1. Introduction
Unmanned aerial vehicle (UAV)-assisted communication presents a line-of-sight (LoS) wireless connection with controllable and flexible utilization [
1]. In this regard, UAVs were mainly utilized to enrich the capacity and network coverage for ground users. As well, in wireless powered networks (WPN), UAVs are used as mobile charging stations to deliver radio frequency (RF)-energy supply to lower power user gadgets [
2]. As a UAV generally utilizes limited-capacity batteries to carry out tasks, like flying, hovering, and offering services, it was vital to make the trade-offs between their coverage area and energy utilization along with service time [
3]. Specifically, UAV-based aerial platforms that provide wireless services have allured the wide industry and research efforts concerning control, deployment problems, and navigation. To enhance the coverage and energy efficiency for UAV-aided communication networks, resource allocation, namely subchannels, transmit power, and serving users, is essential [
4].
Furthermore, consider a multiple-UAV-based wireless communication network (multi-UAV network) where a joint model to optimize trajectory and resource allocation was analyzed as a means to guarantee fairness by optimizing the minimal output throughput among users [
5]. In this study, the author to strike tradeoffs between the sum rate and delay of sensing errands for multi-UAV based uplink single cell network devised a hybrid trajectory design and subchannel assignment method [
6]. Human interference is constrained for the control design of UAVs because of the maneuverability and versatility of UAVs. Hence, to boost the outcome of UAV-enabled communication networks, machine learning (ML)-based intelligent control of UAVs is a priority [
7]. Neural networks (NNs)-based trajectory design is taken into account where concerned from the viewpoint of UAVs’ manufactured structures. Likewise, based on reinforcement learning (RL), a UAV routing design method was developed.
To build data distributions, the Gaussian mixture model was used where a weight expectation-related predictive on-demand deployment algorithm of UAV was devised for reducing the transmit power. As previously mentioned, ML is an auspicious power tool to offer potential and autonomous solutions smartly to boost the UAV-assisted communication network. But, several pieces of research focused on the trajectory and deployment models of UAVs in communication networks [
8]. However, resource allocation methods like sub-channels and transmit power are taken into account as well as the previous research concentrated on time-independent scenarios. Furthermore, for time-dependent cases, the capacities of ML-based resource allocation techniques were inspected [
