1. Introduction
Bed posture identification is an important topic for researchers due to its multiple and recent medical applications. The prevention of Pressure Injury (PI) is one of the most important problems, which affected over 2.5 million people in the US in 2020 [
1]. Concerning sleep quality, a continuous posture identification system is required to detect sleep disorders. In [
2], it was reported that over 70% of chronic medical disorders are correlated with sleep problems. Regardless of the application, the problem is reduced to distinguish between patient postures in bed based on continuous posture tracking systems. In addition, this issue can be complicated when an external object is located on the bed, for example, a pillow, perturbing the measurements with noise.
The ability to classify objects, textures, colors, and other features is an innate human ability based on their senses. However, currently, researchers are trying to replicate this process based on Machine Learning (ML) techniques in a wide variety of applications [
3,
4]. The main tasks of ML algorithms are to evaluate and compare different classes in data groups based on characteristics obtained from mathematical models. Through these models, a machine can learn those characteristics from the dataset [
5]. Here, the sample description is fundamental to differentiating between two or more classes. The classification model selection is based on the analysis of the advantages and disadvantages of the training and validation process [
6]. Also, the performance indicators of each classification model are well-founded statistical metrics; these evaluate the ability of a classifier to distinguish between classes. Therefore, according to the classification model selected, different ML algorithms have been proposed that stand out: artificial neural networks (ANN), Decision Trees, K-means, K-nearest neighbors (KNN), and Support Vector Machines (SVMs). Specifically, the SVM is one of the most known techniques for learning features of a dataset. The SVM is a supervised learning model, which provides an efficient tool for data classification and regression analysis [
7]. In layman’s words, the SVM model is a representation of datasets as points in a defined space, which can be separated by categories based on well-defined gaps. So, the data can be divided into different classes based on two principal stages: training and validation.
Several strategies have been applied to identify body postures in bed by using the SVM technique. In [
8], a system was implemented that uses Electrocardiogram (ECG) data employing capacitively coupled electrodes and a conductive textile sheet. Here, an SVM with Radial Basis Function (RBF) was implemented to estimate only four body postures on the bed. In [
9], the subject position was monitored by fiber-optic pressure sensor mats and classified using an SVM and linear classifiers. This research reported the identification of three positional states. The Received Signal Strength (RSS) measurements and the SVM and K-nearest neighbor methods were employed to identify the position in the bed of two different persons in [
10].
Investigating another SVM application, ref. [
11] proposed a method for detecting animal sperm tracks in an automatic system for reproductive medicine. They used images in which the sperm is shown in the first frame of all sequences, employing a bag-of-words approach and an SVM classifier. The detected sperm cells were tracked in all sequences using mean shift. Three videos were used as the experimental sample frames. The results showed a precision of 0.94, 0.93, and 0.96 in terms of sperm detection. Regarding sperm tracking, they calculated the root-mean-square error for assessment. In addition, knot detection was automatically identified in an image processing pipeline by [
12]. They implemented contrast enhancement, thresholding, and mathematical morphology on images with wood boards. The features were obtained using the Speeded-Up Robust Features (SURF) descriptors on RGB images, which was followed by the creation of a dictionary using the bag-of-words approach, which vectorizes text in terms of a matrix. Two different datasets were implemented, with a total of 640 knots. The recall rate achieved was between 0.92 and 0.97, with a precision of 0.90 and 0.87. In addition, applications with images are used in agricultural areas. A methodology for identification of the disease powdery mildew using diseased leaf images was proposed by [
13], in which the implementation of a Support Vector Machine was used to identify the powdery mildew in cucurbit plants using RGB images and color transformations. First, they used an image dataset from five growing seasons in different locations in natural conditions of light. Twenty-two texture descriptors using the gray-level co-occurrence matrix result were calculated as the main features, and a statistical process [
14] was used for the feature selection. The proposed damage levels identified were healthy leaves, leaves in germination time of the fungal, leaves with first symptoms, and diseased leaves. The implementation revealed that the accuracy in the L*a*b* color space was higher, with a value of 94% and a
kappa Cohen of 0.7638.
