
Explaining Exploration–Exploitation in Humans

Abstract
:1. Introduction
1.1. Motivation
- Uncertainty—the only knowledge about scores is that collected after making choices;
- A sequential nature—according to the score observed so far, the human player updates their beliefs about the possible value and location of the maximum score and then makes the next decision, to balance between trusting their expectation (i.e., exploitation) and fulfilling their need for uncertainty reduction (i.e., exploration);
- Finally, a limited budget—a limited number of sequential trials.
- In [3], it was empirically proven that the highest score found by humans at the end of the task is closer to that identified by Bayesian Optimization (BO) [6,7,8] than those found by other state-of-the-art global optimization methods. This outcome was obtained on one objective function, , and a group of 60 subjects. Indeed, the BO’s underlying rationale is reasonable for a human being: an approximation of is generated according to the observations collected so far—in BO, it is given by a probabilistic surrogate model, usually a Gaussian Process (GP) regression model—then the next location is chosen depending on the prediction provided by this approximation and the associated predictive uncertainty. In BO, these two values are combined by an acquisition function (aka utility function or infill criterion), implementing an exploitation–exploration trade-off mechanism. It is important to remark that, although in [3], there were no significant differences on the highest scores found by humans and BO at the end of the task, differences occur with respect to single sequential decisions.
- In [4], the analysis focused on investigating the possible root causes of the previously mentioned differences. GP modeling and Bayesian learning [9,10] emerged as central paradigms in modeling human learning, but fitting a GP requires to choose, a priori, a kernel that implies specific (shape) features on the approximation of , along with the associated predictive uncertainty. In [11], it was demonstrated that “GPs with standard kernels struggle on function extrapolation problems that are trivial for human learners”, but [4] empirically proved (on 14 subjects and 10 different objective functions) that a suitable uncertainty quantification measure can offer a sounder explanation, than GP’s kernel, of the differences between humans’ and BO’s single decisions. Indeed, as reported in [12], different quantifications of the uncertainty are at the core of theories of cognition and emotion and can, therefore, significantly affect the exploitation–exploration trade-off mechanism in humans’ search. Moreover, in [4], a Pareto analysis was performed, having as objectives the uncertainty quantification and the possible improvement with respect to the