

Predicting Wind Comfort in an Urban Area: A Comparison of a Regression- with a Classification-CNN for General Wind Rose Statistics
 , , , , ,
, , , , ,  and
and
Abstract
:1. Introduction
2. Setup
2.1. Study Area
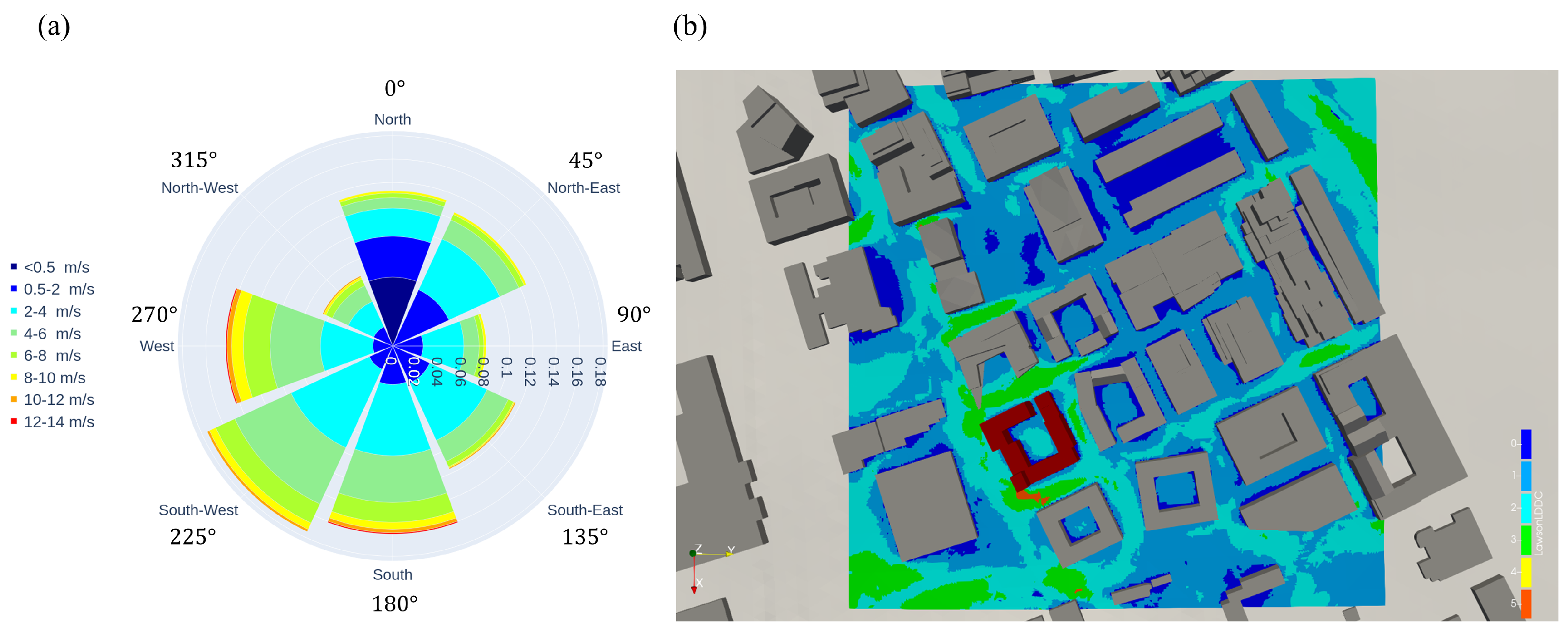
2.2. Wind Rose Statistic and Wind Comfort
Extreme Case Scenarios
2.3. CFD Simulation
2.4. Performed Simulations
3. Machine Learning Models
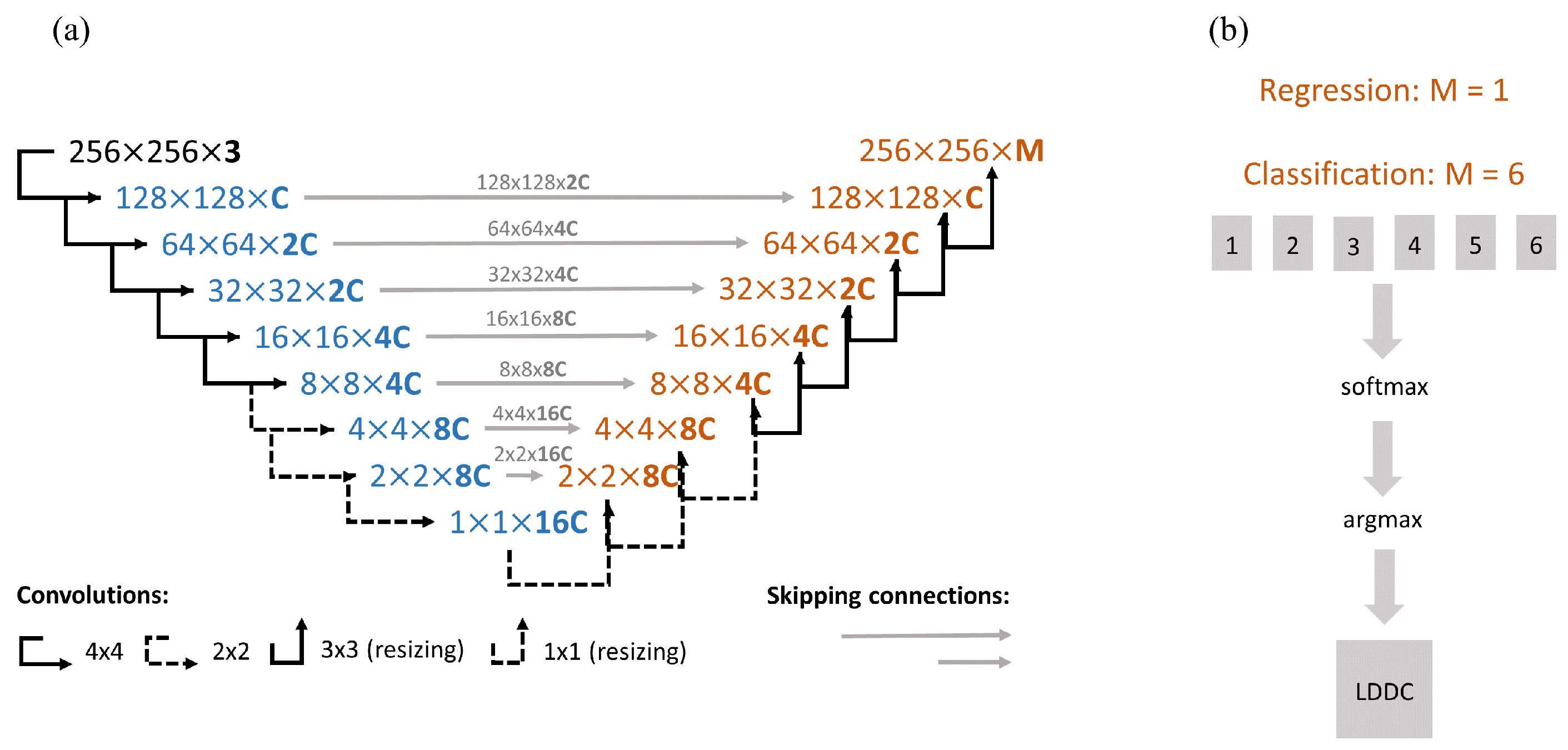
3.1. Architecture of the CNN
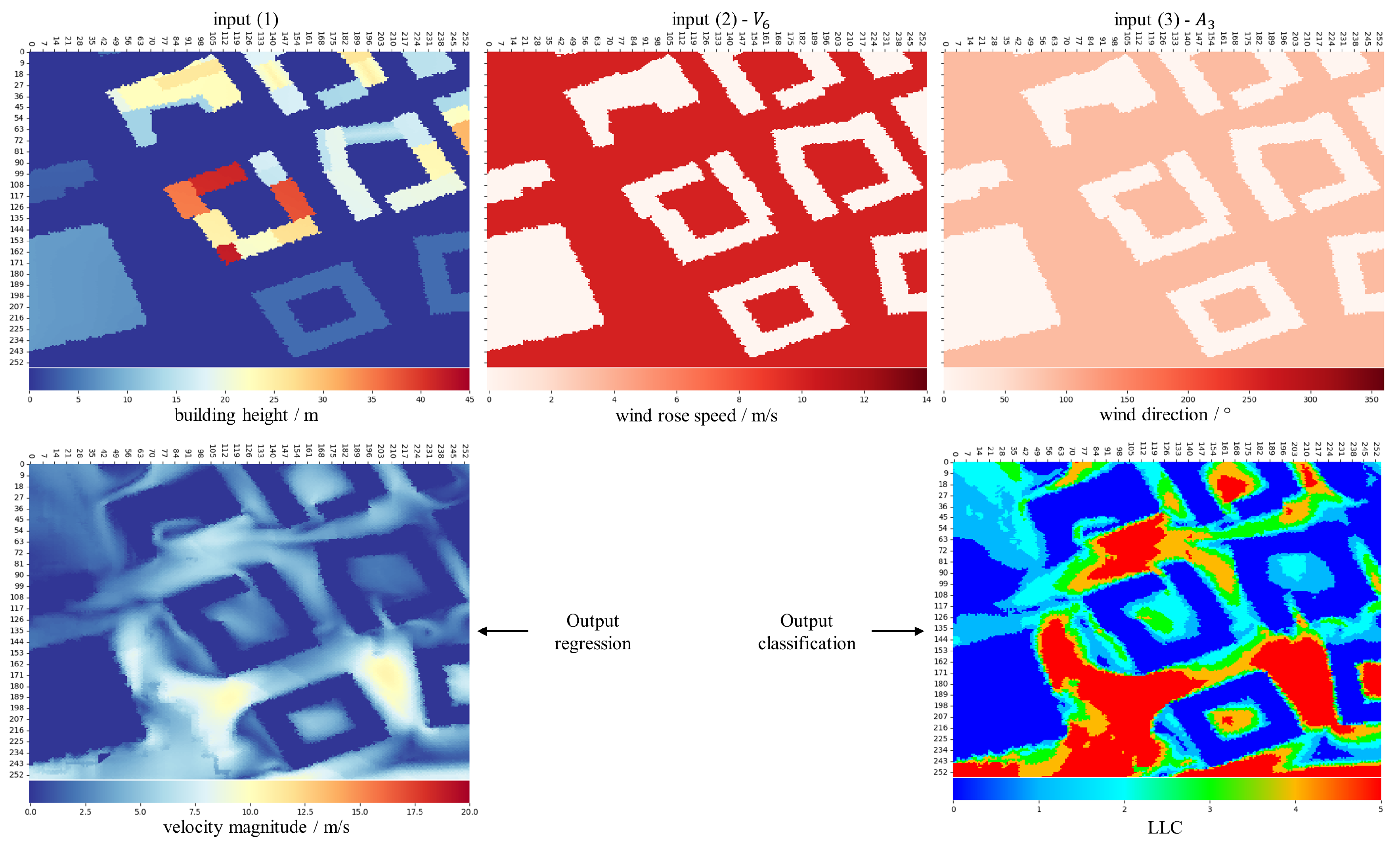
3.2. Inputs and Outputs
3.3. Decision Tree Classifier
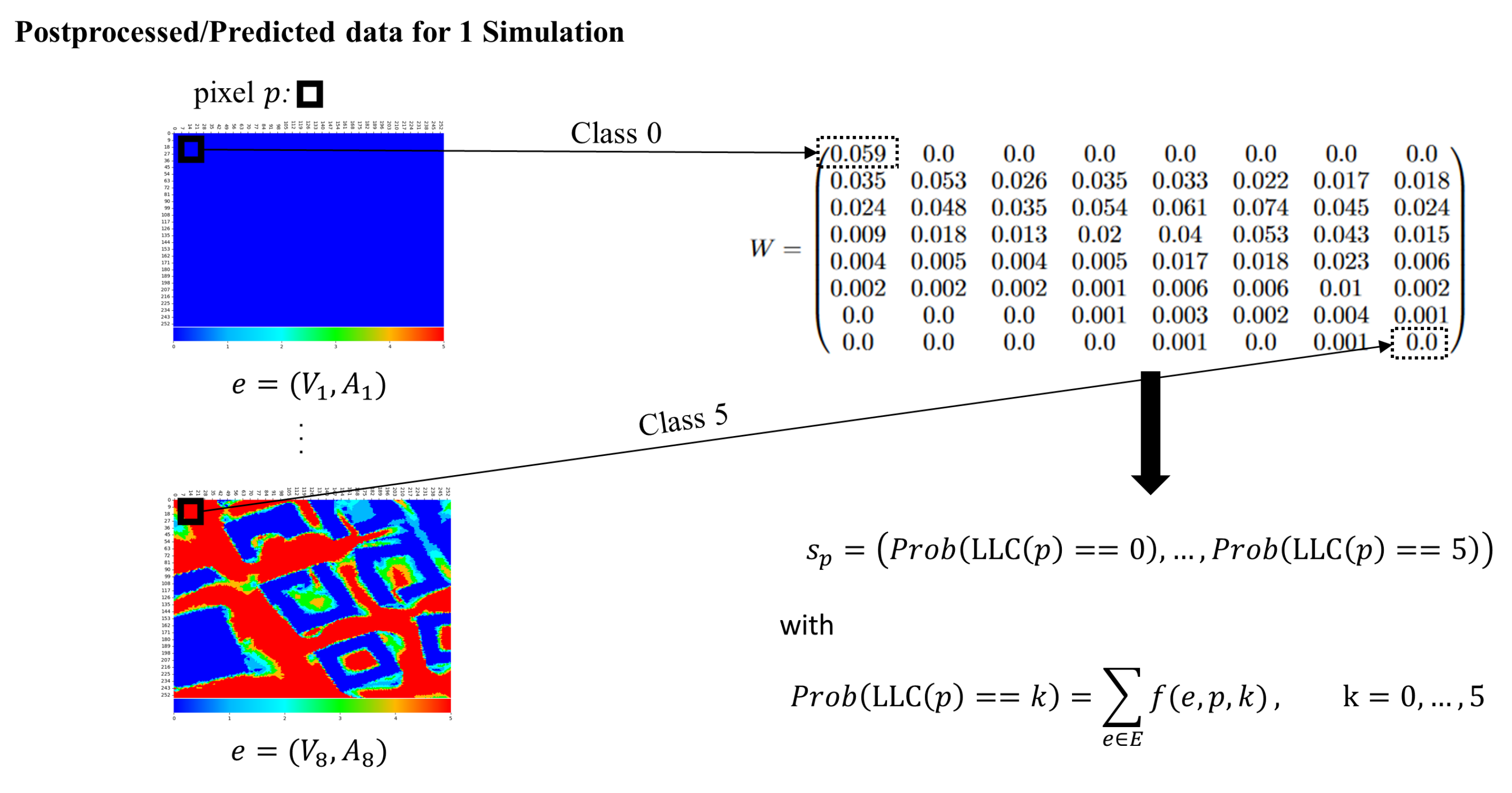
Data Accumulation
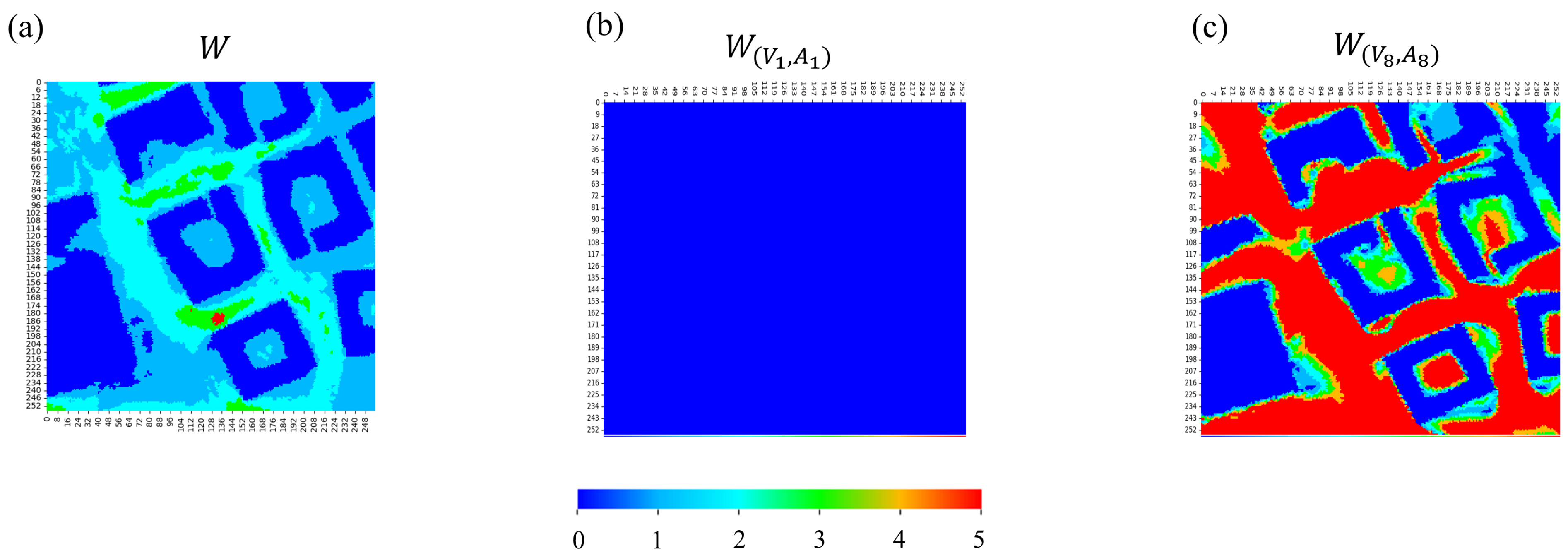
3.4. Post-Processing and Augmenting CFD Simulations for Training
3.5. Machine Learning Workflow
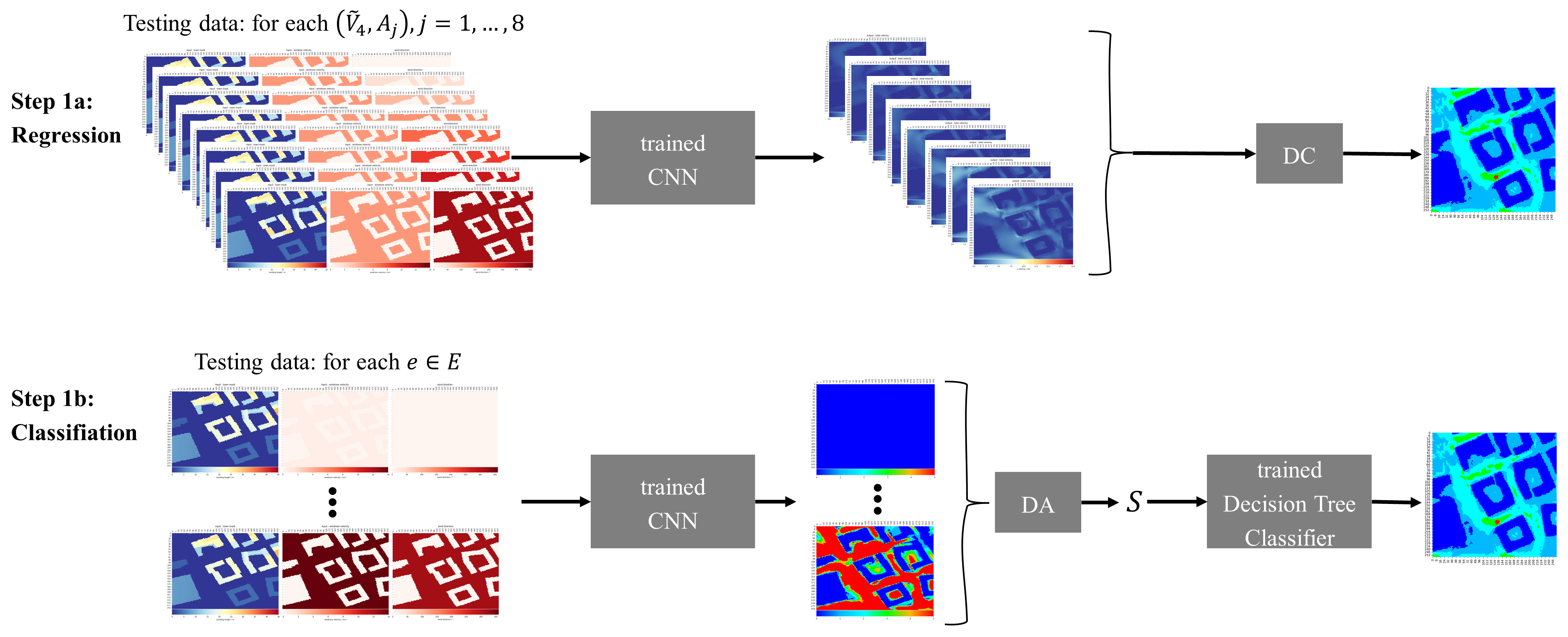
3.5.1. Prediction Workflow for Regression Model
3.5.2. Prediction Workflow for Classification Model
3.6. Error Metrics
4. Training Results
4.1. Regression Model
4.1.1. Hyperparameter Optimization
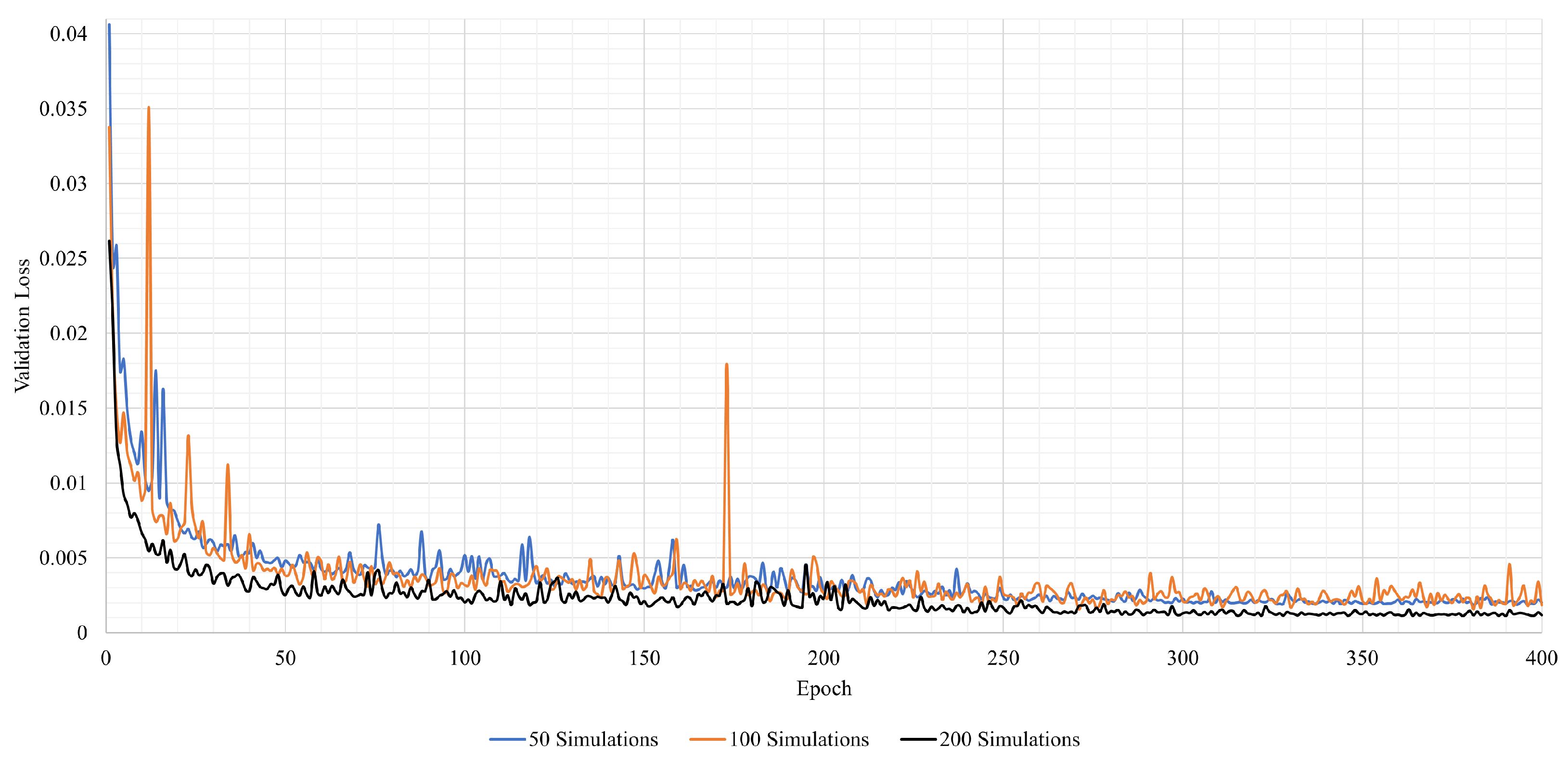
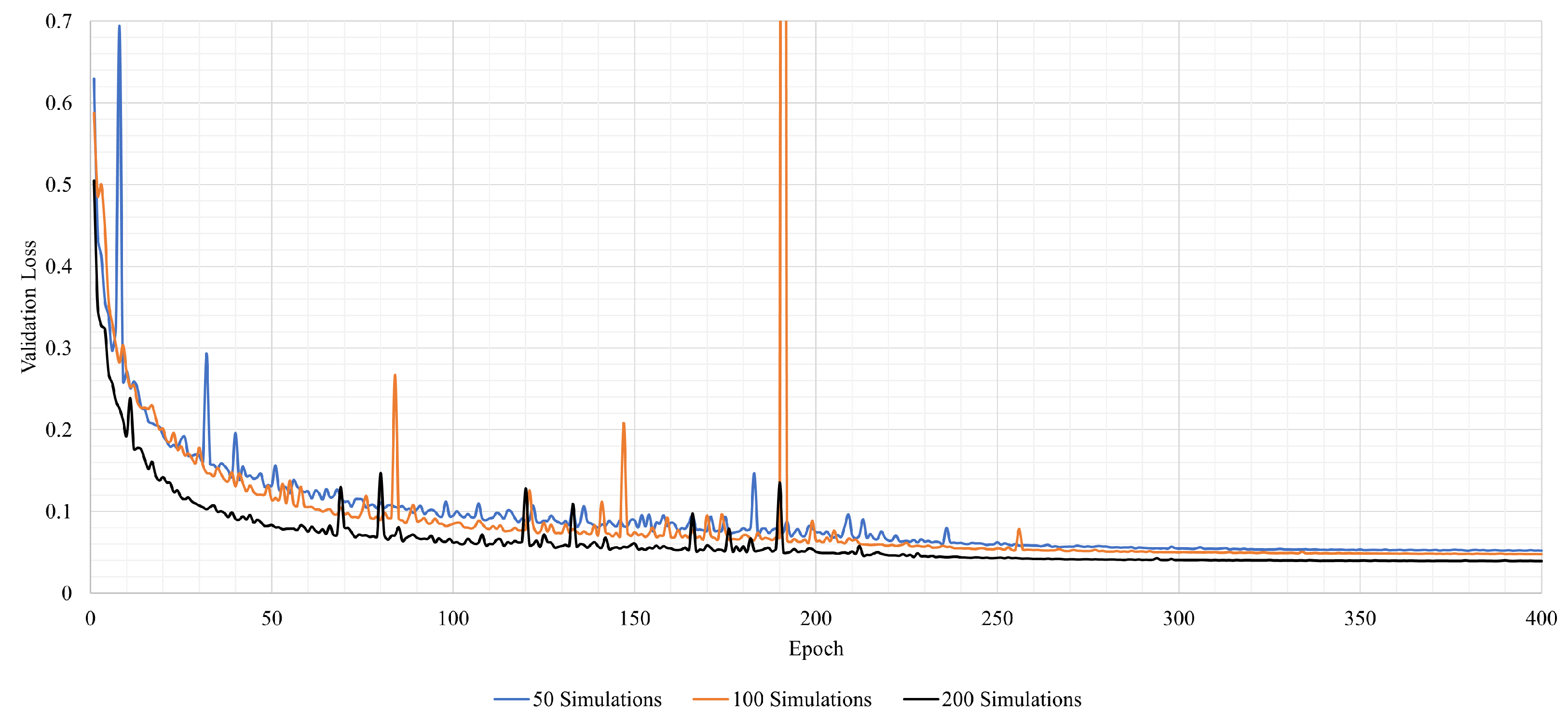
