

Event-Assisted Object Tracking on High-Speed Drones in Harsh Illumination Environment

Abstract
:1. Introduction
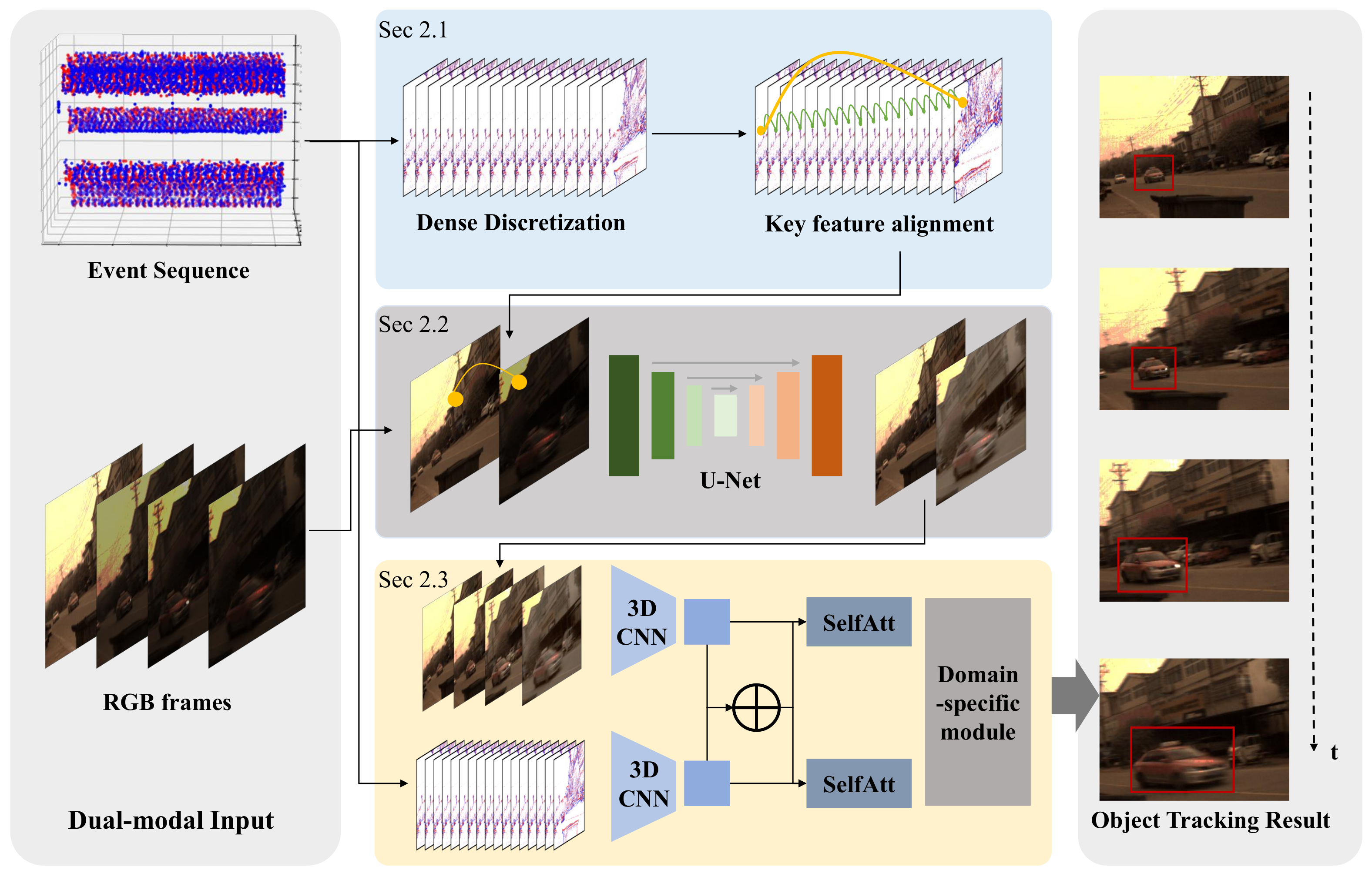
- We propose an event-assisted robust object-tracking algorithm working in high-dynamic-range scenes, which successfully integrates the information from an event camera and an RGB camera to overcome the negative impact of harsh illumination on tracking performance. As far as we know, this is the first work of object tracking under harsh illumination using dual-mode cameras.
