
Research and Application of Improved Multiple Imputation Based on R Language in Fire Prediction



Abstract
:1. Introduction
2. Methodology
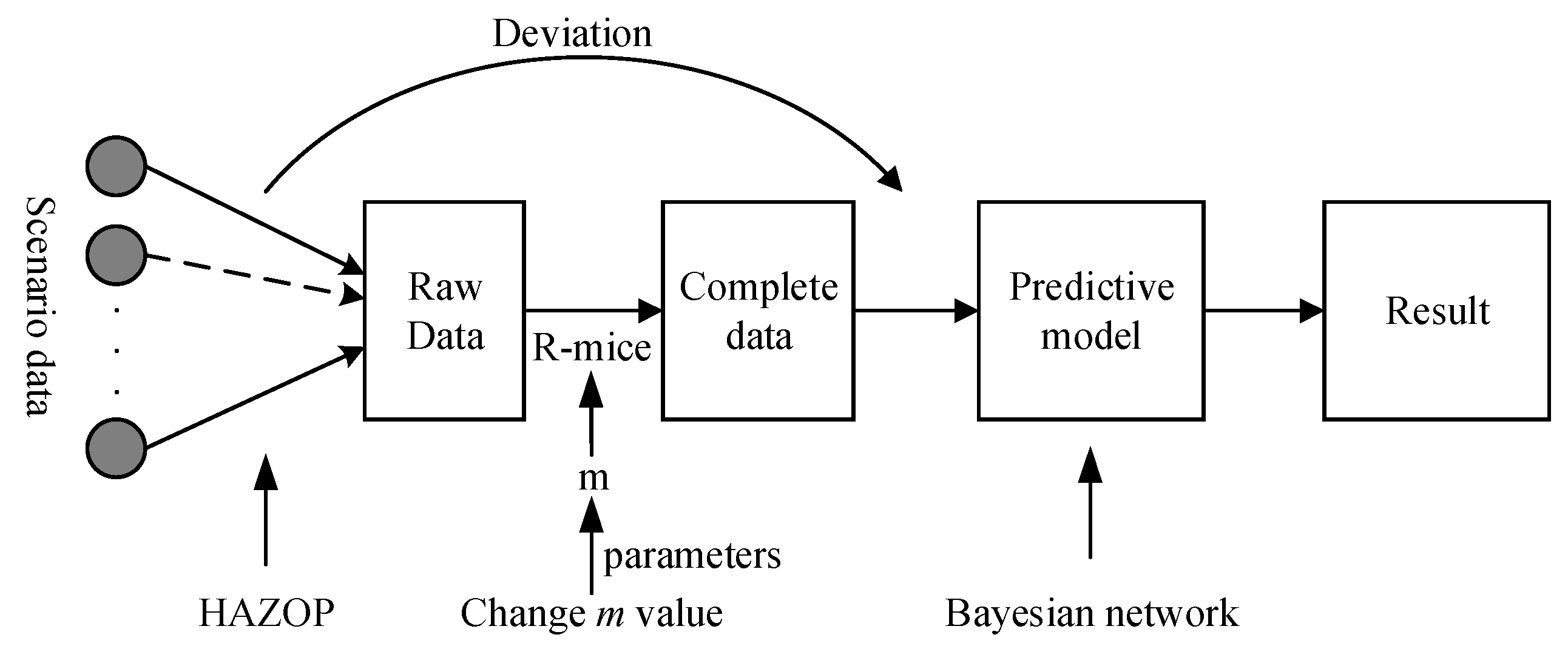
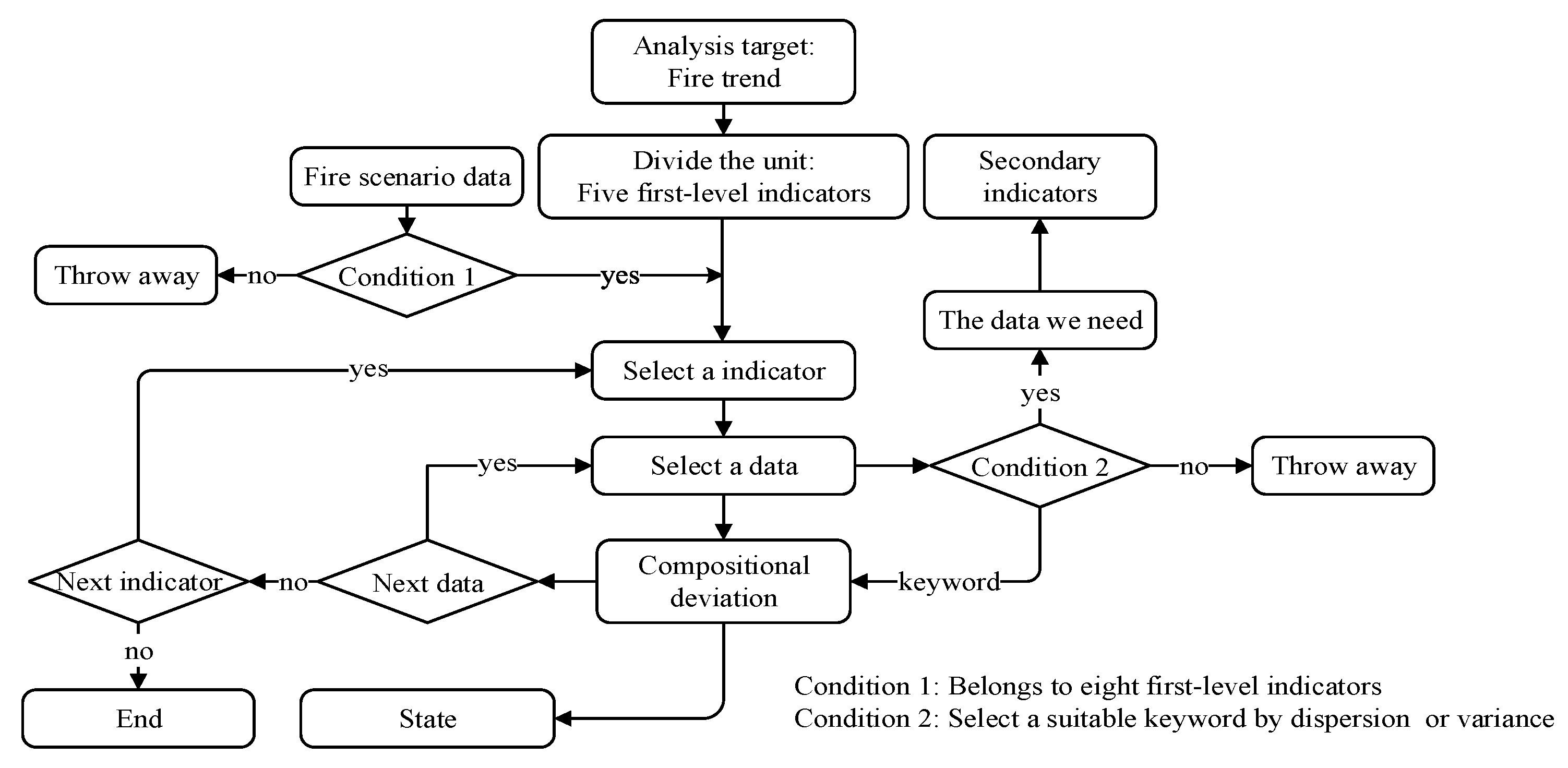
2.1. Hazard and Operability (HAZOP)
2.2. Multiple Fills
- Choose the appropriate padding method based on the data deletion pattern: monotonic or arbitrary [25], such as predictive mean matching, logistic regression imputation, and professional odds models, m-fill missing data to generate m-group complete datasets.
