

A Real-Time Computer Vision Based Approach to Detection and Classification of Traffic Incidents
 , ,
, ,  , , , , ,
, , , , ,  and
and
Abstract
:1. Introduction
- 1.
- A comprehensive system model to detect:
- a.
- road accidents,
- b.
- their severity, and
- c.
- postaccident fires.
- 2.
- Investigation of AI and computer vision-based approaches for object and event detection.
- 3.
- Testing and validating of the proposed model by contrasting with the state-of-the-art techniques.
- 4.
- Detection, alert, and postaccident emergency response mechanisms.
2. Related Work
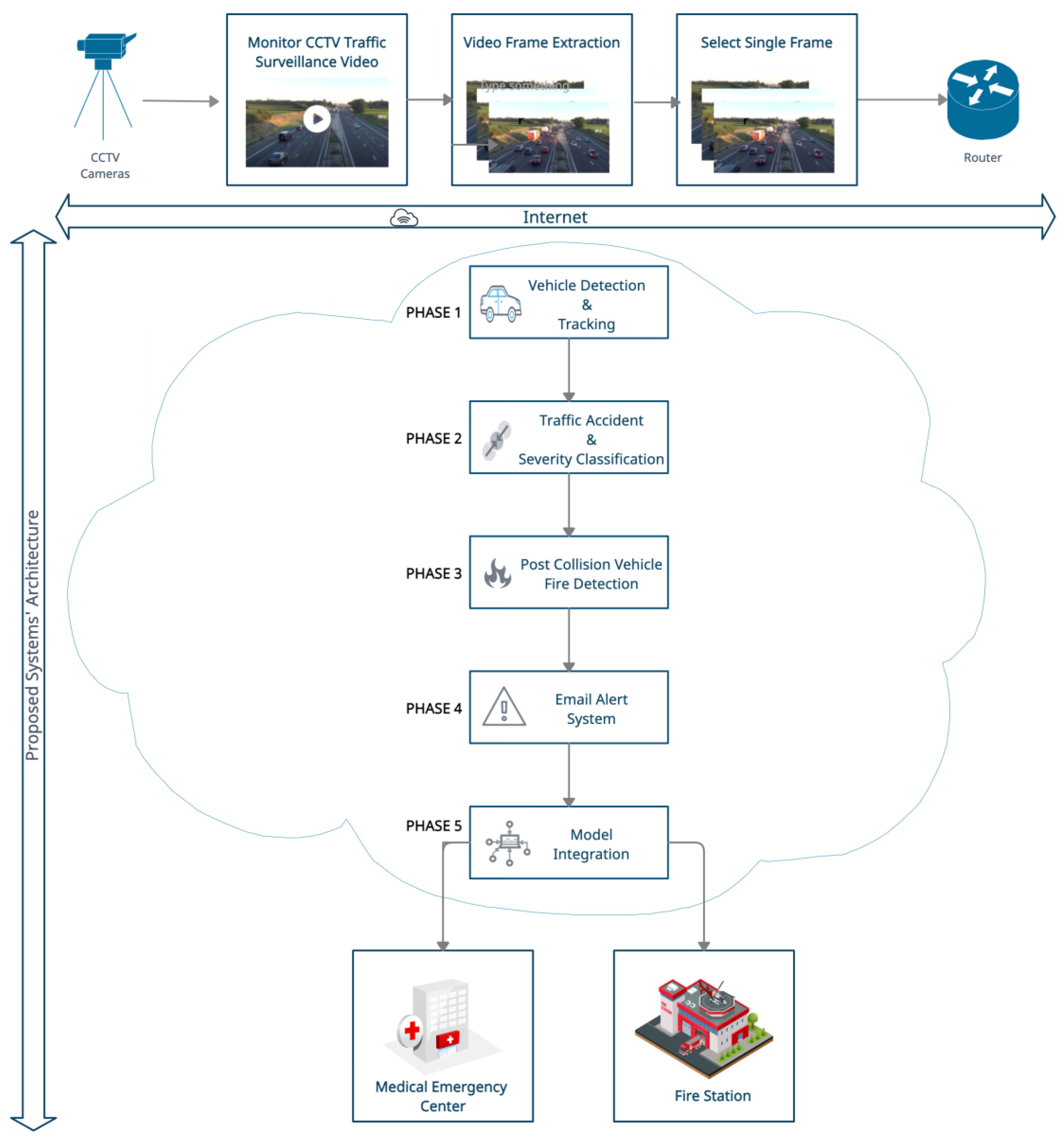
3. Methodology
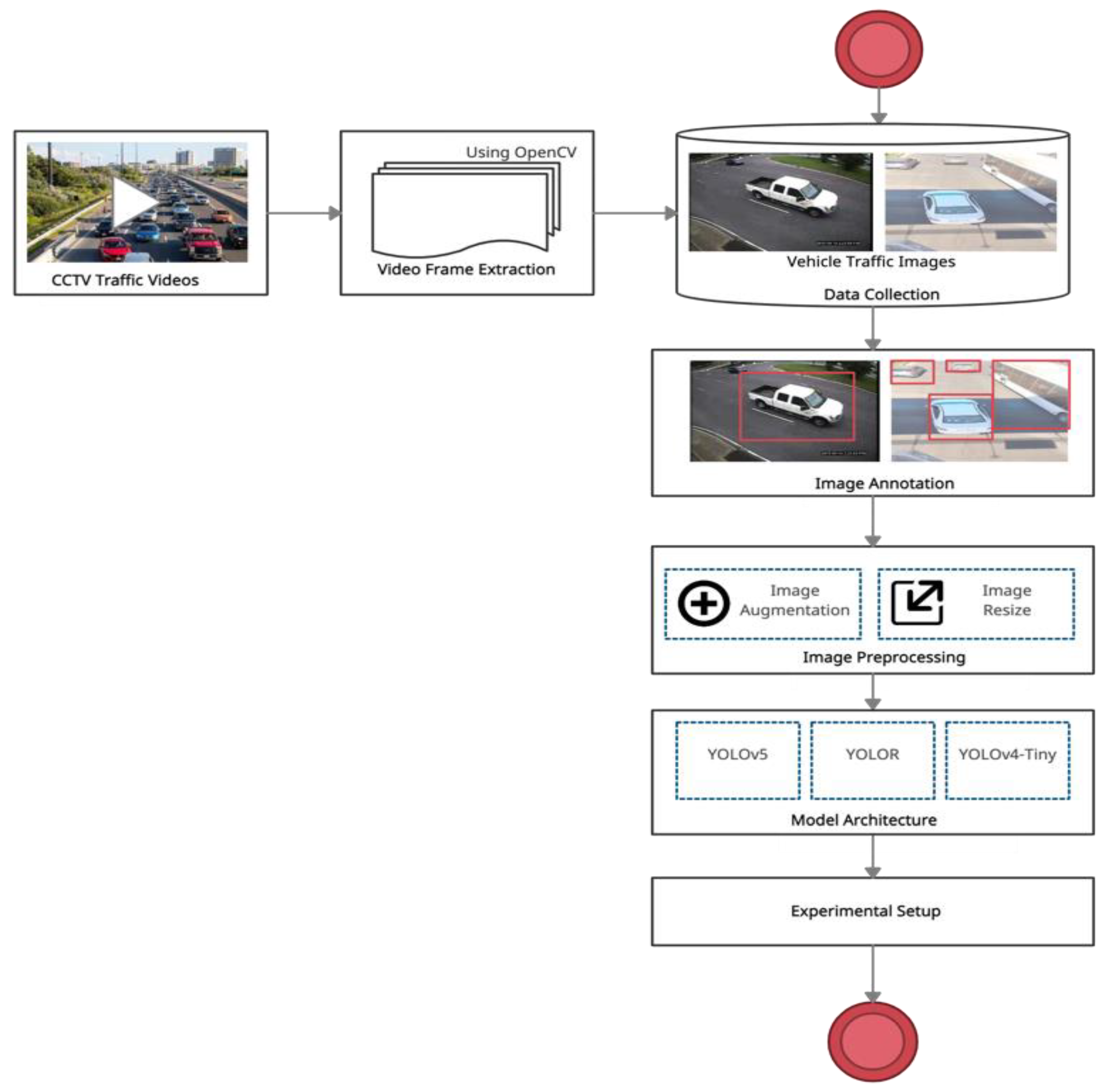
3.1. Phase 1: Vehicle Detection and Tracking
3.1.1. Data Collection
3.1.2. Image Preprocessing
