
A Path-Planning Method Considering Environmental Disturbance Based on VPF-RRT*

Abstract
:1. Introduction
2. Related Works
2.1. Path Planning
2.2. Path Tracking
3. Modeling and Problem Formulation
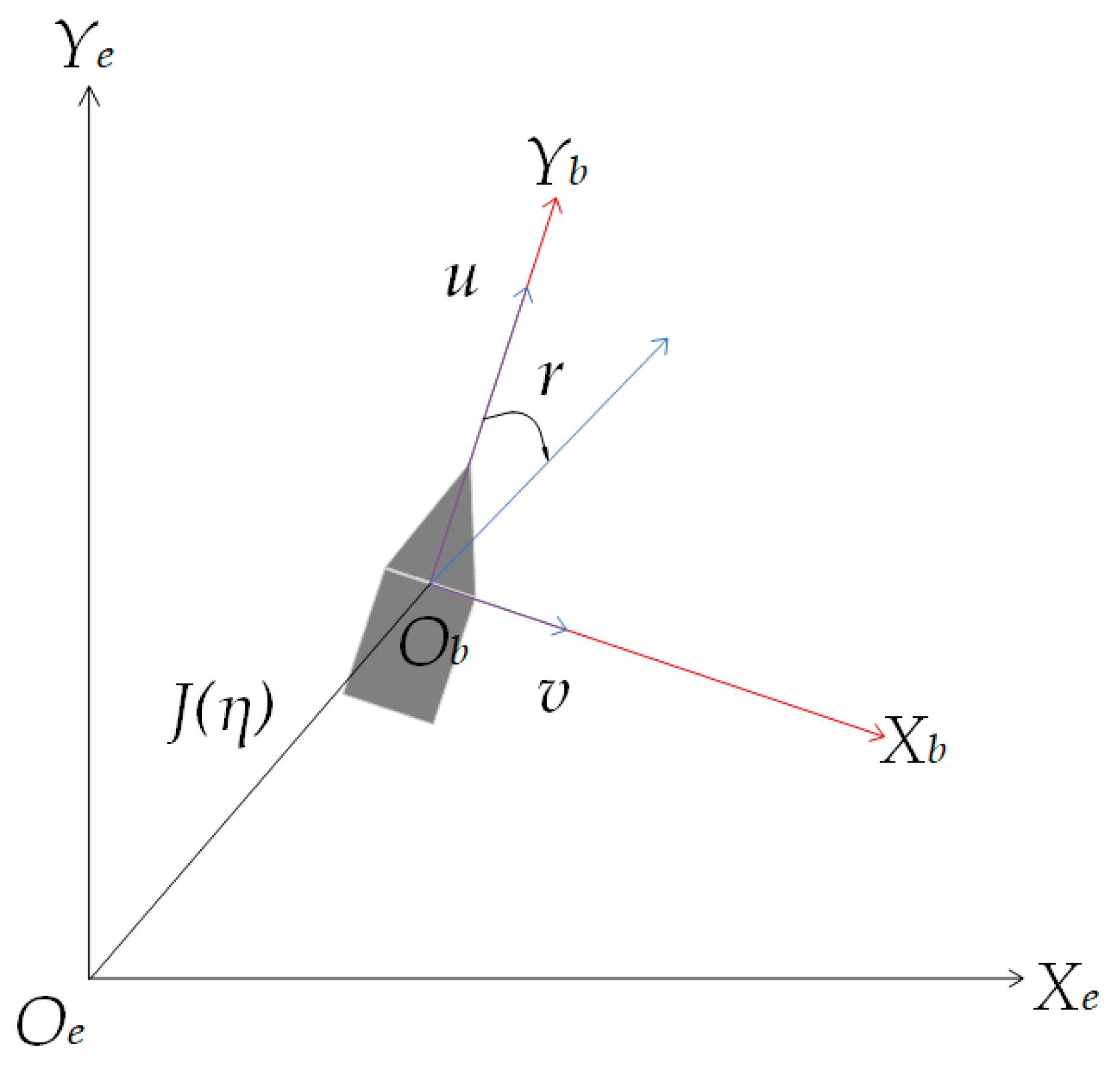
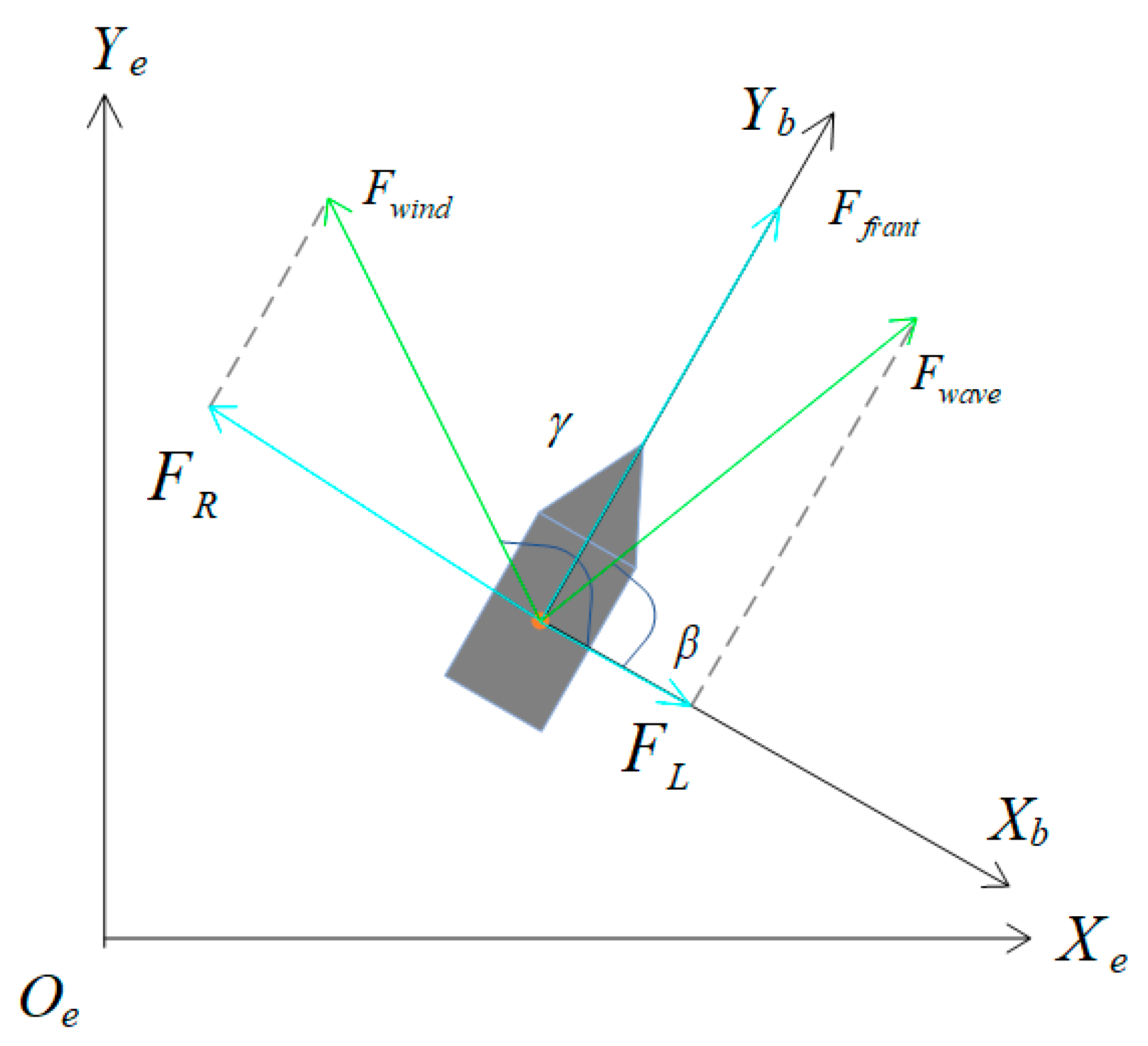
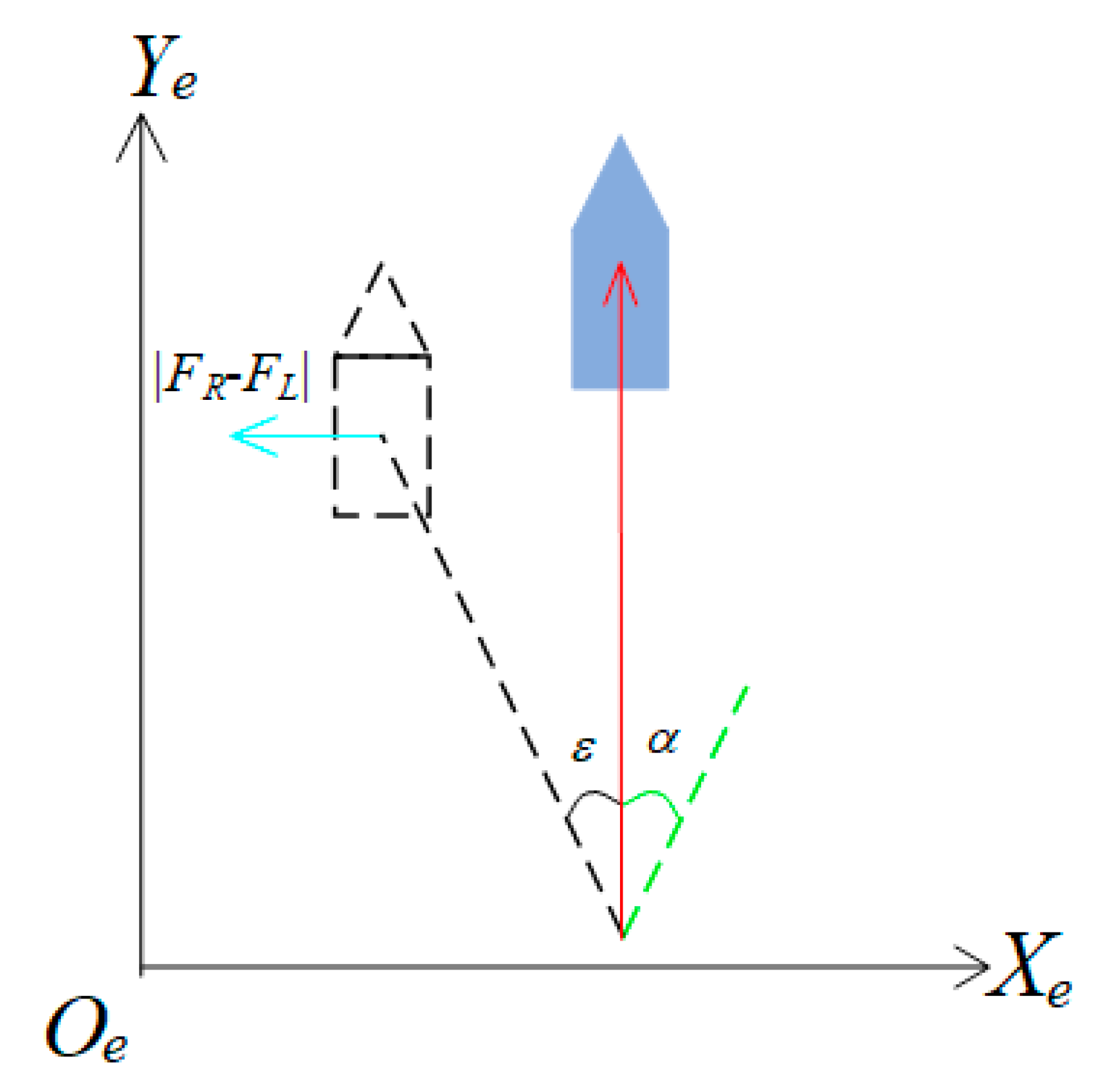
3.1. USV Modeling
3.2. Obstacle Modeling
3.3. Problem Formulation
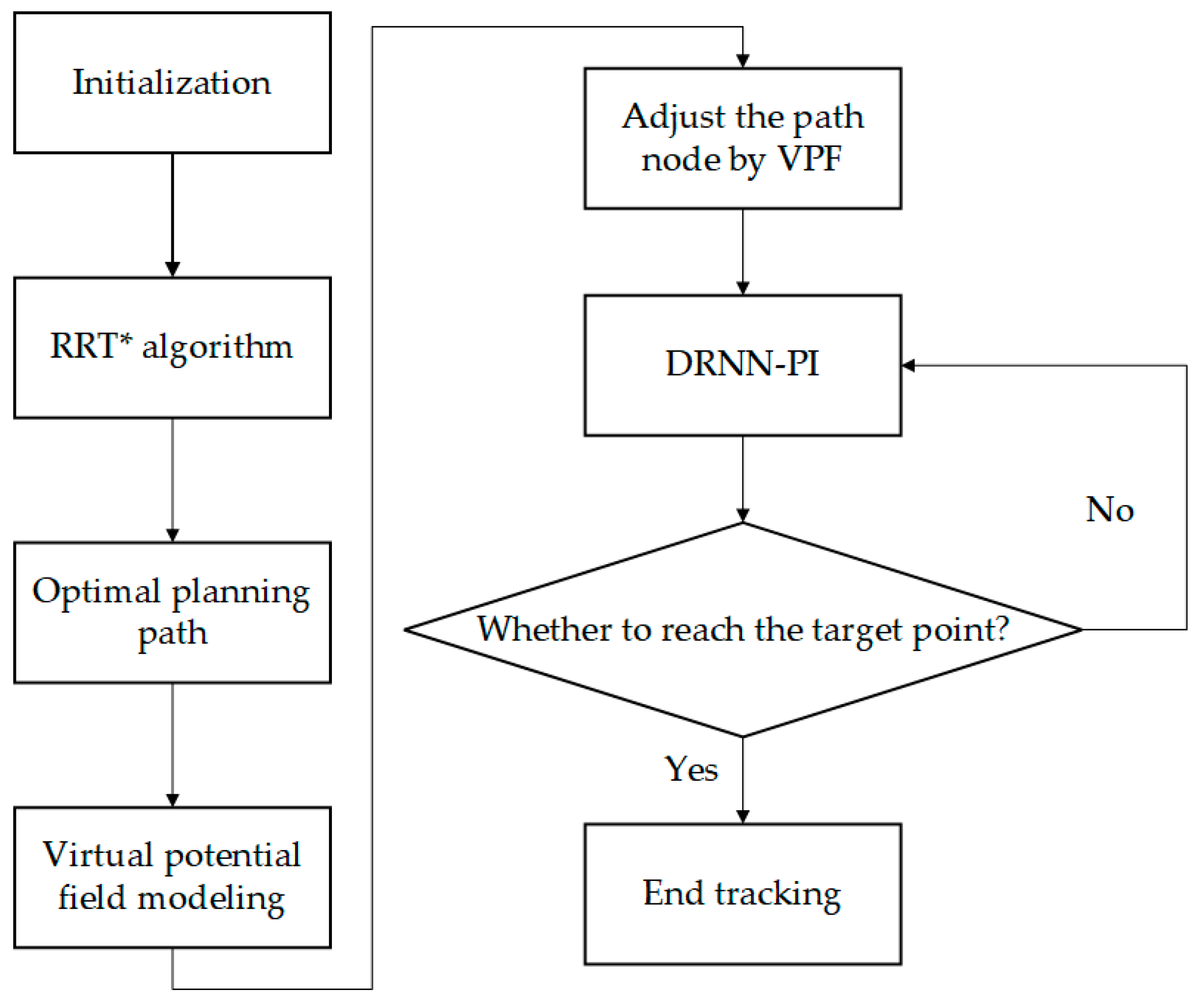
4. Materials and Methods
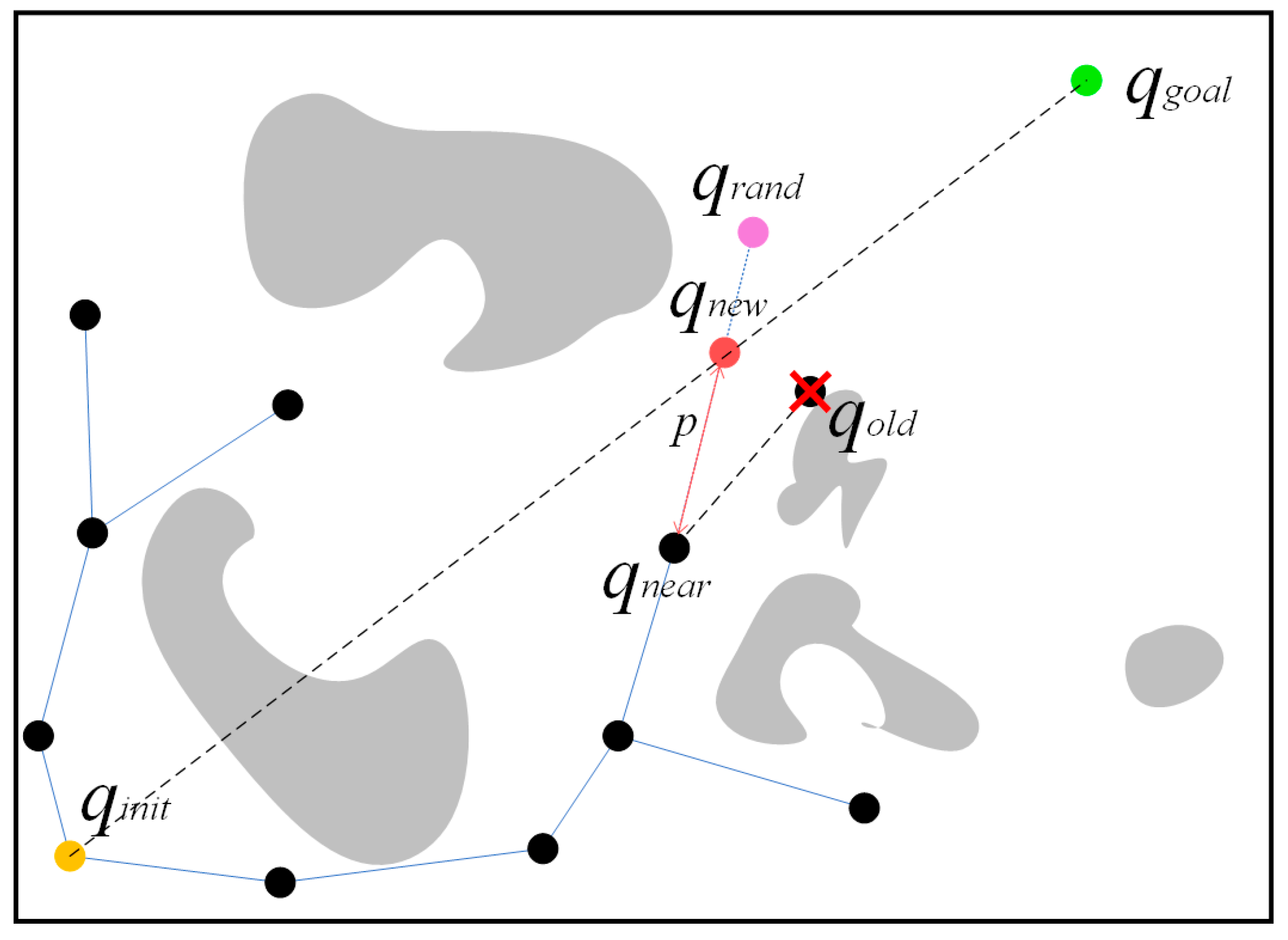
4.1. A Virtual Potential Field -RRT* Algorithm
| Algorithm 1: VPF-RRT* | |
| Step1: | T ← InitializeTree (T, qinit); |
| Step2: | For i = 1: n do |
| Step3: | qrand ← Sample (T, qgoal, M); |
| Step4: | qnear ← Nearest (T, qrand); |
| Step5: | End qnew ← Steer (qnear, qrand, p); |
| Step6: | qneighbor ← Findnearneighbor (T, qnew, M); |
| Step7: | if CollisionFree (qnew, T, M) then |
| Step8: | T ← Chooseparent (qnew, qneighbor, T); |
| Step9: | T ← Rewire (T, qnew, qneighbor); |
| Step10: | T ← (12); |
| Step11: | Return T; |
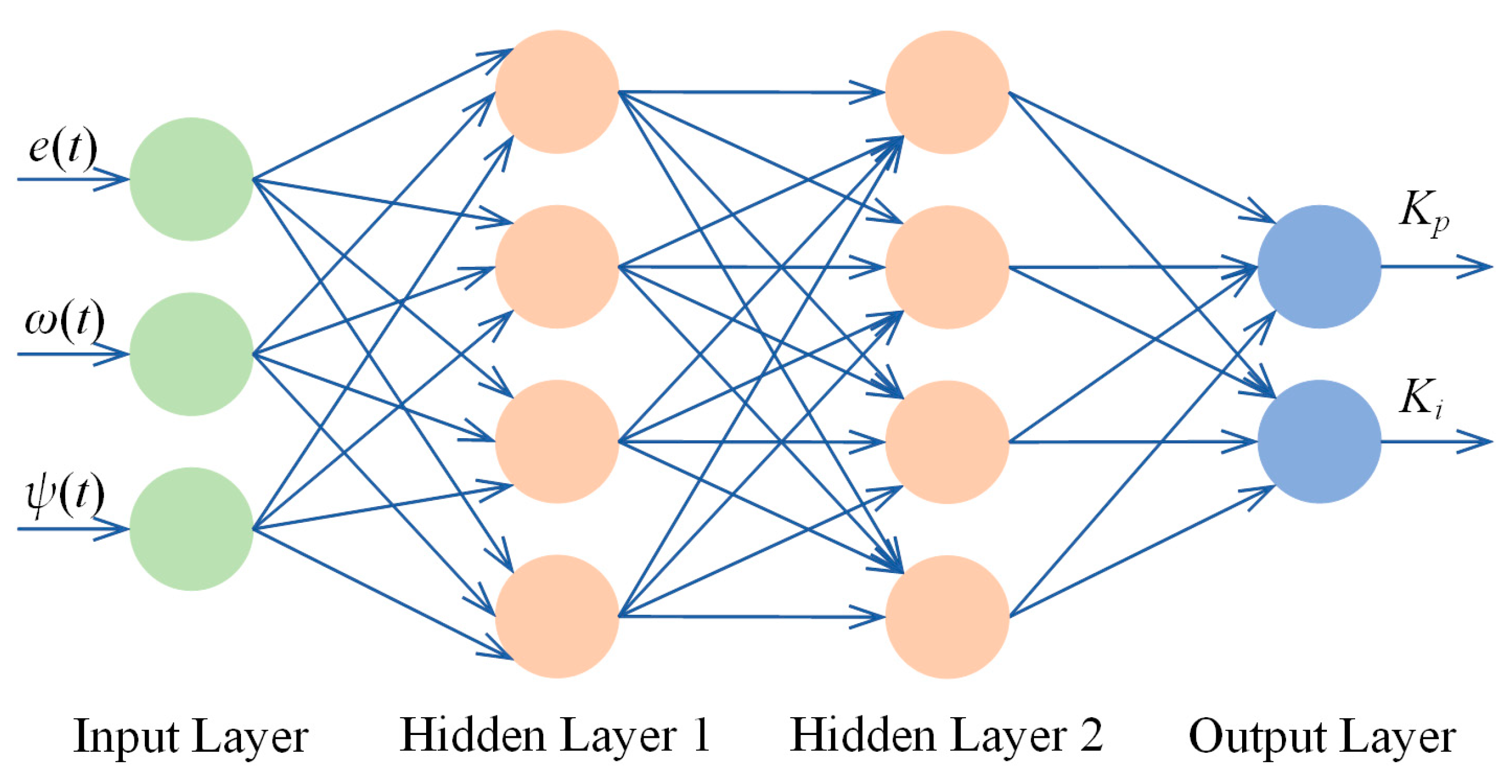
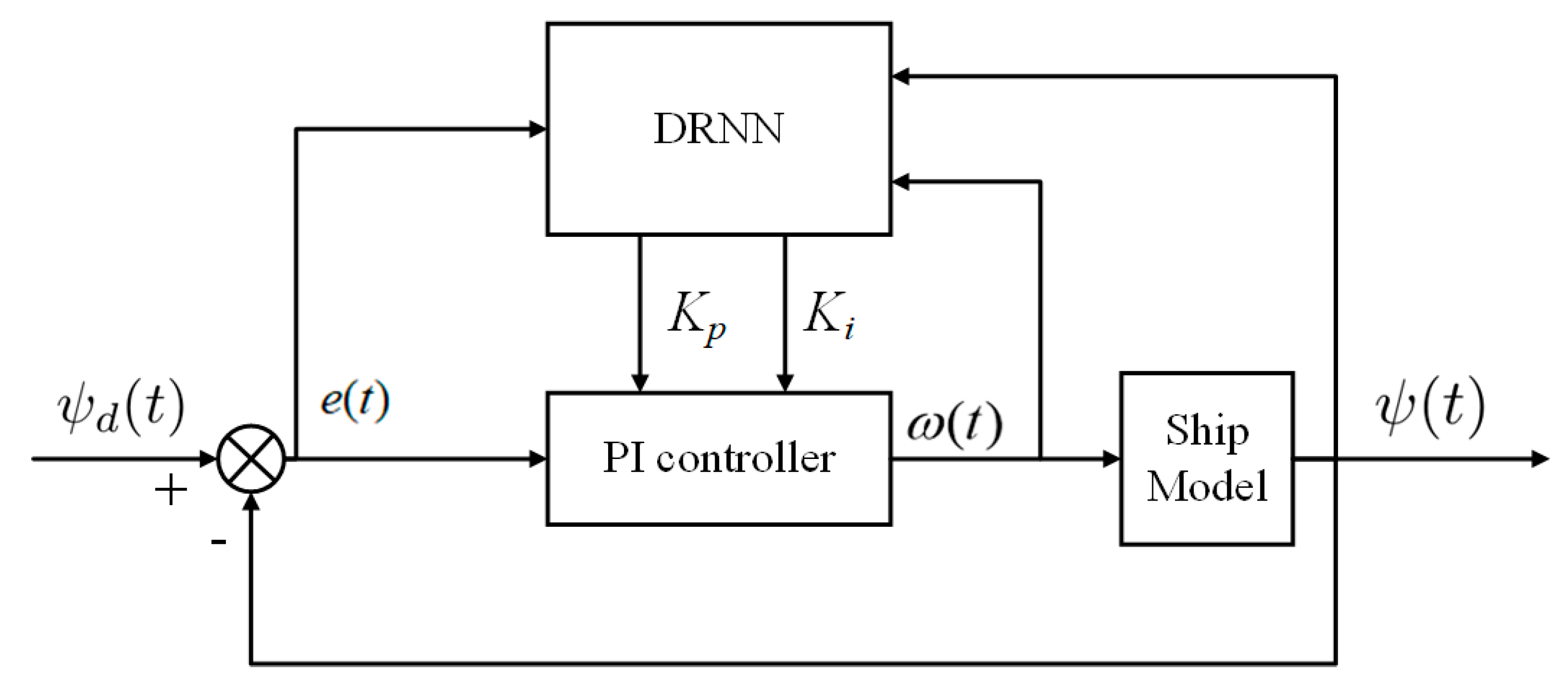
4.2. An Anti-Environmental Disturbance Method Based on DRNN-PI Controller
| Algorithm 2: DRNN-PI controller | |
| Step1: | Initialize parameters; |
| Step2: | α(t) ← (22); |
| Step3: | ψd(t) = α(t); |
| Step4: | Sample ψd(t) and ψ(t); |
| Step5: | ω(t) ← (23); |
| Step6: | The inputs of DRNN ←ψd(t), ψ(t), ω(t); |
| Step7: | The outputs of DRNN ←Kp, Ki; |
| Step8: | DRNN starts iterative learning; |
| Step9: | Return Kp and Ki; |
5. Simulation Experiment and Discussion
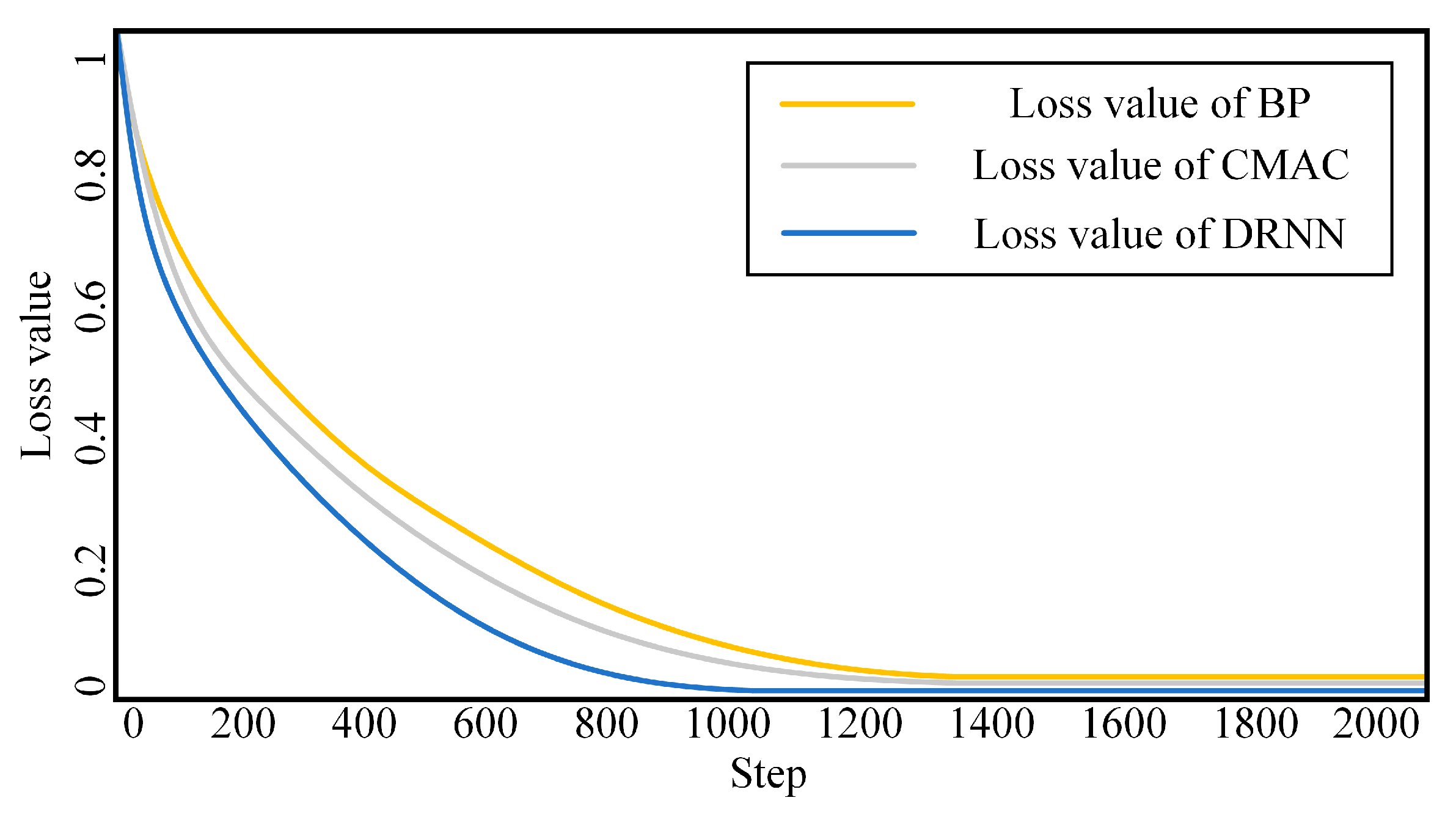
5.1. Simulation Experiment of Neural Network
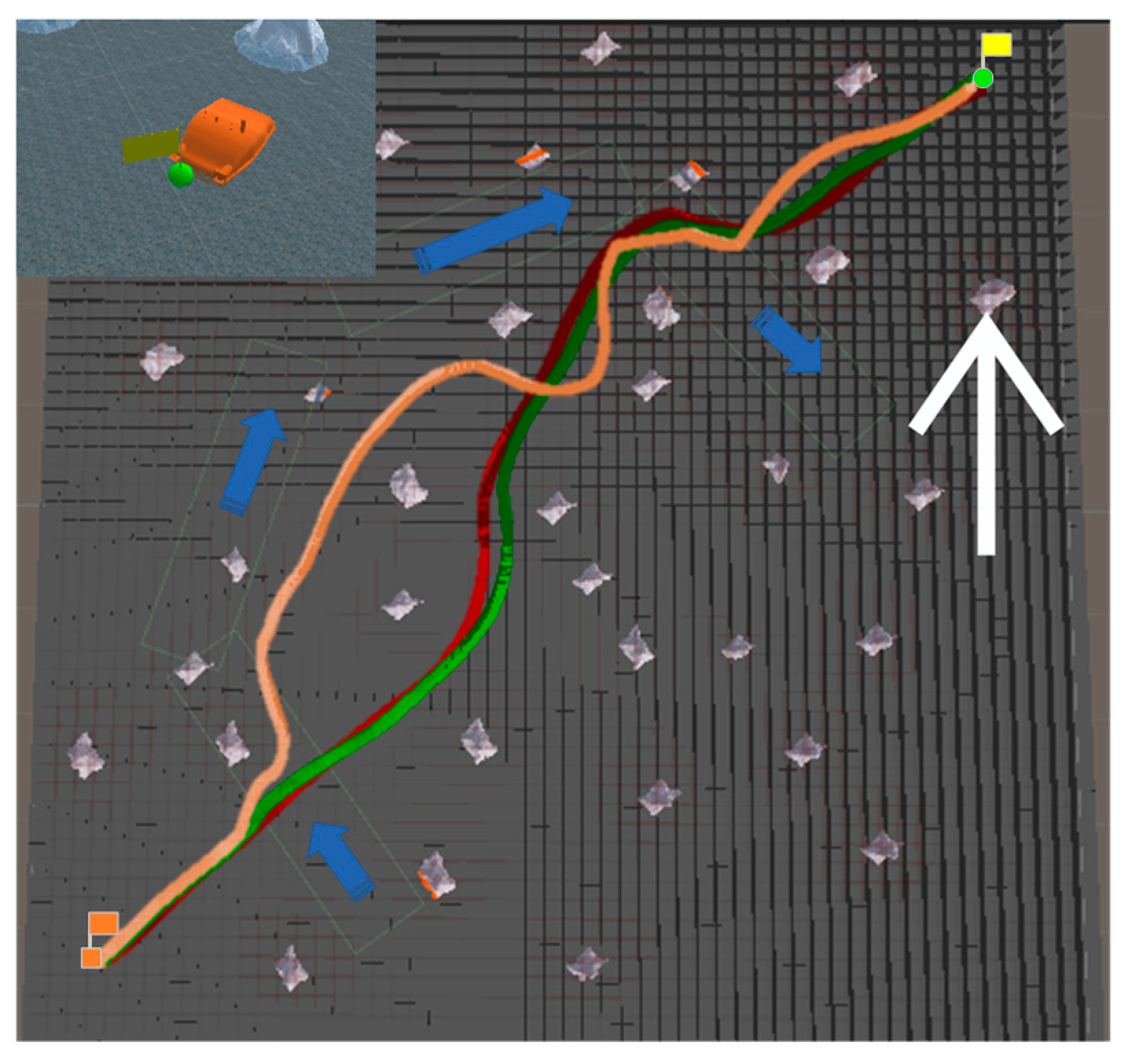
5.2. Simulation Experiment of Path Planning
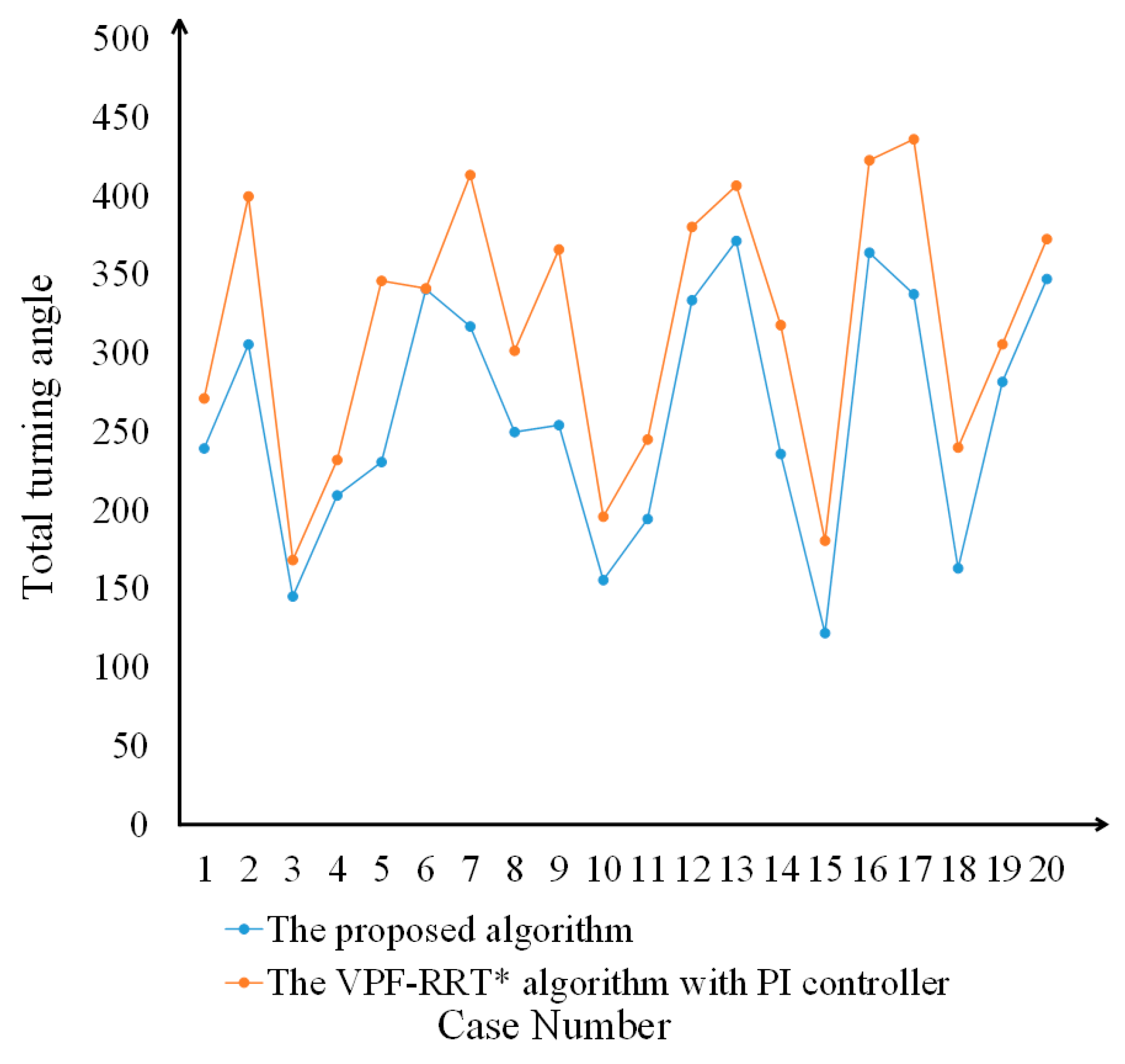
5.3. Simulation Experiment of Path Tracking