- Statistical analysis of m-group datasets.
- The Rubin method was used to integrate all the analysis results to produce a final inference.
- library(mice) # Call into the function package
- x1<- read.spss(“data location/file name.sav”, to.data.frame = T) # Import data
- x2<- mice(x1, m, meth) # Fill in the data
- fit <- with(x2, analysis) # Contains m individual statistical analysis results, analysis is used to set the statistical analysis method applied to m-filled datasets
- pooled <- pool(fit) # Contains m statistical analysis of the average results
- summary(pooled) # Summary
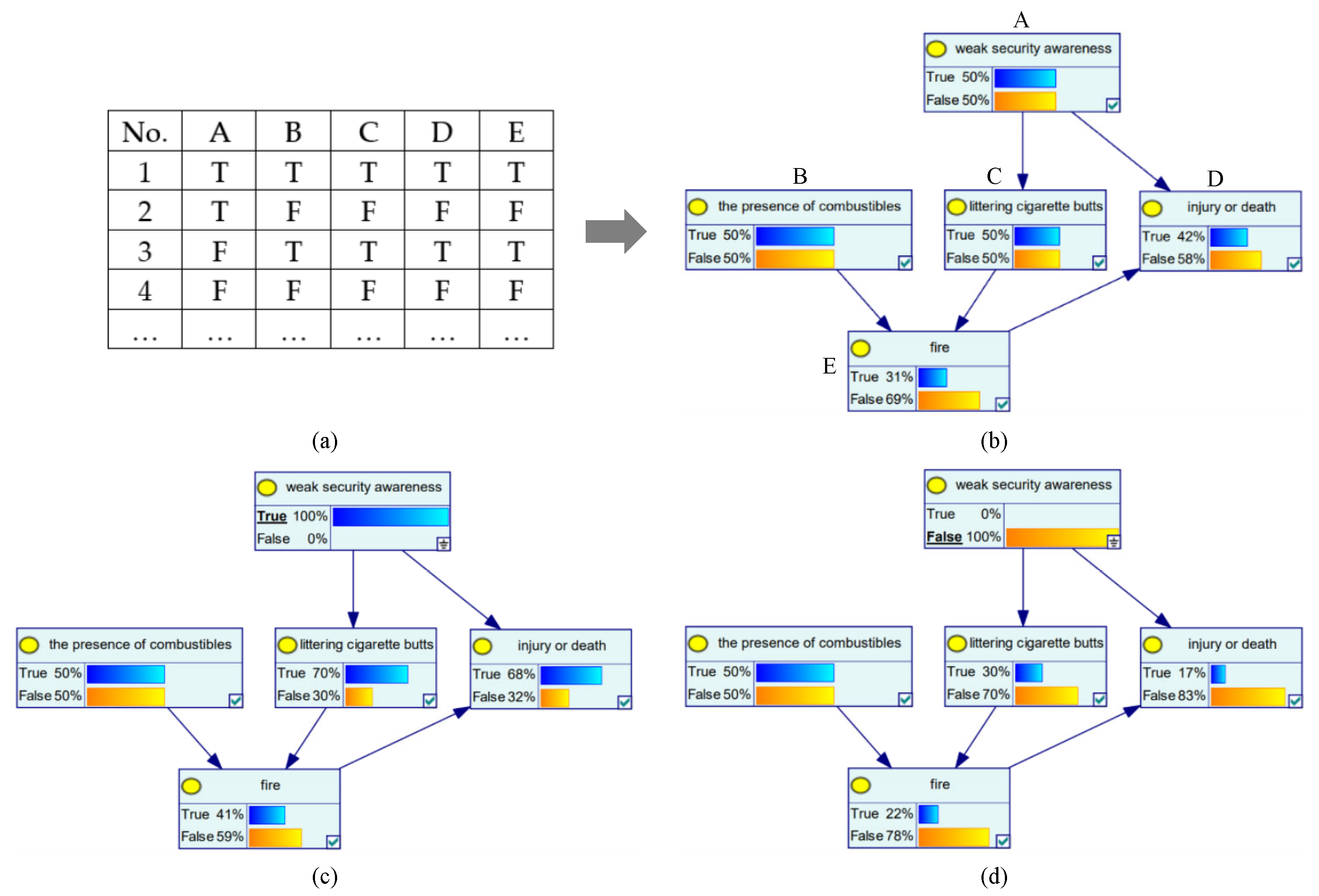
2.3. Bayesian Networks
3. Instance Calculations
3.1. Collection and Processing of Fire Statistics
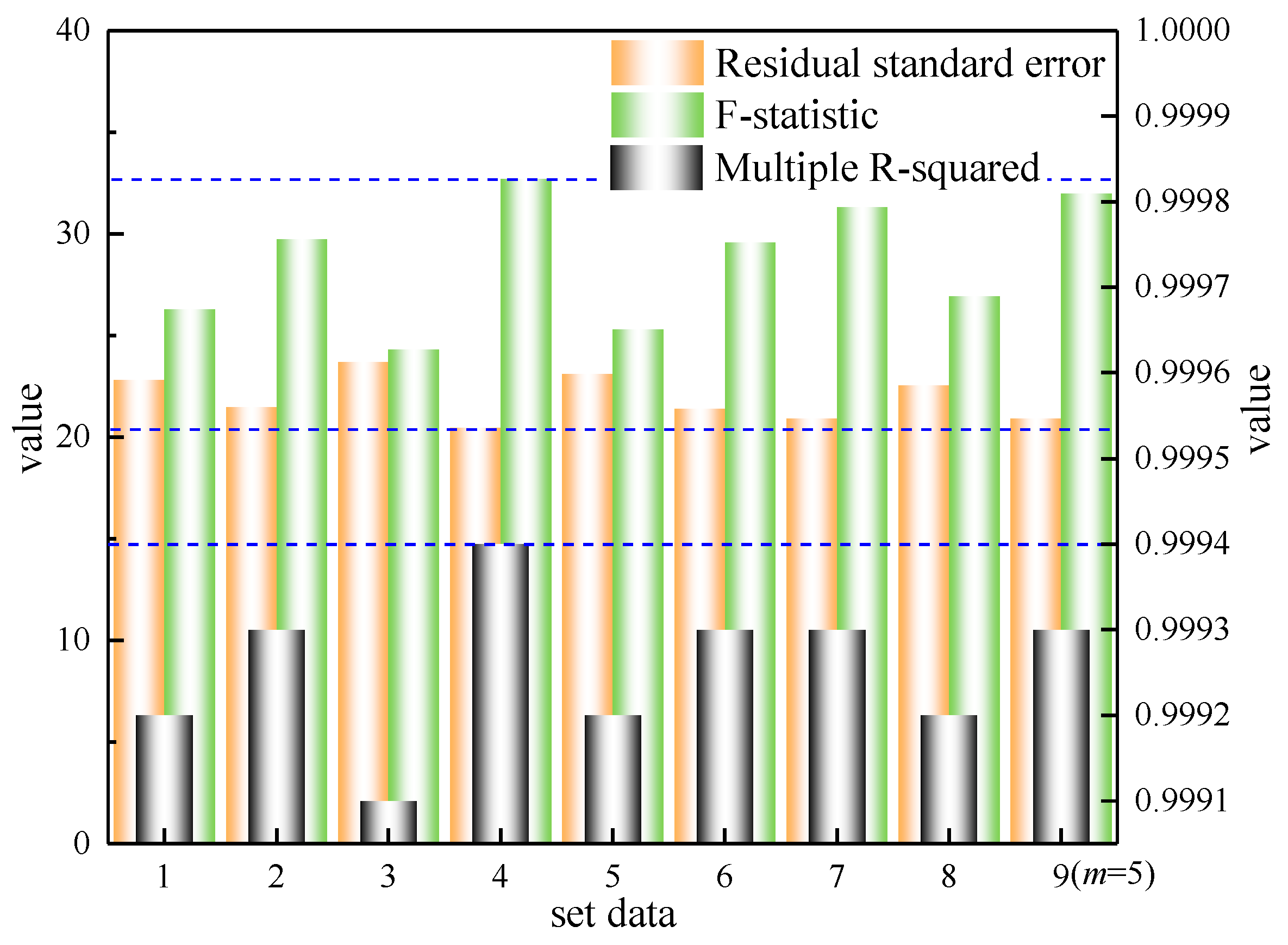
3.2. Fill Scenario Data
- code 1: data <-mice(x, m = I, maxit = 100, seed = 2020), i = 1, 2, …, n
- code 2: fit <- with(data, lm (x0~x1 + x2 + … + x21+ x22))
- code 3: data y <- complete(data, y), y = 1, 2, 3, …, 8
- code 4: fit y <- with(data y, lm (x0~x1 + x2 + … + x21 + x22))
