


Efficient Method for Continuous IoT Data Stream Indexing in the Fog-Cloud Computing Level

 , ,
, , 
Abstract
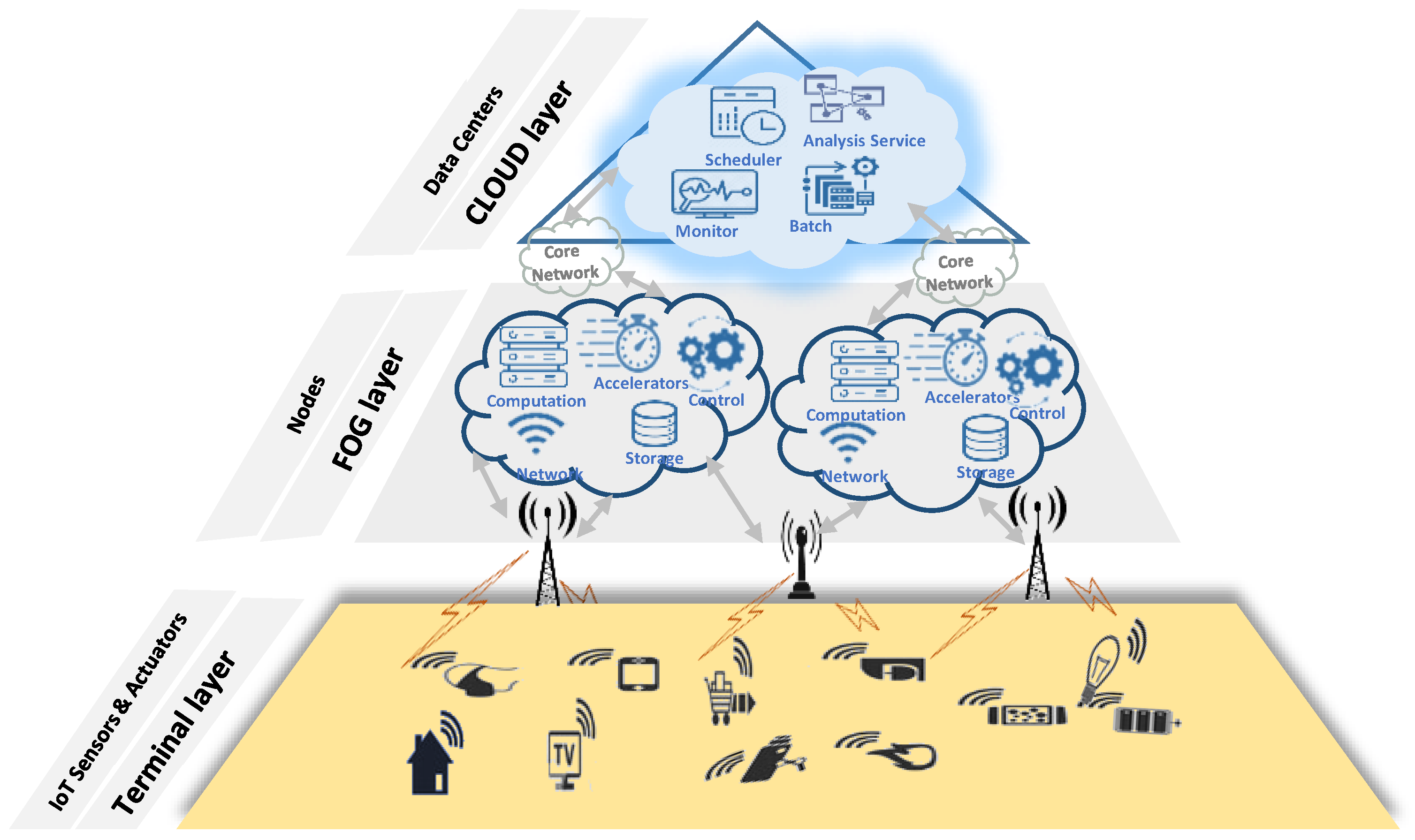
:1. Introduction
2. Related Work
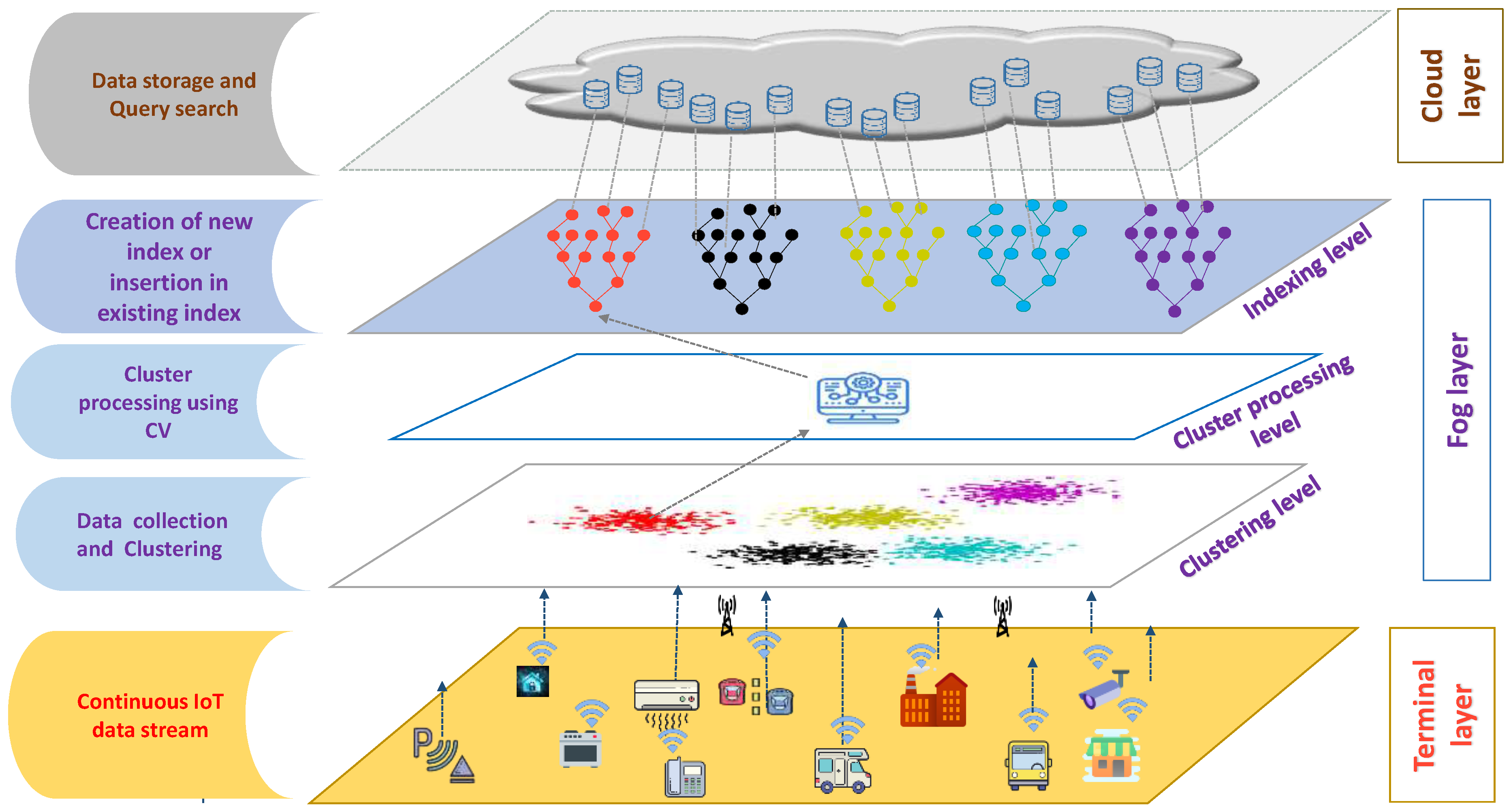
3. Proposed Approach
3.1. Clustering Method
3.2. CV Method
| Algorithm 1 CV method |
| Require: Ensure: for each data stream do for do Calculate the coefficient of variation of the new cluster for do Calculate the coefficient of variation of if then create new index () else insert in end if end for end for end for |
3.3. Indexing Method
- , are two unconfused objects, , called “pivots”. They define the hyper-plane.
- L is a left sub-tree and R is a right sub-tree.