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Balampanis, F.; Maza, I.; Ollero, A. Area decomposition, partition and coverage with multiple remotely piloted aircraft systems operating in coastal regions. In Proceedings of the International Conference on Unmanned Aircraft Systems, Arlington, VA, USA, 7–10 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Acevedo, J.J.; Maza, I.; Ollero, A.; Arrue, B. An Efficient Distributed Area Division Method for Cooperative Monitoring Applications with Multiple UAVs. Sensors 2020, 20, 3448. [Google Scholar] [CrossRef]
- Chen, B.; Zhou, S.; Liu, H.; Ji, X.; Zhang, Y.; Chang, W.; Xiao, Y.; Pan, X. A Prediction Model of Online Car-Hailing Demand Based on K-means and SVR. J. Phys. Conf. Ser. 2020, 1670, 012034. [Google Scholar] [CrossRef]
- Yu, W.; Low, K.H.; Chen, L. Cooperative Path Planning for Heterogeneous Unmanned Vehicles in a Search-and-Track Mission Aiming at an Underwater Target. IEEE Trans. Veh. Technol. 2020, 69, 6782–6787. [Google Scholar]
- Xia, G.; Han, Z.; Zhao, B.; Liu, C.; Wang, X. Global Path Planning for Unmanned Surface Vehicle Based on Improved Quantum Ant Colony Algorithm. Math. Probl. Eng. 2019, 2019, 2902170. [Google Scholar] [CrossRef]
- Xie, S.; Wu, P.; Liu, H.; Yan, P.; Li, X.; Luo, J.; Li, Q. A novel method of unmanned surface vehicle autonomous cruise. Ind. Robot. 2016, 43, 121–130. [Google Scholar] [CrossRef]
- Felski, A.; Zwolak, K. The Ocean-Going Autonomous Ship-Challenges and Threats. J. Mar. Sci. Eng. 2020, 8, 41. [Google Scholar] [CrossRef] [Green Version]
- Yao, P.; Rui, Z.; Qian, Z. A Hierarchical Architecture Using Biased Min-Consensus for USV Path Planning. IEEE Trans. Veh. Technol. 2020, 69, 9518–9527. [Google Scholar] [CrossRef]
- Hamilton, W.; Tarik, N.; Moez, K.; Brahim, A.; Abdeltif, E. A survey of current challenges in partitioning and processing of graph-structured data in parallel and distributed systems. Distrib. Parallel Databases 2020, 38, 495–530. [Google Scholar]
- Bruce, H.; Tamara, G. Graph partitioning models for parallel computing. Parallel Comput. 2000, 26, 1519–1534. [Google Scholar]