3.1.3. Experimental Setup
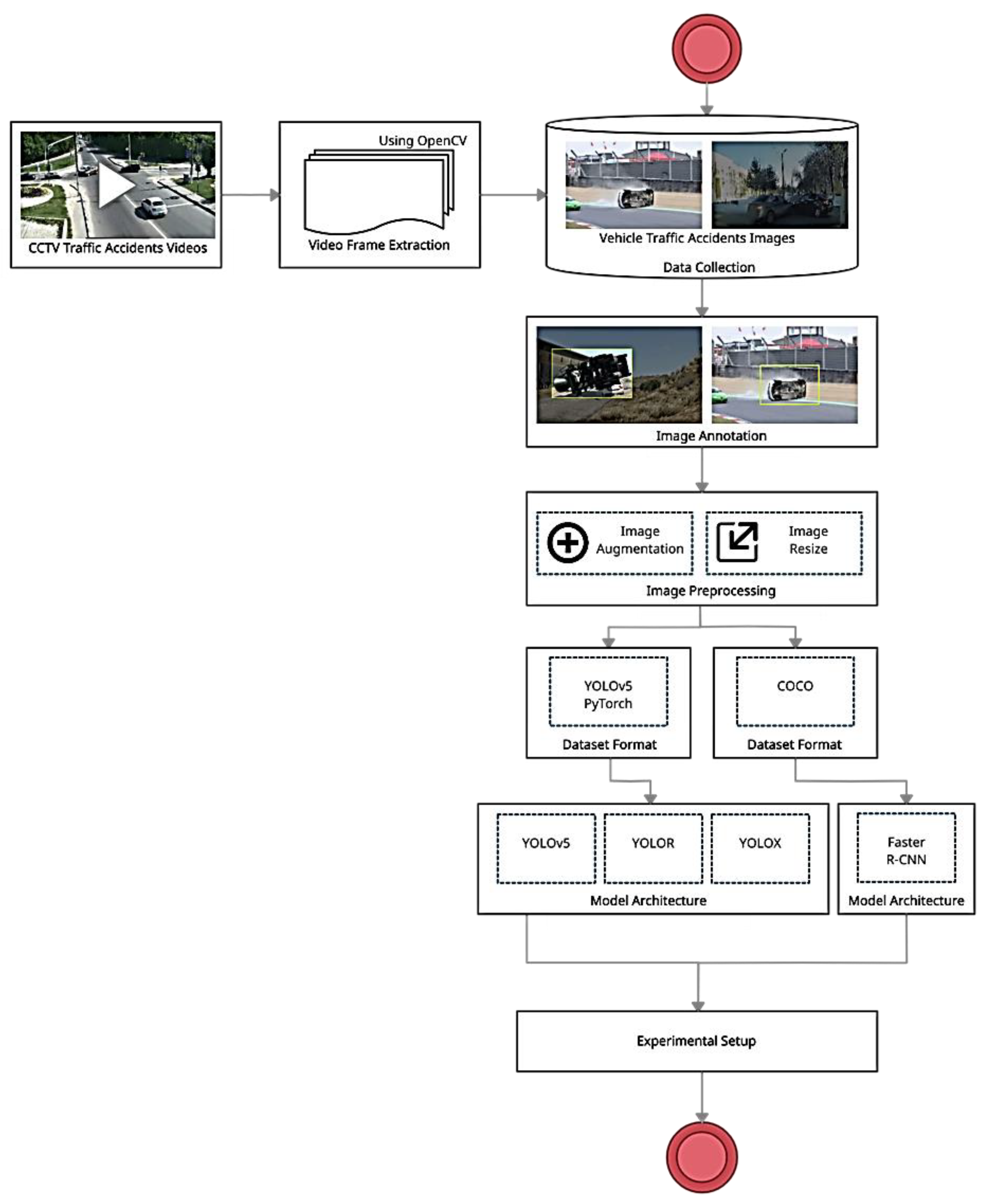
3.2. Phase 1: Traffic Accident and Severity Classification
3.2.1. Data Collection
3.2.2. Image Preprocessing
3.2.3. Experimental Setup
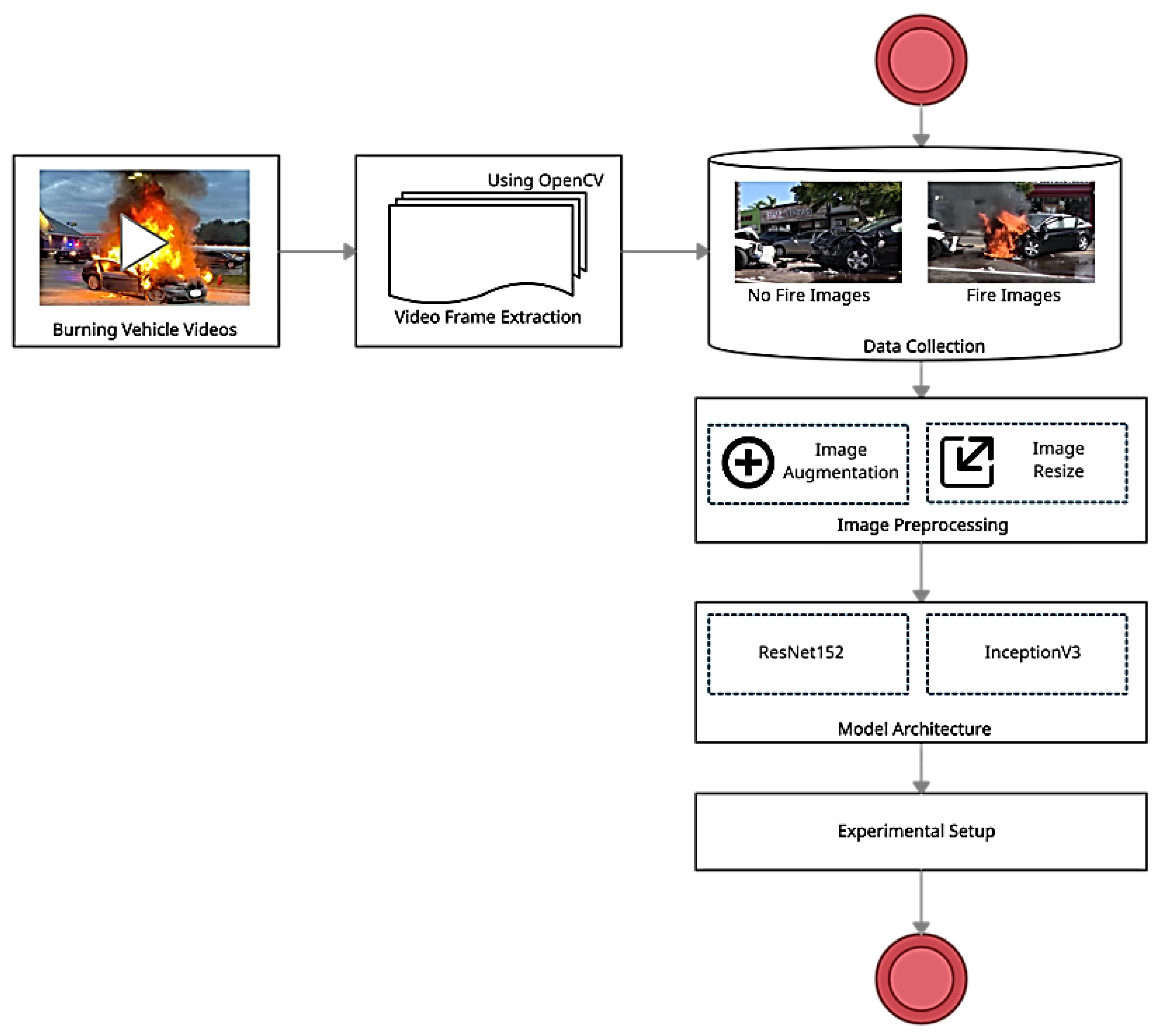
3.3. Phase 3: Postcollision Vehicle Fire Detection
3.3.1. Data Collection
3.3.2. Image Preprocessing
3.3.3. Experimental Setup
