

THOR: A Hybrid Recommender System for the Personalized Travel Experience

 ,
,  , , , and
, , , and
Abstract
:1. Introduction
2. Background and Related Work
2.1. Ecosystem
2.2. Recommender Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type | Category | Name | Type | Category |
|---|---|---|---|---|---|
| Age | Cat. | Profile | Starting Point | Cat. | Offer |
| City | Cat. | Profile | Destination | Cat. | Offer |
| Country | Cat. | Profile | Via | List | Offer |
| Loyalty Cards | List | Profile | LegMode | List | Offer |
| Payment Cards | List | Profile | Class | List | Offer |
| PRM Type | List | Profile | Seats Type | List | Offer |
| Profile Type | Cat. | Profile | Arrival Time | Cat. | Offer |
| Quick | Float | Offer | Departure Time | Cat. | Offer |
| Reliable | Float | Offer | Preferred Transp. Types | List | Search |
| Cheap | Float | Offer | Preferred Carriers | List | Search |
| Comfortable | Float | Offer | Preferred Refund Type | Cat. | Search |
| Door-to-door | Float | Offer | Preferred Services | List | Search |
| Envir. Friendly | Float | Offer | Max. No. of Transfers | Int. | Search |
| Short | Float | Offer | Max. Transfers Duration | Cat. | Search |
| Multitasking | Float | Offer | Max. Walking Dist. to Stop | Cat. | Search |
| Social | Float | Offer | Walking Speed | Cat. | Search |
| Panoramic | Float | Offer | Cycling Distance to Stop | Cat. | Search |
| Healthy | Float | Offer | Cycling Speed | Cat. | Search |
| Legs Number | Int. | Offer | Driving Speed | Cat. | Search |
2.3. Travelers’ Preferences
2.4. Cold Start Problem
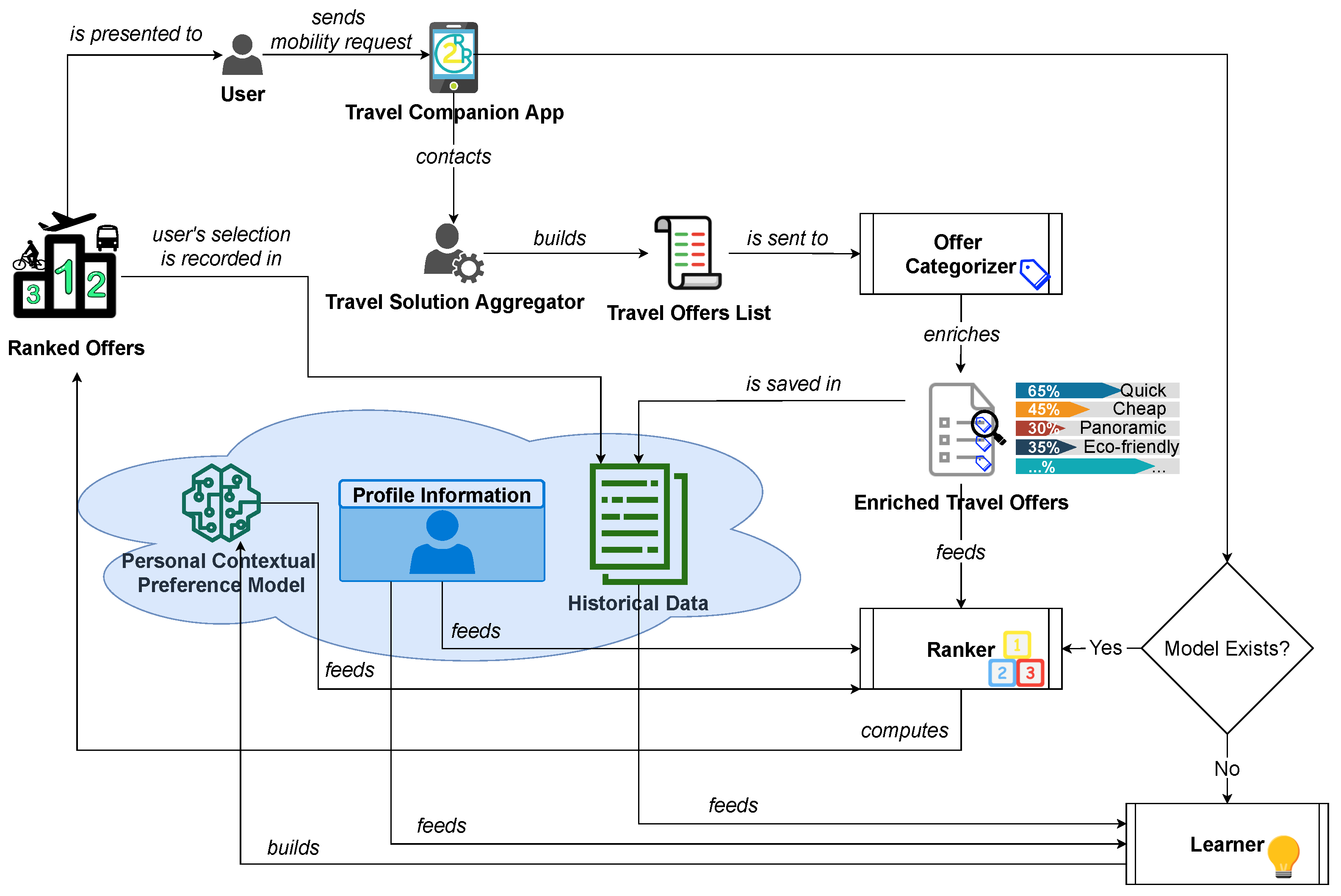
3. The Hybrid Offer Ranker (THOR)
3.1. Overview
3.2. Data Pre-Processing
- One-Hot Encoding:This step translates the raw textual data into a numerical one-hot version. Moreover, null data are replaced with zeros. Consider, for example, the feature “Profile”, which takes one of the following four values: “Basic”, “Business”, “Family”, or “Leisure”. During one-hot encoding, “Profile” is split into four features (one for each possible value) that are mutually exclusive—i.e., only one of them can have a value equal to one, while the rest are zero.