3.4. The kNN Similarity Queries Search
| Algorithm 2 The kNN search in the BH-tree |
| kNN-BH-tree with: query ball q with radius if then return A else Calculate the distances and if then else end if for do if then end if for each node do if then end if end for end for end if |
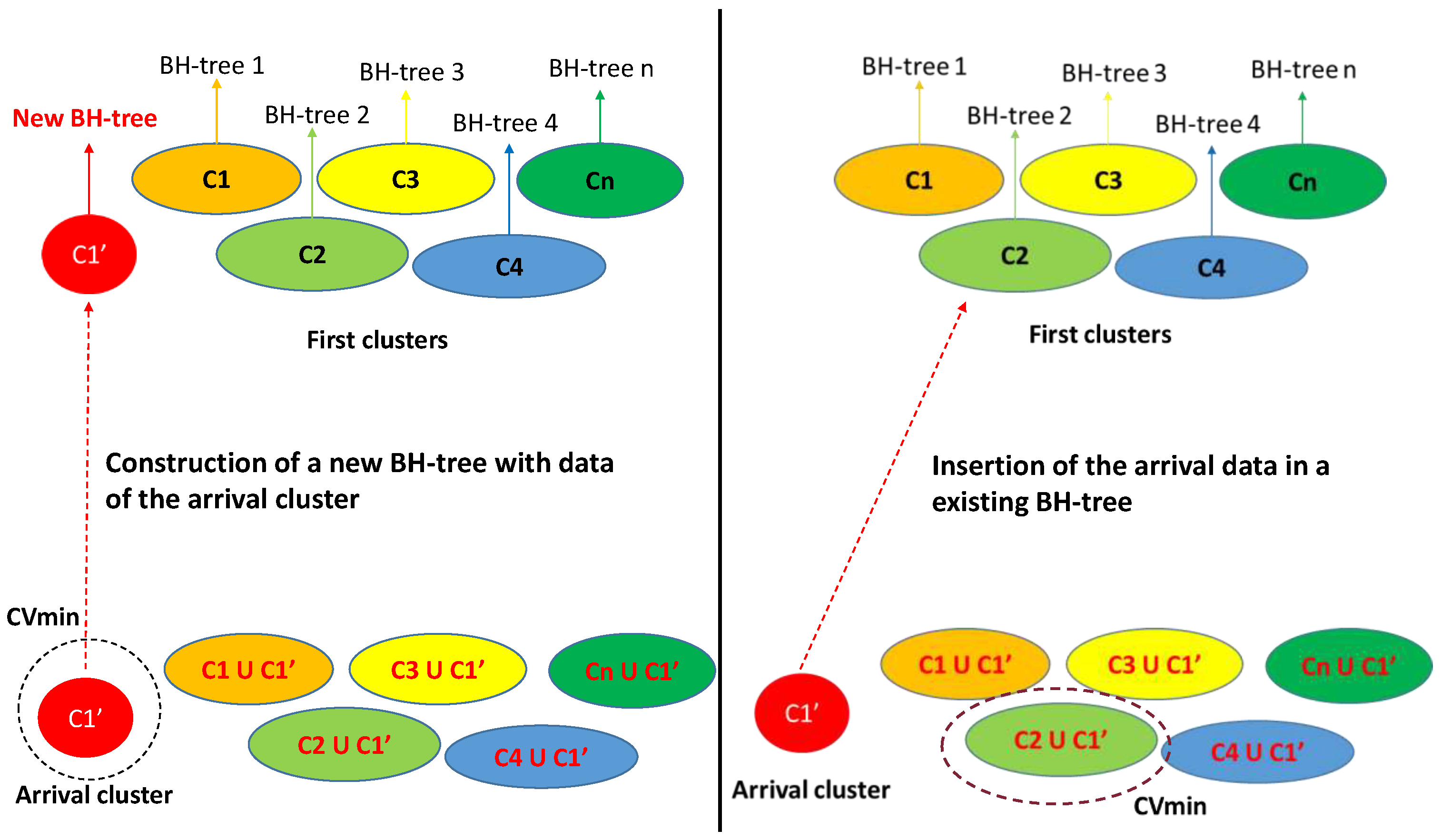
3.4.1. CNI Method
| Algorithm 3 CNI method |
| Require: Ensure: for each data stream do for do create new index( ) end for end for |
3.4.2. IEI Method
| Algorithm 4 IEI method. |
| Require: Ensure: for each data stream do for do for do calculate distances insert in end for end for end for |
4. Experimentation
4.1. Experimental Settings
- GPS Trajectories: collected from Go!Track Android application [41]
- Tracking dataset: moving vectors generated by an object tracking simulator with wireless cameras in the wireless multimedia sensor network in a random simulation [31]
- Wearable Action Recognition Database (WARD): database of human action reconnaissance using wearable movement sensors [42]
- Traffic dataset: belongs to the road network category [43]
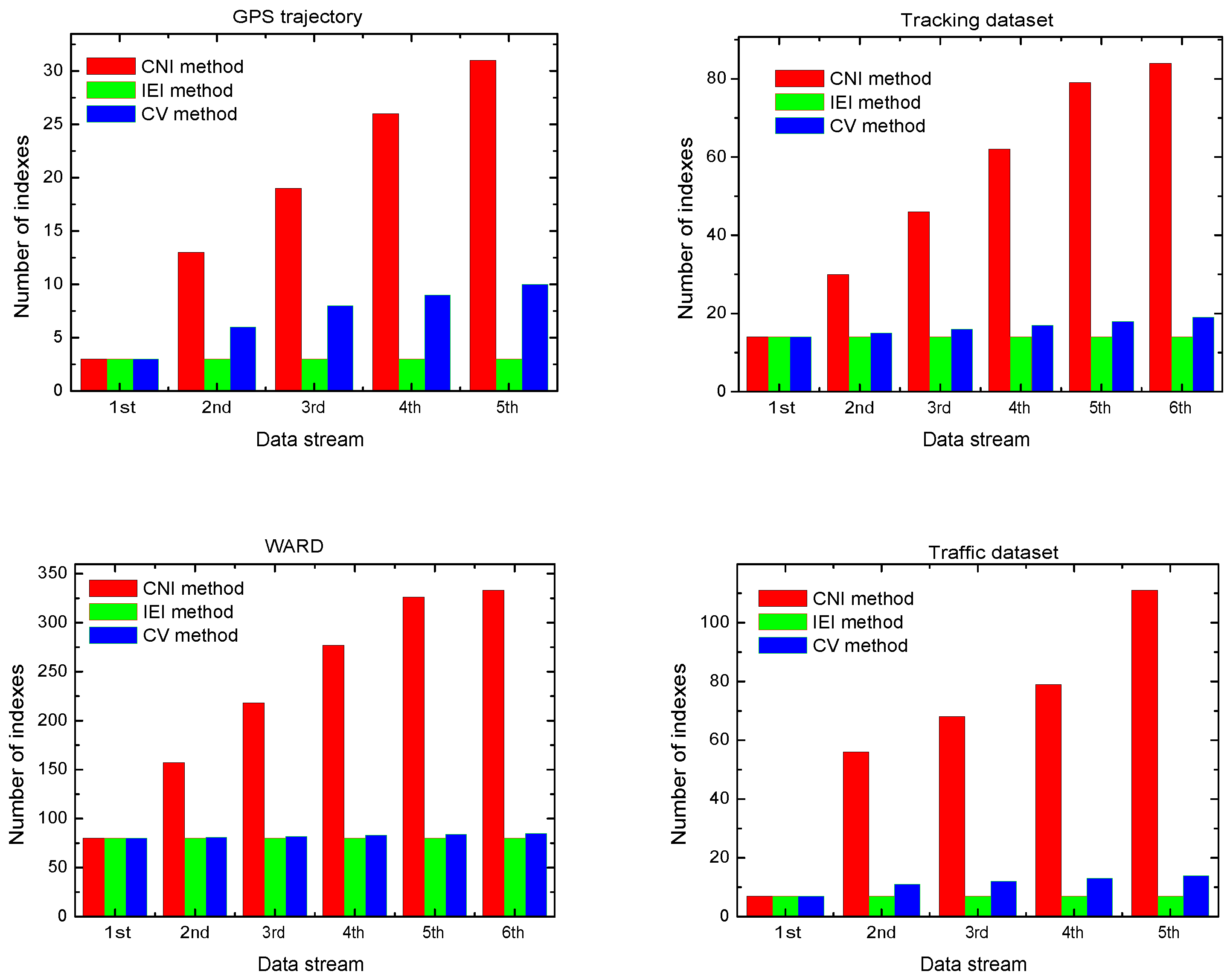
4.2. Evolution of the Number of Indexes with Data Stream
4.3. Evaluation of Index Construction
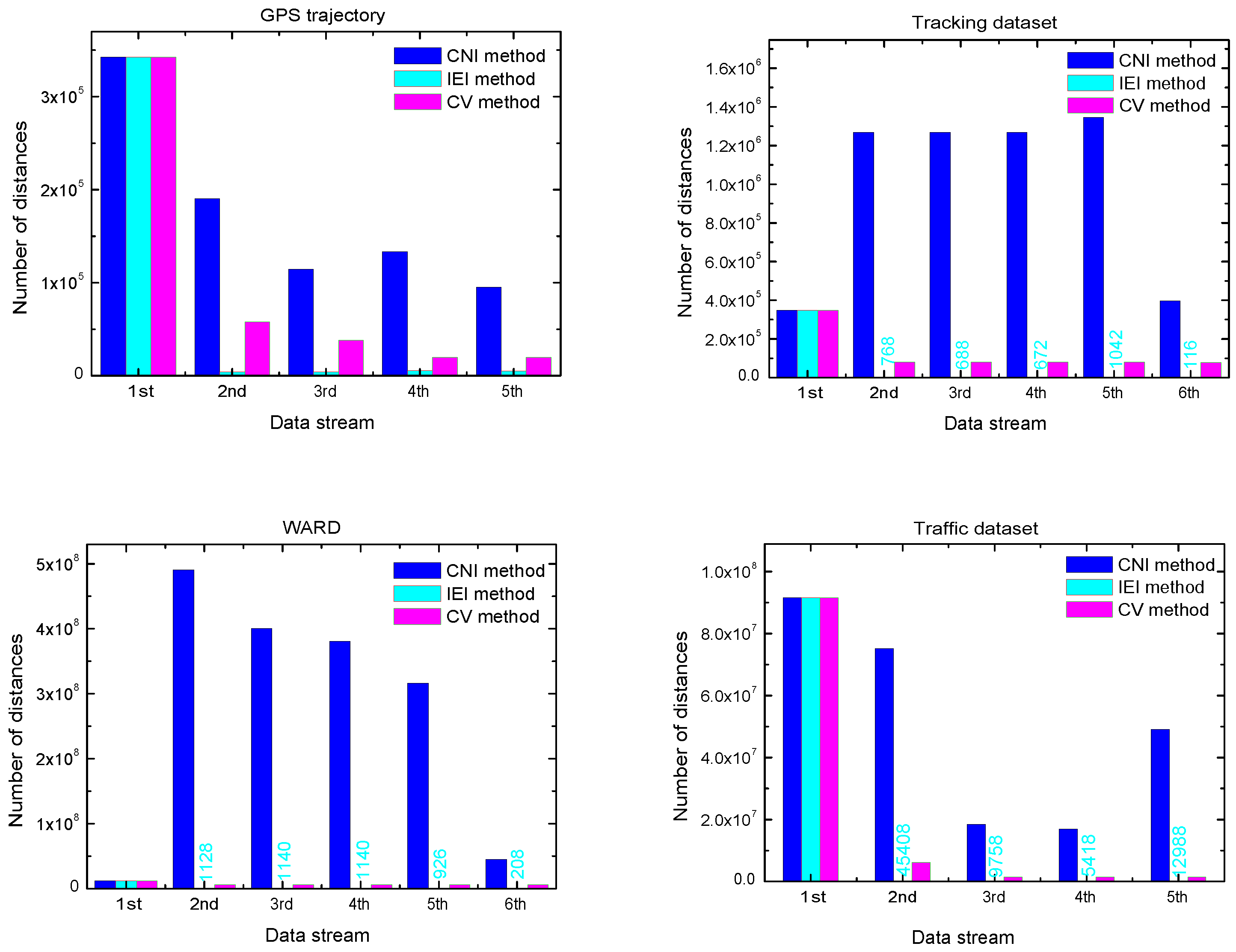
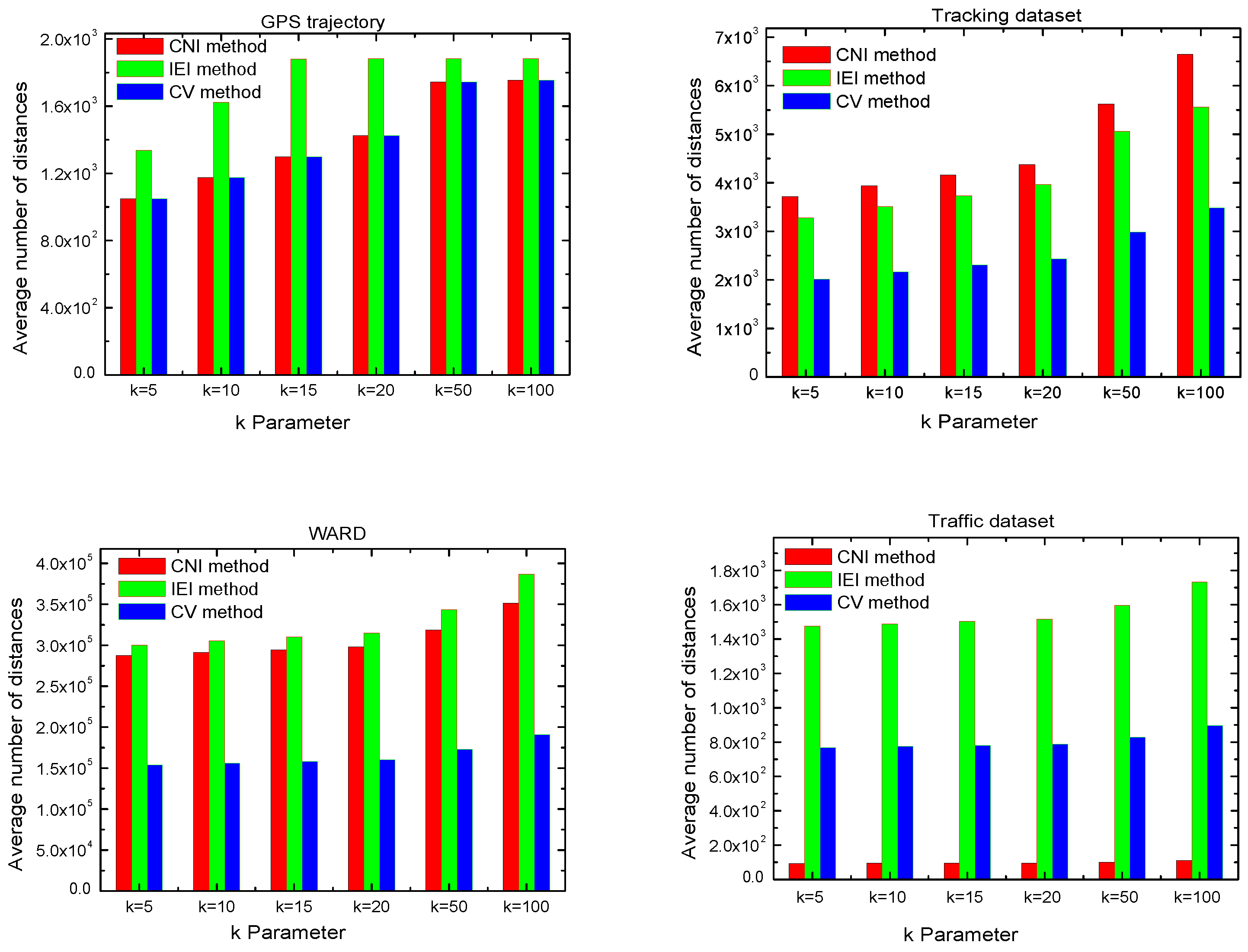
4.3.1. Number of Calculated Distances
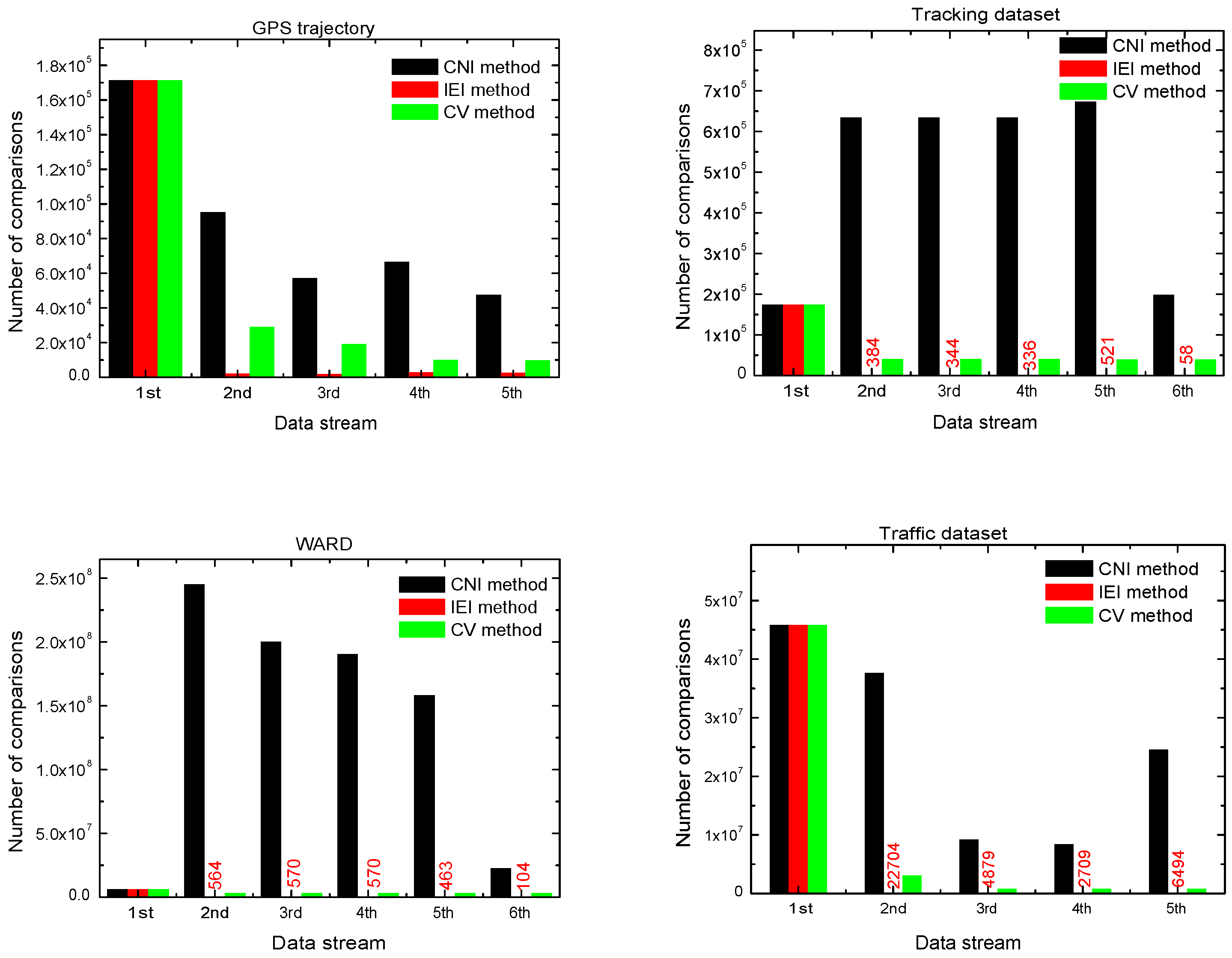
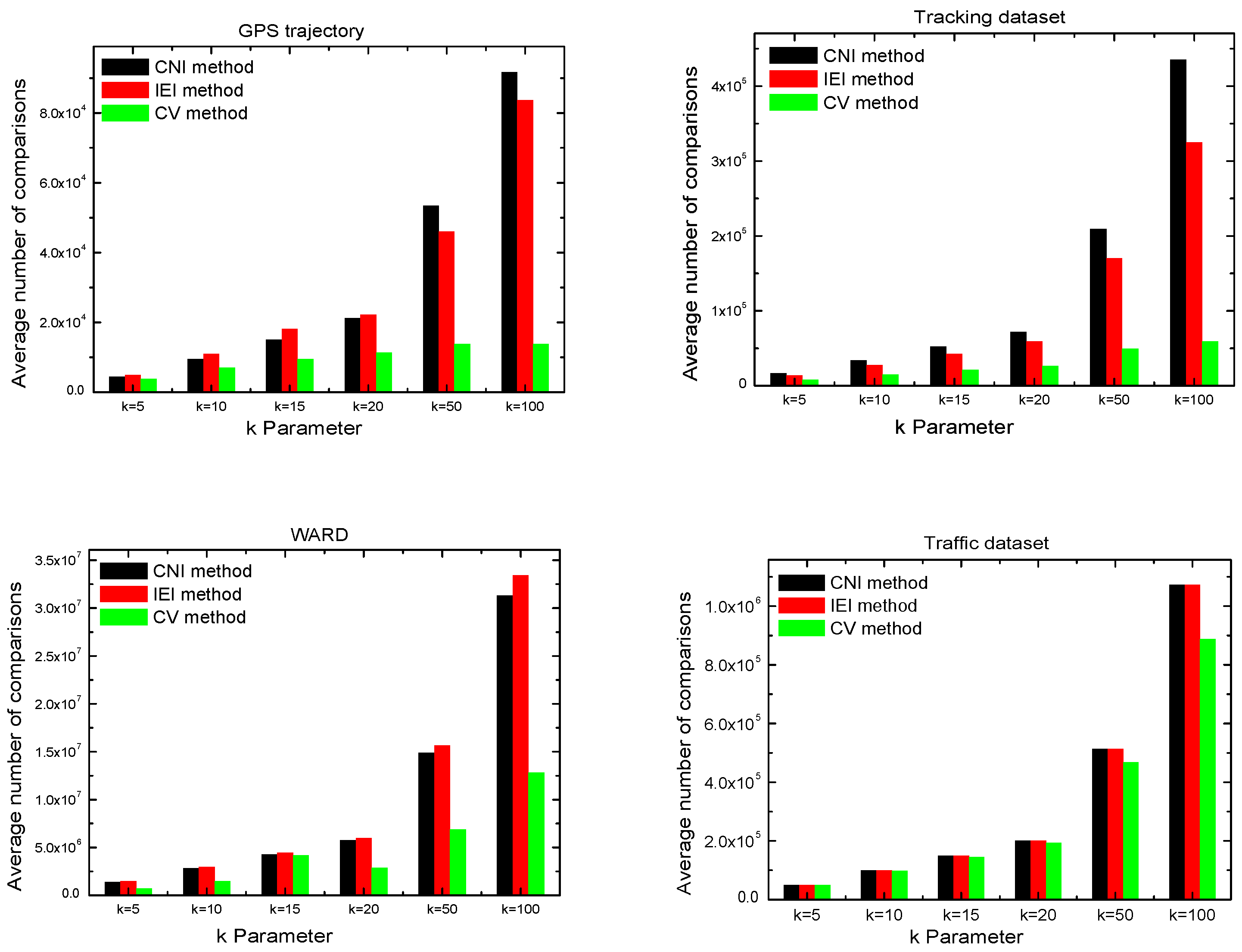
4.3.2. Number of Calculated Comparisons
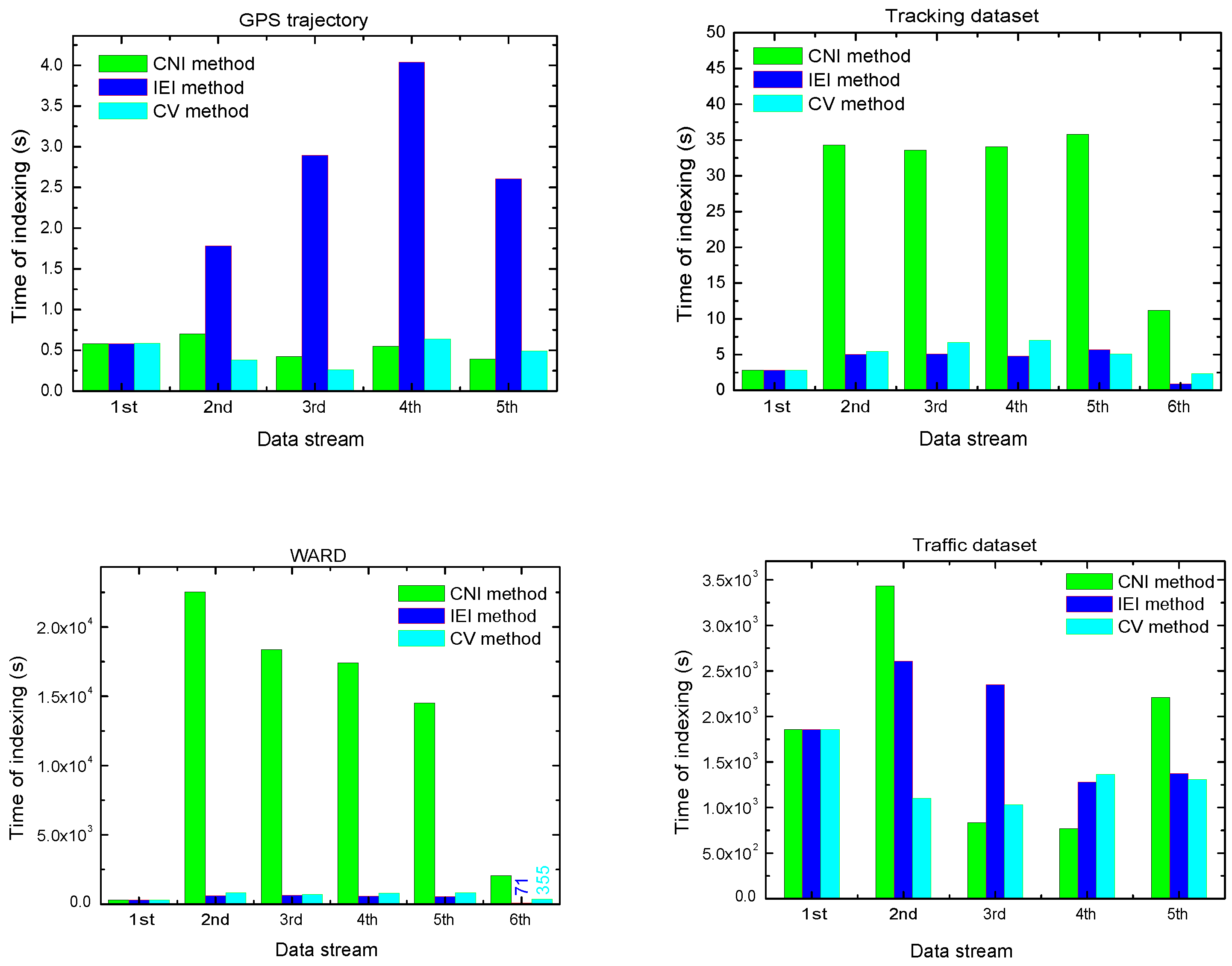
4.3.3. Indexing Time
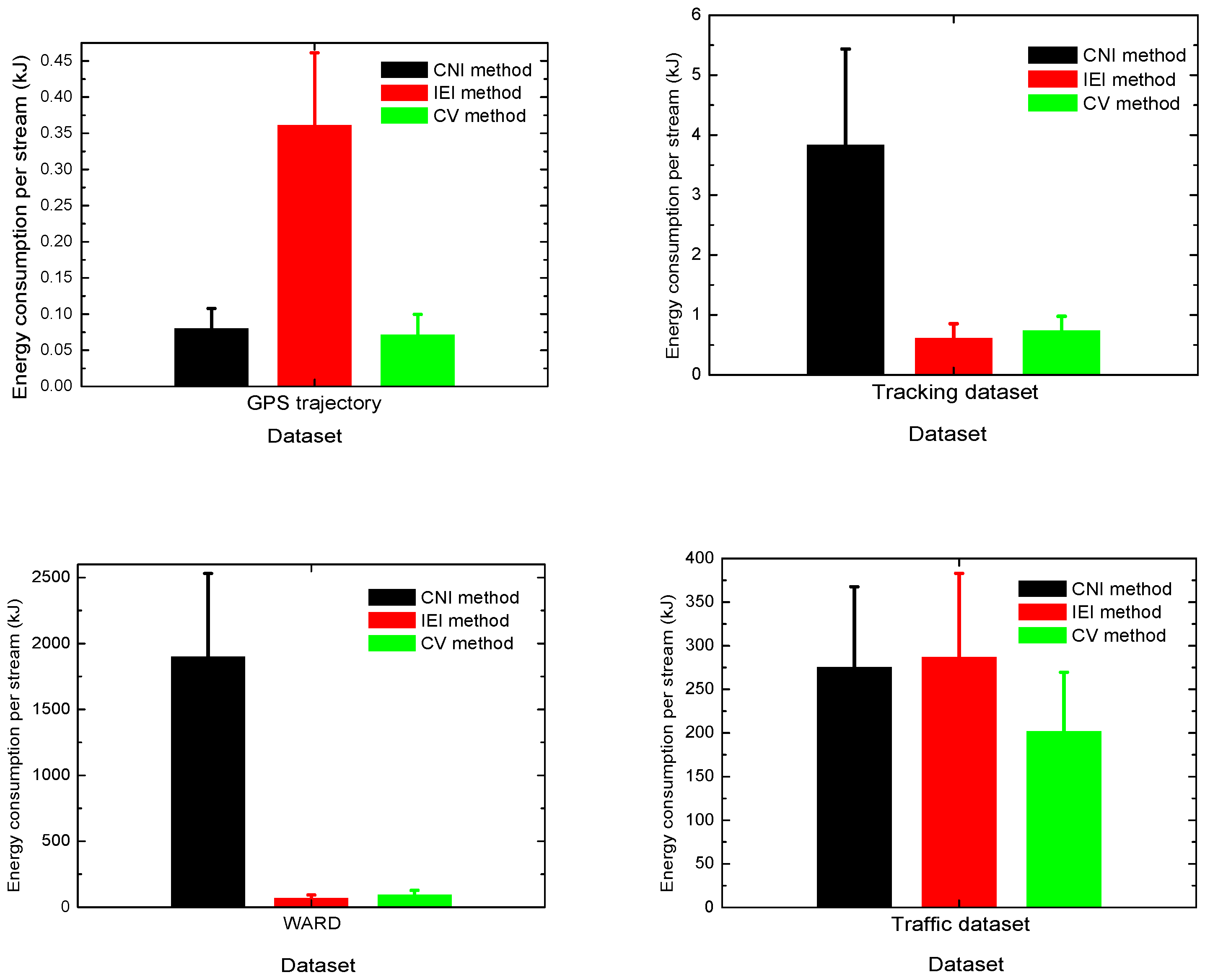
4.3.4. Energy Consumption during the Indexing
4.4. Quality of the Constructed BH-Trees
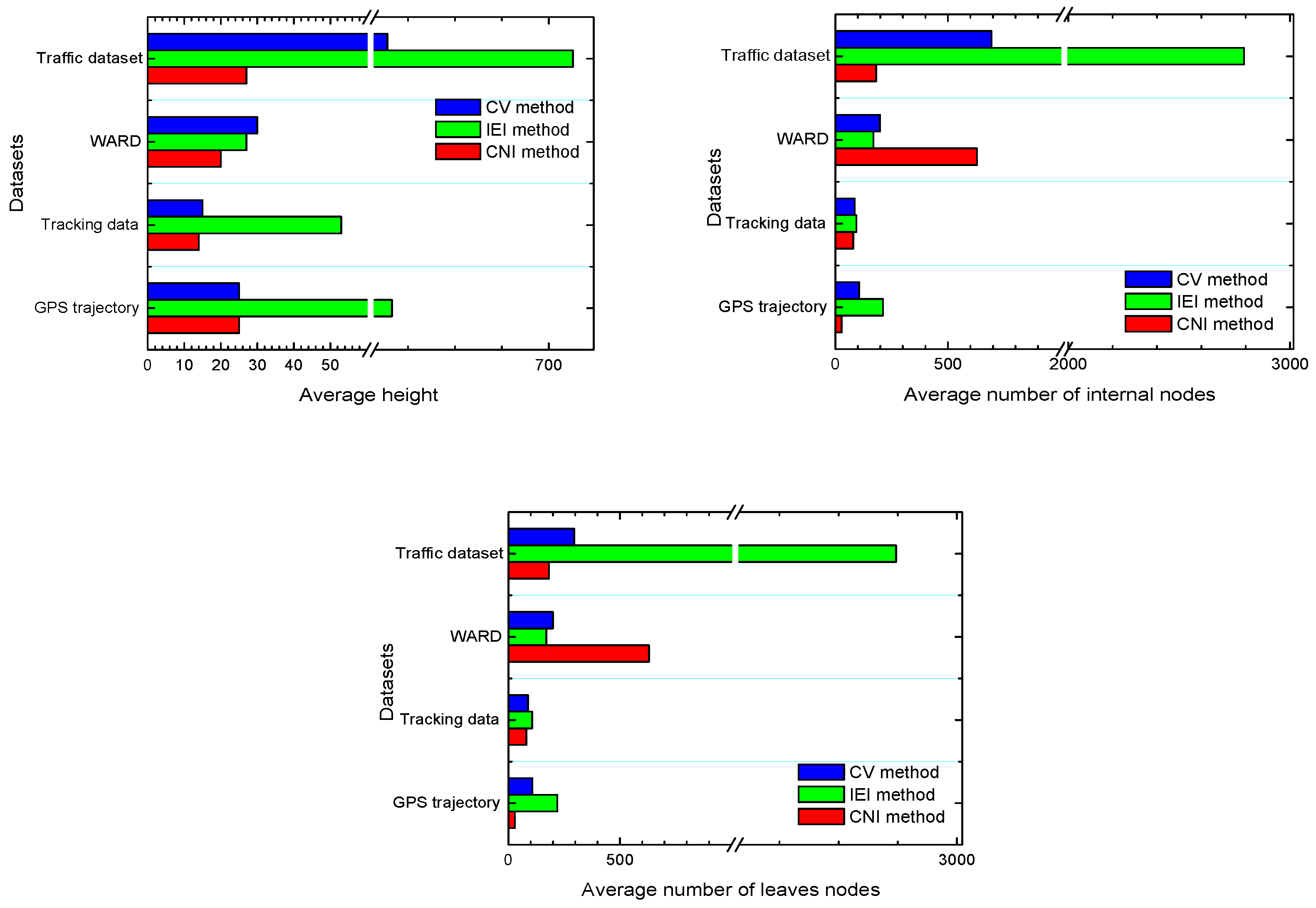
4.4.1. Average Height of BH-Trees
4.4.2. Average Number of Internal Nodes
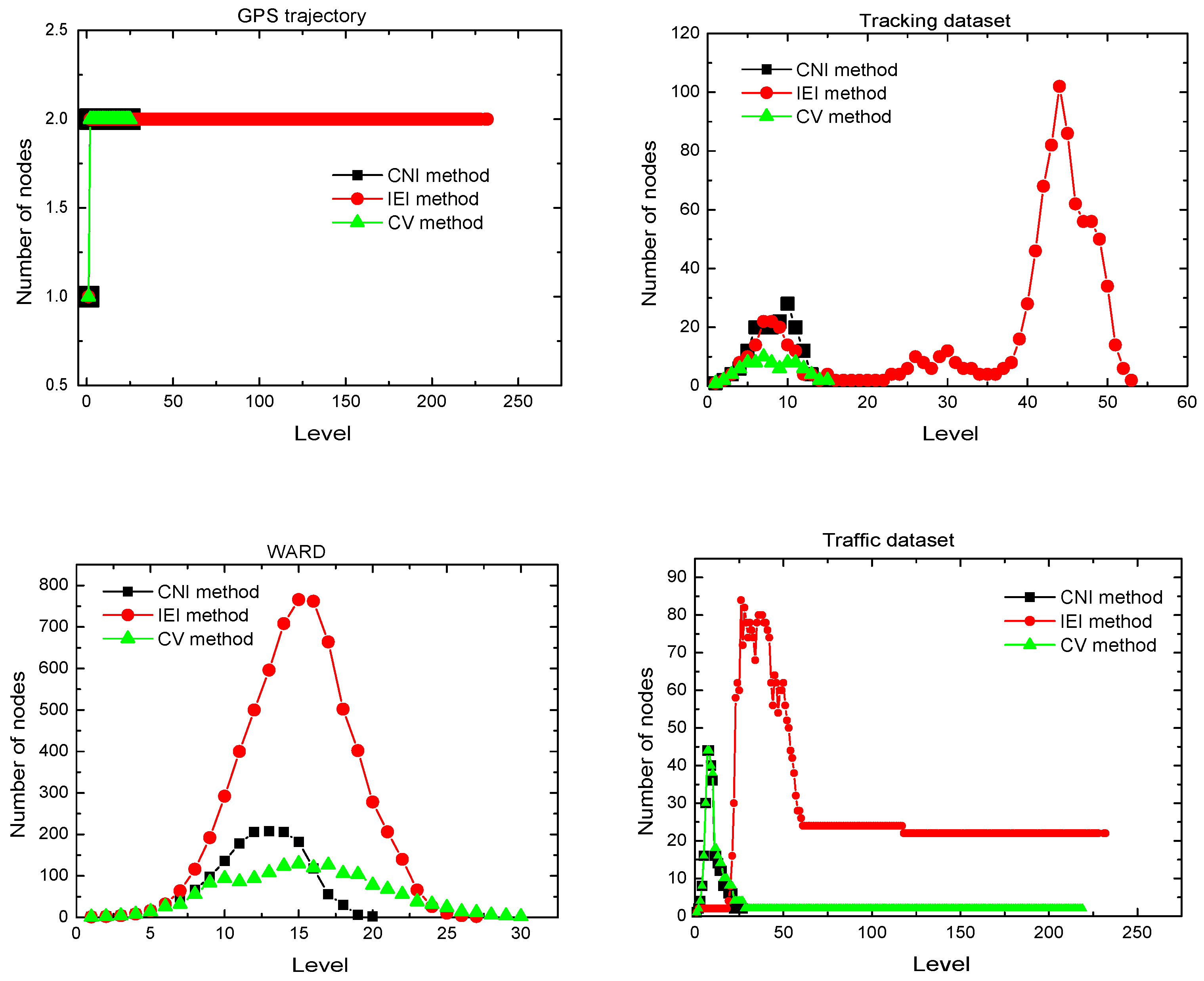
4.4.3. Number of Nodes per Level
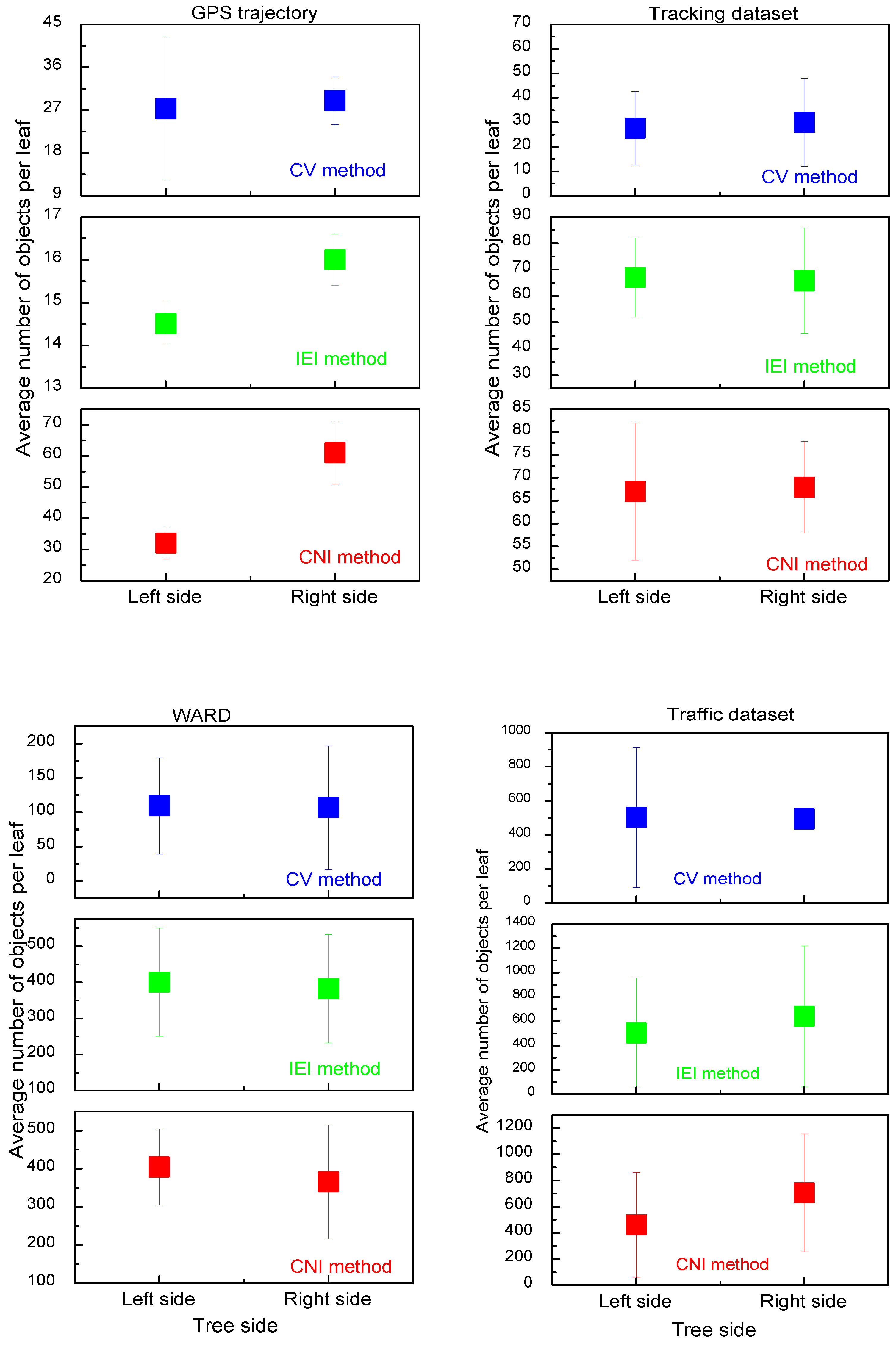
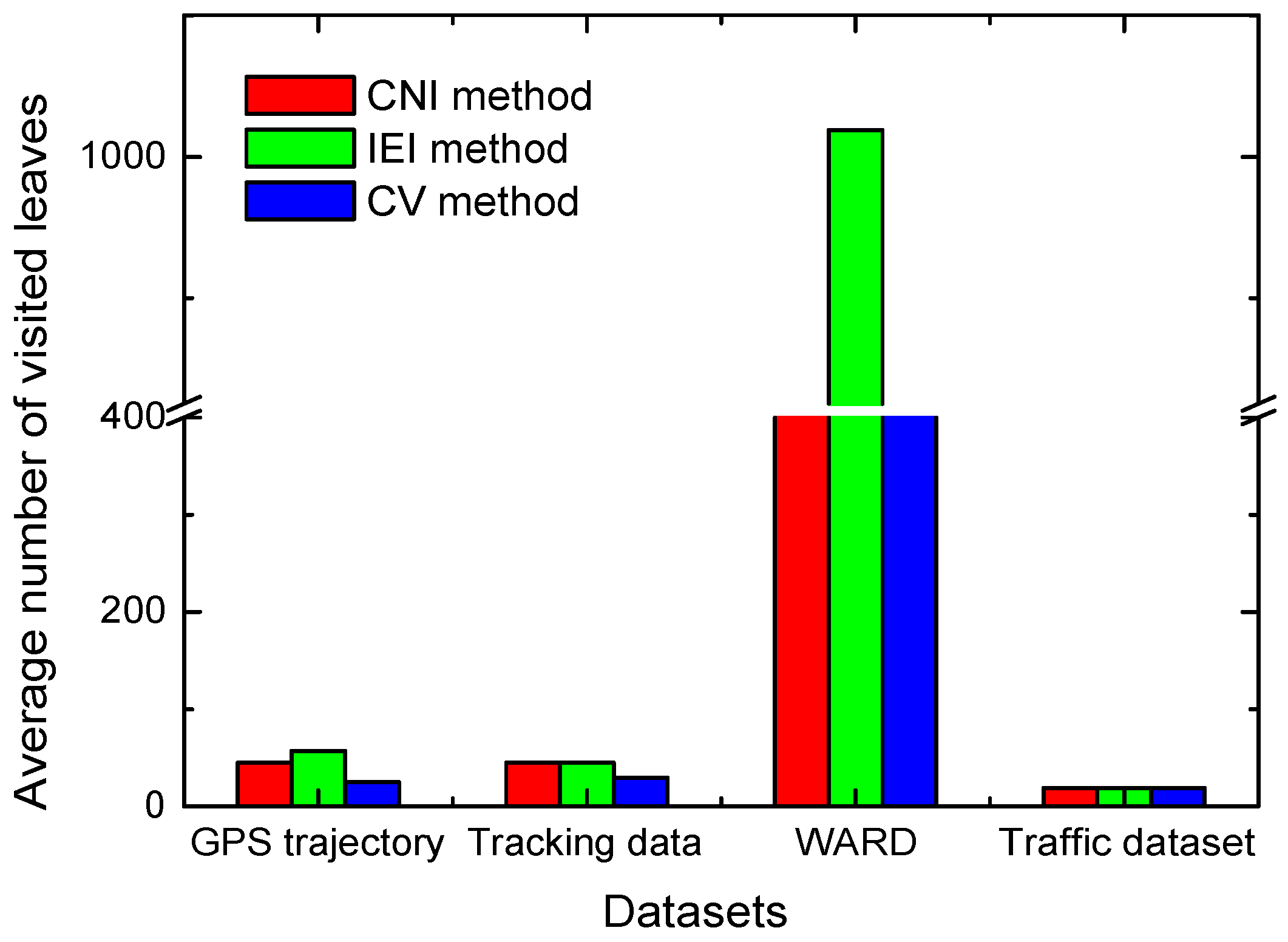
4.4.4. Data Distribution in BH-Tree Leaves
4.5. Evaluation of the Parallel kNN Search in BH-Trees
4.5.1. Number of Calculated Distances
4.5.2. Number of Calculated Comparisons
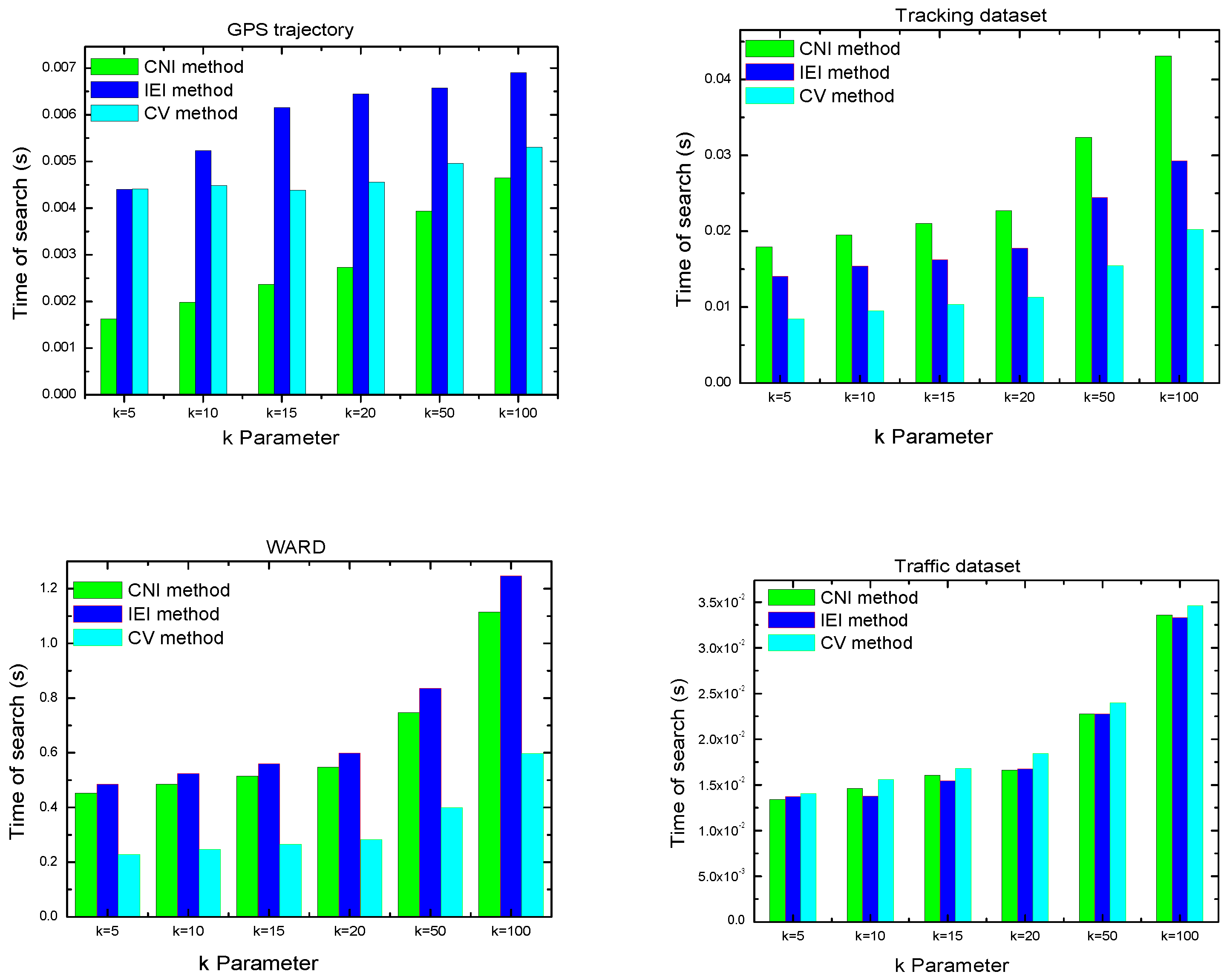
4.5.3. Time of Search