best score observed by the human player so far. Empirical results proved that BO acquisition functions are limited and cannot capture all the choices performed by the humans. Indeed, they can only make Pareto optimal decisions (i.e., BO is Pareto-rational), with all their possible exploitation–exploration trade-offs lying on the Pareto frontier. On the contrary, humans can also make decisions that are far away from the Pareto frontier: this specific behavior has been named “exasperated exploration” (just to differ from the exploration provided by the BO’s acquisition function). It basically coincides with pure random search and occurs with high values of the searcher’s stress. Intuitively, the stress of a human player is associated with their perception that, depending on the current beliefs, there is no chance to further improve the best score collected so far. Stress increases with an increasing number of non-improving trials and with a decreasing number of remaining trials, and it has been measured in terms of Average Cumulative Reward (ACR). It is important to remark that cumulating score is not the goal of the task assigned to humans; ACR has only been used as a possible index quantifying the human player’s stress.
- In [5], the Pareto compliance of the behavior of humans was represented as a discrete distribution binned in deciles, obtaining histograms. The Wasserstein distance was used to measure the similarity between the behavior of different users. This distributional analysis—related to decisions by 14 subjects over 10 different objective functions—was conducted at the individual level and an aggregate level, computing barycenters and performing clustering in the Wasserstein space. It is also interesting to remark that while most of the previous works in cognitive sciences addressed the issue of how people assess the information value of possible queries, in [5], the issue of the perception of probabilistic uncertainty itself was instead addressed.
1.2. Contributions
- Providing an explainable/interpretable Machine Learning model (i.e., a Decision Tree) simulating the trade-off between exploration and exploitation performed by humans, including the exasperated exploration behavior.
- Adopting the explainable/interpretable Machine Learning model to implement a “synthetic human searcher” to compare against standard Bayesian Optimization.
1.3. Related Works
1.3.1. Cognitive Sciences
1.3.2. Economics
1.3.3. Bayesian Optimization
1.3.4. Synthetic Human Searcher/Optimizer
1.4. Outline of the Paper
2. Materials and Methods
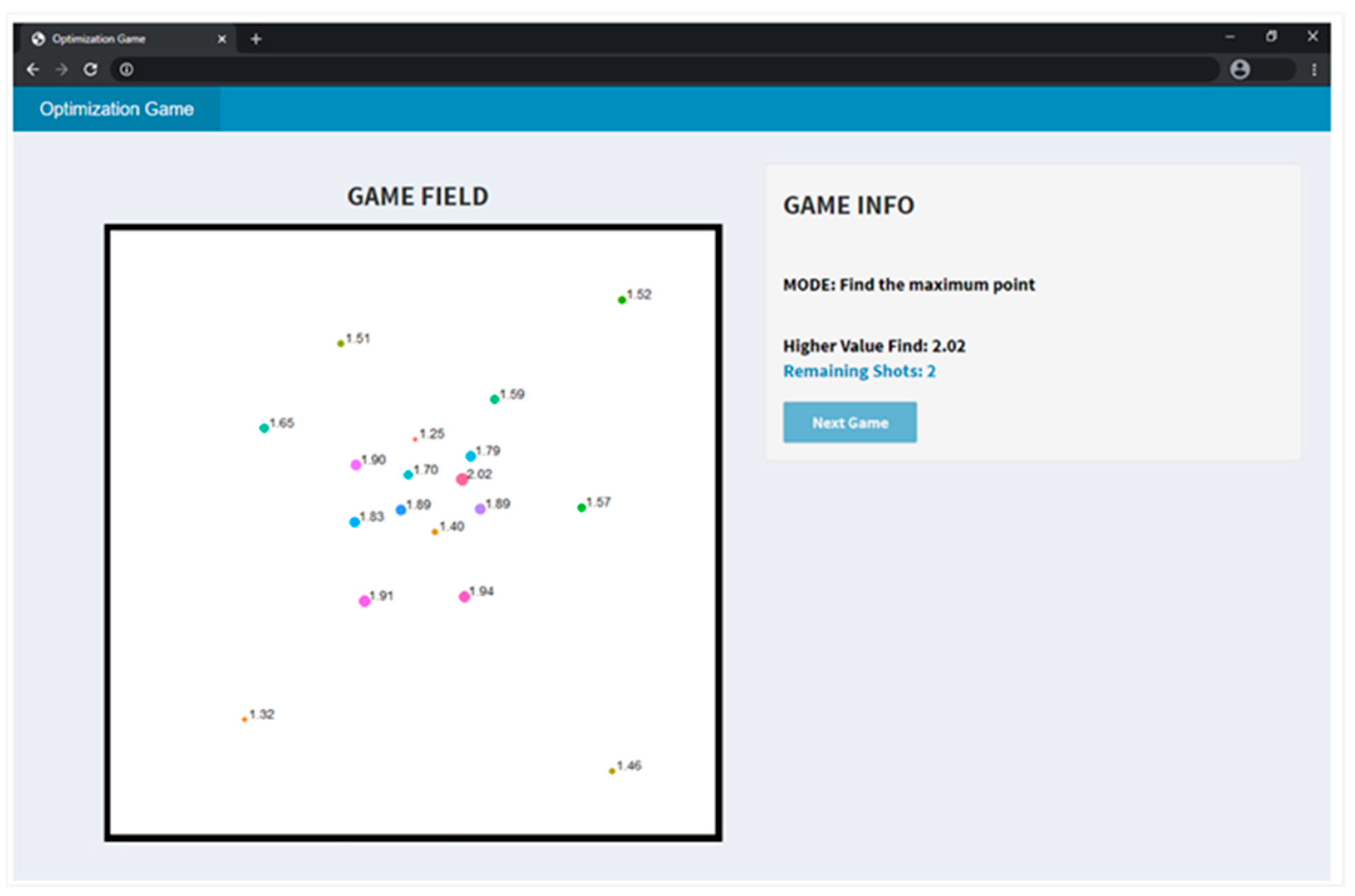
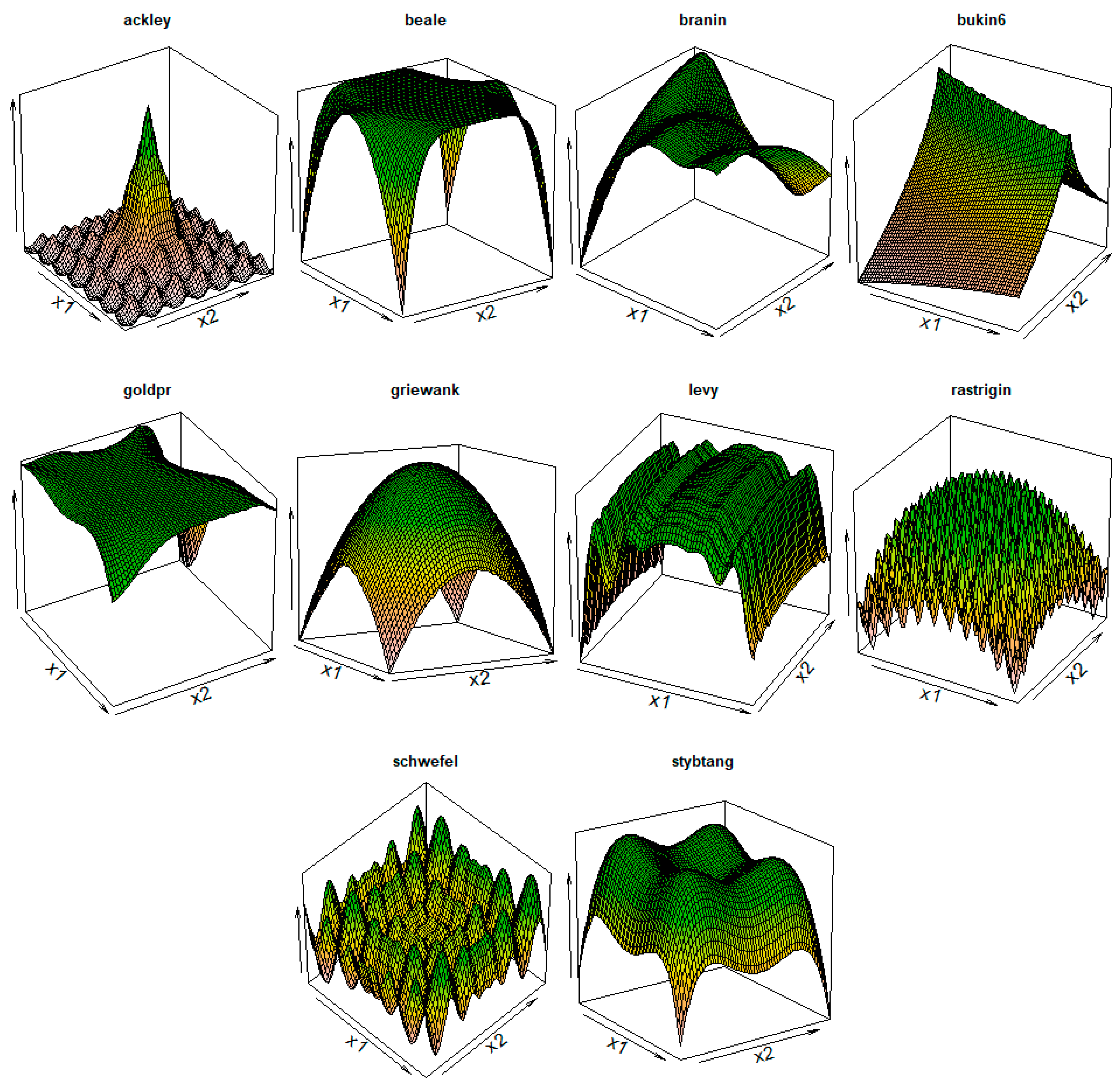
2.1. The Gaming App
2.2. Involved Subjects
2.3. Modeling: Gaussian Process Regression
- Squared Exponential: ;
- Exponential: ;
- Power-exponential: ;
- Matérn3/2: ;
- Matérn5/2: .