- Tewodros, A.; Huawen, L.; Changjun, Z.; Abegaz, M.; Fantahun, B.; Hayla, N.; Yasin, H. Graph Computing Systems and Partitioning Techniques: A Survey. IEEE Access 2022, 10, 118523–118550. [Google Scholar]
- Moez, K. Improving Formal Verification and Testing Techniques for Internet of Things and Smart Cities. Mob. Netw. Appl. 2019, 1, 1–12. [Google Scholar]
- Matt, W.; Michael, F.; Neil, C.; Mike, J. Formal Methods for the Certification of Autonomous Unmanned Aircraft Systems. Int. Conf. Comput. Saf. Reliab. Secur. 2011, 6894, 228–242. [Google Scholar]
- Katharina, H.; Branka, S. Towards formal verification of IoT protocols: A Review. Comput. Netw. 2020, 174, 107233. [Google Scholar]
- Yu, J.; Liu, G.; Xu, J.; Zhao, Z.; Chen, Z.; Yang, M.; Wang, X.; Bai, Y. A Hybrid Multi-Target Path Planning Algorithm for Unmanned Cruise Ship in an Unknown Obstacle Environment. Sensors 2022, 22, 2429. [Google Scholar] [CrossRef]
- Yu, J.; Deng, W.; Zhao, Z.; Wang, X.; Xu, J.; Wang, L.; Sun, Q.; Shen, Z. A Hybrid Path Planning Method for an Unmanned Cruise Ship in Water Quality Sampling. IEEE Access 2019, 7, 87127–87140. [Google Scholar] [CrossRef]
- Yershov, D.; Lavalle, S. Simplicial Dijkstra and A* Algorithms: From Graphs to Continuous Spaces. Adv. Robot. 2012, 26, 2065–2085. [Google Scholar] [CrossRef]
- Zhu, X.; Yan, B.; Yue, Y. Path Planning and Collision Avoidance in Unknown Environments for USVs Based on an Improved D* Lite. Appl. Sci. 2021, 11, 7863. [Google Scholar] [CrossRef]
- Yu, J.; Yang, M.; Zhao, Z.; Wang, X.; Bai, Y.; Wu, J.; Xu, J. Path planning of unmanned surface vessel in an unknown environment based on improved D*Lite algorithm. Ocean Eng. 2022, 266, 112873. [Google Scholar] [CrossRef]
- Zhang, Q.; Song, X.; Yang, Y. Visual graph mining for graph matching. Comput. Vis. Image Underst. 2019, 178, 16–29. [Google Scholar] [CrossRef]
- Lan, W.; Jin, X.; Wang, T.; Zhou, H. Improved RRT Algorithms to Solve Path Planning of Multi-Glider in Time-Varying Ocean Currents. IEEE Access 2021, 9, 158098–158115. [Google Scholar] [CrossRef]
