1. Introduction
Transmission lines are a critical part of the power system with broad coverage, long transmission distances, and high reliability requirements. However, these lines are often exposed to a complex external environment, where the presence of vegetation and buildings of varying heights on the ground poses a potential threat. The proximity of these objects to high-voltage transmission lines can lead to accidents such as line tripping. Furthermore, during the inspection process, the wings of the drone may collide or tangle with the power lines, which poses a significant risk to the safety of the drone’s flight and the stable operation of power facilities. Therefore, it is crucial to effectively monitor and segment transmission lines to ensure the safety of the power grid and low-altitude drones.
The detection methods for transmission lines can be divided into traditional image-processing methods and deep learning-based methods. Among the two methods for detecting transmission lines, traditional image-processing methods have been used for transmission line extraction based on edge detection algorithms. For example, Zhou et al. [
1] proposed a color space variable-based classification and feature extraction method for transmission line images. It classifies images based on the relationship between the values of variables in each color space of the transmission line image and its corresponding image features, specifically focusing on different light intensities. Then, the edge extraction of power line images is performed by the OTSU (NobuyukiOtsumethod) algorithm [
2]. This method mainly considers the power line segmentation under different lighting conditions; although the power lines are effectively extracted, the application scenario is mainly the power lines under low- to high-altitude photography. That is, the background is mainly the sky. When the perspective shifts from high altitude to low altitude shooting, the background is mostly houses, mountains, and rivers. As such, this type of algorithm cannot effectively solve the power line segmentation in complex backgrounds. Zhou et al. [
3] took an improved Ratio operator [
4] with horizontal orientation to extract power lines and then group and fit the power line segments. Since the experimental object of this literature is mainly for power line segmentation in horizontal distribution scenarios, it has a certain specificity. At the same time, the Ratio operator is susceptible to complex backgrounds with large variations in pixel gray values, especially for areas with relatively flat gray values, which are not as effective as the normal operator. Zhou et al. [
5] perform transmission line segmentation in complex backgrounds by proposing a detection operator based on local contextual information. Compared with the literature 4 comprehensive optimization of power lines under a variety of angle changes, mainly considering the horizontal, vertical, and diagonal distribution of transmission lines, with a certain degree of algorithmic stability. Some studies are also based on Hough transform [
6] for transmission line detection [
7,
8]. Shan et al. [
9] design auxiliary devices for the segmentation of transmission lines and the method does not have a universal. In summary, since this type of algorithm does not introduce any prior knowledge and the algorithm model does not need to prepare a large number of samples for training in advance, it has the advantage of a low sample size requirement due to its less restrictive way of data collection. In addition, the power lines extracted using the Hough transform tend to lose the width information [
10]. Both edge detection-based power line extraction algorithms and power line extraction algorithms with a priori knowledge share a common challenge: it is difficult to adaptively adjust the model parameters to maintain the good performance of the algorithm in the scenario-changing test data. All these methods use artificially defined shallow features in constructing power line extraction models.
In this problem, deep learning models with their strong feature extraction capability are effectively used in the field of power systems. A variety of deep learning-based image classification, target recognition, image segmentation, and other power vision algorithms are rapidly developing [
11,
12,
13,
14,
15,
16]. Two power-line recognition algorithms based on VGG-19 [
17] and ResNet-50 [
18] in aerial images are proposed by Yetgin Ö E et al. [
19]. However, this method can only determine whether the image contains power lines and does not achieve the segmentation and detection of power lines. The optimal model for detailed detection of power lines is the segmentation model and the classification model can only determine the presence or absence of power lines in the transmission line in the image. The target detection model can only be presented in the form of a rectangular box and when the transmission line spans the whole picture, the detection effect will occupy the whole picture with a rectangular box, which is not conducive to the accurate positioning of the transmission line and is likely to generate too much redundant information. In the segmentation of power lines for transmission lines. Yang et al. [
20] designed to use VGG-16 as the feature extraction backbone of UNet and combine the attention mechanism based on global average pooling and global maximum pooling for UNet skipping connection layer information supplementation. Finally, the four decoding layers of UNet are fused as a whole to output the final segmentation features. Since the process involves the fusion of four different scale features, it can effectively reduce the loss of multi-scale feature information, but at the same time, it also brings an increase in computational effort. Han et al. [
21] proposed a UNet segmentation model based on GhostNet as the backbone by optimizing and improving the model. For light-weighting, the model and the attention mechanism Shuffle Attention further optimize the detection accuracy of the model, achieving effective segmentation of power lines. However, the actual test speed in the article is still low, mainly because the decoder part of the segmentation network still has a large amount of computation. In segmentation studies targeting complex backgrounds, Xu et al. [
22] also use VGG-16 as the feature extraction backbone to construct an improved UNet-based powerline segmentation network. In this study, a multi-level feature aggregation module is adapted to detect power lines at different pixel widths and orientations. That is, the two features after neighboring convolution are fused again for output, and the output features are then combined with the attention mechanism for semantic information enrichment and background noise suppression. The SPP (Spatial Pyramid Pooling) module is also combined with the perceptual field enhancement, Finally, the four features of the multiscale output are then fused for the overall output. Gao et al. [
23] take proposed an efficient parallel branching network for real-time segmentation of overhead power lines. However, the data in these two literature studies are mainly processed by cropping the images at large resolutions and turning them into small-resolution images. From a complex background at a large resolution to a single background at a small resolution, the whole picture consists only of power lines and some of the power lines’ attached power equipment. Choi et al. [
24] propose a fusion of visible and infrared images of power lines for UNet model-based segmentation detection. The fusion method based on the channel attention mechanism is adopted to achieve the fusion of infrared images and visible images. This achieves effective segmentation of transmission lines in complex contexts by aiding the segmentation of power lines with the help of data from homomodal heterogeneous sources. However, by the above directions of model optimization for complex backgrounds, more pre-processing must take place, and the models cannot be directly used for actual detection scenarios.