2.4. Pareto Analysis: Expectation vs. Uncertainty
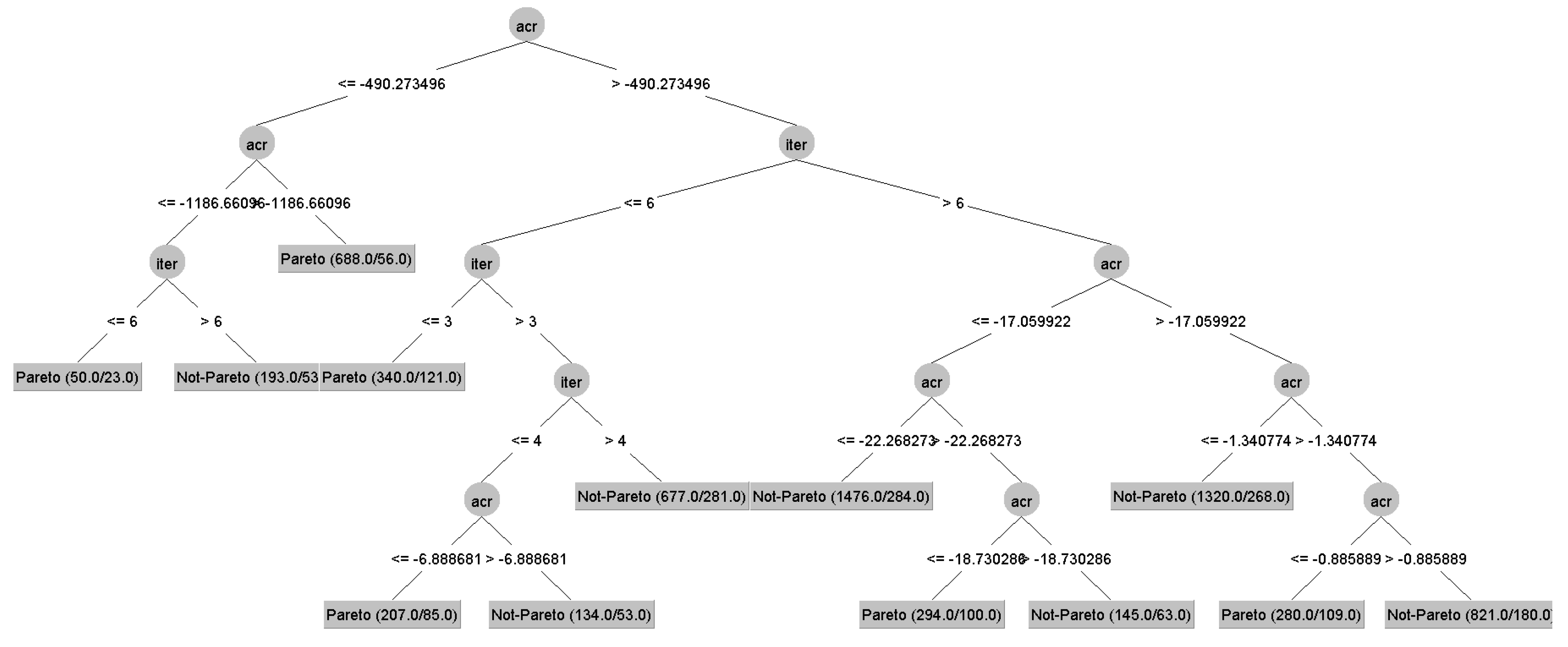
2.5. Decision Tree Analysis
3. Experimental Results
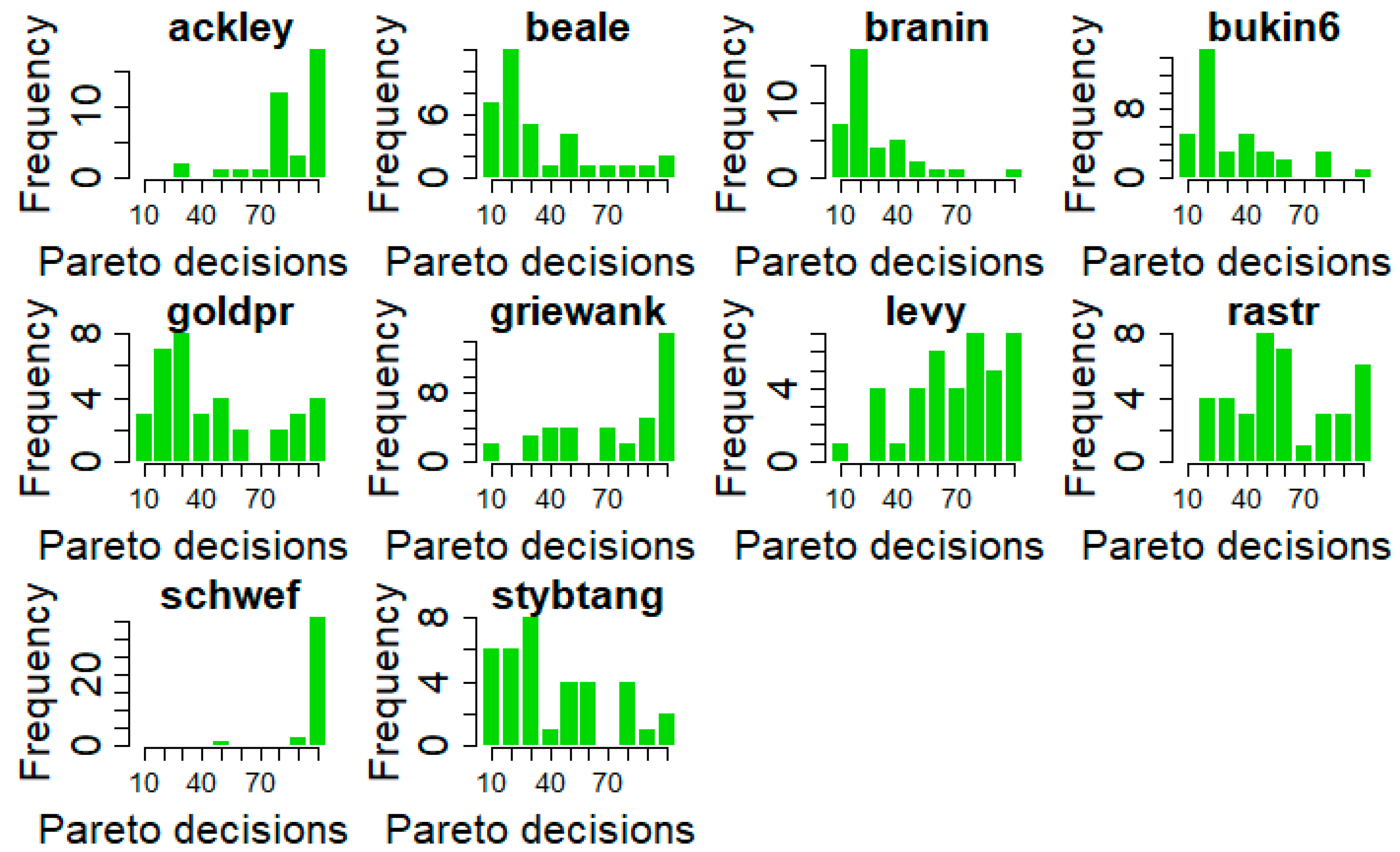
3.1. Pareto Analysis and Comparison with Previous Studies
- Cluster_1 = (ackley, griewank, levy, rastr, schwef);
- Cluster_2 = (beale, branin, bukin6, goldprsc, stybtang).
- On 4 cases (i.e., branin, bukin6, levy, and rastr), Pareto decisions seem to be induced by a higher value of . It is important to remark that these 4 cases belong to both the clusters of functions, meaning that a switch between the two types of decisions (Pareto/Not-Pareto) is always possible, at each time-step, depending on the .
- On 3 cases (i.e., beale, griewank, and stybtang), Pareto decisions seem to be induced by a lower value of . In addition, in these cases, the test functions belong to both clusters of functions, as remarked in the previous point.
3.2. Making Humans’ Strategies Explainable through Decision Tree Learning
- The black-box function underlying the game—tf;
- The user identifier—user;
- The iteration at which the decision has been taken—iter;
- The ACR—ACR;
- The type of decision, Pareto/not-Pareto, that is the “class label” to be predicted by the Decision Tree.
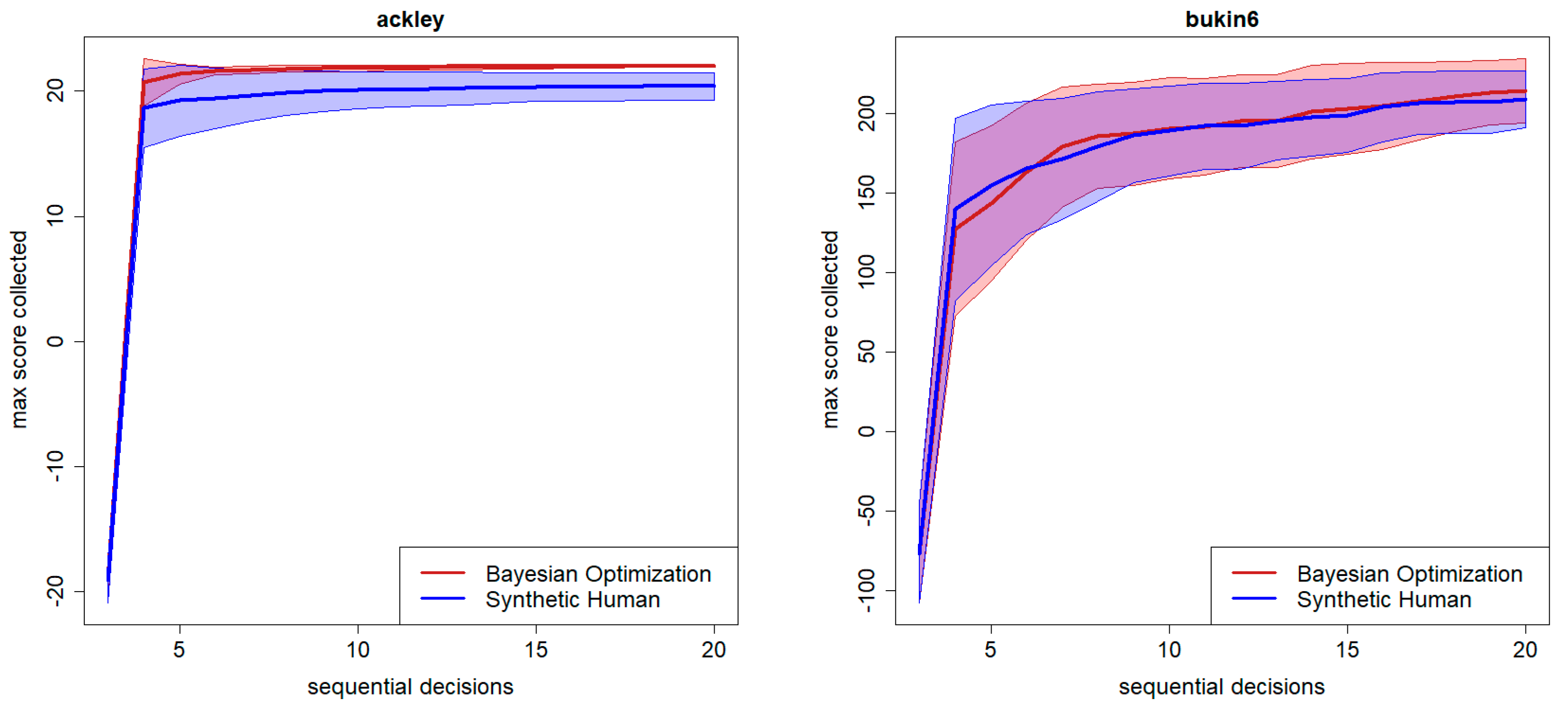
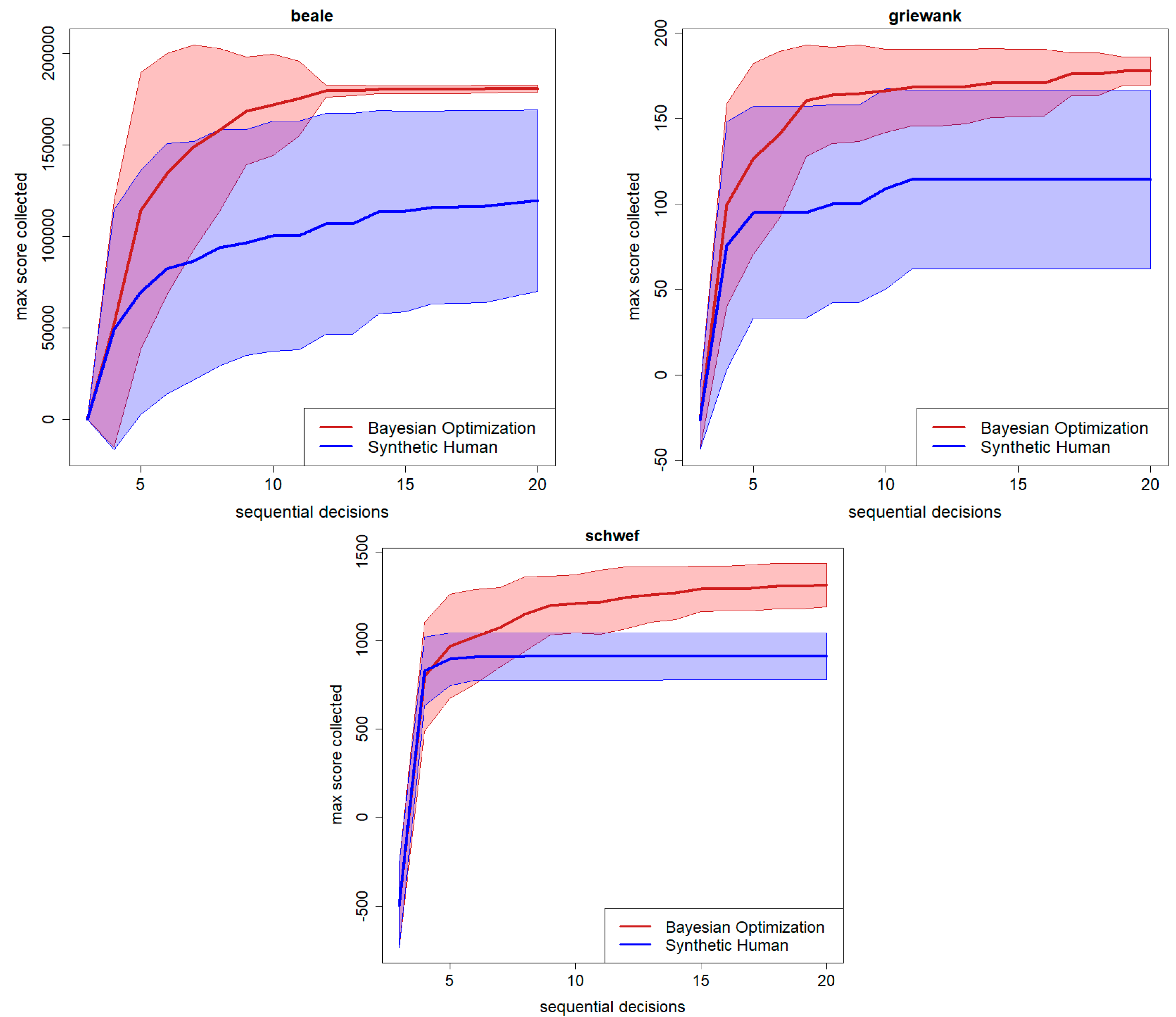
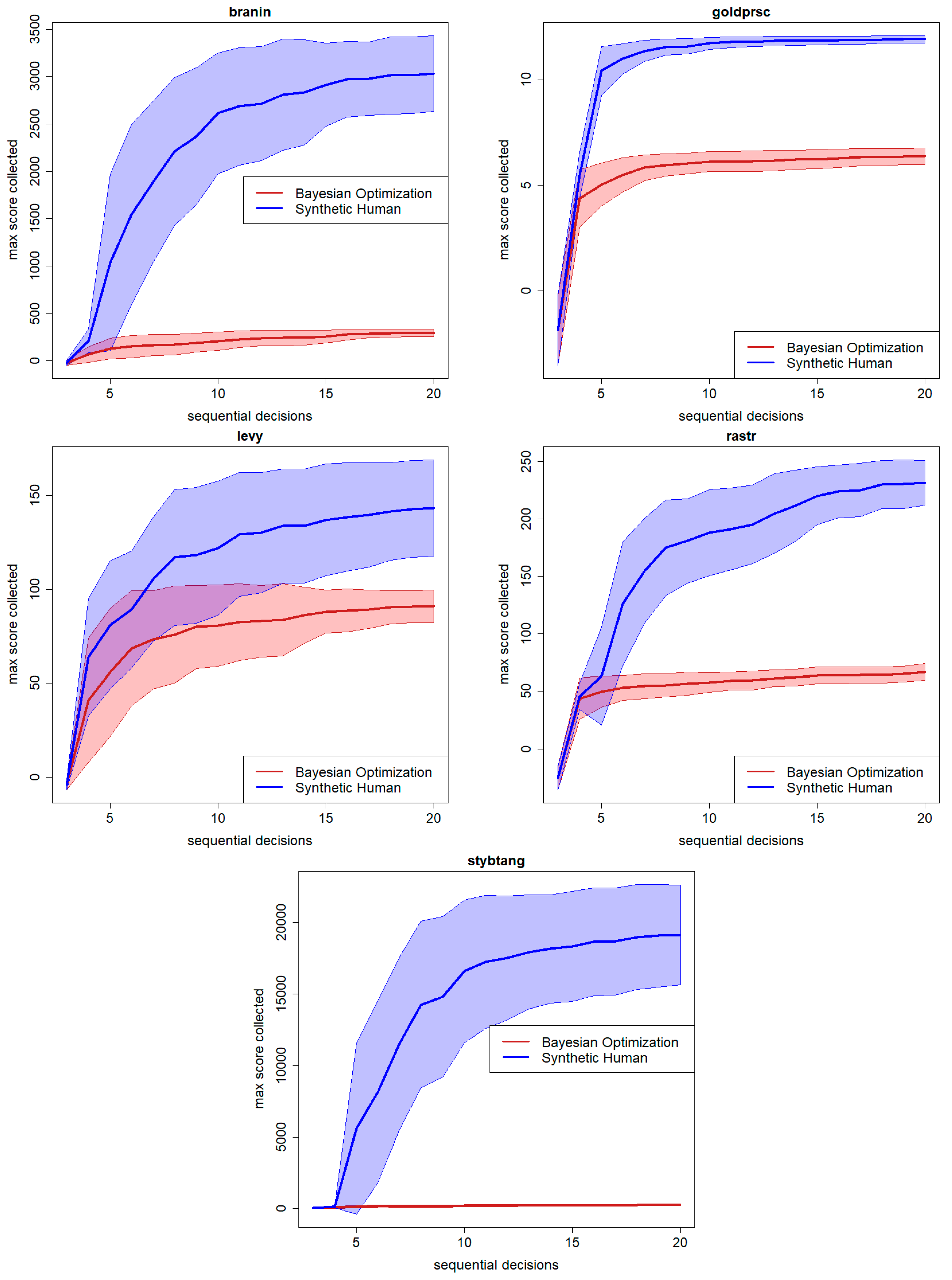
4. Testing the Synthetic Human Searcher/Optimizer
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Wilson, R.C.; Geana, A.; White, J.M.; Ludvig, E.A.; Cohen, J.D. Humans use directed and random exploration to solve the explore–exploit dilemma. J. Exp. Psychol. Gen. 2014, 143, 2074–2081. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilson, R.C.; Bonawitz, E.; Costa, V.D.; Ebitz, R.B. Balancing exploration and exploitation with information and randomization. Curr. Opin. Behav. Sci. 2020, 38, 49–56. [Google Scholar] [CrossRef] [PubMed]