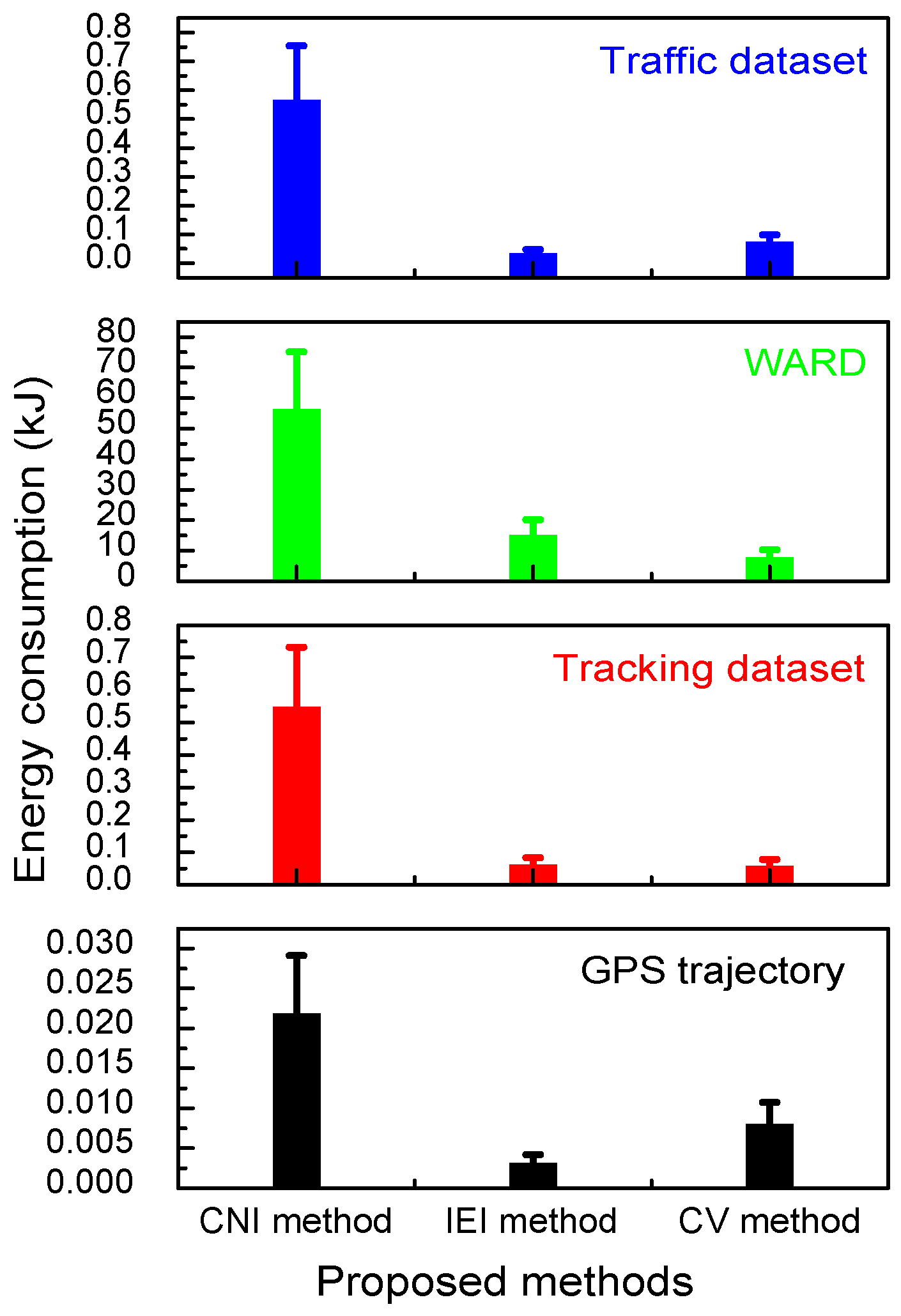
4.5.4. Energy Consumption during the kNN Search
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bangui, H.; Ge, M.; Buhnova, B. Exploring Big Data Clustering Algorithms for Internet of Things Applications. In Proceedings of the IoTBDS, Funchal, Portugal, 19–21 March 2018; pp. 269–276. [Google Scholar]
- Fathy, Y.; Barnaghi, P.; Tafazolli, R. Large-scale indexing, discovery, and ranking for the Internet of Things (IoT). ACM Comput. Surv. (CSUR) 2018, 51, 1–53. [Google Scholar] [CrossRef]
- Demchenko, Y.; Grosso, P.; De Laat, C.; Membrey, P. Addressing big data issues in scientific data infrastructure. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 48–55. [Google Scholar]
- Zhong, Y.; Fang, J.; Zhao, X. VegaIndexer: A distributed composite index scheme for big spatio-temporal sensor data on cloud. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 1713–1716. [Google Scholar]
- Zhou, Y.; De, S.; Wang, W.; Moessner, K. Enabling query of frequently updated data from mobile sensing sources. In Proceedings of the 2014 IEEE 17th International Conference on Computational Science and Engineering, Chengdu, China, 19–21 December 2014; pp. 946–952. [Google Scholar]
- Gao, X.; Gao, Y.; Zhu, Y.; Chen, G. U 2-Tree: A Universal Two-Layer Distributed Indexing Scheme for Cloud Storage System. IEEE/ACM Trans. Netw. 2019, 27, 201–213. [Google Scholar] [CrossRef]
- Mehta, N.; Dang, S. A Review of Clustering Techiques in various Applications for Effective Data Mining. Int. J. Res. IT Manag. 2011, 1, 2231–4334. [Google Scholar]
- Makhmutova, A.; Anikin, I. Uncertain Big Data Stream Clustering. In Cyber-Physical Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 361–372. [Google Scholar]
- Alencar, B.M.; Rios, R.A.; Santana, C.; Prazeres, C. FoT-Stream: A Fog platform for data stream analytics in IoT. Comput. Commun. 2020, 164, 77–87. [Google Scholar] [CrossRef]
- Jiang, Y.; Bi, A.; Xia, K.; Xue, J.; Qian, P. Exemplar-based data stream clustering toward Internet of Things. J. Supercomput. 2020, 76, 2929–2957. [Google Scholar] [CrossRef]