- We construct an end-to-end deep neural network to enhance the high-dynamic-range RGB frames and conduct object tracking sequentially, and the model is built in an unsupervised manner. According to the quantitative experiment, the proposed solution improves tracking accuracy by up to 39.3%.
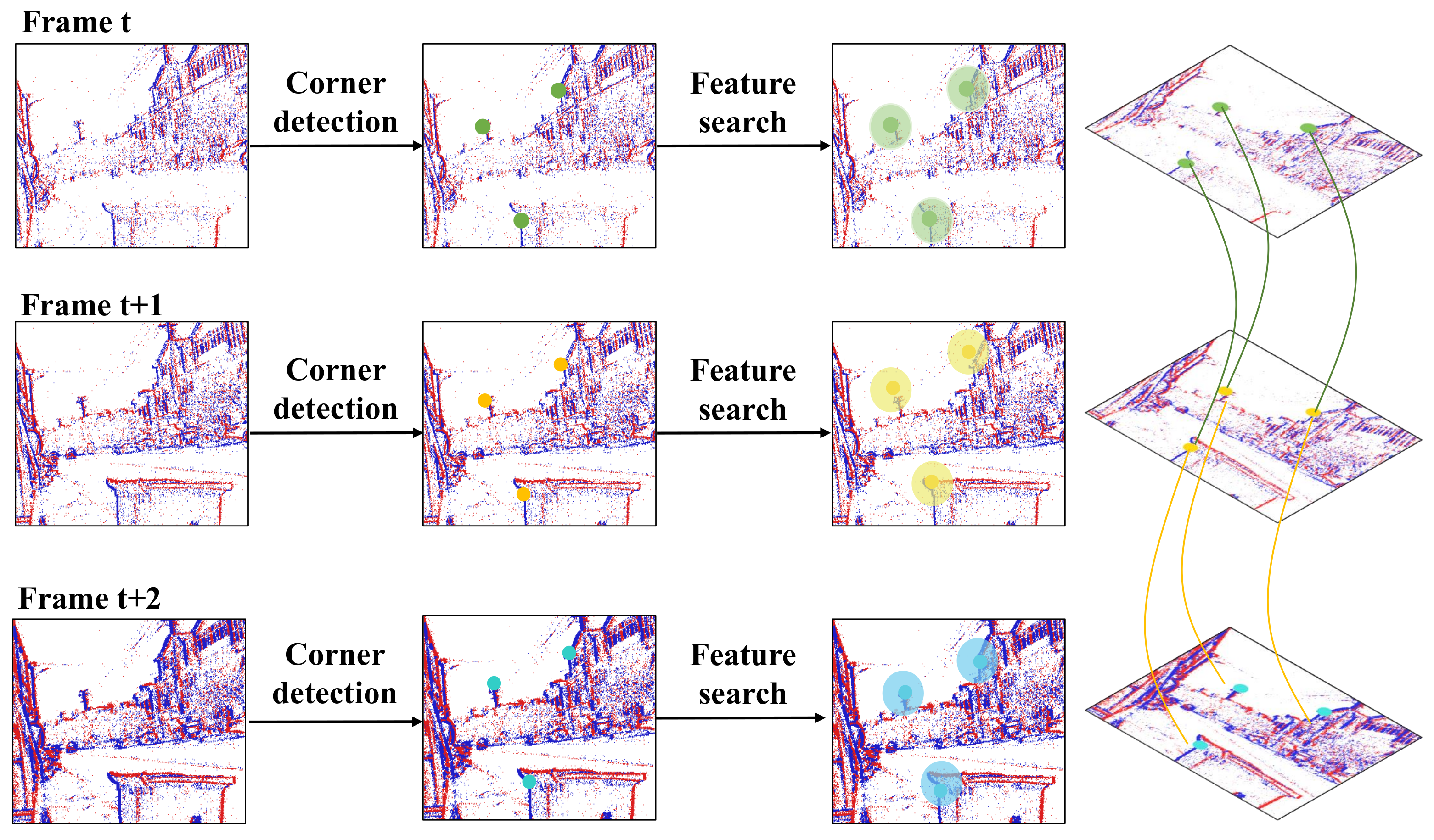
- We design an approach to match the feature points occurring at different time instants from the dense event sequence, which guides the intensity compensation in high-dynamic-range RGB frames. The proposed feature alignment can register the key points in high-dynamic-range frames occurring within a 1 s window.