4. Results and Discussion
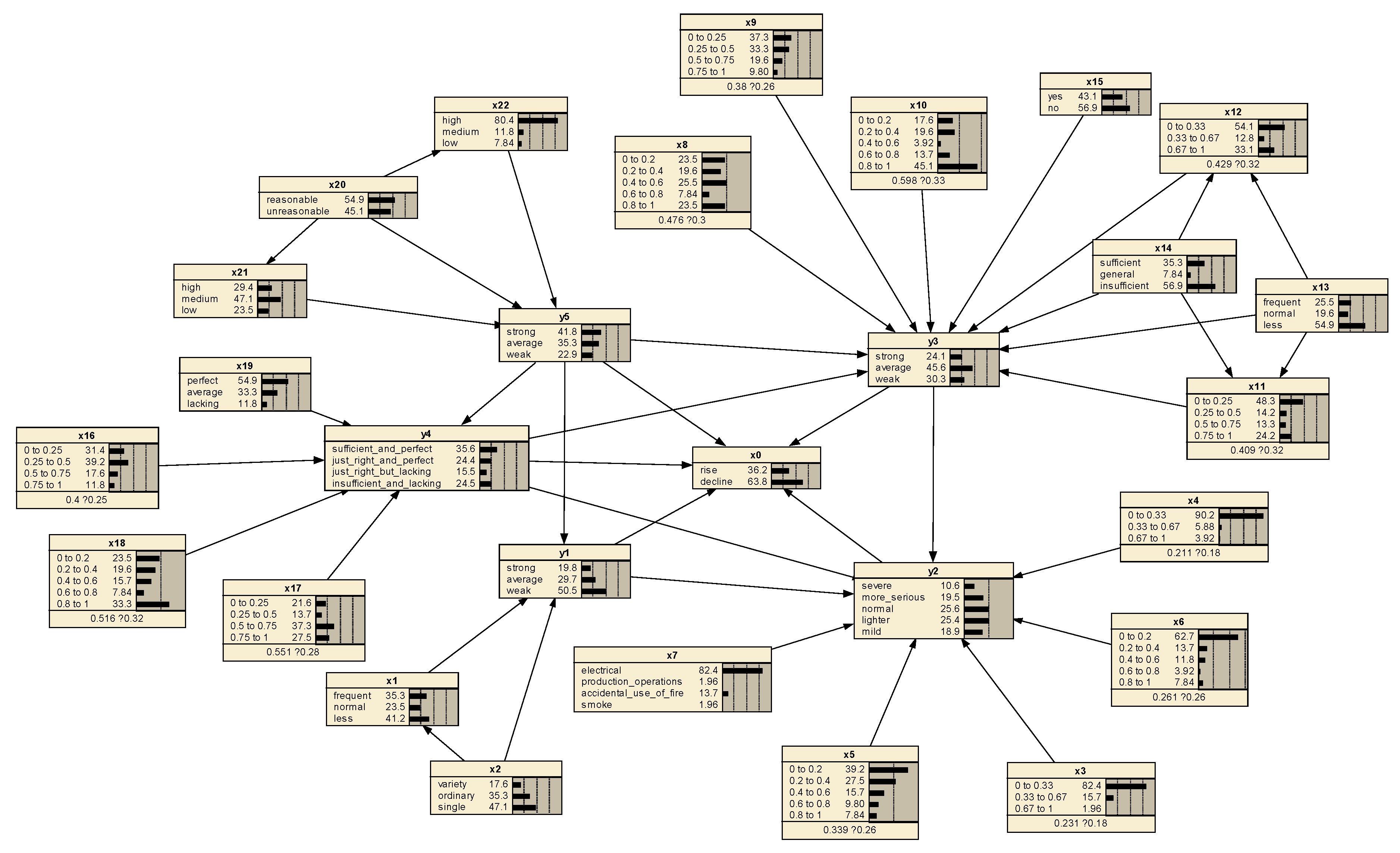
4.1. Predictive Reasoning
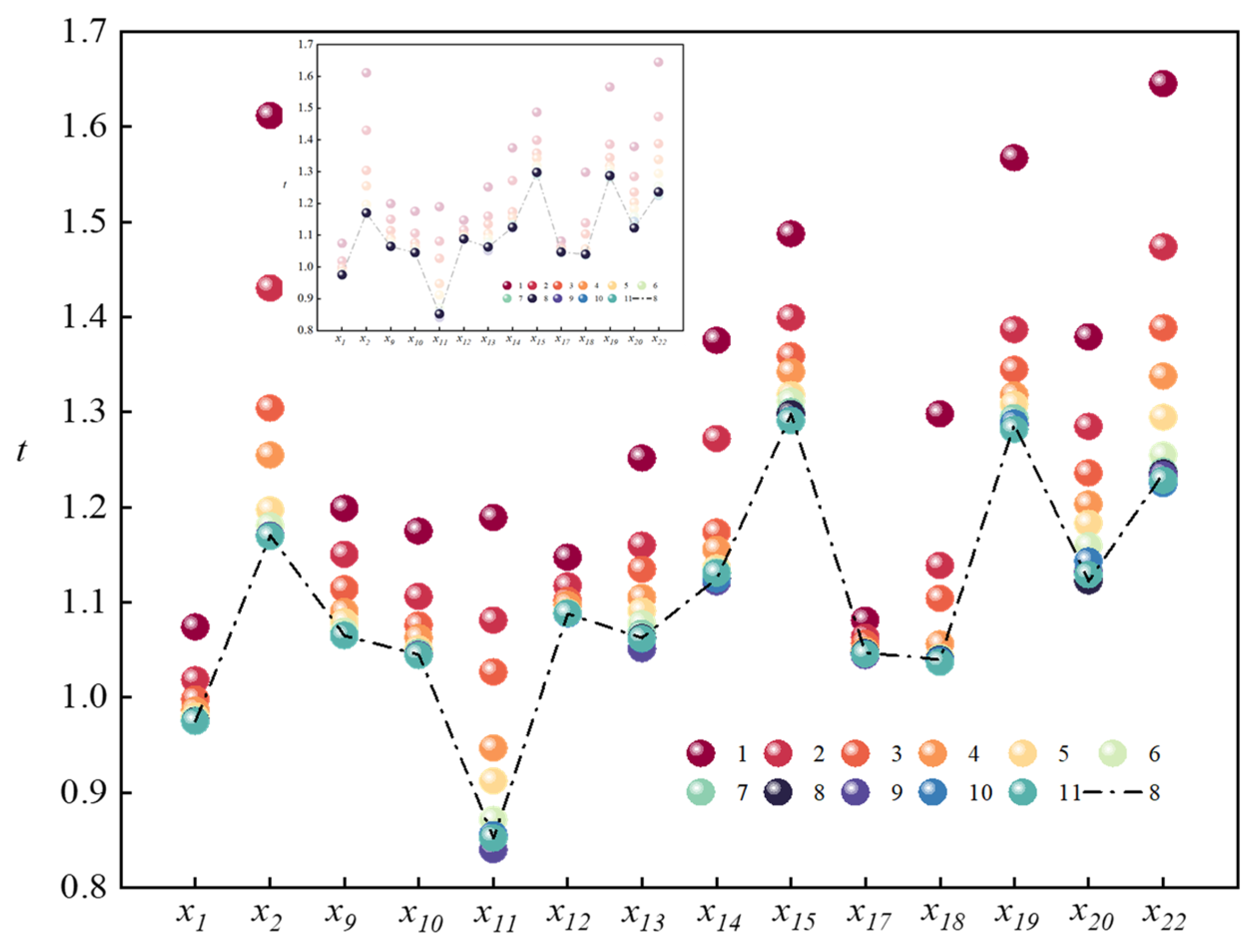
4.2. Sensitivity Analysis
4.3. Measures and Suggestions
5. Conclusions
- Using the HAZOP method to screen data can complete multiple tasks in a shorter time and make full use of expert knowledge and collected data. This method combines qualitative and quantitative data, which not only makes expert knowledge more convincing but also makes data more meaningful and valuable.