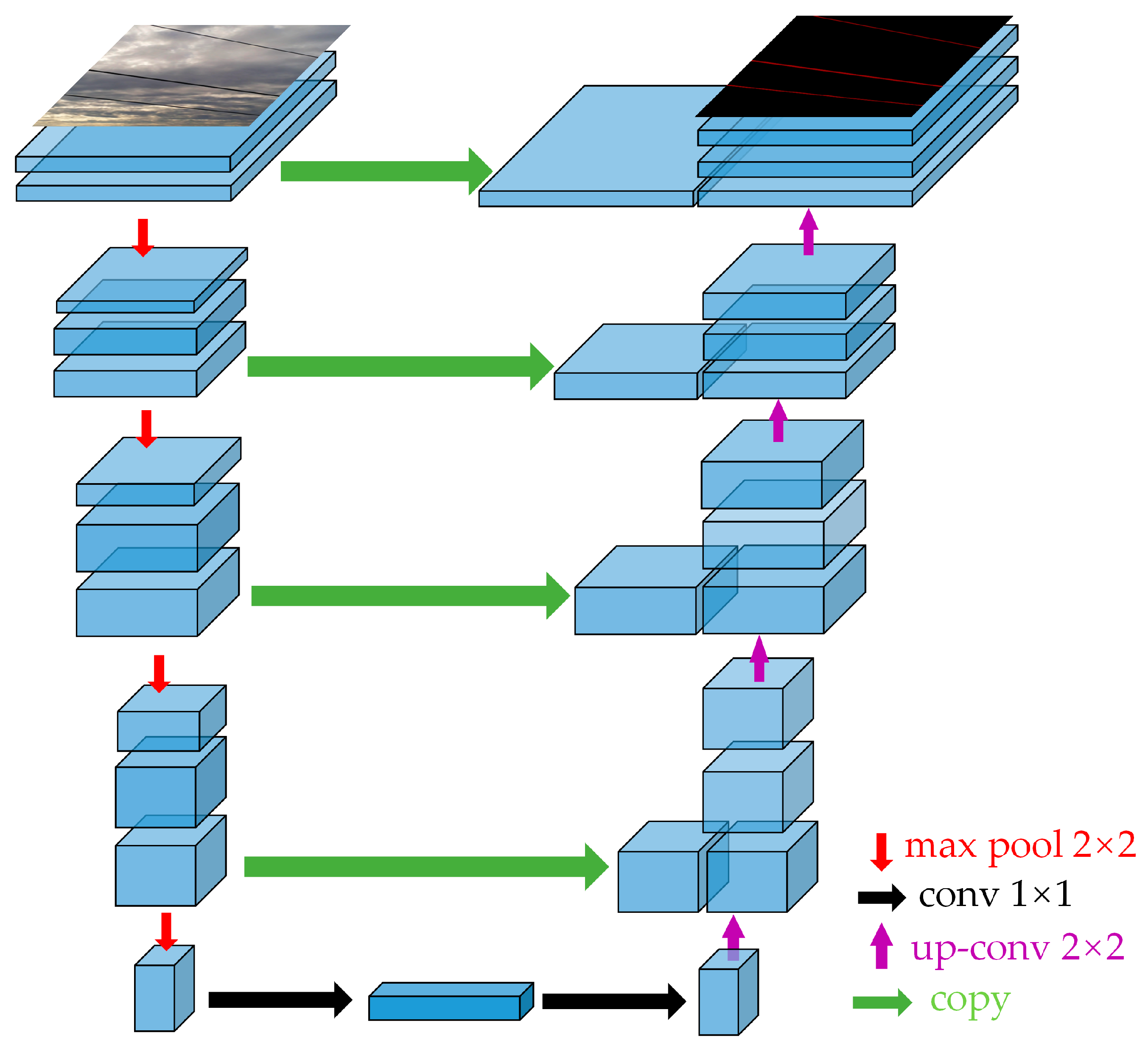
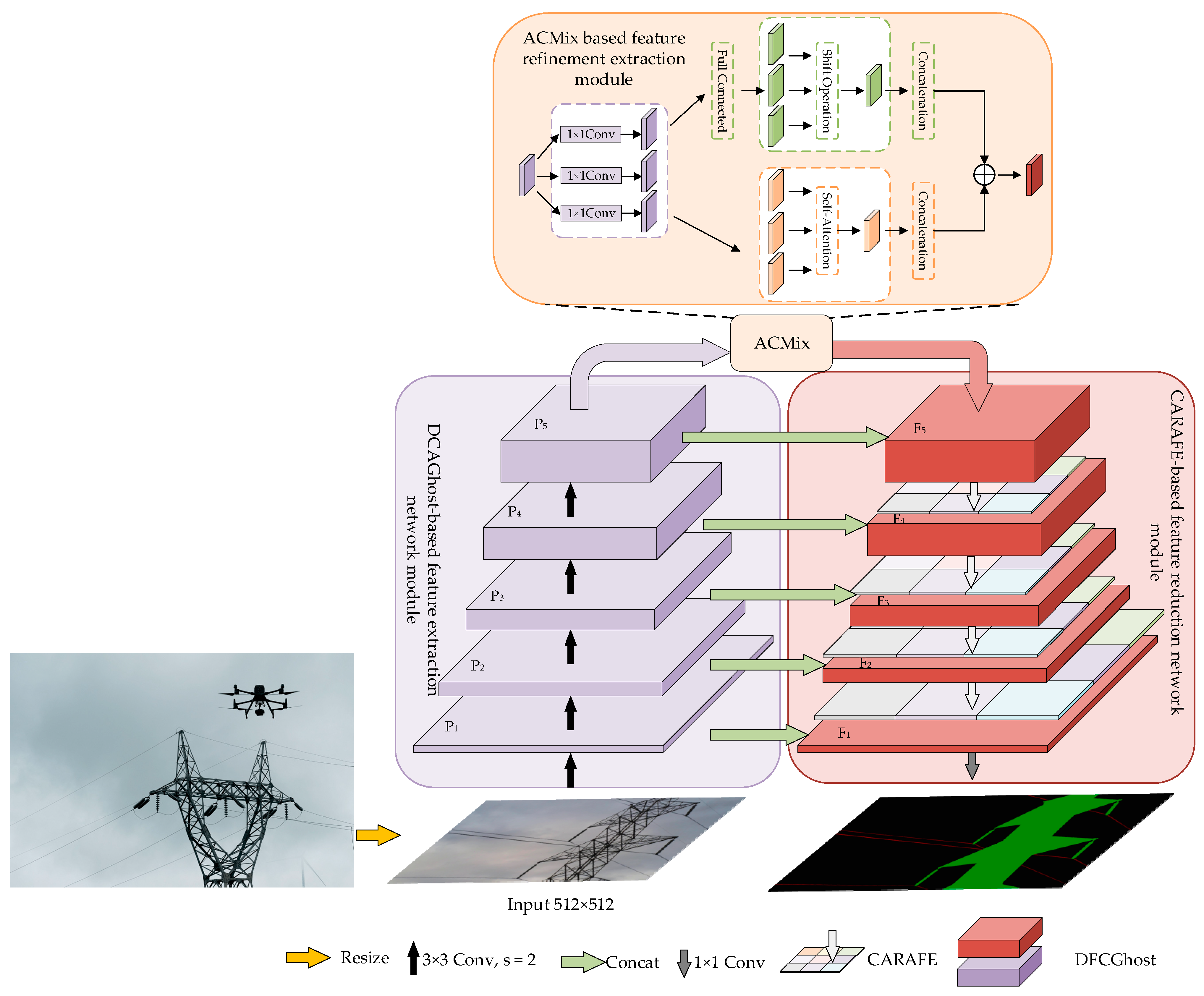
Based on the above problem analysis, this paper proposes a lightweight real-time semantic segmentation network. The network adopts a structure that combines local feature refinement and global receptive field enhancement to effectively solve the problem of power line segmentation in complex backgrounds. Considering the characteristics of power lines, an up-sampling algorithm that combines adjacent pixel information is designed to achieve detailed segmentation of power lines and power poles. In detail, the innovations of this paper are as follows:
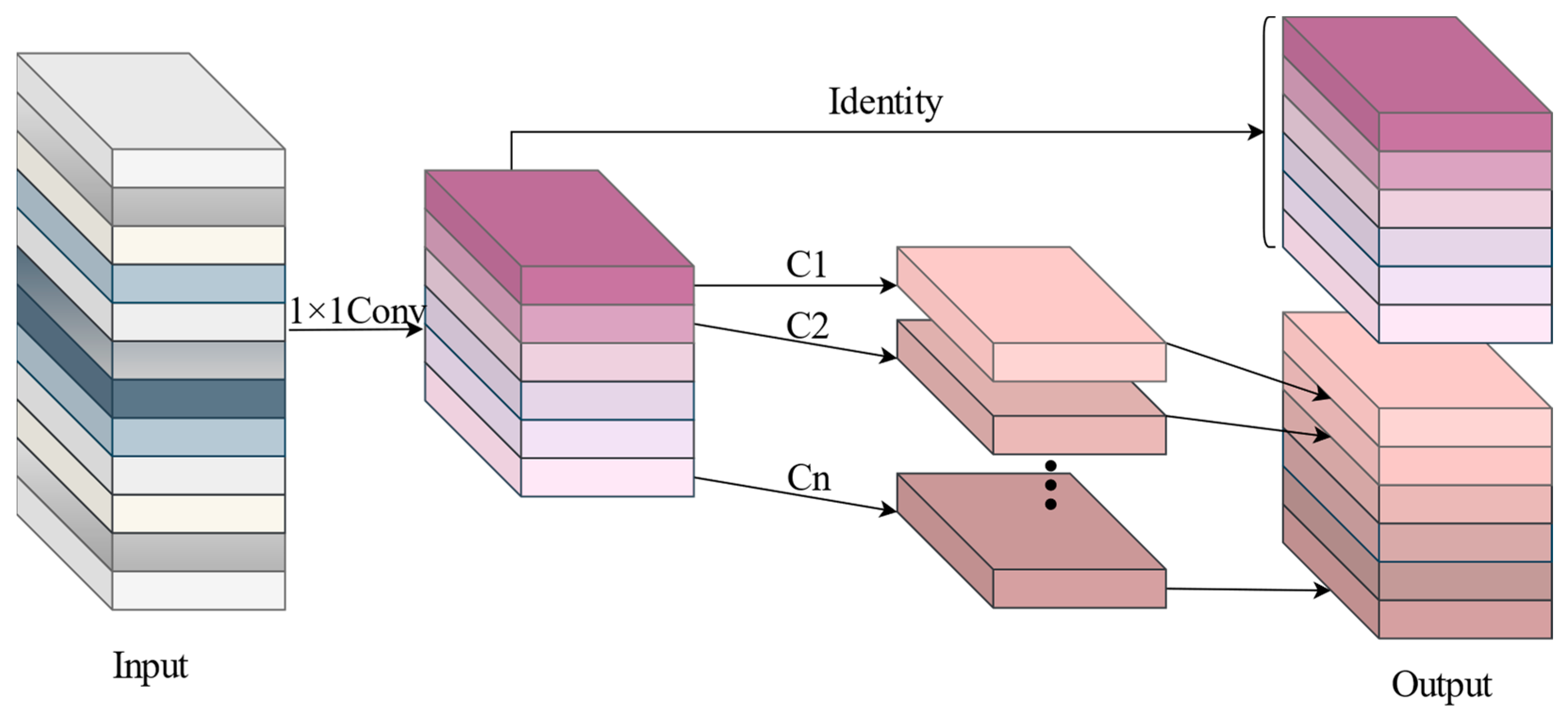
(1) To effectively extract features from power lines and towers, a lightweight DFC-GhostNet feature extraction module has been designed and incorporated into the backbone feature extraction network. Since both power lines and towers have long-range target features, the design divides the symmetric convolutional kernel into two modules: horizontal-based perceptual field enhancement and vertical-based perceptual field enhancement, based on the lightweight GhostNet architecture. This is intended to enable effective target identification and feature extraction.