- Ni, J.; Wu, L.; Shi, P. A dynamic bioinspired neural network based real-time path planning method for autonomous underwater vehicles. Comput. Intell. Neurosci. 2017, 2017, 9269742. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Wang, J.; Xiao, S. Autonomous land vehicle path planning algorithm based on improved heuristic function of A-Star. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211042730. [Google Scholar] [CrossRef]
- Yu, J.; Hou, J.; Chen, G. Improved Safety-First A-Star Algorithm for Autonomous Vehicle. In Proceedings of the International Conference on Advanced Robotics and Mechatronics, Shenzhen, China, 18–21 December 2020. [Google Scholar]
- Verbari, P.; Bascetta, L.; Prandini, M. Multi-agent trajectory planning: A decentralized iterative algorithm based on single-agent dynamic RRT star. In Proceedings of the American Control Conference, 1977–1982, Philadelphia, PA, USA, 10–12 July 2019. [Google Scholar]
- Park, J.; Chung, T. Boundary-RRT* Algorithm for Drone Collision Avoidance and Interleaved Path Re-planning. J. Inf. Process. Syst. 2020, 16, 1324–1342. [Google Scholar]
- Li, G.; Li, Y.; Chen, H. Fractional-Order Controller for Course-Keeping of Underactuated Surface Vessels Based on Frequency Domain Specification and Improved Particle Swarm Optimization Algorithm. Appl. Sci. 2022, 12, 3139. [Google Scholar] [CrossRef]
- Wu, W.; Peng, Z.; Wang, D. Anti-disturbance leader–follower synchronization control of marine vessels for underway replenishment based on robust exact differentiators. Ocean Eng. 2022, 248, 110686. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, X.; Peng, X. An anti-vibration-shock inertial matching measurement method for hull deformation. IET Signal Process. 2022, 16, 490–500. [Google Scholar] [CrossRef]
- Zhang, H.; Wei, X.; Wei, Y. Anti-disturbance control for dynamic positioning system of ships with disturbances. Appl. Math. Comput. 2021, 396, 125929. [Google Scholar] [CrossRef]
- Peng, Z.; Liu, L.; Wang, J. Output-Feedback Flocking Control of Multiple Autonomous Surface Vehicles Based on Data-Driven Adaptive Extended State Observers. IEEE Trans. Cybern. 2021, 51, 4611–4622. [Google Scholar] [CrossRef]
