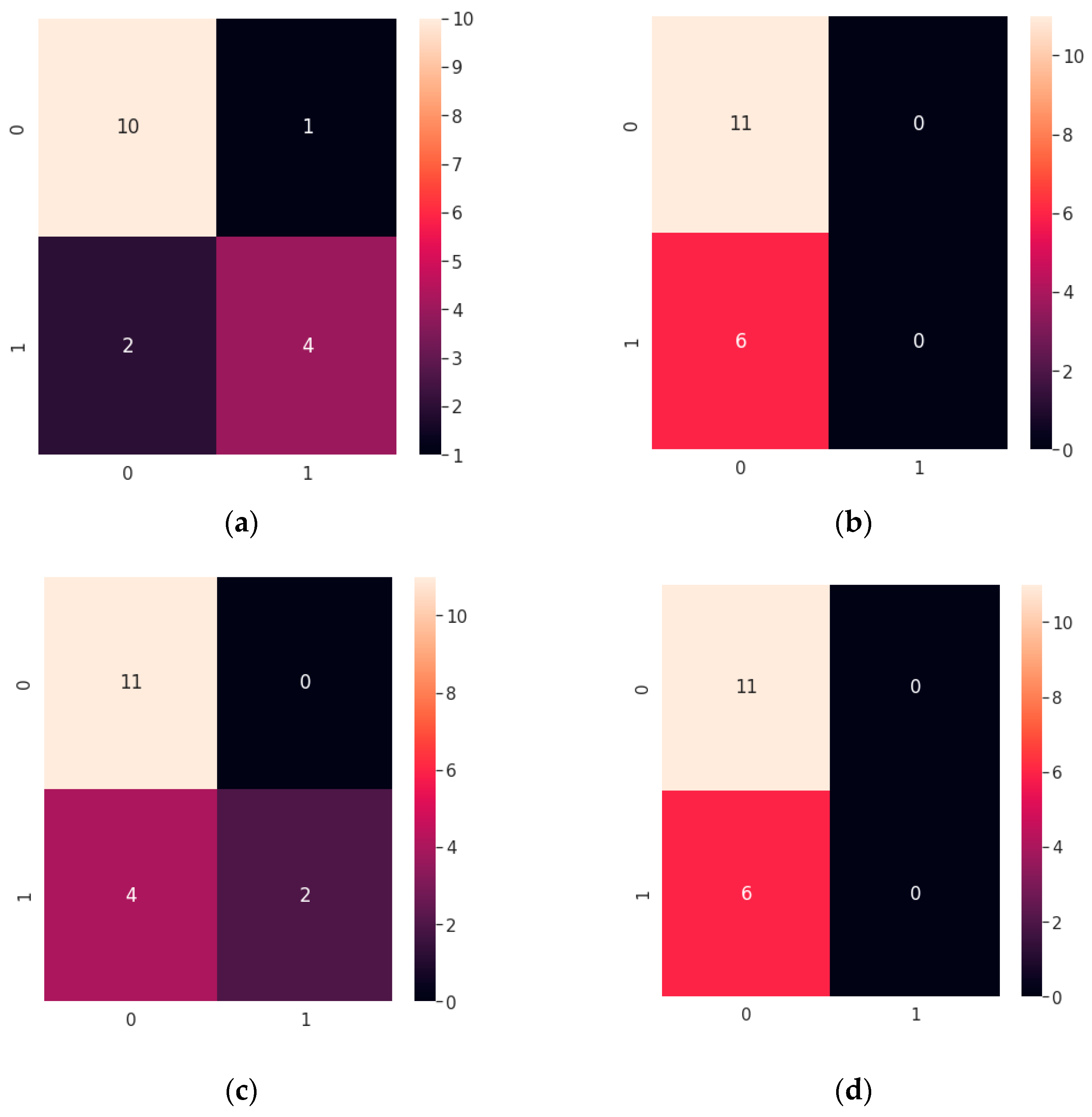
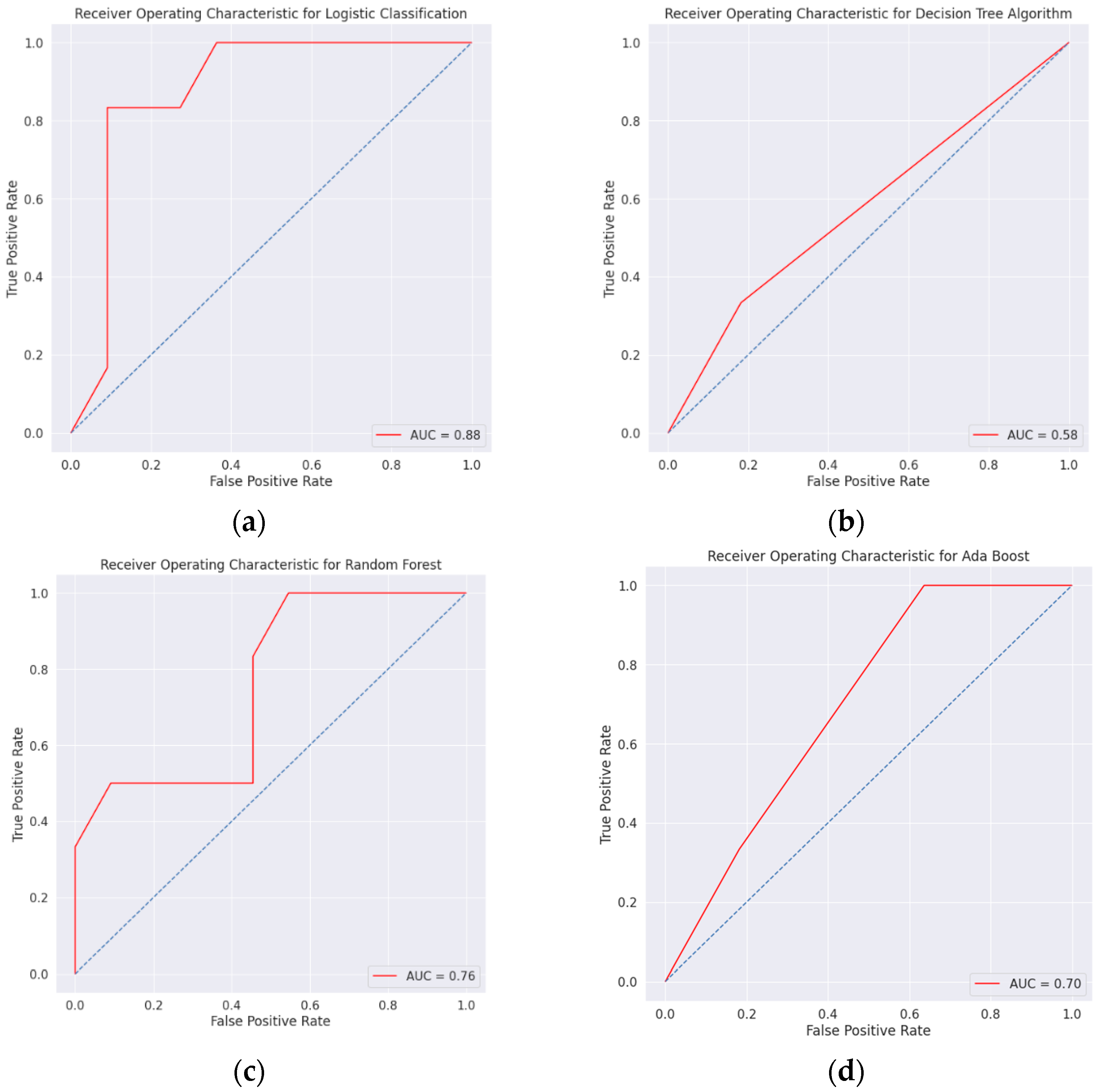
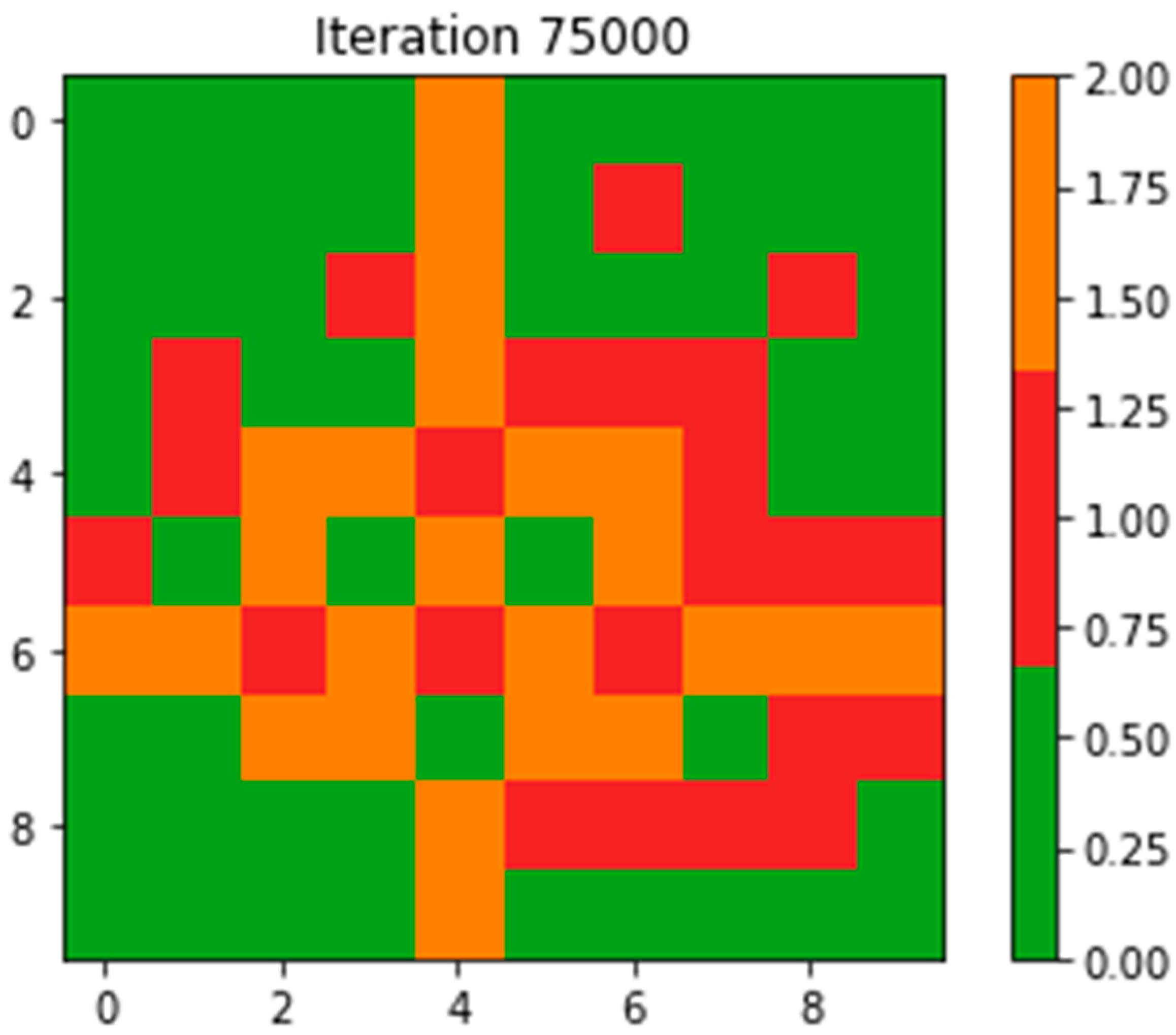
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maren, A.J.; Harston, C.T.; Pap, R.M. Handbook of Neural Computing Applications; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Sumpter, B.G.; Getino, C.; Noid, D.W. Theory and applications of neural computing in chemical science. Annu. Rev. Phys. Chem. 1994, 45, 439–481. [Google Scholar] [CrossRef]
- Xiao, T. Kinetic. jl: A portable finite volume toolbox for scientific and neural computing. J. Open Source Softw. 2021, 6, 3060. [Google Scholar] [CrossRef]
- Zhou, G.; Moayedi, H.; Foong, L.K. Teaching–learning-based metaheuristic scheme for modifying neural computing in appraising energy performance of building. Eng. Comput. 2021, 37, 3037–3048. [Google Scholar] [CrossRef]
- Mumali, F. Artificial neural network-based decision support systems in manufacturing processes: A systematic literature review. Comput. Ind. Eng. 2022, 165, 107964. [Google Scholar] [CrossRef]
- Zhan, P.; Wang, S.; Wang, J.; Qu, L.; Wang, K.; Hu, Y.; Li, X. Temporal anomaly detection on IIoT-enabled manufacturing. J. Intell. Manuf. 2021, 32, 1669–1678. [Google Scholar] [CrossRef]
- Shiau, Y.H.; Yang, S.F.; Adha, R.; Muzayyanah, S. Modeling industrial energy demand in relation to subsector manufacturing output and climate change: Artificial neural network insights. Sustainability 2022, 14, 2896. [Google Scholar] [CrossRef]