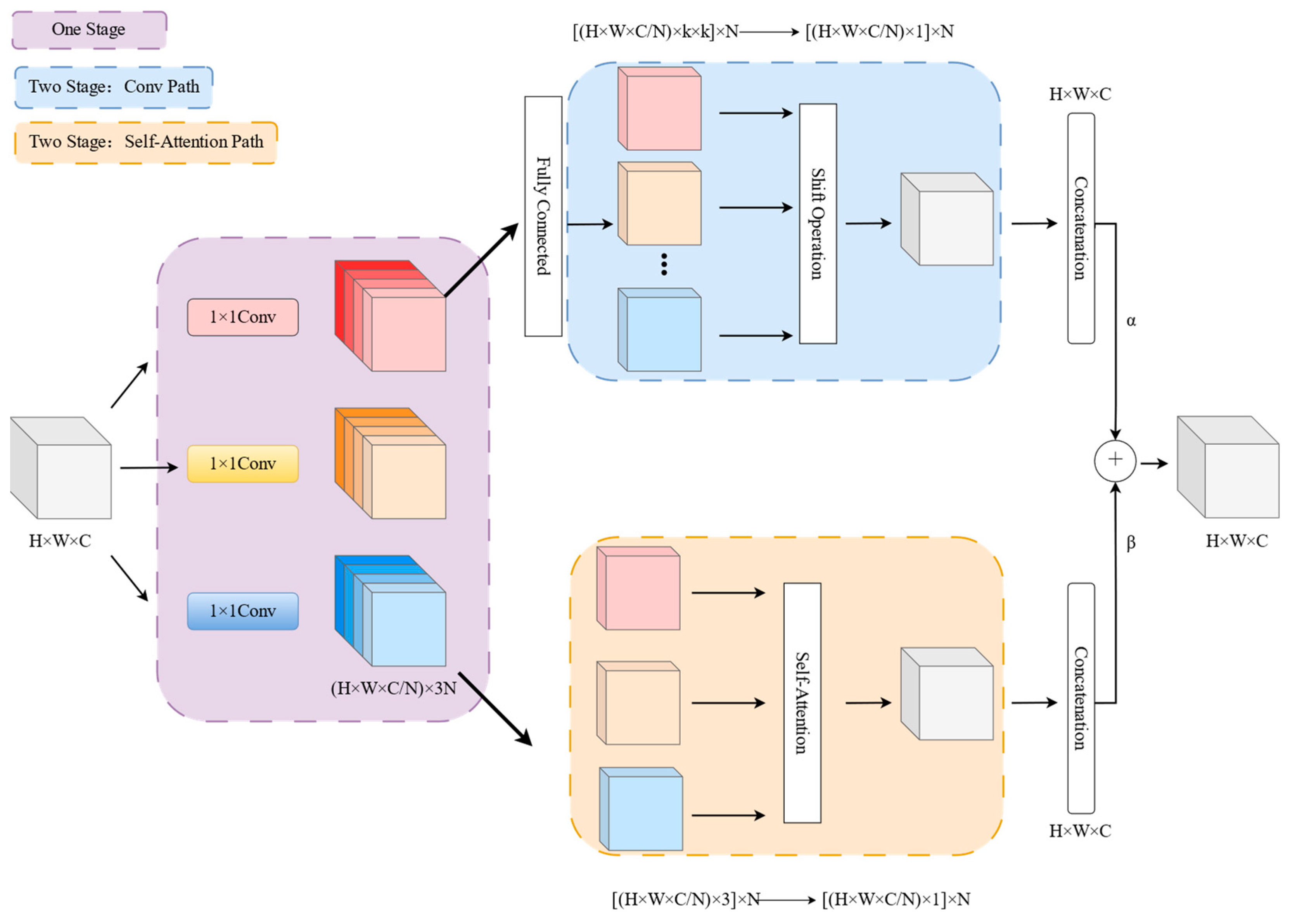
(2) The refinement module of features is designed from the perspective of power line and pole tower feature refinement, combining a convolutional module with local sensory fields and a transformer module with global sensory in deep semantic features to refine target feature areas in complex backgrounds.