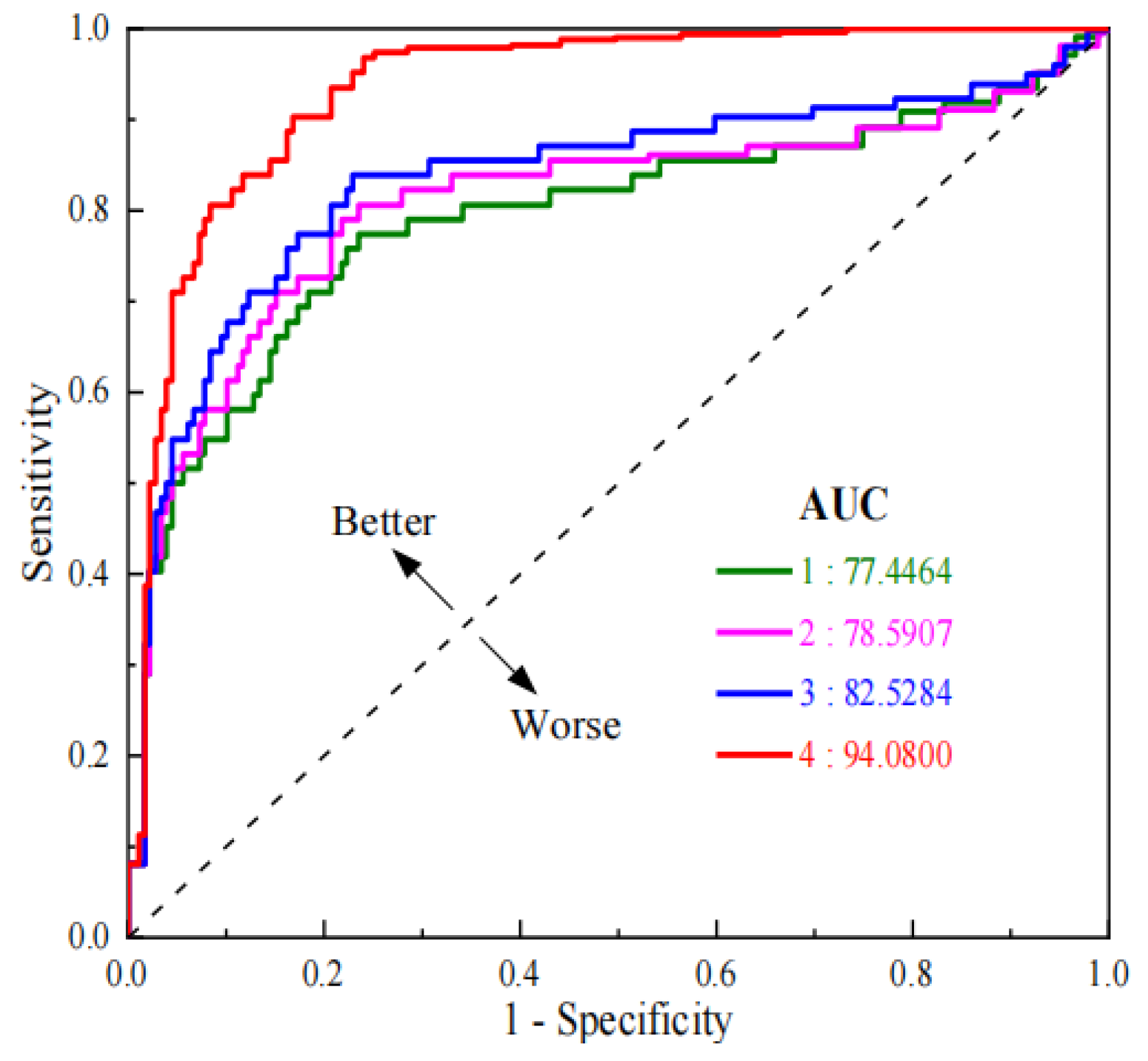
- Determining the value of m through relevant parameters fully considers the randomness of filling data and the differences between datasets. By continuously changing the value of m and using the relevant parameters as the basis for judgment, the best filling data are selected, so that the complete dataset obtained is closer to the real data, and the prediction effect of the prediction model is greatly improved (AUC: 94.0800 > 82.5284).
