
VSAI: A Multi-View Dataset for Vehicle Detection in Complex Scenarios Using Aerial Images

Abstract
:1. Introduction
- Large size variations of instances: this almost depends on the different spatial resolutions of the cameras, which are related to the camera pitch angles and flight heights of UAVs.
- Degraded images: The load carried by a small UAV platform is subject to severe limitations, with respect to the size and battery. Complex external weather variations (e.g., fog, rain, cloud, snow, light, etc.) and rapid UAV flights have led to vague UAV imagery, namely image degradation [13].
- Plenty of small instances: Ground objects with areas smaller than 32 × 32 pixels (MS COC dataset’s definition of small objects) account for the majority of all objects in UAV images, as illustrated in Figure 1. Owing to the less diverse features of small targets, they may yield more errors and miss detection objects.
- Unbalanced object density: Uneven densities of captured objects are extremely prevalent in UAV images. In the same image, some objects may be densely arranged, while others may have sparse and uneven distribution, which are prone to repeated detection and missed detection, respectively.
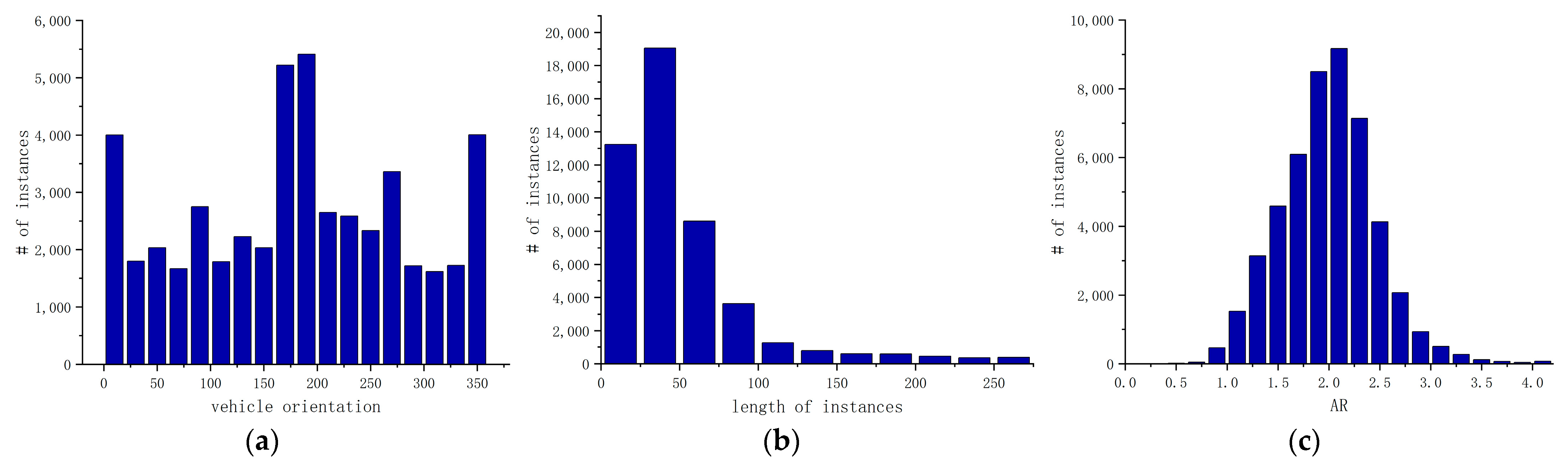
- Arbitrary orientations: objects in aerial images usually appear in any direction, as shown in Figure 1.
- To our knowledge, VSAI is the first vehicle detection dataset annotated with varying camera pitch angles and flight heights (namely multi-view) rather than almost-fixed heights and camera angles of other datasets for object detection. It can be useful for evaluating object detection models in aerial images under complicated conditions closer to real situations.
