1. Introduction
Global food demand is projected to surge by a significant margin of 35% to 56% from 2010 to 2050 [
1]. However, the expansion of industrialization, desertification and urbanization has led to a reduction in the crop production area and, hence, productivity of food [
2]. In addition to these challenges, climate change is increasingly creating favorable conditions for pests such as insects and weeds, harming crops [
3]. Therefore, crop quality and quantity will be affected by insects and weeds if the appropriate treatment is not devised in a timely manner. Traditionally, herbicides and pesticides have been employed as a means of control [
4]. When these herbicides are sprayed throughout entire fields without making precise identification of weeds, such an application of herbicides, while serving its purpose, results in a detrimental impact on both crop yield and the environment. While they effectively combat pests and diseases that threaten crops, their use can lead to reduced agricultural productivity due to their excessive use where no weeds are present [
5]. Therefore, it is essential to precisely identify the weeds vs. crops, so that cultivated plants can be saved from pesticide harm. As such, there is a requirement for a method of weed management that can gather and assess weed-related data within the agricultural field, while also taking appropriate measures to effectively regulate weed growth on farms [
6].
Remote sensing (RS)-based approaches can be an alternative for automated weed detection using satellite imagery [
7]. However, the success of satellite-based RS in weed detection is significantly influenced by three major limitations. First, the satellites acquire images with spatial resolutions measured in meters (e.g., Landsat at 30 m and Sentinel at 10 m), which is generally insufficient for analyzing plant- or individual plot-level weed data. Moreover, the fixed schedule of satellite revisits may not align with the timing needed to capture essential crop field images. Additionally, environmental factors like cloud cover frequently hinder the dependable quality of these images.
Recently, the Unmanned Aerial Vehicle (UAV) has made significant progress in its design and capability, including payload flexibility, communication and connectivity, navigation and autonomy, speed and flight time, etc. [
8]. It offers versatile revisiting capabilities, allowing farmers/researchers to deploy it when weather conditions permit, ensuring frequent image capture (thus achieving high temporal resolution). Moreover, UAVs can capture images with remarkable spatial detail, closely observing individual plants from an elevated perspective, leading to centimeter-level image resolutions. Additionally, by flying at lower altitudes, UAVs can bypass cloud cover, obtaining clear and high-quality images [
9]. Combined with the high-resolution crop field images acquired with UAV, semantic segmentation methods based on deep learning (DL) can provide a promising method for precise weed detection.
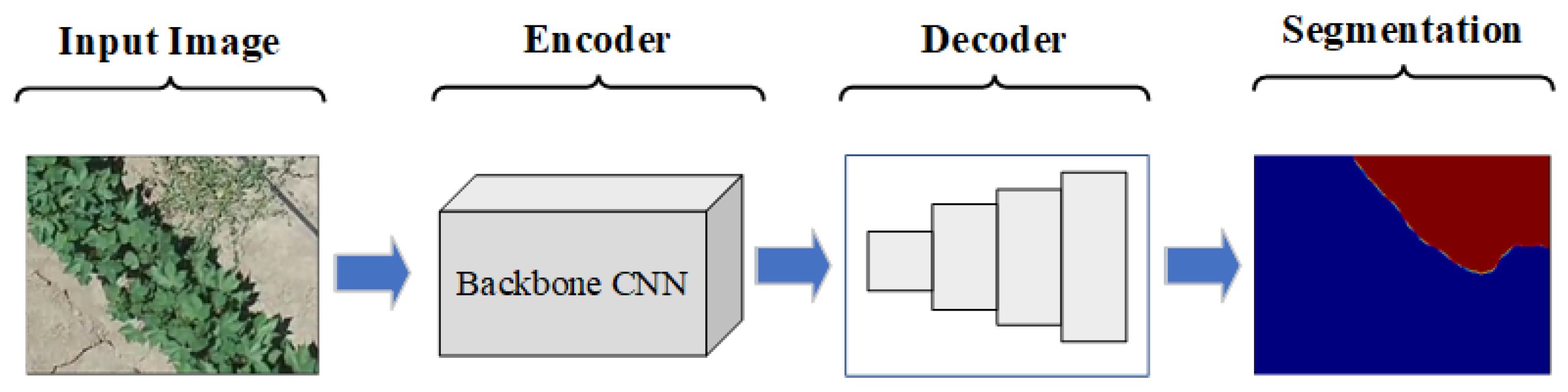
Semantic segmentation (SS) in computer vision is a pixel-level classification task that has revolutionized various fields, such as medical image segmentation [
10,
11] and precision agriculture (PA) [
12]. For instance, Liu et al. [
11] utilized the segmentation of retinal images to help diagnose and treat retinal diseases. In the PA domain, SS has been adopted for different problems such as agricultural field boundary segmentation [
12], agricultural land segmentation [
13], diseased vs. healthy plant detection [
14] and weed segmentation [
15]. Weed segmentation, which helps to identify unnecessary plants disturbing the growth of crops, is considered one of the major areas that directly contribute to improving crop productivity.