- Candelieri, A.; Perego, R.; Giordani, I.; Ponti, A.; Archetti, F. Modelling human active search in optimizing black-box functions. Soft Comput. 2020, 24, 17771–17785. [Google Scholar] [CrossRef]
- Candelieri, A.; Ponti, A.; Archetti, F. Uncertainty quantification and exploration–exploitation trade-off in humans. J. Ambient. Intell. Humaniz. Comput. 2021, 1–34. [Google Scholar] [CrossRef]
- Candelieri, A.; Ponti, A.; Giordani, I.; Archetti, F. On the use of Wasserstein distance in the distributional analysis of human decision making under uncertainty. Ann. Math. Artif. Intell. 2022, 1–22. [Google Scholar] [CrossRef]
- Frazier, P.I. Bayesian optimization. In Recent Advances in Optimization and Modeling of Contemporary Problems; INFORMS: Catonsville, MD, USA, 2018; pp. 255–278. [Google Scholar] [CrossRef]
- Archetti, F.; Candelieri, A. Bayesian Optimization and Data Science; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Candelieri, A. A gentle introduction to bayesian optimization. In Proceedings of the 2021 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 12–15 December 2021; pp. 1–16. [Google Scholar] [CrossRef]
- Kruschke, J.K. Bayesian approaches to associative learning: From passive to active learning. Anim. Learn. Behav. 2008, 36, 210–226. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, T.L.; Kemp, C.; Tenenbaum, J.B. Bayesian models of cognition. In Cambridge Handbook of Computational Cognitive Modelling; Sun, R., Ed.; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar] [CrossRef]