- Yao, B.; Yang, J.; Zhang, Q. Research and Comparison of Automatic Control Algorithm for Unmanned Ship. In Proceedings of the International Conference on Control and Robotics Engineering, Nagoya, Japan, 20–23 April 2018; pp. 85–89. [Google Scholar]
- Xu, N.; Chen, Y.; Xue, A. Backstepping-Based Controller Design for Uncertain Switched High-Order Nonlinear Systems via PI Compensation. IEEE Trans. Syst. Man Cybern.-Syst. 2022, 52, 7810–7820. [Google Scholar] [CrossRef]
- Touzout, W.; Benmoussa, Y.; Benazzouz, D. Unmanned surface vehicle energy consumption modelling under various realistic disturbances integrated into simulation environment. Ocean Eng. 2021, 222, 108560. [Google Scholar] [CrossRef]
- Li, Y.; Wei, W.; Gao, Y.; Wang, D.; Fan, Z. PQ-RRT*: An improved path planning algorithm for mobile robots. Expert Syst. Appl. 2020, 152, 113425. [Google Scholar] [CrossRef]
- Bisandu, D.; Moulitsas, I.; Filippone, S. Social ski driver conditional autoregressive-based deep learning classifier for flight delay prediction. Neural Comput. Appl. 2022, 34, 8777–8802. [Google Scholar] [CrossRef]
- Razmjooei, H.; Palli, G.; Anabi-Sharifi, F.; Alirezaee, S. Adaptive fast-finite-time extended state observer design for uncertain electro-hydraulic systems. Eur. J. Control 2022, 69, 100749. [Google Scholar] [CrossRef]
- Razmjooei, H.; Palli, G.; Abdi, E. Continuous finite-time extended state observer design for electro-hydraulic systems. J. Frankl. Inst. 2022, 359, 5036–5055. [Google Scholar] [CrossRef]
- Razmjooei, H.; Palli, G.; Nazari, M. Disturbance observer-based nonlinear feedback control for position tracking of electrohydraulic systems in a finite time. Eur. J. Control 2022, 67, 100659. [Google Scholar] [CrossRef]
- Razmjooei, H.; Palli, G.; Abdi, E.; Strano, S.; Terzo, M. Finite-time continuous extended state observers: Design and experimental validation on electro-hydraulic systems. Mechatronics 2022, 85, 102812. [Google Scholar] [CrossRef]