9]. But, many ML techniques concentrated on multi-or-single UAV scenarios by assuming the accessibility of whole network data for all UAVs.
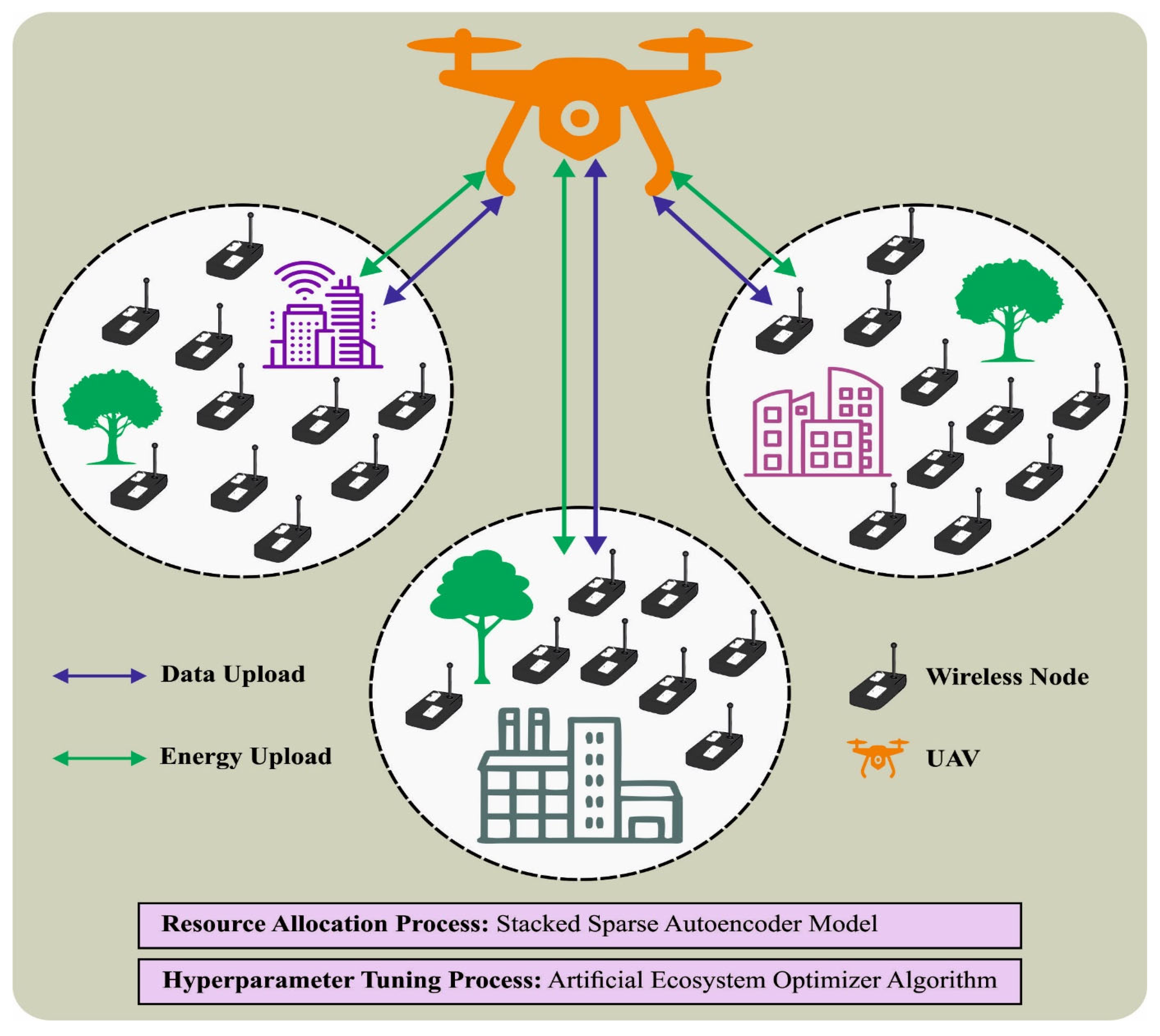
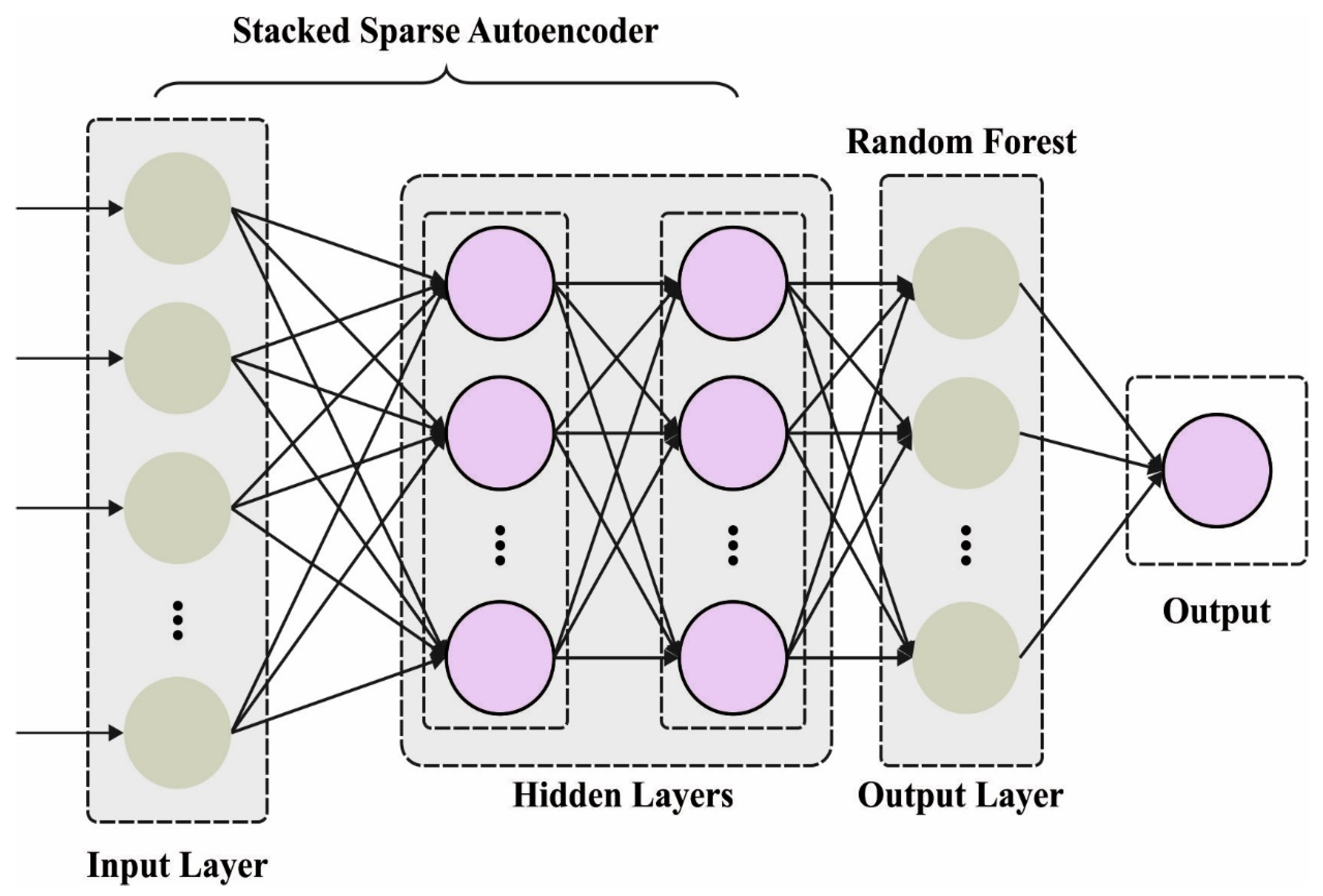
This article introduces an intelligent resource allocation using an artificial ecosystem optimizer with a deep learning (IRA-AEODL) technique on UAV networks. The presented IRA-AEODL technique aims to effectually allot the resources in the wireless UAV network. In such cases, the IRA-AEODL technique focuses on the maximization of system utility over all users, combined user association, energy scheduling, and trajectory design. To optimally allocate the UAV policies, the stacked sparse autoencoder (SSAE) model is used in the UAV networks. For the hyper-parameter tuning process, the AEO algorithm is used to enhance the performance of the SSAE model. The experimental results of the IRA-AEODL technique are examined under different aspects.
The highlights of this article include the use of unmanned aerial vehicles (UAVs) as a solution for flexible coverage and high data rates in next-generation networks, the challenge of energy consumption and limited battery capacity in UAVs, and the introduction of an intelligent resource allocation technique using an artificial ecosystem optimizer with deep learning (IRA-AEODL) on UAV networks. The research motivation behind this article is to find a solution to the energy cost issue in UAV-aided mmWave networks by utilizing energy harvesting and an intelligent resource allocation technique.
2. Related Works
In [
10], the authors examine the Resource Allocation (RA) issue in UAV-assisted EH-powered D2D Cellular Networks (UAV-EH-DCNs). The main goal is to enhance power effectiveness and, at the same time, ensure the gratification of Ground Users (GUs). Also, the LSTM network is implemented to ease the rapidity of conjunction by taking out the prior data of GUs’ gratification in regulating the present RA policy. Chang et al. [
11] suggest an ML-founded policy RA protocol that encompasses RL and DL to devise the maximum strategy of the comprehensive UAV. Then, the authors also introduce a Multi-Agent (MA) DRL system for dispersed employment without being aware of a previous idea of the dynamic behavior of networks. Li et al. [
12] suggest a novel DRL-founded Flight Resource Allocation Framework (FRA) to lessen the comprehensive information packet loss in a sequential activity space. Also, a state classification layer, leveraging LSTM, is established in forecasting network dynamics, outcoming from time-varying airborne channels and power arrivals at the devices on the ground.
