1. Introduction
Various types of small unmanned aerial vehicles threaten infrastructure, hardware and people seriously [
1,
2]. At the same time, the accurate detection of drone targets in low-resolution, visually blurred infrared images is a challenging task. There are two main problems:
- (1)
The influence of the target itself: due to the flight altitude being usually below 500 m, drone targets often have a few to several tens of pixels in an infrared image. In addition, drones usually have a low signal-to-noise ratio (SCR) and are easily submerged in strong noise and cluttered backgrounds [
3,
4,
5]. Therefore, the radiation intensity of the target is lower and it lacks significant morphological features, making target detection in infrared images difficult [
6,
7].
- (2)
The contradiction between the target and the detection algorithm: compared to RGB images, detecting drones in infrared images presents more problems, such as the lack of shape and texture features. After filtering and convolution calculations, it is easy to weaken or even lose the representative features of drones (such as wings) [
8,
9]. Besides, although building shallow networks can improve performance in deep learning algorithms, the contradiction between advanced semantic features and high resolution still cannot be resolved [
10].
Overall, there are too many negative samples in the image due to the large variation in target size and the extremely low percentage of pixels in infrared images, resulting in the loss of most of the available information during algorithm operation [
11]. In addition, most negative samples are easily classified, which makes it difficult for the algorithm to optimize in the expected direction [
12]. Therefore, the nets designed for normal objects are hardly used to detect drones in infrared images.
To detect drone targets in infrared images, researchers have proposed many traditional methods over the past few years. The traditional detection method involves implementing SIRST (Single-frame InfraRed Small Target) detection by calculating the non-coherence between the target and background. Typical methods include filter-based methods [
13,
14,
15], which can only suppress uniform and smooth background noise. They are also unable to adapt to complex backgrounds and may have a higher false alarm rate. The HVS method [
16,
17,
18,
19] uses the ratio of gray values between each pixel position and its neighboring region as an enhancement factor. It can effectively enhance the real target. However, it cannot effectively suppress the background noise. The low-rank representation [
20,
21,
22] can adapt to infrared images with low SCR ratios. However, in complex backgrounds, there is still a high false alarm rate for small and shape-varying targets. Most traditional methods heavily rely on manual features. These methods are simple calculations without training or learning. However, designing hand-crafted features and tuning hyperparameters require expert knowledge and a significant amount of engineering effort.
With the development of CNN methods, more data-driven methods are being applied to infrared small target detection [
23,
24,
25,
26]. Data-driven methods are suitable for more complex real scenarios and are less affected by target size, shape, and background changes. These methods require a large amount of data to demonstrate strong model fitting ability and have achieved better detection performance than traditional methods. Based on data-driven methods, the convolutional segmentation network can simultaneously produce pixel-level classification and location output [
27]. The first segmentation-based SIRST detection method ACM was proposed by [
28], which designed a semantic segmentation network using an asymmetric context module. On this basis, Dai [
29] further introduced expanded local contrast to improve their model. They use bottom-up local attention modulation modules to embed subtle low-level details at higher levels by combining traditional methods with deep learning methods. Zhang [
30] used an attention mechanism to guide the pyramid context network to detect targets. The feature map is divided into blocks to compute local correlations. Then global contextual attention is used to compute the correlation between semantics. Finally, the decoding maps of different scales are fused to improve detection performance.
As well as using segmentation networks to solve the problem of drone target detection, researchers also offer some other ideas. In [
31], a balance between missed detection (MD) and false alarms (FA) was achieved. The cGAN networks were used to separately build models for miss detection (MD) and false alarm (FA) as two subtasks as generators. Next, a discriminator for image classification is used to distinguish the outputs of the two generators and ground-truth images. Chen [
32] uses visible light images to achieve drone detection. By lightweight improvement of the backbone network and using the multi-scale fusion method to enhance the use of shallow features. A new non-maximum suppression method is designed to solve the problem of drone loss in multi-scale detection, ultimately achieving real-time detection. However, the above methods still have many shortcomings. First, the problem of small target feature loss in the deep layers of the network still exists, and the contradiction between high-level semantic features and high resolution cannot be resolved. Second, the coding maps generated by each downsampling layer cannot be well used. These problems will make the drone detection algorithm less robust to scene changes (such as cluttered backgrounds, and targets with different SCR, shapes and sizes).
