

Predicting the Continuous Spatiotemporal State of Ground Fire Based on the Expended LSTM Model with Self-Attention Mechanisms
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
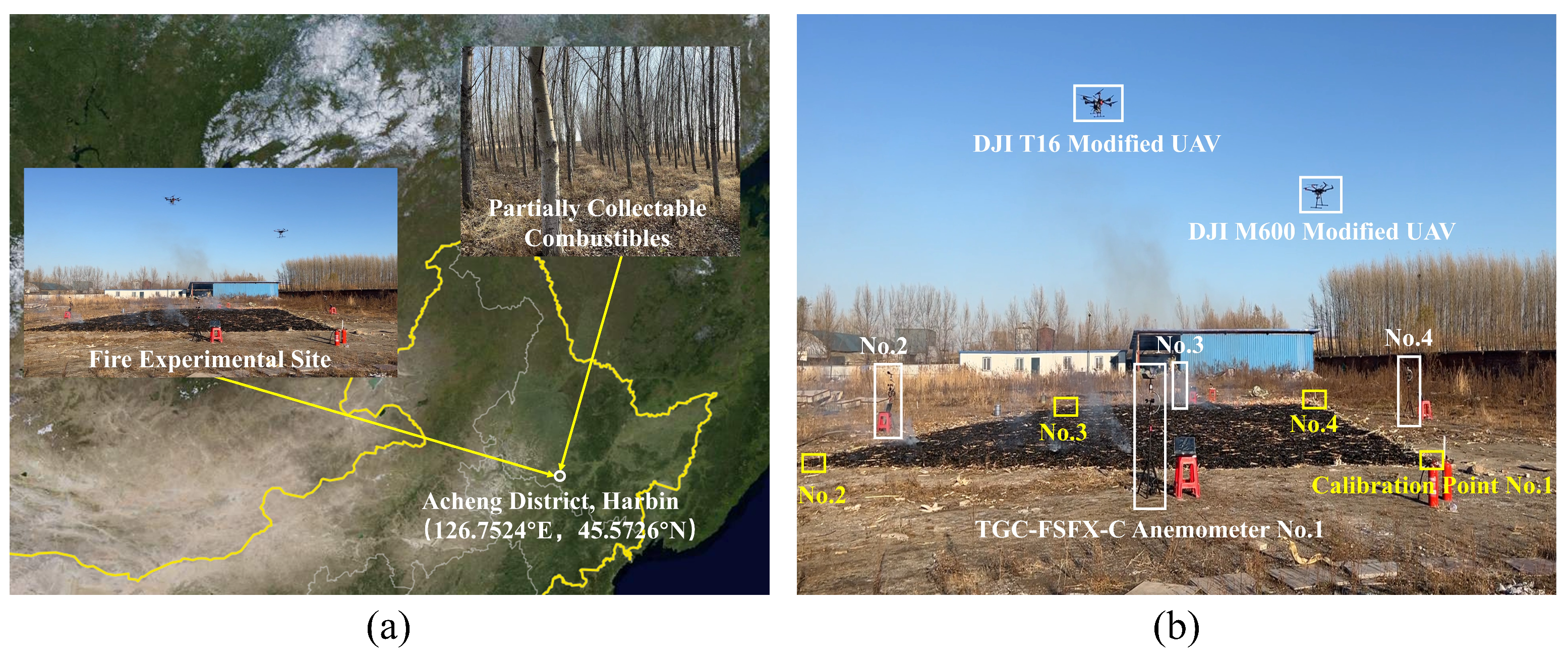
2.1. Small-Scale Ground Fire Experiments
2.2. Data Preprocessing
2.2.1. Preprocessing for Combustion Images
2.2.2. Preprocessing for Environmental Variables
2.3. The Task Definition of Predicting the Combustion Image Sequence
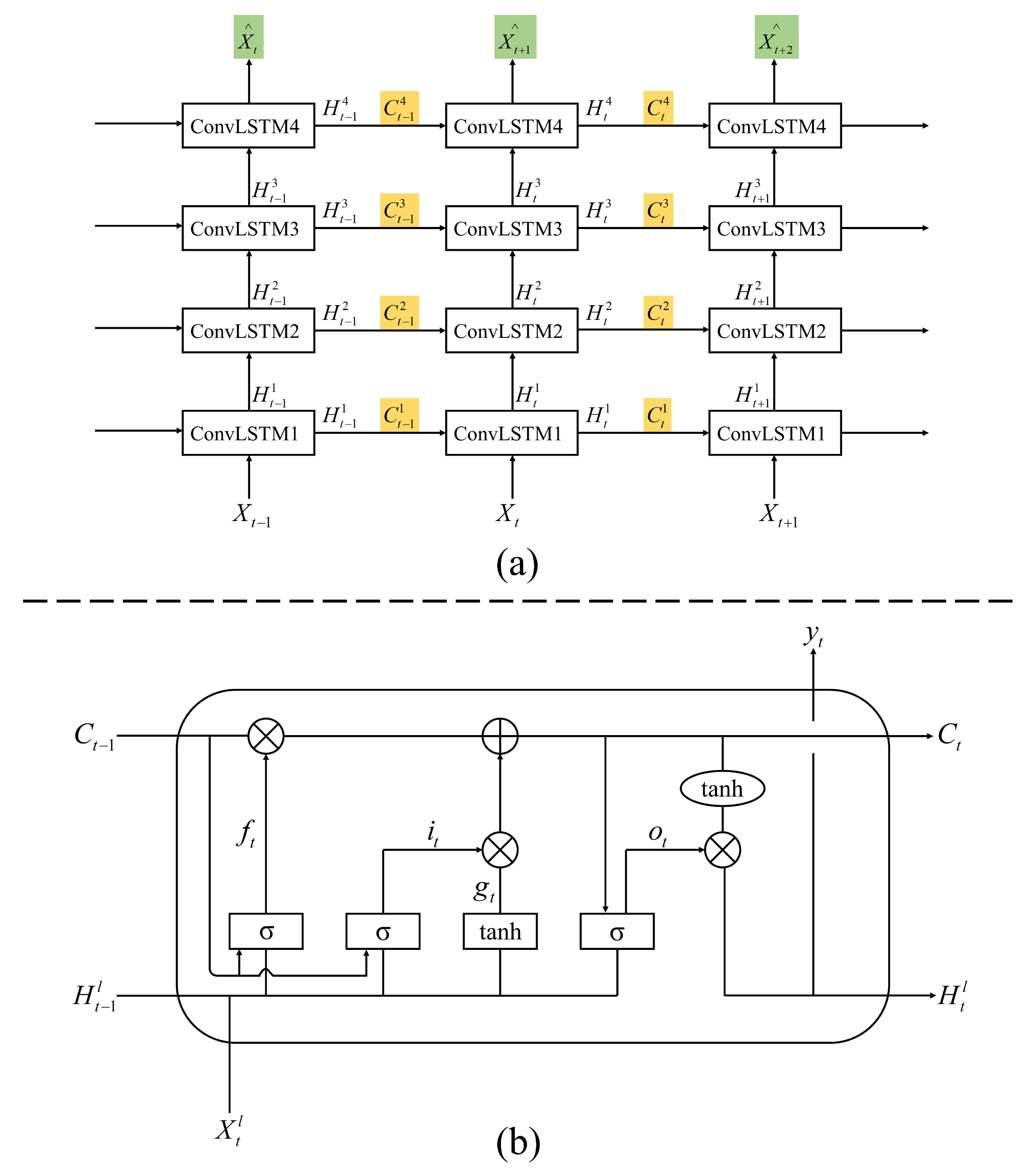
2.4. The State-of-the-Art Spatiotemporal Prediction Models
2.5. The Self-Attention Mechanism