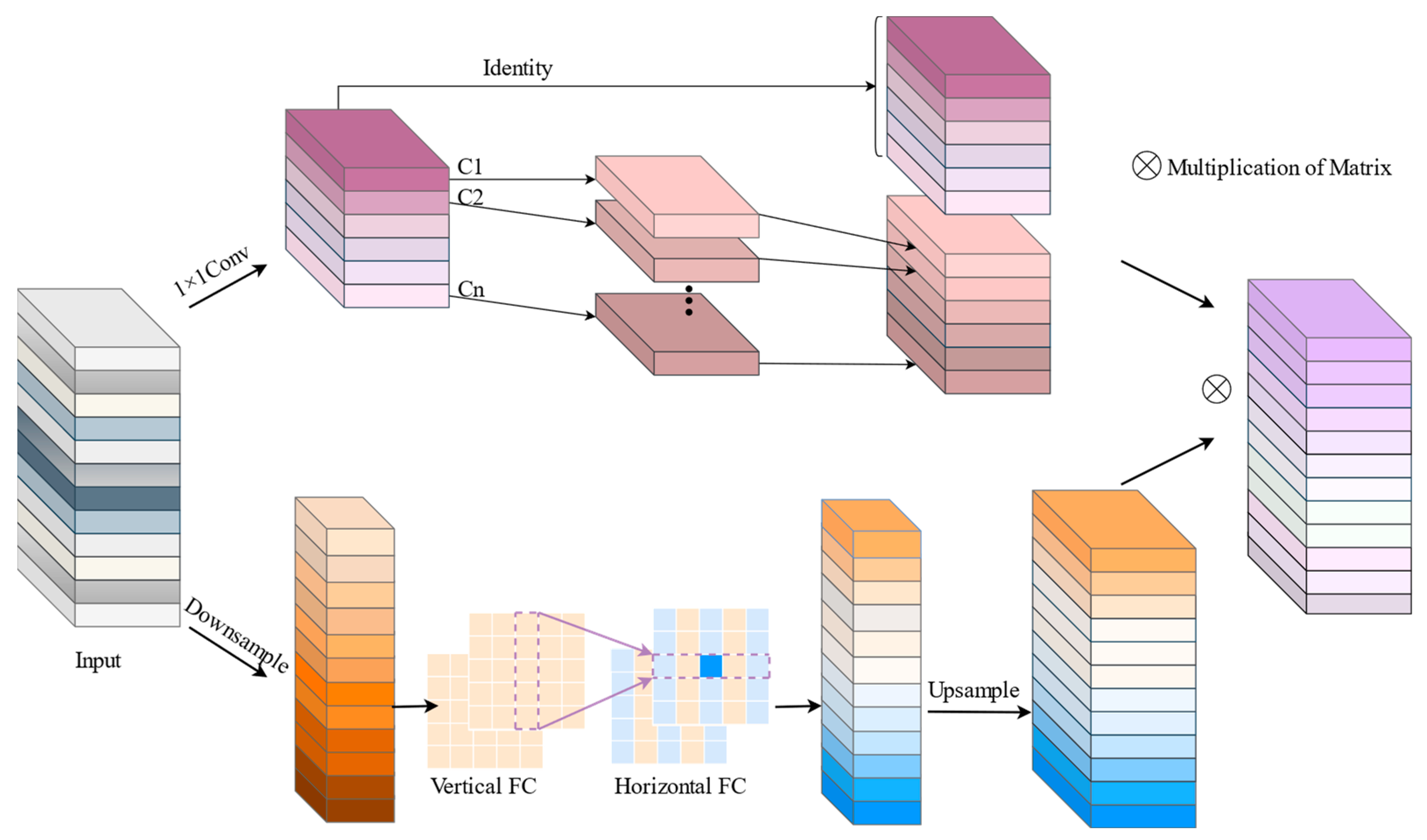
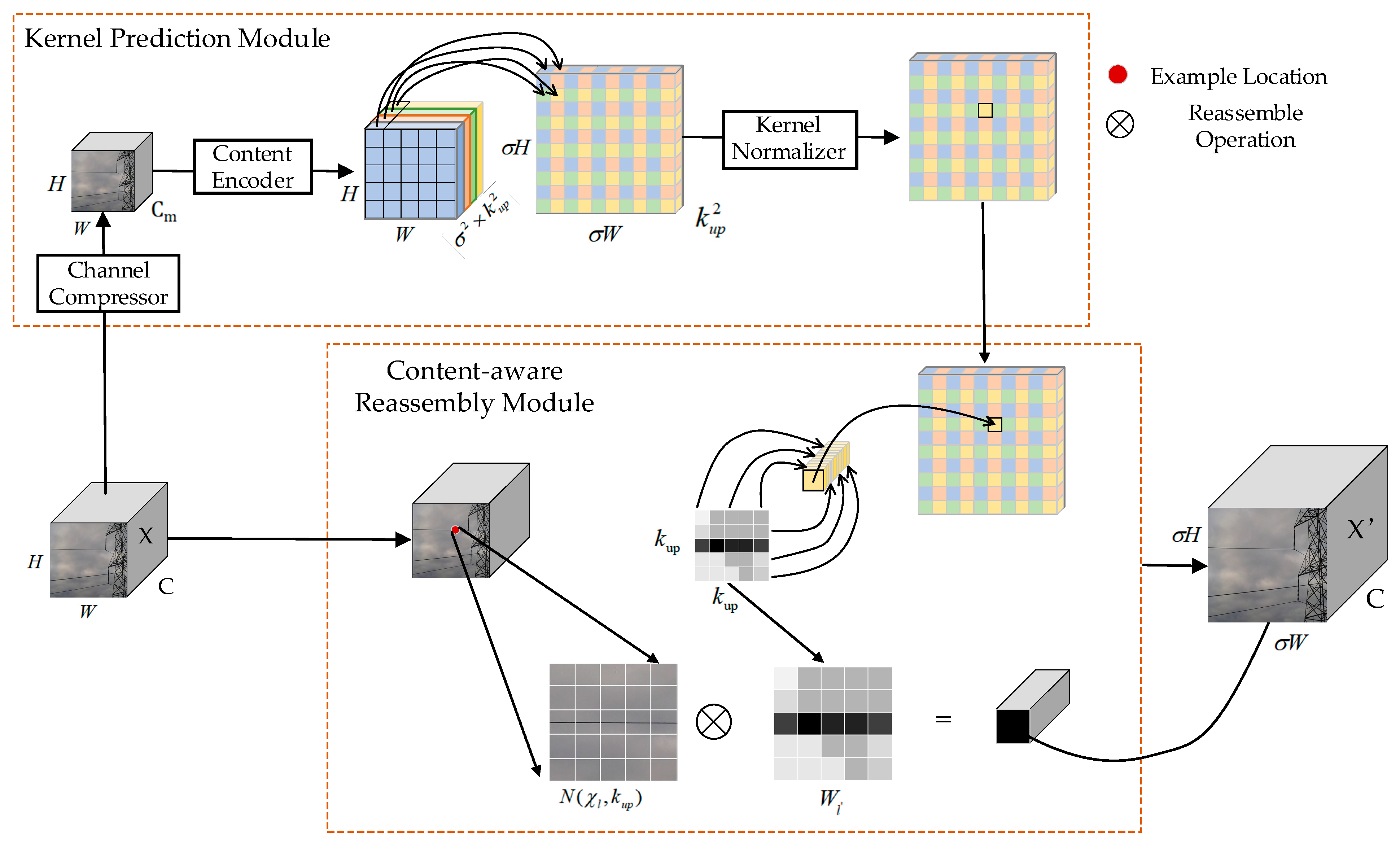
(3) In the process of feature image restoration from low resolution to high resolution, i.e., the decoder part of the semantic segmentation model. Traditional upsampling only considers the information distribution of sub-pixel points and without consider the semantic information of the entire feature map, which leads to the loss of feature map information, and the deconvolution leads to the increase of computation or even Checkerboard Artifacts, which affects the performance of the model. Therefore, a content-aware feature recombination module is designed. This module is mainly to construct a learnable upsampling operator for each pixel in low resolution to