- The approach demonstrates superb performance in a variety of harshly lit environments, which validates the effectiveness of the proposed approach and largely broadens the practical applications of drones.
2. Framework and Algorithm Design
- (i)
- Retrieving the motion trajectories of key feature points from the dense event sequence. We divide the event sequence into groups occurring in overlapping, short time windows, and the key points from Harris corner detection in each event group can construct some motion trajectories. Further, we integrate these short local trajectories to figure out the motion over a longer period across the RGB frames, even under harsh illumination.
- (ii)
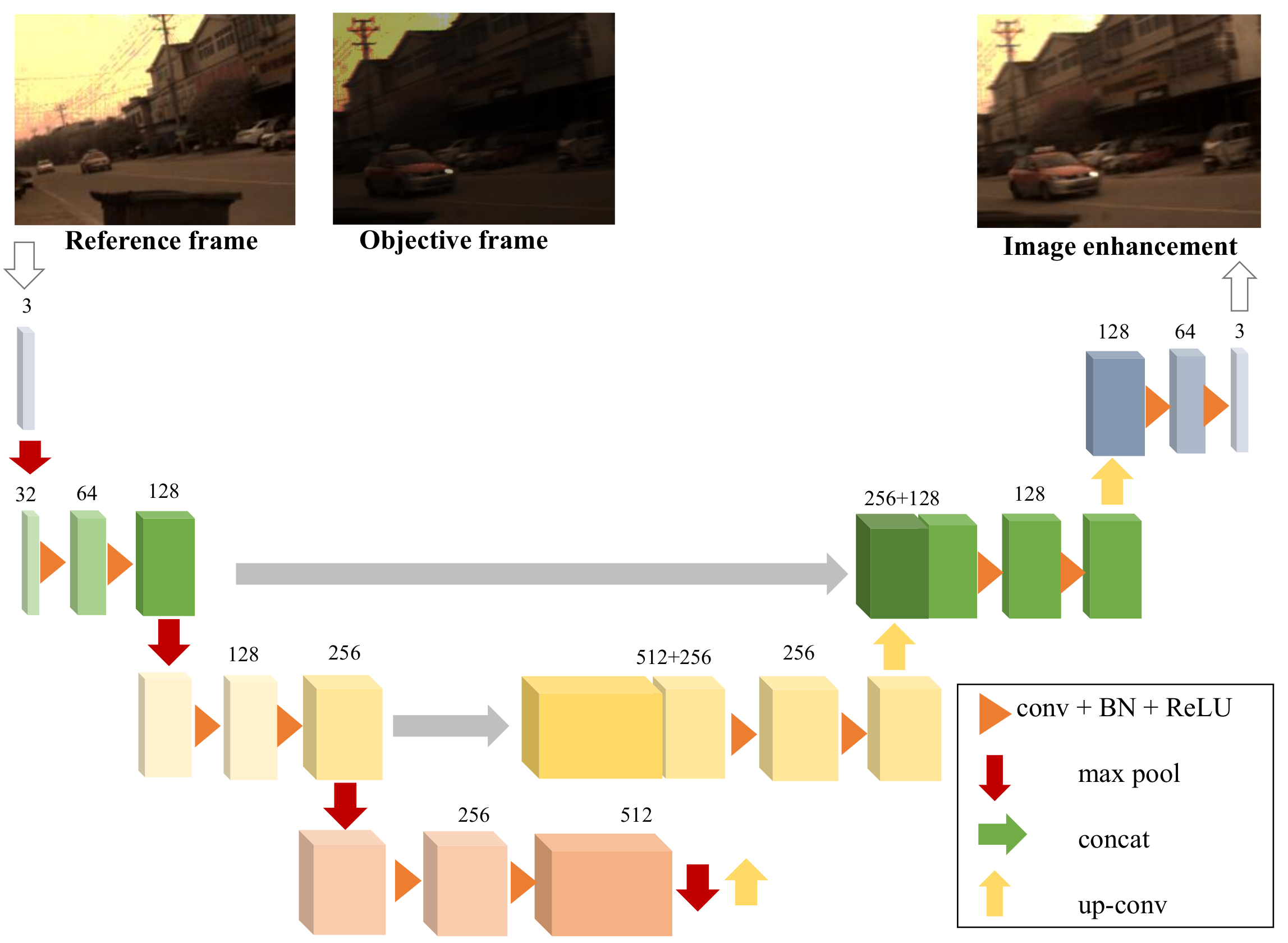
- Enhancing the high-dynamic-range RGB frame according to inter-frame matching and information propagation. Based on the matching among feature points across frames, we build a deep neural network to compensate for the overexposed or underexposed regions using neighboring frames with higher-visibility reference frames to guide low-visibility objective frames. In implementation, we build a U-Net-based neural network for image enhancement.
- (iii)
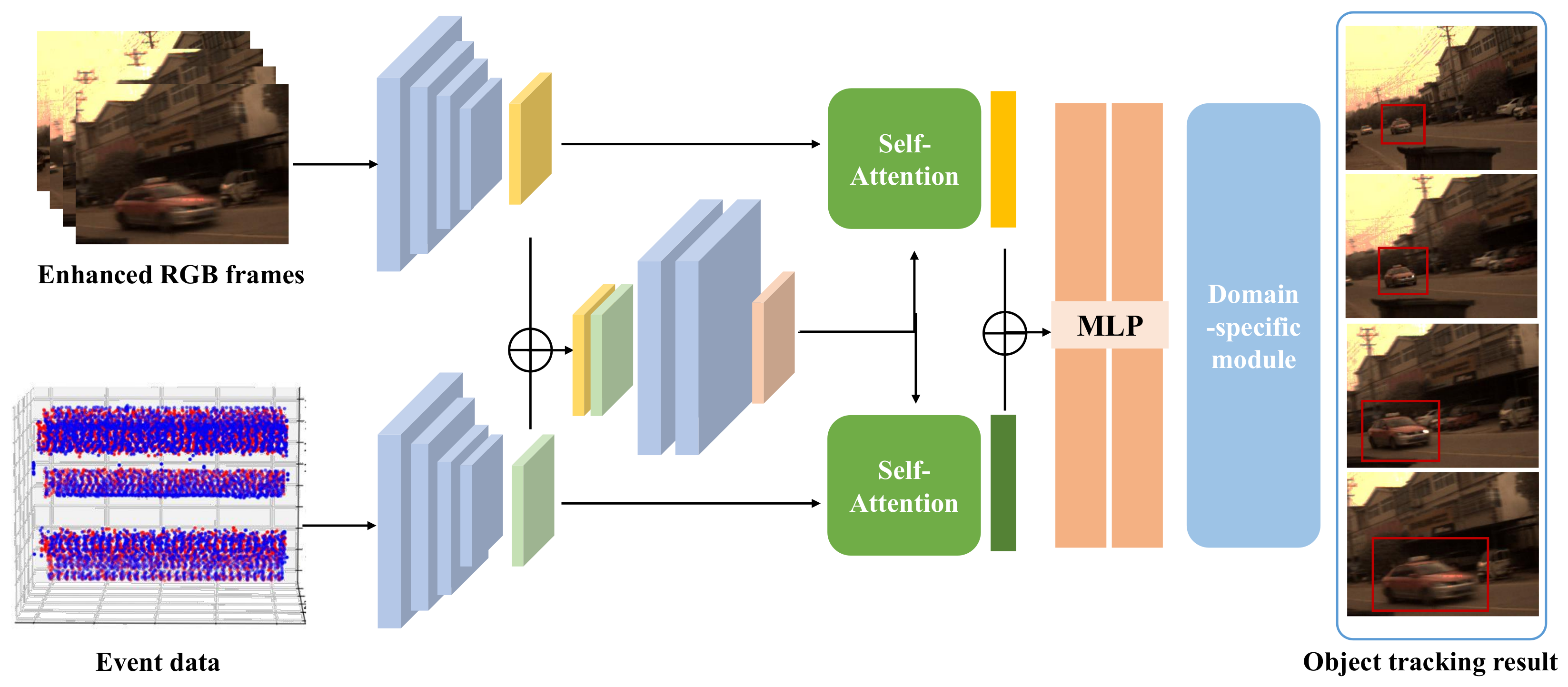
- Tracking the target objects by fusing information from both RGB and event inputs. We design a tracking model taking dual-mode inputs to aggregate the information from the enhanced RGB frames and event sequences to locate the motion trajectories. Specifically, we construct 3D CNNs for feature extraction, fuse the features from two arms using the self-attention mechanism, and then employ an MLP to infer the final object motion.