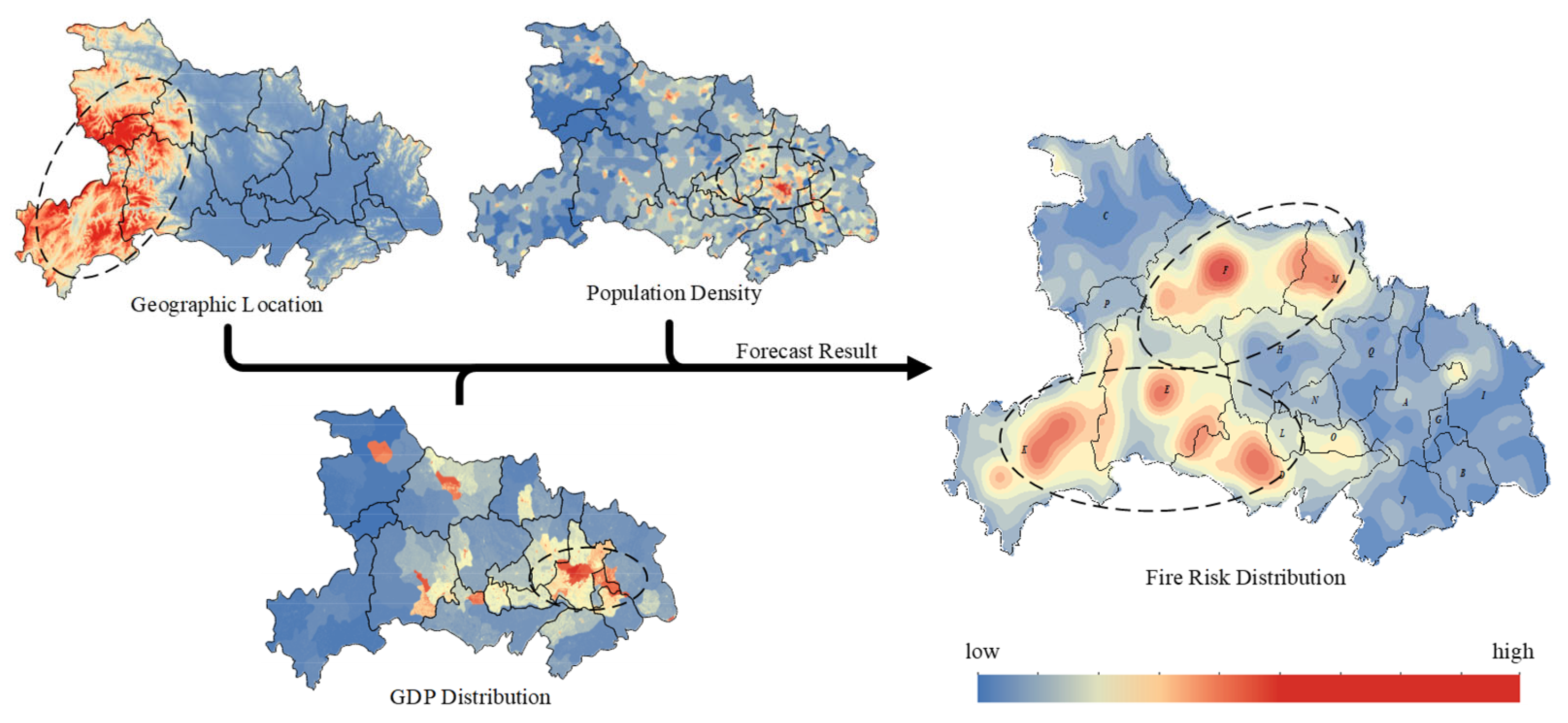
- The forecast results show that the western part of Hubei Province (especially the southwestern part) is a high fire risk area, which is consistent with the actual situation. The reason may be that its geographic location and development strategy has caused its economic development to lag, lack of rich funds to develop the fire protection industry, neglect of safety management, and generally low awareness of public safety. For the above reasons, this article puts forward some suggestions for improvement, see Section 4.3 for details.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alipour, M.; La Puma, I.; Picotte, J.; Shamsaei, K.; Rowell, E.; Watts, A.; Kosovic, B.; Ebrahimian, H.; Taciroglu, E. A Multimodal Data Fusion and Deep Learning Framework for Large-Scale Wildfire Surface Fuel Mapping. Fire 2023, 6, 36. [Google Scholar] [CrossRef]
- Tavakol Sadrabadi, M.; Innocente, M.S. Vegetation Cover Type Classification Using Cartographic Data for Prediction of Wildfire Behaviour. Fire 2023, 6, 76. [Google Scholar] [CrossRef]
- Mahamed (Polinova), M.; Wittenberg, L.; Kutiel, H.; Brook, A. Fire Risk Assessment on Wildland–Urban Interface and Adjoined Urban Areas: Estimation Vegetation Ignitability by Artificial Neural Network. Fire 2022, 5, 184. [Google Scholar] [CrossRef]
- Kussul, N.; Fedorov, O.; Yailymov, B.; Pidgorodetska, L.; Kolos, L.; Yailymova, H.; Shelestov, A. Fire Danger Assessment Using Moderate-Spatial Resolution Satellite Data. Fire 2023, 6, 72. [Google Scholar] [CrossRef]
- Łopucki, R.; Kiersztyn, A.; Pitucha, G.; Kitowski, I. Handling missing data in ecological studies: Ignoring gaps in the dataset can distort the inference. Ecol. Model. 2022, 468, 109964. [Google Scholar] [CrossRef]
- Xiong, Z.; Guo, H.; Wu, Y. Review of Missing Data Processing Methods. Comput. Eng. Appl. 2021, 57, 27–38. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol. 1977, 39, 1–22. [Google Scholar]
- Little, R.J.A. Hierarchical Logistic Regression Models for Imputation of Unresolved Enumeration Status in Undercount Estimation: Comment. J. Am. Stat. Assoc. 1993, 88, 1159. [Google Scholar] [CrossRef]
- Rubin, D.B.; Service, E.T. Multiple imputations in sample surveys—A phenomenological Bayesian approach to nonresponse. In Proceedings of the Survey Research Methods Section of the American Statistical Association, Alexandria, VA, USA, 2 January 1978. [Google Scholar]
- Razavi-Far, R.; Cheng, B.; Saif, M.; Ahmadi, M. Similarity-learning information-fusion schemes for missing data imputation. Knowl.-Based Syst. 2020, 187, 104805. [Google Scholar] [CrossRef]
- Gondara, L.; Wang, K. MIDA: Multiple Imputation Using Denoising Autoencoders. Adv. Knowl. Discov. Data Min. 2018, 91, 10939. [Google Scholar]
- Mohammed, Y.S.; Abdelkader, H.; Pławiak, P.; Hammad, M. A novel model to optimize multiple imputation algorithm for missing data using evolution methods. Biomed. Signal Process. Control 2022, 76, 103661. [Google Scholar] [CrossRef]
- Li, W.; Wang, Y.; Zhang, J.; Li, J.; Huang, B. Application of MICE in R for imputing incomplete multivariate data. Chin. J. Hosp. Stat. 2011, 18, 309–312. [Google Scholar]
- Jakobsen, J.C.; Gluud, C.; Wetterslev, J.; Winkel, P. When and how should multiple imputation be used for handling missing data in randomised clinical trials—A practical guide with flowcharts. BMC Med. Res. Methodol. 2017, 17, 162. [Google Scholar] [CrossRef] [Green Version]
- Cory, W.O.; Bishrant, A.; Simon, P.A.; Paddington, H.; Chen, X.; Thomas, A.M. Predicting Fire Propagation across Heterogeneous Landscapes Using WyoFire: A Monte Carlo-Driven Wildfire Model. Fire 2020, 3, 71. [Google Scholar]
- Malik, A.A.; Nasif, M.S.; Arshad, U.; Mokhtar, A.A.; Tohir, M.Z.; Al-Waked, R. Predictive Modelling of Wind-Influenced Dynamic Fire Spread Probability in Tank Farm Due to Domino Effect by Integrating Numerical Simulation with ANN. Fire 2023, 6, 85. [Google Scholar] [CrossRef]
- Liu, X.; Lu, Y.; Xia, Z.; Li, F.; Zhang, T. A Data Mining Method for Potential Fire Hazard Analysis of Urban Buildings based on Bayesian Network. In Proceedings of the 2nd International Conference on Intelligent Information Processing—IIP’17, Bangkok, Thailand, 17–18 July 2017; ACM Press: New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Jin, G.; Wang, Q.; Zhu, C.; Feng, Y.; Huang, J.; Hu, X. Urban Fire Situation Forecasting: Deep sequence learning with spatio-temporal dynamics. Appl. Soft Comput. 2020, 97, 106730. [Google Scholar] [CrossRef]