In [
13], the authors concentrate on a downlink cellular network, where several UAVs play as aerial base stations for the users on the ground over Frequency Division Multiple Access (FDMA). Targeting maximizing both fairness and comprehensive throughput, the authors prototype RA and route design as a Decentralized Partially Observable Markov Decision Process (Dec-POMDP) and suggest MARL as a resolution. In [
14], a MADRL-founded approach is introduced to accomplish the optimum long-term network utility while gratifying the customer’s device value of service needs. However, considering that the efficacy of every UAV was determined founded on the atmosphere of the network and several other UAV activities, the JTDPA issue is prototyped as the stochastic game.
In [
15], the authors present their IRA-AEODL framework, which combines the Intra-Routing Algorithm (IRA) and Aerial Edge-mounted On-Demand Learning (AEODL). The IRA allows UAVs in the network to organize them for routing, while AEODL leverages machine learning to enhance dynamic route optimization. Afterward, the authors evaluate the performance of their proposed IRA-AEODL network, comparing it against existing UAV network solutions. They perform numerical simulations to evaluate the end-to-end delay, network throughput, and packet delivery ratio. They also analyze the mobile edge computing capabilities of their proposed network.
In [
16], the authors examine the anti-jamming issue with integrated channel and energy distribution for UAV networks. Specifically, the authors concentrate on discarding both shared intrusion amongst exterior malevolent jamming and UAVs to optimize the scheme Quality of Experience (QoE) related to energy utilization. Then, the authors suggest a joint MA Layered Q Learning (MALQL) founded anti-jamming transmission protocol in minimizing the huge dimensionality of the activity space and examine the asymptotic convergence of the suggested protocol. In [
16], the novelty of this research lies in its ability to address the total energy reduction issue in a non-convex way, while also incorporating several advanced protocols, such as a central MARL protocol and an MA Federated RL protocol, into an MEC scheme with multiple UAVs. By doing so, the authors propose a new and innovative approach that can potentially reduce energy consumption and improve the overall energy efficiency. The author [
17] presents a stochastic geometry-based analysis of an integrated aerial-ground network, enabled by multi-UAVs. The novelty of this paper is that the exact distribution of the network throughput is derived and explored under various system parameters. However, the analysis is restricted to Rayleigh fading and a single interfering UAV.
Overall, the literature survey highlights a research gap in the area of resource allocation in UAV-assisted networks. While there have been previous studies focusing on using algorithms such as LSTM, RL, and DRL for efficient resource allocation, there is still a need for further investigation in this area. Furthermore, there is also a need for exploring the use of multi-agent reinforcement learning (MARL) in resource allocation as it has shown promising results in other areas of machine learning. There is also a gap in the evaluation of these proposed resource allocation techniques as most existing studies use simulation-based results rather than real-world implementation and testing. Therefore, further research in this field can contribute to the development of more efficient and adaptive resource allocation policies for UAV-assisted networks.