In [
15], a system with a low-resolution pressure sensor array and an SVM classifier with a linear kernel was presented to identify four basic positions. However, the implementation of this method requires advanced knowledge in signal processing, or the samples should be conditioned according to the physical characteristics of the patient. Also, the pressure array information is preferably exhibited in color images to be processed [
16,
17,
18].
Patient posture identification based on images and ML techniques is considered a feasible solution [
19,
20,
21]. In [
21], solutions were reviewed regarding the use of sensor-based data with images as information derived from intelligent algorithms to provide healthcare to patients at risk of developing pressure ulcers. The implications of this review and our results are derived from a possible solution in medical care. Due to our proposed postures, we achieved the identification of the pressure points. They selected 21 studies about sensors and algorithms relevant to recommendations for patients, although this review had the objective of obtaining a general architecture for a prevention system for pressure ulcers. To classify posture images, it is required to extract their visual information based on statistical operations [
22]. These data are known as descriptors and can describe form, color, or texture. The selection of a descriptor is conditioned to the origin and content of the images. Also, the information obtained from descriptors is different according to the color space of the image. So, the task of choosing the optimal color space and descriptor becomes challenging for image classification. In particular, the pressure images have a low resolution, and external objects hide the relevant information for ML algorithms. Given the diversity of variables, several strategies have been proposed to classify the postures based on image processing [
23,
24,
25,
26]. In these works, a pre-processing stage is suggested that refers to the conditioning of the images before they are processed by the ML algorithm. Nevertheless, these propose to use complex or computationally heavy algorithms, which require advanced knowledge in signal processing, or avoid the use of high physical resources of the computer equipment.
In this work, we propose a methodology to identify patient posture in bed based on an SVM algorithm and low-resolution pressure images, selecting the best texture descriptors and color space. For this study, it was crucial to find the most suitable texture descriptors to obtain a high accuracy in posture identification. Based on sample processed images with a median filter and histogram equalization, the feature extraction with texture descriptors and feature selection with multivariate statistical characteristics are used to classify four proposed bed postures. First, we introduce image pre-processing of the images based on the histogram equalization and median filter. Then, a feature extraction process is implemented with the calculus of the gray co-occurrence matrix to obtain the texture descriptors. Multivariate statistical methods are proposed for the feature selection to choose the best texture descriptors to avoid the over-pre-processing in the image samples. Finally, a classification through Support Vector Machines and performance evaluation with the confusion matrix are performed.
The rest of this manuscript is organized as follows. In
Section 2, the theoretical foundations of the Support Vector Machines are described. The methodology, including the image pre-processing, the feature extraction, the feature selection, and classification, is explained in detail in
Section 3. Here, a performance evaluation with a confusion matrix is shown with the percentages of the classified data of different postures. Consequently, the results and discussion according to the identification of the postures and the comparison between the results of the images in different conditions are presented in
Section 4. Finally, in
Section 5, the conclusions are described in detail.
4. Results
In this study, feature extraction was used to identify four postures of different patients in bed with several trained SVMs. Once the multi-class problem was established and the structure for a multi-classification was constructed, the identification process for the four postures could be completed. Aiming to compare the results, two alternatives were employed: the SVM based on Principal Component Analysis (PCA) and traditional Convolutional Neural Networks (CNNs). The SVM with PCA was selected to compare the same procedure with a different feature extraction method. Meanwhile, the CNNs are highly appropriate for image classification tasks even though these can be considered a standard option for such tasks due to their effectiveness [
47].
The method of Principal Component Analysis (PCA) is incorporated into feature extraction and classification with an SVM. PCA is one of the most important algorithms for calculating the characteristics and reducing the dimension of data. Also, PCA is widely used in image classification with different types of images [
48,
49,
50]. This technique was employed by using the image posture database without additional processing and normalizing the results, in the same way as the texture descriptors, before incorporating it into the SVM.