learn the distribution of image features. This paper aims to realize upsampling based on input content to improve the feature decoding effect of the final output layer.
3. Experimental Results and Analysis
3.1. Experimental Environment and Setting
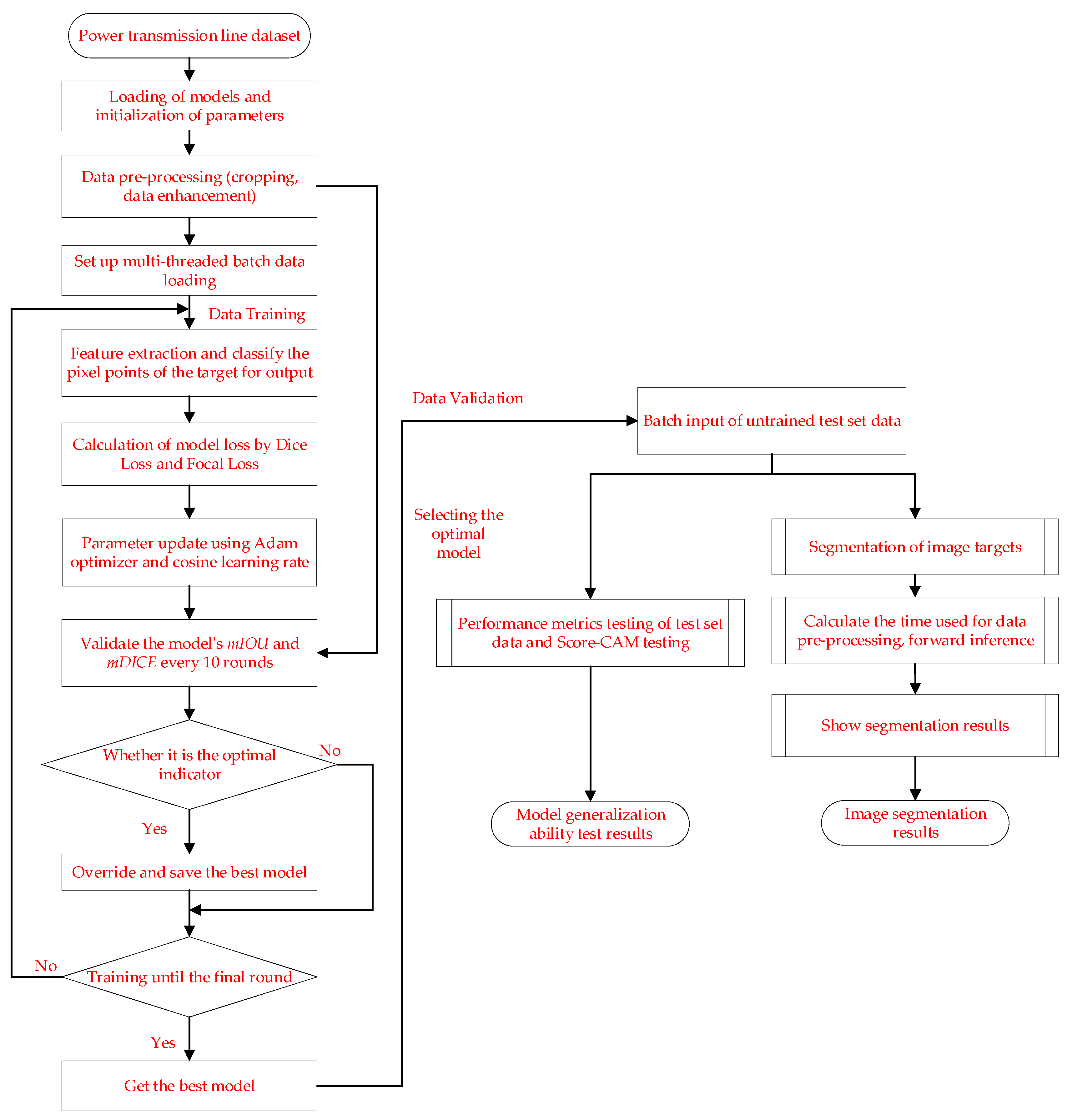
The data are randomly divided into the training set, validation set, and test set in the ratio of 8:1:1. The training set is used to train the model parameters of the segmentation algorithm to obtain the training weights for this dataset. Validation sets are used to monitor the training process and prevent training overfitting. The test set is used to test the training effect and algorithm performance. No data augmentation was performed before training.