- Information-Less Columns Dropping (ILCD): in this step, the system deletes all columns that have the same value in the dataset. For instance, if the user has never changed their hometown, we can delete it because this feature means nothing to our system. Deleting these columns substantially speeds up the training phase.
- Data Normalization: Since the scales and magnitudes of the features are not the same, if the original data values are used directly during the prediction phase, their degree of influence is different. The system applies a normalization process through which every feature will have the same influence on the result.
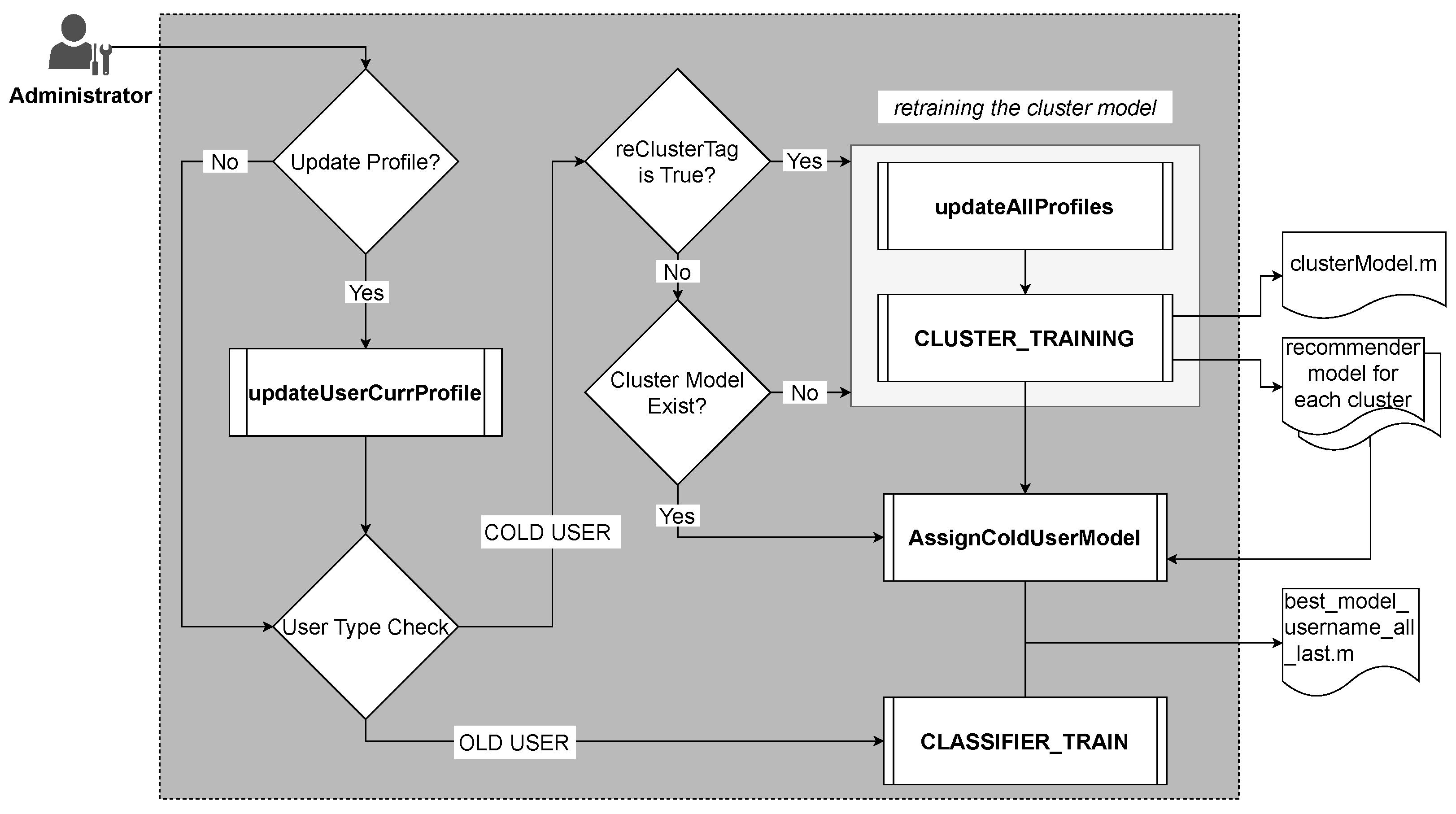
3.3. Learner Module
| Algorithm 1 Learner |
|
| Algorithm 2 Cluster Model Training |
|
3.3.1. Cluster Training for New User
3.3.2. User Recommender Model Training
| Algorithm 3 Recommender Model Training |
|
3.4. Ranker
| Algorithm 4 RANKER |
|
3.5. User Feedback
4. Experimental Results
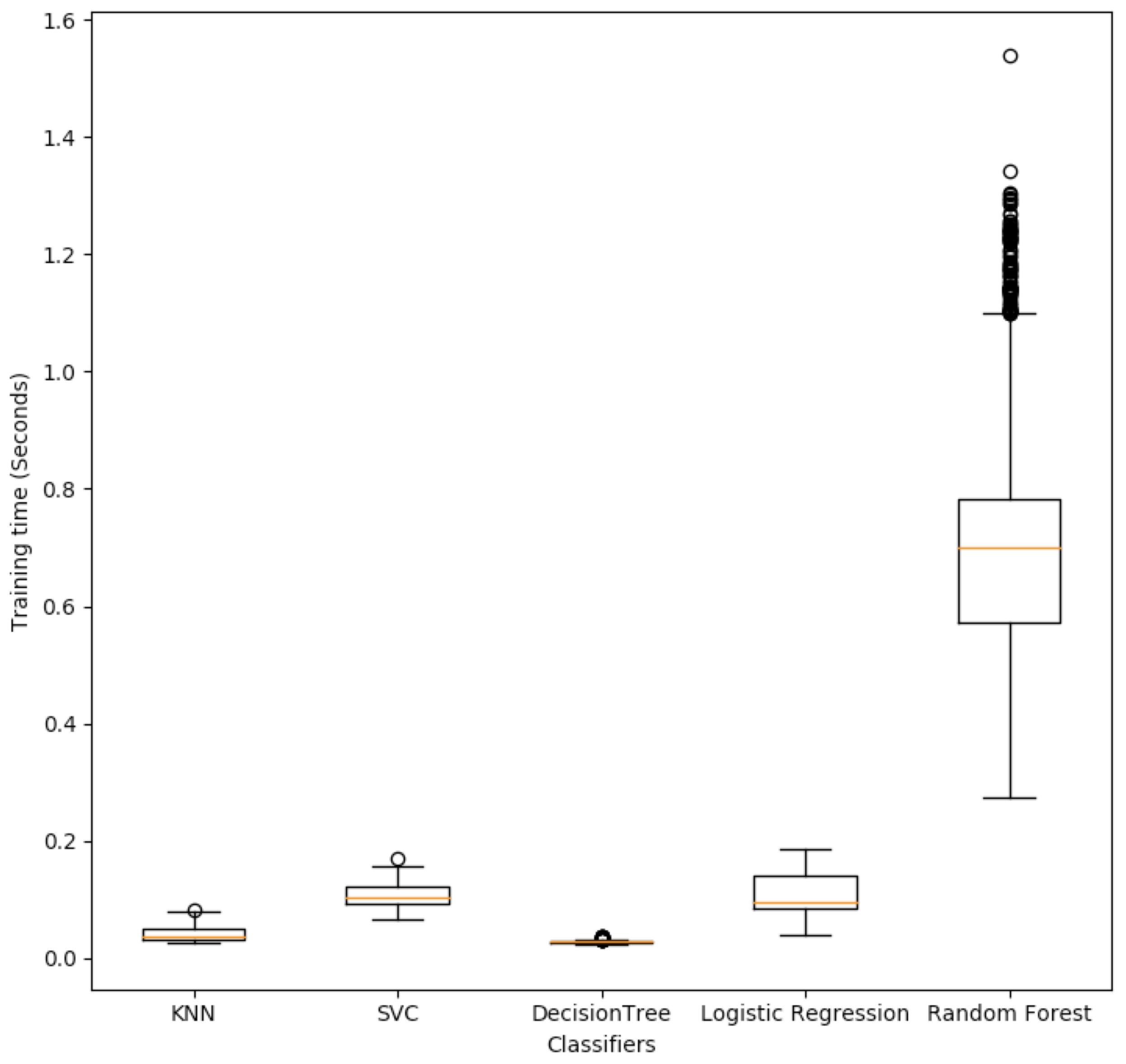
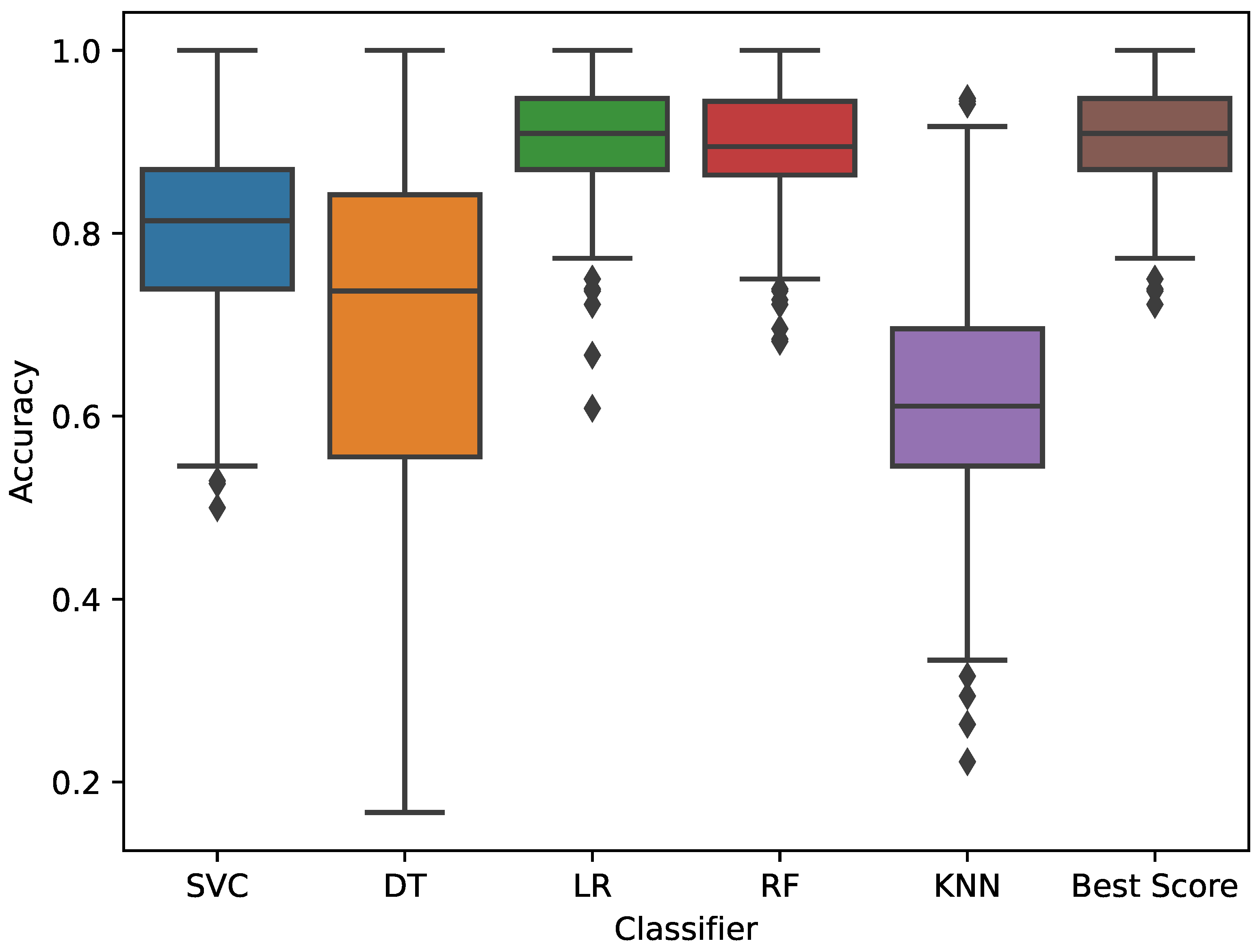
4.1. Validating the Classifiers
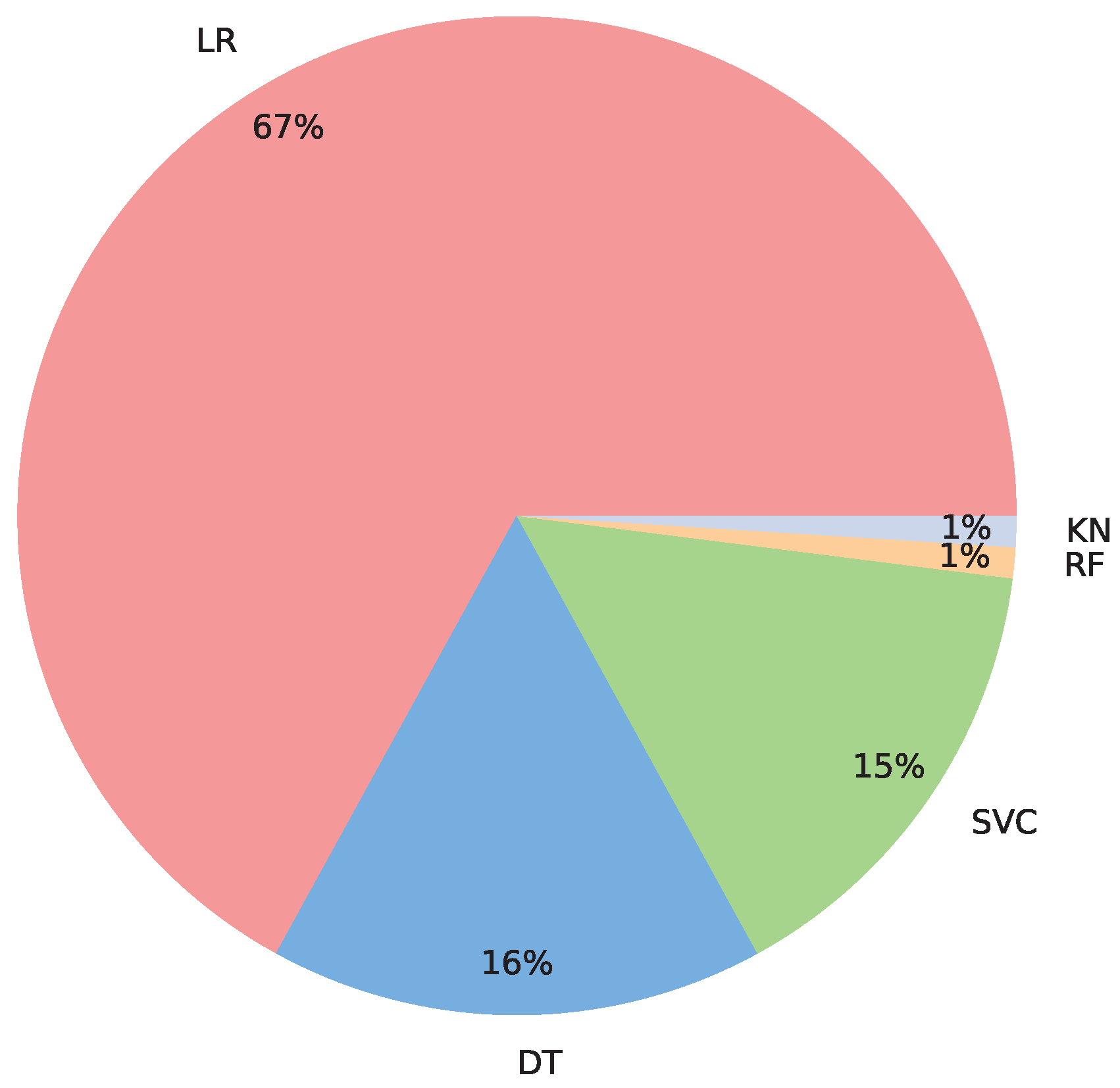
4.2. Validating the Ranker
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brambilla, M.; Javadian Sabet, A.; Masciadri, A. Data-driven user profiling for smart ecosystems. In Smart Living between Cultures and Practices. A Design Oriented Perspective; Mandragora: Milan, Italy, 2019; pp. 84–98. [Google Scholar]
- Ferreira, J.C.; Martins, A.L.; da Silva, J.V.; Almeida, J. T2*—Personalized Trip Planner. In Proceedings of the Ambient Intelligence–Software and Applications—8th International Symposium on Ambient Intelligence (ISAmI 2017), Porto, Portugal, 21–23 June 2017; De Paz, J.F., Julián, V., Villarrubia, G., Marreiros, G., Novais, P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 167–175. [Google Scholar]
- Chen, X.; Liu, Q.; Qiao, X. Approaching Another Tourism Recommender. In Proceedings of the 2020 IEEE 20th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Macau, China, 11–14 December 2020; pp. 556–562. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to Recommender Systems Handbook. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 1–35. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-Aware Recommender Systems. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 217–253. [Google Scholar] [CrossRef]
- Abbar, S.; Bouzeghoub, M.; Lopez, S. Context-aware recommender systems: A service-oriented approach. In Proceedings of the VLDB PersDB Workshop, Lyon, France, 28 August 2009; pp. 1–6. [Google Scholar]