4.1.2. Training
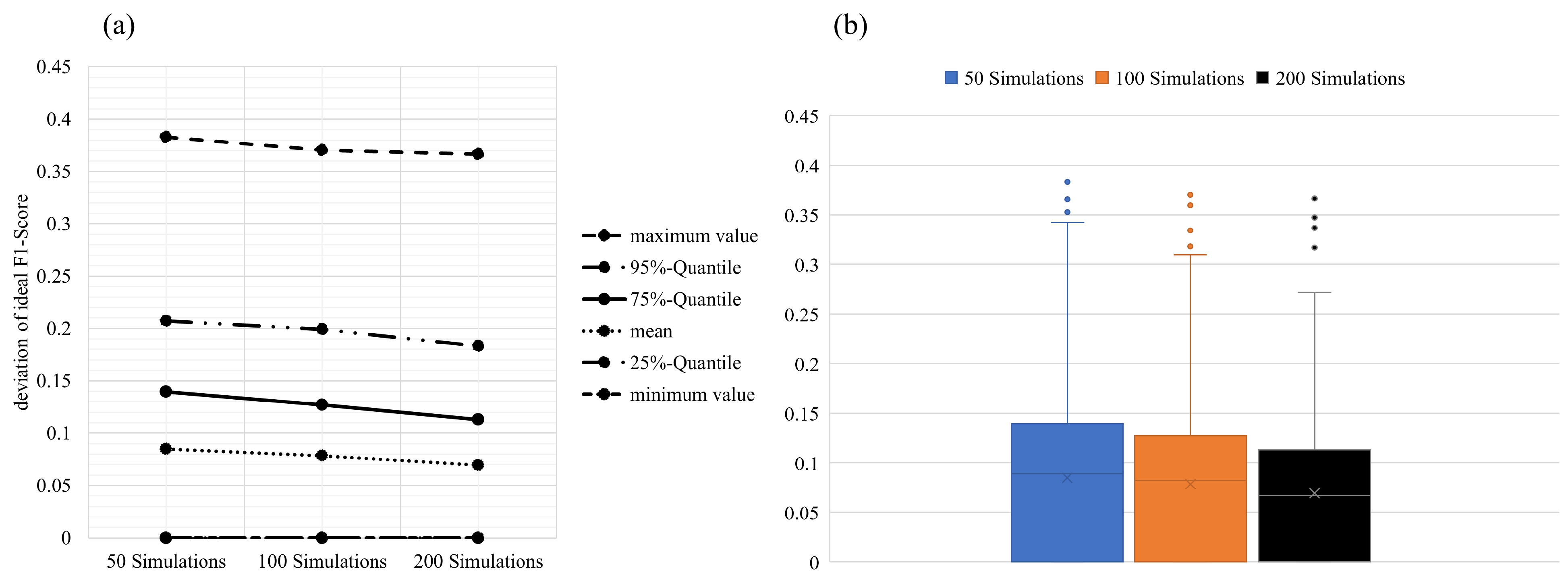
4.1.3. Performance on Test Set
4.1.4. Discussion
4.2. Classification Model
4.2.1. Hyperparameter Optimization
4.2.2. Training
4.2.3. Decision Tree Classifier Training
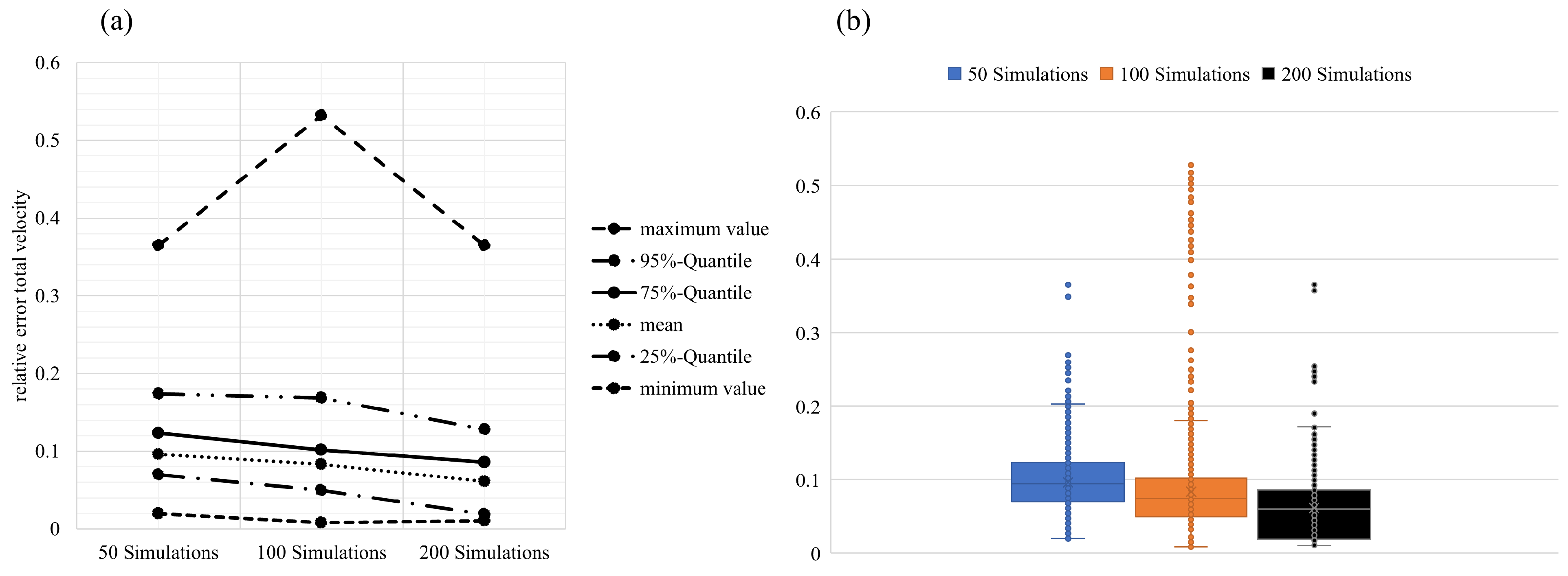
4.2.4. Performance on Test Set
4.2.5. Discussion
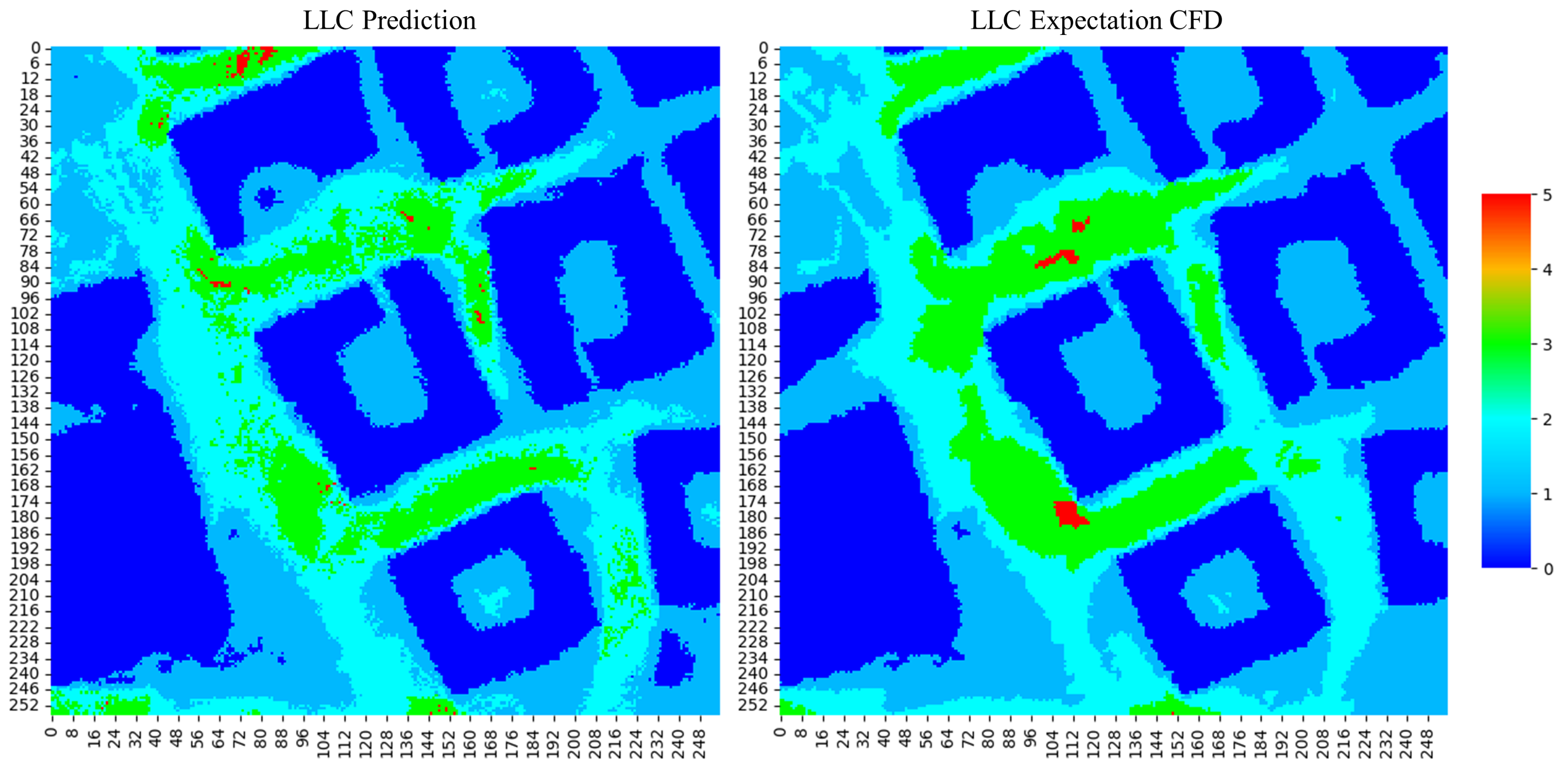
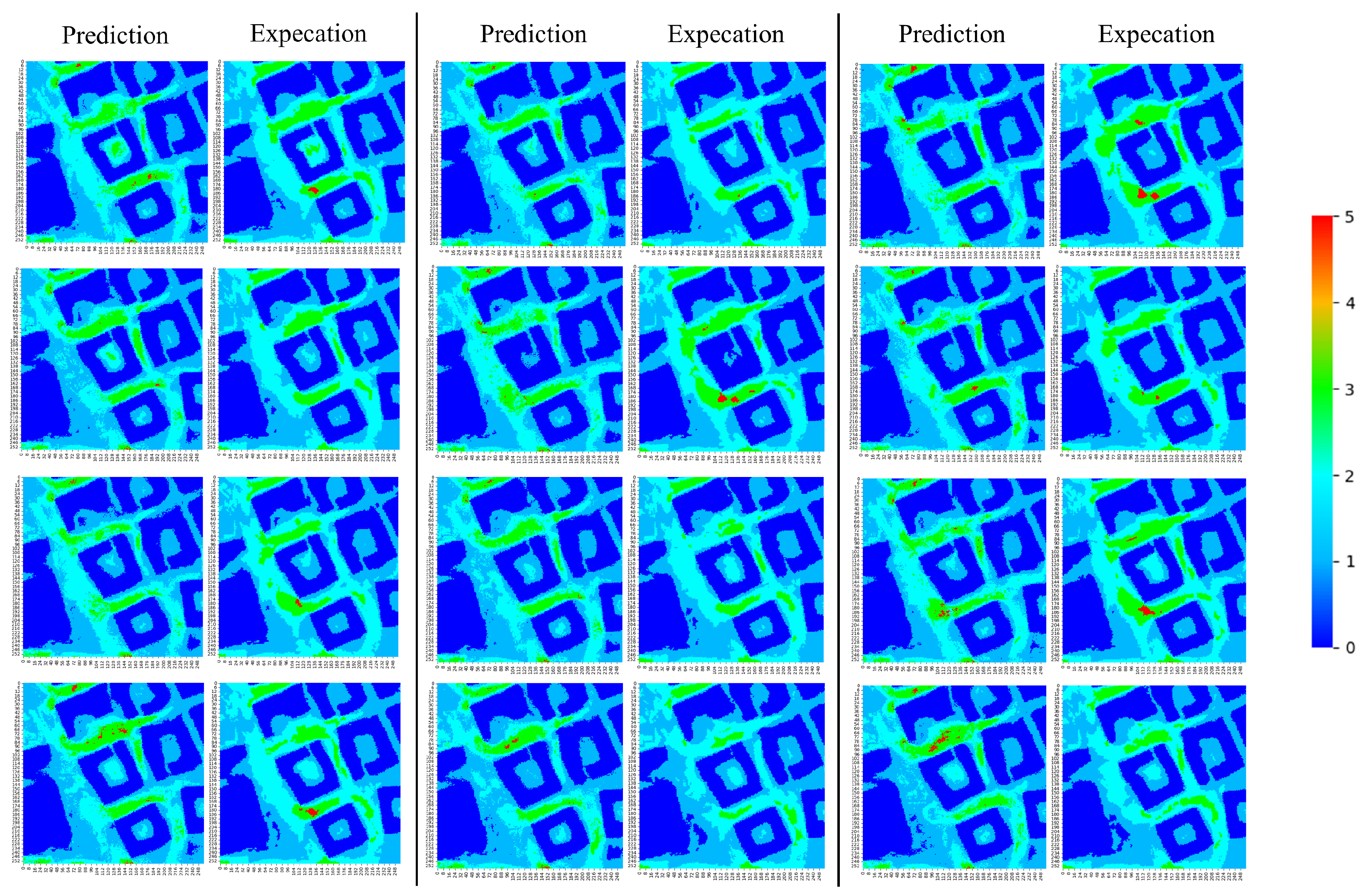
4.3. Wind Comfort Predictions with Regression and Classification Models
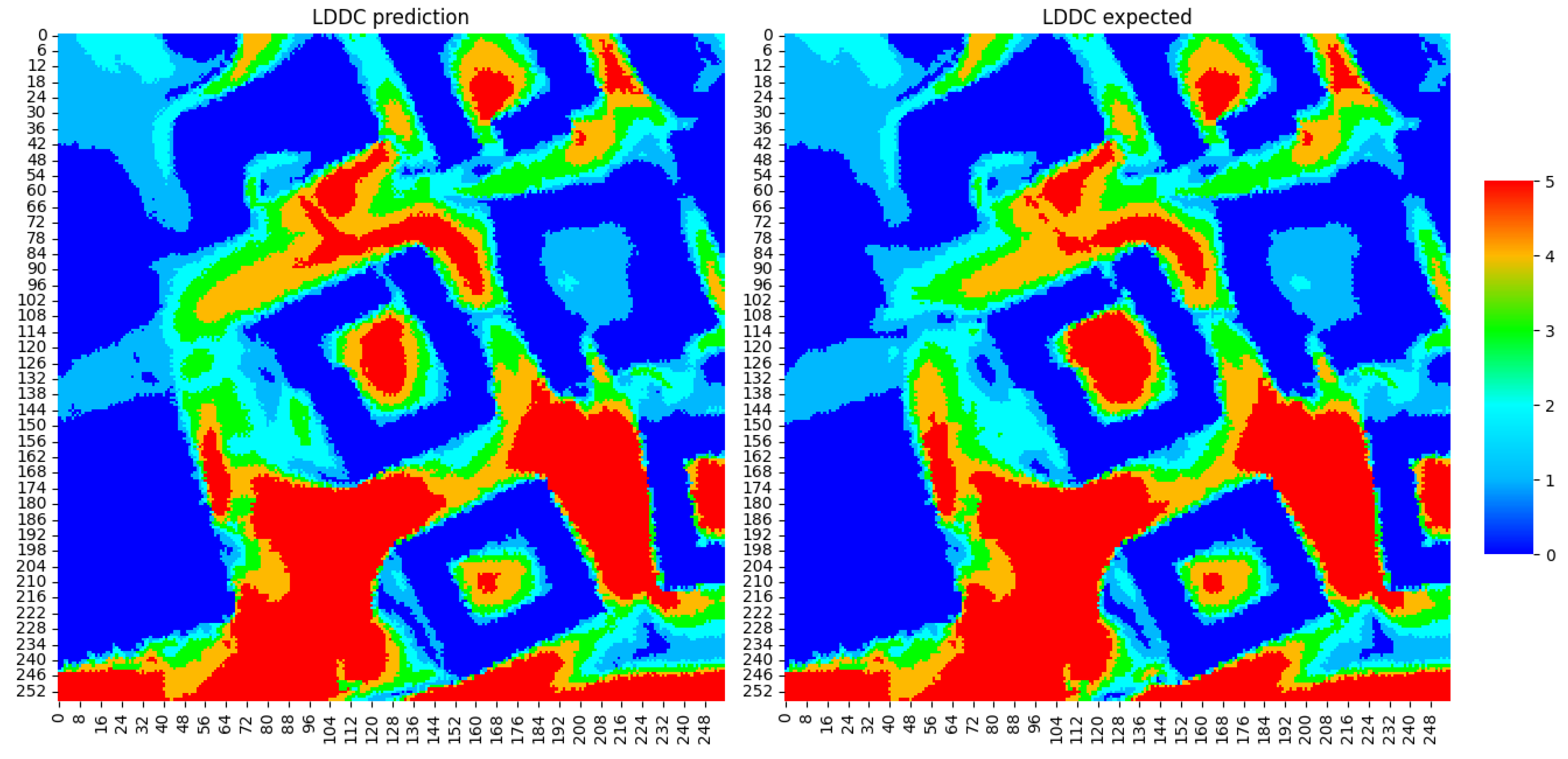
4.3.1. Regression Model
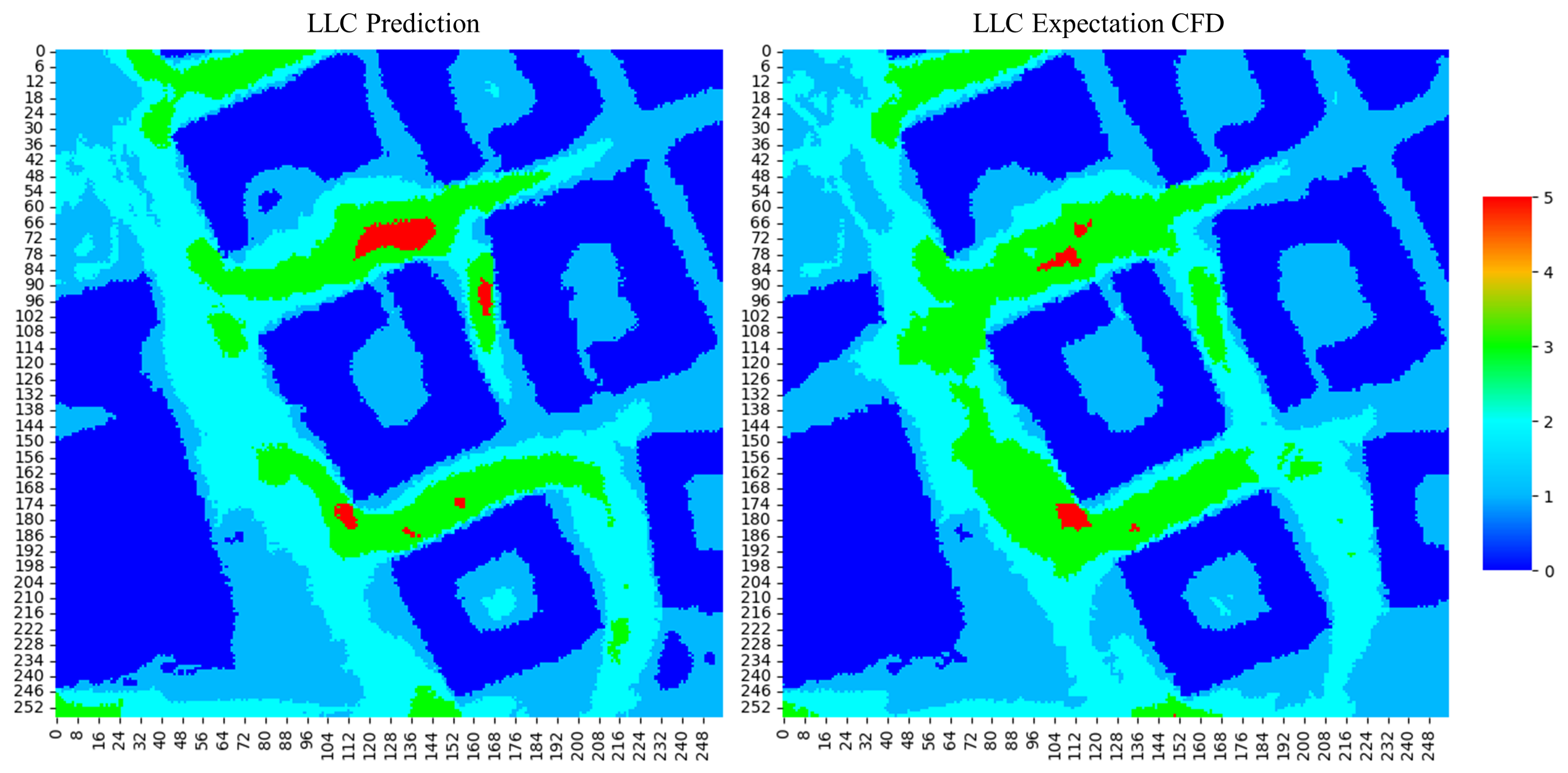
4.3.2. Classification Model
4.3.3. Summary
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
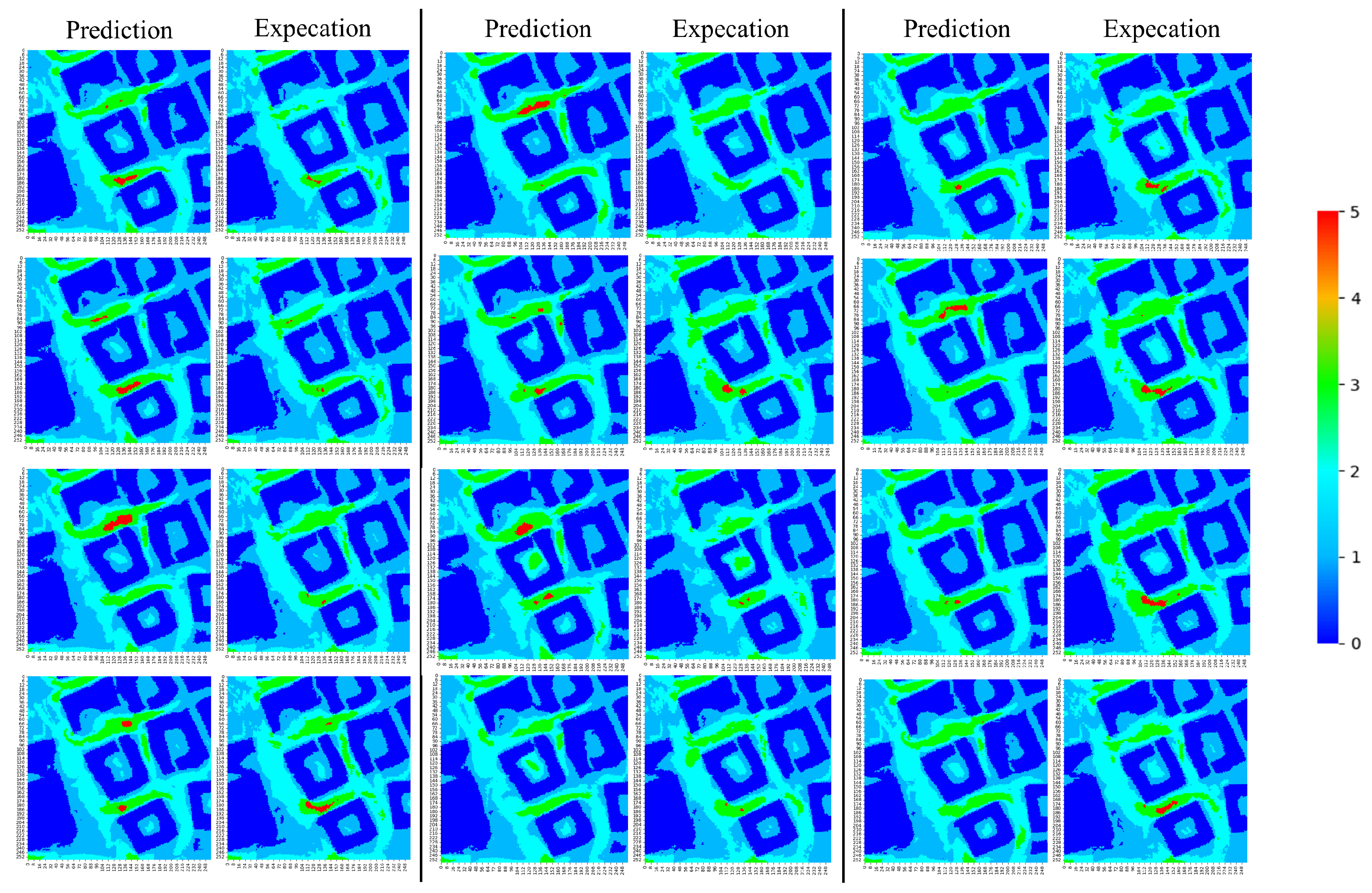
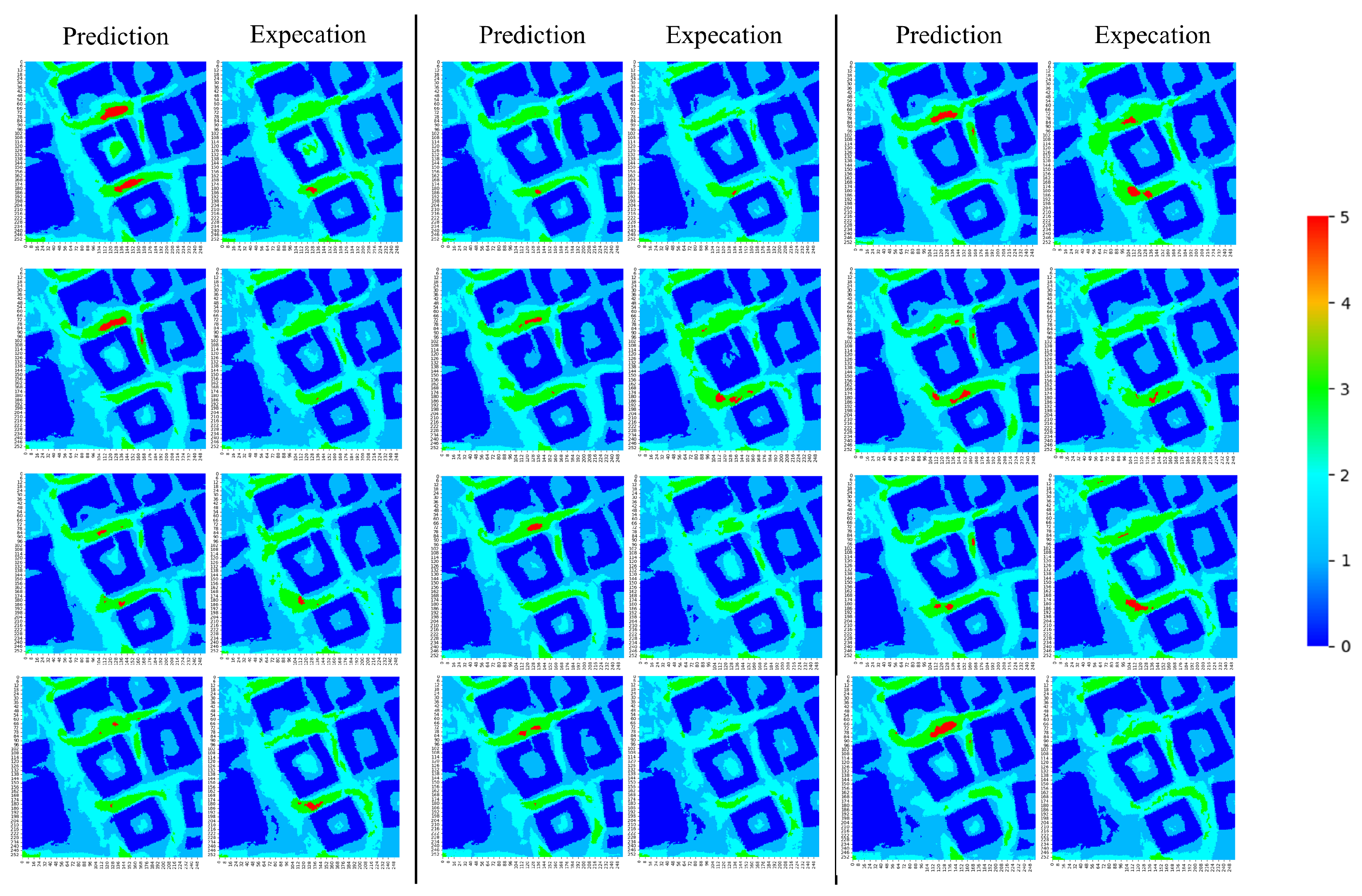
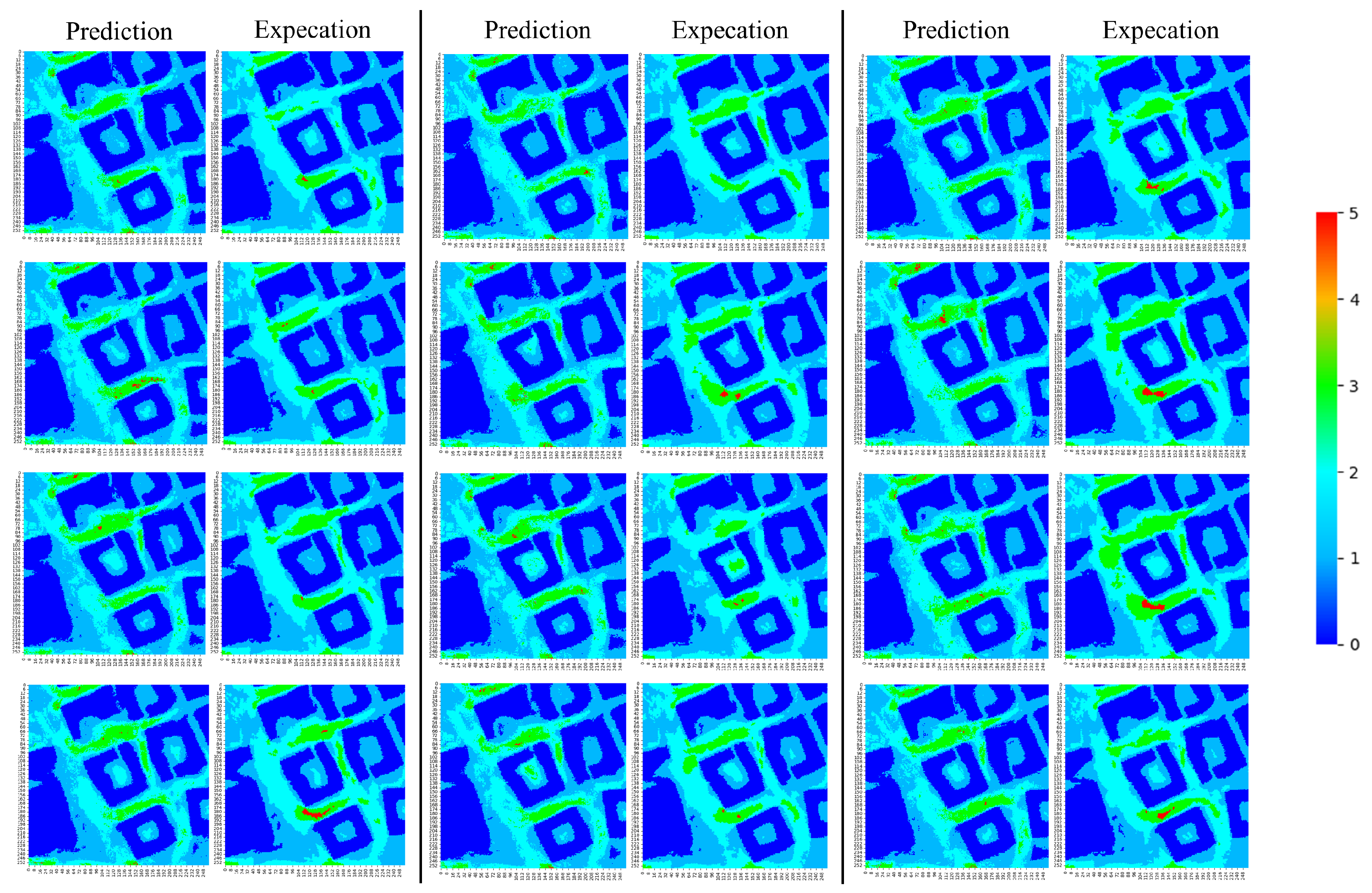
Appendix A. LLC Test Set

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample No. | Class 0 | Class 1 | Class 2 | Class 3 | Class 4 | Class 5 |
|---|---|---|---|---|---|---|
| 1 | 27,929 | 21,018 | 14,805 | 2391 | 0 | 30 |
