
A Hybrid XGBoost-MLP Model for Credit Risk Assessment on Digital Supply Chain Finance


Abstract
:1. Introduction
2. Literature Review
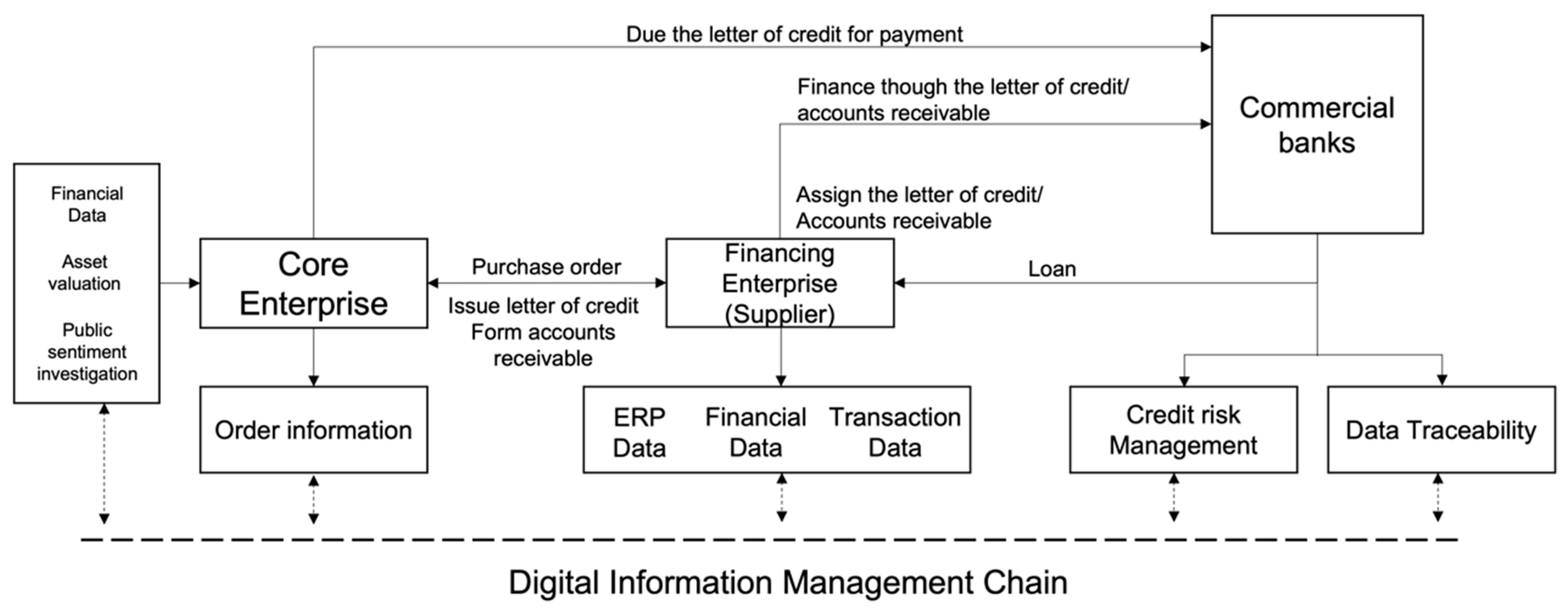
2.1. Background of DSCF
2.2. Machine Learning and Credit Risk Models
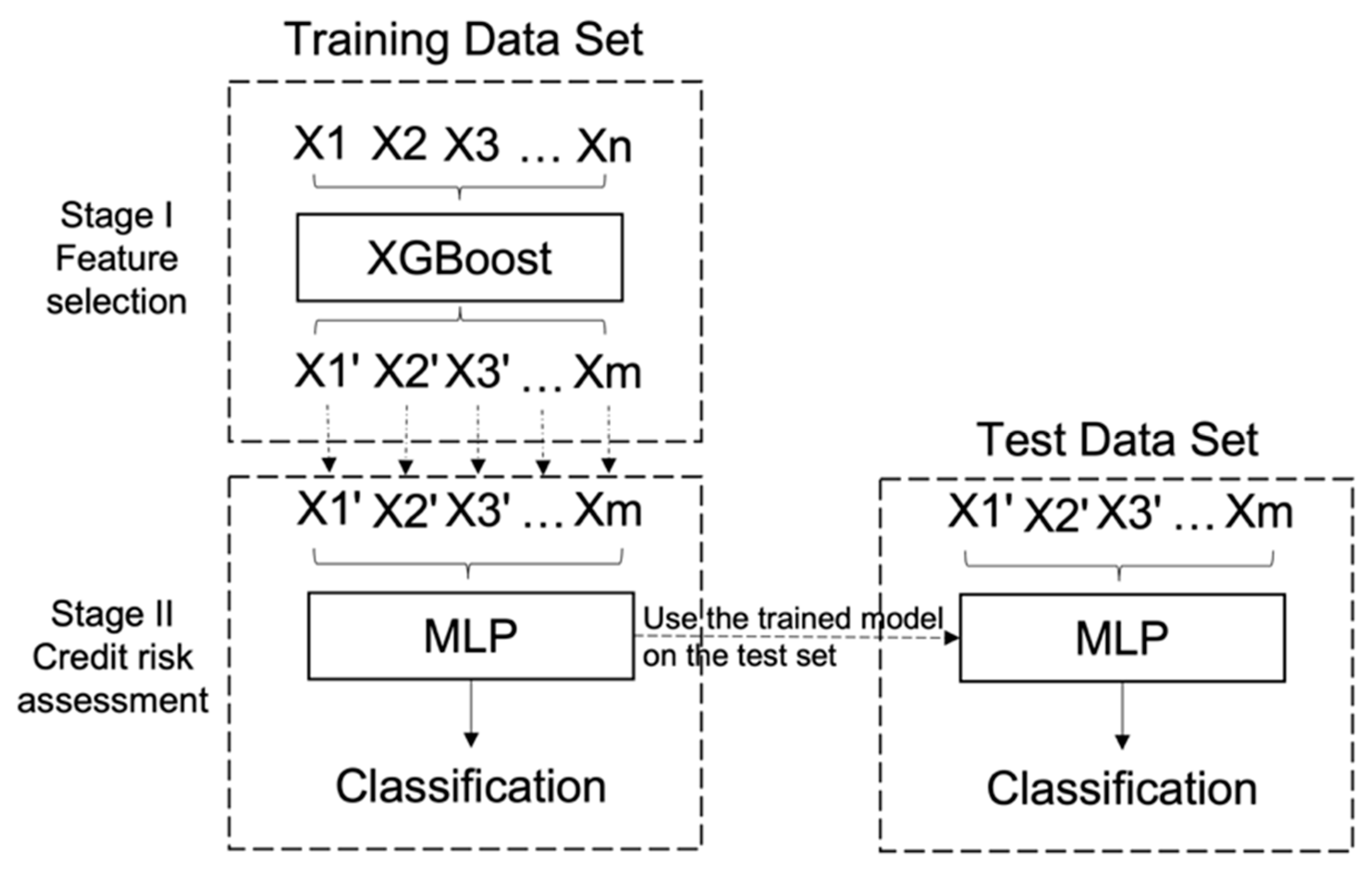
3. Methodology
3.1. Stage I: Feature Selection with XGBoost
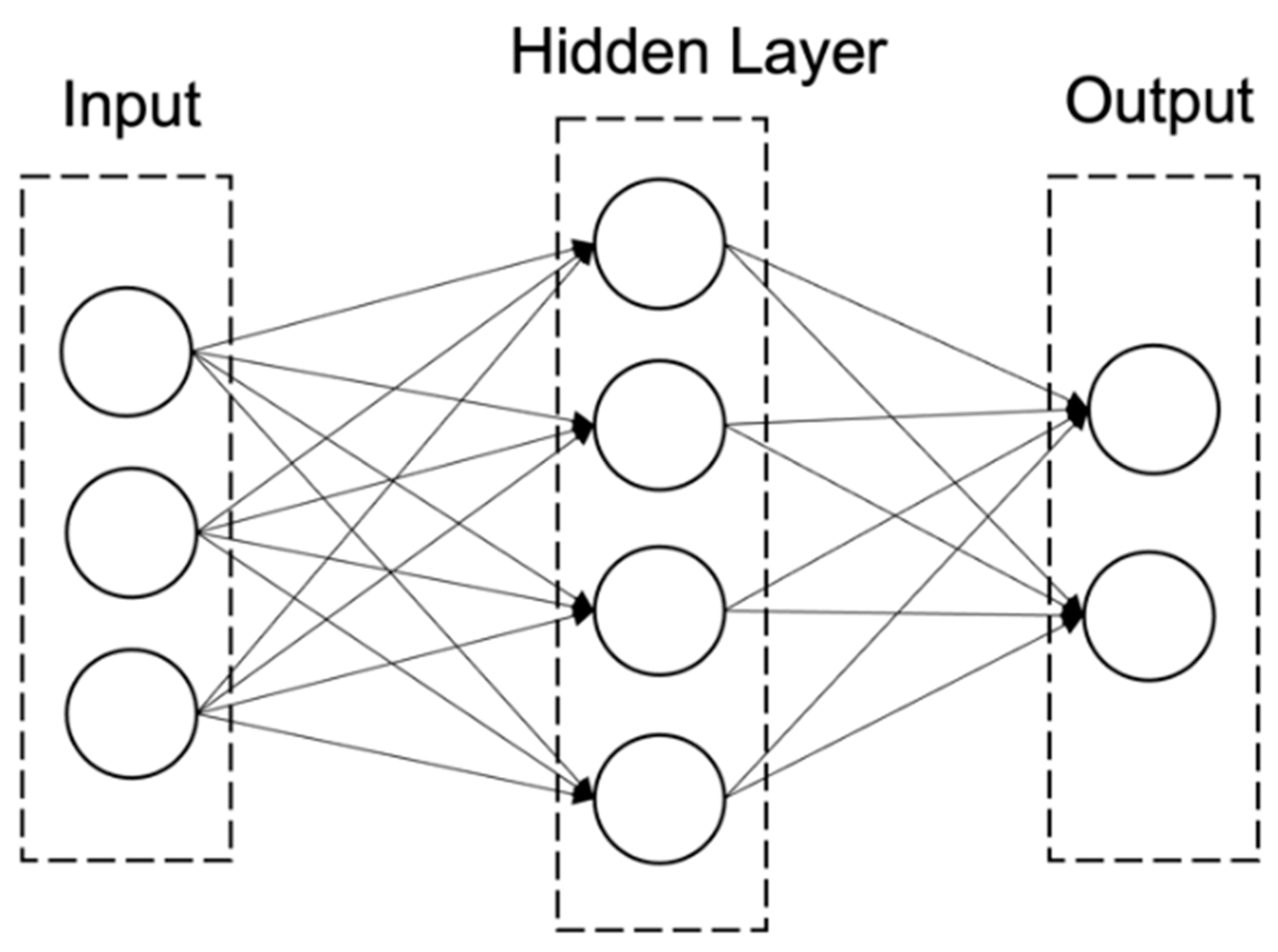
3.2. Stage II: Credit Risk Assessment Models
4. Experimental Design
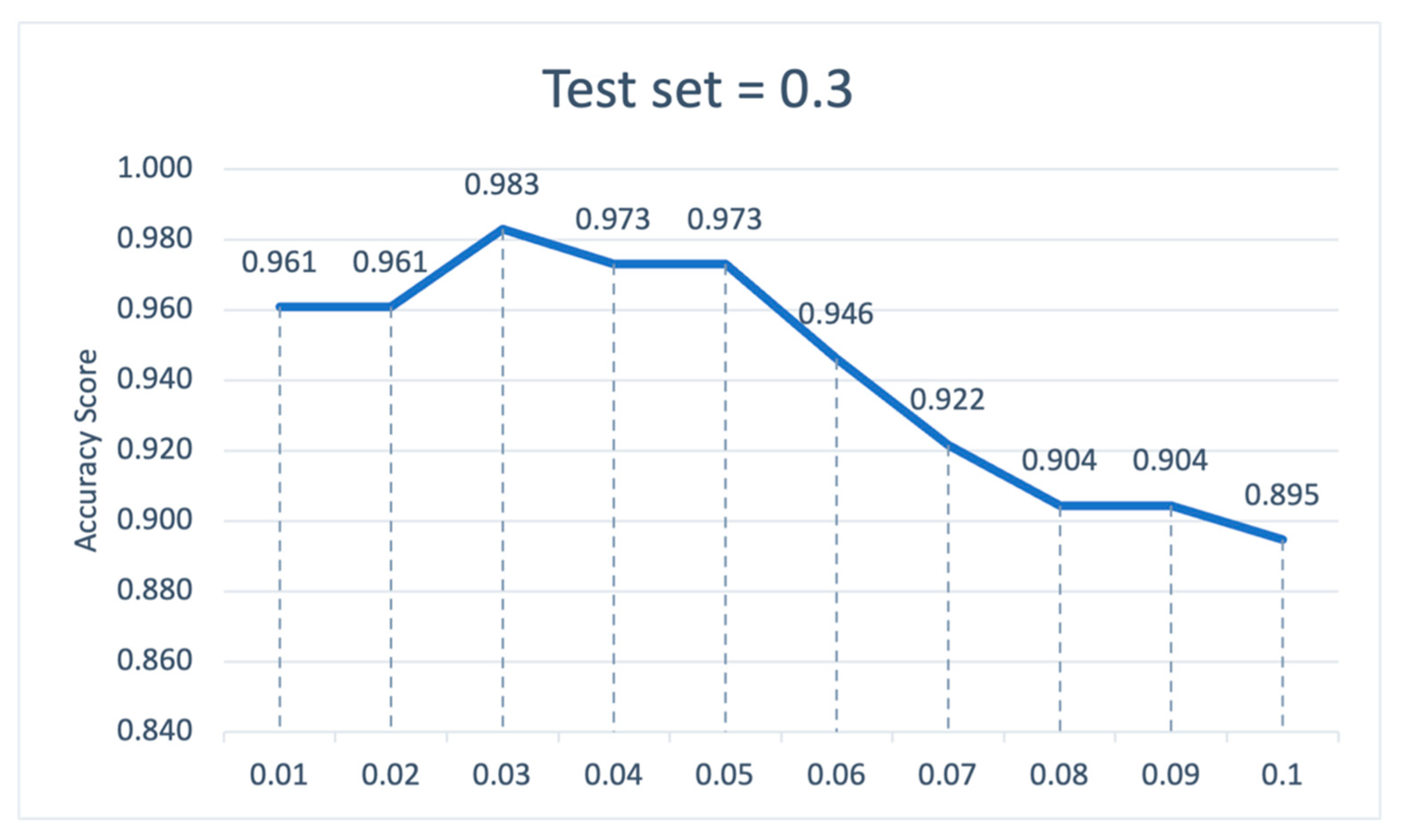
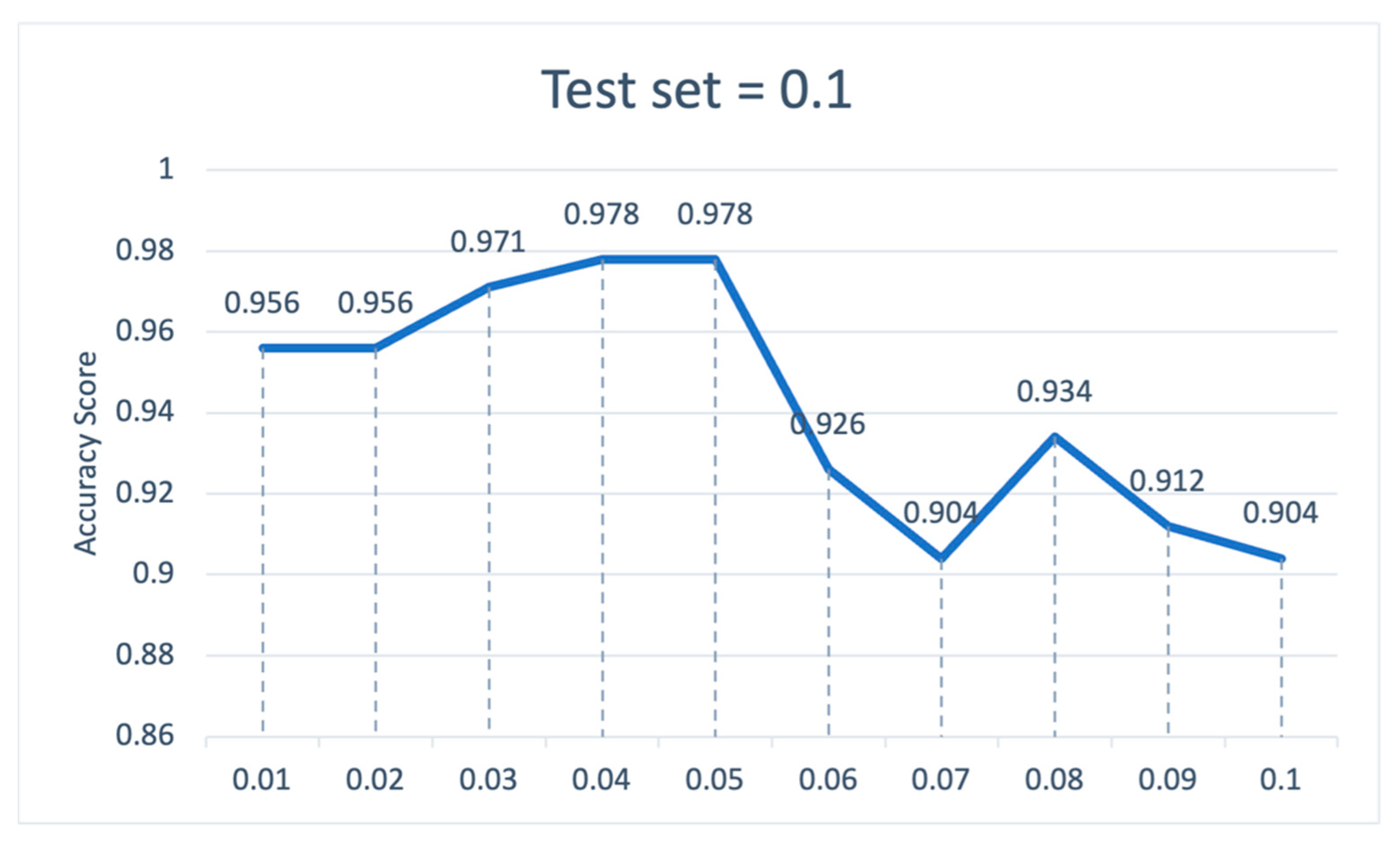
5. Experimental Result
5.1. Model Performance Evaluation
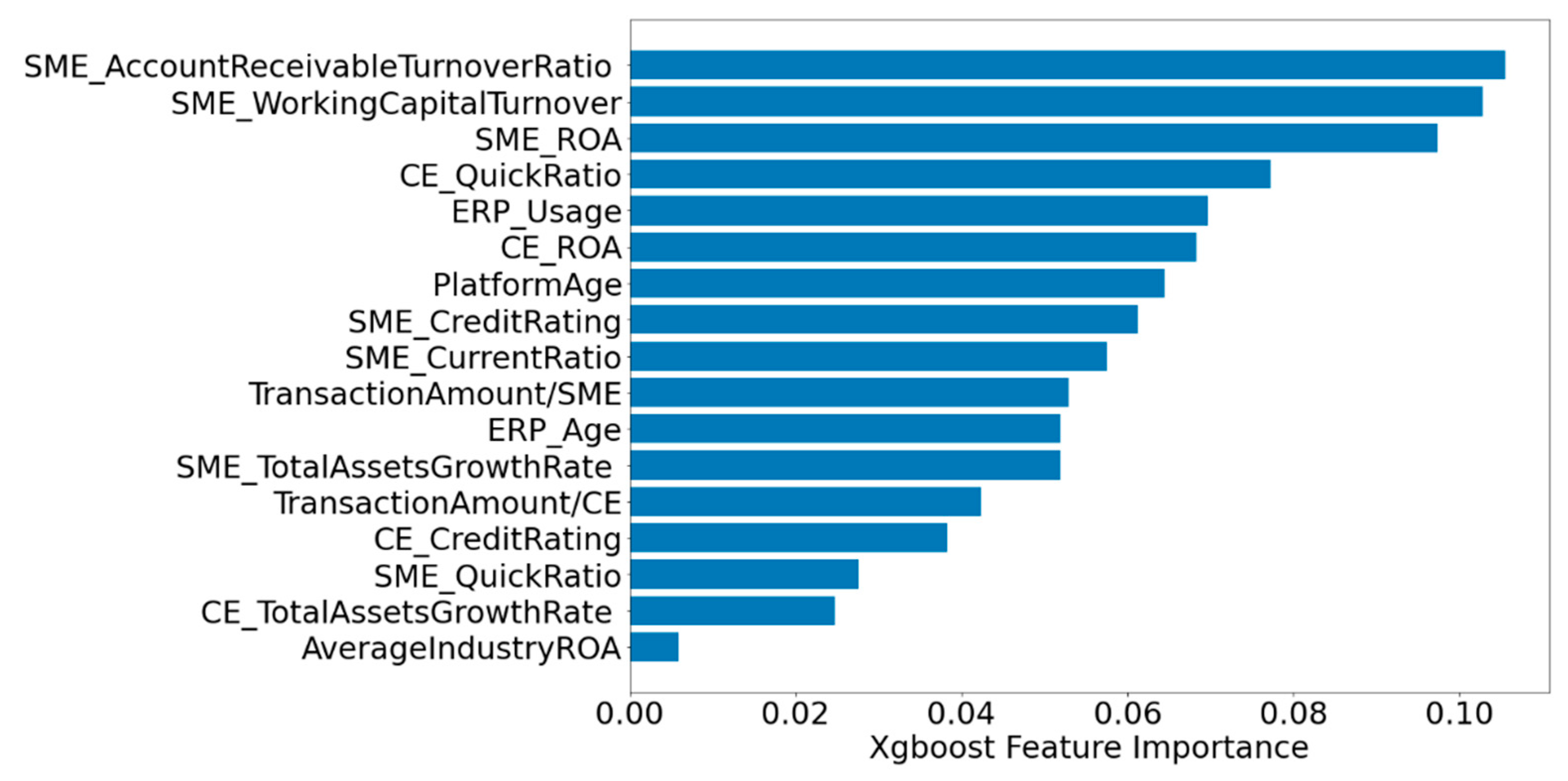
5.2. The Impact of Feature Selection
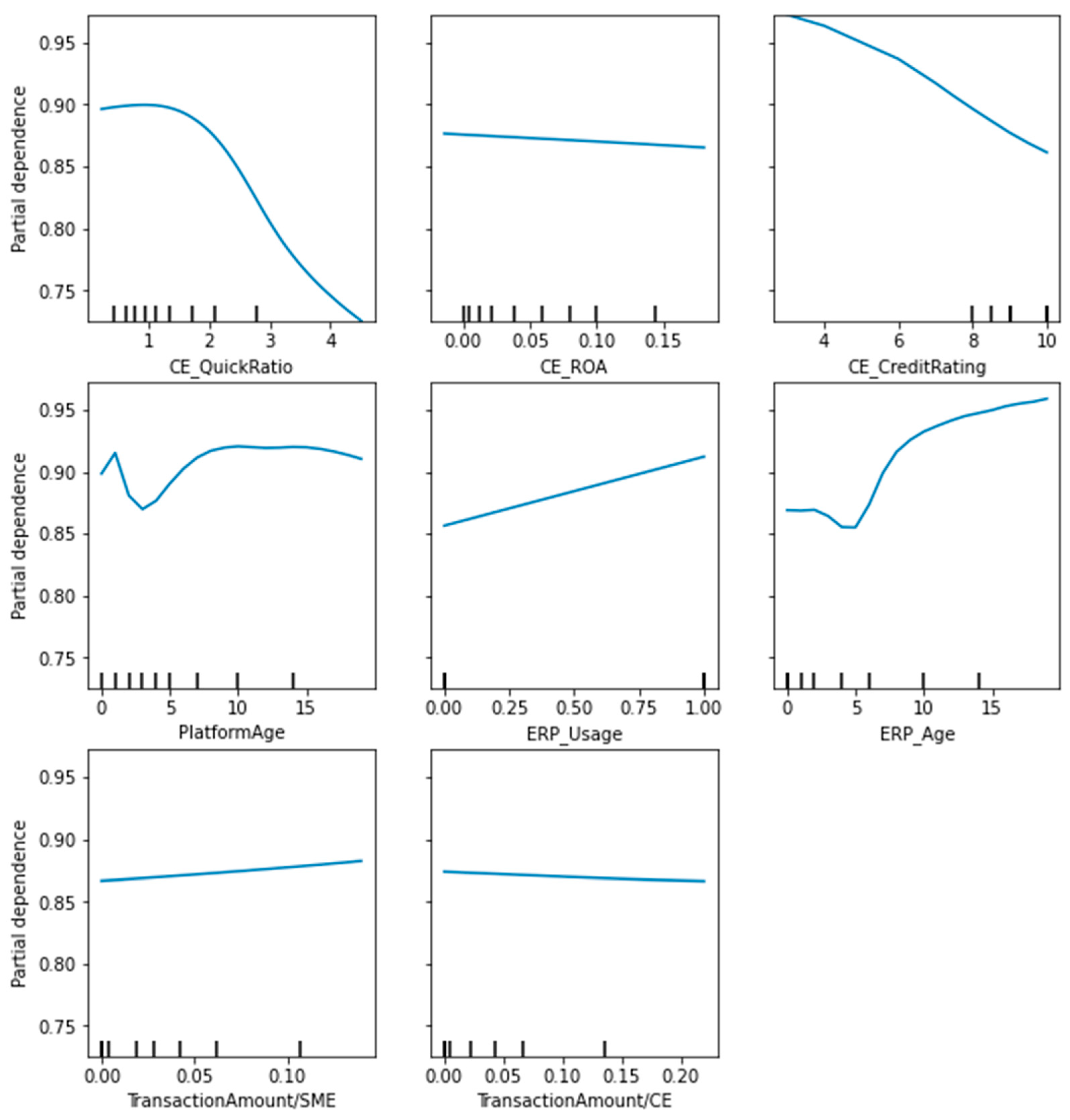
5.3. The Impact of DSCF Feature
6. Robustness Check
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Du, M.; Chen, Q.; Xiao, J.; Yang, H.; Ma, X. Supply Chain Finance Innovation Using Blockchain. IEEE Trans. Eng. Manag. 2020, 67, 1045–1058. [Google Scholar] [CrossRef]
- Scuotto, V.; Caputo, F.; Villasalero, M.; Del Giudice, M. A Multiple Buyer—Supplier Relationship in the Context of SMEs’ Digital Supply Chain Management. Prod. Plan. Control 2017, 28, 1378–1388. [Google Scholar] [CrossRef]
- Korpela, K.; Hallikas, J.; Dahlberg, T. Digital Supply Chain Transformation toward Blockchain Integration. In Proceedings of the 50th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 4–7 January 2017. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, A.; Lücker, F.; Ries, J.M. An Empirical Analysis of Suppliers’ Trade-off Behaviour in Adopting Digital Supply Chain Financing Solutions. IJOPM 2021, 41, 313–335. [Google Scholar] [CrossRef]
- Ivanov, D.; Dolgui, A. A Digital Supply Chain Twin for Managing the Disruption Risks and Resilience in the Era of Industry 4.0. Prod. Plan. Control 2021, 32, 775–788. [Google Scholar] [CrossRef]
- Denison, D.G.; Holmes, C.C.; Mallick, B.K.; Smith, A.F. Bayesian Methods for Nonlinear Classification and Regression; John Wiley & Sons: Hoboken, NJ, USA, 2002; Volume 386. [Google Scholar]
- Khemakhem, S.; Boujelbene, Y. Artificial Intelligence for Credit Risk Assessment: Artificial Neural Network and Support Vector Machines. ACRN Oxf. J. Financ. Risk Perspect. 2017, 6, 1–17. [Google Scholar]
- Danenas, P.; Garsva, G. Credit Risk Evaluation Modeling Using Evolutionary Linear SVM Classifiers and Sliding Window Approach. Procedia Comput. Sci. 2012, 9, 1324–1333. [Google Scholar] [CrossRef] [Green Version]
- Bahnsen, A.C.; Gonzalez, A.M. Evolutionary Algorithms for Selecting the Architecture of a MLP Neural Network: A Credit Scoring Case. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 725–732. [Google Scholar] [CrossRef]