Over recent years, SS has gained significant attraction in the weed detection area of PA. Computer vision techniques that utilize image processing and machine learning methods for weed detection are widely investigated in the literature [
16,
17,
18]. However, deep learning methods for SS have shown state-of-the-art (SOTA) results for image segmentation tasks in general. The availability of pre-trained deep neural networks on large datasets such as ImageNet [
19] made it possible to transfer cross-domain knowledge to agriculture field images. For instance, convolutional neural networks (CNNs) such as DeepLab [
20], UNet [
21] and SegNet [
22] are implemented for weed detection on various crop fields. The performance of these neural networks depends on multiple factors, such as the resolution of images, types of crops and field conditions. Since the colour and texture of weeds are very similar to crops, it is a complex problem to make a differentiation between crops and weeds. Furthermore, if more than one type of weed is present in the field, it becomes more challenging to segment such regions.
A few researchers attempted to perform a thorough review and bench-marking of weed detection and segmentation tasks using computer vision and machine learning techniques [
23,
24]. For instance, Li et al. [
23] evaluated the performance of various deep learning methods such as Faster RCNN [
25], YOLO [
26] and CenterNet [
27] for weed detection on publicly available datasets. Additionally, Fathipoor et al. [
24] experimented with UNet and its variation for weed segmentation using ground-based RGB images. They achieved an IoU score of 56% with UNet++. Since most of these research works dealt with ground-based RGB images, it is still essential to explore the comparative study of DL methods for weed segmentation using UAV-based RGB images. Despite significant advancements in SS for weed detection, it has the following limitations. First, the existing works lack rigorous comparison to identify the optimal deep learning (DL)-based model for weed segmentation. Second, the performances of these DL-based models are dependent on the use of various CNNs as feature extractors, the number of training images available and the type of regions that need to be segmented or identified. As a result, it might be essential to apply some data augmentation techniques for the effective training of such a DL-based segmentation model when using various backbone CNNs as feature extractors.
Considering the aforementioned limitations, we conduct a detailed comparative study of DL models being used for weed detection and identify the best-performing model in the field. We also evaluate the performance of such SOTA models on a UAV dataset that is publicly available for weed segmentation. In summary, the main contributions of this paper are as follows:
- (i)
The comprehensive implementation of five backbone CNNs with three segmentation models for weed detection is achieved. For this, we utilize the patch-based data augmentation method for model building.
- (ii)
The performance comparison of five well-established CNNs as feature extractors employed with three segmentation models is reported. For this, we experiment with two strategies: binary segmentation (weed vs. non-weed) and multi-class segmentation (three classes of weed and non-weed).
- (iii)
A DL-based method is implemented for weed segmentation using the best-performing backbone CNN and segmentation model.
- (iv)
The effect of data augmentation techniques on the learning curve of the DL-based segmentation model while training is compared and reported.
The remainder of the paper is organized as follows:
Section 2 presents a literature review, highlighting the summary of the existing works.
Section 3 discusses the materials and methods used in this study.
Section 4 presents the results and discussion, and
Section 5 concludes the paper with future recommendations.