| 2 | 27,311 | 21,936 | 13,095 | 3171 | 0 | 23 |
| 3 | 27,162 | 20,424 | 14,131 | 3808 | 0 | 11 |
| 4 | 26,207 | 19,537 | 12,753 | 6877 | 0 | 162 |
| 5 | 27,158 | 20,216 | 14,056 | 3887 | 0 | 219 |
| 6 | 26,988 | 20,630 | 14,158 | 3760 | 0 | 0 |
| 7 | 27,116 | 19,294 | 14,328 | 4692 | 0 | 106 |
| 8 | 27,115 | 21,864 | 13,800 | 2728 | 0 | 29 |
| 9 | 27,208 | 19,976 | 14,660 | 3668 | 0 | 24 |
| 10 | 26,889 | 19,810 | 14,884 | 3852 | 0 | 101 |
| 11 | 26,402 | 19,053 | 14,406 | 5464 | 0 | 211 |
| 12 | 26,486 | 18,940 | 13,695 | 6188 | 0 | 227 |
| 13 | 27,199 | 20,143 | 14,624 | 3447 | 0 | 123 |
| 14 | 26,640 | 19,541 | 14,695 | 4579 | 0 | 81 |
| 15 | 27,251 | 20,558 | 13,943 | 3784 | 0 | 0 |
| 16 | 27,260 | 19,905 | 14,345 | 373 | 0 | 53 |
| 17 | 26,964 | 19,656 | 14,975 | 3813 | 0 | 128 |
| 18 | 27,243 | 20,661 | 14,775 | 2851 | 0 | 6 |
| 19 | 27,592 | 19,111 | 13,104 | 5537 | 0 | 192 |
| 20 | 27,318 | 20,716 | 14,737 | 265 | 0 | 0 |
| 21 | 27,941 | 21,926 | 13,478 | 2191 | 0 | 0 |
| 22 | 26,836 | 19,527 | 13,173 | 5735 | 0 | 265 |