CNNs are a class of deep neural networks designed for processing structured grid data, such as images. These techniques are particularly powerful for tasks like image classification, object detection, image segmentation, and feature extraction from images. Classification with CNNs is based on a hierarchical pattern of layers to automatically and adaptively learn spatial hierarchies of features from the input data [
51]. Three CNN architectures were employed: VGG-16, MobileNet, and DenseNet121. As a CNN is a deep learning framework, for the purpose of comparing our results, we decided to use VGG-16, MobileNet, and DenseNet121, which are among the most commonly used CNN models. VGG-16 is a 16-layer CNN model with 95 million parameters and was trained on over one billion images divided into classes. This model uses input images of size 224 × 224 pixels with 4096 convolutional features. It is efficient and widely used for various applications in computer vision, including object detection. MobileNet is a model that can be used in a mobile application to classify images or detect objects with small CNN architectures employed in embedded devices. MobileNet contains 100–300 layers and can automatically identify common objects in images. DenseNet121 is a model in which each convolutional layer, except the first one, receives the output of the previous convolutional layer and produces an output feature map that is passed on to the next convolutional layer. It allows for feature reuse, as redundant feature maps are discarded from all preceding layers. The impact on the execution of epochs in each CNN model depends on the task, the image datasets, and the optimization process in the classification. They were implemented following the same procedure, modifying only the execution epochs to 10, 15, and 15 for VGG-16, MobileNet, and DenseNet121, respectively. In our implementation, the CNNs were constructed with a specific architecture comprising two dense hidden layers, each consisting of 256 neurons, followed by an output layer consisting of four neurons. The activation functions used were Rectified Linear Units (ReLU) for the hidden layers and Softmax for the output layer. Finally, we leveraged the power of transfer learning by freezing the pre-trained layers of a specific model. For CNNs, the dataset was divided into 80% for training and 20% for testing. Additionally, the images were resized to 150 × 150 pixels, and a batch size of 32 was selected.
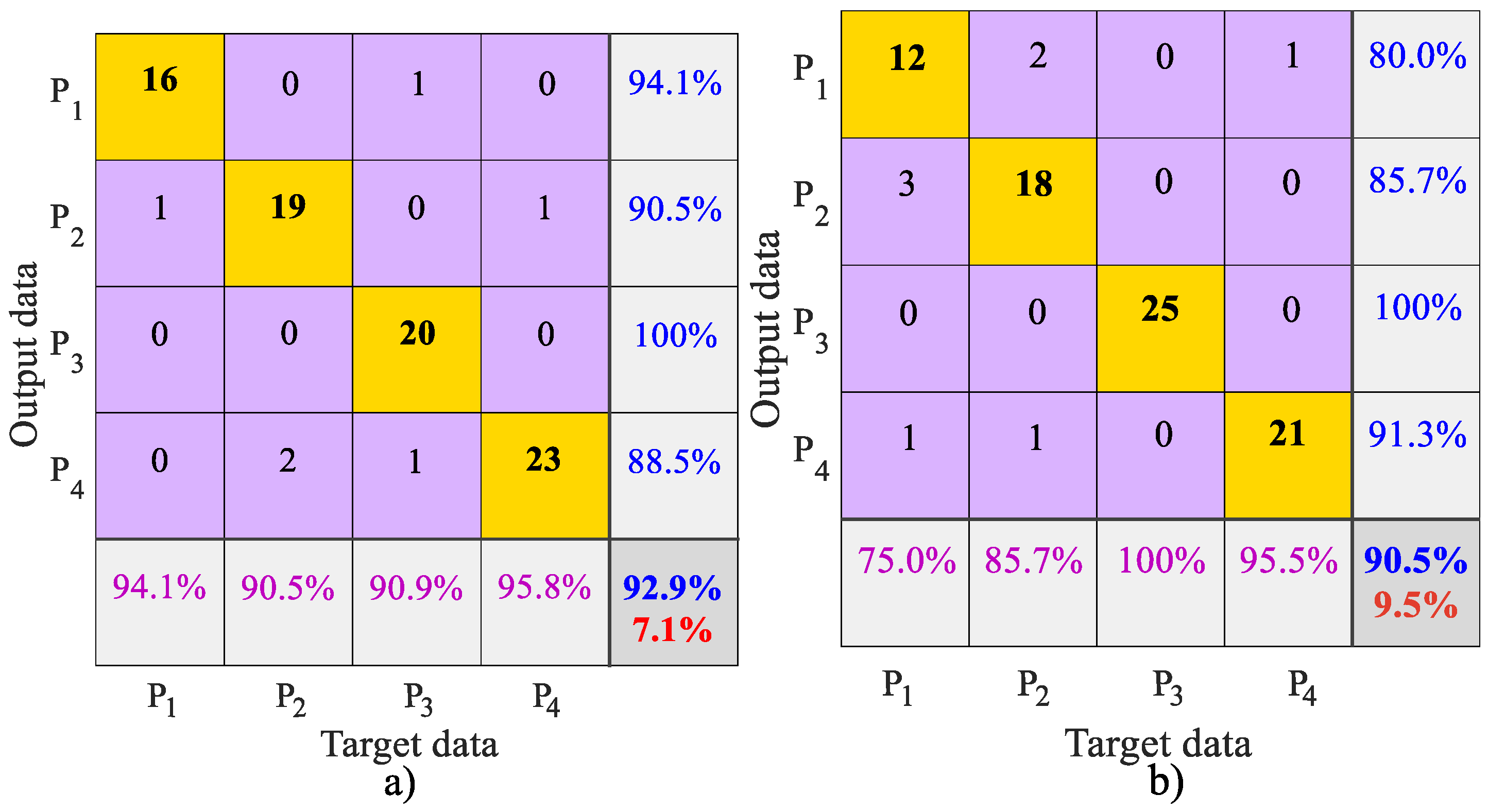
After a series of tests, the results to classify each posture,
,
,
, and
, are presented and analyzed through confusion matrices, accuracy, and the
kappa coefficient for the SVM method. The results based on the confusion matrix are presented in
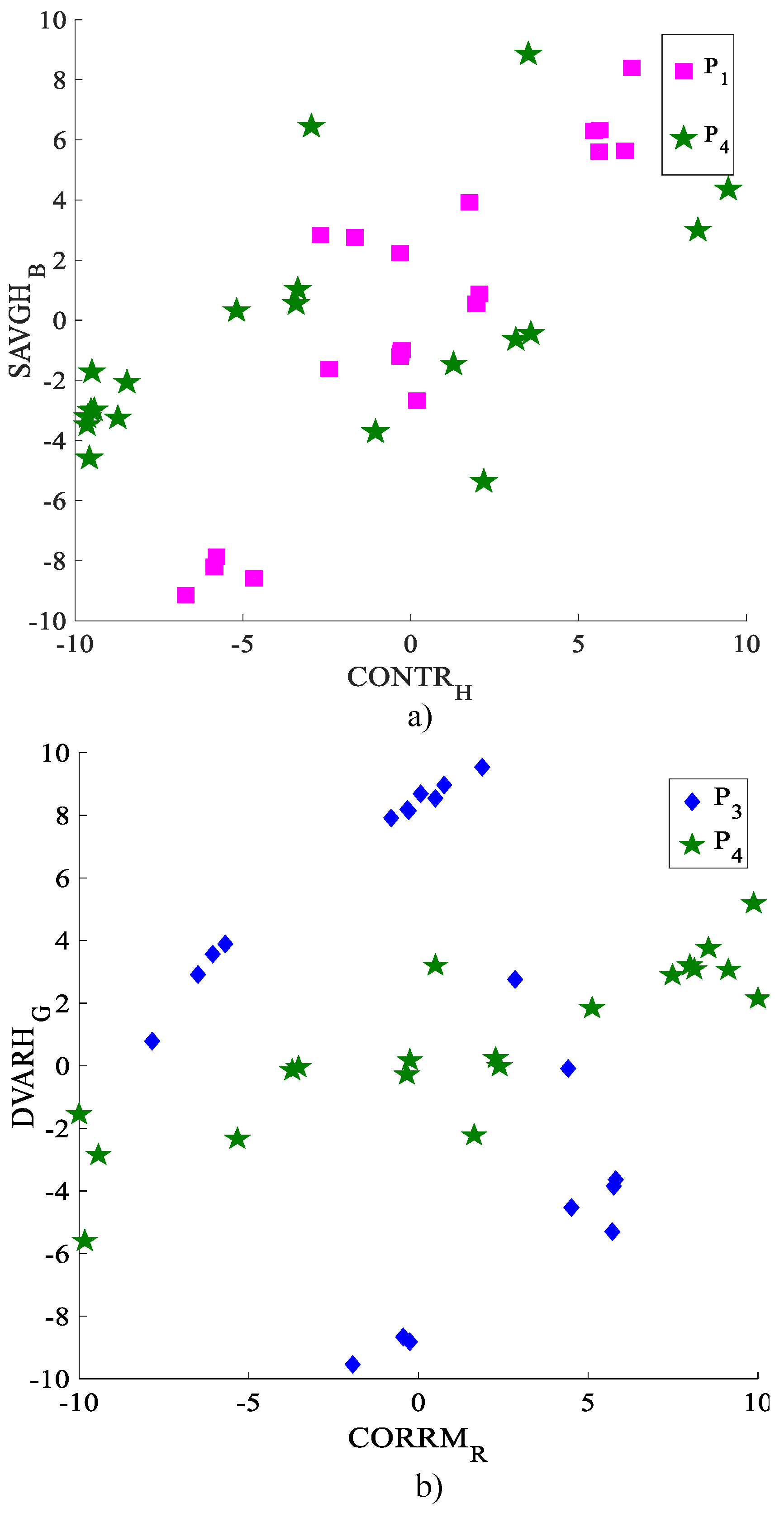
Figure 6; this allows the number of classified images with a concordance agreement to be counted to define data confidence. The best results of the classification are obtained with the characterized images in set
. These results describe that the postures
and
achieve the best identification percentages, with 100% and 94.1%, while
and
obtain 90.5% and 88.5%, respectively. These percentages are achieved by using feature vector
in the space color RGB, which are shown in
Figure 6a. The classification percentages of feature vector