2.1. Event-Based Cross-Frame Alignment
2.2. RGB Image Enhancement
2.3. Dual-Mode Object Tracking
3. Experimental Settings
- Datasets. We verify the proposed method on both simulated and real datasets. We use VisEvent [52] as the simulated data and mimic harsh illumination by modifying the brightness and contrast of the RGB frames. Specifically, we modify the luminance and contrast as follows: We let the luminance vary linearly, quadratically, or exponentially across the frames, and the image contrast undergoes a linear change with different slopes. We first randomly select 1/3 of the data for luminance modification and then apply contrast modification to 1/3 randomly selected videos. Two examples from the simulated dataset are shown in Figure 6. The first scene mimics the brightness changes in the underexposed scenes, and the second scene simulates overexposure, through modification of image brightness and contrast. One can see that we can generate videos under complex illumination from the original counterpart with roughly uniform illuminance. In the generated high-dynamic-range RGB frames, the textures of some regions are invisible in some frames due to either underexposure or overexposure. In contrast, the contours across the whole field of view are recorded decently.

- Baseline algorithms. We choose three different algorithms with state-of-the-art tracking performance as baselines for the proposed solution, i.e., RT-MDNet [50], Siamrpn++ [53], and VisEvent [52]. RT-MDNet [50] and Siamrpn++ [53] are two RGB-input trackers performing well under normal illumination. So far, there are few objective algorithms specially developed for harsh