- Wilson, A.G.; Dann, C.; Lucas, C.; Xing, E.P. The human kernel. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 2854–2862. [Google Scholar]
- Gershman, S.J. Uncertainty and exploration. Decision 2019, 6, 277–286. [Google Scholar] [CrossRef]
- Cohen, J.D.; McClure, S.M.; Yu, A.J. Should I stay or should I go? How the human brain manages the trade-off between exploitation and exploration. Philos. Trans. R. Soc. B Biol. Sci. 2007, 362, 933–942. [Google Scholar] [CrossRef] [Green Version]
- Gershman, S.J.; Uchida, N. Believing in dopamine. Nat. Rev. Neurosci. 2019, 20, 703–714. [Google Scholar] [CrossRef]
- Schulz, E.; Gershman, S.J. The algorithmic architecture of exploration in the human brain. Curr. Opin. Neurobiol. 2019, 55, 7–14. [Google Scholar] [CrossRef]
- Friston, K.; Schwartenbeck, P.; FitzGerald, T.; Moutoussis, M.; Behrens, T.; Dolan, R.J. The anatomy of choice: Dopamine and decision-making. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 20130481. [Google Scholar] [CrossRef] [PubMed]
- Borji, A.; Itti, L. Bayesian optimization explains human active search. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2013; pp. 55–63. [Google Scholar]
- Wu, C.M.; Schulz, E.; Speekenbrink, M.; Nelson, J.D.; Meder, B. Generalization guides human exploration in vast decision spaces. Nat. Hum. Behav. 2018, 2, 915–924. [Google Scholar] [CrossRef] [PubMed]
- Tversky, A.; Kahneman, D. Rational choice and the framing of decisions. In Multiple Criteria Decision-Making and Risk Analysis Using Microcomputers; Springer: Berlin/Heidelberg, Germany, 1989; pp. 81–126. [Google Scholar] [CrossRef]
- Kourouxous, T.; Bauer, T. Violations of dominance in decision-making. Bus. Res. 2019, 12, 209–239. [Google Scholar] [CrossRef] [Green Version]