This experiment was conducted on an Ubuntu 18.08 system with Python version 3.8.0, CUDA version 11.2, and a deep learning framework based on PyTorch 1.8 environment for training and testing. The training was conducted with two NVIDIA GeForce RTX 3090-24G graphics cards and the graphics card used for the data tested in this article was the NVIDIA GeForce GTX 1050 Ti-4G.
Table 4 contains the experimental parameters and settings.
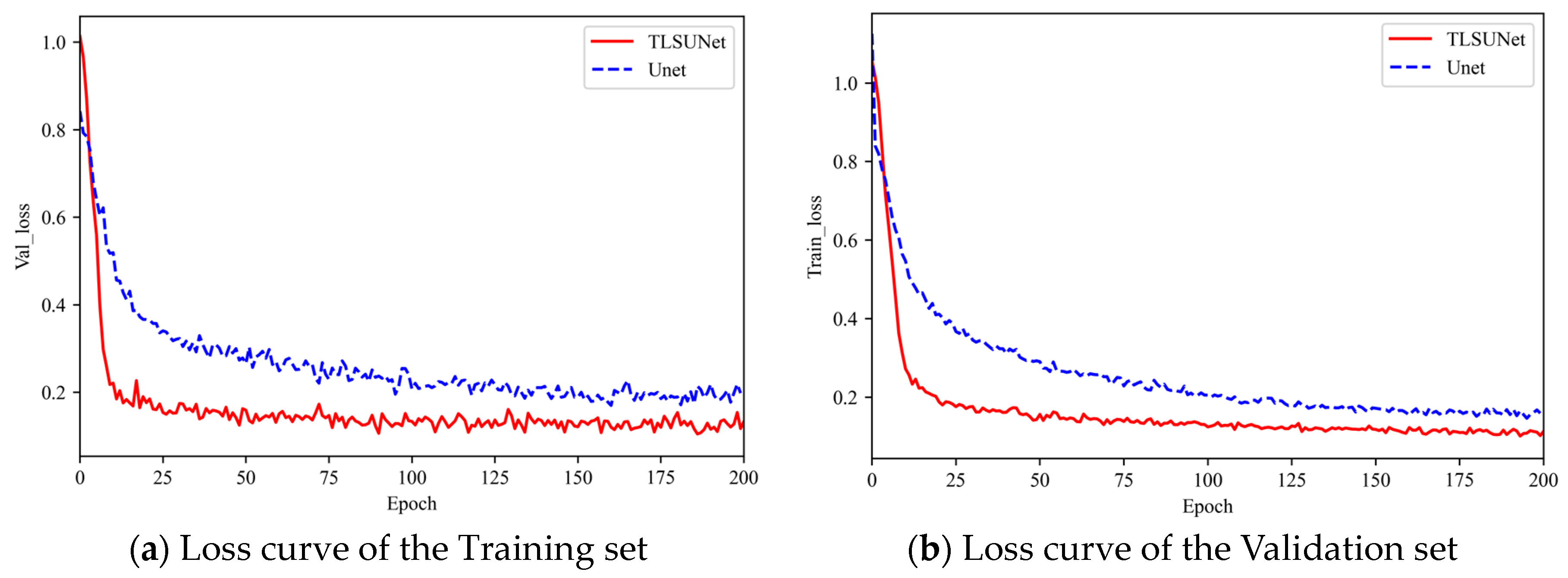
A comparison of the loss curves of the training and validation sets during the training process is shown in
Figure 10. A total of 200 rounds were trained; the initial learning of the model was 0.0001, the momentum was 0.9, and the learning rate was optimized using cosine decay. The batch size was 4, and Iterative optimization of model parameters took place using Adam optimizer.
Figure 10a shows the training loss convergence of the improved model and the original model.
Figure 10b shows the validation loss convergence of the improved model and the original model. Among them, we will finally fuse all the improved models named TLSUNet (UNet + DFC-Ghost + ACmix + CARAFE), which is the red curve in
Figure 10 and
Figure 11. From the figure, it can be seen that the improved model has faster loss convergence and lower loss value than the original model, The model is smooth in the region around 150 rounds.
Figure 11a,b show the validation set change curves of the
mIOU and
mDice metrics of the model before and after the improvement. As can be seen from the curves, the
mIOU and
mDice indexes of the improved model are higher than those of the original model, verifying the effectiveness of the model improvement.
3.2. Comparison of Splitting Accuracy Metrics
To verify the effectiveness of the improved algorithm, ablation experiments were conducted in the same environment, as shown in
Table 5:
(1) From the perspective of detection accuracy, the UNet model without any improvements as a baseline “+” indicates a mix of modules. mIOU has been improved by 6.71 compared to the original model, mDice by 4.57 compared to the original model, mPA by 4.36 compared to the original model, mRecall by 4.36 compared to the original model, and mPrecision is improved by 4.9 compared to the original model. At the same time, the results of different ablation experiments are better compared to the original model. The above enhancement verifies the feasibility of the improved scheme in terms of detection accuracy.
(2) From the perspective of detection speed, in this paper, by performing DFCGhost-based model lightweighting on both the encode and decode of the original model. The improved model on GFLOPs is only 8.3% of the computational effort of the original model, and the number of parameters is only 21.4% of the original model. The inference speed delay is reduced by 0.012 s. The above enhancement verifies the feasibility of the improved scheme in terms of detection speed.