4. Results and Discussion
In this section, the experimental validation of the IRA-AEODL technique is examined under various aspects.
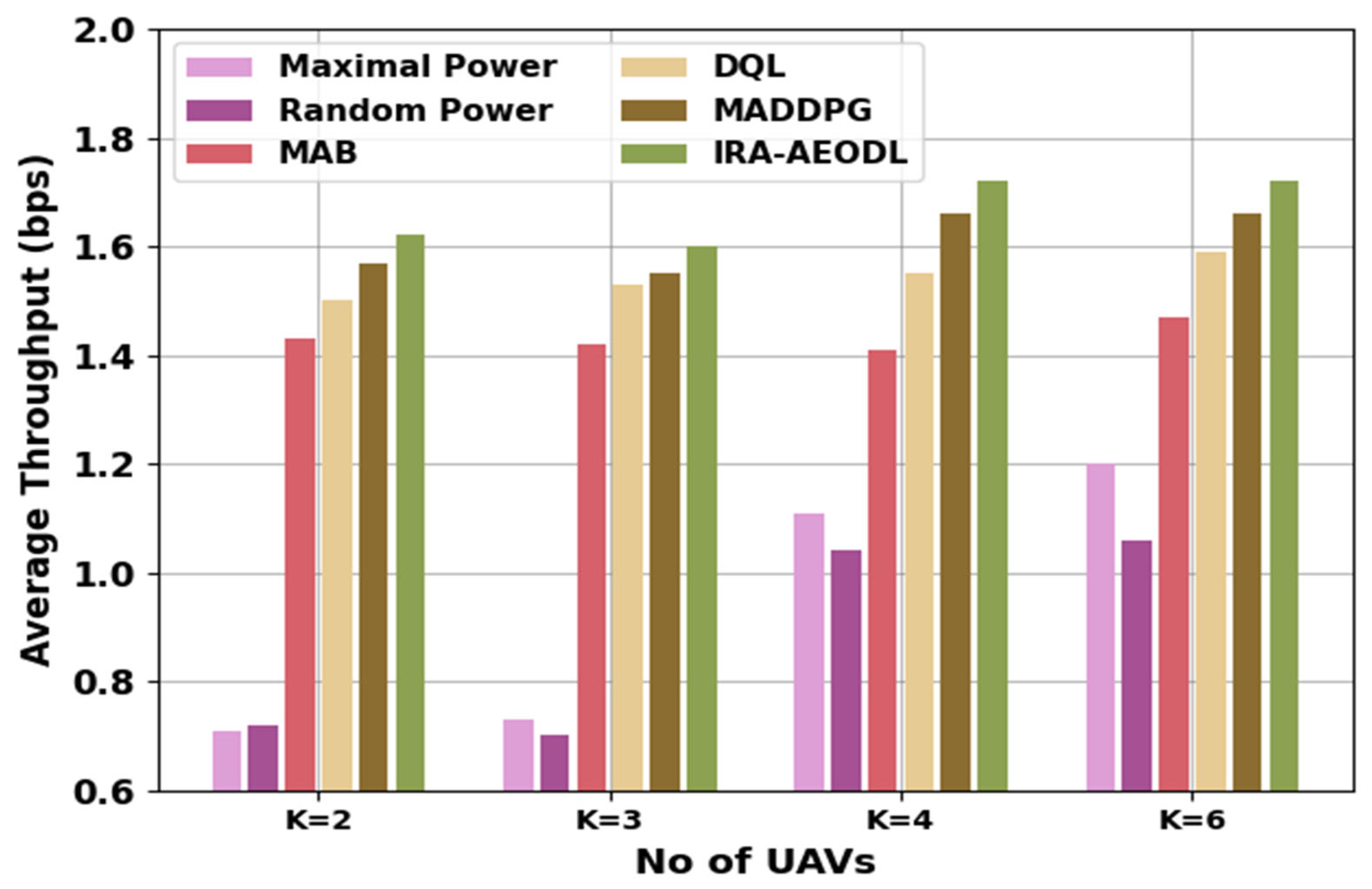
Table 1 and
Figure 3 report a comparative average throughput (ATHRO) study of the IRA-AEODL technique with recent models [
20]. The outcomes indicate the increasing ATHRO values of the IRA-AEODL technique under all K values. For K = 2, the IRA-AEODL technique obtains a higher ATHO value of 1.62 bps while the MP, RP, MAB, DQL, and MADDPG [
21] models accomplish reduced ATHO values of 0.71 bps, 0.72 bps, 1.43 bps, 1.50 bps, and 1.57 bps, respectively. Similarly, with K = 6, the IRA-AEODL technique reaches improving ATHO of 1.72 bps while the MP, RP, MAB, DQL, and MADDPG models result in reduced ATHO values of 1.20 bps, 1.06 bps, 1.47 bps, 1.59 bps, and 1.66 bps, respectively. The proposed DNN was trained on an offline dataset of simulated UAV-aided mmWave. The parameters of the proposed algorithm were optimized to obtain the best learning performance. The training was conducted for 1000 epochs using Keras and Tensorflow on a Nvidia GTX 1060 GPU. The accuracy comparison of the proposed DNN was conducted against existing state-of-the-art algorithms. The results showed that the proposed IRA-AEODL technique achieved an average improvement in 11.5% over existing algorithms. This accuracy improvement was attributed to the stacked sparse autoencoder’s ability to efficiently perform resource allocation and the AEO algorithm’s ability to optimize the model.
The proposed model is a Deep Neural Network (DNN) model that has been trained on a dataset of images of different fruits. The DNN architecture uses convolutional layers to extract features from the images, followed by a densely connected set of layers to identify the classes of fruits. The training process will involve feeding the DNN model with labeled images of each of the desired fruit classes. The model will learn the features associated with each class and develop a set of weights that will allow it to recognize which fruits belong to which class. After training has been completed, the model can then be used to classify new images of fruits into their respective classes. Additionally, to improve accuracy, the model can also be fine-tuned using data augmentation techniques, such as randomly adjusting the size and orientation of the images as well as adjusting the brightness and contrast. This can help the model to better recognize the features in different images. Once training and fine-tuning is complete, the DNN can then be tested with a set of validation images to ensure that it is able to accurately classify the different types of fruits. Once satisfactory accuracy has been achieved, the model can then be deployed for use in applications.
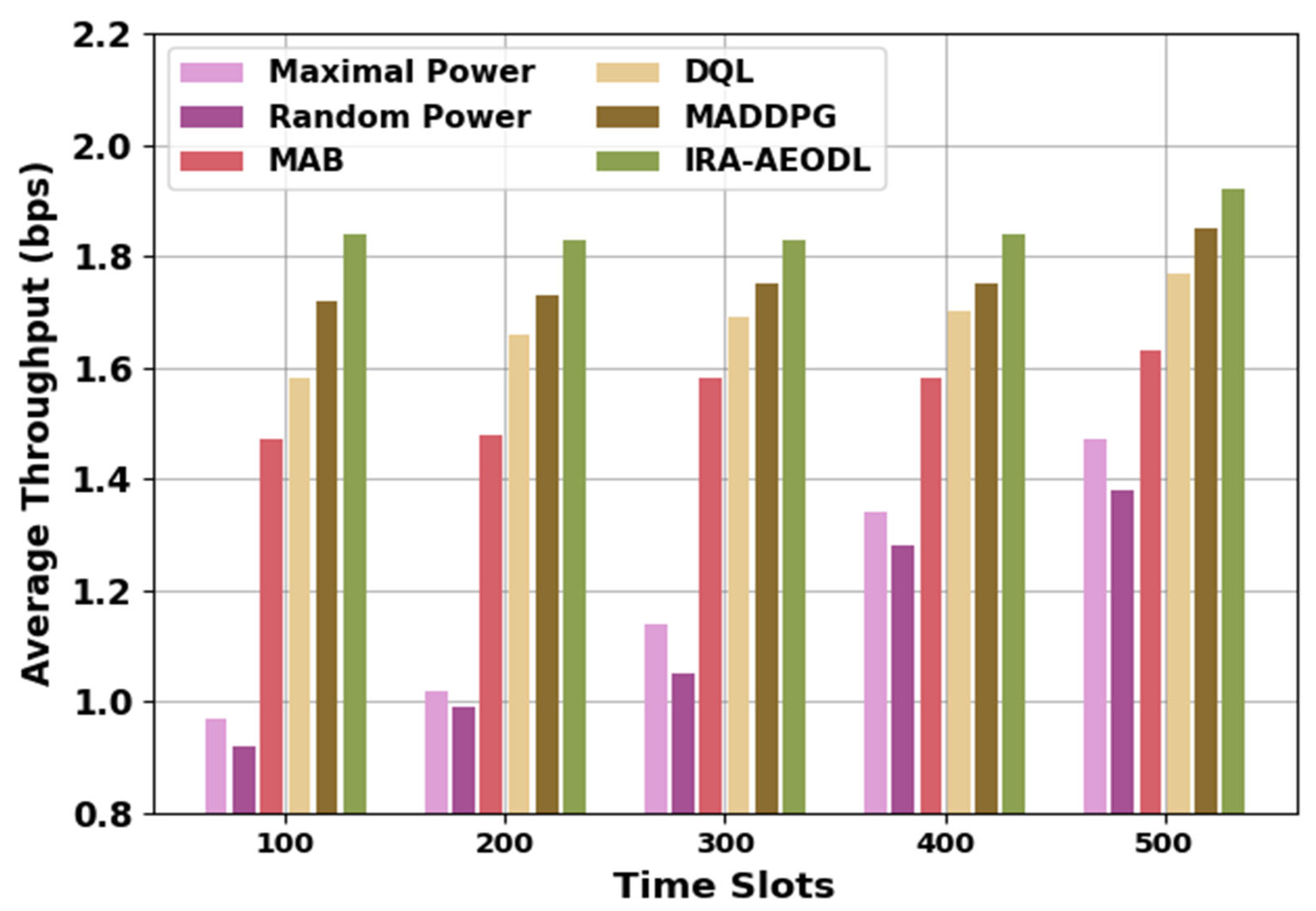
Table 2 and
Figure 4 demonstrate a comparative ATHRO study of the IRA-AEODL method with recent methods. The results represent the increasing ATHRO values of the IRA-AEODL technique under varying time slots. For 100 time slots, the IRA-AEODL method attains a maximum ATHO value of 1.84 bps whereas the MP, RP, MAB, DQL, and MADDPG methods attain decreased ATHO values of 0.97 bps, 0.92 bps, 1.47 bps, 1.58 bps, and 1.72 bps, respectively. Similarly, with 300-time slots, the IRA-AEODL method attains an increasing ATHO of 1.83 bps while the MP, RP, MAB, DQL, and MADDPG methods resulted in decreased ATHO values of 1.14 bps, 1.05 bps, 1.58 bps, 1.69 bps, and 1.75 bps, resepctively.