- Wang, F.; Ding, L.; Yu, H.; Zhao, Y. Big Data Analytics on Enterprise Credit Risk Evaluation of E-Business Platform. Inf. Syst. E-Bus. Manag. 2020, 18, 311–350. [Google Scholar] [CrossRef]
- Timme, S.G.; Williams-Timme, C. The Financial-SCM Connection. Supply Chain. Manag. Rev. 2000, 4, 33–40. [Google Scholar]
- Berger, A.N.; Demirguc-Kunt, A.; Levine, R.; Haubrich, J.G. Bank Concentration and Competition: An Evolution in the Making. J. Money Credit Bank. 2004, 36, 433–451. [Google Scholar] [CrossRef]
- Hofmann, E. Supply Chain Finance—Some Conceptual Insights. In Logistik Management; Lasch, R., Janker, C.G., Eds.; Deutscher Universitätsverlag: Wiesbaden, Germany, 2005; pp. 203–214. [Google Scholar] [CrossRef]
- Kerle, P. Steady Supply: The Growing Role of Supply Chain Finance in Europe. Supply Chain. Eur. 2007, 16, 18. [Google Scholar]
- Camerinelli, E. Supply Chain Finance. J. Paym. Strategy Syst. 2009, 3, 114–128. [Google Scholar]
- Lyons, A.C.; Mondragon, A.E.C.; Piller, F.; Poler, R. Supply Chain Performance Measurement. In Customer-Driven Supply Chains; Springer: Berlin/Heidelberg, Germany, 2012; pp. 133–148. [Google Scholar]
- Guillén, G.; Badell, M.; Puigjaner, L. A Holistic Framework for Short-Term Supply Chain Management Integrating Production and Corporate Financial Planning. Int. J. Prod. Econ. 2007, 106, 288–306. [Google Scholar] [CrossRef]
- Gomm, M.L. Supply Chain Finance: Applying Finance Theory to Supply Chain Management to Enhance Finance in Supply Chains. Int. J. Logist. Res. Appl. 2010, 13, 133–142. [Google Scholar] [CrossRef]
- Caniato, F.; Gelsomino, L.M.; Perego, A.; Ronchi, S. Does Finance Solve the Supply Chain Financing Problem? SCM 2016, 21, 534–549. [Google Scholar] [CrossRef]
- Wuttke, D.A.; Blome, C.; Henke, M. Focusing the Financial Flow of Supply Chains: An Empirical Investigation of Financial Supply Chain Management. Int. J. Prod. Econ. 2013, 145, 773–789. [Google Scholar] [CrossRef]
- Wandfluh, M.; Hofmann, E.; Schoensleben, P. Financing Buyer–Supplier Dyads: An Empirical Analysis on Financial Collaboration in the Supply Chain. Int. J. Logist. Res. Appl. 2016, 19, 200–217. [Google Scholar] [CrossRef]
- Atkinson, W. Supply Chain Finance: The next Big Opportunity. Supply Chain Manag. Rev. 2008, 12, 57–60. [Google Scholar]
- Gobbi, G.; Sette, E. Do Firms Benefit from Concentrating Their Borrowing? Evidence from the Great Recession. Rev. Financ. 2014, 18, 527–560. [Google Scholar] [CrossRef]
- Jing, B.; Seidmann, A. Finance Sourcing in a Supply Chain. Decis. Support Syst. 2014, 58, 15–20. [Google Scholar] [CrossRef]
