
MS-YOLOv7:YOLOv7 Based on Multi-Scale for Object Detection on UAV Aerial Photography
Abstract
:1. Introduction
- (1)
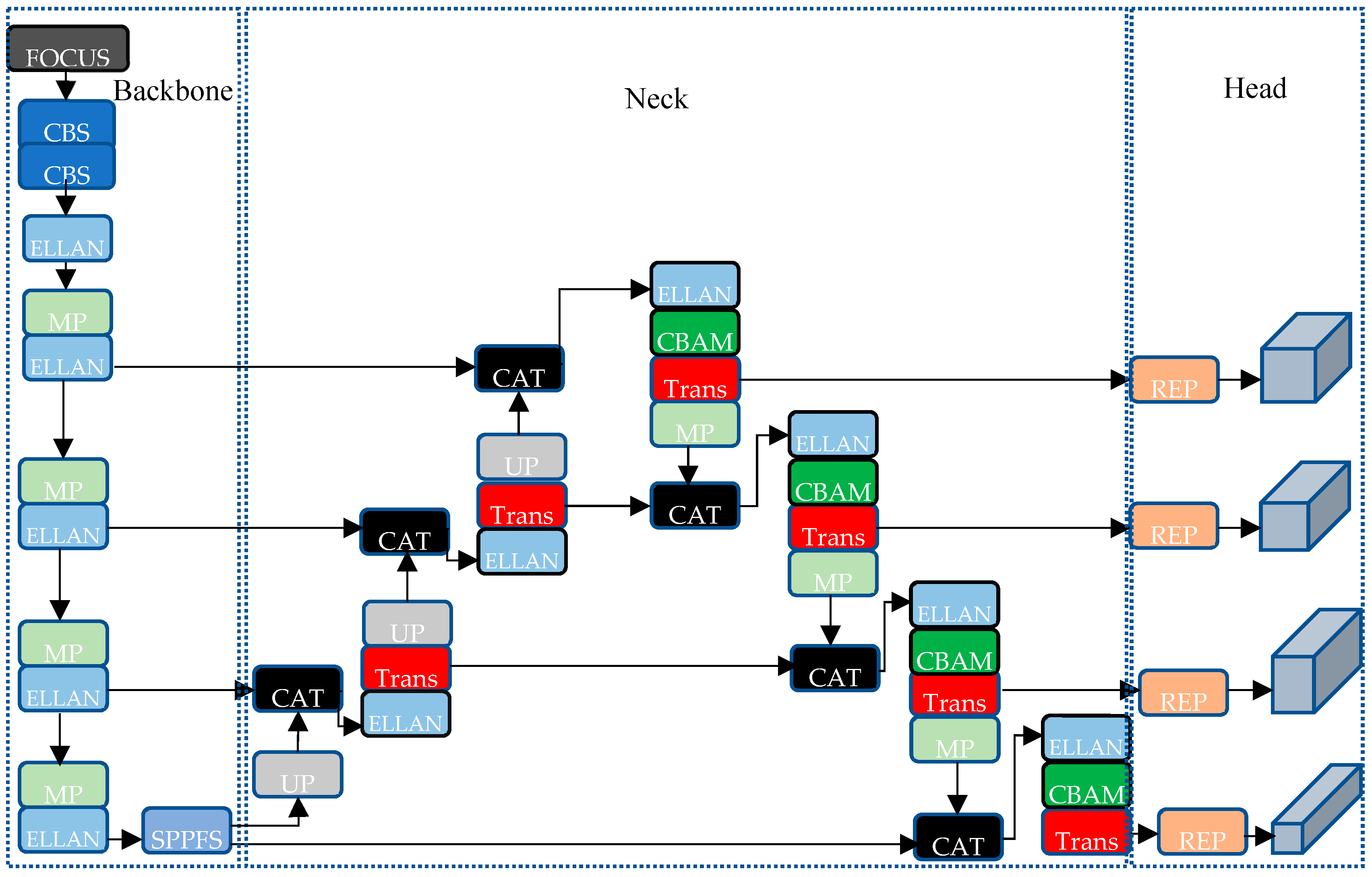
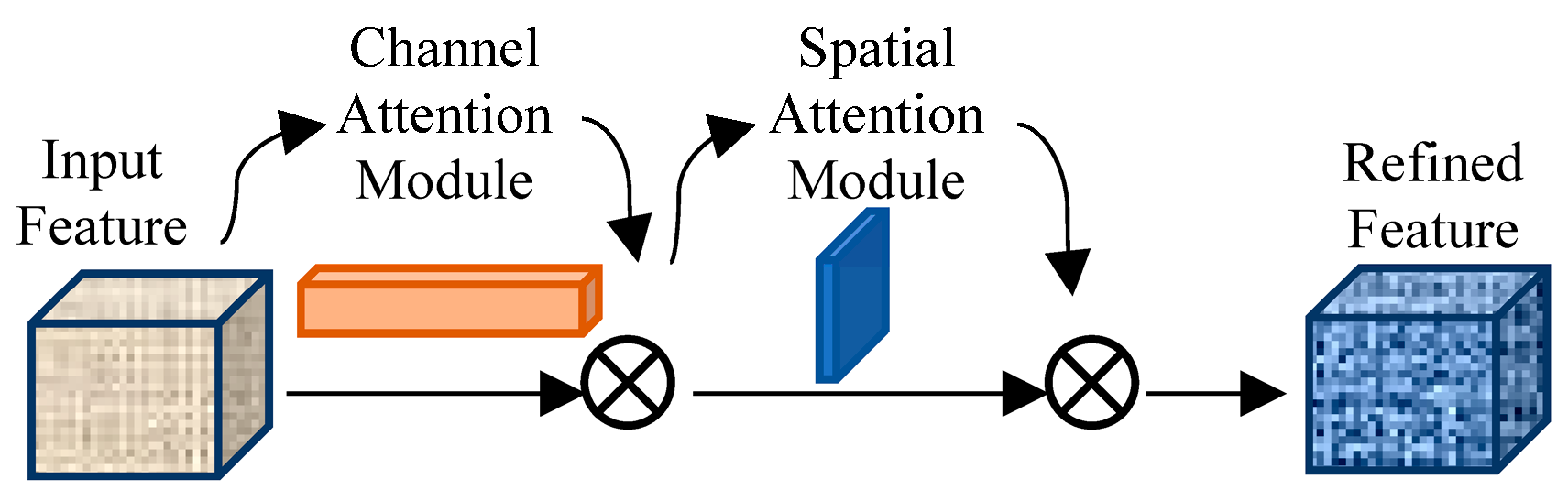
- We propose a novel network with multiple detection head and introduce the CBAM convolutional attention module