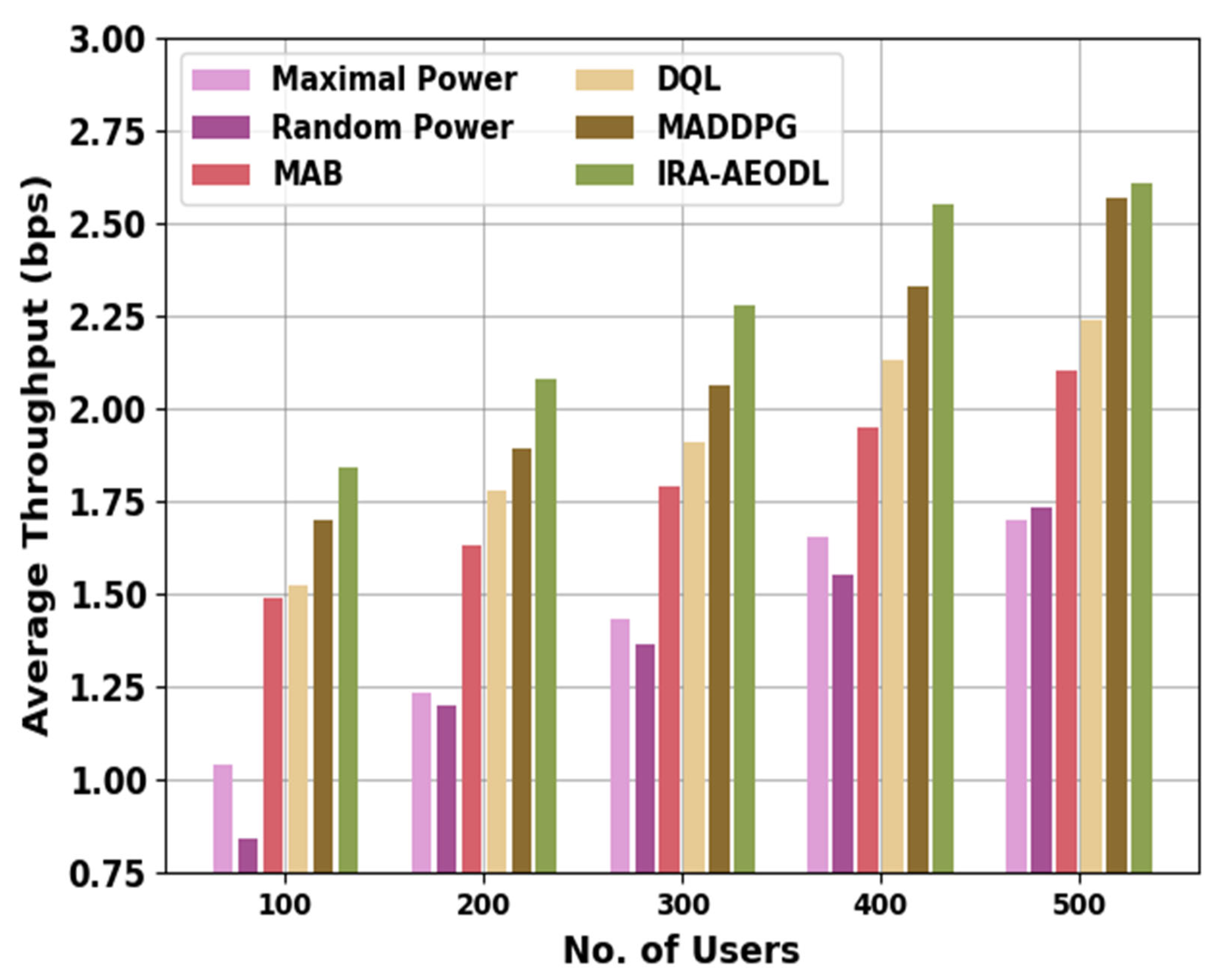
Table 3 and
Figure 5 illustrate a comparative ATHRO study of the IRA-AEODL method with recent models. The results indicate the increasing ATHRO values of the IRA-AEODL technique under varying users. For 100 users, the IRA-AEODL technique obtains a higher ATHO value of 1.84 bps while the MP, RP, MAB, DQL, and MADDPG methods accomplish reduced ATHO values of 1.04 bps, 0.84 bps, 1.49 bps, 1.52 bps, and 1.70 bps, respectively. Similarly, with 300 users, the IRA-AEODL technique reaches an improving ATHO of 2.28 bps while the MP, RP, MAB, DQL, and MADDPG models resulted in reduced ATHO values of 1.43 bps, 1.36 bps, 1.79 bps, 1.91 bps, and 2.06 bps, respectively.