- Goldfarb, A.; Tucker, C. Digital Economics. J. Econ. Lit. 2019, 57, 3–43. [Google Scholar] [CrossRef] [Green Version]
- Hallikas, J.; Virolainen, V.-M.; Tuominen, M. Risk Analysis and Assessment in Network Environments: A Dyadic Case Study. Int. J. Prod. Econ. 2002, 78, 45–55. [Google Scholar] [CrossRef]
- Finch, P. Supply Chain Risk Management. Supply Chain Manag. 2004, 9, 183–196. [Google Scholar] [CrossRef]
- Yurdakul, M.; İç, Y.T. AHP Approach in the Credit Evaluation of the Manufacturing Firms in Turkey. Int. J. Prod. Econ. 2004, 88, 269–289. [Google Scholar] [CrossRef]
- Ghadge, A.; Dani, S.; Chester, M.; Kalawsky, R. A Systems Approach for Modelling Supply Chain Risks. Supply Chain Manag. 2013, 18, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Xie, C.; Wang, G.-J.; Yan, X.-G. Comparison of Individual, Ensemble and Integrated Ensemble Machine Learning Methods to Predict China’s SME Credit Risk in Supply Chain Finance. Neural Comput. Appl. 2017, 28, 41–50. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhou, L.; Xie, C.; Wang, G.-J.; Nguyen, T.V. Forecasting SMEs’ Credit Risk in Supply Chain Finance with an Enhanced Hybrid Ensemble Machine Learning Approach. Int. J. Prod. Econ. 2019, 211, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Orgler, Y.E. A Credit Scoring Model for Commercial Loans. J. Money Credit Bank. 1970, 2, 435. [Google Scholar] [CrossRef]
- Fitzpatrick, D.B. An Analysis of Bank Credit Card Profit. J. Bank Res. 1976, 7, 199–205. [Google Scholar]
- Lucas, A. Updating Scorecards: Removing the Mystique. In Credit Scoring and Credit Control; Thomas, L.C., Crook, J.N., Edelman, D.B., Eds.; Oxford University Press: Oxford, UK, 1992; pp. 180–197. [Google Scholar]
- Henley, W.E. Statistical Aspects of Credit Scoring; Open University: Milton Keynes, UK, 1995. [Google Scholar] [CrossRef]
- Wiginton, J.C. A Note on the Comparison of Logit and Discriminant Models of Consumer Credit Behavior. J. Financ. Quant. Anal. 1980, 15, 757. [Google Scholar] [CrossRef]
- Steenackers, A.; Goovaerts, M. A Credit Scoring Model for Personal Loans. Insur. Math. Econ. 1989, 8, 31–34. [Google Scholar] [CrossRef]
- Cramer, J.S. Scoring Bank Loans That May Go Wrong: A Case Study. Stat. Neerl. 2004, 58, 365–380. [Google Scholar] [CrossRef] [Green Version]
- Grablowsky, B.J.; Talley, W.K. Probit and Discriminant Functions for Classifying Credit Applicants-a Comparison. J. Econ. Bus. 1981, 33, 254–261. [Google Scholar]
- Makowski, P. Credit Scoring Branches Out. Credit World 1985, 75, 30–37. [Google Scholar]
- Carter, C.; Catlett, J. Assessing Credit Card Applications Using Machine Learning. IEEE Comput. Archit. Lett. 1987, 2, 71–79. [Google Scholar] [CrossRef]