- Villegas, N.M.; Sánchez, C.; Díaz-Cely, J.; Tamura, G. Characterizing context-aware recommender systems: A systematic literature review. Knowl.-Based Syst. 2018, 140, 173–200. [Google Scholar] [CrossRef]
- Sabet, A.J.; Rossi, M.; Schreiber, F.A.; Tanca, L. Context Awareness in the Travel Companion of the Shift2Rail Initiative. In Proceedings of the 28th Italian Symposium on Advanced Database Systems, CEUR-WS.org, CEUR Workshop Proceedings, Villasimius, Sardinia, Italy, 21–24 June 2020; Volume 2646, pp. 202–209. [Google Scholar]
- Javadian Sabet, A.; Rossi, M.; Schreiber, F.A.; Tanca, L. Towards Learning Travelers’ Preferences in a Context-Aware Fashion. In Proceedings of the Ambient Intelligence—Software and Applications; Springer International Publishing: Cham, Switzerland, 2021; pp. 203–212. [Google Scholar] [CrossRef]
- Dey, A. Understanding and Using Context. Pers. Ubiquitous Comput. 2001, 5, 4–7. [Google Scholar] [CrossRef]
- Bolchini, C.; Curino, C.A.; Quintarelli, E.; Schreiber, F.A.; Tanca, L. A data-oriented survey of context models. ACM Sigmod Rec. 2007, 36, 19–26. [Google Scholar] [CrossRef] [Green Version]
- Alegre, U.; Augusto, J.C.; Clark, T. Engineering context-aware systems and applications: A survey. J. Syst. Softw. 2016, 117, 55–83. [Google Scholar] [CrossRef]
- Hong, J.Y.; Suh, E.H.; Kim, S.J. Context-aware systems: A literature review and classification. Expert Syst. Appl. 2009, 36, 8509–8522. [Google Scholar] [CrossRef]
- Ng, P.C.; She, J.; Cheung, M.; Cebulla, A. An Images-Textual Hybrid Recommender System for Vacation Rental. In Proceedings of the 2016 IEEE Second International Conference on Multimedia Big Data (BigMM), Taipei, Taiwan, 20–22 April 2016; pp. 60–63. [Google Scholar] [CrossRef]
- Sebastia, L.; Garcia, I.; Onaindia, E.; Guzman, C. e-Tourism: A Tourist Recommendation and Planning Application. In Proceedings of the 2008 20th IEEE International Conference on Tools with Artificial Intelligence, Dayton, OH, USA, 3–5 November 2008; Volume 2, pp. 89–96. [Google Scholar] [CrossRef] [Green Version]
- Kbaier, M.E.B.H.; Masri, H.; Krichen, S. A Personalized Hybrid Tourism Recommender System. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 244–250. [Google Scholar] [CrossRef]
- Bolchini, C.; Quintarelli, E.; Tanca, L. CARVE: Context-aware automatic view definition over relational databases. Inf. Syst. 2013, 38, 45–67. [Google Scholar] [CrossRef]
- Arnaoutaki, K.; Bothos, E.; Magoutas, B.; Aba, A.; Esztergár-Kiss, D.; Mentzas, G. A Recommender System for Mobility-as-a-Service Plans Selection. Sustainability 2021, 13, 8245. [Google Scholar] [CrossRef]