illumination scenarios; we chose the above two robust and widely used tracking solutions as baselines. VisEvent [52] constructs a two-modality neural network fusing RGB and event signals, and we compare the proposed solution with VisEvent [52] to verify the effectiveness of the image enhancement module under harsh illumination. This benchmark has input similar to our method’s and exhibits state-of-the-art performance, serving as a good option to validate the proposed image enhancement module under harsh illumination.
- Training. Training is implemented on the NVIDIA 3090 for about 4.7 h. We set the input image size as well as the spatial resolution of the event sequence to pixels and seven continuous RGB frames (∼350 ms) for intensity balancing. We use the Adam optimizer, with the learning rate being 5 ×, the momentum being 0.9, and the weight decay being 5 ×.
4. Results
4.1. Results Based on Simulated Data
4.1.1. Qualitative Results
4.1.2. Quantitative Results
4.2. Results Based on Real-World Data
4.3. Ablation Studies
5. Summary and Discussions
- Limitations. The proposed algorithm mainly has two limitations. First, because of the involved complex calculations, it is difficult to deploy the algorithm into a UAV due to the limited arithmetic power. To achieve UAV deployment, it is necessary to further optimize the network structure for lightweight computation. Second, since the event camera can only capture the intensity changes in the scene, it is difficult to sense the targets being relatively stationary with respect to the event camera. Therefore, other complementary sensors need to be equipped for highly robust object tracking.