- Huang, C.Y.; Chang, Y.J. An adaptively multi-attribute index framework for big IoT data. Comput. Geosci. 2021, 155, 104841. [Google Scholar] [CrossRef]
- Limkar, S.V.; Jha, R.K. A novel method for parallel indexing of real time geospatial big data generated by IoT devices. Future Gener. Comput. Syst. 2019, 97, 433–452. [Google Scholar] [CrossRef]
- Xia, J.; Huang, S.; Zhang, S.; Li, X.; Lyu, J.; Xiu, W.; Tu, W. DAPR-tree: A distributed spatial data indexing scheme with data access patterns to support Digital Earth initiatives. Int. J. Digit. Earth 2020, 13, 1656–1671. [Google Scholar] [CrossRef]
- Chaudhry, N.; Yousaf, M.M.; Khan, M.T. Indexing of real time geospatial data by IoT enabled devices: Opportunities, challenges and design considerations. J. Ambient. Intell. Smart Environ. 2020, 12, 281–312. [Google Scholar] [CrossRef]
- Chen, L.; Gao, Y.; Song, X.; Li, Z.; Miao, X.; Jensen, C.S. Indexing metric spaces for exact similarity search. arXiv 2020, arXiv:2005.03468. [Google Scholar] [CrossRef]
- Zhang, R.; Manotas, I.; Li, M.; Hildebrand, D. Towards a big data benchmarking and demonstration suite for the online social network era with realistic workloads and live data. In Proceedings of the BPOE, Kohala, HI, USA, 31 August–4 September 2015; pp. 25–36. [Google Scholar]
- Ma, K.; Bagula, A.; Nyirenda, C.; Ajayi, O. An iot-based fog computing model. Sensors 2019, 19, 2783. [Google Scholar] [CrossRef]
- Din, I.U.; Guizani, M.; Hassan, S.; Kim, B.S.; Khan, M.K.; Atiquzzaman, M.; Ahmed, S.H. The Internet of Things: A review of enabled technologies and future challenges. IEEE Access 2018, 7, 7606–7640. [Google Scholar] [CrossRef]
- Marjani, M.; Nasaruddin, F.; Gani, A.; Karim, A.; Hashem, I.A.T.; Siddiqa, A.; Yaqoob, I. Big IoT data analytics: Architecture, opportunities, and open research challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar]
- Han, J.; Kamber, M. Data Mining Concepts and Techniques, 2nd ed.; Stephan, A., Ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA; Elsevier Inc.: San Francisco, CA, USA, 2006; Volume 40, pp. 347–350. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. 1999, 29, 433–439. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Wang, J.; Wu, S.; Gao, H.; Li, J.; Ooi, B.C. Indexing multi-dimensional data in a cloud system. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, Indianapolis, IN, USA, 6–10 June 2010; pp. 591–602. [Google Scholar]