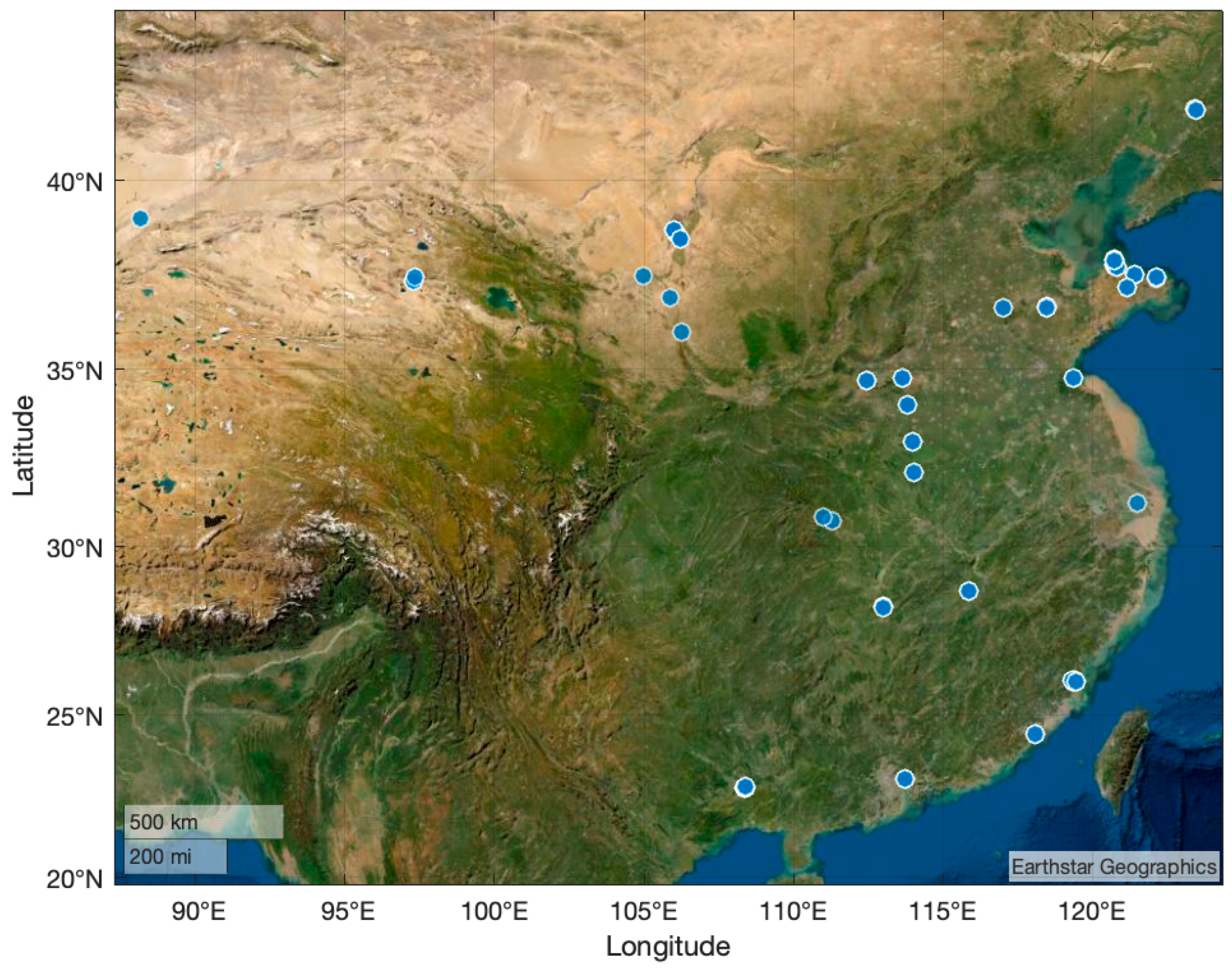
- Our dataset’s images c massive complex scenes (in exception for multi-view information) from many Chinese cities, such as backlights, the seaside, brides, dams, fog, ice and snow, deserts, tollbooths, suburbs, night, forest, Gobi, harbors, overhead bridges, crossroads, and mountainous regions, as shown in Figure 1.