- Cover, T. Estimation by the Nearest Neighbor Rule. IEEE Trans. Inf. Theory 1968, 14, 50–55. [Google Scholar] [CrossRef] [Green Version]
- Henley, W.E.; Hand, D.J. A K-Nearest-Neighbour Classifier for Assessing Consumer Credit Risk. Statistician 1996, 45, 77. [Google Scholar] [CrossRef]
- Hand, D.J. Discrimination and Classification; Wiley Series in Probability and Mathematical Statistics; Wiley: Chichester, UK, 1981. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: Burlington, MA, USA, 1988. [Google Scholar]
- Hsieh, N.-C.; Hung, L.-P. A Data Driven Ensemble Classifier for Credit Scoring Analysis. Expert Syst. Appl. 2010, 37, 534–545. [Google Scholar] [CrossRef]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Langley, P.; Iba, W.; Thompson, K. An Analysis of Bayesian Classi Ers. In Proceedings of the Tenth Na-Tional Conference on Articial Intelligence, San Jose, CA, USA, 12–16 July 1992; p. 15. [Google Scholar]
- Do Prado, J.W.; de Castro Alcântara, V.; de Melo Carvalho, F.; Vieira, K.C.; Machado, L.K.C.; Tonelli, D.F. Multivariate Analysis of Credit Risk and Bankruptcy Research Data: A Bibliometric Study Involving Different Knowledge Fields (1968–2014). Scientometrics 2016, 106, 1007–1029. [Google Scholar] [CrossRef]
- Odom, M.D.; Sharda, R. A Neural Network Model for Bankruptcy Prediction. In Proceedings of the 1990 IJCNN International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; Volume 2, pp. 163–168. [Google Scholar] [CrossRef]
- Davis, R.H.; Edelman, D.B.; Gammerman, A.J. Machine-Learning Algorithms for Credit-Card Applications. IMA J. Manag. Math 1992, 4, 43–51. [Google Scholar] [CrossRef]
- Desai, V.S.; Conwayf, D.G.; Crookj, J.N.; Overstreet, G.A., Jr. Credit-Scoring Models in the Credit-Onion Environment Using Neural Networks and Genetic Algorithms. IMA J. Manag. Math. 1997, 8, 323–346. [Google Scholar] [CrossRef]
- Piramuthu, S. Financial Credit-Risk Evaluation with Neural and Neurofuzzy Systems. Eur. J. Oper. Res. 1999, 112, 310–321. [Google Scholar] [CrossRef]
- Lee, T.; Chen, I. A Two-Stage Hybrid Credit Scoring Model Using Artificial Neural Networks and Multivariate Adaptive Regression Splines. Expert Syst. Appl. 2005, 28, 743–752. [Google Scholar] [CrossRef]
- Tsai, C.-F. Financial Decision Support Using Neural Networks and Support Vector Machines. Expert Syst. 2008, 25, 380–393. [Google Scholar] [CrossRef]