- Peters, O. The ergodicity problem in economics. Nat. Phys. 2019, 15, 1216–1221. [Google Scholar] [CrossRef] [Green Version]
- Schumpeter, J.A. History of Economic Analysis; Psychology Press, Taylor and Francis an Informa Business: London, UK, 1954. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus & Giroux: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Schulz, E.; Tenenbaum, J.B.; Reshef, D.N.; Speekenbrink, M.; Gershman, S. Assessing the perceived predictability of functions. In Proceedings of the 37th Annual Meeting of the Cognitive Science Society, CogSci 2015, Pasadena, CA, USA, 22–25 July 2015. [Google Scholar]
- Gershman, S.J. Deconstructing the human algorithms for exploration. Cognition 2018, 173, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Žilinskas, A.; Calvin, J. Bi-objective decision making in global optimization based on statistical models. J. Glob. Optim. 2019, 74, 599–609. [Google Scholar] [CrossRef] [Green Version]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Srinivas, N.; Krause, A.; Kakade, S.M.; Seeger, M.W. Information-theoretic regret bounds for gaussian process optimization in the bandit setting. IEEE Trans. Inf. Theory 2012, 58, 3250–3265. [Google Scholar] [CrossRef] [Green Version]
- Iwazaki, S.; Inatsu, Y.; Takeuchi, I. Mean-variance analysis in Bayesian optimization under uncertainty. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, Virtually, 13–15 April 2021; pp. 973–981. [Google Scholar]
- De Ath, G.; Everson, R.M.; Fieldsend, J.E.; Rahat, A.A. ϵ-shotgun: ϵ-greedy batch bayesian optimisation. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference, Cancún, Mexico, 8–12 July 2020; pp. 787–795. [Google Scholar] [CrossRef]