2. Related Work
Owing to the recent advancement in drone and sensor technology, the research on weed detection using DL methods has been swiftly progressing. For instance, a CNN was implemented by Dos et al. [
15] for weed detection using aerial images. They acquired soybean (
Glycine max) field images in Brazil with a drone and created a database of more than 1500 images including images of the soil, soybeans, broad-leaf and grass weeds. A classification accuracy of 98% was achieved using ConvNet while detecting the broadleaf and grass weeds. However, their approach employed the classification of whole images into different categories for weed detection rather than the segmentation of image pixels into various classes. Similarly, a CNN was implemented for weed mapping in Sod production using aerial images by Zhang et al. [
28]. They first processed the UAV images using Pix4DMapper and produced an orthomosaic of the agricultural field. Then, the orthomosaic was divided into smaller image tiles. A CNN was built with an image size of (
) as input. The CNN achieved a maximum precision of 0.87, 0.82, 0.83, 0.90 and 0.88 for broadleaf, grass weeds, spurge (
Euphorbia spp.), sedges (
Cyperus spp.) and no weeds, respectively. Ong et al. [
29] performed weed detection on a Chinese cabbage field using UAV images. They adapted AlexNet [
30] to perform weed detection and compared its performance with traditional machine learning classifiers such as Random forest [
31]. The results showed that CNN achieved the highest accuracy of 92.41%, which was 6% higher than that of Random forest. A lightweight deep learning framework for weed detection in soybean fields was implemented by Razfar et al. [
32] using MobileNetV2 [
33] and ResNet50 [
34] networks.
Aside from the single-stage CNNs, few works have been reported that use multi-stage pipelines for weed detection on UAV images. For instance, Bah et al. [
35] implemented a three-step method for weed detection on spinach and bean fields using UAV images. First, they detected the crop rows using the Hough transform [
36] technique; then, the weeds between these crop rows were used as training samples where a CNN was trained to detect the crop and weed in the UAV images. However, their proposal depends on the accuracy of the line detection technique, which might not be robust when the UAV images contain varying backgrounds and image contrast. A two-stage classifier for weed detection in tobacco crops was implemented in [
37]. Here, they first segmented the background pixel from the vegetation pixels which included both weed as well as tobacco pixels. Then, a three-class image segmentation model was implemented. Their proposal achieved the maximum Intersection of Union (IoU) of 0.91 for weed segmentation. However, the two-stage segmentation model requires separate training at each stage, and hence it is not possible to train the model in an end-to-end fashion, adding extra complexity to its deployment.
Object detection approaches such as single shot detector (SSD) [
38], Faster RCNN [
39] and YOLO [
40] were also employed for weed detection using UAV images. For instance, Veeranampalayam et al. [
38] compared two object detectors, namely, Faster RCNN and SSD, for weed detection using UAV images. The InceptionV2 [
41] model was used for feature extraction in both detectors (Faster RCNN and SSD). The comparison revealed that Faster RCNN models produced a higher accuracy as well as less inference time for weed detection.
The segmentation of images into weed and non-weed regions at the pixel level is more precise and can be beneficial for the accurate application of pesticides. Xu et al. [
20] combined the visible color index with a DL-based segmentation model for weed detection in soybean fields. They first generated the visible color index image for each UAV image and fed it into a DL-based segmentation model which utilized the DeeplabV3 [
42] network. When comparing its performance with other SOTA segmentation architectures such as fully convolutional neural network (FCNN) [
43] and UNet [
44], it provided an accuracy of 90.50% and an IoU score of 95.90% for weed segmentation.
4. Results and Discussion
4.1. Performance Comparison of Different DL-Based Models for Binary Segmentation
In this section, we present the outcomes of the weed vs. background segmentation task. Since this task exhibits relatively lower complexity, all segmentation models based on DL yielded commendable performance.
The performance of the majority of the models (combination of backbone CNNs plus segmentation models) on both datasets D1 and D2 are similar, which shows that the data augmentation technique has no significant effect on the binary segmentation task (see
Table 3). For instance, the highest performing model (DenseNet121 + SegNet) has a mean IoU score of 67.56% on D2 (with augmentation) and 67.12% on D1 (without augmentation). Similar results are seen for other combinations of backbone CNNs and segmentation models (SegNet, UNet and DeepLabV3), except for VGG16. In this case, UNet with VGG16 as a backbone improves its mean IoU score of 54.54% to 64.22% when the data augmentation technique is utilized.