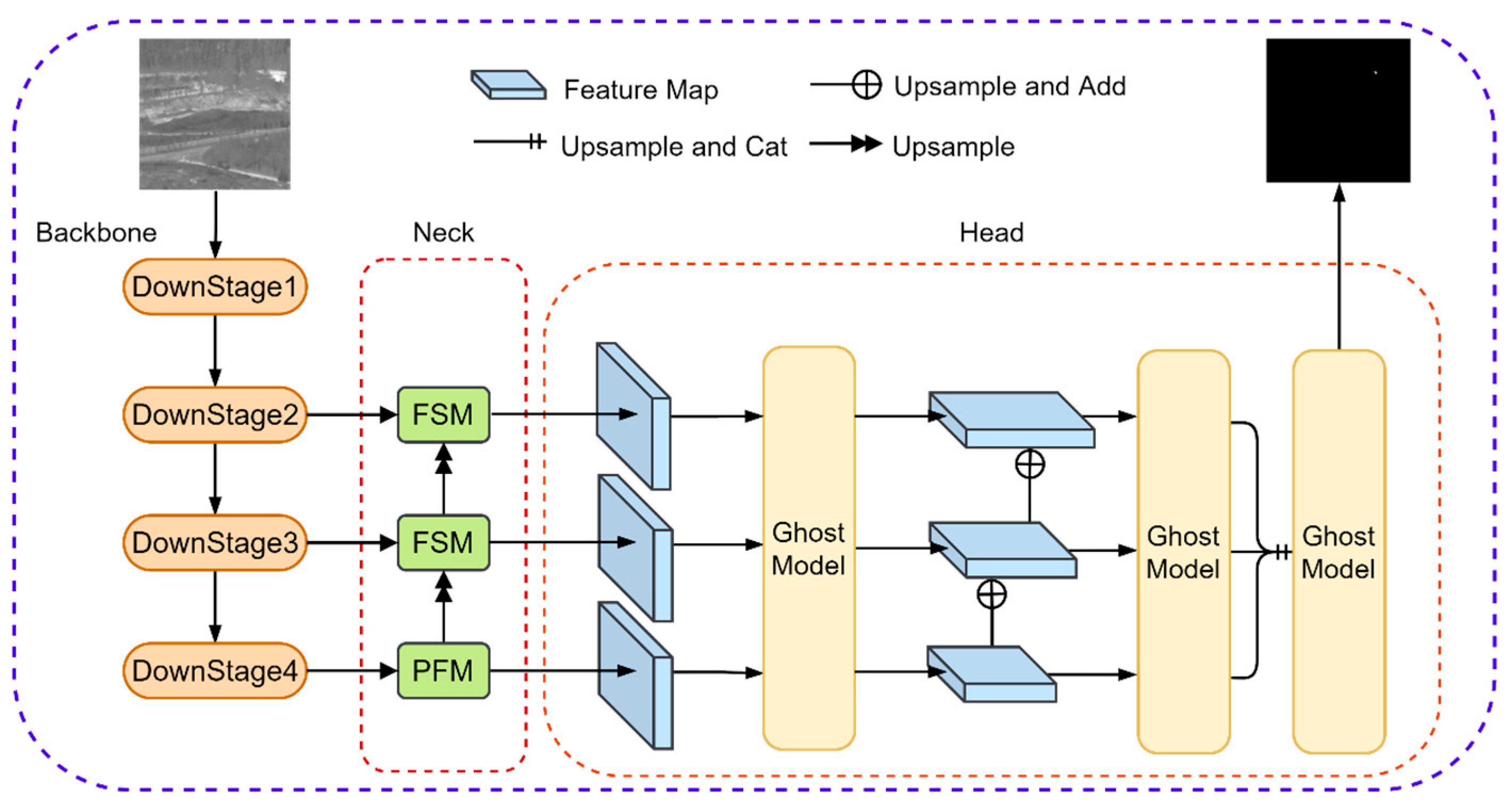
To solve these problems, we propose a data-driven progressive feature fusion detection method (PFFNet) from the perspective of infrared unmanned aerial vehicle target detection. First, global features were extracted from the input infrared image. Then, it passes the encoding maps output by downsampling to the FSM and PFM modules. The deep features that include high-level semantic information, the shallow features that contain rich image contour and the position information can be fully fused, thereby improving the utilization of the output encoding maps of the downsampling layer. In addition, the output feature maps are cross-scale fused to enhance the response amplitude of infrared unmanned aerial vehicle targets in the deep network and solve the problem of feature loss in small targets in the deep layers of the network. The high-level semantic information and shallow semantic information are superimposed and output through dimensional cascading. The confidence map is obtained through threshold segmentation to output the final detection result. Finally, to verify the effectiveness of PFFNet, we conducted extensive ablation studies on FSM and PFM and comparative experiments with existing methods on the SIRST Aug and IRSTD datasets. The experimental results show that the various modules of PFFNet have improved the detection of infrared unmanned aerial vehicle targets. Our algorithm has stronger robustness, better detection performance, and faster target detection time.
2. Methods
Given an input image I, we aim to classify each pixel by end-to-end convolving a neural network to determine whether it is a drone target. Finally, we output a segmentation result that is the same size as I. The PFFNet detection algorithm is divided into two parts: the global feature extractor and the progressive feature fusion network. The global feature extractor extracts the basic features of the input infrared image I by looking at the entire image. The redundant information in the image can effectively reduce by obtaining these basic features.
The progressive fusion network is divided into two modules: the Neck and the Head. The Neck includes the Pool Pyramid Fusion Model (PFM) and the Feature Selection Model (FSM). The former is used to enhance the feature response amplitude in the deep network of the infrared drone target. The latter acts as a bridge for information interaction between high and low layers, increasing the utilization rate of the downsampling output encoding map. The Head implements the progressive fusion of feature maps of different scales and generates a segmentation mask.
As shown in
Figure 1, the input image I is encoded into different dimensions and resolutions by the backbone to generate encoding maps
ba (
a = 2, 3, 4). The low-level spatial position information of the target’s salient features is obtained from
ba (a = 2, 3) by the FSM. Locating the high-frequency response area to reduce the influence of redundant signals on the target position information and output the feature maps
fa (
a = 2, 3). The
b4 is used as the input of the PFM to output the decoded image
p. The PFM is composed of four different pooling structures in parallel to form a pyramid network. The high-frequency response amplitude of deep target features is enhanced and then passes to the FSM after upsampling. The FSM and PFM extract local features of targets and use the progressive fusion method to calculate the phase output feature maps
ya (
a = 1, 2, 3). After being processed by the Ghost Model [
33],
ya is doubled in size and element-wise added. This process greatly simplifies the task of small target detection by sharing the same weight for all convolution blocks and reduces the parameters of the P algorithm by using element-wise addition while reducing the network inference time.
Then, the fused output is upsampled and dimensionally cascaded through convolution calculation. We proposed a multi-scale fusion strategy to progressively fuse feature maps of different sizes. Furthermore, the confidence map O is obtained by performing the final threshold segmentation on the fused feather map. The backbone is mainly used to expand the receptive field and extract deep semantic features. Upsampling helps to restore the size of the feature map. The progressive multi-scale feature fusion is achieved by upsampling and downsampling. The FSM and PFM modules are used to ensure the feature representation of small targets in the network.
To achieve good context data modeling ability, the simplest way is to repeat and stack the network depth. The more layers the network has, the richer the semantic information and the larger the receptive field [
34,
35,
36,
37]. However, infrared small targets have significant differences in size and a very low pixel ratio. If the network depth is blindly increased, the problem of feature disappearance may occur after the drone target undergoes multiple downsampling operations. Therefore, we should design special modules to extract high-level features while ensuring the representation of small targets with a very small pixel ratio in the deep network.