- Duan, K.; Fong, S.; Chen, C.L.P. Reinforcement learning based model-free optimized trajectory tracking strategy design for an AUV. Neurocomputing 2022, 469, 289–297. [Google Scholar] [CrossRef]
- Woo, J.; Chanwoo, Y.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Path Smoothing | Increase of Efficiency |
|---|---|---|
| Autonomous land vehicle path-planning algorithm based on improved heuristic function of A-Star [23] | Yes | / |
| Improved safety-first A-star algorithm for autonomous vehicle [24] | Yes | / |
| Multiagent trajectory planning: A decentralized iterative algorithm based on single-agent dynamic RRT star [25] | / | Yes |
| Boundary-RRT* algorithm for drone collision avoidance and interleaved path replanning [26] | / | Yes |
| Algorithm | Improve Anti-Interference Capability | Increase Flexibility |
|---|---|---|
| Fractional-order controller for course-keeping of underactuated surface vessels based on frequency domain specification and improved particle swarm optimization algorithm [27] | Yes | / |
| Antidisturbance leader–follower synchronization control of marine vessels for underway replenishment based on robust exact differentiators [28] | Yes | / |
| An antivibration-shock inertial matching measurement method for hull deformation [29] | Yes | / |
| Antidisturbance control for dynamic positioning system of ships with disturbances [30] | Yes | / |
| Output-feedback flocking control of multiple autonomous surface vehicles based on data-driven adaptive extended state observers [31] | Yes | / |
| Research and comparison of automatic control algorithm for unmanned ship [32] | / | Yes |
| Backstepping-based controller design for uncertain Switched high-order nonlinear systems via pi compensation [33] | / | Yes |
| Parameters | Definition | Numerical Value |
|---|---|---|
| u (m/s) | Forward speed of USV | 10 |
| Ffront (N) | Forward force of USV | 30 |
| r (rad/s) | Maximum angular velocity of USV | 0.3 |
| R (m) | Minimum turning radius of USV | 3 |