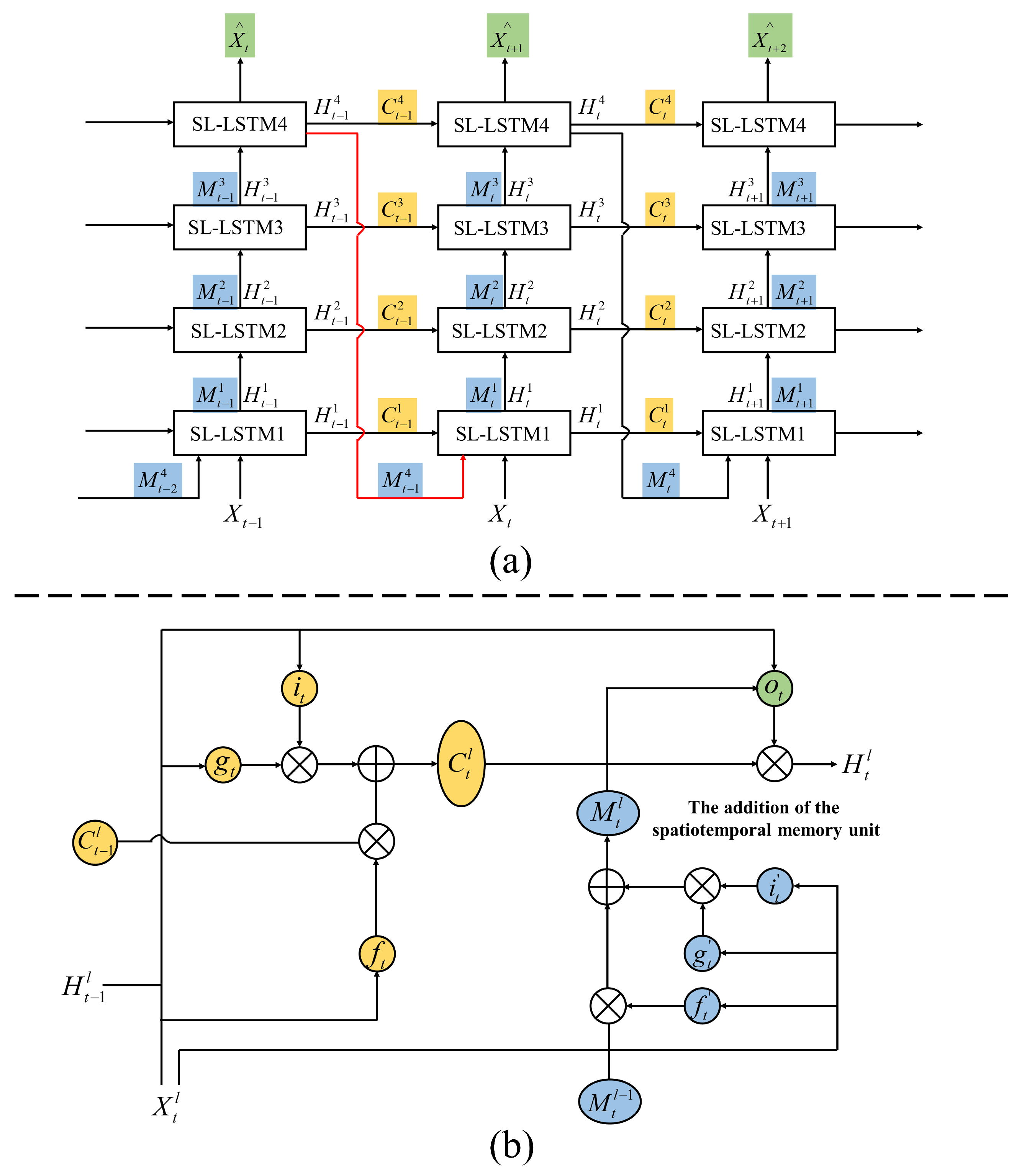
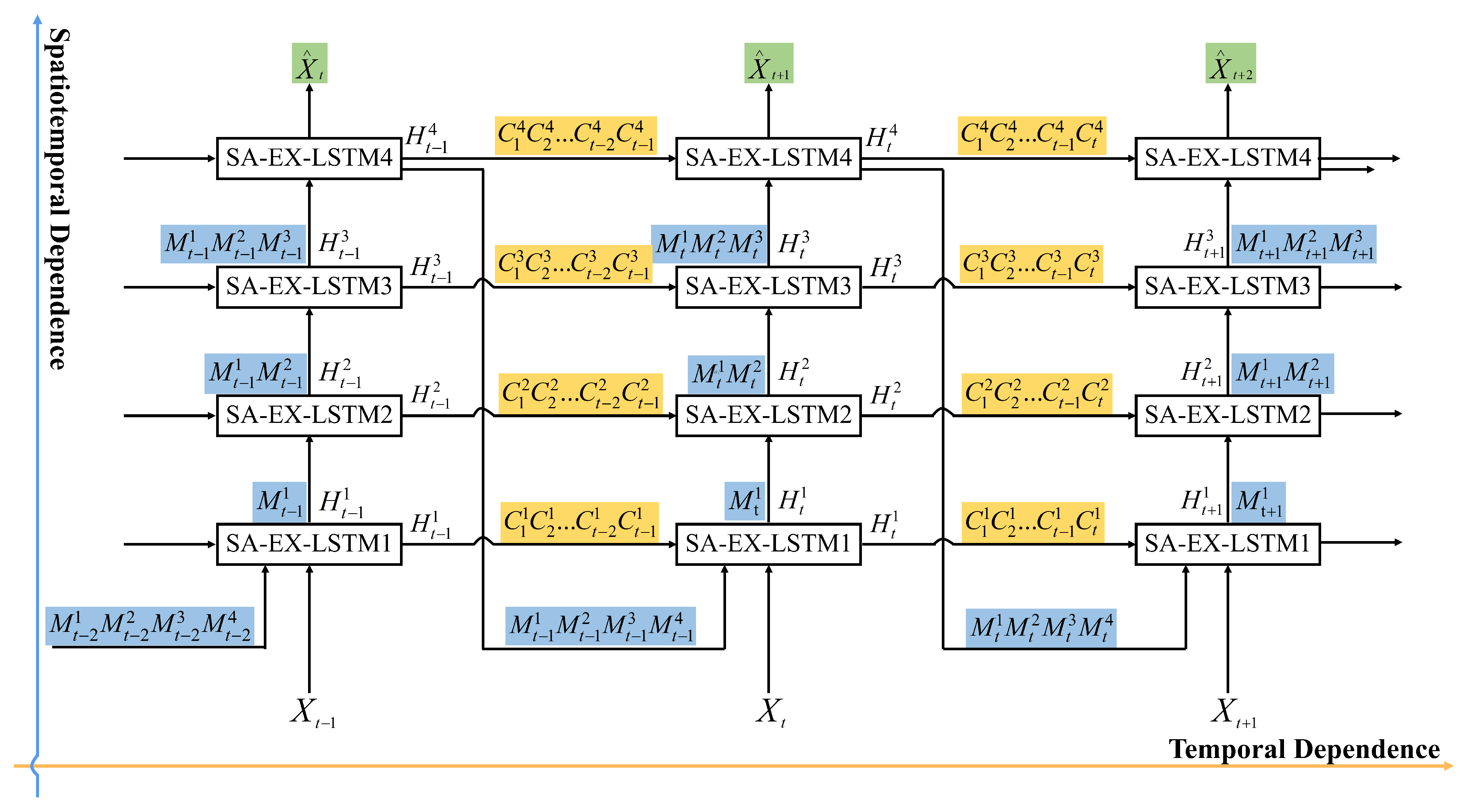
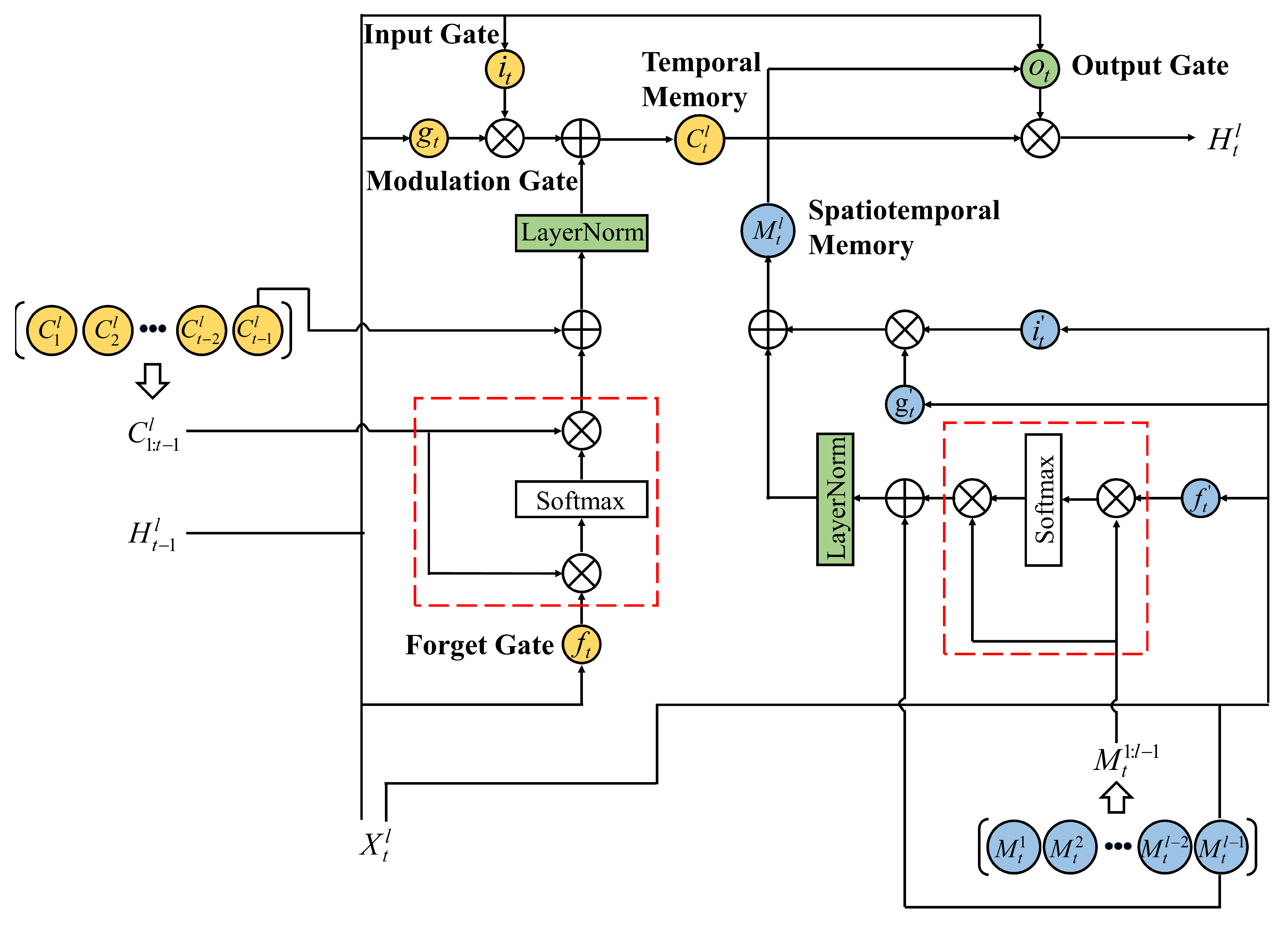
2.6. The Structure of the SA-EX-LSTM
2.7. Performance Metrics
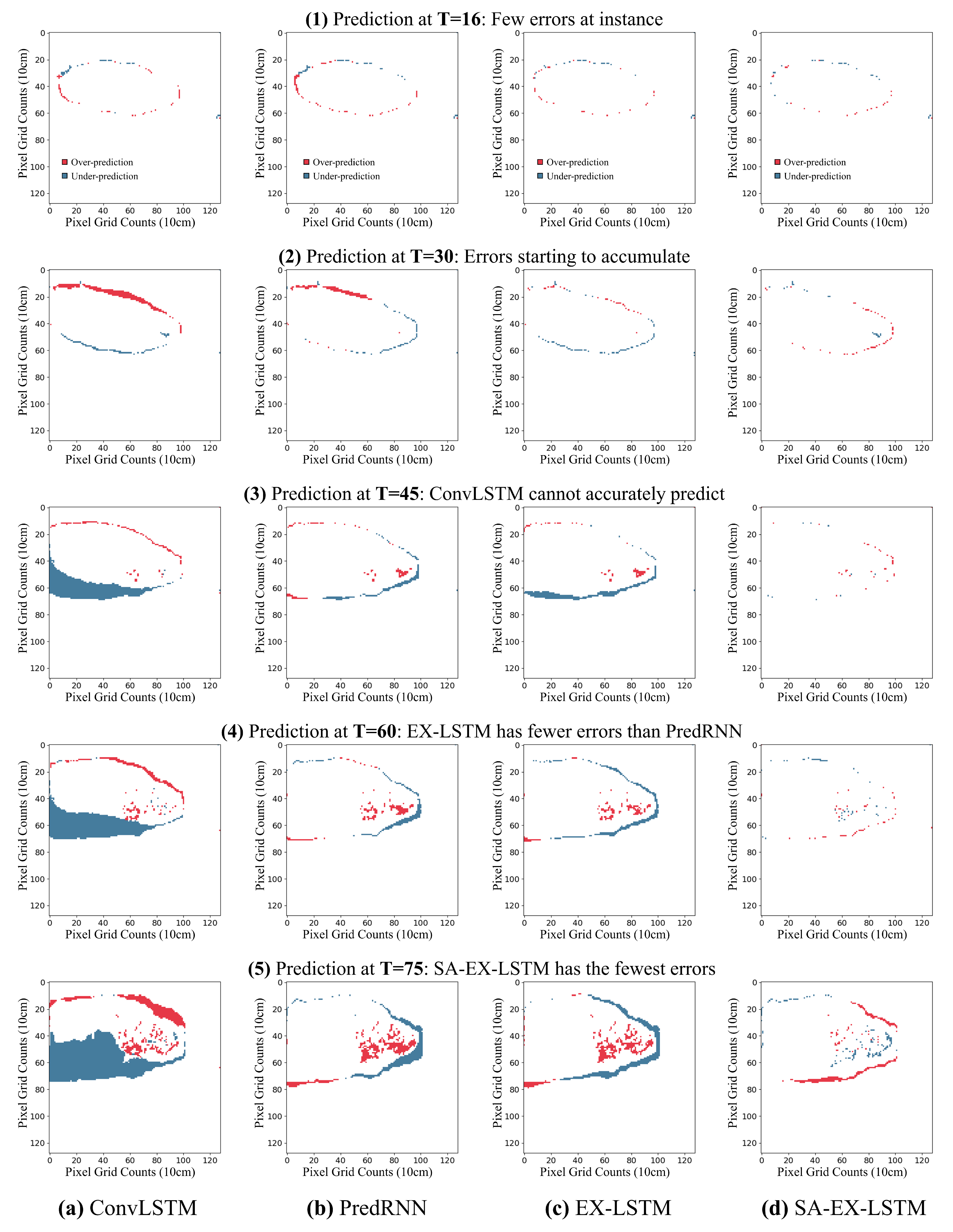
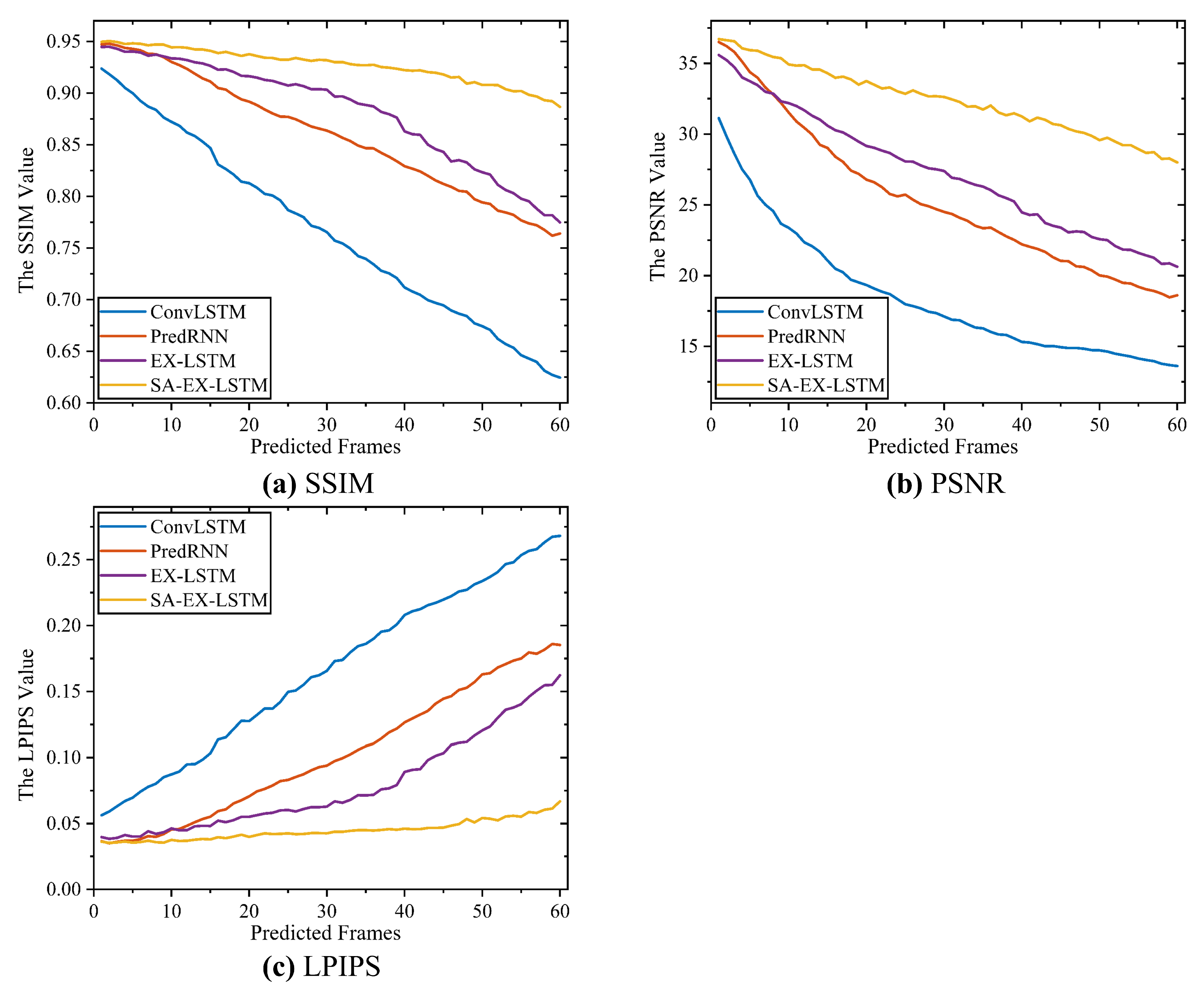
3. Results
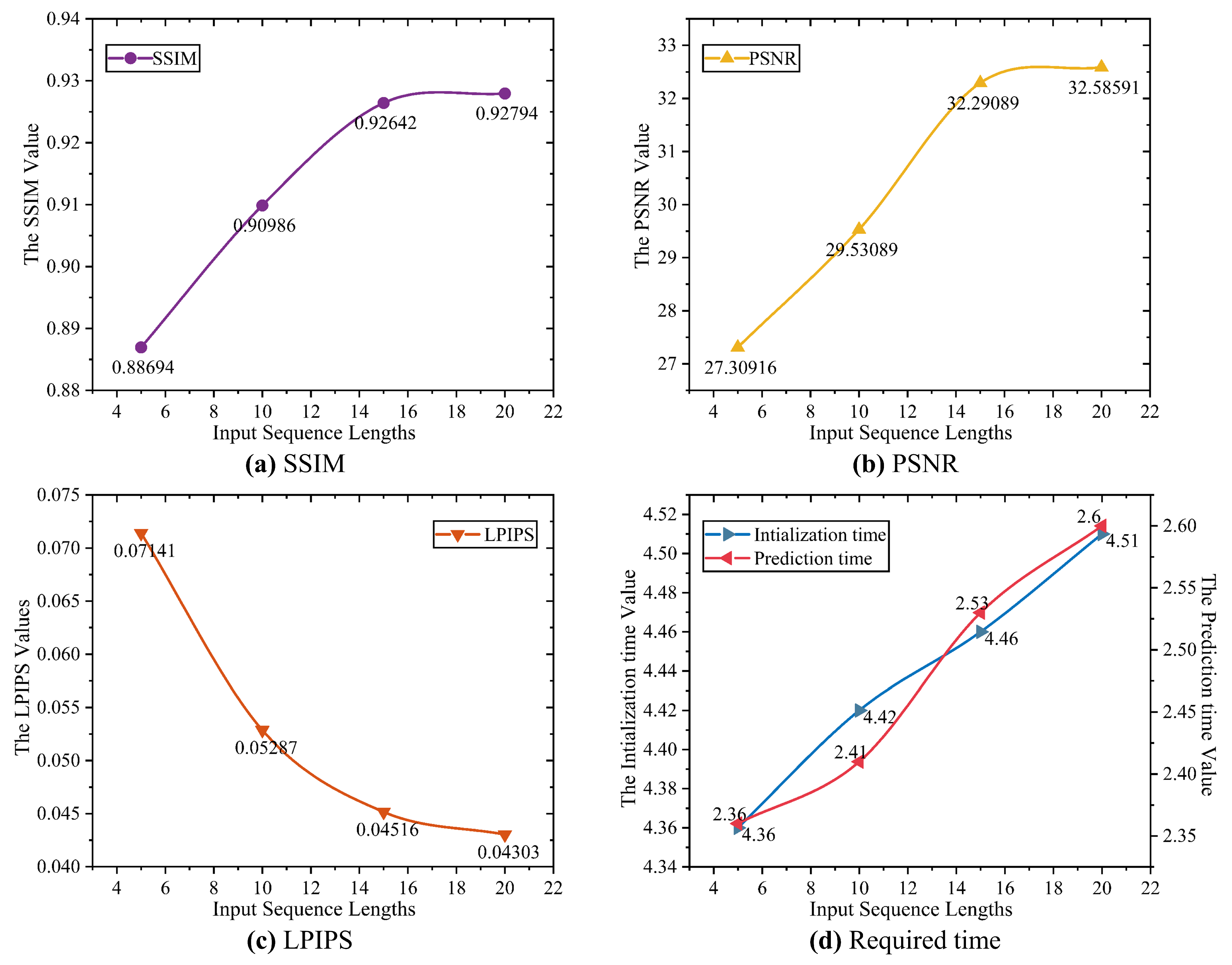
The Influence of Different Input Sequence Lengths on Model Prediction
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, F.; Shu, L.F.; Zhou, R.L. A review of wildland fire spread modelling. World For. Res. 2017, 30, 46–50. [Google Scholar]