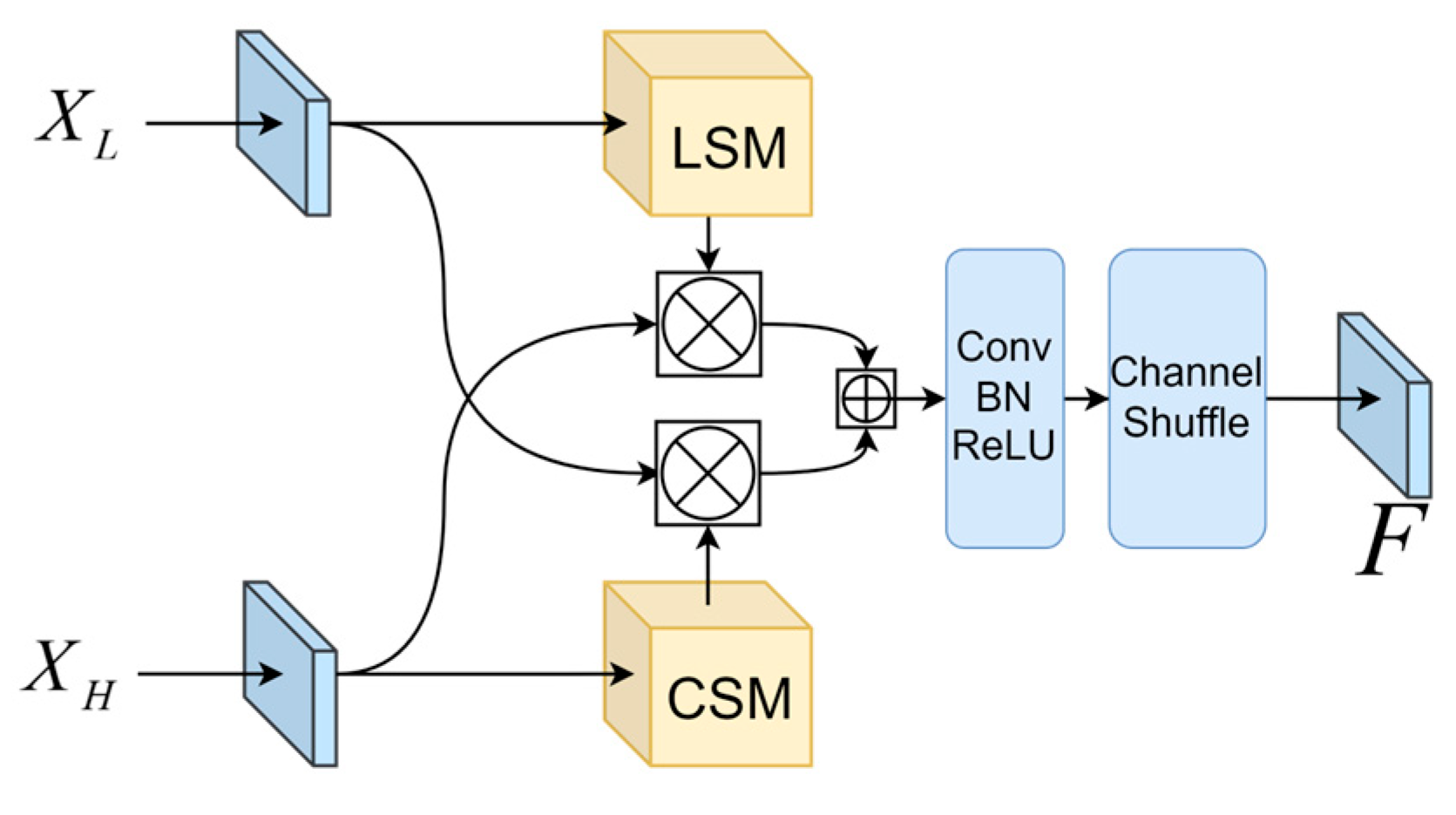
2.1. Feature Selection Module
We hope to improve the ability of channel information to interact between different downsampling layers based on a feature fusion perspective. Inspired by CBAM [
38] and ShuffleNet [
35], a new module called Feature Selection Module (FSM) is proposed to aggregate low-level and deep semantic information. The FSM is mainly divided into two parts: Location Selection Model (LSM) and Channel Selection Model (CSM). Experiments have shown that high-level semantic features contain detailed semantic information about the target, while low-level semantic features contain precise information about the target’s location. As shown in
Figure 2, FSM processes the different categories of information separately and uses the semantic information of each dimension to achieve information interaction between different coding graphs.
To preserve the feature of drone targets in deep networks and encode the spatial details of targets’ positions, this paper combines LSM and CSM. In order to cover more parts of the target to be recognized with features, this module first aggregates the channels via CSM. LSM was used to obtain more contour features and accurate location information. Then, the output of the current branch is multiplied by the input of another branch to enhance the high-low level channel features and facilitate multi-channel information interaction. Through 5 × 5 convolution we obtain a larger receptive field. Finally, the information exchange between different channels is established based on the Channel Shuffle idea. The output of the feature selection module
is represented as:
where
XH is the deep feature that includes high-level semantic information,
XL is the shallow feature that contains rich image contour information and position information, ⊗ and ⊕ represents element-wise multiplication and addition of vectors,
C and
L represent the CSM and LSM modules, respectively.
Ε is the convolution calculation.
Σ represents the activation function of the Rectified Linear Unit.
Μ is used to enhance feather representation and is a positive integer.
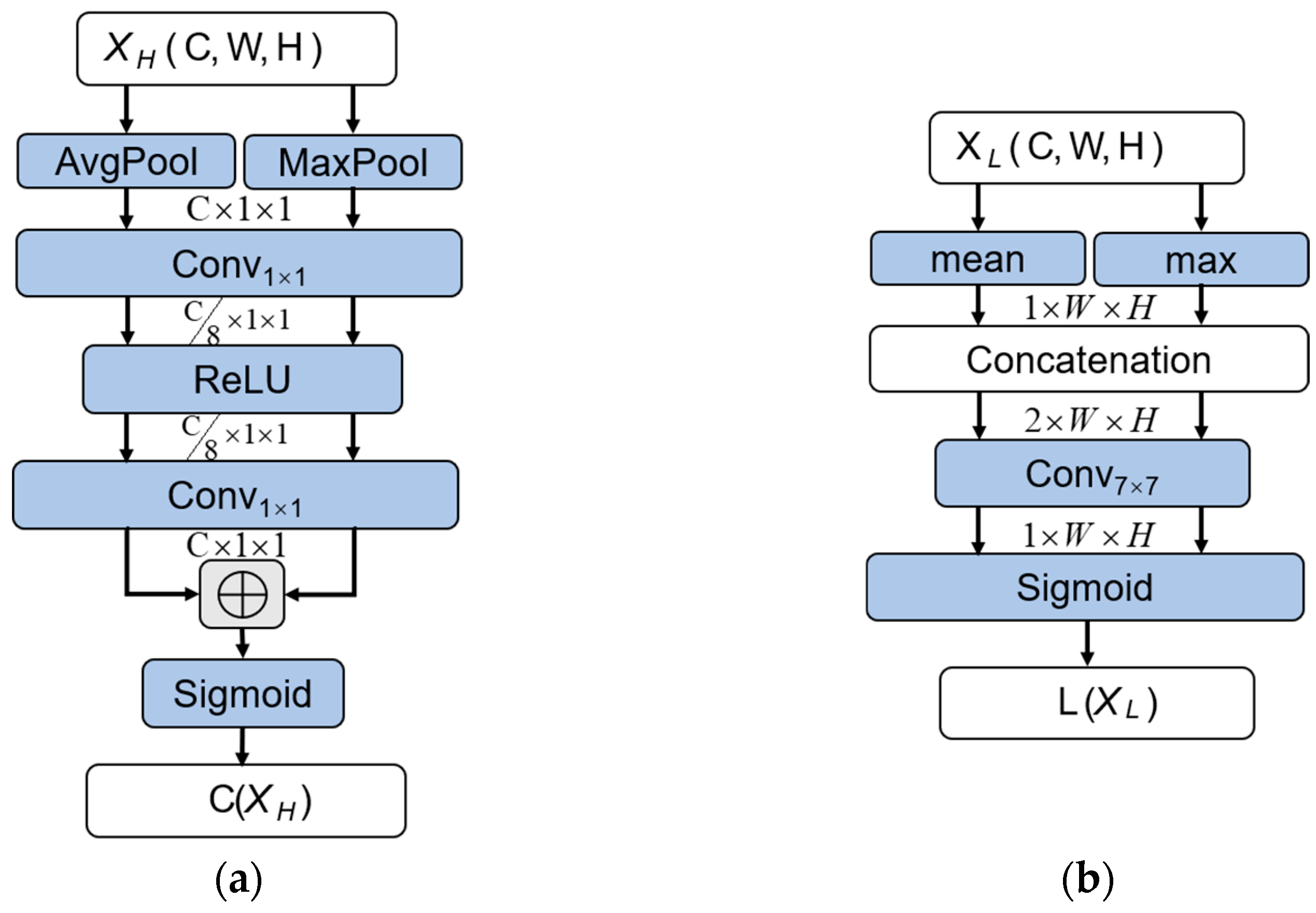
2.2. Channel Selection Model
To solve the problem of losing or weakening the target area response value during upsampling of drone targets, the CSM is used to enhance the target area response amplitude.