- Al-Jarrah, R.; AL-Oqla, F.M. A novel integrated BPNN/SNN artificial neural network for predicting the mechanical performance of green fibers for better composite manufacturing. Compos. Struct. 2022, 289, 115475. [Google Scholar] [CrossRef]
- Hartl, R.; Bachmann, A.; Habedank, J.B.; Semm, T.; Zaeh, M.F. Process monitoring in friction stir welding using convolutional neural networks. Metals 2021, 11, 535. [Google Scholar] [CrossRef]
- Du, Y.; Mukherjee, T.; DebRoy, T. Conditions for void formation in friction stir welding from machine learning. Npj Comput. Mater. 2019, 5, 68. [Google Scholar] [CrossRef]
- Du, Y.; Mukherjee, T.; Mitra, P.; DebRoy, T. Machine learning based hierarchy of causative variables for tool failure in friction stir welding. Acta Mater. 2020, 192, 67–77. [Google Scholar] [CrossRef]
- Cao, X.; Fraser, K.; Song, Z.; Drummond, C.; Huang, H. Machine learning and reduced order computation of a friction stir welding model. J. Comput. Phys. 2022, 454, 110863. [Google Scholar] [CrossRef]
- Anandan, B.; Manikandan, M. Machine Learning approach for predicting the peak temperature of dissimilar AA7050-AA2014A Friction stir welding butt joint using various regression models. Mater. Lett. 2022, 325, 132879. [Google Scholar] [CrossRef]