- De Ath, G.; Everson, R.M.; Rahat, A.A.; Fieldsend, J.E. Greed is good: Exploration and exploitation trade-offs in Bayesian optimisation. ACM Trans. Evol. Learn. Optim. 2021, 1, 1–22. [Google Scholar] [CrossRef]
- Sandholtz, N.; Miyamoto, Y.; Bornn, L.; Smith, M.A. Inverse Bayesian Optimization: Learning Human Acquisition Functions in an Exploration vs Exploitation Search Task. Bayesian Anal. 2022, 18, 1–24. [Google Scholar] [CrossRef]
- Gajawada, S. Artificial Human Optimization-An Introduction. Trans. Mach. Learn. Artif. Intell. 2018, 6. [Google Scholar] [CrossRef]
- Gajawada, S. Ten artificial human optimization algorithms. Trans. Mach. Learn. Artif. Intell. 2019, 6, 1–9. [Google Scholar] [CrossRef]
- Brochu, E. Interactive Bayesian Optimization: Learning User Preferences for Graphics and Animation. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2010. [Google Scholar]
- Astudillo, R.; Frazier, P. Multi-attribute Bayesian optimization with interactive preference learning. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Virtually, 26–28 August 2020; pp. 4496–4507. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar] [CrossRef] [Green Version]
- Gramacy, R.B. Surrogates: Gaussian Process Modeling, Design, and Optimization for the Applied Sciences; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar] [CrossRef]
- Bemporad, A. Global optimization via inverse distance weighting and radial basis functions. Comput. Optim. Appl. 2020, 77, 571–595. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Function | Original Distance from Pareto Front | [0, 1]-Rescaled Distance from Pareto Front |
|---|---|---|
| ackley | 57.29% | 58.46% (+1.17%) |
| beale | 10.15% | 31.06% (+20.91%) |