3.3. Test Image Comparison
To verify the actual detection effect of the model,
Table 6 exemplifies the detection results of the algorithm before and after the improvement of the test set. In
Table 6, the first line is the real image under the aerial image, and the second line Ground Truth is the real label image after labeling the target through Labelme. It is mainly used for evaluating and comparing the predicted images during the training process. With the help of the second section, the mentioned evaluation index is used to judge the results between the real map and the predicted map. The following is the prediction result graph of the comparison model.
(1) The first of these images is a typical power line segmentation in a complex background. The fusion improvement model (TLSUNet) can better segment power lines in complex backgrounds, the rest of the models have intermittent segmentation or mis-segmentation problems.
(2) The second picture and the third picture show the division of power lines and towers with the sky in the background. The second picture is a wood-type tower and the other is a fence-type tower. The fusion improvement model (TLSUNet) model can better achieve the effective segmentation of power lines and different types of towers, while the rest of the network has the problem of missed segmentation.
(3) The fourth image shows the simultaneous segmentation of the pole tower and power line in a complex background, where the background is a more complex mountainous area and there is interference from the road color being similar to the pole tower. The fusion improvement model (TLSUNet) can better achieve the effective segmentation of power lines and towers. The above segmentation results also verify the feasibility of the improved scheme for image generalization ability detection.
3.4. Test Image with Score-CAM Comparison
Finally, this paper visualizes and compares the areas of interest of the images through the Score-cam heatmap. The principle of the Score-cam is mainly to weigh the feature map with the score of the target region to remove the dependence on the feature gradient (due to the complexity of the gradient information and the problem of gradient disappearance for activation functions such as Sigmoid and ReLU) [
41]. The final result is obtained by taking a linear combination of weights and activation maps. The calculation principle is shown in Equation (15).
In Equation (15), denotes the size of the output feature map, l indicates the feature hierarchy of the output, and k denotes the number of channels corresponding to each feature layer. is the sigmoid activation function. The value interval is used to normalize the feature map. denotes the size of the original output image size. f(X) is the input feature map, and f(X*) is the weighted result of the input feature map. is the region of interest of the obtained model for the input image.
Through the visualization of the heat map, we know that the heat map is concerned with the location of the target segmentation area, and the darker color represents the focus of attention on the region; as such, the proportion of attention to the outward diffusion is reduced. The first image in
Table 7 shows the complex background power line segmentation detected earlier, and the heat map shows that the improved model (TLSUNet) has a clear focus on transmission lines, and the rest of the models all show breakpoints or a low level of color-based focus. The second image shows the segmentation of multiple transmission line towers. The improved model (TLSUNet) pays better attention to all the towers present in the image, especially the long-distance ones. The third and fourth sheets show two types of targets for the same diagram and the improved model (TLSUNet) has a clear focus on the pairs of transmission lines and towers. The heat map-based analysis results also verify the improved scheme’s feasibility in enhancing the image segmentation capability.
4. Discussion
To achieve efficient and accurate segmentation of power lines and power towers in transmission lines, in this paper we propose an improved UNet segmentation algorithm. In this study, we verified the effectiveness of the improved network in terms of segmentation accuracy and segmentation speed by comparing the basic segmentation network with the improved network, and have better solved the power lines and power towers in the transmission line under the complex background. In addition, on this basis, we will further conduct research on the following points:
(1) Use the researched lightweight segmentation network on the edge hardware to conduct test experiments to verify whether its inference speed can meet the requirements of normal inspection, and provide a reference for further performance optimization.
(2) It can be seen from
Table 6 that at present, only the division of power lines and power towers can be realized, and more power transmission line equipment will be introduced in the future for detection, to further improve the demand for transmission line inspection.
(3) Further combine mobile edge terminals with UAVs to achieve fully autonomous line inspection requirements. At the same time, it is necessary to further consider the detection effect of the model in dense urban places.
5. Conclusions
For efficient segmentation of power lines and power towers in transmission lines in a complex context, this paper proposes a segmentation algorithm based on an improved UNet structure, and the following conclusions can be drawn by analyzing and comparing the effects of relevant factors on the segmentation effect through existing power transmission data sets.
(1) To address the lightweight problem of the model, this paper designs the DFCGhost convolutional feature extraction network, which is used for the compression of the number of parameters on the one hand, and enhances the feature extraction process in the horizontal and vertical directions at the same time, so that the model can be modeled with long-distance spatial information. The results indicate an improvement of 1.62 in mIOU and 1.16 in mDice of the model. Secondly, the complex background is the main factor affecting the model segmentation, so the deep semantic features are refined and weight extracted by combining the convolution module with local perceptual field enhancement and the transformer module with global perceptual field enhancement. The results showed that the model improved mIOU by 3.46 and mDice by 2.28. Finally, high-precision decoding of features is achieved by using CARAFE’s feature parameter reconstruction to improve the usability of features. The results showed that the model had been improved by 2.85 for mIOU and 1.91 for mDice.
(2) The results of the ablation experiments show that the model incorporating all improvements improves by 6.71 on mIOU, 4.57 on mDice, 4.8 on mPrecision, 4.36 on mRecall, and 4.36 on mPA for power lines and power towers.
(3) The fusion experimental model is tested on the computer side and the results show that the parameters of the lightweight model are only 8.3% of the computation of the original model, and the number of parameters is only 21.4% of the original model. The inference speed delay is reduced by 0.012 s. The test results can play a certain role in the intelligent inspection of power system automation.
At the same time, the power line segmentation task realized in this paper can provide a feasible technical solution and reference for UAV automatic line following inspection technology.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











































