2. Related Work
2.1. Drone-Based Datasets
2.2. Vehicle Object Datasets
2.3. Oriented Object Detection
3. Overview of VSAI
3.1. Image Collection
3.2. Category Selection
3.3. Annotation Method
4. Properties of VSAI
4.1. Multi-View
4.2. Complex Scenarios
4.3. Vehicle Statistics
4.4. Object Occlusion Ratio
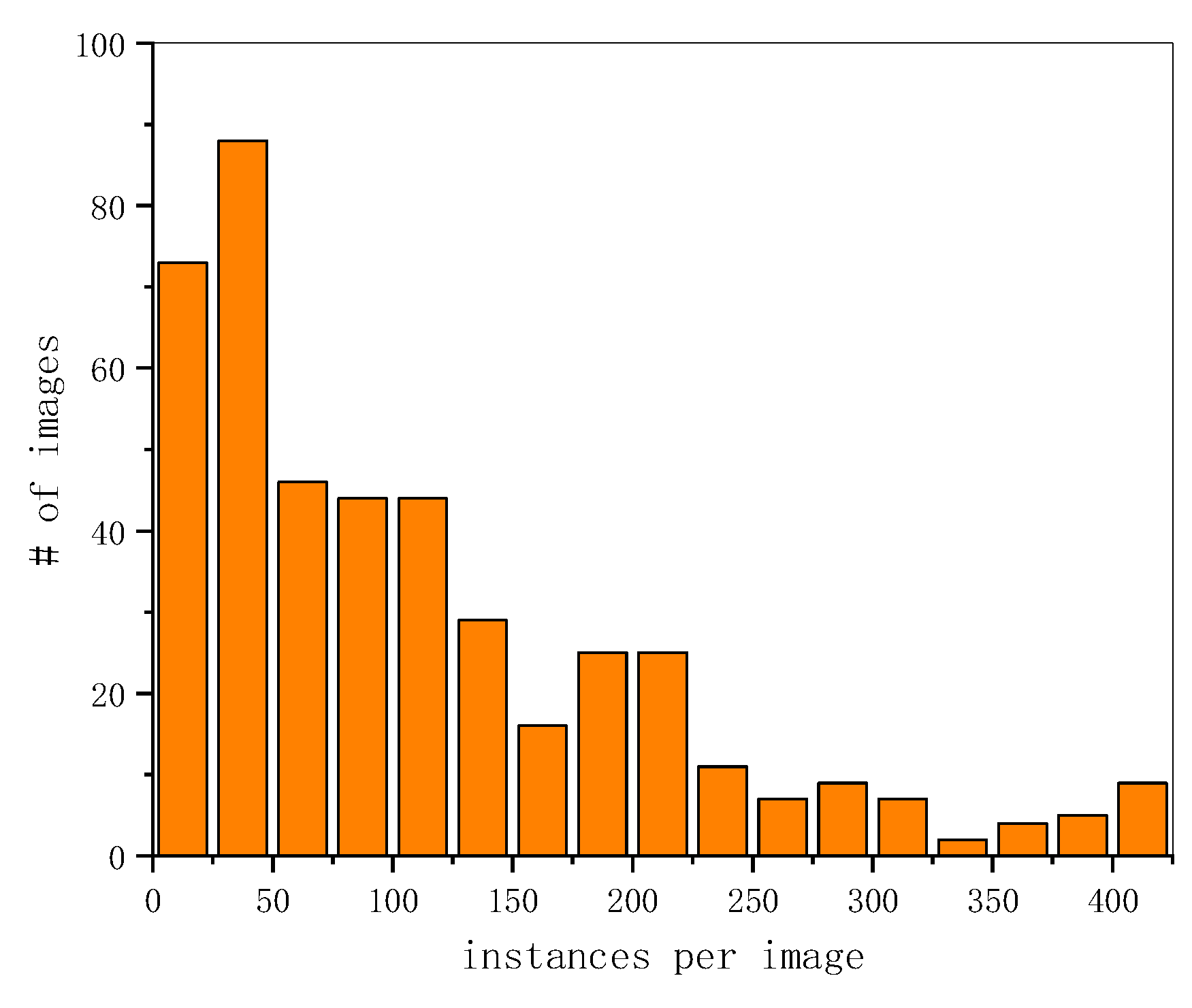
4.5. Average Instances
5. Method
5.1. RROI Learner
5.2. RROI Warping
5.3. Architecture of ROI Transformer
5.4. ResNeSt
6. Evaluations
6.1. Dataset Split and Experimental Setup
6.2. Experimental Baseline
6.3. Experimental Analysis
6.4. Cross-Dataset Validation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lin, Y.; He, H.; Yin, Z.; Chen, F. Rotation-invariant object detection in remote sensing images based on radial-gradient angle. IEEE Geosci. Remote Sens. Lett. 2014, 12, 746–750. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Rifd-cnn: Rotation-invariant and fisher discriminative convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2884–2893. [Google Scholar]
- Moranduzzo, T.; Melgani, F. Detecting cars in UAV images with a catalog-based approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly supervised learning based on coupled convolutional neural networks for aircraft detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Wang, G.; Wang, X.; Fan, B.; Pan, C. Feature extraction by rotation-invariant matrix representation for object detection in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 851–855. [Google Scholar] [CrossRef]
- Wan, L.; Zheng, L.; Huo, H.; Fang, T. Affine invariant description and large-margin dimensionality reduction for target detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1116–1120. [Google Scholar] [CrossRef]
- Ok, A.O.; Senaras, C.; Yuksel, B. Automated detection of arbitrarily shaped buildings in complex environments from monocular VHR optical satellite imagery. IEEE Trans. Geosci. Remote Sens. 2012, 51, 1701–1717. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An augmented linear mixing model to address spectral variability for hyperspectral unmixing. IEEE Trans. Image Process. 2018, 28, 1923–1938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Hsieh, M.-R.; Lin, Y.-L.; Hsu, W.H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 4145–4153. [Google Scholar]