- Marcano-Cedeño, A.; Marin-De-La-Barcena, A.; Jimenez-Trillo, J.; Piñuela, J.A.; Andina, D. Artificial Metaplasticity Neural Network Applied to Credit Scoring. Int. J. Neur. Syst. 2011, 21, 311–317. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Stecking, R.; Schebesch, K.B. Variable Subset Selection for Credit Scoring with Support Vector Machines. In Operations Research Proceedings 2005; Haasis, H.-D., Kopfer, H., Schönberger, J., Eds.; Operations Research Proceedings; Springer: Berlin/Heidelberg, Germany, 2006; Volume 2005, pp. 251–256. [Google Scholar] [CrossRef]
- Lai, K.K.; Yu, L.; Huang, W.; Wang, S. A Novel Support Vector Machine Metamodel for Business Risk Identification. In PRICAI 2006: Trends in Artificial Intelligence; Yang, Q., Webb, G., Eds.; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., et al., Series Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4099, pp. 980–984. [Google Scholar] [CrossRef]
- Schebesch, K.B.; Stecking, R. Using Multiple SVM Models for Unbalanced Credit Scoring Data Sets. In Data Analysis, Machine Learning and Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 515–522. [Google Scholar]
- Yu, L.; Wang, S.; Lai, K.K. Developing an SVM-Based Ensemble Learning System for Customer Risk Identification Collaborating with Customer Relationship Management. Front. Comput. Sci. China 2010, 4, 196–203. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: San Francisco, CA, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 1984. [Google Scholar]
- Sermpinis, G.; Dunis, C.; Laws, J.; Stasinakis, C. Forecasting and Trading the EUR/USD Exchange Rate with Stochastic Neural Network Combination and Time-Varying Leverage. Decis. Support Syst. 2012, 54, 316–329. [Google Scholar] [CrossRef]
- Crook, J.N.; Edelman, D.B.; Thomas, L.C. Recent Developments in Consumer Credit Risk Assessment. Eur. J. Oper. Res. 2007, 183, 1447–1465. [Google Scholar] [CrossRef]
- Hassanniakalager, A.; Sermpinis, G.; Stasinakis, C.; Verousis, T. A Conditional Fuzzy Inference Approach in Forecasting. Eur. J. Oper. Res. 2020, 283, 196–216. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Sermpinis, G.; Stasinakis, C.; Hassanniakalager, A. Reverse Adaptive Krill Herd Locally Weighted Support Vector Regression for Forecasting and Trading Exchange Traded Funds. Eur. J. Oper. Res. 2017, 263, 540–558. [Google Scholar] [CrossRef] [Green Version]
- Rish, I. An Empirical Study of the Naive Bayes Classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Antonakis, A.C.; Sfakianakis, M.E. Assessing Naive Bayes as a Method for Screening Credit Applicants. J. Appl. Stat. 2009, 36, 537–545. [Google Scholar] [CrossRef]
- Hassanniakalager, A.; Sermpinis, G.; Stasinakis, C. Trading the Foreign Exchange Market with Technical Analysis and Bayesian Statistics. J. Empir. Financ. 2021, 63, 230–251. [Google Scholar] [CrossRef]
