The research background of this paper is that natural disasters occur frequently in my country, and the rescue of a large number of trapped people after the disaster is the focus of the current emergency work. The use of drone swarms for the transportation of relief materials is an important research direction. The focus of this paper is the distribution scheme of heterogeneous UAVs to transport the materials carried by them to the rescue area.
3.1. Simulation Environment Modeling
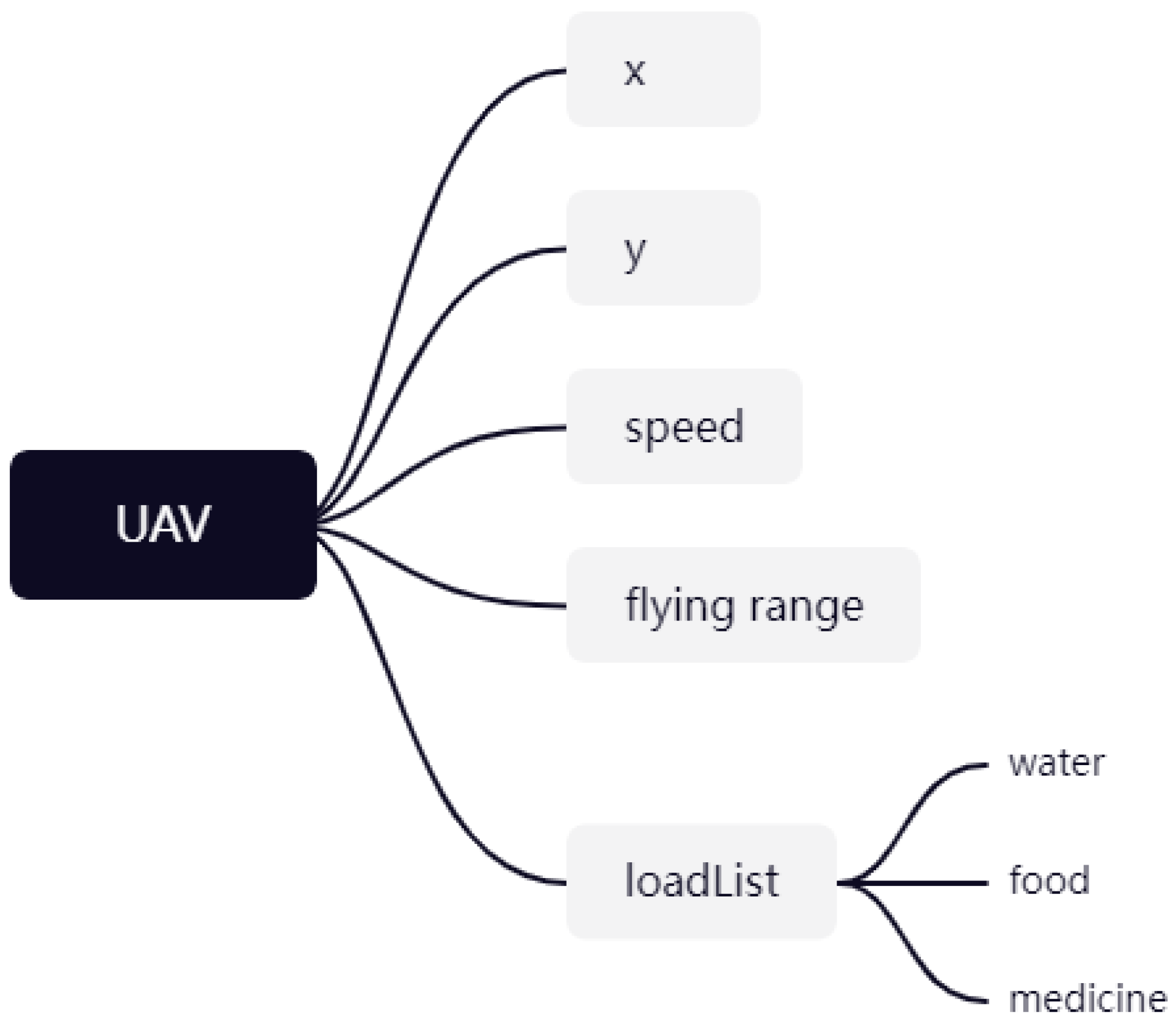
Multiple UAVs form the UAV swarm to be allocated
where
M is the number of drones in the cluster. In order to digitize the indicators of the drone, the parameters of each drone are represented by a collection
where
: the horizontal axis coordinate of the starting point of the drone;
: the vertical axis coordinate of the starting point of the drone;
: the current horizontal axis coordinate of the drone;
: the current vertical axis coordinates of the drone;
: the average speed of the drone;
: The maximum range that the drone can fly in a single flight without supplementation;
: The current flight range of the drone;
: Whether the drone is returning, the returning drone will no longer be assigned tasks, the initial value is 0;
: The list of materials carried by the drone, which is an array.