- Sudhagar, S.; Sakthivel, M.; Ganeshkumar, P. Monitoring of friction stir welding based on vision system coupled with Machine learning algorithm. Measurement 2019, 144, 135–143. [Google Scholar] [CrossRef]
- Verma, S.; Misra, J.P.; Popli, D. Modeling of friction stir welding of aviation grade aluminium alloy using machine learning approaches. Int. J. Model. Simul. 2022, 42, 1–8. [Google Scholar] [CrossRef]
- Dhungana, D.S.; Mallet, N.; Fazzini, P.F.; Larrieu, G.; Cristiano, F.; Plissard, S. Self-catalyzed InAs nanowires grown on Si: The key role of kinetics on their morphology. Nanotechnology 2022, 33, 48. [Google Scholar] [CrossRef]
- Bonaventura, E.; Dhungana, D.S.; Martella, C.; Grazianetti, C.; Macis, S.; Lupi, S.; Bonera, E.; Molle, A. Optical and thermal responses of silicene in Xene heterostructures. Nanoscale Horiz. 2022, 7, 924–930. [Google Scholar] [CrossRef]
- Deman, A.L.; Mekkaoui, S.; Dhungana, D.; Chateaux, J.F.; Tamion, A.; Degouttes, J.; Dupuis, V.; Le Roy, D. Anisotropic composite polymer for high magnetic force in microfluidic systems. Microfluid. Nanofluidics 2017, 21, 170. [Google Scholar] [CrossRef]
- Dhungana, D.S. Growth of InAs and Bi1-xSBx Nanowires on Silicon for Nanoelectronics and Topological Qubits by Molecular Beam Epitaxy. Ph.D. Thesis, Université Paul Sabatier-Toulouse III, Toulouse, France, 2018. [Google Scholar]