As shown in
Figure 3a, the channel features at each spatial position are individually aggregated. The high-frequency response channel weights of small targets are directionally enhanced to highlight the subtle details of deep targets. In Equation (3), this module performs average pooling and max pooling operations on the input feature map
XH to generate different 3D tensors
xhi. Coupling the global information of the feature map X in its internal channel. Then, a 1 × 1 convolution is used to evaluate the importance of each channel and calculate the corresponding weight. The aggregated output
can be represented as:
where
xh1 and
xh2 are the feature vector calculated by average pooling and maximum pooling.
W and
h represent the width and height of the feature map, respectively. The output of CSM as
is
where δ represent the Sigmoid function. The output through
are (
c,
c/
rf, 1, 1) and (
c/
rf,
c, 1, 1), respectively.
Rf is the channel descent ratio.
2.3. Location Selection Model
The SCR of drone targets in infrared images is extremely low, which easily take interference signals into the process of feature extraction. The LSM could quickly locate visual salient regions. As shown in
Figure 3b, this module calculates the maximum and mean values of the input feature map
XL, respectively.
where
xl1 and
xl2 represent the mean and maximum calculation of channel dimension. Perform cascading operations in the channel direction before performing convolution operations. Here, a 7 × 7 convolution can further expand the receptive field of the convolution kernel. It can also capture areas with higher local response amplitudes from the lower-level network. In addition, the accurate position of the drone target in the feature map is ensured. The output
can be calculated using the following equation:
where
C represents the dimension cascade operation. The final output size of the feature map of this module is (1,
W,
H).
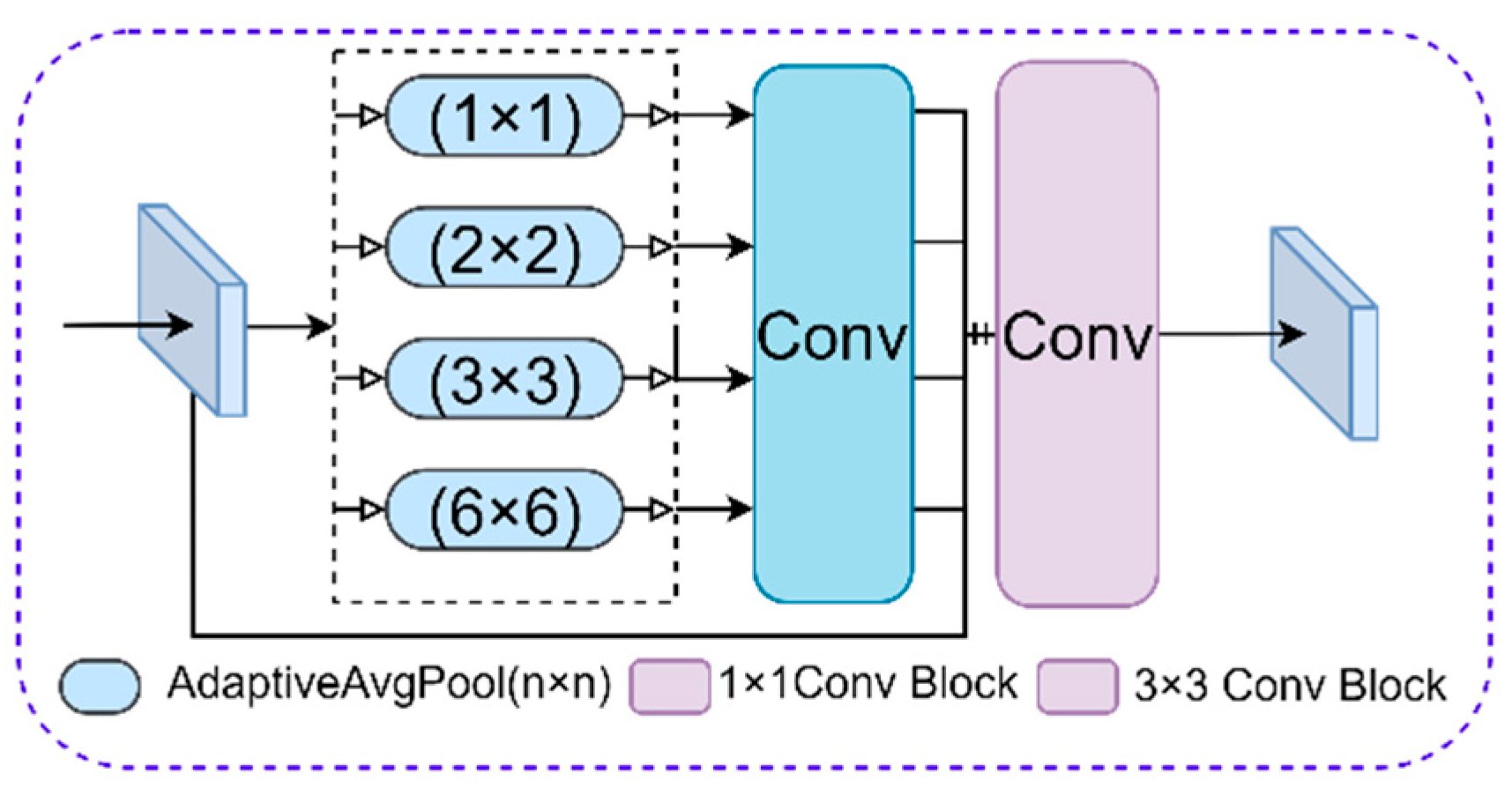
2.4. Pooling Pyramid Fusion Module
Deeper neural networks can obtain more detailed semantic information about the target, but this method is not suitable for smaller targets. As the number of downsamplings increases, the feature of drone targets (such as propellers and arms) weakens or even disappears. To solve this problem, this paper proposes a Pooling Pyramid Fusion Module (PFM) for drone target detection. Affected by [
39], the PFM is only used to process the encoding map of the highest downsampling layer. Therefore, it can provide a more effective global context prior to pixel-level scene parsing. The PFM compresses spatial dimensions through different global adaptive pooling layer structures. Besides, the corresponding dimension mean value can be extracted to enhance the feature representation of small targets in deep networks.