- Jaafar, H.B.; Mukahar, N.B.; Binti Ramli, D.A. A methodology of nearest neighbor: Design and comparison of biometric image database. In Proceedings of the 2016 IEEE Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 30 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Lan, L.S. M-SVC (mixed-norm SVC)—A novel form of support vector classifier. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems, Kos, Greece, 21–24 May 2006; p. 3264. [Google Scholar] [CrossRef]
- Yu, Y.; Fu, Z.-L.; Zhao, X.-H.; Cheng, W.-F. Combining Classifier Based on Decision Tree. In Proceedings of the 2009 WASE International Conference on Information Engineering, Taiyuan, China, 10–11 July 2009; Volume 2, pp. 37–40. [Google Scholar] [CrossRef]
- Bingzhen, Z.; Xiaoming, Q.; Hemeng, Y.; Zhubo, Z. A Random Forest Classification Model for Transmission Line Image Processing. In Proceedings of the 2020 15th International Conference on Computer Science Education (ICCSE), Delft, The Netherlands, 18–22 August 2020; pp. 613–617. [Google Scholar] [CrossRef]
- Zou, X.; Hu, Y.; Tian, Z.; Shen, K. Logistic Regression Model Optimization and Case Analysis. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 135–139. [Google Scholar] [CrossRef]
- Lu, S.; Yu, H.; Wang, X.; Zhang, Q.; Li, F.; Liu, Z.; Ning, F. Clustering Method of Raw Meal Composition Based on PCA and Kmeans. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9007–9010. [Google Scholar] [CrossRef]
- Smiti, A.; Elouedi, Z. DBSCAN-GM: An improved clustering method based on Gaussian Means and DBSCAN techniques. In Proceedings of the 2012 IEEE 16th International Conference on Intelligent Engineering Systems (INES), Lisbon, Portugal, 13–15 June 2012; pp. 573–578. [Google Scholar] [CrossRef]
- Golightly, D.; Comerio, M.; Consonni, C.; Vaghi, C.; Pistilli, G.; Rizzi, G.; Di Pasquale, G.; Palacin, R.; Boratto, L.; Scrocca, M. Ride2Rail: Integrating ridesharing for attractive multimodal rail journeys. In Proceedings of the World Congress Rail Research 2022, Birmingham, UK, 6–10 June 2022. [Google Scholar]
- Sadeghi, M.; Buchníček, P.; Carenini, A.; Corcho, O.; Gogos, S.; Rossi, M.; Santoro, R. SPRINT: Semantics for PerfoRmant and scalable INteroperability of multimodal Transport. In Proceedings of the TRA, Helsinki, Finland, 27–30 April 2020; pp. 1–10. [Google Scholar]
- Hosseini, M.; Kalwar, S.; Rossi, M.G.; Sadeghi, M. Automated mapping for semantic-based conversion of transportation data formats. In Proceedings of the 1st International Workshop On Semantics For Transport, Karlsruhe, Germany, 9 September 2019; Volume 2447, pp. 1–6. [Google Scholar]
- Kalwar, S.; Sadeghi, M.; Javadian Sabet, A.; Nemirovskiy, A.; Rossi, M.G. SMART: Towards Automated Mapping between Data Specifications. In Proceedings of the 33rd International Conference on Software Engineering and Knowledge Engineering, SEKE 2021, KSIR Virtual Conference Center, Pittsburgh, PA, USA, 1–10 July 2021. [Google Scholar] [CrossRef]