| a (m) | x-axis radius of obstacle | 8 |
| b (m) | y-axis radius of obstacle | 8 |
| q | x-axis gain of obstacle | 1.5 |
| p | y-axis gain of obstacle | 1.5 |
| Rs (m) | Safety range of USV | 6 |
| Fmax (N) | Maximum disturbing force of USV | 10 |
| B | Inertia coefficient | 8 |
| η | Repulsion coefficient | 6 |
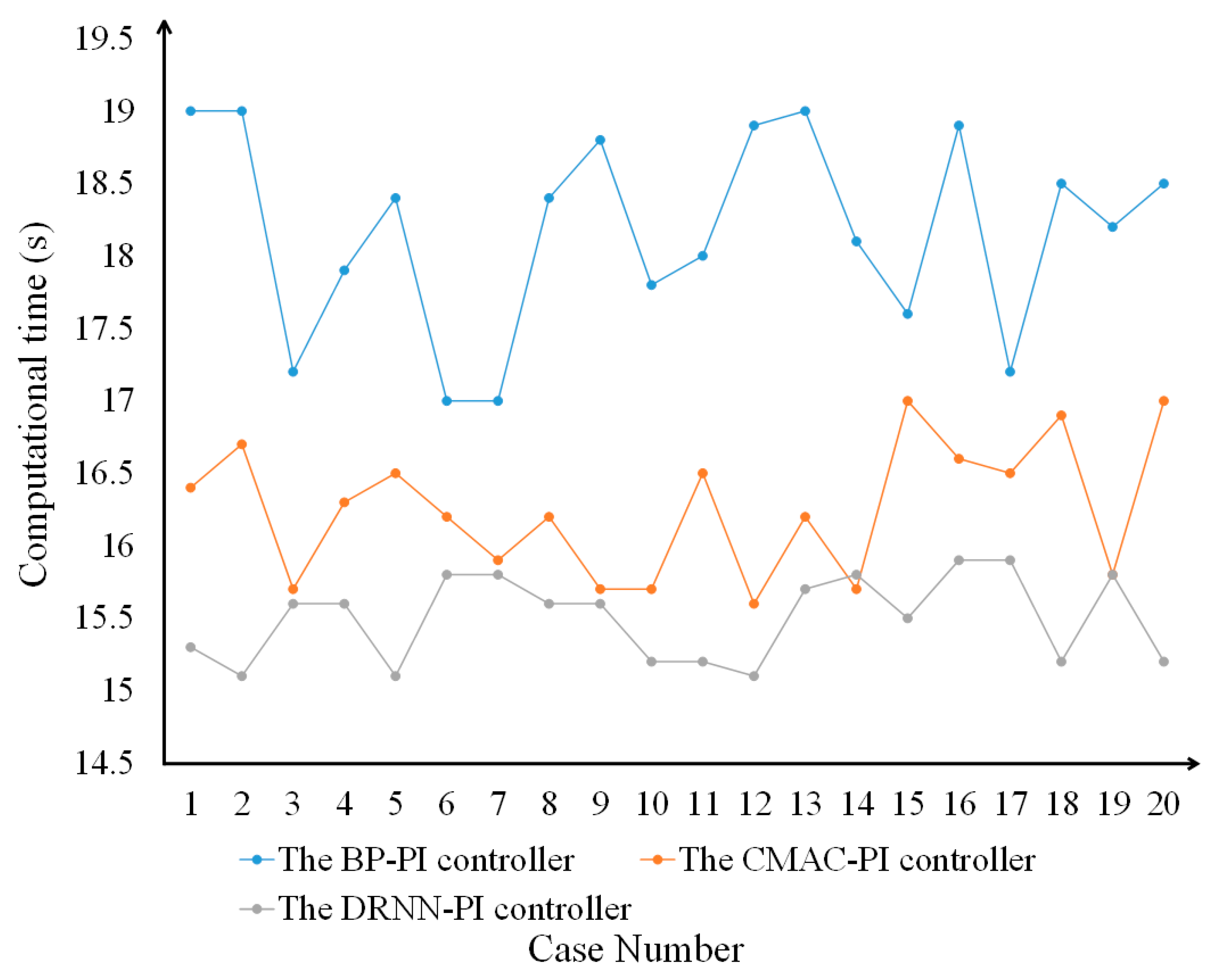
| Algorithm | RMSE | MRE | Loss | Computational Time (s) |
|---|---|---|---|---|
| BP-PI | 7.3519 | 12–14% | 0.0396 | 18.5181 |
| CMAC-PI | 6.5987 | 8–11% | 0.0287 | 16.2566 |
| DRNN-PI | 5.9182 | 7–9% | 0.0211 | 16.3271 |
| Algorithm Name | Path Length (m) | Total Turning Angle | Computational Time (s) | Sailing Time (s) | Normalization Index |
|---|---|---|---|---|---|
| RRT* with PI controller | 1710.15182 | 161°3752′ | 22.15748 | 182.54843 | 1.43525 |
| B-spline curve-RRT* with PI controller | 1952.94236 | 286°1475′ | 26.22971 | 201.21855 | 1.63901 |
| VPF-RRT* with PI controller | 1623.07952 | 89°1398′ | 22.87613 | 178.33216 | 1.36217 |
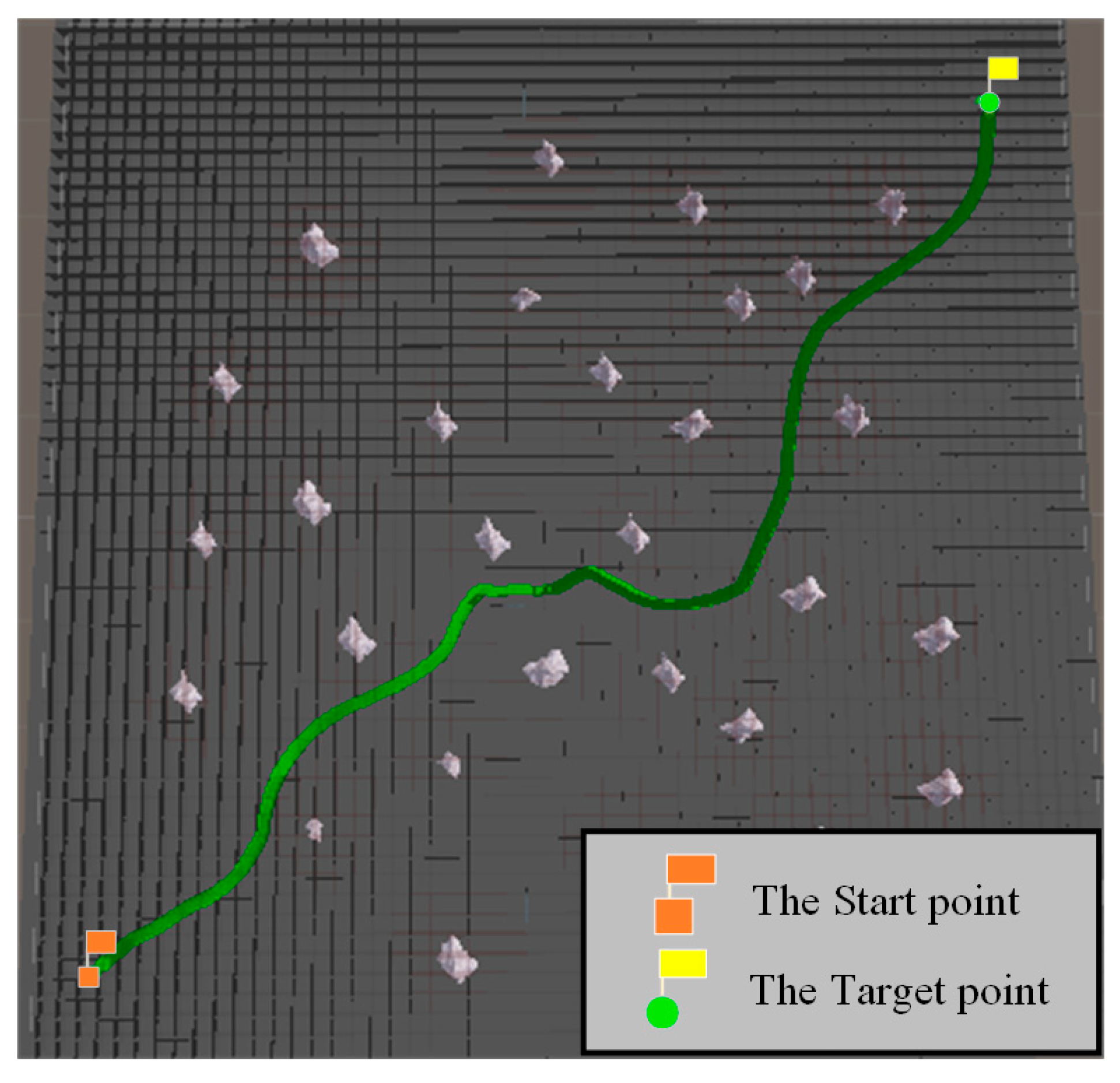
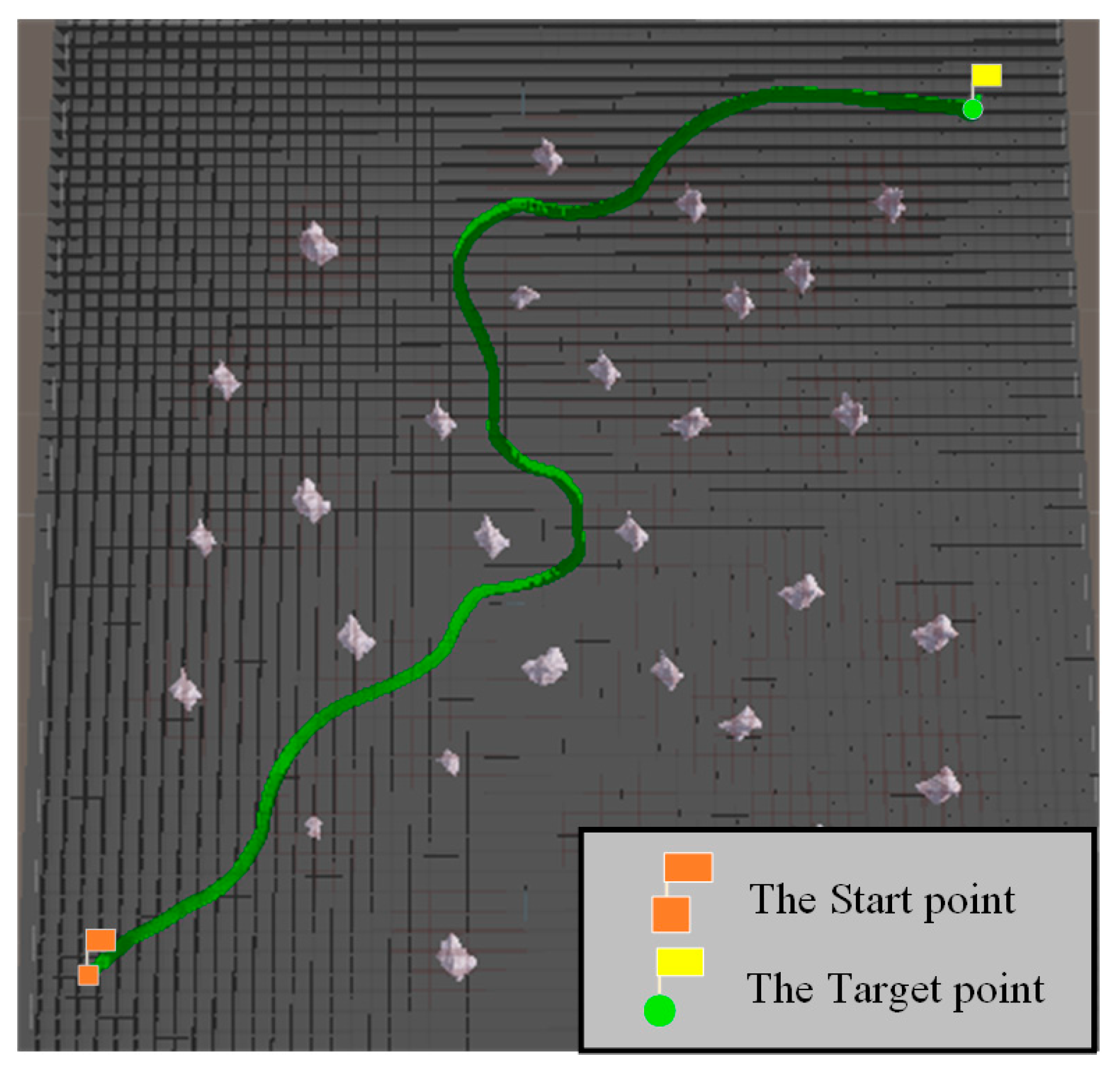
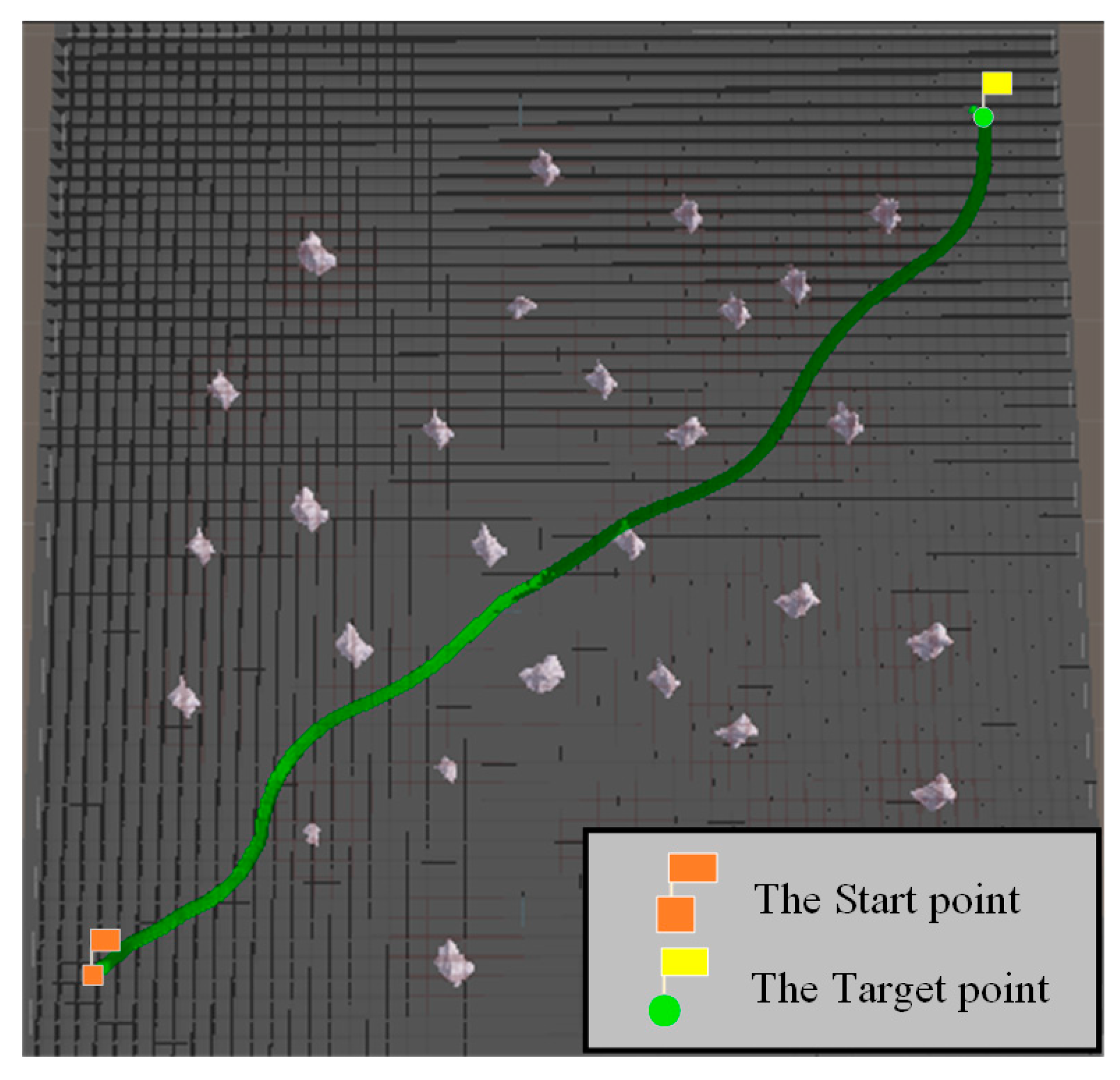
| Start and Target | Algorithm Name | Path Length (m) | Total Turning Angle | Computational Time (s) | Sailing Time (s) | Normalization Index |
|---|---|---|---|---|---|---|
| (−94, −27) (347, −451) | RRT* algorithm with PI controller | 725.15104 | 45°1268′ | 13.20158 | 90.12177 | 1.11500 |
| B-spline curve-RRT* with PI controller | 816.20583 | 50°3288′ | 14.98402 | 99.37544 | 1.25501 | |
| VPF-RRT* algorithm with PI controller | 709.13587 | 44°1534′ | 13.81035 | 87.79353 | 1.09037 | |
| (400, 400) (−400,−400) | RRT* algorithm with PI controller | 1634.98075 | 109°8418′ | 20.56508 | 171.34998 | 1.44513 |
| B-spline curve-RRT* with PI controller | 2120.18598 | 302°9211′ | 26.30054 | 219.44503 | 1.87399 | |
| VPF-RRT* algorithm with PI controller | 1568.27831 | 105°7518′ | 18.60874 | 168.47056 | 1.38617 | |
| (400, −400) (−400, 400) | RRT* algorithm with PI controller | 1612.83788 | 141°4894′ | 19.32007 | 182.21533 | 1.42556 |