- Quinlan, J.R. Improved Use of Continuous Attributes in C4.5. J. Artif. Intell. Res. 1996, 4, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests; UC Berkeley TR567; University of California: Berkeley, CA, USA, 1999. [Google Scholar]
- Cusano, C.; Ciocca, G.; Schettini, R. Image Annotation Using SVM. In Internet Imaging V, Proceedings of the ELECTRONIC IMAGING 2004, San Jose, CA, USA, 18–22 January 2004; International Society for Optics and Photonics: Bellingham, WA, USA, 2003; pp. 330–338. [Google Scholar] [CrossRef]
- Bao, W.; Lianju, N.; Yue, K. Integration of Unsupervised and Supervised Machine Learning Algorithms for Credit Risk Assessment. Expert Syst. Appl. 2019, 128, 301–315. [Google Scholar] [CrossRef]
- Stasinakis, C.; Sermpinis, G.; Psaradellis, I.; Verousis, T. Krill-Herd Support Vector Regression and Heterogeneous Autoregressive Leverage: Evidence from Forecasting and Trading Commodities. Quant. Financ. 2016, 16, 1901–1915. [Google Scholar] [CrossRef]
- Zhang, L.; Hu, H.; Zhang, D. A Credit Risk Assessment Model Based on SVM for Small and Medium Enterprises in Supply Chain Finance. Financ. Innov. 2015, 1, 14. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Ma, J. A Hybrid Ensemble Approach for Enterprise Credit Risk Assessment Based on Support Vector Machine. Expert Syst. Appl. 2012, 39, 5325–5331. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 45, 1189–1232. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Condition | |||
|---|---|---|---|
| Positive (non-risky) | Negative (risky) | ||
| Test result | Positive (non-risky) | True positive (TP) | False positive (FP) |
| Negative (risky) | False negative (FN) | True negative (TN) | |
| Groups | Independent Variables |
| Status of financing company | Current ratio of SMEs |
| Quick ratio of SMEs | |
| Working capital turnover of SMEs | |
| Accounts receivable turnover ratio of SMEs | |
| Rate of return on total assets of SMEs | |
| Total assets growth rate of SMEs | |
| Credit rating of SME (the evaluation of SMEs creditworthiness is divided into 10 grade) | |
| Status of core enterprise | Quick ratio of the CE |
| Total assets growth rate of the CE | |
| Rate of return on total assets of the CE | |
| Credit rating of CE (the evaluation of CEs creditworthiness is divided into 10 grade) | |
| Status of supply chain | Transaction amount/SME sales or cost of sales (sales when the SME is upstream, cost of sales when the SME is downstream) |
| Transaction amount/cost of sales of the core enterprise (sales when the core enterprise is an upstream supplier, cost of sales when the core enterprise is a downstream purchaser) | |
| Average rate of return on total assets in the industry | |
| Status of digitalization | Age of online platform construction |