- Li, S.; Yeung, D.-Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhang, H.; Sun, M.; Li, Q.; Liu, L.; Liu, M.; Ji, Y. An empirical study of multi-scale object detection in high resolution UAV images. Neurocomputing 2021, 421, 173–182. [Google Scholar] [CrossRef]
- Zhu, P.; Sun, Y.; Wen, L.; Feng, Y.; Hu, Q. Drone based rgbt vehicle detection and counting: A challenge. arXiv 2020, arXiv:2003.02437. [Google Scholar]
- Robicquet, A.; Sadeghian, A.; Alahi, A.; Savarese, S. Learning social etiquette: Human trajectory prediction in crowded scenes. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning rotation-invariant and fisher discriminative convolutional neural networks for object detection. IEEE Trans. Image Process. 2018, 28, 265–278. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Barekatain, M.; Martí, M.; Shih, H.F.; Murray, S.; Prendinger, H. Okutama-Action: An Aerial View Video Dataset for Concurrent Human Action Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Bondi, E.; Jain, R.; Aggrawal, P.; Anand, S.; Hannaford, R.; Kapoor, A.; Piavis, J.; Shah, S.; Joppa, L.; Dilkina, B. BIRDSAI: A dataset for detection and tracking in aerial thermal infrared videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1747–1756. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Zhu, P.; Wen, L.; Bian, X.; Ling, H.; Hu, Q. Vision meets drones: A challenge. arXiv 2018, arXiv:1804.07437. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Hu, Q.; Ling, H. Vision meets drones: Past, present and future. arXiv 2020, arXiv:2001.06303. [Google Scholar]
- Zhang, W.; Liu, C.; Chang, F.; Song, Y. Multi-scale and occlusion aware network for vehicle detection and segmentation on uav aerial images. Remote Sens. 2020, 12, 1760. [Google Scholar] [CrossRef]
- Bozcan, I.; Kayacan, E. Au-air: A multi-modal unmanned aerial vehicle dataset for low altitude traffic surveillance. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8504–8510. [Google Scholar]