- Wu, S.; Jiang, D.; Ooi, B.C.; Wu, K.L. Efficient B-tree based indexing for cloud data processing. Proc. VLDB Endow. 2010, 3, 1207–1218. [Google Scholar] [CrossRef]
- Feng, C.; Yang, X.; Liang, F.; Sun, X.H.; Xu, Z. LCIndex: A local and clustering index on distributed ordered tables for flexible multi-dimensional range queries. In Proceedings of the 2015 44th International Conference on Parallel Processing, Beijing, China, 1–4 September 2015; pp. 719–728. [Google Scholar]
- Hong, Y.; Tang, Q.; Gao, X.; Yao, B.; Chen, G.; Tang, S. Efficient R-tree based indexing scheme for server-centric cloud storage system. IEEE Trans. Knowl. Data Eng. 2016, 28, 1503–1517. [Google Scholar] [CrossRef]
- Ciaccia, P.; Patella, M.; Zezula, P. M-tree: An efficient access method for similarity search in metric spaces. In Proceedings of the, 23rd International Conference on Very Large Data Bases, Athens, Greece, 25–29 August 1997; Volume 97, pp. 426–435. [Google Scholar]
- Kouahla, Z.; Martinez, J. A new intersection tree for content-based image retrieval. In Proceedings of the 2012 10th International Workshop on Content-Based Multimedia Indexing (CBMI), Annecy, France, 27–29 June 2012; pp. 1–6. [Google Scholar]
- Kouahla, Z.; Anjum, A.; Akram, S.; Saba, T.; Martinez, J. XM-tree: Data driven computational model by using metric extended nodes with non-overlapping in high-dimensional metric spaces. Comput. Math. Organ. Theory 2019, 25, 196–223. [Google Scholar] [CrossRef]
- Benrazek, A.E.; Kouahla, Z.; Farou, B.; Ferrag, M.A.; Seridi, H.; Kurulay, M. An efficient indexing for Internet of Things massive data based on cloud-fog computing. Trans. Emerg. Telecommun. Technol. 2020, 31, e3868. [Google Scholar] [CrossRef]
- Khettabi, K.; Kouahla, Z.; Farou, B.; Seridi, H. QCCF-tree: A New Efficient IoT Big Data Indexing Method at the Fog-Cloud Computing Level. In Proceedings of the 2021 IEEE International Smart Cities Conference (ISC2), Manchester, UK, 7–10 September 2021; pp. 1–7. [Google Scholar]