- Potential extensions. In the future, we will dig deeper into the characteristics of event signals and construct neural networks that are more compatible with event signals to realize lightweight network design and efficient learning. In addition, we will integrate sensing units such as LIDAR and IMUs to achieve depth-aware 3D representation of scenes.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Hu, J.; Lian, J.; Fan, Z.; Ouyang, X.; Ye, W. Seeing the forest from drones: Testing the potential of lightweight drones as a tool for long-term forest monitoring. Biol. Conserv. 2016, 198, 60–69. [Google Scholar] [CrossRef]
- Duffy, J.P.; Cunliffe, A.M.; DeBell, L.; Sandbrook, C.; Wich, S.A.; Shutler, J.D.; Myers-Smith, I.H.; Varela, M.R.; Anderson, K. Location, location, location: Considerations when using lightweight drones in challenging environments. Remote Sens. Ecol. Conserv. 2018, 4, 7–19. [Google Scholar] [CrossRef]
- Zhang, Y.; He, D.; Li, L.; Chen, B. A lightweight authentication and key agreement scheme for Internet of Drones. Comput. Commun. 2020, 154, 455–464. [Google Scholar] [CrossRef]
- McNeal, G.S. Drones and the future of aerial surveillance. Georg. Wash. Law Rev. 2016, 84, 354. [Google Scholar]
- Akram, M.W.; Bashir, A.K.; Shamshad, S.; Saleem, M.A.; AlZubi, A.A.; Chaudhry, S.A.; Alzahrani, B.A.; Zikria, Y.B. A secure and lightweight drones-access protocol for smart city surveillance. IEEE Trans. Intell. Transp. Syst. 2021, 23, 19634–19643. [Google Scholar] [CrossRef]
- Guvenc, I.; Koohifar, F.; Singh, S.; Sichitiu, M.L.; Matolak, D. Detection, tracking, and interdiction for amateur drones. IEEE Commun. Mag. 2018, 56, 75–81. [Google Scholar] [CrossRef]
- Bamburry, D. Drones: Designed for product delivery. Des. Manag. Rev. 2015, 26, 40–48. [Google Scholar] [CrossRef]
- Panda, S.S.; Rao, M.N.; Thenkabail, P.S.; Fitzerald, J.E. Remote Sensing Systems—Platforms and Sensors: Aerial, Satellite, UAV, Optical, Radar, and LiDAR. In Remotely Sensed Data Characterization, Classification, and Accuracies; CRC Press: Boca Raton, FL, USA, 2015; pp. 37–92. [Google Scholar]
- Jeong, N.; Hwang, H.; Matson, E.T. Evaluation of low-cost lidar sensor for application in indoor UAV navigation. In Proceedings of the IEEE Sensors Applications Symposium, Seoul, Republic of Korea, 12–14 March 2018; pp. 1–5. [Google Scholar]
- Bellon-Maurel, V.; McBratney, A. Near-infrared (NIR) and mid-infrared (MIR) spectroscopic techniques for assessing the amount of carbon stock in soils—Critical review and research perspectives. Soil Biol. Biochem. 2011, 43, 1398–1410. [Google Scholar] [CrossRef]
- Chen, P.; Dang, Y.; Liang, R.; Zhu, W.; He, X. Real-time object tracking on a drone with multi-inertial sensing data. IEEE Trans. Intell. Transp. Syst. 2017, 19, 131–139. [Google Scholar] [CrossRef]
- Wen, L.; Zhu, P.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Liu, C.; Cheng, H.; Liu, X.; Ma, W.; et al. Visdrone-SOT2018: The vision meets drone single-object tracking challenge results. In Proceedings of the European Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 469–495. [Google Scholar]
- Bartak, R.; Vykovskỳ, A. Any object tracking and following by a flying drone. In Proceedings of the Mexican International Conference on Artificial Intelligence, Cuernavaca, Mexico, 25–31 October 2015; pp. 35–41. [Google Scholar]