Rescue areas with different urgency and needs form a task set
where
N is the number of rescue areas. The information of each rescue area is represented by a collection
where
x: the horizontal axis coordinate of the rescue area;
y: the vertical axis coordinate of the rescue area;
: The emergency level of the rescue area;
: The list of materials needed by the rescue area, which is an array.
When the environment is initialized, all the information about the drone swarm and rescue areas needs to be provided. After initialization, the environment will record the initialization information to facilitate the reset of task assignment. The result of the task assignment is entered in the form of , where . means that the drone i goes to the rescue area for material transportation. If the drone can meet the needs of the rescue area, we unload the amount of materials needed in the rescue area from the drone. Otherwise, unload all the materials on the drone to the rescue area, and modify the location of the drone, the amount of materials carried by the drone, the distance flown by the drone, and the amount of materials needed in the rescue area. When , it means that the drone completes the flight mission and returns, and the parameter of the drone needs to be set.
3.2. MDP Model of Task Allocation
Using model-free reinforcement learning to solve the multi-UAV task assignment problem requires modeling the problem as a Markov decision process. Modeling requires the definition of state space, observation space, action space, and reward function.
3.2.1. State Space
According to the description of the simulation environment above, it can be found that only the drone cluster and the rescue areas are involved in this environment, so the state space only needs to contain all the information of the drone cluster and the rescue areas. For the sake of simplicity, we flatten the UAV information and the rescue area information. The state space data form is shown in (
10), where the expression of
is (
11), and
expression is Formula (
12).
3.2.2. Observation Space
Since the problem involved in this paper is the multi-UAVs task assignment, involving multiple agents, the distributed reinforcement learning method is used to solve it. The observation space of each UAV is related to itself but not related to other UAVs. The observation space is not the same as the state space, so it needs to be redefined. The observation space of the
i-th UAV is shown in (
13).
3.2.3. Action Space
The action space of each drone is related to the current state of the drone. When , that is, when the drone is not in the returning state, the action space of the drone is , where action j represents the UAV to perform the task . When , the drone is in the returning state, and the action space of the drone is , where is a virtual target point, which means that the drone continues to return to home.