Upon evaluating the backbone CNNs without employing augmentation (D1), both ResNet50 and DenseNet121 yield a mean IoU score exceeding 60% across all three segmentation models (SegNet, UNet and DeepLabV3+). Among these three segmentation models, SegNet achieves the highest mean IoU score of 67.12% when paired with DenseNet121. It also demonstrates competitive results with a mean IoU score of 66.85% for EfficientNetB0, 65.85% for ResNet50 and 63.50% for VGG16, except for MobileNetV2. In this case, UNet outperforms all other models, attaining a mean IoU score of 67.07%. Comparing the results of backbone CNNs on the augmented dataset (D2), DenseNet121 and EfficientNetB0 produce the highest mean IoU score of 67.56% and 67.24% when combined with the SegNet model, respectively, whereas MobineNetV2 with UNet shows a competitive performance (mean IoU score of 67.07%).
Regarding accuracy comparison, the SegNet model with both DenseNet121 and EfficintNetBO as backbones achieves the highest accuracy, surpassing 88%. Notably, the DeepLabV3+ model with VGG16 as its backbone displays the lowest performance. This disparity in performance might be attributed to the limited availability of training data for the models.
4.2. Comparative Study of DL-Based Models for Multi-Class Segmentation
The results of the multi-class segmentation task are discussed. Since this task aims to segment the image region into four classes, including three types of weed and background, it is really challenging to distinguish each pixel from one class to another class for most of the segmentation models. Distinguishing the weed classes is considerably complex due to the resemblances in texture, color and patterns exhibited by distinct types of weeds. This similarity substantially contributes to the challenges encountered in effectively categorizing these diverse weed species.
For the multi-class task, the performance of the majority of the models is increased with data augmentation. For instance, EfficientNetB0 combined with UNet produces a mean IoU of 56.21%, whereas its mean IoU is only 51.97% when data augmentation is not applied (see
Table 4).
Among the three segmentation models, UNet with EfficientNetB0 produces the highest mean IoU of 56.21%. It is noted that UNet performed well with other backbone CNNs as compared with SegNet and DeepLabV3+. For instance, the mean IoU of UNet with DenseNet121 is 56.09%, which is the second-highest performance among the compared models.
Comparing the performance of five backbone CNNs, ResNet50, DenseNet121 and EfficientNetB0 achieve a mean IoU score of above 50% when combined with UNet and SegNet on both datasets (D1 and D2). MobileNetV2 combined with DeepLabV3+ has a mean IoU of 32.56% for D1 and 33.06% for D2.
It is observed that DenseNet121 with SegNet performs the best for the binary task, whereas EfficieentNetBo with UNet achieves the best performance for the multi-class task. However, the combination of other backbone CNN and segmentation models also yields a similar performance for the binary task. It might be attributed to the relatively lower complexity associated with the binary segmentation problem, where all models are able to discriminate between the background (also includes the crops) and weeds. In comparison, the multi-class segmentation task is more challenging as it has higher intra-classes similarity between the different types of weeds. Since UNet [
4] transfers the entire feature from encoder to decoder, they might help discriminate the multiple weed classes for multi-class segmentation. This is further supported by the consistently higher performance of UNet in the majority of backbone CNNs for the multi-class segmentation task (refer to
Table 4).
The pixel-wise classification accuracy of most of the models ranges from 75% to 88%, which shows that the DL-based segmentation models are able to learn some patterns from the UAV images and have some potential in weed segmentation.
4.3. Class-Wise Study of Best-Performing DL-Based Segmentation Model
We report the class-wise performance of the best models; DenseNet121 with SegNet for the binary and EfficientNetB0 with UNet for the multi-class segmentation.
Table 5 shows that the model is able to identify the background class with all the performance matrices ( IoU of 87.66%, precision 91.68%, Recall 95.24% and F1-score 96.42) higher than 87%. However, the performance metrics for the weed class ranged from 47% (IoU) to 71% (Precision).
For the multi-class segmentation, the background class has the highest performance (IoU of 88.09%), while the weed class (Johnson grass) has the lowest performance (IoU of 44.78%) (refer to
Table 6). It seems that it is more challenging to distinguish between the types of weeds than to differentiate between background vs. weed pixels.