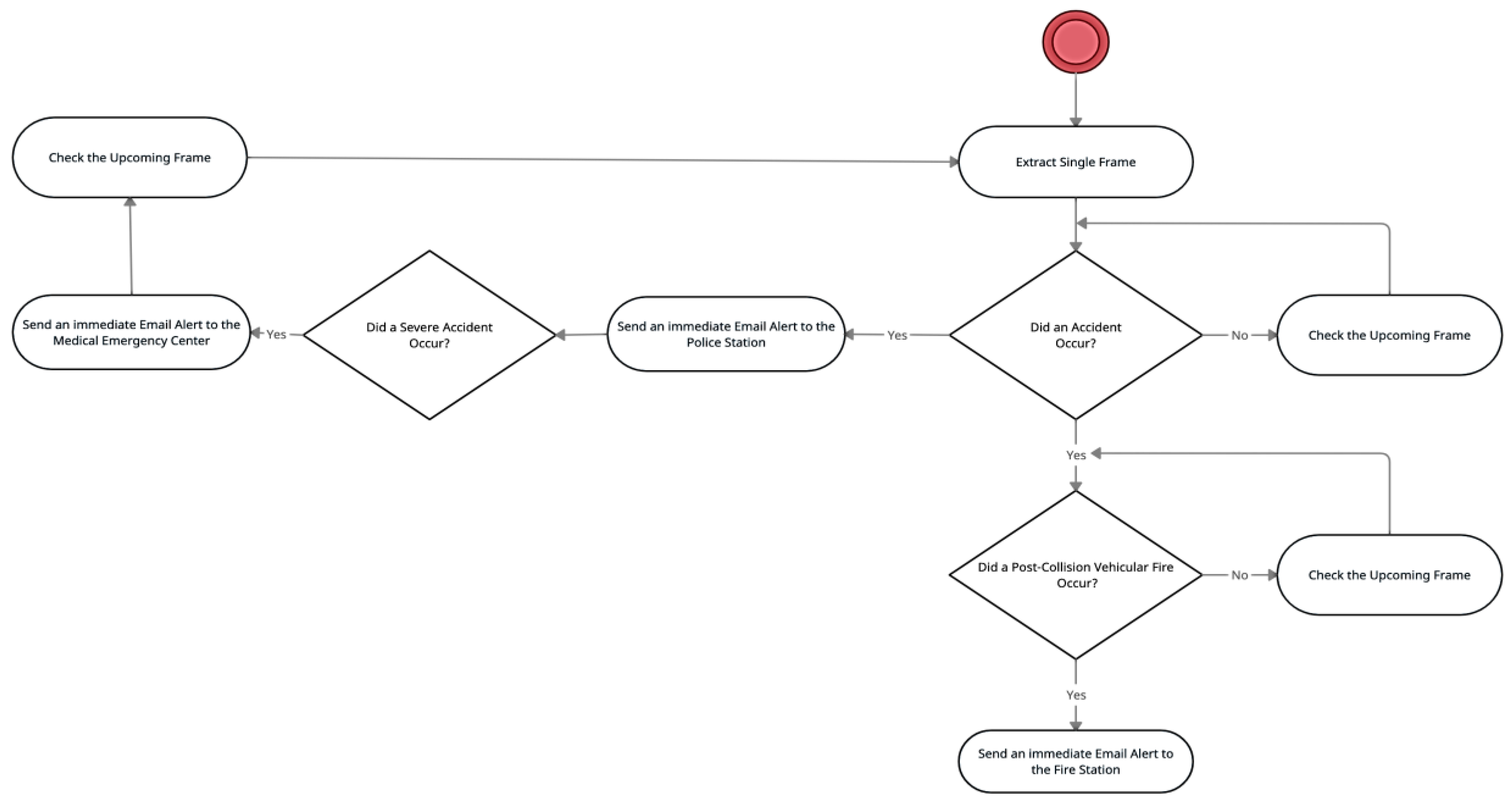
3.4. Phase 4: Email Alert System
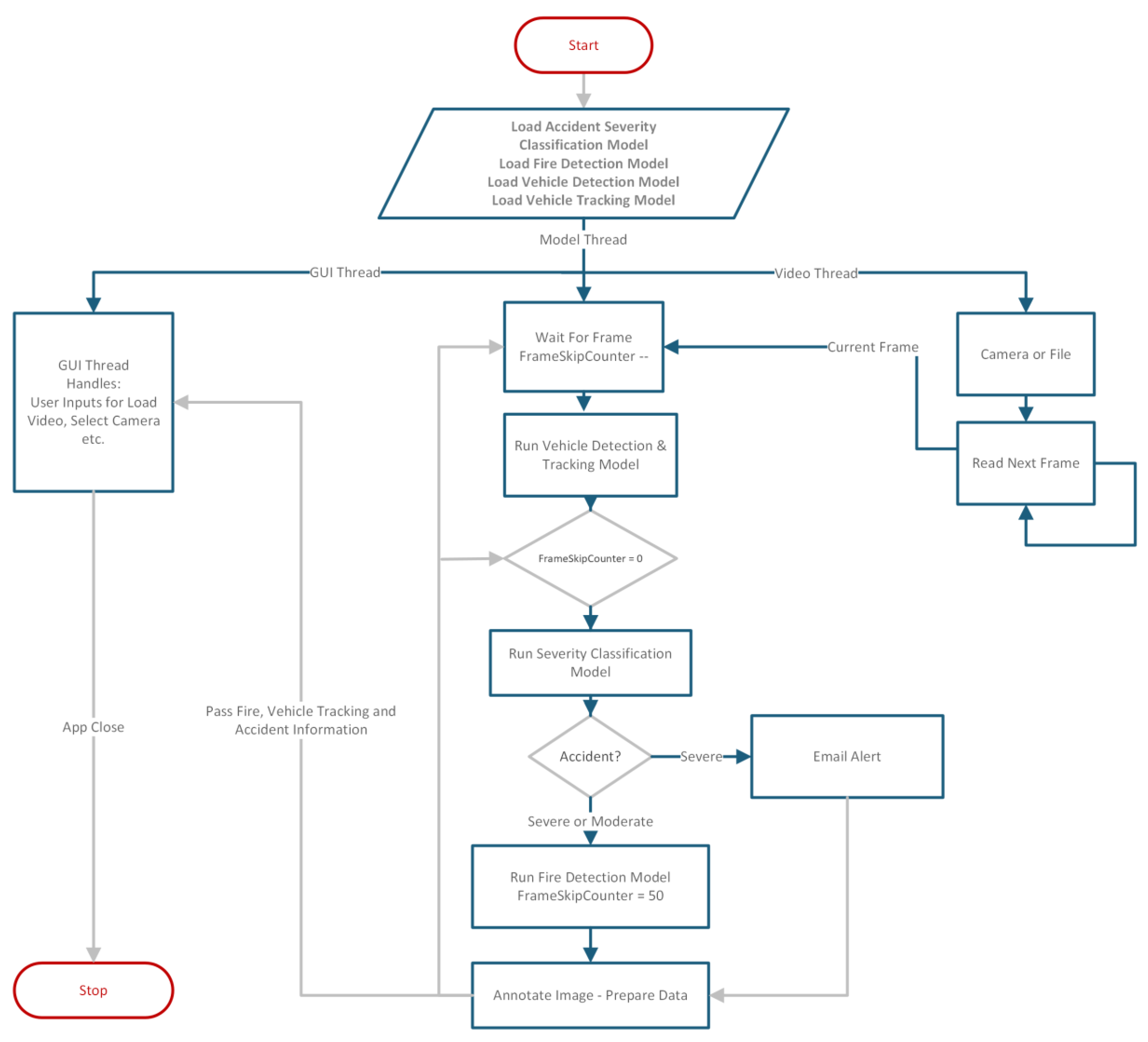
3.5. Phase 5: Model Integration
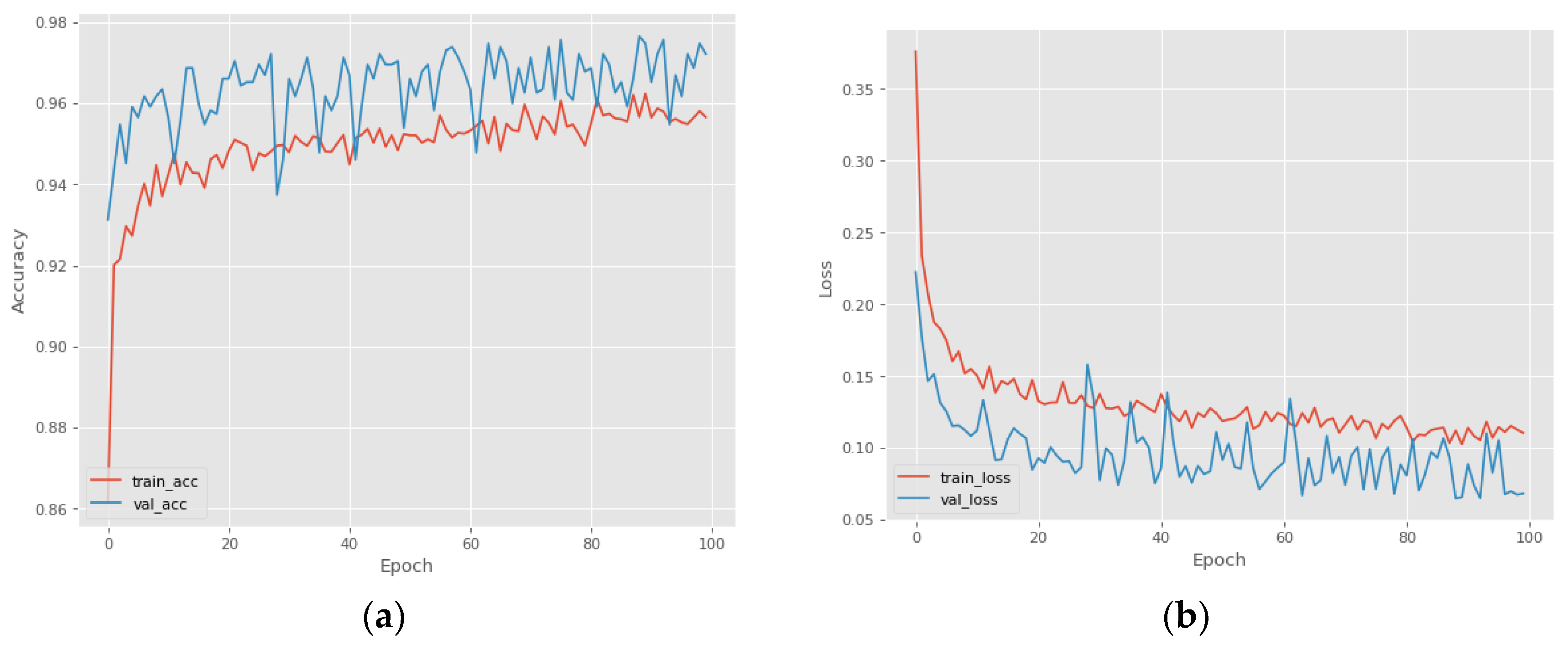
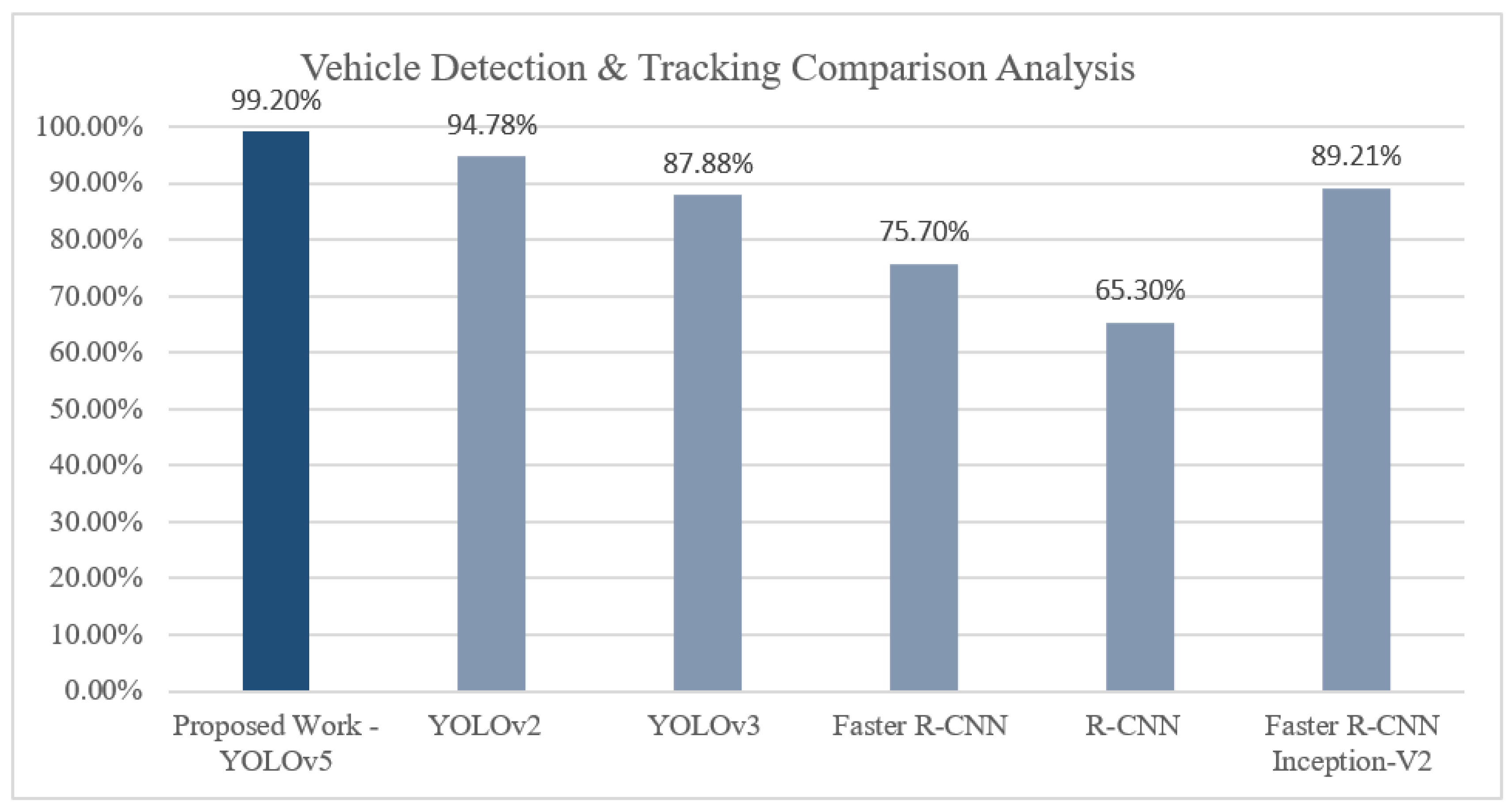
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mansuri, F.A.; Al-Zalabani, A.H.; Zalat, M.M.; Qabshawi, R.I. Road safety and road traffic accidents in Saudi Arabia: A systematic review of existing evidence. Saudi Med. J. 2015, 36, 418–424. [Google Scholar] [CrossRef]
- Brahimi, T. Using Artificial Intelligence to Predict Wind Speed for Energy Application in Saudi Arabia. Energies 2019, 12, 4669. [Google Scholar] [CrossRef] [Green Version]
- Pillai, M.S.; Chaudhary, G.; Khari, M.; Crespo, R.G. Real-time image enhancement for an automatic automobile accident detection through CCTV using deep learning. Soft Comput. 2021, 25, 11929–11940. [Google Scholar] [CrossRef]
- Kingdom of Saudi Arabia’s Vision 2030. Available online: https://www.my.gov.sa/wps/portal/snp/content/saudivision/!ut/p/z0/04_Sj9CPykssy0xPLMnMz0vMAfIjo8zivQIsTAwdDQz9LSw8XQ0CnT0s3JxDfA0MLAz0g1Pz9AuyHRUBTTar_g!!/ (accessed on 28 May 2022).