are shown in
Figure 6b; the highest accuracy is for
, with 100%, while the posture
is classified with 91.3%. The precision achieved by
and
is 80% and 85.7%, respectively, with samples of color components in HSV. Therefore, set
describes the postures with the best discrimination. The total positive percentage of the classification in
is 92.9%, with an error of 7.1%, in comparison with
with 90.5%.
Following the same procedure, the confusion matrices were obtained for the classification based on the SVM by using the PCA components. The results are illustrated in
Figure 7. Here, the accuracy reached for the sample
in the RGB color component is 69%, while, for the sample vector,
in the HSV color component is 70.2%. It can be noted that the performance of the SVM based on PCA is lower than that of the SVM with the vectors
and
previously structured. The accuracy difference to classify the postures based on RGB and HSV color components is 23.9% and 20.3%, respectively.
Regarding the results obtained by the CNNs previously described, the architectures MobileNet and DenseNet121 obtain the best classification results with a total accuracy of 96% and 94%, respectively. The CNNs based on VGG-16 achieve a 92% effectiveness for classifying the postures in bed. The three architectures proposed perfectly identified the position and , except for VGG-16, which obtained an accuracy of 80% in . Here, the lowest results of CNNs identifying the posture were obtained by VGG-16 with 86.67% and MobileNet with 92.86%. Meanwhile, the posture was identified with different percentages of 90% for the VGG-16, 94.74% for MobileNet, and 86.36% for DenseNet121.