| 23 | 27,080 | 19,942 | 13,874 | 4610 | 0 | 30 |
| 24 | 26,588 | 19,114 | 13,964 | 5676 | 0 | 194 |
| 25 | 27,652 | 20,894 | 13,846 | 3144 | 0 | 0 |




References
- Lawson, T.V. The effect of wind on people in the vicinity of buildings. In Proceedings of the 4th International Conference on Wind Effects on Buildings and Structures, London, UK, September 1975. [Google Scholar]
- Allegrini, J. A wind tunnel study on three-dimensional buoyant flows in street canyons with different roof shapes and building lengths. Build. Environ. 2018, 143, 71–88. [Google Scholar] [CrossRef]
- Blocken, B.; Janssen, W.D.; van Hooff, T. CFD simulation for pedestrian wind comfort and wind safety in urban areas: General decision framework and case study for the Eindhoven University campus. Environ. Model. Softw. 2012, 30, 15–34. [Google Scholar] [CrossRef]
- Fadl, M.S.; Karadelis, J. CFD Simulation for Wind Comfort and Safety in Urban Area: A Case Study of Coventry University Central Campus. Int. J. Archit. Eng. Constr. 2013, 2, 131–143. [Google Scholar] [CrossRef]
- Zheng, C.; Li, Y.; Wu, Y. Pedestrian-level wind environment on outdoor platforms of a thousand-meter-scale megatall building: Sub-configuration experiment and wind comfort assessment. Build. Environ. 2016, 106, 313–326. [Google Scholar] [CrossRef]
- Wu, H.; Kriksic, F. Designing for pedestrian comfort in response to local climate. J. Wind Eng. Ind. Aerodyn. 2012, 104–106, 397–407. [Google Scholar] [CrossRef]
- Willemsen, E.; Wisse, J.A. Design for wind comfort in The Netherlands: Procedures, criteria and open research issues. J. Wind Eng. Ind. Aerodyn. 2007, 95, 1541–1550. [Google Scholar] [CrossRef]
- Düring, S.; Chronis, A.; Koenig, R. Optimizing Urban Systems: Integrated optimization of spatial configurations. In Proceedings of the 11th Annual Symposium on Simulation for Architecture and Urban Design, Vienna, Austria, 25–27 May 2020. [Google Scholar]
- Purup, P.B.; Petersen, S. Research framework for development of building performance simulation tools for early design stages. Autom. Constr. 2020, 109, 102966. [Google Scholar] [CrossRef]