As shown in
Figure 4, the input feature map
is parallelly input into the pyramid pooling module for decoding, generating four encoding structures of different sizes 1 × 1, 2 × 2, 3 × 3, and 6 × 6. Then, 1 × 1 convolution is used to reduce the feature dimension to 1/4C.
rp is the channel descent ratio. The four feature maps of different sizes are upsampled by bilinear interpolation. Then concatenating with the input feature map in the channel dimension. Finally, a 3 × 3 convolution is performed to output the feature map
, and form a contextual pyramid through five feature maps of the same dimension but different scales.
2.5. Segmentation Head
After multiple downsampling and convolution calculations, the targets’ feature response in the deepest layer of the convolutional network will weaken. In response to this problem, we proposed a progressive feature fusion structure that is better suited for drones. This segmentation head is designed and improved based on FPN [
40]. It can fuse different sizes of feature maps and enable the stacking of information between high and low layers to enhance the high-frequency response amplitude of the target.
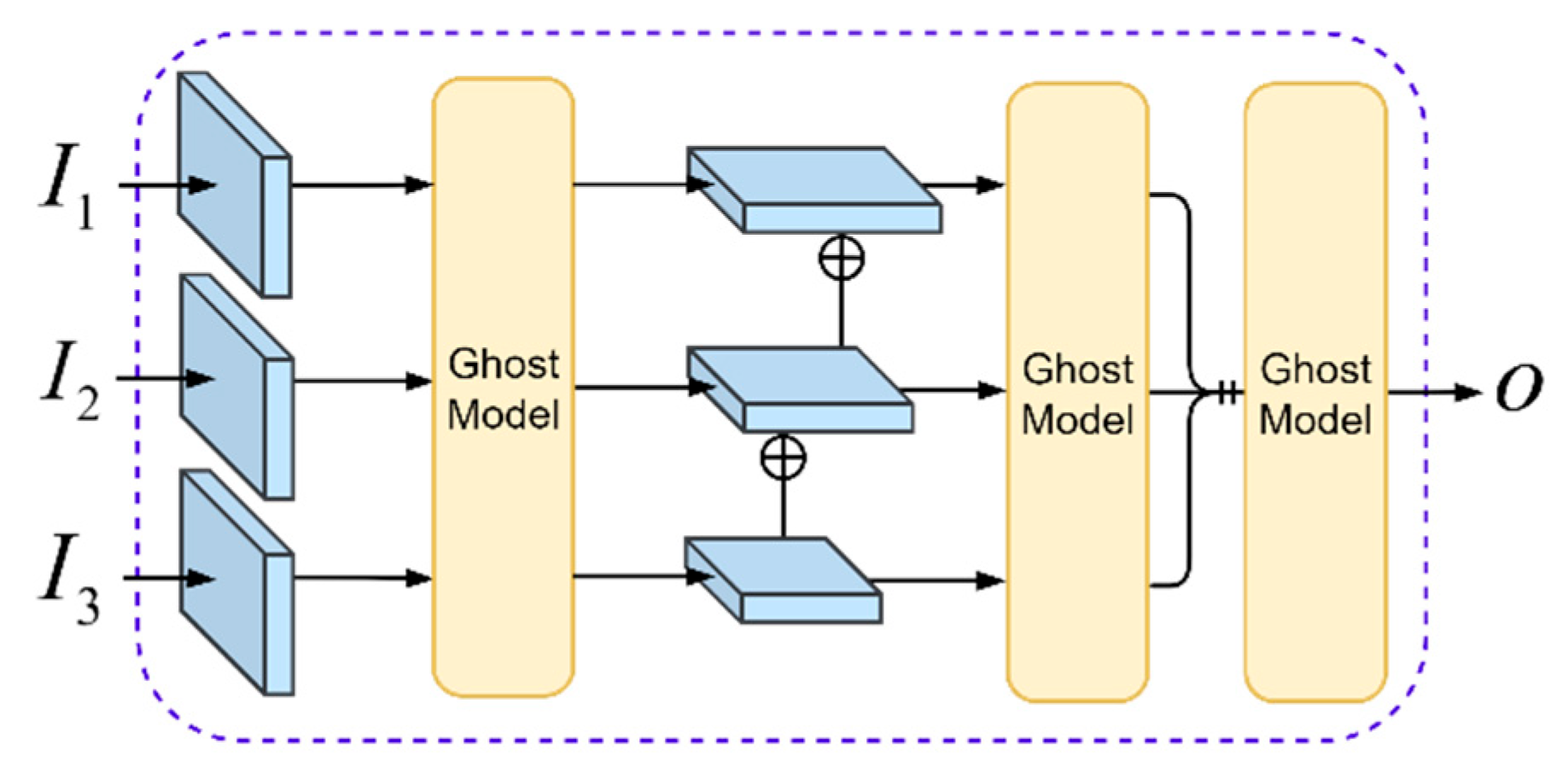
As shown in
Figure 5, the input
I with different sizes proceeds through the Ghost Model. Due to the small proportion of drone targets in the image, ordinary convolution calculations can generate a large number of feature maps with the same texture information or even without drone target information. However, the Ghost Model could generate encoding maps with the same number and texture information through simple linear calculations. This step reduces the convolution parameter volume and improves training and inference efficiency.