The results of each classification method are summarized in
Table 6, where the accuracy percentages and the
kappa values are presented. The worst results based on the
kappa metric are obtained by the SVM with PCA method. This method reaches
in the RGB color component and
in the HSV color component. The best accuracy is obtained by the CNNs based on the MobileNet architecture method, with a 96% total accuracy and
, followed by the CNNs with DenseNet, which obtain an accuracy of 94% and
. Our proposed approach achieves higher precision and kappa values, slightly outperforming the metrics achieved by the CNN based on VGG-16. These minimal differences are 0.9% in total accuracy and 0.074 for
kappa values. Despite our proposal being located in third place according to the results presented in
Table 6, the differences concerning the second and first place are 1.1% and 3.1% in total accuracy and 0.0114 and 0.04 in
kappa values. It should be noted that CNNs are more complex methods, and are specialized in image classification. However, this comparison was realized to show the grade of precision that can be achieved with a technique that more simply selects the optimal texture descriptors, i.e., the descriptors to achieve the maximal accuracy for the in-bed image classification.
It should be noted that CNNs are more complex, robust, and specialized methods for image classification than an SVM. However, this comparison was conducted to showcase the level of precision that can be achieved with a simpler technique by selecting optimal texture descriptors, i.e., the descriptors for the SVM that yield the highest accuracy for classifying in-bed posture images.
An ROC curve presents the concept of discrimination. The Y-axis of the ROC curve graph represents the proportion of true positives over the total data belonging to one position (sensitivity), and the X-axis represents the proportion of false positives over the total data of another position (specificity). Therefore, an ROC curve plot illustrates the ’proportion of true positives’ (Y-axis) versus the ’proportion of false positives’ (X-axis) for each cut-off point of a classification test whose measurement scale is continuous. A line is drawn from point 0.0 to point 1.1, representing the diagonal or non-discrimination line. This line describes what would be the ROC curve of a classification test unable to discriminate [
40], for example, one class 1 (
) versus class 2 (
), because each cut-off point that composes it determines the same proportion of true positives and false positives. A discrimination test will have a greater identification capacity to the extent that its cut-off points plot an ROC curve as far as possible from the non-discrimination line, as close as possible to the left and upper sides of the graph.
For a graphic comparison of performance, the ROC curves are plotted in
Figure 8; these graphs describe the relationship of
against the
results that show the scoring classifier [
40]. In
Figure 8a,b, the posture
reaches the coordinate (0, 1), obtaining a perfect classification by using both feature vectors
and
in RGB and HSV color components, respectively. The postures
,
, and
are near to the perfect coordinate in
Figure 8a, almost closer than the numbers computed employing the feature vector
in the HSV space color. In the same way,
Figure 9 shows the ROC curve for the SVM and PCA methods. In
Figure 9a, a considerable distance from the perfect classification for the postures
,
, and
can be noted, with an accuracy of 76.9%, 66.7%, and 54.8%, respectively, while the best classification is for the samples for
with an accuracy of 82.1%.
Figure 9b shows that the scores of the SVM with PCA for the HSV and RGB color components are similar, with accuracy levels of
,
, and
being 66.7%, 68.4%, and 57.1%, respectively. The ROC curve closest to perfect classification is the one for the posture
, with 83.3%, in
Figure 9b.
In spite of the classification accuracy being less than that reported in [
23], it is worth highlighting that the principal purpose of this work was to simplify the stage of image pre-processing. The results obtained employing the proposed methodology are considered excellent based on established metrics. Additionally, it should be considered that the number of patient positions to be identified was increased and that only basic techniques were employed, such as a median filter and histogram equalization.