- Lino, M.; Fotiadis, S.; Bharath, A.A.; Cantwell, C.D. Current and emerging deep-learning methods for the simulation of fluid dynamics. Proc. R. Soc. A Math. Phys. Eng. Sci. 2023, 479, 20230058. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Farimani, A.B.; Gomes, J.; Pande, V.S. Deep Learning the Physics of Transport Phenomena. arXiv 2017, arXiv:1709.02432. [Google Scholar]
- Thuerey, N.; Weissenow, K.; Prantl, L.; Hu, X. Deep Learning Methods for Reynolds-Averaged Navier-Stokes Simulations of Airfoil Flows. AIAA J. 2020, 58, 25–36. [Google Scholar] [CrossRef]
- Low, S.J.; Raghavan, V.S.G.; Gopalan, H.; Wong, J.C.; Yeoh, J.; Ooi, C.C. FastFlow: AI for Fast Urban Wind Velocity Prediction. In Proceedings of the 2022 IEEE International Conference on Data Mining Workshops (ICDMW), Orlando, FL, USA, 28 November–1 December 2022. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mokhtar, S.; Sojka, A.; Davila, C.C. Conditional Generative Adversarial Networks for Pedestrian Wind Flow Approximation; Society for Modeling & Simulation International (SCS): San Diego, CA, USA, 2020. [Google Scholar]
- BenMoshe, N.; Fattal, E.; Leitl, B.; Arav, Y. Using Machine Learning to Predict Wind Flow in Urban Areas. Atmosphere 2023, 14, 990. [Google Scholar] [CrossRef]
- Eslamirad, N.; de Luca, F.; Sakari Lylykangas, K.; Ben Yahia, S. Data generative machine learning model for the assessment of outdoor thermal and wind comfort in a northern urban environment. Front. Archit. Res. 2023, 12, 541–555. [Google Scholar] [CrossRef]
- Mostafa, K.; Zisis, I.; Moustafa, M.A. Machine Learning Techniques in Structural Wind Engineering: A State-of-the-Art Review. Appl. Sci. 2022, 12, 5232. [Google Scholar] [CrossRef]
- Hoeiness, H.; Gjerde, K.; Oggiano, L.; Giljarhus, K.E.T.; Ruocco, M. Positional Encoding Augmented GAN for the Assessment of Wind Flow for Pedestrian Comfort in Urban Areas. arXiv 2021, arXiv:2112.08447. [Google Scholar]
- SMHI. Available online: https://www.smhi.se/data/meteorologi/ladda-ner-meteorologiska-observationer/#param=wind,stations=core,stationid=71420 (accessed on 2 October 2023).