Finally, we train the entire network by
SoftIoULoss and
CELoss in PFFNet and optimize the weighted loss between the predicted and segmented images. They can be expressed by the following equations:
where
T and
P represent the pixel values of the real target and the output prediction, respectively. Based on the initial loss value during training,
α = 3 and
β = 1 were set to balance the individual loss with the total loss to optimize the algorithm in the expected direction. To ensure stability in the calculation, this paper sets
smooth = 1. Different weight balances may affect performance indicators [
10].
3. Experiments
This section mainly introduces the implementation details and evaluation metrics of the algorithm and compares it with other methods on two different datasets. In order to verify the effectiveness of the data-driven model PFFNet, comparative experiments and ablation experiments were conducted, respectively.
3.1. Datasets
Performance-based on data-driven methods is highly affected by the quality, quantity, and diversity of the data. Infrared image datasets have fewer images compared to visible datasets. Most methods are trained and evaluated on their own private datasets. Wang [
31] established an open infrared small target dataset that includes 10,000 images. However, many of the targets in the dataset are too large and the annotations are not accurate which affects the training effectiveness. Dai [
28] released a dataset with high-quality semantic segmentation masks. However, the dataset is small, which easily leads to unstable model training, overfitting, and model convergence problems. To verify the reliability and robustness of the algorithm, experiments were conducted on two publicly available datasets with different image sizes (SIRST Aug [
30] and IRSTD 1k [
41]). The dataset [
30] includes 8525 images in the training set and 545 images in the test set with an image size of 256 × 256, which is sufficient to satisfy the training requirements of data-driven models. The image size in the dataset [
41] is 512 × 512 and includes different types of small targets such as drones, organisms, ships, and vehicles. This dataset also covers many different scenes, including seawater, fields, mountains, cities, and clouds, with a cluttered background and severe noise. Therefore, it is sufficient to verify the proposed detection method.
3.2. Experimental Preparation and Evaluation Method
PFFNet will conduct ablation experiments and multi-algorithm comparison experiments on the SIRST Aug and IRSTD 1k open datasets.
This paper uses classic semantic segmentation evaluation indicators such as F1-score, receiver operating characteristic curve (ROC), and Intersection over Union (IoU). To measure the connection between precision and recall,
F1-score is introduced. Meaning that the network must be able to detect targets and ensure as few false alarms as possible. ROC is a qualitative indicator that reflects the connection between the target detection rate (
Pd) and the false alarm rate (
Pf).
Precision,
recall, target
Pd, and
Pf are defined as follows:
where
TP represents the target pixels that are correctly matched with the true label by the predicted pixels.
FP represents the background label pixels that are incorrectly predicted as targets.
FN represents the number of target pixels that are incorrectly classified as background.
N represents the total number of pixels in the image.
F1-score and IoU can be defined as:
PFFNet is implemented based on Pytorch. The optimizer uses stochastic gradient descent (SGD), with momentum and weight decay coefficients set to 0.9 and 0.0001, respectively. The initial learning rate is 0.05, and a poly decay strategy is used. In SIRST Aug, the batch size is set to 32, and 30 epochs are trained. In IRSTD 1k, the batch size is set to 8, and 150 epochs are trained. In terms of hardware, we use a Tesla P100 GPU for training and a 3060 GPU for inference.
3.3. Comparative Experiments
We compared PFFNet with four classic methods of different types. Results in [
28,
30] show that data-driven methods are superior to model-driven methods. Therefore, only data-driven methods are compared in our experiments. In the data-driven scheme, we select AGPCNet, ACM, MDFA, ALC and PFFNet for comparison. PFFNet-S and PFFNet-R represent the selection of Swin Transformer V1 [
42] and ResNet-18 [
43] as the global feature extractors, respectively. The purpose is to verify whether the algorithm is compatible with different feature extraction structures. The hyperparameters of other algorithms are not changed and remain at their default settings.
As shown in
Table 1, the maximum and secondary values of each column are highlighted in bold and underlined, respectively. PFFNet achieved the best detection performance on both different datasets, with an IoU of up to 73.7% on the SIRST AUG dataset. PFFNet-R and AGPCNet were selected for comparison because they both chose ResNet-18 as their global feature extractor. Obviously, compared to AGPCNet, PFFNet-R increased IoU by 8.9% (73.7 vs. 67.6) and 5.5% (66.1 vs. 62.6) on both datasets, respectively. This method reduces detection time by 55.8% (0.01 vs. 0.05) while maintaining detection accuracy. Compared to ALC, PFFNet-S increased IoU by 2.5% (73.7 vs. 71.9) and 3.2% (64.2 vs. 62.2), respectively, and reduced the detection time by 81% (0.01 vs. 0.06). Furthermore, we calculated the average time of different methods on 1000 infrared images, among which PFFNet-S is 6 ms slower than ACM, but PFFNet-S has a better detection performance.
Besides, it can also be seen that each algorithm performs significantly better on the SIRST Aug dataset compared to IRSTD 1k. Just like the IoU values of PFFNet-S on different datasets (73.7% on SIRST Aug dataset and 64.2% on IRSTD 1k dataset). There are two reasons for this result:
- (1)
Number of data used for model training
The results of detection based on data-driven methods are affected by the number of data. The SIRST Aug dataset is used to train models with more data than IRSTD 1k (8525:800). Due to the higher resolution of the images contained in IRSTD 1k (512 × 512), good detection results were also achieved even with a small amount of data. The higher the image resolution, the better the detection result, which has been proven [
44].
- (2)
The complexity of the data
The IRSTD 1k dataset contains more challenging scenarios for detection. For example, drone targets with different shapes, low contrast, low signal-to-noise ratio, as well as more complex backgrounds and more noise interference. The complexity of its data is much higher than SIRST Aug.