- Wang, S.; Maier, D.; Ooi, B.C. Lightweight indexing of observational data in log-structured storage. Proc. VLDB Endow. 2014, 7, 529–540. [Google Scholar] [CrossRef]
- Doan, Q.T.; Kayes, A.; Rahayu, W.; Nguyen, K. Integration of iot streaming data with efficient indexing and storage optimization. IEEE Access 2020, 8, 47456–47467. [Google Scholar] [CrossRef]
- Ding, Z.; Xu, J.; Yang, Q. SeaCloudDM: A database cluster framework for managing and querying massive heterogeneous sensor sampling data. J. Supercomput. 2013, 66, 1260–1284. [Google Scholar] [CrossRef]
- Balakrishna, S.; Thirumaran, M.; Solanki, V.K.; Núñez Valdéz, E.R. Incremental hierarchical clustering driven automatic annotations for unifying IoT streaming data. Int. J. Interact. Multimed. Artif. Intell. 2020, 6, 56–70. [Google Scholar]
- Mukherjee, M.; Matam, R.; Shu, L.; Maglaras, L.; Ferrag, M.A.; Choudhury, N.; Kumar, V. Security and privacy in fog computing: Challenges. IEEE Access 2017, 5, 19293–19304. [Google Scholar] [CrossRef]
- Al-mamory, S.O.; Algelal, Z.M. A modified DBSCAN clustering algorithm for proactive detection of DDoS attacks. In Proceedings of the 2017 Annual Conference on New Trends in Information & Communications Technology Applications (NTICT), Baghdad, Iraq, 7–9 March 2017; pp. 304–309. [Google Scholar]
- Khettabi, K.; Kouahla, Z.; Farou, B.; Seridi, H.; Ferrag, M.A. Clustering and parallel indexing of big IoT data in the fog-cloud computing level. Trans. Emerg. Telecommun. Technol. 2022, 33, e4484. [Google Scholar] [CrossRef]
- Liu, T.; Qu, S.; Zhang, K. A Clustering Algorithm for Automatically Determining the Number of Clusters Based on Coefficient of Variation. In Proceedings of the 2nd International Conference on Big Data Research, Weihai, China, 27–29 October 2018; pp. 100–106. [Google Scholar]
- Cruz, M.; Macedo, H.T.; Guimarães, A.P. Grouping Similar Trajectories for Carpooling Purposes. In Proceedings of the 2015 Brazilian Conference on Intelligent Systems (BRACIS), Natal, Brazil, 4–7 November 2015; pp. 234–239. [Google Scholar]