In the literature, different methodologies have been proposed in which image pre-processing is used for feature extraction and the identification of objects, with different algorithms presenting high accuracy. Additionally, for future researchers, applying the utility of these results and using our proposal in monitoring medical patients with varying characterized parameters would be beneficial. However, some of the processes are robust and complex due to the implementation involving a series of intricate mathematical calculations. One purpose of differentiating between in-bed postures was to demonstrate that such methods can indeed be simple and applicable to other areas.
In this study, some limitations and considerations involve optical devices and experimental issues that affect the quality of the sample image. Environmental and real conditions in hospitals, such as changes in object hue due to luminosity, external objects, textures, camera and sensor distance, and time, can influence image acquisition in patients. Regarding limitations in the image processing area and the time consumed by computing limits, there are two situations. Firstly, the time for image pre-processing and sample conditioning for feature extraction. For this work, the raw images were in low resolution, aligning with the image quality and the proposed feature extraction methodology. Secondly, the time for the training and validation phases used for the classifiers. To select a binary classifier, it is necessary to identify the behavior of the samples through a cross-validation process, depending on the number of samples and the portion of training data to use. The approach of this study was to use selected features of the images as the proposed optimal texture descriptors for in-bed postures. According to the final results, high accuracy performances were obtained with these features; therefore, they are considered useful for future studies applied to medical uses. With these results, some characteristic color components converted into texture descriptors have sufficient class separability.
5. Conclusions
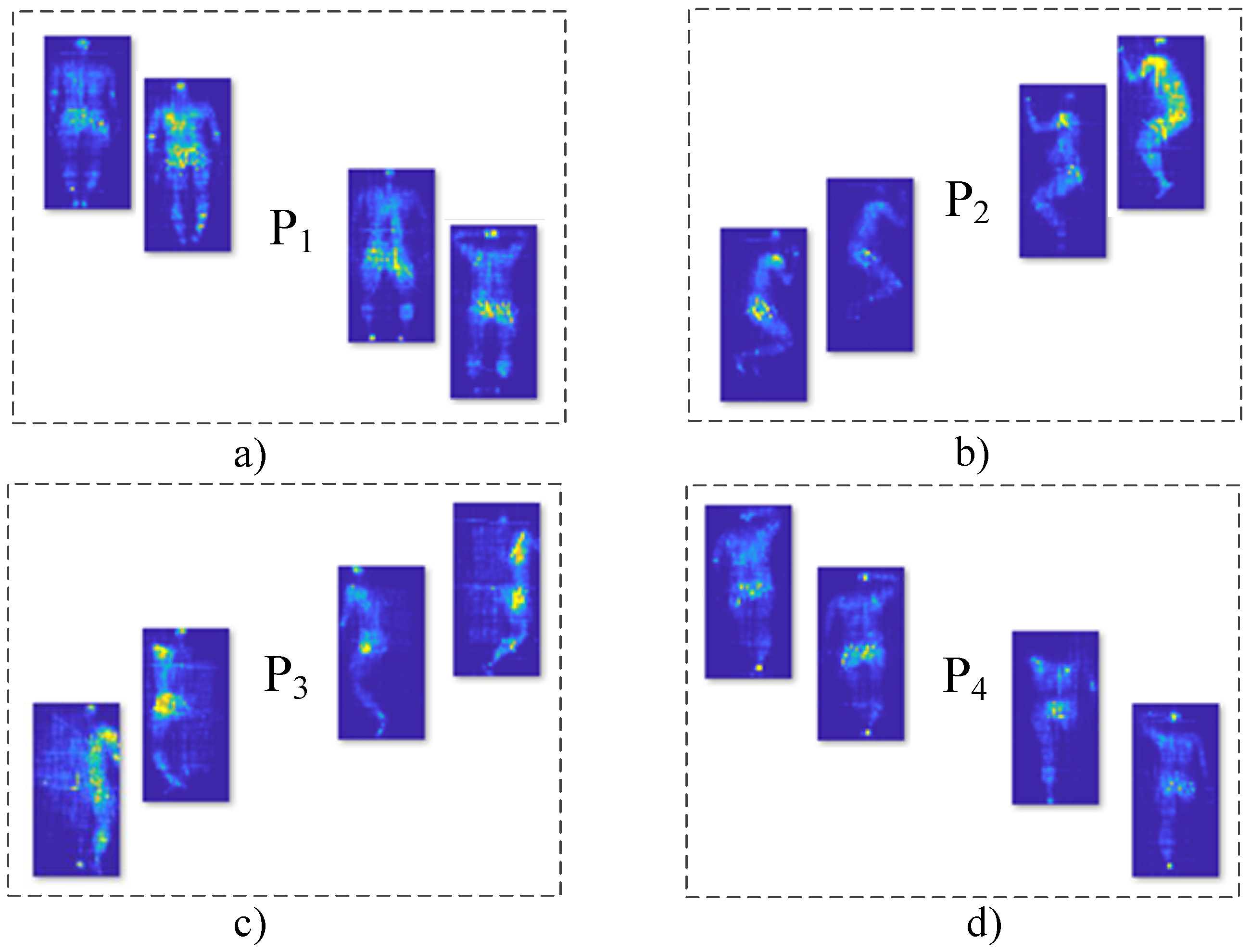
In this work, we proposed the identification of a patient’s posture in bed based on Support Vector Machine training with minimal sample preconditioning. The images were analyzed based on three important stages: sample conditioning, feature extraction, and classification. In the sample conditioning stage, the images are submitted to histogram equalization and a median filter, aiming to avoid complex and computationally heavy pre-processing for the images to be classified. Based on the database description, two experiments were carried out by applying the median filter (MF) to all samples and by using