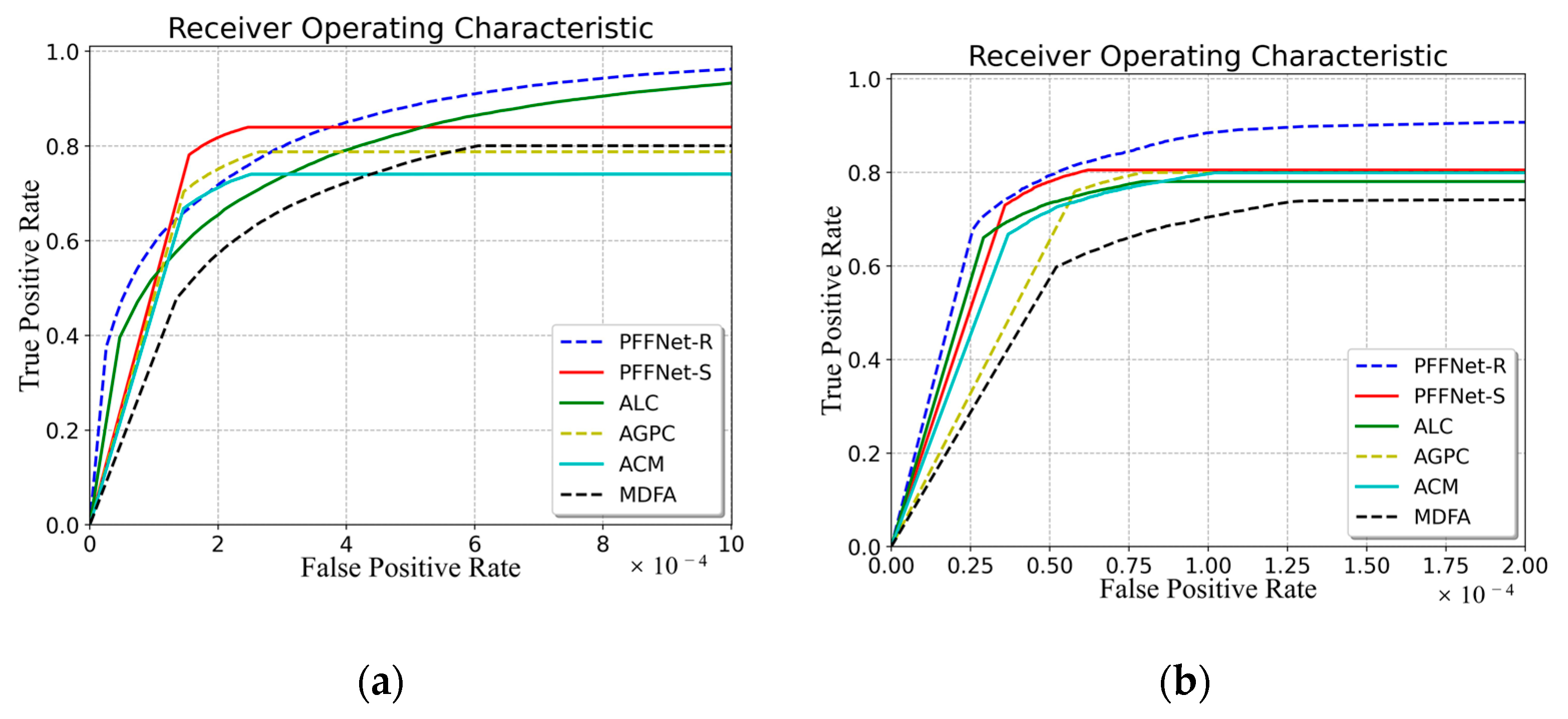
Furthermore, to visually compare the AUC, the ROC curves of these methods on two different datasets are shown in
Figure 6. Experimental results demonstrate that PFFNet can greatly suppress the background. This method fully learns highly discriminative semantic features from diverse training data to achieve highly robust object detection results. In addition, it can segment targets more accurately than other state-of-the-art methods.
This paper also selects four types of data for visual evaluation of the above algorithms. As shown in
Figure 7, Introducing infrared images and GT (Ground Truth) for four different scenarios. The ‘ori’ represents the original images and the ‘after’ represents the enhanced ones. The local contrast between the target and background is extremely low in
Figure 7a,d.
Figure 7b,c have a high local contrast with a complex background. Meanwhile,
Figure 7a,c have multiple drone targets.
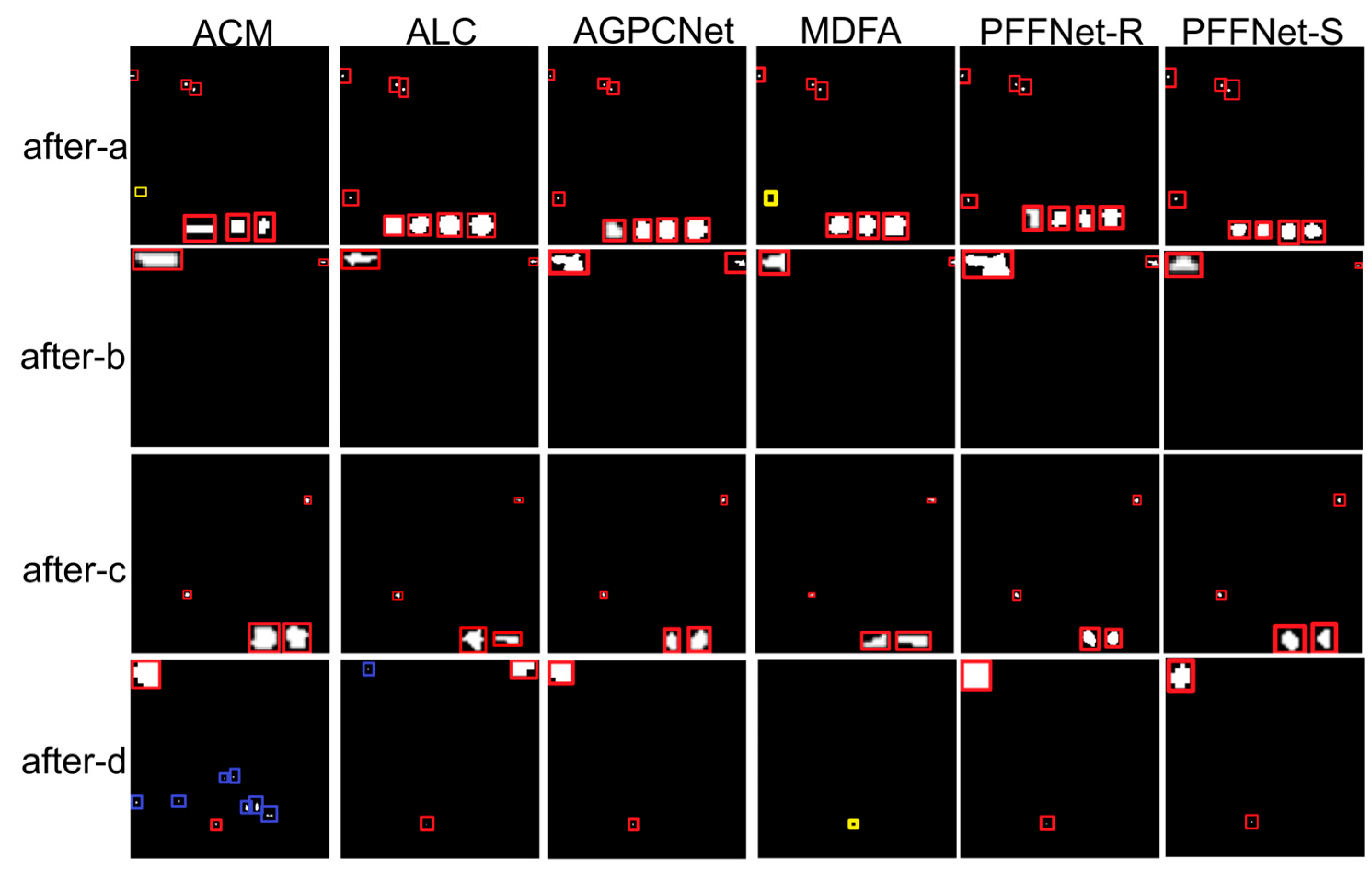
Figure 8 shows the output of the GT map with five different methods. Although the enhanced after-a has stronger local contrast, ACM and MDFA still cannot detect all targets. When there are few targets (after-b) or the background is relatively simple (after-c), all algorithms have good performance. For after-d, although the image features have been enhanced, false alarms (ACM, ALC) or missed detections (MDFA) still occur. In addition, both AGPCNet and PFFNet can detect all targets, although PFFNet has a shorter detection time. Obviously, PFFNet is more suitable for drone target detection.