3.2.4. Reward Function
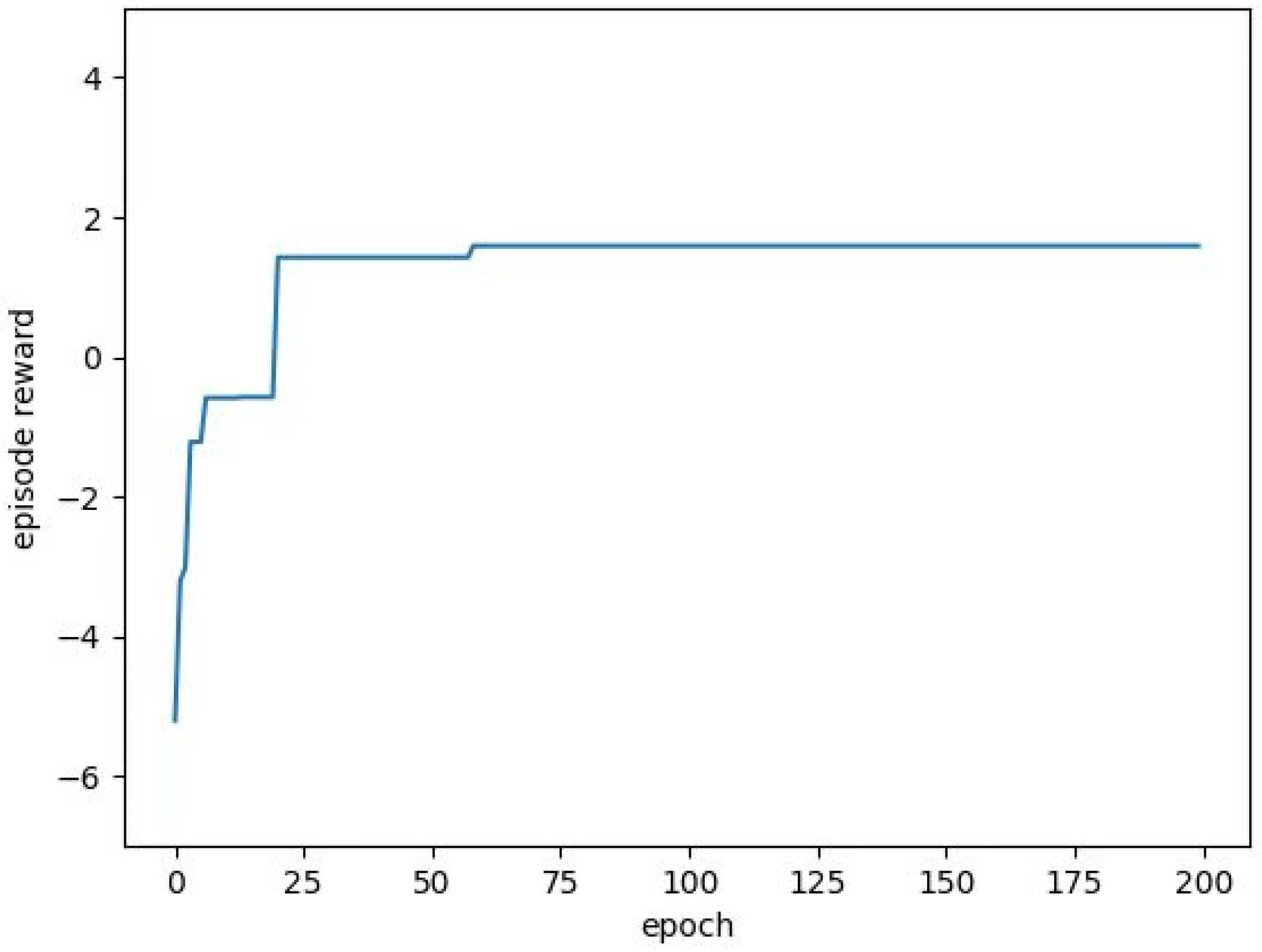
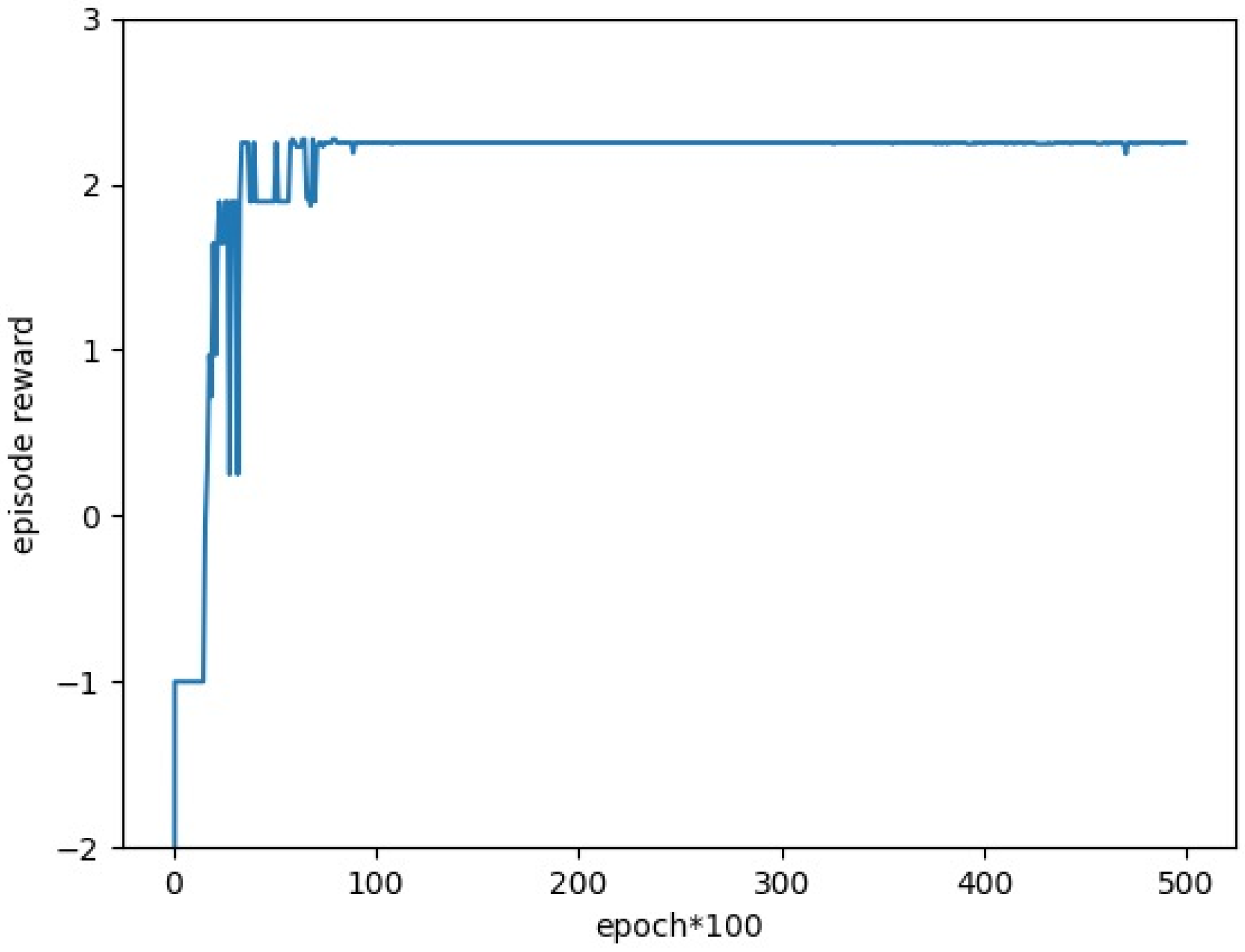
The reward function is very important for reinforcement learning because the agent needs to learn the action through the reward value. It can be said that the quality of the reward function determines the convergence of the algorithm and the convergence result. The goal of the task allocation problem solved in this paper is to complete the task allocation under the condition that the total voyage of the UAV is as small as possible. At the same time, priority shall be given to meeting the material needs of the rescue areas with a high degree of urgency. Experiments show that the reward value calculation formula shown in (
14) has a good effect, where
means that
can satisfy
the number of resources required,
indicates the number of resources required by
,
represents the drone selected by
to perform the task, and
represents the Euclidean distance between the drone and the target point.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}