- Azmat, Y.; Saad, N. The Safety Policies Practiced in the Construction Industry of Saudi Arabia. 2018. Available online: https://www.longdom.org/open-access/the-safety-policies-practiced-in-the-construction-industry-of-saudi-arabia.pdf (accessed on 7 December 2021).
- Egelhaaf, M.; Wolpert, D. Post Collision Vehicle Fire Analysis. Environ. Sci. 2019, 11, 315. [Google Scholar]
- General Department of Traffic. Saher System. Available online: https://www.moi.gov.sa/wps/portal/Home/sectors/publicsecurity/traffic/contents/!ut/p/z0/04_Sj9CPykssy0xPLMnMz0vMAfIjo8ziDTxNTDwMTYy83V0CTQ0cA71d_T1djI0MXA30g1Pz9L30o_ArApqSmVVYGOWoH5Wcn1eSWlGiH1FSlJiWlpmsagBlKCQWqRrkJmbmqRoUJ2akFukXZLuHAwCkY5qs/ (accessed on 12 January 2023).
- Lee, C.; Kim, H.; Oh, S.; Doo, I. A Study on Building a “Real-Time Vehicle Accident and Road Obstacle Notification Model” Using AI CCTV. Appl. Sci. 2021, 11, 8210. [Google Scholar] [CrossRef]
- Nancy, P.; Dilli Rao, D.; Babuaravind, G.; Bhanushree, S. Highway Accident Detection and Notification Usingmachine Learning. Int. J. Comput. Sci. Mob. Comput. 2020, 9, 168–176. [Google Scholar]
- Ghosh, S.; Sunny, S.J.; Roney, R. Accident Detection Using Convolutional Neural Networks. In Proceedings of the 2019 International Conference on Data Science and Communication (IconDSC), Bangalore, India, 1–2 March 2019. [Google Scholar] [CrossRef]
- Ijjina, E.P.; Chand, D.; Gupta, S.; Goutham, K. Computer Vision-based Accident Detection in Traffic Surveillance. In Proceedings of the 2019 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kanpur, India, 6–8 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Gollapalli, M.; Rahman, A.U.; Musleh, D.; Ibrahim, N.; Khan, M.A.; Abbas, S.; Atta, A.; Farooqui, M.; Iqbal, T.; Ahmed, M.S.; et al. A Neuro-Fuzzy Approach to Road Traffic Congestion Prediction. Comput. Mater. Contin. 2022, 73, 295–310. [Google Scholar] [CrossRef]
- Ahmed, M.I.B.; Rahman, A.-U.; Farooqui, M.; Alamoudi, F.; Baageel, R.; Alqarni, A. Early Identification of COVID-19 Using Dynamic Fuzzy Rule Based System. Math. Model. Eng. Probl. 2021, 8, 805–812. [Google Scholar] [CrossRef]
- Rahman, A.; Basheer, M.I. Virtual Clinic: A CDSS Assisted Telemedicine Framework. In Telemedicine Technologies; Academic Press: Cambridge, MA, USA, 2019; pp. 227–238. [Google Scholar]
- Alotaibi, S.M.; Rahman, A.U.; Basheer, M.I.; Khan, M.A. Ensemble Machine Learning Based Identification of Pediatric Epilepsy. Comput. Mater. Contin. 2021, 68, 149–165. [Google Scholar] [CrossRef]
- Rahman, A.-U.; Abbas, S.; Gollapalli, M.; Ahmed, R.; Aftab, S.; Ahmad, M.; Khan, M.A.; Mosavi, A. Rainfall Prediction System Using Machine Learning Fusion for Smart Cities. Sensors 2022, 22, 3504. [Google Scholar] [CrossRef] [PubMed]
- Overview of the YOLO Object Detection Algorithm|by ODSC—Open Data Science. 25 September 2018. Available online: https://odsc.medium.com/overview-of-the-yolo-object-detection-algorithm-7b52a745d3e0 (accessed on 10 May 2022).
- MEGA The Privacy Company User-Encrypted Cloud Services. Available online: https://mega.nz/folder/wtdFEK5I#i-DhrihW2Gprb07xWHhlhQ (accessed on 30 August 2022).
- Accident Detection from CCTV Footage. Available online: https://www.kaggle.com/datasets/ckay16/accident-detection-from-cctv-footage (accessed on 30 August 2022).
- Car Object Detection. Available online: https://www.kaggle.com/datasets/sshikamaru/car-object-detection (accessed on 30 August 2022).