| Enterprise resource planning (ERP) system application (1/0) | |
| Age of ERP system application |
| Code | Observations | Mean | Std. Dev | Minimum | Maximum |
|---|---|---|---|---|---|
| SME_CurrentRatio | 1357 | 2.327 | 2.327 | 0.162 | 45.316 |
| SME_QuickRatio | 1357 | 1.802 | 1.972 | 0.161 | 45.191 |
| SME_WorkingCapitalTurnover | 1355 | 0.502 | 5.859 | −3.101 | 189.143 |
| SME_AccountReceivableTurnover | 1319 | 12.710 | 92.873 | 0.000 | 1736.194 |
| SME_ROA | 1357 | 0.029 | 0.059 | −0.909 | 0.248 |
| SME_TotalAssetGrowthRate | 1357 | 0.091 | 0.327 | −0.579 | 5.779 |
| SME_CreditRating | 1357 | 8.757 | 1.365 | 2.000 | 10.000 |
| CE_QuickRatio | 1348 | 1.570 | 1.587 | 0.000 | 19.821 |
| CE_TotalAssetGrowthRate | 1348 | 0.163 | 0.304 | −0.708 | 2.587 |
| CE_ROA | 1348 | 533.465 | 285.922 | 1.000 | 946.000 |
| CE_CreditRating | 1357 | 4.850 | 3.511 | 1 | 10 |
| TransactionAmount/SME | 1357 | 96.944 | 57.707 | 1.000 | 197.000 |
| TransactionAmount/CE | 1357 | 57.027 | 60.218 | 1.000 | 185.000 |
| AverageIndustryROA | 1357 | 3.248 | 1.481 | 1.000 | 5.000 |
| ERP_Age | 1324 | 4.546 | 5.348 | 0.000 | 19.000 |
| ERP_Usage | 1325 | 0.649 | 0.487 | 0.000 | 1.000 |
| PlatformAge | 1325 | 5.629 | 5.323 | 0.000 | 19.000 |
| Average Accuracy | Recall | Precision | Type I Error | Type II Error | F-Measure | MCC | |
|---|---|---|---|---|---|---|---|
| LR | 0.909 | 0.994 | 0.910 | 0.098 | 0.038 | 0.950 | 0.508 |
| KNN | 0.946 | 0.983 | 0.956 | 0.045 | 0.115 | 0.969 | 0.741 |
| NB | 0.897 | 0.938 | 0.943 | 0.056 | 0.423 | 0.941 | 0.545 |
| DT | 0.936 | 0.978 | 0.951 | 0.051 | 0.154 | 0.964 | 0.693 |
| SVM | 0.961 | 1.000 | 0.957 | 0.044 | 0.000 | 0.978 | 0.814 |
| RF | 0.966 | 1.000 | 0.962 | 0.039 | 0.000 | 0.981 | 0.839 |
| MLP | 0.973 | 0.986 | 0.983 | 0.017 | 0.009 | 0.985 | 0.922 |
| XGBoost-KNN | 0.953 | 0.986 | 0.961 | 0.039 | 0.096 | 0.974 | 0.776 |
| XGBoost-NB | 0.912 | 0.952 | 0.947 | 0.053 | 0.327 | 0.949 | 0.607 |
| XGBoost-DT | 0.963 | 0.986 | 0.972 | 0.028 | 0.096 | 0.979 | 0.921 |
| XGBoost-SVM | 0.963 | 1.000 | 0.960 | 0.042 | 0.000 | 0.979 | 0.826 |
| XGBoost-RF | 0.973 | 1.000 | 0.970 | 0.031 | 0.000 | 0.985 | 0.875 |
| XGBoost-MLP | 0.983 | 0.994 | 0.986 | 0.014 | 0.038 | 0.994 | 0.922 |
| Average Accuracy | Recall | Precision | Type I Error | Type II Error | F-Measure | MCC | |
|---|---|---|---|---|---|---|---|
| LR | 0.917 | 0.991 | 0.919 | 0.087 | 0.056 | 0.954 | 0.573 |
| KNN | 0.978 | 0.994 | 0.981 | 0.019 | 0.040 | 0.987 | 0.900 |
| NB | 0.902 | 0.948 | 0.939 | 0.061 | 0.347 | 0.944 | 0.558 |
| DT | 1.000 | 1.000 | 1.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| SVM | 0.967 | 1.000 | 0.964 | 0.037 | 0.000 | 0.982 | 0.850 |