- Carenini, A.; Dell’Arciprete, U.; Gogos, S.; Kallehbasti, M.M.P.; Rossi, M.; Santoro, R. ST4RT – Semantic Transformations for Rail Transportation. In Proceedings of the TRA 2018, Vienna, Austria, 16–19 April 2018; pp. 1–10. [Google Scholar]
- Alobaid, A.; Garijo, D.; Poveda-Villalón, M.; Santana-Perez, I.; Fernández-Izquierdo, A.; Corcho, O. Automating ontology engineering support activities with OnToology. J. Web Semant. 2019, 57, 100472. [Google Scholar] [CrossRef]
- Sadeghi, M.; Sartor, L.; Rossi, M. A Semantic-Based Access Control Mechanism for Distributed Systems. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, SAC’ 21, Gwangju, Korea, 22–26 March 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1864–1873. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Cai, Y.; Leung, H.F.; Li, Q.; Min, H.; Tang, J.; Li, J. Typicality-Based Collaborative Filtering Recommendation. IEEE Trans. Knowl. Data Eng. 2014, 26, 766–779. [Google Scholar] [CrossRef] [Green Version]
- Valliyammai, C.; PrasannaVenkatesh, R.; Vennila, C.; Krishnan, S.G. An intelligent personalized recommendation for travel group planning based on reviews. In Proceedings of the 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, 19–21 January 2017; pp. 67–71. [Google Scholar] [CrossRef]
- Cao, Y.; Li, Y. An intelligent fuzzy-based recommendation system for consumer electronic products. Expert Syst. Appl. 2007, 33, 230–240. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Lorenzi, F.; Loh, S.; Abel, M. PersonalTour: A Recommender System for Travel Packages. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; Volume 2, pp. 333–336. [Google Scholar] [CrossRef]
- Sabet, A.J.; Gopalakrishnan, S.; Rossi, M.; Schreiber, F.A.; Tanca, L. Preference Mining in the Travel Domain. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; pp. 358–365. [Google Scholar] [CrossRef]
- Fang, G.S.; Kamei, S.; Fujita, S. Automatic Generation of Temporal Feature Vectors with Application to Tourism Recommender Systems. In Proceedings of the 2016 Fourth International Symposium on Computing and Networking (CANDAR), Hiroshima, Japan, 22–25 November 2016; pp. 676–680. [Google Scholar] [CrossRef]
- Coelho, J.; Nitu, P.; Madiraju, P. A Personalized Travel Recommendation System Using Social Media Analysis. In Proceedings of the 2018 IEEE International Congress on Big Data (BigData Congress), Seattle, DC, USA, 10–13 December 2018; pp. 260–263. [Google Scholar] [CrossRef] [Green Version]