- Alasadi, S.A.; Bhaya, W.S. Review of data preprocessing techniques in data mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar] [CrossRef]
- Yu, J.; Yang, Y.; Zhang, H.; Sun, H.; Zhang, Z.; Xia, Z.; Zhu, J.; Dai, M.; Wen, H. Spectrum Analysis Enabled Periodic Feature Reconstruction Based Automatic Defect Detection System for Electroluminescence Images of Photovoltaic Modules. Micromachines 2022, 13, 332. [Google Scholar] [CrossRef] [PubMed]
- Imran, M.; Alsuhaibani, S.A. Alsuhaibani, S.A. A Neuro-Fuzzy Inference Model for Diabetic Retinopathy Classification. In Intelligent Data Analysis for Biomedical Applications; Academic Press: Cambridge, MA, USA, 2019; pp. 147–172. [Google Scholar] [CrossRef]
- Ibrahim, N.M.; Gabr, D.G.I.; Rahman, A.-U.; Dash, S.; Nayyar, A. A deep learning approach to intelligent fruit identification and family classification. Multimed. Tools Appl. 2022, 81, 27783–27798. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18), Red Hook, NY, USA, 3–8 December 2018; pp. 8792–8802. [Google Scholar]
- Kingma, D.P.; Lei Ba, J. ADAM: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Prechelt, L. Early Stopping—But When? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 59–69. [Google Scholar] [CrossRef]
- Jose, A.; Davis, A.; Thomas, A. Accident Detection and Warning System. Int. J. Innov. Sci. Res. Technol. 2021, 6, 1532–1535. [Google Scholar]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An Improved YOLOv2 for Vehicle Detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, H.; Liang, H.; Li, H.; Dai, Z.; Yun, X. Vision-based vehicle detection and counting system using deep learning in highway scenes. Eur. Transp. Res. Rev. 2019, 11, 51. [Google Scholar] [CrossRef] [Green Version]
- Mouna, B.; Mohamed, O. A Vehicle Detection Approach Using Deep Learning Network. In Proceedings of the 2019 International Conference on Internet of Things, Embedded Systems and Communications (IINTEC), Tunis, Tunisia, 20–22 December 2019. [Google Scholar] [CrossRef]
- Mansour, A.; Hassan, A.; Hussein, W.M.; Said, E. Automated vehicle detection in satellite images using deep learning. IOP Conf. Ser. Mater. Sci. Eng. 2019, 610, 012027. [Google Scholar] [CrossRef]
- Vishnu, V.C.M.; Rajalakshmi, M.; Nedunchezhian, R. Intelligent traffic video surveillance and accident detection system with dynamic traffic signal control. Clust. Comput. 2018, 21, 135–147. [Google Scholar] [CrossRef]
- Cheng, Y.; Bai, H.; Li, Z.; Zhang, Y.; Chen, L.; Chen, K. Information Inversion and Dynamic Analysis of Video-Driven Fire Detection Based on Object-Oriented Segmentation. Fire Technol. 2022, 58, 1599–1616. [Google Scholar] [CrossRef]
- Olatunji, S.O.; Alotaibi, S.; Almutairi, E.; Alrabae, Z.; Almajid, Y.; Altabee, R.; Altassan, M.; Ahmed, M.I.B.; Farooqui, M.; Alhiyafi, J. Early diagnosis of thyroid cancer diseases using computational intelligence techniques: A case study of a Saudi Arabian dataset. Comput. Biol. Med. 2021, 131, 104267. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Pixel Dimensions |
|---|---|
| InceptionV3 | 299 × 299 |
| ResNet 152 | 256 × 256 |
| Accident’s Severity Level | The Center Receiving the Email | The Content of the Email |
|---|---|---|
| Severe | Medical Center | Severe Collision Occurred. Accident Location: (The IP address of the CCTV camera) Incident time. |
| Fire | Fire Station | Fire Occurred. Accident Location: (The IP address of the CCTV camera) Incident time. |
| Algorithm | Epoch/Iteration | Batch Size | mAP | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| YOLOv5 | 900 | 16 | 99.2% | 98.4% | 97.5% | - |
| YOLOR | 200 | 32 | 99.4% | 90.3% | 98.6% | - |
| YOLOv4-Tiny | 50,000 Iterations | - | 91.71% | 93.1% | 91% | 90.5% |
| Algorithm | Epoch/Iteration | Batch Size | mAP | Precision | Recall |
|---|---|---|---|---|---|
| YOLOv5 | 1150 | 16 | 83.3% | 84.01% | 76.7% |
| YOLOR | 100 | 16 | 87.2% | 73.9% | 86.2% |
| Faster R-CNN | 30,000 Iterations | 16 | 79.8% | - | 68.6% |
| Algorithm | Epoch/Iteration | Batch Size | Accuracy/mAP | Precision | Recall |
|---|---|---|---|---|---|
| Resnet152 | 100 | 16 | 98.955% | 98.72% | 98.905% |
| InceptionV3 | 200 | 64 | 97.563% | 98.178% | 96.768% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basheer Ahmed, M.I.; Zaghdoud, R.; Ahmed, M.S.; Sendi, R.; Alsharif, S.; Alabdulkarim, J.; Albin Saad, B.A.; Alsabt, R.; Rahman, A.; Krishnasamy, G. A Real-Time Computer Vision Based Approach to Detection and Classification of Traffic Incidents. Big Data Cogn. Comput. 2023, 7, 22. https://doi.org/10.3390/bdcc7010022
Basheer Ahmed MI, Zaghdoud R, Ahmed MS, Sendi R, Alsharif S, Alabdulkarim J, Albin Saad BA, Alsabt R, Rahman A, Krishnasamy G. A Real-Time Computer Vision Based Approach to Detection and Classification of Traffic Incidents. Big Data and Cognitive Computing. 2023; 7(1):22. https://doi.org/10.3390/bdcc7010022
Chicago/Turabian StyleBasheer Ahmed, Mohammed Imran, Rim Zaghdoud, Mohammed Salih Ahmed, Razan Sendi, Sarah Alsharif, Jomana Alabdulkarim, Bashayr Adnan Albin Saad, Reema Alsabt, Atta Rahman, and Gomathi Krishnasamy. 2023. "A Real-Time Computer Vision Based Approach to Detection and Classification of Traffic Incidents" Big Data and Cognitive Computing 7, no. 1: 22. https://doi.org/10.3390/bdcc7010022