- Azimi, S.M.; Bahmanyar, R.; Henry, C.; Kurz, F. Eagle: Large-scale vehicle detection dataset in real-world scenarios using aerial imagery. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6920–6927. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1452–1459. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented r-cnn for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8792–8801. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-Adaptive Selection and Measurement for Oriented Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022. [Google Scholar]
- Haag, M.; Nagel, H.-H. Combination of edge element and optical flow estimates for 3D-model-based vehicle tracking in traffic image sequences. Int. J. Comput. Vis. 1999, 35, 295–319. [Google Scholar] [CrossRef]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1083–1090. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Liu, K.; Mattyus, G. Fast multiclass vehicle detection on aerial images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2013. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-attention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Zhou, Y.; Xue, Y.; Zhang, G.; Wang, J.; Liu, Y.; Hou, L.; Jiang, X.; Liu, X.; Yan, J.; Lyu, C.; et al. MMRotate: A Rotated Object Detection Benchmark using PyTorch. arXiv 2022, arXiv:2204.13317. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 3163–3171. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
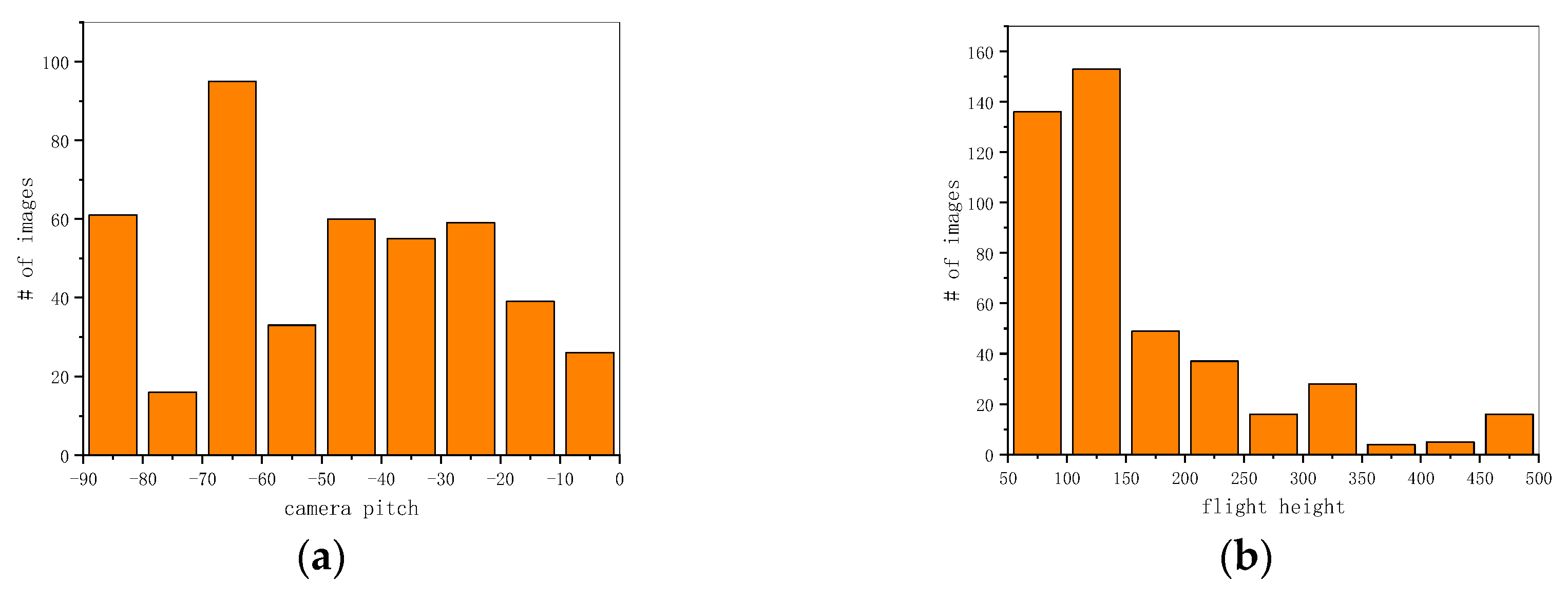{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Version | CMOS | Field Angle | Resolution |
|---|---|---|---|
| Mavic air | 1/2.3 inch | 85° | 4056 × 3040 |
| Mavic 2 pro | 1 inch | 77° | 5472 × 3648 |
| Phantom 3 Pro | 1/2.3 inch | 94° | 4000 × 3000 |
| Phantom 4 | 1/2.3 inch | 94° | 4000 × 3000 |
| Phantom 4 RTK | 1 inch | 84° | 5472 × 3648 |
| Dataset | Camera Pitch Angles | Flight Heights |
|---|---|---|
| MOHR [17] | −90° | About 200, 300, 400 m |
| VisDrone2019 [27] | Unannotated | Unannotated |
| Drone Vehicle [18] | −90° | Unannotated |
| Okutama-Action [23] | −45°, −90° | 10–45 m |
| EAGLE [30] | −90° | Between 300 and 3000 m |
| VSAI | From 0° to −90° | 55–500 m |