to extract features at different scales to improve the detection accuracy of objects at various scales, particularly small objects;
- (2)
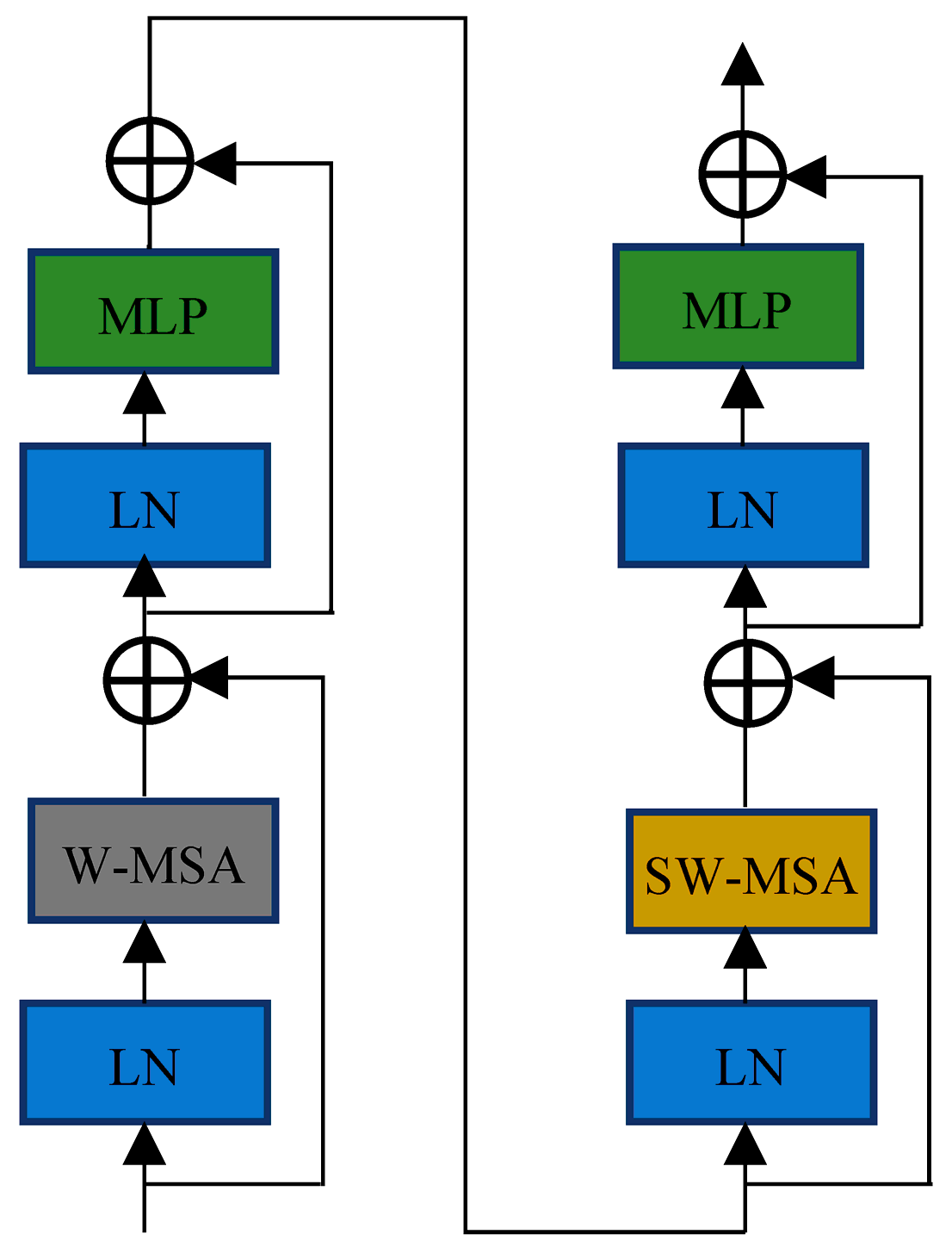
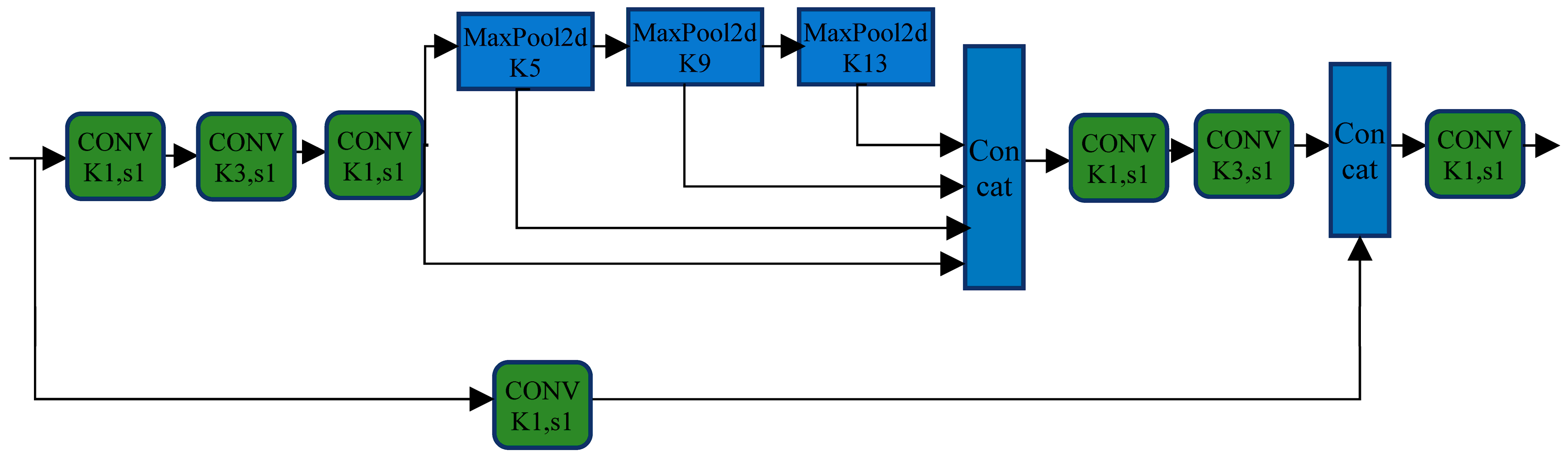
- We combine the YOLOv7 network architecture with the Swin Transformer unit and incorporate a new pyramidal pooling module, SPPFS, to solve the problem of high-density object detection;
- (3)
- We incorporate the SoftNMS and the Mish() activation function to improve the network’s ability to identify overlapping and occlusion objects. Various experiments demonstrate the superiority of our work.