- Zong, X.Z.; Tain, X.R. Research progress in forest fire behavior and suppression technology. World For. Res. 2019, 32, 31–36. [Google Scholar]
- San José, R.; Pérez, J.L.; González, R.M. Analysis of fire behaviour simulations over Spain with WRF-FIRE. Int. J. Environ. Pollut. 2014, 55, 148–156. [Google Scholar] [CrossRef]
- Cruz, M.G.; Alexander, M.E. Modelling the rate of fire spread and uncertainty associated with the onset and propagation of crown fires in conifer forest stands. Int. J. Wildland Fire 2017, 26, 413–426. [Google Scholar] [CrossRef]
- Fons, W.L. Analysis of fire spread in light forest fuels. J. Agric. Res. 1946, 72, 93–121. [Google Scholar]
- Albini, F.A. A model for fire spread in wildland fuels by-radiation. Combust. Sci. Technol. 1985, 42, 229–258. [Google Scholar] [CrossRef]
- Wang, X.; Wotton, B.M.; Cantin, A.S. cffdrs: An R package for the Canadian forest fire danger rating system. Ecol. Process. 2017, 6, 5. [Google Scholar] [CrossRef]
- Leonard, S. Predicting sustained fire spread in Tasmanian native grasslands. Environ. Manag. 2009, 44, 430–440. [Google Scholar] [CrossRef]
- Rothermel, R.C. A Mathematical Model for Predicting Fire Spread in Wildland Fuels; Intermountain Forest & Range Experiment Station, Forest Service, US Department of Agriculture: Washington, DC, USA, 1972.
- Finney, M.A. Fire Area Simulator–Model Development and Evaluation; US Department of Agriculture, Forest Service, Rocky Mountain Research Station: Washington, DC, USA, 1998.
- Zhang, F.; Xie, X. An Improved Forest Fire Spread Model and Its Realization. Geomat. Spat. Inf. Technol. 2012, 35, 50–53. [Google Scholar]
- Sullivan, A.L. A review of wildland fire spread modelling, 1990–present, 1: Physical and quasi-physical models. arXiv 2007, arXiv:0706.3074. [Google Scholar]
- Sullivan, A.L. Wildland surface fire spread modelling, 1990–2007. 2: Empirical and quasi-empirical models. Int. J. Wildland Fire 2009, 18, 369–386. [Google Scholar] [CrossRef] [Green Version]
- Andrews, P.L.; Cruz, M.G.; Rothermel, R.C. Examination of the wind speed limit function in the Rothermel surface fire spread model. Int. J. Wildland Fire 2013, 22, 959–969. [Google Scholar] [CrossRef]
- Andrews, P.L. The Rothermel Surface Fire Spread Model and Associated Developments: A Comprehensive Explanation; United States Department of Agriculture, Forest Service, Rocky Mountain Research Station: Washington, DC, USA, 2018.