3.4. Ablation Experiments
To investigate the effectiveness of each module in PFFNet, we conducted multiple ablation studies using SIRST Aug and IRSTD 1k. Although ResNet-18 has better performance, it has a longer training and inference time. Therefore, we choose Swin Transformer v1, which performed well and had a shorter detection time as the backbone for ablation.
In
Table 2, ablation experiments were conducted on Segmentation Head, FSM, and PFM, respectively. First, for Swin Transformer v1, after adding the Segmentation Head module, the IoU increased by 49.1% (71.3 vs. 47.8) and 49.3% (60.3 vs. 40.4). It can prove the effectiveness of using different downsampling output encoding and multi-scale fusion when segmenting targets. To verify the effectiveness of other modules, we use the Backbone and Segmentation Head modules as baselines to fine-tune the model. After adding the FSM module, the IoU increased by 3% (73.4 vs. 71.3) and 5% (63.4 vs. 60.3). Therefore, the detection accuracy could be improved by enhancing the information exchange between high-level and low-level features. After adding the PFM module, the IoU increased by 0.52% (71.6 vs. 71.3) and 1.8% (61.3 vs. 60.3). Although the texture information of the top-level target is more abundant, there is a lack of effective global contextual priors. Using PFM modules to enhance global feature representation can achieve better performance.
For FSM, as shown in
Table 3. CSM is used to directly enhance the response weight of targets of the upsampling layer. Although good results can be achieved (71.3 vs. 72.5, 62 vs. 60.3), effective use of lower layer feature maps can achieve better results (72.8 vs. 71.3, 62.6 vs. 60.3). This is because the lower sampling output contains more information of target location and drone contour. Therefore, using different strategies for different sampling output results is beneficial for drone target detection.
Dimensionality reduction can reduce redundant information and greatly accelerate the training speed in the network. However, this may result in the loss of useful information. In PFFNet, two dimensionality reductions were performed in FSM and PFM separately, and the reduction ratios were denoted as (
rf,
rp). We choose different dimensionality reduction ratios to explore the best way to segment small infrared targets. According to [
38], we set
rf = 8. As shown in
Table 4, the best result was IoU (73.7%,64.2%) when
rf = 8 and
rp = 4.
With the network deepening and the number of channels increasing, more complex features are learned. In order to enhance the network’s expressive ability, it is necessary to cover as many key features as possible. However, it does not apply to all kinds of target detection, such as small drone targets, which have small size and low signal-to-noise ratio. After multiple downsampling, there may be repeated features or even feature loss. Setting a smaller ratio of dimensionality reduction becomes meaningless, such as rp = 1 or 2. Alternatively, choosing a larger ratio of dimensionality reduction may result in the model being unable to learn more complex features, such as rp = 8, which is clearly not what we expected. Therefore, an appropriate proportion with different kinds of targets should be chosen to enhance the expressive ability of the model.
4. Discussion
From the above experiments, MDFA divides the generator into miss detection and false alarm and uses GAN to detect infrared targets. However, the results of the downsampling cannot be used effectively. Additionally, MDFA can easily lead to false alarms and miss-detection when the local contrast is low. ACM was the first to use segmentation methods to detect infrared targets, providing a theoretical basis and experimental data for researchers. However, it has many limitations, such as the global information could not be used effectively. ALC combines data-driven and model-driven methods to achieve high precision. However, it ignored the effect of the target’s surrounding environment because of only enlarged the scale and enhanced the local contrast. AGPCNet used attention modules and self-attention-guided algorithms to learn more contextual information. However, it can easily lead to miss detection when the target is in a complex environment. Overall, the above methods do not balance the detection accuracy and time cost.
Table 5 shows the comparison of all methods.
In our method, ablation was used to verify the role of each module. For drone targets, the segmentation head was designed to achieve progressive multi-scale fusion. In addition, the problem of feature disappearance was solved. Then, considering the influence of global context prior on the top layer output of the network, the PFM was used to enhance drone feature representation in networks. Finally, FSM was designed to promote information exchange between layers to improve detection accuracy.
5. Conclusions
This paper proposes a fast detection method for infrared small targets: Progressive Feature Fusion Network (PFFNet). The FSM was used to promote the use of shallow features and enhance upsampling output amplitude of the target. Then, the high-low level encoding outputs are fused to improve the accuracy of the model. The PFM was used to process the output coding diagram of the highest downsampling layer in the backbone and provide more effective global contextual priors for pixel-level scene parsing, guiding algorithms to learn more target features. Then, from the perspective of multi-scale fusion, we design a lightweight segmentation head to adapt to drone targets based on FPN. Enhance the ability to detect small targets by progressively fusing low-level and high-level semantics. Comparative and Ablation experiments demonstrate that PFFNet has the ability to accurately detect drones in complex scenes. Additionally, it can balance the detection accuracy and detection time. This study could promote drone target detection and even expand drone remote sensing segmentation.
However, there are still some problems with the algorithm that need further research, such as dealing with network overfitting, utilizing more efficient contextual information, etc. In future work, RGB images and fusion images will continue to be explored for their application in infrared drone detection.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}