- Yang, A.Y.; Jafari, R.; Sastry, S.S.; Bajcsy, R. Distributed recognition of human actions using wearable motion sensor networks. J. Ambient. Intell. Smart Environ. 2009, 1, 103–115. [Google Scholar] [CrossRef]
- Rossi, R.; Ahmed, N. The network data repository with interactive graph analytics and visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Wu, H.Y.; Lee, C.R. Energy efficient scheduling for heterogeneous fog computing architectures. In Proceedings of the 2018 IEEE 42nd annual computer software and applications conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 555–560. [Google Scholar]
- Khettabi, K.; Kouahla, Z.; Farou, B.; Seridi, H.; Ferrag, M.A. A new method for indexing continuous IoT data flows in metric space. Internet Technol. Lett. 2022, e391. [Google Scholar] [CrossRef]
- Sprenger, S.; Schäfer, P.; Leser, U. Bb-tree: A main-memory index structure for multidimensional range queries. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1566–1569. [Google Scholar]
- Jin, S.; Kim, O.; Feng, W. MX-tree: A double hierarchical metric index with overlap reduction. In Proceedings of the Computational Science and Its Applications—ICCSA 2013: 13th International Conference, Ho Chi Minh City, Vietnam, 24–27 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 574–589. [Google Scholar]
- Berchtold, S.; Keim, D.A.; Kriegel, H.P. The X-tree: An index structure for high-dimensional data. In Proceedings of the Very Large Data-Bases, Mumbai, India, 3–6 September 1996; pp. 28–39. [Google Scholar]
- Uhlmann, J.K. Satisfying general proximity/similarity queries with metric trees. Inf. Process. Lett. 1991, 40, 175–179. [Google Scholar] [CrossRef]
- Zhang, K.; Zhou, W.; Sun, S.; Li, B. Multiple complementary inverted indexing based on multiple metrics. Multimed. Tools Appl. 2019, 78, 7727–7747. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Explantation |
|---|---|
| N | Number of the first clusters |
| K | Number of the arrival clusters |
| Clusters of the first data stream | |
| Clusters of the arrival data stream | |
| Cluster centers of the first data stream | |
| Cluster centers of the arrival data stream | |