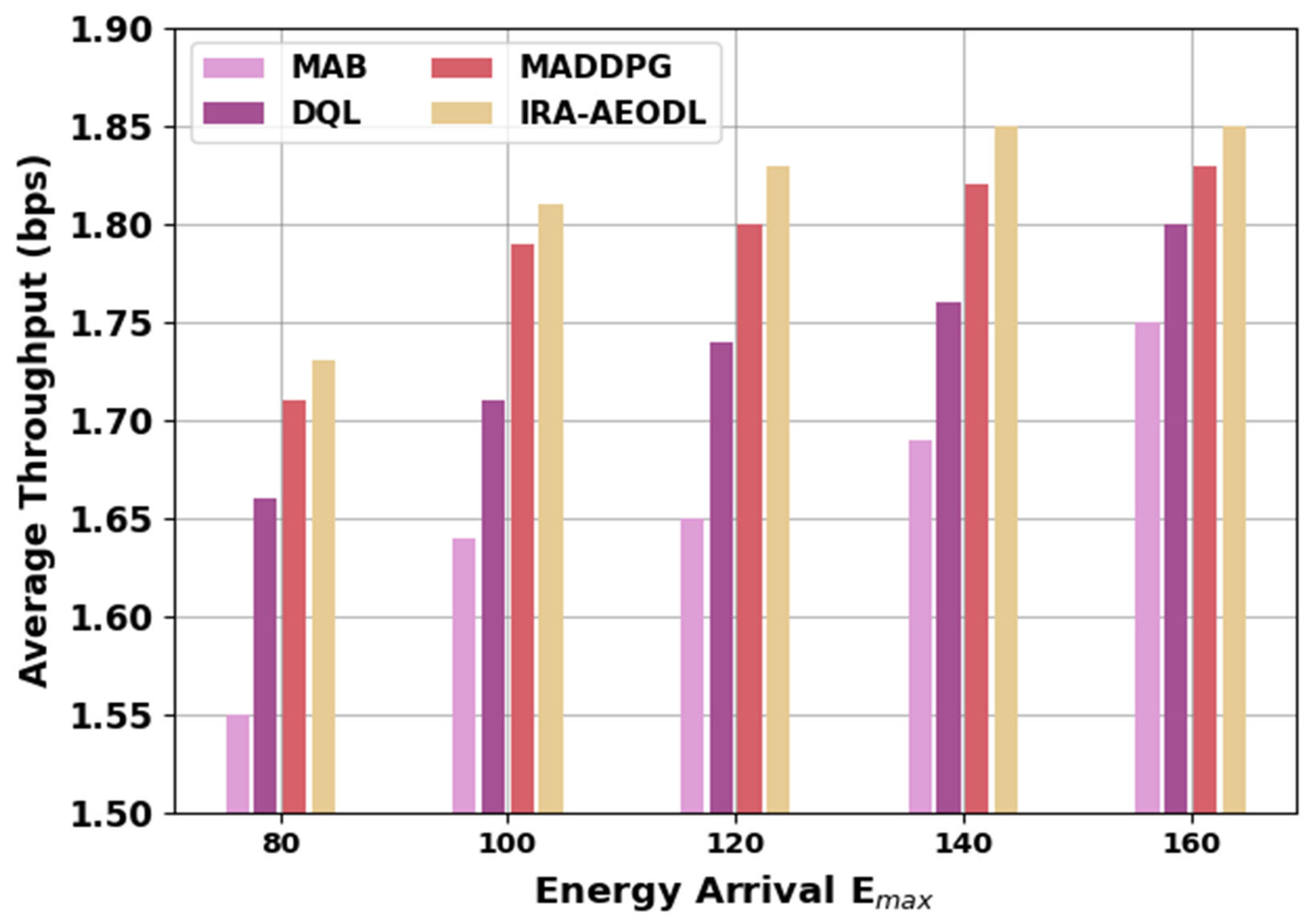
Table 4 and
Figure 6 depict a comparative ATHRO study of the IRA-AEODL technique with recent models. The outcomes indicate the increasing ATHRO values of the IRA-AEODL technique under varying energy arrival E
max. For 80 energy arrival E
max, the IRA-AEODL technique attains a higher ATHO value of 1.73 bps while the MAB, DQL, and MADDPG methods obtain minimum ATHO values of 1.55 bps, 1.66 bps, and 1.71 bps respectively. Similarly, with the 160 energy arrival E
max, the IRA-AEODL technique reaches an improving ATHO of 1.85 bps while the MAB, DQL, and MADDPG models resulted in reduced ATHO values of 1.75 bps, 1.80 bps, and 1.83 bps, respectively.