- Zhang, H.; Wang, G.; Lei, Z.; Hwang, J.N. Eye in the sky: Drone-based object tracking and 3D localization. In Proceedings of the ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 899–907. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 850–865. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. ECO: Efficient convolution operators for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Dai, K.; Wang, D.; Lu, H.; Sun, C.; Li, J. Visual tracking via adaptive spatially-regularized correlation filters. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4670–4679. [Google Scholar]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. GradNet: Gradient-guided network for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6162–6171. [Google Scholar]
- Mitrokhin, A.; Fermüller, C.; Parameshwara, C.; Aloimonos, Y. Event-based moving object detection and tracking. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar]
- Chen, H.; Suter, D.; Wu, Q.; Wang, H. End-to-end learning of object motion estimation from retinal events for event-based object tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10534–10541. [Google Scholar]
- Burdziakowski, P.; Bobkowska, K. Lighting Conditions—Accuracy Considerations. Sensors 2021, 21, 3531. [Google Scholar] [CrossRef]
- Wisniewski, M.; Rana, Z.A.; Petrunin, I. Drone Model Classification Using Convolutional Neural Network Trained on Synthetic Data. J. Imaging 2022, 8, 218. [Google Scholar] [CrossRef] [PubMed]
- Onzon, E.; Mannan, F.; Heide, F. Neural auto-exposure for high-dynamic range object detection. In Proceedings of the IEEE/CVF CVPR Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7710–7720. [Google Scholar]
- Mahlknecht, F.; Gehrig, D.; Nash, J.; Rockenbauer, F.M.; Morrell, B.; Delaune, J.; Scaramuzza, D. Exploring Event Camera-Based Odometry for Planetary Robots. IEEE Robot. Autom. Lett. 2022, 7, 8651–8658. [Google Scholar]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 643–652. [Google Scholar]
- Kang, S.B.; Uyttendaele, M.; Winder, S.; Szeliski, R. High dynamic range video. ACM Trans. Graph. 2003, 22, 319–325. [Google Scholar] [CrossRef]
- Mangiat, S.; Gibson, J. High dynamic range video with ghost removal. In Proceedings of the Applications of Digital Image Processing, San Diego, CA, USA, 1–5 August 2010; National Council of Teachers of Mathematics: Reston, VA, USA, 2010; Volume 7798, pp. 307–314. [Google Scholar]
- Mangiat, S.; Gibson, J. Spatially adaptive filtering for registration artifact removal in HDR video. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1317–1320. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep high dynamic range imaging of dynamic scenes. ACM Trans. Graph. 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Gryaditskaya, Y. High Dynamic Range Imaging: Problems of Video Exposure Bracketing, Luminance Calibration and Gloss Editing. Ph.D. Thesis, Saarland University, Saarbrücken, Germany, 2016. [Google Scholar]
- Hajisharif, S.; Kronander, J.; Unger, J. Adaptive dualISO HDR reconstruction. EURASIP J. Image Video Process. 2015, 2015, 41. [Google Scholar] [CrossRef]
- Heide, F.; Steinberger, M.; Tsai, Y.T.; Rouf, M.; Pająk, D.; Reddy, D.; Gallo, O.; Liu, J.; Heidrich, W.; Egiazarian, K.; et al. Flexisp: A flexible camera image processing framework. ACM Trans. Graph. 2014, 33, 1–13. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Nayar, S.K.; Mitsunaga, T. High dynamic range imaging: Spatially varying pixel exposures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; Volume 1, pp. 472–479. [Google Scholar]
- Zhao, H.; Shi, B.; Fernandez-Cull, C.; Yeung, S.K.; Raskar, R. Unbounded high dynamic range photography using a modulo camera. In Proceedings of the IEEE International Conference on Computational Photography, Houston, TX, USA, 24–26 April 2015; pp. 1–10. [Google Scholar]
- Gallego, G.; Delbrück, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.J.; Conradt, J.; Daniilidis, K.; et al. Event-based vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 154–180. [Google Scholar] [CrossRef]