| Union of the arrival clusters and the first | |
| clusters | |
| Distance between two centers | |
| , | Set of indexes |
| Minimum distances between the centers | |
| of the existing clusters and the incoming clusters | |
| , | Pivots |
| E | Set of elements |
| LN | Leaf node |
| IN | Inner node |
| o | Object |
| L | Left sub tree |
| R | Right sub tree |
| q | Query |
| Radius for recovering k objects closes to q | |
| A | List in with, the set of k objects is stored |
| Query ball q with radius |
| Dataset | Size (Vectors) | Dimension | Data Stream Size (Vectors) | Data Stream Size (Bytes) |
|---|---|---|---|---|
| GPS trajectory | 18,107 | 3 | 4000 | 115,507.02 |
| Tracking dataset | 62,702 | 20 | 12,000 | 1,270,493.8 |
| WARD | 3,078,552 | 5 | 600,000 | 18,058,184 |
| Traffic dataset | 5,000,000 | 2 | 1,000,000 | 20,132,659.2 |
| Indexing Methods | CV | TD [45] | B3CF-Tree [39] | BCCF-Tree [31] | BB-Tree [46] | MX-Tree [47] | IWC-Tree [31] | |
|---|---|---|---|---|---|---|---|---|
| Datastes | ||||||||
| GPS trajectory | 0.00531 s | 0.13583 s | 0.00118 s | 0.16191 s | 0.97994 s | 0.35414 s | 0.04013 s | |
| Tracking dataset | 0.02022 s | 0.03919 s | 0.00020 s | 0.21034 s | 20.26953 s | 19.70434 s | 20.12095 s | |
| WARD | 0.59673 s | 1.13473 s | 0.00576 s | 2.72482 s | 116.87681 s | 3.0745 s | 120.23918 s | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khettabi, K.; Kouahla, Z.; Farou, B.; Seridi, H.; Ferrag, M.A. Efficient Method for Continuous IoT Data Stream Indexing in the Fog-Cloud Computing Level. Big Data Cogn. Comput. 2023, 7, 119. https://doi.org/10.3390/bdcc7020119
Khettabi K, Kouahla Z, Farou B, Seridi H, Ferrag MA. Efficient Method for Continuous IoT Data Stream Indexing in the Fog-Cloud Computing Level. Big Data and Cognitive Computing. 2023; 7(2):119. https://doi.org/10.3390/bdcc7020119
Chicago/Turabian StyleKhettabi, Karima, Zineddine Kouahla, Brahim Farou, Hamid Seridi, and Mohamed Amine Ferrag. 2023. "Efficient Method for Continuous IoT Data Stream Indexing in the Fog-Cloud Computing Level" Big Data and Cognitive Computing 7, no. 2: 119. https://doi.org/10.3390/bdcc7020119