2. Related Work
3. Network Structures
3.1. Swin Transform
3.2. CBAM
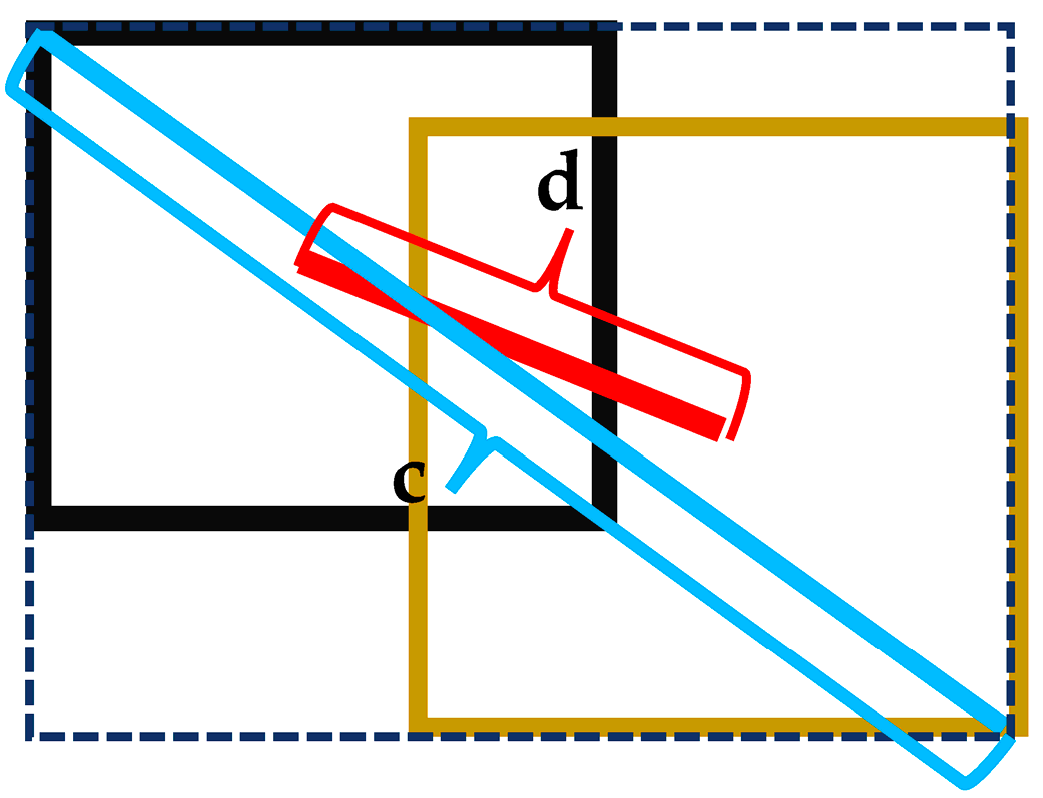
3.3. SPPFS
3.4. Soft-NMS
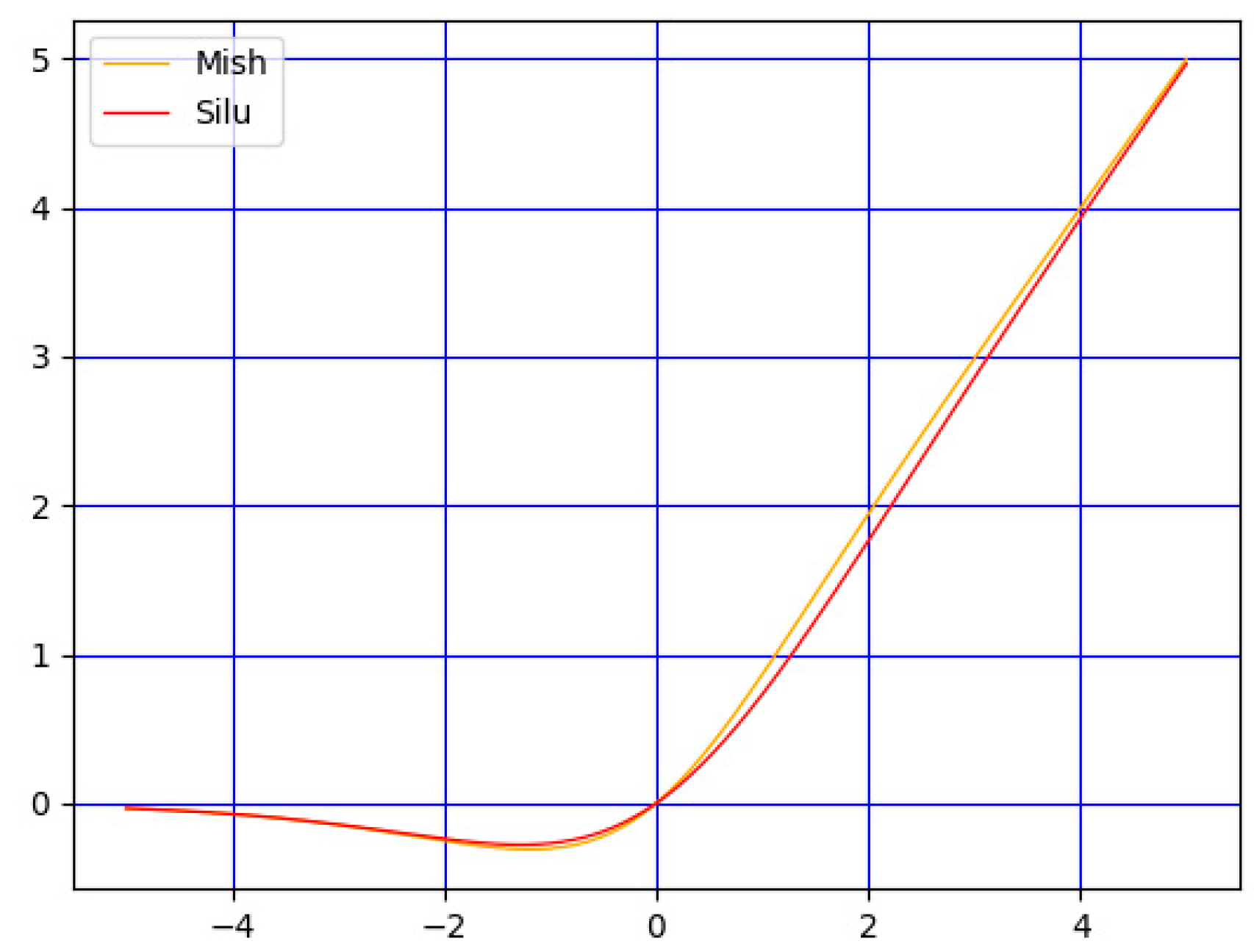
3.5. Activation Function
4. Experiment
4.1. Data Set and Parameter Settings
4.2. Comparison of Detection Results of Different Algorithms on VisDrone2019
4.3. Ablation Experiment
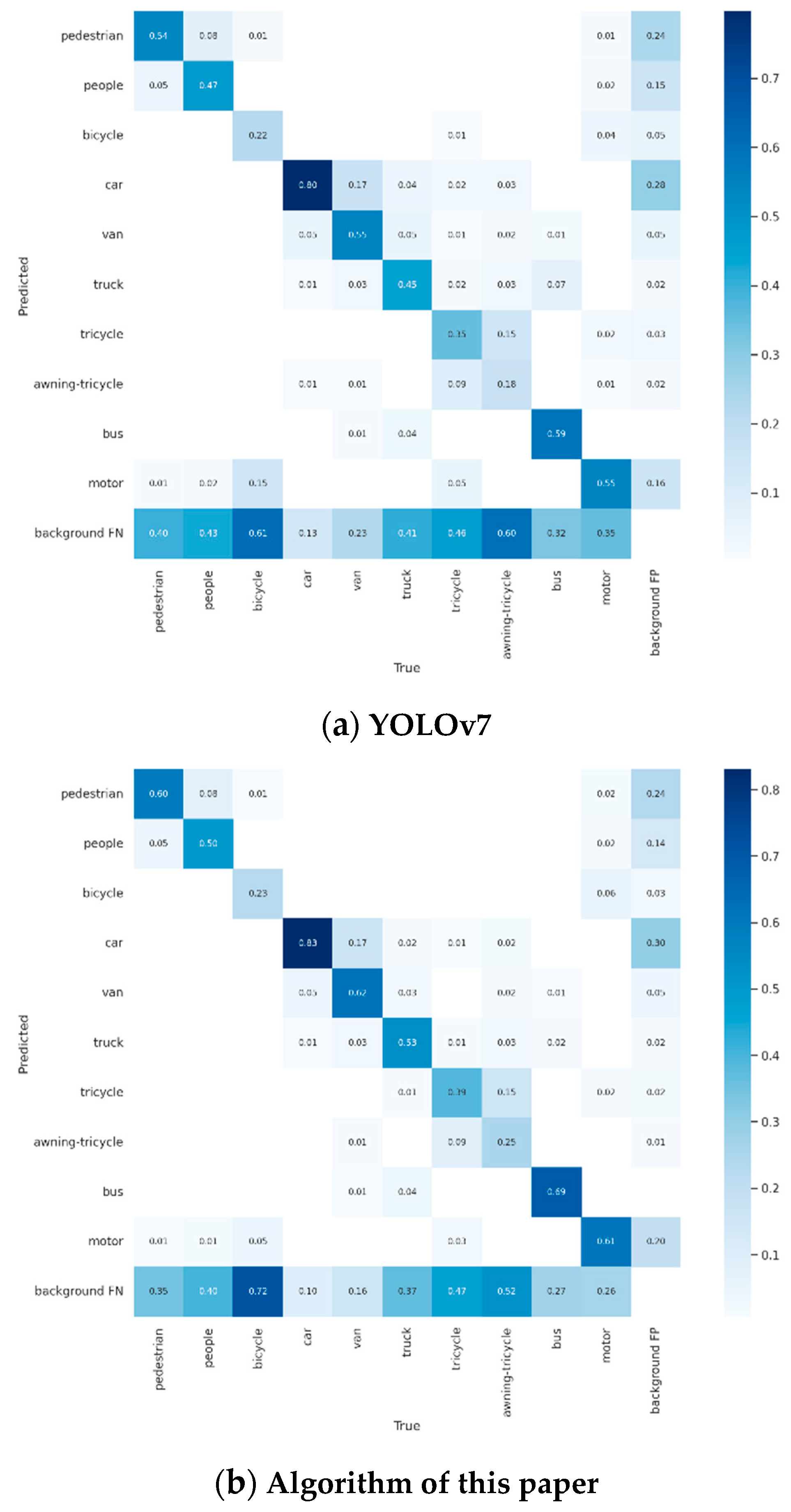
4.4. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiao, L.; Wang, D.; Bai, Y.; Chen, P.; Liu, F. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7380–7399. [Google Scholar]
- Liu, S.; Liu, Y.; Sun, Y.; Li, Y.; Wang, J. Small target detection of UAV aerial photography images based on inverted residual attention. J. Beihang Univ. 2023, 3, 1–13. [Google Scholar]
- Mao, G.; Deng, T.; Yu, N. Object detection algorithm for UAV aerial photography images based on multi-scale segmentation of attention. J. Aeronaut. 2023, 1, 1–12. [Google Scholar]
- Dai, J.; Wu, L.; Wang, P. Overview of UAV Target Detection Algorithms Based on Deep Learning. In Proceedings of the 2021 IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 17–19 December 2021; pp. 736–745. [Google Scholar]
- Zhang, J.; Nong, C.; Yang, Z. Review of object detection algorithms based on convolutional neural network. J. Ordnance Equip. Eng. 2022, 43, 37–47. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conferenceon Computer Vision; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6:A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Shf, P.; Zhao, C. Review on Deep based Object Detection. In Proceedings of the 2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 372–377. [Google Scholar]
- Feng, J.; Liang, Y.; Ye, Z. Small object detection in optical remote sensing video with motion guided R-CNN. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 272–275. [Google Scholar]
- Li, L.; Cheng, L.; Guo, X. Deep adaptive proposal network in optical remote sensing images objective detection. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2651–2654. [Google Scholar]
- He, W.; Huang, Z.; Wei, Z.; Li, C.; Guo, B. TF-YOLO: An improved incremental network for real-time object detection. Appl. Sci. 2019, 9, 322. [Google Scholar]
- Xu, J.; Xie, Z.; Li, H. Signature balanced target detection algorithm for UAV aerial photography images. Comput. Eng. Appl. 2023, 3, 1–9. [Google Scholar]
- Pei, W.; Xu, Y.; Zhu, Y.; Wang, P.; Lu, M.; Li, F. Improved SSD aerial target detection method. J. Softw. 2019, 30, 738–758. [Google Scholar]
- Ze, L.; Yutong, L.; Yue, C.; Han, H.; Yixuan, W.; Zheng, Z. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Van Etten, A. YOLT: You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Duan, C.; Wei, Z.; Zhang, C.; Qu, S.; Wang, H. Coarse-grained Density Map Guided Object Detection in Aerial Images. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2789–2798. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wang, Y.; Yang, Y.; Zhao, X. Object Detection Using Clustering Algorithm Adaptive Searching Regions in Aerial Images. In Proceedings of the ECCV 2020: Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 651–664. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8310–8319. [Google Scholar]
- Deng, S.; Li, S.; Xie, K.; Song, W.; Liao, X.; Hao, A.; Qin, H. A Global-Local Self-Adaptive Network for Drone-View Object Detection. IEEE Trans. Image Process. 2021, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Li, Y.; Wang, S. AdaZoom: Adaptive Zoom Network for Multi-Scale Object Detection in Large Scenes. arXiv 2021, arXiv:2106.10409. [Google Scholar]
- Xu, C.; Wang, J.; Yang, W. Dot Distance for Tiny Object Detection in Aerial Images. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021; pp. 1192–1201. [Google Scholar]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.-S. Tiny Object Detection in Aerial Images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar]
- Li, Z.; Wang, Z.; He, Y. Aerial Photography Dense Small Target Detection Algorithm Based on Adaptive Collaborative Attention Mechanism. J. Aeronaut. 2023, 10, 1–12. [Google Scholar] [CrossRef]
- Huang, H.; Li, L.; Ma, H. An Improved Cascade R-CNN-Based Target Detection Algorithm for UAV Aerial Images. In Proceedings of the 2022 7th International Conference on Image, Vision and Computing (ICIVC), Xi’an, China, 26–28 July 2022; pp. 232–237. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Object Category | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pedestrian | People | Bicycle | Car | Van | Truck | Tri | Awn-Tri | Bus | Motor | ||
| Faster R-CNN | 20.9 | 14.8 | 7.3 | 51.0 | 29.7 | 19.5 | 14.0 | 8.8 | 30.5 | 21.2 | 21.8 |
| RetinaNet | 13.0 | 7.9 | 1.4 | 45.5 | 19.9 | 11.5 | 6.3 | 4.2 | 17.8 | 11.8 | 13.9 |
| YOLOv4 | 24.8 | 12.6 | 8.6 | 64.3 | 22.4 | 22.7 | 11.4 | 7.6 | 44.3 | 21.7 | 30.7 |
| CDNet | 35.6 | 19.2 | 13.8 | 55.8 | 42.1 | 38.2 | 33.0 | 25.4 | 49.5 | 29.3 | 34.2 |
| YOLOv3-LITE | 34.5 | 23.4 | 7.9 | 70.8 | 31.3 | 21.9 | 15.3 | 6.2 | 40.9 | 32.7 | 28.5 |
| MSC-CenterNet | 33.7 | 15.2 | 12.1 | 55.2 | 40.5 | 34.1 | 29.2 | 21.6 | 42.2 | 27.5 | 31.1 |
| DMNet | 28.5 | 20.4 | 15.9 | 56.8 | 37.9 | 30.1 | 22.6 | 14.0 | 41.7 | 29.2 | 30.3 |
| HR-Cascade++ | 32.6 | 17.3 | 11.1 | 54.7 | 42.4 | 35.3 | 32.7 | 24.1 | 46.5 | 28.2 | 32.5 |
| DBAI-Net | 36.7 | 12.8 | 14.7 | 47.4 | 38.0 | 41.4 | 23.4 | 16.9 | 31.9 | 16.6 | 28.0 |
| Cascade R-CNN | 22.2 | 14.8 | 7.6 | 54.6 | 31.5 | 21.6 | 14.8 | 8.6 | 34.9 | 21.4 | 23.2 |
| CenterNet | 22.6 | 20.6 | 14.6 | 59.7 | 24.0 | 21.3 | 20.1 | 17.4 | 37.9 | 23.7 | 26.2 |
| MSA-YOLO | 33.4 | 17.3 | 11.2 | 76.8 | 41.5 | 41.4 | 14.8 | 18.4 | 60.9 | 31.0 | 34.7 |
| TPH-YOLOv5 | 29.00 | 16.7 | 15.6 | 68.9 | 49.7 | 45.1 | 27. | 24.7 | 61.8 | 30.9 | 37.3 |