- Sattari, F.; Macciotta, R.; Kurian, D.; Lefsrud, L. Application of Bayesian network and artificial intelligence to reduce accident/incident rates in oil & gas companies. Saf. Sci. 2021, 133, 104981. [Google Scholar]
- Squillante, R.; Santos Fo, D.J.; Maruyama, N.; Junqueira, F.; Moscato, L.A.; Nakamoto, F.Y.; Miyagi, P.E.; Okamoto, J. Modeling accident scenarios from databases with missing data: A probabilistic approach for safety-related systems design. Saf. Sci. 2018, 104, 119–134. [Google Scholar] [CrossRef]
- Carpenter, J.R.; Kenward, M.G. Multiple Imputation And Its Application. Int. Stat. Rev. 2014, 82, 151–152. [Google Scholar]
- Schafer, J.L. Multiple imputation: A primer. Stat. Methods Med. Res. 1999, 8, 3–15. [Google Scholar] [CrossRef]
- Buuren, S.V. Flexible Imputation of Missing Data; Chapman and Hall/CRC: New York, NY, USA, 2012. [Google Scholar]
- Marhavilas, P.K.; Filippidis, M.; Koulinas, G.K.; Koulouriotis, D.E. An expanded HAZOP-study with fuzzy-AHP (XPA-HAZOP technique): Application in a sour crude-oil processing plant. Saf. Sci. 2020, 124, 104590. [Google Scholar] [CrossRef]
- Dunjo, J.; Fthenakis, V.; Vilchez, J.A.; Arnaldos, J. Hazard and operability (HAZOP) analysis. A literature review. J. Hazard. Mater. 2010, 173, 19–32. [Google Scholar] [CrossRef] [PubMed]
- Dohoo, I.R.; Nielsen, C.R.; Emanuelson, U. Multiple imputation in veterinary epidemiological studies: A case study and simulation. Prev. Vet. Med. 2016, 129, 35–47. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Flatau Harrison, H.; Griffin, M.A.; Gagne, M.; Andrei, D. Assessing shortened safety climate measures: Simulating a planned missing data design in a field setting. Saf. Sci. 2018, 104, 189–201. [Google Scholar] [CrossRef]
- Enders, C.K. Applied Missing Data Analysis, 1st ed.; The Guilford Press: New York, NY, USA, 2010. [Google Scholar]
- Lawrence, J.-M.; Ibne Hossain, N.U.; Jaradat, R.; Hamilton, M. Leveraging a Bayesian network approach to model and analyze supplier vulnerability to severe weather risk: A case study of the U.S. pharmaceutical supply chain following Hurricane Maria. Int. J. Disaster Risk Reduct. 2020, 49, 101607. [Google Scholar] [CrossRef] [PubMed]
- Cooper, G.F.; Herskovits, E. A Bayesian method for the induction of probabilistic networks from data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef] [Green Version]
- Dlamini, W.M. Application of Bayesian networks for fire risk mapping using GIS and remote sensing data. GeoJournal 2011, 76, 283–296. [Google Scholar] [CrossRef]
- Sevinc, V.; Kucuk, O.; Goltas, M. A Bayesian network model for prediction and analysis of possible forest fire causes. For. Ecol. Manag. 2020, 457, 117723. [Google Scholar] [CrossRef]
- Leao, T.; Madeira, S.C.; Gromicho, M.; De Carvalho, M.; Carvalho, A.M. Learning dynamic Bayesian networks from time-dependent and time-independent data: Unraveling disease progression in Amyotrophic Lateral Sclerosis. J. Biomed. Inform. 2021, 117, 103730. [Google Scholar] [CrossRef]
- Lee, S.; Kang, J.E.; Park, C.S.; Yoon, D.K.; Yoon, S. Multi-risk assessment of heat waves under intensifying climate change using Bayesian Networks. Int. J. Disaster Risk Reduct. 2020, 50, 101704. [Google Scholar] [CrossRef]
- Baksh, A.-A.; Khan, F.; Gadag, V.; Ferdous, R. Network based approach for predictive accident modelling. Saf. Sci. 2015, 80, 274–287. [Google Scholar] [CrossRef]
- Liu, H.; Guo, Y. Design and implementation of fire prediction model based on scenario data. Technol. Innov. Appl. 2018, 26, 79–80. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction of Variable and Feature Selection. J. Mach. Learn. Res. Spec. Issue Var. Feature Sel. 2003, 3, 1157–1182. [Google Scholar]
- Liang, H.; Zhang, M.; Wang, H. A Neural Network Model for Wildfire Scale Prediction Using Meteorological Factors. IEEE Access 2019, 7, 176746–176755. [Google Scholar] [CrossRef]
- Neil, M. Risk Assessment and Decision Analysis with Bayesian Networks, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar]