- The City of London Corporation Wind Microclimate Guidelines for Developments in the City of London. 2019; pp. 1–15. Available online: https://www.cityoflondon.gov.uk/assets/Services-Environment/wind-microclimate-guidelines.pdf (accessed on 15 November 2023).
- Girin, A.; Lawson Wind Comfort Criteria: A Closer Look. Simscale Blog. 2021. Available online: https://www.simscale.com/blog/lawson-wind-comfort-criteria/ (accessed on 25 October 2022).
- Mark, A.; Rundqvist, R.; Edelvik, F. Comparison Between Different Immersed Boundary Conditions for Simulation of Complex Fluid Flows. Fluid Dyn. Mater. Process. 2011, 7, 241–258. [Google Scholar] [CrossRef]
- Mitkov, R.; Pantusheva, M.; Naserentin, V.; Hristov, P.; Wästberg, D.; Hunger, F.; Mark, A.; Petrova-Antonova, D.; Edelvik, F.; Logg, A. Using the Octree Immersed Boundary Method for urban wind CFD simulations. IFAC-PapersOnLine 2022, 55, 179–184. [Google Scholar] [CrossRef]
- Vanky, P.; Mark, A.; Haeger-Eugensson, M.; Tarraso, J.; Adelfio, M.; Kalagasidis, A.S.; Sardina, G. Addressing wind comfort in an urban area using an immersed boundary framework. Tech. Mech. 2023, 43, 151–161. [Google Scholar] [CrossRef]
- Andersson, T.; Nowak, D.; Johnson, T.; Mark, A.; Edelvik, F.; Küfer, K.H. Multiobjective Optimization of a Heat-Sink Design Using the Sandwiching Algorithm and an Immersed Boundary Conjugate Heat Transfer Solver. J. Heat Transf. 2018, 140, 102002. [Google Scholar] [CrossRef]
- Nowak, D.; Johnson, T.; Mark, A.; Ireholm, C.; Pezzotti, F.; Erhardsson, L.; Ståhlberg, D.; Edelvik, F.; Küfer, K.H. Multicriteria Optimization of an Oven With a Novel ϵ-Constraint-Based Sandwiching Method. J. Heat Transf. 2020, 143. [Google Scholar] [CrossRef]
- Nowak, D.; Werner, J.; Parsons, Q.; Johnson, T.; Mark, A.; Edelvik, F. Optimisation of city structures with respect to high wind speeds using U-Net models. Eng. Appl. Artif. Intell. Under Rev. 2024; in press. [Google Scholar]
- Brozovsky, J.; Simonsen, A.; Gaitani, N. Validation of a CFD model for the evaluation of urban microclimate at high latitudes: A case study in Trondheim, Norway. Build. Environ. 2021, 205, 108175. [Google Scholar] [CrossRef]
- Wieringa, J. Updating the Davenport roughness classification. J. Wind Eng. Ind. Aerodyn. 1992, 41, 357–368. [Google Scholar] [CrossRef]
- Aupoix, B. Roughness Corrections for the k–ω Shear Stress Transport Model: Status and Proposals. J. Fluids Eng. 2014, 137, 021202. [Google Scholar] [CrossRef]
- Kalitzin, G.; Medic, G.; Iaccarino, G.; Durbin, P. Near-wall behavior of RANS turbulence models and implications for wall functions. J. Comput. Phys. 2005, 204, 265–291. [Google Scholar] [CrossRef]
- Menter, F.R. Two-Equation Eddy-Viscosity Turbulence Models for Engineering Applications. AIAA J. 1994, 32, 1598–1605. [Google Scholar] [CrossRef]
- Menter, F.R.; Kuntz, M.; Langtry, M.R. Ten Years of Industrial Experience with the SST Turbulence Model. Turbul. Heat Mass Transf. 1994, 4, 625–632. [Google Scholar]
- Sobol’, I.M. On the distribution of points in a cube and the approximate evaluation of integrals. Zhurnal Vychislitel’noi Mat. Mat. Fiz. 1967, 7, 784–802. [Google Scholar] [CrossRef]
- Stoller, D.; Ewert, S.; Dixon, S. Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation. arXiv 2018, arXiv:1806.03185. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Giri, R.; Isik, U.; Krishnaswamy, A. Attention Wave-U-Net for Speech Enhancement. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Piscataway, NJ, USA, 20–23 October 2019. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 10 October 2023).
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical learning: Data Mining, Inference, and Prediction/Trevor Hastie, Robert Tibshirani, Jerome Friedman, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rebala, G.; Ravi, A.; Churiwala, S. An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]















| Segment | Width | Length | x Position | y Position | z Position | Rotation about z-Axis |
|---|---|---|---|---|---|---|
| 1 | m | m | m | m | m | ° |
| 2 | m | m | m | m | m | ° |
| 3 | m | m | m | m | m | ° |
| 4 | m | m | m | m | m | ° |
| 5 | m | m | m | m | m | ° |
| 6 | m | m | m | m | m | ° |
| 7 | m | m | m | m | m | ° |
| 8 | m | m | m | m | m | ° |
| 9 | m | m | m | m | m | ° |
| Class | Upper Velocity Limit in m/s | Exceedance Threshold | Comfort Level |
|---|---|---|---|
| A-0 | 2.5 | <5 | Frequent sitting |
| B-1 | 4 | <5 | Occasional sitting |
| C-2 | 6 | <5 | Standing |
| D-3 | 8 | <5 | Walking |
| E-4 | 8 | >5% | Uncomfortable |
| S-5 | 15 | >0.022% | Unsafe |
| Hyperparameter | Range/Set |
|---|---|
| channel exponent | * |
| dropout probability | |
| batch size | |
| maximum learning rate | |
| decaying learning rate |
| Setting | 50 Simulations | 100 Simulations | 200 Simulations |
|---|---|---|---|
| channel exponent L in Equation (6) | 7 | 8 | 8 |
| dropout probability | |||
| batch size | 6 | 6 | 6 |
| maximum learning rate | |||
| decaying learning rate | True | True | True |
| trainable parameters | 36,668,929 | 146,607,105 | 146,607,105 |
| number of training samples | 4536 | 8136 | 15,336 |
| Setting | 50 Simulations | 100 Simulations | 200 Simulations |
|---|---|---|---|
| channel exponent | 7 | 7 | 7 |
| dropout probability | |||
| batch size | 6 | 16 | 11 |
| maximum learning rate | |||
| decaying learning rate | True | True | True |
| trainable parameters | 36,689,414 | 36,668,929 | 36,689,414 |
| number of training samples | 4032 | 7232 | 13,632 |
| Hyperparameter | Range/Set |
|---|---|
| maximum depth of the tree | |
| min. number of samples leaf | |
| Optimal Hyperparameters | |
| maximum depth of the tree | 35 |
| min. number of samples leaf | 2 |
| Setting | 50 Simulations | 100 Simulations | 200 Simulations |
|---|---|---|---|
| Accuracy in % | 96.76 | 96.52 | 96.12 |
| Metric | 50 Simulations | 100 Simulations | 200 Simulations |
|---|---|---|---|
| Regression | |||
| Average -score Regression | |||
| Recall class 0 | |||
| Recall class 1 | |||
| Recall class 2 | |||
| Recall class 3 | |||
| Recall class 5 | |||
| Classification | |||
| Average -score Classification | |||
| Recall class 0 | |||
| Recall class 1 | |||
| Recall class 2 | |||
| Recall class 3 | |||
| Recall class 5 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Werner, J.; Nowak, D.; Hunger, F.; Johnson, T.; Mark, A.; Gösta, A.; Edelvik, F. Predicting Wind Comfort in an Urban Area: A Comparison of a Regression- with a Classification-CNN for General Wind Rose Statistics. Mach. Learn. Knowl. Extr. 2024, 6, 98-125. https://doi.org/10.3390/make6010006
Werner J, Nowak D, Hunger F, Johnson T, Mark A, Gösta A, Edelvik F. Predicting Wind Comfort in an Urban Area: A Comparison of a Regression- with a Classification-CNN for General Wind Rose Statistics. Machine Learning and Knowledge Extraction. 2024; 6(1):98-125. https://doi.org/10.3390/make6010006
Chicago/Turabian StyleWerner, Jennifer, Dimitri Nowak, Franziska Hunger, Tomas Johnson, Andreas Mark, Alexander Gösta, and Fredrik Edelvik. 2024. "Predicting Wind Comfort in an Urban Area: A Comparison of a Regression- with a Classification-CNN for General Wind Rose Statistics" Machine Learning and Knowledge Extraction 6, no. 1: 98-125. https://doi.org/10.3390/make6010006