| Dataset | Vehicle Instances per Image | No. of Images | No. of Instances | Instances per Image | Image Width (Pixels) |
|---|---|---|---|---|---|
| UAVDT [25] | 841,500 | 80,000 | 841,500 | 10.52 | 1080 |
| DOTA [22] | 43,462 | 2806 | 188,282 | 67.10 | 300–4000 |
| EAGLE [30] | 215,986 | 8280 | 215,986 | 26.09 | 936 |
| DLR-3K-Vehicle [40] | 14,232 | 20 | 14,232 | 711.6 | 5616 |
| VSAI | 49,712 | 444 | 49,712 | 111.96 | 4000, 4056, 5472 |
| Method | Backbone | Split and Rotation | Type | AP [%] | ||
|---|---|---|---|---|---|---|
| SV | LV | Mean | ||||
| Rotated RetinaNet [45] | R50 | SS | One-Stage | 67.1 | 32.6 | 49.9 |
| R3Det [49] | R50 | SS | One-Stage | 69.6 | 38.5 | 54.0 |
| Gliding Vertex [33] | R50 | SS | Two-Stage | 70.3 | 42.5 | 56.4 |
| Rotated Faster R-CNN [44] | R50 | SS | Two-Stage | 70.7 | 44.0 | 57.3 |
| S²A-Net [31] | R50 | SS | One-Stage | 73.6 | 41.9 | 57.7 |
| Oriented R-CNN [34] | R50 | SS | Two-Stage | 76.9 | 43.1 | 60.0 |
| SASM [36] | R50 | SS | One-Stage | 76.7 | 45.2 | 60.9 |
| CFA [35] | R50 | SS | Two-Stage | 77.6 | 45.0 | 61.3 |
| ROI Transformer [32] | R50 | SS | Two-Stage | 77.4 | 38.4 | 57.9 |
| S50 | SS | Two-Stage | 77.7 | 46.2 | 62.0 | |
| R50 | MS | Two-Stage | 78.9 | 48.2 | 63.6 | |
| S50 | MS | Two-Stage | 78.8 | 49.8 | 64.3 | |
| R50 | MS, RR | Two-Stage | 79.0 | 49.2 | 64.1 | |
| S50 | MS, RR | Two-Stage | 79.4 | 50.4 | 64.9 | |
| Training Set | Test Set | SV | LV | mAP |
|---|---|---|---|---|
| DOTA | VSAI | 17.0 | 4.5 | 10.8 |
| VSAI | DOTA | 35.5 | 6.1 | 20.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Teng, X.; Li, Z.; Yu, Q.; Bian, Y.; Wei, J. VSAI: A Multi-View Dataset for Vehicle Detection in Complex Scenarios Using Aerial Images. Drones 2022, 6, 161. https://doi.org/10.3390/drones6070161
Wang J, Teng X, Li Z, Yu Q, Bian Y, Wei J. VSAI: A Multi-View Dataset for Vehicle Detection in Complex Scenarios Using Aerial Images. Drones. 2022; 6(7):161. https://doi.org/10.3390/drones6070161
Chicago/Turabian StyleWang, Jinghao, Xichao Teng, Zhang Li, Qifeng Yu, Yijie Bian, and Jiaqi Wei. 2022. "VSAI: A Multi-View Dataset for Vehicle Detection in Complex Scenarios Using Aerial Images" Drones 6, no. 7: 161. https://doi.org/10.3390/drones6070161