| ACAM-YOLO | 57.6 | 45.9 | 25.7 | 88.5 | 51.9 | 45.5 | 38.1 | 19.9 | 69.1 | 56.3 | 49.5 |
| YOLOv8 | 50.2 | 39.7 | 21.3 | 74.8 | 50.5 | 46.2 | 33.3 | 22.1 | 67.4 | 45.3 | 40.2 |
| Ours | 63.2 | 51.7 | 26.2 | 88.7 | 56.2 | 48.7 | 39.7 | 21.8 | 70.1 | 63.8 | 53.1 |
| Method | Parameters | ||
|---|---|---|---|
| YOLOv7 | 47.1 | 26.4 | 71.4 M |
| YOLOv7 + Sw T | 49.5 | 27.9 | 77.2 M |
| YOLOv7 + Small | 51.8 | 30.7 | 74.4 M |
| YOLOv7 + Mish | 49.3 | 27.9 | 71.4 M |
| YOLOv7 + SPP | 49.3 | 27.7 | 71.4 M |
| YOLOv7 + CBAM | 49.5 | 28.0 | 62.9 M |
| YOLOv7 + Soft | 49.7 | 28.1 | 71.4 M |
| YOLOv7_ Small _Sw T | 51.5 | 30.6 | 79.7 M |
| YOLOv7_ Small _Sw T_ CBAM | 51.6 | 30.4 | 79.7 M |
| YOLOv7_ Small _Sw T_ CBAM _SPP | 52.1 | 30.9 | 79.7 M |
| YOLOv7_ Small _Sw T_ CBAM _SPP _ Mish | 52.8 | 31.1 | 79.7 M |
| YOLOv7_ Small _Sw T_ CBAM _SPP _ Mish _Soft | 53.1 | 31.3 | 79.7 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Zhu, M. MS-YOLOv7:YOLOv7 Based on Multi-Scale for Object Detection on UAV Aerial Photography. Drones 2023, 7, 188. https://doi.org/10.3390/drones7030188
Zhao L, Zhu M. MS-YOLOv7:YOLOv7 Based on Multi-Scale for Object Detection on UAV Aerial Photography. Drones. 2023; 7(3):188. https://doi.org/10.3390/drones7030188
Chicago/Turabian StyleZhao, LiangLiang, and MinLing Zhu. 2023. "MS-YOLOv7:YOLOv7 Based on Multi-Scale for Object Detection on UAV Aerial Photography" Drones 7, no. 3: 188. https://doi.org/10.3390/drones7030188