| branin | 8.96% | 10.59% (+1.63%) |
| bukin6 | 11.79% | 14.39% (+2.6%) |
| goldprsc | 13.51% | 14.09% (+0.58%) |
| griewank | 25.97% | 27.51% (+1.54%) |
| levy | 18.58% | 22.11% (+3.53%) |
| rastr | 23.00% | 25.11% (+2.11%) |
| schwef | 95.26% | 95.26% (+0.00%) |
| stybtang | 14.95% | 17.79% (+2.84%) |
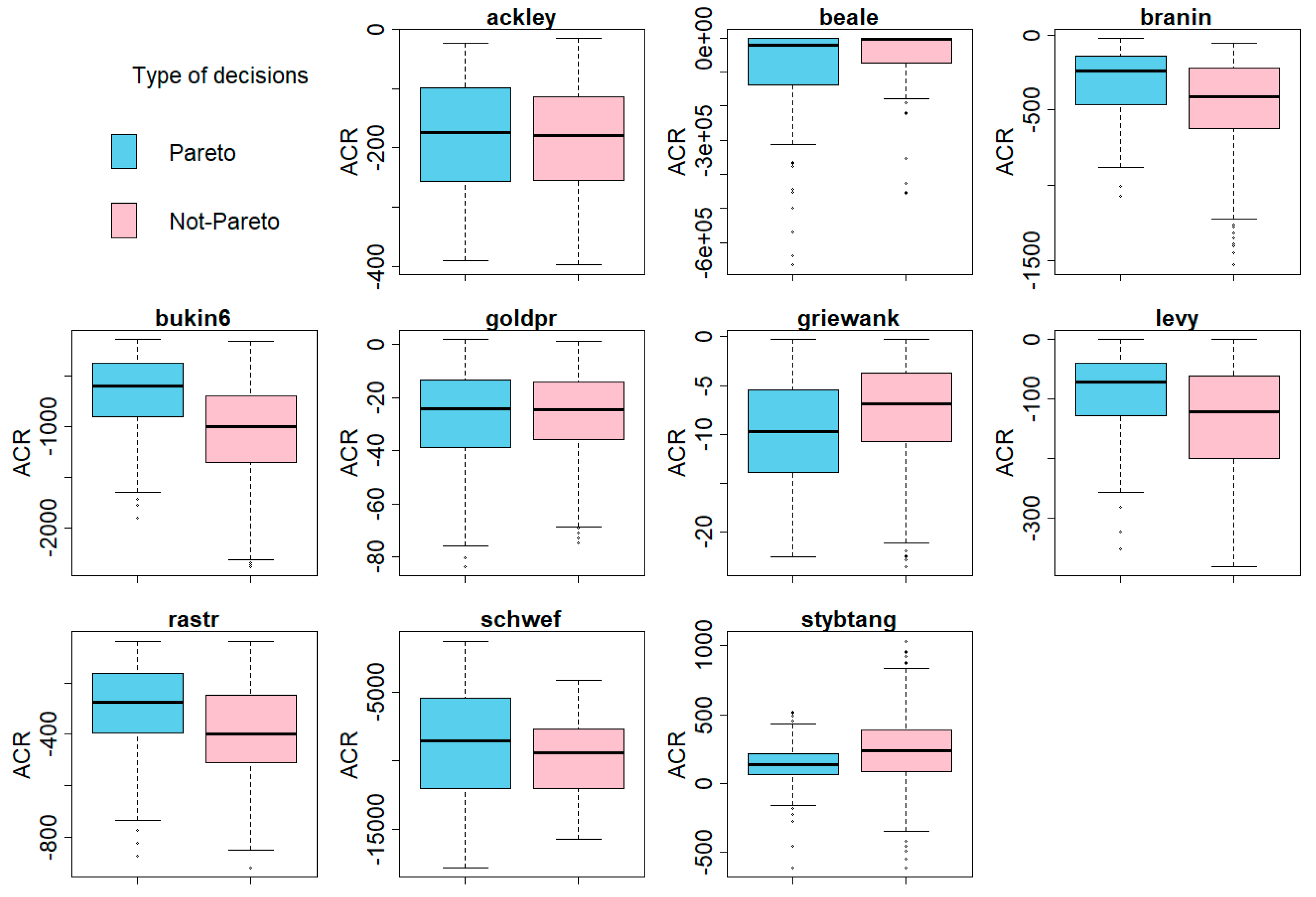
| Test Function | ACR Pareto | ACR Not-Pareto | U Mann-Whitney Test |
|---|---|---|---|
| Mean (SD) | Mean (SD) | p-Value | |
| ackley | −182.6841 (94.268) | −183.1297 (90.2213) | 0.7447 |
| beale | −98,706.7900 (152,129.9000) | −45,552.8900 (84,082.4400) | 0.0318 |
| branin | −316.1284 (235.0969) | −460.6150 (296.6918) | <0.001 |
| bukin6 | −694.5507 (410.6313) | −1045.3670 (466.4098) | <0.001 |
| goldprscsc | −27.2690 (19.5577) | −26.6695 (16.9001) | 0.9825 |
| griewank | −9.8474 (5.2752) | −7.68593 (5.25079) | <0.001 |
| levy | −92.9790 (70.8990) | −135.2082 (88.2782) | <0.001 |
| rastr | −298.4032 (166.3426) | −387.9695 (170.5657) | <0.001 |
| schwef | −8823.6370 (4015.2560) | −9797.6580 (3172.1390) | 0.1772 |
| stybtang | 135.8438 (155.6749) | 244.7435 (244.6132) | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Candelieri, A.; Ponti, A.; Archetti, F. Explaining Exploration–Exploitation in Humans. Big Data Cogn. Comput. 2022, 6, 155. https://doi.org/10.3390/bdcc6040155
Candelieri A, Ponti A, Archetti F. Explaining Exploration–Exploitation in Humans. Big Data and Cognitive Computing. 2022; 6(4):155. https://doi.org/10.3390/bdcc6040155
Chicago/Turabian StyleCandelieri, Antonio, Andrea Ponti, and Francesco Archetti. 2022. "Explaining Exploration–Exploitation in Humans" Big Data and Cognitive Computing 6, no. 4: 155. https://doi.org/10.3390/bdcc6040155