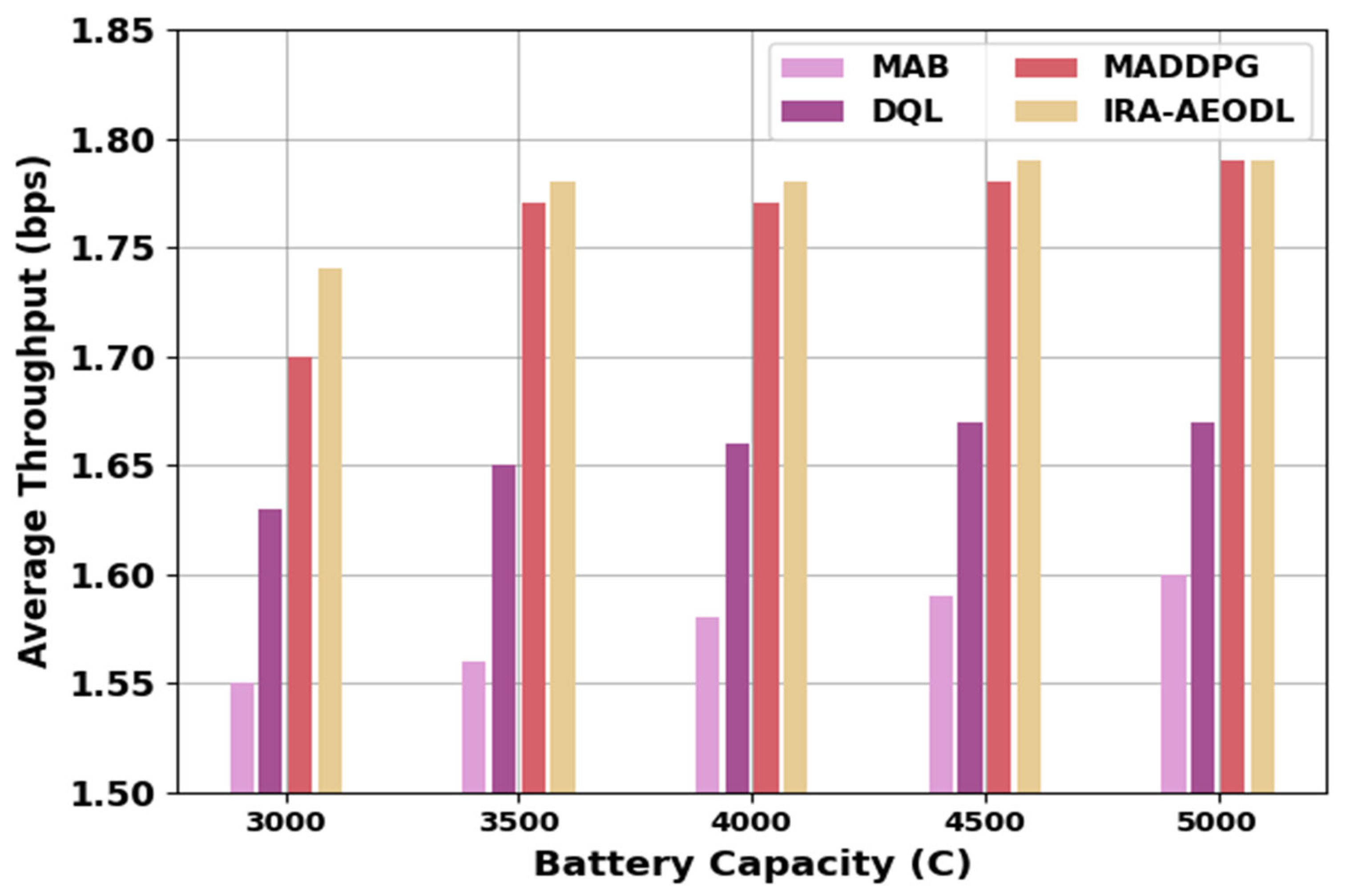
Table 5 and
Figure 7 demonstrate a comparative ATHRO study of the IRA-AEODL technique with recent methods. The results indicate the increasing ATHRO values of the IRA-AEODL technique under varying battery capacity (BC). For 3000 BC, the IRA-AEODL technique obtains a higher ATHO value of 1.74 bps while the MAB, DQL, and MADDPG methods accomplish reduced ATHO values of 1.55 bps, 1.63 bps, and 1.70 bps, respectively. Similarly, with 5000 BC, the IRA-AEODL technique reaches an improving ATHO of 1.79 bps while the MAB, DQL, and MADDPG models resulted in reduced ATHO values of 1.60 bps, 1.67 bps, and 1.79 bps, respectively.
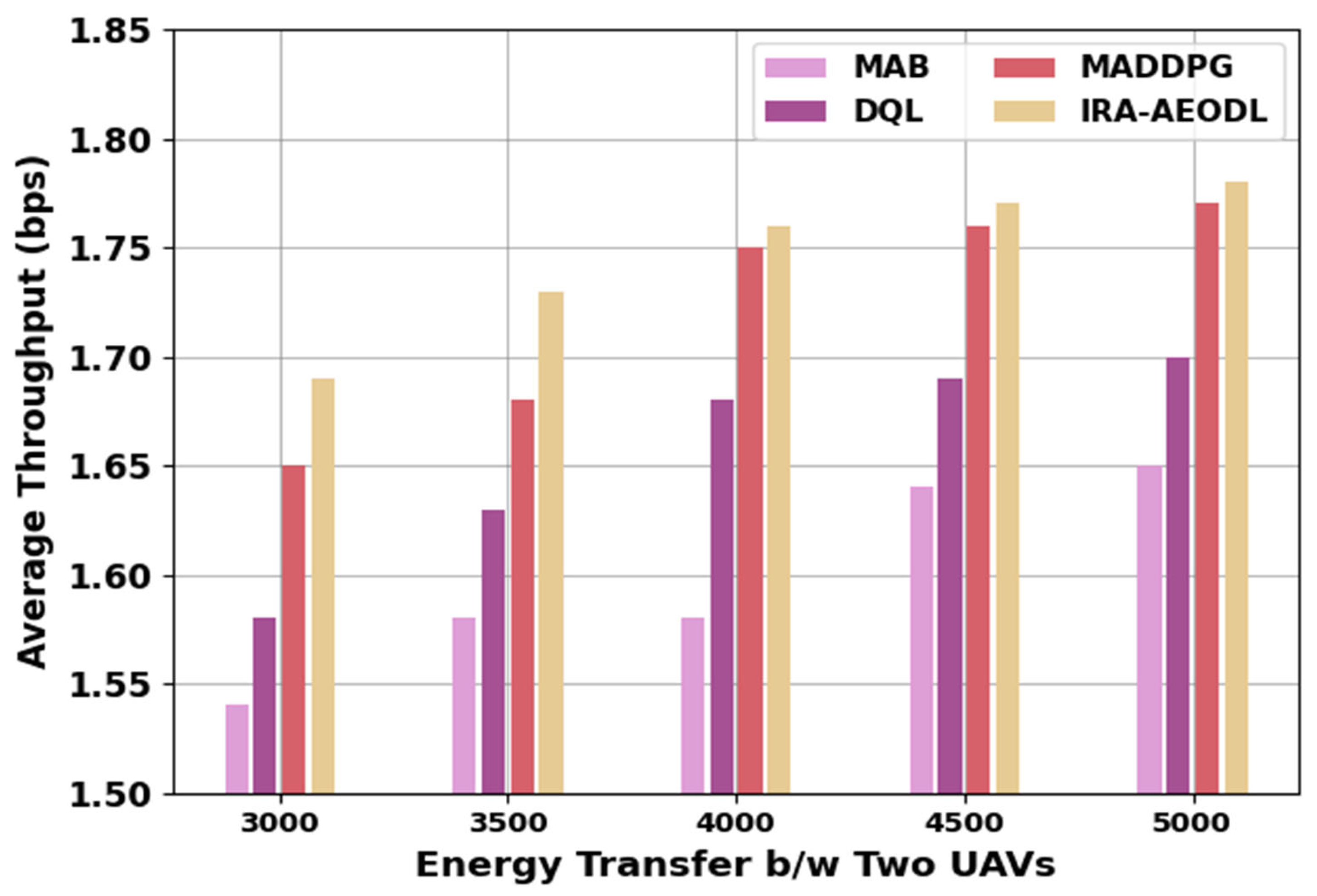
Table 6 and
Figure 8 depict a comparative ATHRO study of the IRA-AEODL technique with recent models. The results indicate the increasing ATHRO values of the IRA-AEODL technique under varying Energy Transfer b/w Two UAVs (ETTUAV). For 3000 ETTUAV, the IRA-AEODL technique attains a higher ATHO value of 1.69 bps while the MAB, DQL, and MADDPG methods accomplish reduced ATHO values of 1.54 bps, 1.58 bps, and 1.65 bps, respectively. Similarly, with 5000 ETTUAV, the IRA-AEODL technique reaches an improving ATHO of 1.78 bps while the MAB, DQL, and MADDPG models resulted in reduced ATHO values of 1.65 bps, 1.70 bps, and 1.77 bps, respectively.