- Gu, X.; Wu, Z.; Zhang, Y.; Yan, S.; Fu, J.; Du, L. Prediction research of the forest fire in Jiangxi province in the background of climate change. Acta Ecol. Sin. 2020, 40, 667–677. [Google Scholar]
- Bai, H.; Liu, X.; Niu, S.; He, Y. Construction of forest fire prediction model based on Bayesian model averaging method: Taking Dali Prefecture, Yunnan Province of southwestern China as an example. J. Beijing For. Univ. 2021, 43, 44–52. [Google Scholar]
- Chang, Y.; Zhu, Z.; Bu, R.; Chen, H.; Feng, Y.; Li, Y.; Hu, Y.; Wang, Z. Predicting fire occurrence patterns with logistic regression in Heilongjiang Province, China. Landsc. Ecol. 2013, 28, 1989–2004. [Google Scholar] [CrossRef]
- Pollino, C.A.; Woodberry, O.; Nicholson, A.; Korb, K.; Hart, B.T. Parameterisation and evaluation of a Bayesian network for use in an ecological risk assessment. Environ. Model. Softw. 2007, 22, 1140–1152. [Google Scholar] [CrossRef]
- De Iuliis, M.; Kammouh, O.; Cimellaro, G.P.; Tesfamariam, S. Quantifying restoration time of pipelines after earthquakes: Comparison of Bayesian belief networks and fuzzy models. Int. J. Disaster Risk Reduct. 2021, 64, 102491. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test No. | First-Level Indicators | Scenario Data (Illustration) | Abbr. | Deviation |
|---|---|---|---|---|
| 1 | Safety awareness y1 | propaganda situation fire propaganda method (internet, slogans, lectures, etc.) | x1 x2 | frequent, normal, less variety, ordinary, single |
| 2 | Adverse effects y2 | number of dead number of injures direct economic loss affected households | x3 x4 x5 x6 | [0, 0.33), [0.33, 0.67), [0.67, 1] [0, 0.33), [0.33, 0.67), [0.67, 1] [0, 0.2), [0.2, 0.4), [0.4, 0.6), [0.6, 0.8), [0.8, 1] [0, 0.2), [0.2, 0.4), [0.4, 0.6), [0.6, 0.8), [0.8, 1] |
| Cause of the fire (electrical, production operations, accidental use of fire, smoking, nature, lightning strikes, static electricity, arson, etc.) | x7 | dominant reason | ||
| 3 | Emergency rescue capability y3 | alarm dispatch situation number of combatants number of dispatched vehicles number of rescuers salvage property value joint training situation emergency plan preparation fire research results | x8 x9 x10 x11 x12 x13 x14 x15 | [0, 0.2), [0.2, 0.4), [0.4, 0.6), [0.6, 0.8), [0.8, 1] [0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1] [0, 0.2), [0.2, 0.4), [0.4, 0.6), [0.6, 0.8), [0.8, 1] [0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1] [0, 0.33), [0.33, 0.67), [0.67, 1] frequent, normal, less sufficient, general, insufficient yes, no |
| 4 | Equipment and facilities y4 | number of fire stations number of fire engines number of rescue equipment public fire protection facilities (fire hydrants, smoke alarms, etc.) | x16 x17 x18 x19 | [0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1] [0, 0.25), [0.25, 0.5), [0.5, 0.75), [0.75, 1] [0, 0.2), [0.2, 0.4), [0.4, 0.6), [0.6, 0.8), [0.8, 1] perfect, average, lacking |
| 5 | Supervision intensity y5 | organizational structure (informatization, flattening, and standardization) hidden danger rectification rate ((Nrectifications)/(Ndiscoveries)) fire protection expenditure utilization rate ((use/approve)) | x20 x21 x22 | reasonable, unreasonable high, medium, low high, medium, low |
| AUC | [0.5, 0.7] | [0.7, 0.85] | [0.85, 0.95] | [0.95, 1] |
|---|---|---|---|---|
| Effect | low | fair | good | perfect |
| Text No. | Data Screening Method | m Value |
|---|---|---|
| 1 | / | 5 |
| 2 | Filtering | 5 |
| 3 | HAZOP | 5 |
| 4 | HAZOP | m |
| Nodes | y5 | y1 | y4 | y3 | y2 |
|---|---|---|---|---|---|
| ER | 0.7175 | 0.3238 | 0.261 | 0.1376 | 0.1279 |
| Percentage (%) | 45.33 | 26.77 | 20.11 | 9.67 | 8.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Yang, M.; Li, T.; Jiang, X.; Lu, K. Research and Application of Improved Multiple Imputation Based on R Language in Fire Prediction. Fire 2023, 6, 235. https://doi.org/10.3390/fire6060235
Wang J, Yang M, Li T, Jiang X, Lu K. Research and Application of Improved Multiple Imputation Based on R Language in Fire Prediction. Fire. 2023; 6(6):235. https://doi.org/10.3390/fire6060235
Chicago/Turabian StyleWang, Jie, Meilin Yang, Tianming Li, Xuepeng Jiang, and Kaihua Lu. 2023. "Research and Application of Improved Multiple Imputation Based on R Language in Fire Prediction" Fire 6, no. 6: 235. https://doi.org/10.3390/fire6060235