| RF | 1.000 | 1.000 | 1.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| MLP | 1.000 | 1.000 | 1.000 | 0.000 | 0.000 | 1.000 | 0.995 |
| XGBoost-KNN | 0.978 | 0.996 | 0.979 | 0.022 | 0.024 | 0.987 | 0.899 |
| XGBoost-NB | 0.906 | 0.958 | 0.935 | 0.067 | 0.274 | 0.947 | 0.558 |
| XGBoost-DT | 1.000 | 1.000 | 1.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| XGBoost-SVM | 0.969 | 1.000 | 0.966 | 0.035 | 0.000 | 0.983 | 0.870 |
| XGBoost-RF | 1.000 | 1.000 | 1.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| XGBoost-MLP | 0.999 | 1.000 | 0.999 | 0.001 | 0.000 | 0.999 | 0.995 |
| Average Accuracy | Recall | Precision | Type I Error | Type II Error | F-Measure | MCC | |
|---|---|---|---|---|---|---|---|
| XGBoost-MLP (Threshold = 0.03) with DSCF features | 0.983 | 0.994 | 0.986 | 0.014 | 0.038 | 0.994 | 0.922 |
| XGBoost-MLP (Threshold = 0.03) without DSCF features | 0.946 | 0.986 | 0.954 | 0.048 | 0.096 | 0.970 | 0.739 |
| Average Accuracy | Recall | Precision | Type I Error | Type II Error | F-Measure | MCC | |
|---|---|---|---|---|---|---|---|
| LR | 0.926 | 0.992 | 0.929 | 0.076 | 0.056 | 0.959 | 0.638 |
| KNN | 0.971 | 0.992 | 0.975 | 0.025 | 0.056 | 0.983 | 0.868 |
| NB | 0.860 | 0.889 | 0.946 | 0.051 | 0.722 | 0.917 | 0.487 |
| DT | 0.956 | 0.966 | 0.983 | 0.017 | 0.222 | 0.974 | 0.818 |
| SVM | 0.971 | 1.000 | 0.967 | 0.034 | 0.000 | 0.983 | 0.867 |
| RF | 0.963 | 1.000 | 0.959 | 0.042 | 0.000 | 0.979 | 0.832 |
| MLP | 0.978 | 1.000 | 0.975 | 0.025 | 0.000 | 0.987 | 0.901 |
| XGBoost-KNN | 0.978 | 0.992 | 0.983 | 0.017 | 0.056 | 0.987 | 0.902 |
| XGBoost-NB | 0.882 | 0.924 | 0.939 | 0.059 | 0.500 | 0.932 | 0.512 |
| XGBoost-DT | 0.934 | 0.983 | 0.943 | 0.059 | 0.111 | 0.963 | 0.695 |
| XGBoost-SVM | 0.977 | 1.000 | 0.975 | 0.025 | 0.000 | 0.987 | 0.901 |
| XGBoost-RF | 0.971 | 1.000 | 0.967 | 0.034 | 0.000 | 0.983 | 0.867 |
| XGBoost-MLP | 0.978 | 0.989 | 0.986 | 0.014 | 0.077 | 0.987 | 0.901 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Stasinakis, C.; Yeo, W.M. A Hybrid XGBoost-MLP Model for Credit Risk Assessment on Digital Supply Chain Finance. Forecasting 2022, 4, 184-207. https://doi.org/10.3390/forecast4010011
Li Y, Stasinakis C, Yeo WM. A Hybrid XGBoost-MLP Model for Credit Risk Assessment on Digital Supply Chain Finance. Forecasting. 2022; 4(1):184-207. https://doi.org/10.3390/forecast4010011
Chicago/Turabian StyleLi, Yixuan, Charalampos Stasinakis, and Wee Meng Yeo. 2022. "A Hybrid XGBoost-MLP Model for Credit Risk Assessment on Digital Supply Chain Finance" Forecasting 4, no. 1: 184-207. https://doi.org/10.3390/forecast4010011