- Dhungana, D.S.; Grazianetti, C.; Martella, C.; Achilli, S.; Fratesi, G.; Molle, A. Two-Dimensional Silicene–Stanene Heterostructures by Epitaxy. Adv. Funct. Mater. 2021, 31, 2102797. [Google Scholar] [CrossRef]
- Akinlabi, E.T.; Andrews, A.; Akinlabi, S.A. Effects of processing parameters on corrosion properties of dissimilar friction stir welds of aluminium and copper. Trans. Nonferrous Met. Soc. China 2014, 24, 1323–1330. [Google Scholar] [CrossRef]
- Mishra, A.; Vats, A. Supervised machine learning classification algorithms for detection of fracture location in dissimilar friction stir welded joints. Frat. Integrità Strutt. 2021, 15, 242–253. [Google Scholar] [CrossRef]
- Mishra, A. Machine learning classification models for detection of the fracture location in dissimilar friction stir welded joint. Appl. Eng. Lett. 2020, 5, 87–93. [Google Scholar] [CrossRef]
- Mishra, A. Artificial intelligence algorithms for the analysis of mechanical property of friction stir welded joints by using python programming. Weld. Technol. Rev. 2020, 92, 7–16. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tensile Sample | Rotational Speed (RPM) | Traverse Speed (mm/min) | Shoulder Diameter (mm) | Fracture Location | |
|---|---|---|---|---|---|
| Count | 81 | 81 | 81 | 81 | 81 |
| Mean | 2.000 | 916.666 | 166.666 | 19.333 | 0.320 |
| Std | 0.821 | 247.613 | 103.380 | 4.216 | 0.469 |