- Fararni, K.A.; Nafis, F.; Aghoutane, B.; Yahyaouy, A.; Riffi, J.; Sabri, A. Hybrid recommender system for tourism based on big data and AI: A conceptual framework. Big Data Min. Anal. 2021, 4, 47–55. [Google Scholar] [CrossRef]
- Shekari, M.; Sabet, A.J.; Guan, C.; Rossi, M.; Schreiber, F.A.; Tanca, L. Personalized Context-Aware Recommender System for Travelers. In Proceedings of the 30th Italian Symposium on Advanced Database Systems, SEBD 2022, Tirrenia, Italy, 19–22 June 2022; Amato, G., Bartalesi, V., Bianchini, D., Gennaro, C., Torlone, R., Eds.; 2022; Volume 3194, pp. 497–504. [Google Scholar]
- Basile, S.; Consonni, C.; Manca, M.; Boratto, L. Matching User Preferences and Behavior for Mobility. In Proceedings of the 31st ACM Conference on Hypertext and Social Media, HT ’20, Online, 13–15 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 141–150. [Google Scholar] [CrossRef]
- Consonni, C.; Basile, S.; Manca, M.; Boratto, L.; Freitas, A.; Kovacikova, T.; Pourhashem, G.; Cornet, Y. What’s Your Value of Travel Time? Collecting Traveler-Centered Mobility Data via Crowdsourcing. arXiv 2021, arXiv:cs.CY/2104.05809. [Google Scholar] [CrossRef]
- Boratto, L.; Manca, M.; Lugano, G.; Gogola, M. Characterizing user behavior in journey planning. Computing 2020, 102. [Google Scholar] [CrossRef]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in IR, Tampere, Finland, 11–15 August 2002; pp. 253–260. [Google Scholar]
- Rashid, A.M.; Albert, I.; Cosley, D.; Lam, S.K.; McNee, S.M.; Konstan, J.A.; Riedl, J. Getting to Know You: Learning New User Preferences in Recommender Systems. In Proceedings of the 7th International Conference on Intelligent User Interfaces, IUI ’02, College Station, TX, USA, 21–25 March 2022; Association for Computing Machinery: New York, NY, USA, 2002; pp. 127–134. [Google Scholar] [CrossRef]
- Guo, G. Integrating trust and similarity to ameliorate the data sparsity and cold start for recommender systems. In Proceedings of the 7th ACM conference on Recommender Systems, Hong Kong, 12–16 October 2013; pp. 451–454. [Google Scholar]
- Yu, K.; Schwaighofer, A.; Tresp, V.; Xu, X.; Kriegel, H.P. Probabilistic memory-based collaborative filtering. IEEE Trans. Knowl. Data Eng. 2004, 16, 56–69. [Google Scholar] [CrossRef]
- Ghodsad, P.R.; Chatur, P.N. Handling User Cold-Start Problem for Group Recommender System Using Social Behaviour Wise Group Detection Method. In Proceedings of the 2018 International Conference on Research in Intelligent and Computing in Engineering (RICE), San Salvador, El Salvador, 22–24 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Sang, A.; Vishwakarma, S.K. A ranking based recommender system for cold start data sparsity problem. In Proceedings of the 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 10–12 August 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN Revisited, Revisited: Why and How You Should (Still) Use DBSCAN. ACM Trans. Database Syst. 2017, 42, 3068335. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin, Germany, 2013; Volume 112. [Google Scholar]