- Li, X.; Zhang, M.; Zhang, S. Simulating forest fire spread with cellular automation driven by a LSTM based speed model. Fire 2022, 5, 13. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Mitri, G. Artificial intelligence for forest fire prediction. In Proceedings of the 2010 IEEE/ASME International Conference on Advanced Intelligent Mechatronics, Montreal, QC, Canada, 6–9 July 2010; pp. 1311–1316. [Google Scholar]
- Castelli, M.; Vanneschi, L.; Popovič, A. Predicting burned areas of forest fires: An artificial intelligence approach. Fire Ecol. 2015, 11, 106–118. [Google Scholar] [CrossRef]
- Wu, Z.; Li, M.; Wang, B. Using artificial intelligence to estimate the probability of forest fires in Heilongjiang, northeast China. Remote Sens. 2021, 13, 1813. [Google Scholar] [CrossRef]
- Hodges, J.L.; Lattimer, B.Y. Wildland fire spread modeling using convolutional neural networks. Fire Technol. 2019, 55, 2115–2142. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, B.; Li, M. Simulation of forest fire spread based on artificial intelligence. Ecol. Indic. 2022, 136, 108653. [Google Scholar] [CrossRef]
- Marjani, M.; Mesgari, M.S. The Large-Scale Wildfire Spread Prediction Using a Multi-Kernel Convolutional Neural Network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 10, 483–488. [Google Scholar] [CrossRef]
- Singh, K.R.; Neethu, K.P.; Madhurekaa, K. Parallel SVM model for forest fire prediction. Soft Comput. Lett. 2021, 3, 100014. [Google Scholar] [CrossRef]
- Casallas, A.; Jiménez-Saenz, C.; Torres, V. Design of a forest fire early alert system through a deep 3D-CNN structure and a WRF-CNN bias correction. Sensors 2022, 22, 8790. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, M.; Liu, K. Forest fire susceptibility modeling using a convolutional neural network for Yunnan province of China. Int. J. Disaster Risk Sci. 2019, 10, 386–403. [Google Scholar] [CrossRef] [Green Version]
- Allaire, F.; Mallet, V.; Filippi, J.B. Emulation of wildland fire spread simulation using deep learning. Neural Netw. 2021, 141, 184–198. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Lin, C.; Zhang, M. Predicting the rate of forest fire spread toward any directions based on a CNN model considering the correlations of input variables. J. For. Res. 2023, 28, 111–119. [Google Scholar] [CrossRef]
- Cheng, T.; Wang, J. Integrated spatio-temporal data mining for forest fire prediction. Trans. GIS 2008, 12, 591–611. [Google Scholar] [CrossRef]
- Li, D.; Cova, T.J. Dennison, P.E. Setting wildfire evacuation triggers by coupling fire and traffic simulation models: A spatiotemporal GIS approach. Fire Technol. 2019, 55, 617–642. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Burge, J.; Bonanni, M.; Ihme, M. Convolutional LSTM neural networks for modeling wildland fire dynamics. arXiv 2020, arXiv:2012.06679. [Google Scholar]
- Papadopoulos, G.D.; Pavlidou, F.N. A comparative review on wildfire simulators. IEEE Syst. J. 2011, 5, 233–243. [Google Scholar] [CrossRef]
- Su, J.; Byeon, W.; Kossaifi, J. Convolutional tensor-train lstm for spatio-temporal learning. Adv. Neural Inf. Process. Syst. 2020, 33, 13714–13726. [Google Scholar]
- Wang, Y.; Wu, H.; Zhang, J. Predrnn: A recurrent neural network for spatiotemporal predictive learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 4, 2208–2225. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Cao, Y.; Yang, F.; Tang, Q. An attention enhanced bidirectional LSTM for early forest fire smoke recognition. IEEE Access 2019, 7, 154732–154742. [Google Scholar] [CrossRef]
- Li, Z.; Huang, Y.; Li, X. Wildland fire burned areas prediction using long short-term memory neural network with attention mechanism. Fire Technol. 2021, 57, 1–23. [Google Scholar] [CrossRef]
- Majid, S.; Alenezi, F.; Masood, S. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Mezirow, J. Perspective transformation. Adult Educ. 1978, 28, 100–110. [Google Scholar] [CrossRef]
- Wu, B.; Mu, C.; Zhao, J. Effects on carbon sources and sinks from conversion of over-mature forest to major secondary forests and korean pine plantation in Northeast China. Sustainability 2019, 11, 4232. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Gao, H.; Zhang, M. Prediction of Forest fire spread rate using UAV images and an LSTM model considering the interaction between fire and wind. Remote Sens. 2021, 13, 4325. [Google Scholar] [CrossRef]
- Vollmer, M. Infrared thermal imaging. In Computer Vision: A Reference Guide; Springer International: Cham, Switzerlnad, 2021; pp. 666–670. [Google Scholar]
- Ciprián-Sánchez, J.F.; Ochoa-Ruiz, G.; González-Mendoza, M. Assessing the applicability of Deep Learning-based visible-infrared fusion methods for fire imagery. arXiv 2021, arXiv:2101.11745v2. [Google Scholar]
- Pei, Z.; Tong, Q.; Wang, L. A median filter method for image noise variance estimation. In Proceedings of the 2010 Second, International Conference on Information Technology and Computer Science, Kiev, Ukraine, 24–25 July 2010; pp. 13–16. [Google Scholar]
- Zhang, J.; Zhang, J.; Chen, B. A perspective transformation method based on computer vision. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 765–768. [Google Scholar]
- Cary, G.J.; Keane, R.E.; Gardner, R.H. Comparison of the sensitivity of landscape-fire-succession models to variation in terrain, fuel pattern, climate and weather. Landsc. Ecol. 2006, 21, 121–137. [Google Scholar] [CrossRef]
- Guo, F.; Su, Z.; Wang, G. Understanding fire drivers and relative impacts in different Chinese forest ecosystems. Sci. Total. Environ. 2017, 605, 411–425. [Google Scholar] [CrossRef] [PubMed]
- Coop, J.D.; Parks, S.A.; Stevens-Rumann, C.S. Extreme fire spread events and area burned under recent and future climate in the western USA. Glob. Ecol. Biogeogr. 2022, 31, 1949–1959. [Google Scholar] [CrossRef]