| Min | 1.000 | 600.000 | 50.000 | 15.000 | 0.000 |
| 25% | 1.000 | 600.000 | 50.000 | 15.000 | 0.000 |
| 75% | 3.000 | 1200.000 | 300.000 | 25.000 | 1.000 |
| Max | 3.000 | 1200.000 | 300.000 | 25.000 | 1.000 |
| Algorithms | Precision Value of ‘0′ | Precision Value of ‘1′ | Recall Value of ‘0′ | Recall Value of ‘1′ | F1-Score |
|---|---|---|---|---|---|
| Logistic Classification | 0.83 | 0.80 | 0.91 | 0.67 | 0.82 |
| Decision tree | 0.65 | 0.00 | 1.00 | 0.00 | 0.65 |
| Random forest | 0.73 | 1.00 | 1.00 | 0.33 | 0.76 |
| AdaBoost | 0.65 | 0.00 | 1.00 | 0.00 | 0.65 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mishra, A.; Dasgupta, A. Supervised and Unsupervised Machine Learning Algorithms for Forecasting the Fracture Location in Dissimilar Friction-Stir-Welded Joints. Forecasting 2022, 4, 787-797. https://doi.org/10.3390/forecast4040043
Mishra A, Dasgupta A. Supervised and Unsupervised Machine Learning Algorithms for Forecasting the Fracture Location in Dissimilar Friction-Stir-Welded Joints. Forecasting. 2022; 4(4):787-797. https://doi.org/10.3390/forecast4040043
Chicago/Turabian StyleMishra, Akshansh, and Anish Dasgupta. 2022. "Supervised and Unsupervised Machine Learning Algorithms for Forecasting the Fracture Location in Dissimilar Friction-Stir-Welded Joints" Forecasting 4, no. 4: 787-797. https://doi.org/10.3390/forecast4040043