4.4. Five-Fold Results of Best-Performing Model
To perform the validation of the best-performing model, we provide the five-fold cross-validation results for the multi-class (EfficientNetB0+UNet)) segmentation model. The confidence interval (CI) (refer to Equation (
6)) for each performance metric is calculated at a 95% confidence level, which shows the statistical estimate of performance among the five folds of the dataset [
60].
where
and n represent the sample mean, confidence level, sample standard deviation and sample size. We preferred the CI over the p-value in this statitical analysis because the interpretation of trial results based solely on p-values can be misleading [
61].
Table 7 reports the performance scores of the EfficientNetB0 with UNet model for five folds, shedding light on the consistency of the model across the folds. The performance of the model in Fold-3 (mean IoU of 60.43%) is the highest, followed by the Fold-1 (mean IoU of 58.05%). The minimum scores of the models are reported in Fold-4 (mean IoU of 56.21%). However, the confidence interval (CI) at
shows that the model is robust across the fold with the minimum margin of errors (
for IoU,
for precision,
for recall and
for f-score) from the mean.
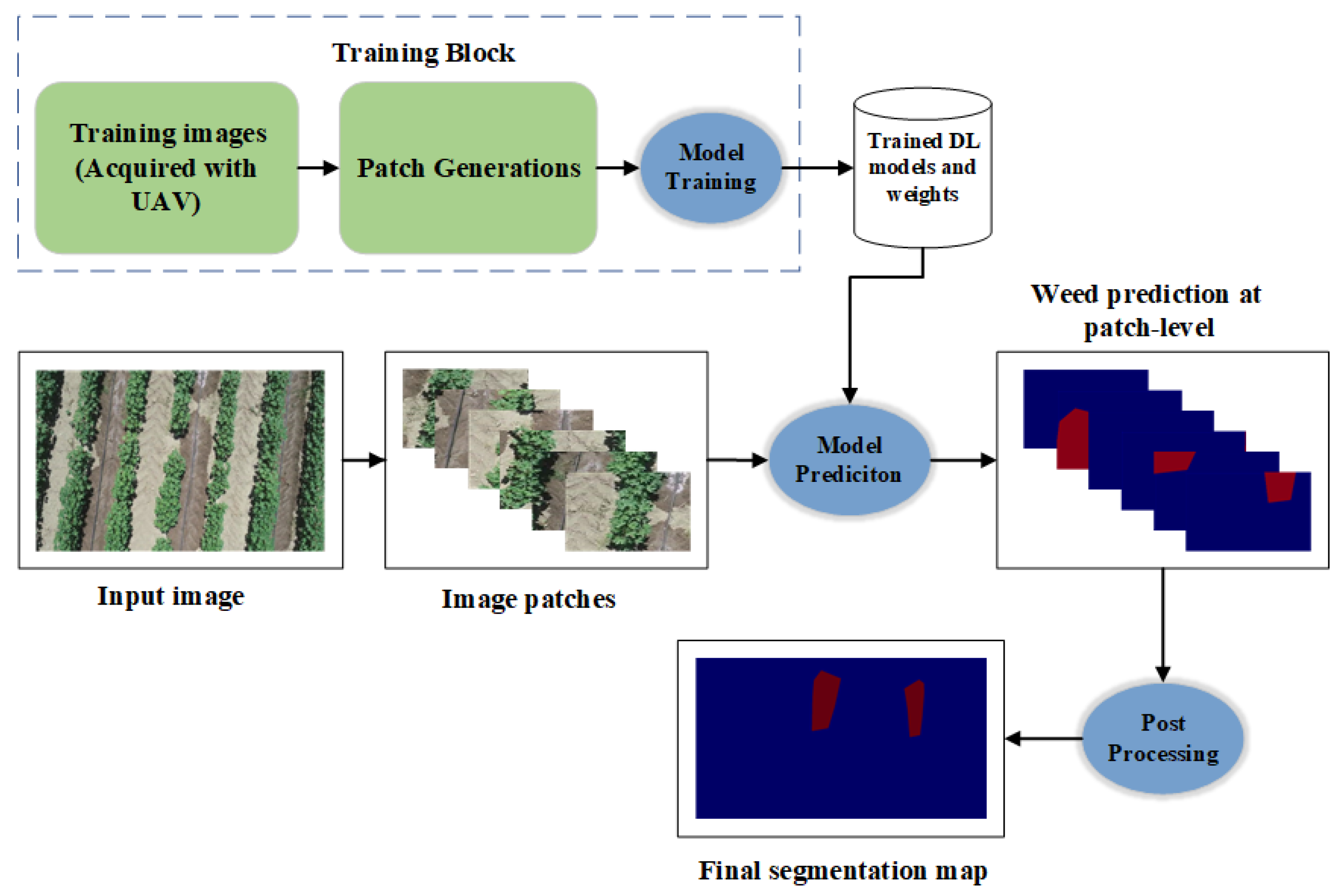
4.5. A DL-Based Framework for Weed Detection on UAV Images
We finally present the DL-based framework for weed detection using UAV images, which consists of five stages: (a) input UAV-acquired images, (b) patch generations, (c) load the trained DL model at patch level, (d) make the prediction, (e) post-process the patch level prediction and (f) generate the final segmentation map (refer to
Figure 7).