- Etminani, K.; Naghibzadeh, M. A min-min max-min selective algorihtm for grid task scheduling. In Proceedings of the 2007 3rd IEEE/IFIP International Conference in Central Asia on Internet, Tashkent, Uzbekistan, 26–28 September 2007; pp. 1–7. [Google Scholar]
- Um, E.; Lee, D.S.; Pyo, H.B. Continuous generation of hydrogel beads and encapsulation of biological materials using a microfluidic droplet-merging channel. Microfluid. Nanofluidics 2008, 5, 541–549. [Google Scholar] [CrossRef]
- Fessler, J.A.; Sutton, B.P. Nonuniform fast Fourier transforms using min-max interpolation. IEEE Trans. Signal Process. 2003, 51, 560–574. [Google Scholar] [CrossRef] [Green Version]
- Rao, A.; Park, J.; Woo, S. Studying the effects of self-attention for medical image analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3416–3425. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Radiuk, P.M. Impact of training set batch size on the performance of convolutional neural networks for diverse datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Köksoy, O. Multiresponse robust design: Mean square error (MSE) criterion. Appl. Math. Comput. 2006, 175, 1716–1729. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, H.; He, P. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Jais, I.K.M.; Ismail, A.R.; Nisa, S.Q. Adam optimization algorithm for wide and deep neural network. Knowl. Eng. Data Sci. 2019, 2, 41–46. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Brunet, D.; Vrscay, E.R.; Wang, Z. On the mathematical properties of the structural similarity index. IEEE Trans. Image Process. 2011, 21, 1488–1499. [Google Scholar] [CrossRef]
- Poobathy, D.; Chezian, R.M. Edge detection operators: Peak signal to noise ratio based comparison. IJ Image Graph. Signal Process. 2014, 10, 55–61. [Google Scholar] [CrossRef] [Green Version]
- Bondzulic, B.P.; Pavlovic, B.Z.; Petrovic, V.S. Performance of peak signal-to-noise ratio quality assessment in video streaming with packet losses. Electron. Lett. 2016, 52, 454–456. [Google Scholar] [CrossRef]
- Talebi, H.; Milanfar, P. Learned perceptual image enhancement. In Proceedings of the 2018 IEEE International Conference on Computational Photography (ICCP), Pittsburgh, PA, USA, 4–6 May 2018; pp. 1–13. [Google Scholar]
- Tang, R.; Zeng, F.; Chen, Z. The comparison of predicting storm-time ionospheric TEC by three methods: ARIMA, LSTM, and Seq2Seq. Atmosphere 2020, 11, 316. [Google Scholar] [CrossRef] [Green Version]
- Gauch, M.; Mai, J.; Lin, J. The proper care and feeding of CAMELS: How limited training data affects streamflow prediction. Environ. Model. Softw. 2021, 135, 104926. [Google Scholar] [CrossRef]
- Misawa, S.; Taniguchi, M.; Miura, Y. Character-based Bidirectional LSTM-CRF with words and characters for Japanese Named Entity Recognition. In Proceedings of the First, Workshop on Subword and Character Level Models in NLP, Copenhagen, Denmark, 7 September 2017; pp. 97–102. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Wu, C.; Wu, F.; Qi, T. Hi-Transformer: Hierarchical interactive transformer for efficient and effective long document modeling. arXiv 2021, arXiv:2106.01040. [Google Scholar]
- Wang, Z.; Su, X.; Ding, Z. Long-term traffic prediction based on lstm encoder-decoder architecture. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6561–6571. [Google Scholar] [CrossRef]
- Zhang, K.; Riegler, G.; Snavely, N. Nerf++: Analyzing and improving neural radiance fields. arXiv 2020, arXiv:2010.07492. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Adv. Neural Inf. Process. Syst. 2017, 30, 879–888. [Google Scholar]
- Malmivirta, T.; Hamberg, J.; Lagerspetz, E. Hot or not? Robust and accurate continuous thermal imaging on flir cameras. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications, Kyoto, Japan, 11–15 March 2019; pp. 1–9. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Num | Combustibles | Combustible Area | Combustible Weight | Combustible Load | Bed Depth | Moisture Content | Experimental Location |
|---|---|---|---|---|---|---|---|
| 1 | Leaf wood | 4 × 5 m2 | 17.895 kg | 1.482 kg/m2 | 5.64 cm | 12.2% | 126.7524° E, 45.5726° N |
| 2 | Leaf wood | 6.5 × 7.5 m2 | 42.86 kg | 1.199 kg/m2 | 6.08 cm | 12.1% | |
| 3 | Leaf wood | 6.5 × 7.5 m2 | 44.275 kg | 1.201 kg/m2 | 6.0 cm | 12.5% | |
| 4 | Leaf wood | 8.5 × 8.5 m2 | 110.345 kg | 1.543 kg/m2 | 5.0 cm | 13.9% | |
| 5 | Conifer | 5.5 × 7.3 m2 | 71.915 kg | 1.791 kg/m2 | 5.0 cm | 12.8% | |
| 6 | Conifer | 5.5 × 7 m2 | 91.06 kg | 2.454 kg/m2 | 7.0 cm | 13.1% | |
| 7 | Sylvestris | 7.5 × 7.5 m2 | 92.565 kg | 1.6098 kg/m2 | 5.0 cm | 13.3% | |
| 8 | Sylvestris | 5 × 8 m2 | 55.6 kg | 1.39 kg/m2 | 6.05 cm | 13.0% | |
| 9 | Poplar leaves | 5 × 8 m2 | 96.7 kg | 2.4175 kg/m2 | 5.0 cm | 14.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, X.; Zhang, M.; Tang, C.; Li, X.; Sun, S.; Wang, Y.; Li, D.; Li, S. Predicting the Continuous Spatiotemporal State of Ground Fire Based on the Expended LSTM Model with Self-Attention Mechanisms. Fire 2023, 6, 237. https://doi.org/10.3390/fire6060237
Wang X, Wang X, Zhang M, Tang C, Li X, Sun S, Wang Y, Li D, Li S. Predicting the Continuous Spatiotemporal State of Ground Fire Based on the Expended LSTM Model with Self-Attention Mechanisms. Fire. 2023; 6(6):237. https://doi.org/10.3390/fire6060237
Chicago/Turabian StyleWang, Xinyu, Xinquan Wang, Mingxian Zhang, Chun Tang, Xingdong Li, Shufa Sun, Yangwei Wang, Dandan Li, and Sanping Li. 2023. "Predicting the Continuous Spatiotemporal State of Ground Fire Based on the Expended LSTM Model with Self-Attention Mechanisms" Fire 6, no. 6: 237. https://doi.org/10.3390/fire6060237