the same filter only for because it presented an external object. From this phase, it was corroborated that the position required an additional treatment due to an obstacle that made it difficult to appreciate the position of the patient. However, it was demonstrated in the first experiment that an MF is enough to remove the disturbances in the images of position and thus improve their classification accuracy. The identification of samples , , and was affected if the MF was applied; this was corroborated with the accuracy and kappa metrics in a second experiment.
Due to the characteristics of the images depicting patient positions, the selection of texture descriptors was a challenging task. Twenty texture descriptors were employed, and the optimal ones were chosen based on two well-known metrics: ANOVA and the Tukey test. These parameters suggest that different texture descriptors can be utilized based on the color component, whether RGB or HSV.
Nevertheless, in the classification stage, the results suggest that the RGB color component is the most effective for classifying the pressure database of patients. It was also confirmed that the best feature vector can be formed with the data of contrast, correlation, sum of squares, difference of variance, sum average, and information measure of correlation. The classification performance using these variables achieved an accuracy of 92.9% and a kappa of 0.904. Specifically, position could be perfectly classified as long as an MF was applied beforehand. The positions , , and obtained distinction percentages of 94.1%, 90.5%, and 88.5%, respectively. Despite the widespread use of an SVM with PCA for image classification, this technique showed lower performance, as demonstrated by confusion matrices, kappa values, and ROC curves.
Aiming to assess the performance of our proposal, Convolutional Neural Networks were implemented with different architectures to serve as a reference point. Specifically, CNNs based on MobileNet and DenseNet121 obtained the best results, although with minimal differences of 1.1% and 3.1% in total accuracy and 0.0114 and 0.04 in kappa values, respectively. Therefore, this comparison demonstrates and categorizes the precision that can be achieved by using an SVM while selecting the optimal texture descriptors.
This work proposes simplifying the image pre-processing phase to achieve the classification of a patient’s position in bed by adequately training a Support Vector Machine. The conclusions drawn from this study can assist inexperienced researchers in classifying pressure images and reducing sample preparation time and guide the selection of appropriate color components and texture descriptors.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}