The framework begins with large input images ((
)), and the image is divided into smaller patches of size (
). By dividing the whole image into manageable patches, we believe that the backbone CNNs can focus on discriminating features within localized areas that include weed pixels. Then, the best-performing DL-based segmentation model (e.g., EfficientNetB0 with UNet) is loaded and deployed to make the segmentation mask prediction at the patch level. The model evaluates the content of each patch and predicts types of weeds and background pixels based on the knowledge acquired during training (binary or multi-class). Finally, after obtaining predictions for individual patches, the framework proceeds to post-process these predictions. This step involves refining and combining the patch-level predictions to generate a more coherent and accurate prediction map for the whole image. In order to deploy the proposed DL framework for weed segmentation for new crop fields (other crops and weed types), the steps included in the training block (see
Figure 7) are required, which will train the model to learn how to discriminate the specific crops vs. weeds. The trained model can then be deployed to predict the weeds in the given field image.
By applying the above procedure, we tested the efficacy of the proposed framework (using EfficientNetB0 with UNet) for a multi-class segmentation task. The sample output generated by the proposed framework is demonstrated in
Figure 8.
5. Conclusions
In this work, we comprehensively studied the well-established deep learning-based segmentation models for weed detection. Through the investigation of weed segmentation using UAV images in three aspects, backbone CNNs, segmentation models and data augmentation, binary as well as multi-class weed segmentation frameworks are suggested. The results indicate that DenseNet121 paired with SegNet performs the best for the binary task, while EfficientNetB0 combined with UNet poses the highest performance for multi-class segmentation. Furthermore, the comparison of five backbone CNNs on the benchmark dataset shows that the UNet model with the EfficienNet, DensNet121 and ResNet50 backbone has the best performance on multi-class weed detection. The other models have varying results while using different CNNs as the backbone.
Comparing the three segmentation models (UNet, SegNet and DeepLabV3+) with different backbones, we find a mixed performance on both binary and multi-class segmentation tasks. In particular, in the binary task, SegNet (with DenseNet121 as backbone CNN) has the highest mean IoU score of 67.56%, whereas UNet (with EfficientNetBO) has the highest mean IoU score for multi-class segmentation tasks.
Based on the complexity of segmentation tasks (binary and multi-class), the majority of models (combination of backbone CNNs and segmentation models) demonstrate similar performance for the binary task. This similarity might be attributed to the relatively lower complexity of binary segmentation, where all models effectively distinguish between the background (including crops) and weeds. In contrast, the multi-class segmentation task is more challenging due to higher intra-class similarity between different types of weeds, where UNet excels compared with the other models, which might be attributed to its ability to transfer the entire feature from encoder to decoder during segmentation.
This work has two limitations. First, the model is trained with RGB images which only include the visible light spectrum. Multispectral images can capture more canopy information and might be helpful in learning distinguishable patterns between the weeds and the background. This might further boost the performance of the segmentation models, as these SOTA models have shown the greatest performance in other domains. Second, the effect of data augmentation on multi-class task performance in most of the models indicates the necessity of more training data for improved performance. Data generation techniques such as generative models can be employed to increase the dataset.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}