- Kanagala, H.K.; Jaya Rama Krishnaiah, V. A comparative study of K-Means, DBSCAN and OPTICS. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kumar, R.; Verma, R. Classification algorithms for data mining: A survey. Int. J. Innov. Eng. Technol. (Ijiet) 2012, 1, 7–14. [Google Scholar]
- Narayanan, U.; Unnikrishnan, A.; Paul, V.; Joseph, S. A survey on various supervised classification algorithms. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, India, 1–2 August 2017; pp. 2118–2124. [Google Scholar] [CrossRef]
- Chung, T.H.; Burdick, J.W. Analysis of Search Decision Making Using Probabilistic Search Strategies. IEEE Trans. Robot. 2012, 28, 132–144. [Google Scholar] [CrossRef]
- Huang, Q.; Mao, J.; Liu, Y. An improved grid search algorithm of SVR parameters optimization. In Proceedings of the 2012 IEEE 14th International Conference on Communication Technology, Chengdu, China, 19–21 October 2012; pp. 1022–1026. [Google Scholar] [CrossRef]
- Shani, G.; Gunawardana, A. Evaluating recommendation systems. In Recommender Systems Handbook; Springer: Berlin, Germany, 2011; pp. 257–297. [Google Scholar]
- Hosseini, M. Feature Selection for Microarray Classification Problems. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2018. [Google Scholar]
- Brankovic, A.; Hosseini, M.; Piroddi, L. A Distributed Feature Selection Algorithm Based on Distance Correlation with an Application to Microarrays. ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1802–1815. [Google Scholar] [CrossRef]
- Rajeswari, K. Feature selection by mining optimized association rules based on apriori algorithm. Int. J. Comput. Appl. 2015, 119, 30–34. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5966–5978. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–10. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Cea-Morán, J.J.; González-Briones, A.; De La Prieta, F.; Prat-Pérez, A.; Prieto, J. Extraction of Travellers’ Preferences Using Their Tweets. In Proceedings of the International Symposium on Ambient Intelligence; Springer: Berlin, Germany, 2020; pp. 224–235. [Google Scholar]
- Rivas, A.; González-Briones, A.; Cea-Morán, J.J.; Prat-Pérez, A.; Corchado, J.M. My-Trac: System for Recommendation of Points of Interest on the Basis of Twitter Profiles. Electronics 2021, 10, 1263. [Google Scholar] [CrossRef]