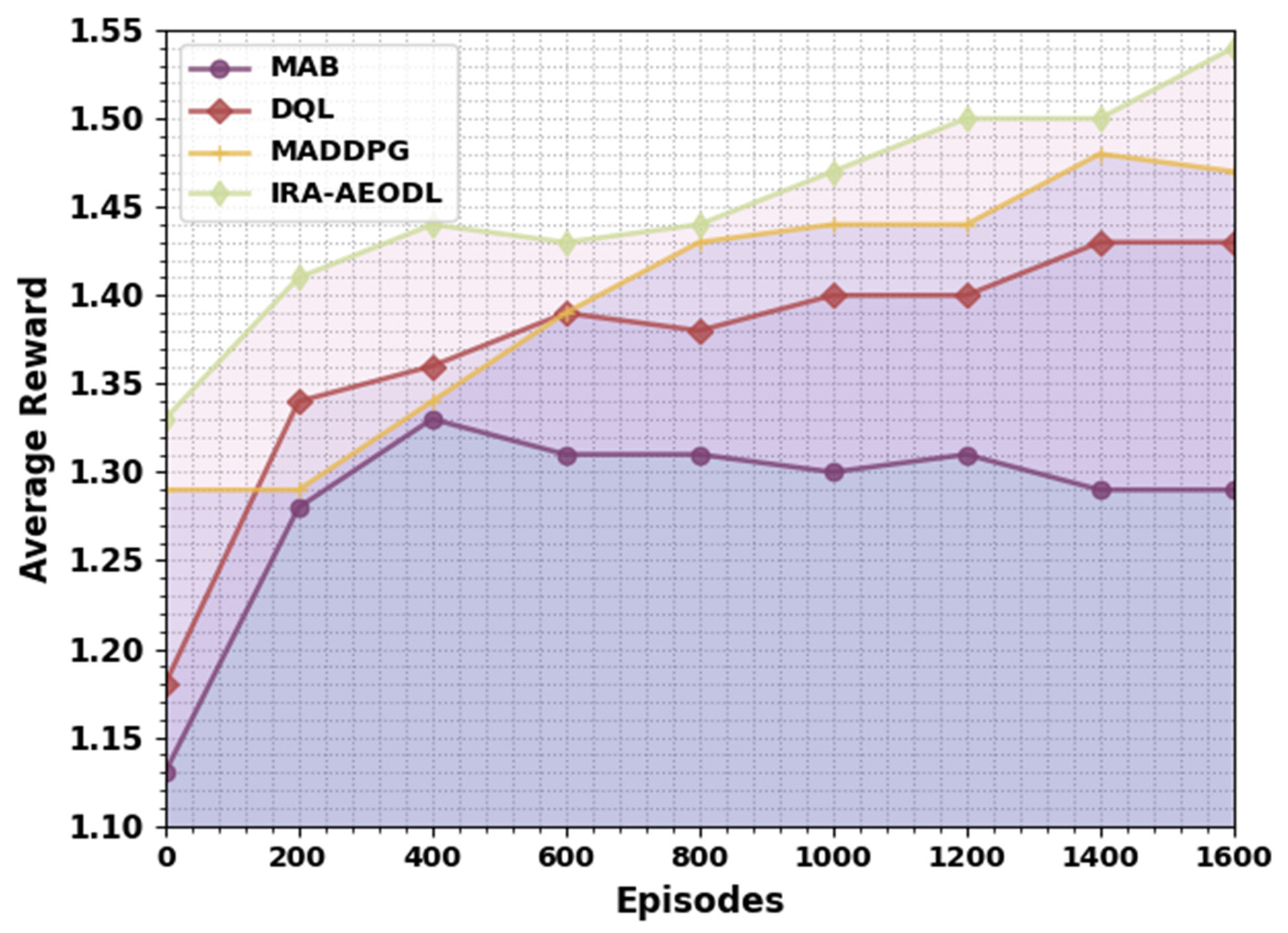
Finally, the average reward examination of the IRA-AEODL technique with different models takes place in
Table 7 and
Figure 9. The results demonstrate that the IRA-AEODL technique gains increasing reward values over other models. For instance, with 200 episodes, the IRA-AEODL technique attains an increasing average reward of 1.41 while the MAB, DQL, and MADDPG techniques obtain reducing average rewards of 1.28, 1.34, and 1.29, respectively.
Meanwhile, with 800 episodes, the IRA-AEODL technique attains an increasing average reward of 1.44 while the MAB, DQL, and MADDPG methods attain reducing average rewards of 1.31, 1.38, and 1.43, respectively. Eventually, with 1600 episodes, the IRA-AEODL technique attains an increasing average reward of 1.54 while the MAB, DQL, and MADDPG techniques obtain reducing average rewards of 1.29, 1.43, and 1.47, respectively. These results exhibited the superior performance of the IRA-AEODL technique over other existing models on the UAV networks.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}