| B-spline curve-RRT* with PI controller | 1984.33276 | 291°0233′ | 24.11328 | 203.55983 | 1.75391 | |
| VPF-RRT* algorithm with PI controller | 1567.15489 | 134°4537′ | 18.83021 | 177.00357 | 1.38518 |
| Parameters | Definition | Numerical Value |
|---|---|---|
| Fwind (N) | Disturbing force of wind | 1 |
| Fwave (N) | Disturbing force of wave | 15 |
| vwind (m/s) | Velocity vector of wind | 0.1 |
| vwave (m/s) | Velocity vector of wave | 3 |
| Algorithm Name | Navigating Time (s) | Navigating Length (m) | Total Turning Angle |
|---|---|---|---|
| The VPF-RRT* algorithm with PI controller | 71.18744 | 1664.6812 | 381°0250′ |
| The proposed algorithm | 62.86429 | 1598.489 | 206°7511′ |
| Start and Target Point | Algorithm Name | Navigating Time (s) | Navigating Length (m) | Total Turning Angle |
|---|---|---|---|---|
| (420, −50) (−400, 0) | The VPF-RRT* algorithm with PI controller | 52.15899 | 1040.41123 | 159°3235′ |
| The proposed algorithm | 43.70968 | 1009.45018 | 120°9144′ | |
| (400, 400) (−400, −400) | The VPF-RRT* algorithm with PI controller | 73.15134 | 1632.12661 | 327°4137′ |
| The proposed algorithm | 59.08492 | 1601.4809 | 291°1008′ | |
| (400, 400) (−44, −131) | The VPF-RRT* algorithm with PI controller | 64.15184 | 1303.02153 | 186°5998′ |
| The proposed algorithm | 41.21003 | 927.60188 | 154°3234′ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Yu, J.; Zhao, Z.; Wang, X.; Chen, Y. A Path-Planning Method Considering Environmental Disturbance Based on VPF-RRT*. Drones 2023, 7, 145. https://doi.org/10.3390/drones7020145
Chen Z, Yu J, Zhao Z, Wang X, Chen Y. A Path-Planning Method Considering Environmental Disturbance Based on VPF-RRT*. Drones. 2023; 7(2):145. https://doi.org/10.3390/drones7020145
Chicago/Turabian StyleChen, Zhihao, Jiabin Yu, Zhiyao Zhao, Xiaoyi Wang, and Yang Chen. 2023. "A Path-Planning Method Considering Environmental Disturbance Based on VPF-RRT*" Drones 7, no. 2: 145. https://doi.org/10.3390/drones7020145