- Manca, M.; Boratto, L.; Morell Roman, V.; Martori i Gallissà, O.; Kaltenbrunner, A. Using social media to characterize urban mobility patterns: State-of-the-art survey and case-study. Online Soc. Netw. Media 2017, 1, 56–69. [Google Scholar] [CrossRef]
- Balduini, M.; Brambilla, M.; Della Valle, E.; Marazzi, C.; Arabghalizi, T.; Rahdari, B.; Vescovi, M. Models and Practices in Urban Data Science at Scale. Big Data Res. 2019, 17, 66–84. [Google Scholar] [CrossRef] [Green Version]
- Javadian Sabet, A. Social Media Posts Popularity Prediction during Long-Running Live Events. A Case Study on Fashion Week. Master’s Thesis, Politecnico di Milano, Milan, Italy, 2019. [Google Scholar]
- Brambilla, M.; Javadian Sabet, A.; Hosseini, M. The role of social media in long-running live events: The case of the Big Four fashion weeks dataset. Data Brief 2021, 35, 106840. [Google Scholar] [CrossRef]
- Javadian Sabet, A.; Brambilla, M.; Hosseini, M. A multi-perspective approach for analyzing long-running live events on social media: A case study on the “Big Four” international fashion weeks. Online Soc. Netw. Media 2021, 24, 100140. [Google Scholar] [CrossRef]
- Brambilla, M.; Javadian, A.; Sulistiawati, A.E. Conversation Graphs in Online Social Media. In Proceedings of the Web Engineering, ICWE 2021, Biarritz, France, 18–21 May 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 97–112. [Google Scholar] [CrossRef]
- Brambilla, M.; Javadian Sabet, A.; Kharmale, K.; Sulistiawati, A.E. Graph-Based Conversation Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 113. [Google Scholar] [CrossRef]
- Scotti, V.; Tedesco, R.; Sbattella, L. A Modular Data-Driven Architecture for Empathetic Conversational Agents. In Proceedings of the 2021 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 17–20 January 2021; pp. 365–368. [Google Scholar] [CrossRef]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javadian Sabet, A.; Shekari, M.; Guan, C.; Rossi, M.; Schreiber, F.; Tanca, L. THOR: A Hybrid Recommender System for the Personalized Travel Experience. Big Data Cogn. Comput. 2022, 6, 131. https://doi.org/10.3390/bdcc6040131
Javadian Sabet A, Shekari M, Guan C, Rossi M, Schreiber F, Tanca L. THOR: A Hybrid Recommender System for the Personalized Travel Experience. Big Data and Cognitive Computing. 2022; 6(4):131. https://doi.org/10.3390/bdcc6040131
Chicago/Turabian StyleJavadian Sabet, Alireza, Mahsa Shekari, Chaofeng Guan, Matteo Rossi, Fabio Schreiber, and Letizia Tanca. 2022. "THOR: A Hybrid Recommender System for the Personalized Travel Experience" Big Data and Cognitive Computing 6, no. 4: 131. https://doi.org/10.3390/bdcc6040131