- Muglikar, M.; Gehrig, M.; Gehrig, D.; Scaramuzza, D. How to calibrate your event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1403–1409. [Google Scholar]
- Lagorce, X.; Meyer, C.; Ieng, S.H.; Filliat, D.; Benosman, R. Asynchronous event-based multikernel algorithm for high-speed visual features tracking. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1710–1720. [Google Scholar] [CrossRef]
- Rebecq, H.; Ranftl, R.; Koltun, V.; Scaramuzza, D. High speed and high dynamic range video with an event camera. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1964–1980. [Google Scholar] [CrossRef]
- Brandli, C.; Muller, L.; Delbruck, T. Real-time, high-speed video decompression using a frame-and event-based DAVIS sensor. In Proceedings of the IEEE International Symposium on Circuits and Systems, Melbourne, Australia, 1–5 June 2014; pp. 686–689. [Google Scholar]
- Ni, Z.; Pacoret, C.; Benosman, R.; Ieng, S.; RÉGNIER*, S. Asynchronous event-based high speed vision for microparticle tracking. J. Microsc. 2012, 245, 236–244. [Google Scholar] [CrossRef]
- Tulyakov, S.; Gehrig, D.; Georgoulis, S.; Erbach, J.; Gehrig, M.; Li, Y.; Scaramuzza, D. Time lens: Event-based video frame interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16155–16164. [Google Scholar]
- Tulyakov, S.; Bochicchio, A.; Gehrig, D.; Georgoulis, S.; Li, Y.; Scaramuzza, D. Time lens++: Event-based frame interpolation with parametric non-linear flow and multi-scale fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17755–17764. [Google Scholar]
- Pan, L.; Liu, M.; Hartley, R. Single image optical flow estimation with an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1669–1678. [Google Scholar]
- Bardow, P.; Davison, A.J.; Leutenegger, S. Simultaneous optical flow and intensity estimation from an event camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 884–892. [Google Scholar]
- Wan, Z.; Dai, Y.; Mao, Y. Learning dense and continuous optical flow from an event camera. IEEE Trans. Image Process. 2022, 31, 7237–7251. [Google Scholar] [CrossRef] [PubMed]
- Akolkar, H.; Ieng, S.H.; Benosman, R. Real-time high speed motion prediction using fast aperture-robust event-driven visual flow. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 361–372. [Google Scholar] [CrossRef] [PubMed]
- Ramesh, B.; Zhang, S.; Lee, Z.W.; Gao, Z.; Orchard, G.; Xiang, C. Long-term object tracking with a moving event camera. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 241. [Google Scholar]
- Ronneberger, O.ß.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time MDNet. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 83–98. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, X.; Li, J.; Zhu, L.; Zhang, Z.; Chen, Z.; Li, X.; Wang, Y.; Tian, Y.; Wu, F. VisEvent: Reliable Object Tracking via Collaboration of Frame and Event Flows. arXiv 2023, arXiv:2108.05015. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Our Algorithm | VisEvent | Siamrpn++ | RT-MDNet | |
|---|---|---|---|---|
| PP | 0.783 | 0.712 | 0.390 | 0.405 |
| SP | 0.554 | 0.465 | 0.232 | 0.321 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Yu, X.; Luan, H.; Suo, J. Event-Assisted Object Tracking on High-Speed Drones in Harsh Illumination Environment. Drones 2024, 8, 22. https://doi.org/10.3390/drones8010022
Han Y, Yu X, Luan H, Suo J. Event-Assisted Object Tracking on High-Speed Drones in Harsh Illumination Environment. Drones. 2024; 8(1):22. https://doi.org/10.3390/drones8010022
Chicago/Turabian StyleHan, Yuqi, Xiaohang Yu, Heng Luan, and Jinli Suo. 2024. "Event-Assisted Object Tracking on High-Speed Drones in Harsh Illumination Environment" Drones 8, no. 1: 22. https://doi.org/10.3390/drones8010022